컴퓨터의 뇌구조는 어떻게 생겼길래 방대한 데이터를 빠르고 효율적으로 처리할 수 있는걸까?
비트(Bit)의 개념
사실 컴퓨터가 이해할 수 있는 최소의 정보 단위는 0과 1이라는 사실!
컴퓨터는 이처럼 0과 1의 조합으로 이루어진 정보들을 처리할 수 있는데, 컴퓨터가 처리할 수 있는 가장 작은 단위의 정보를 나타내는 것이 "Bit" 입니다.
Bit는 0 또는 1이라는 정보를 담을 수 있는데, 신호가 있고 없고 불이 켜지고 꺼지고 0과 1 이런 기본적인 정보만 처리할 수 있다.
우리 사람은 10개의 손가락을 이용해서 숫자 1부터 10까지 10진수를 다룰 수 있지만 컴퓨터는 신호가 있고 없고 딱 두가지로만 다룰 수 있습니다. 그리고 이런 2진수들이 모여서 조금 더 큰 범위의 데이터를 담을 수 있는것!
1bit는 0과 1 딱 두가지만 담을 수 있고 2bit는 4가지 조합(00, 01, 10, 11)을 담을 수 있다.
1비트는 정보의 최소 단위지만 데이터를 저장하거나 처리할 때는 1바이트(8비트)가 기본 단위로 사용된다. 1바이트는 8비트로 구성이 되어져 있기 때문에 256가지의 다른 정보들을 담을 수 있다.
(2를 8번 곱했다!!)
숫자로 친다면 256가지의 다른 숫자를 담을 수 있으므로 숫자 0부터 시작한다면 0,255까지의 숫자를 나타낼 수 있다.
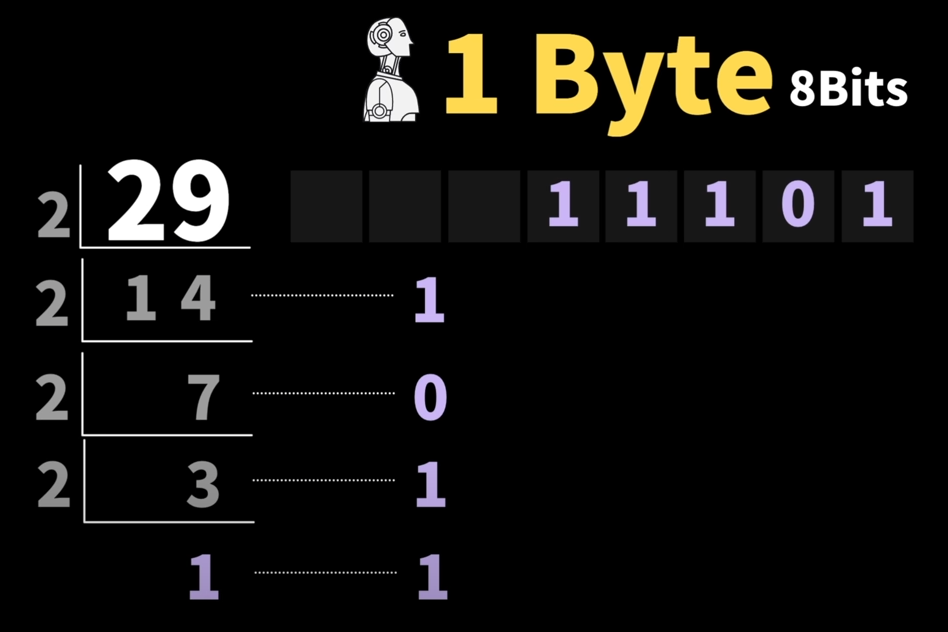
우리 사람에게 익숙한 숫자29를 2진수로 나타내는 방법은 2로 나누어지지 않을 때까지 계속해서 2로 나누면 됩니당. 이렇게 되면 2진수로는 11101.

다시 2진수를 10진수로 변환하고 싶다면 나누기 했던 것과 반대로 각각의 비트에 위치를 2의0승 2의1승 숫자를 증가해서 곱한 다음에 곱한 결과값을 모두 더하면 10진수로 만들 수 있다.
ASCII (American Standard Code for Information Interchange)
그렇다면 문자열은 어떻게 변환을 할까?
ASCII는 컴퓨터에서 문자와 숫자를 저장 및 처리하기 위해 사용하는 문자 인코딩 표준으로 주로 영어 알파벳과 숫자, 특수문자를 표현하는 데 사용된다.
문자열은 특정한 규칙이 있는것이 아니라 사람들이 미리 약속해둔 테이블을 이용해서 서로 변환을 할 수 있다.
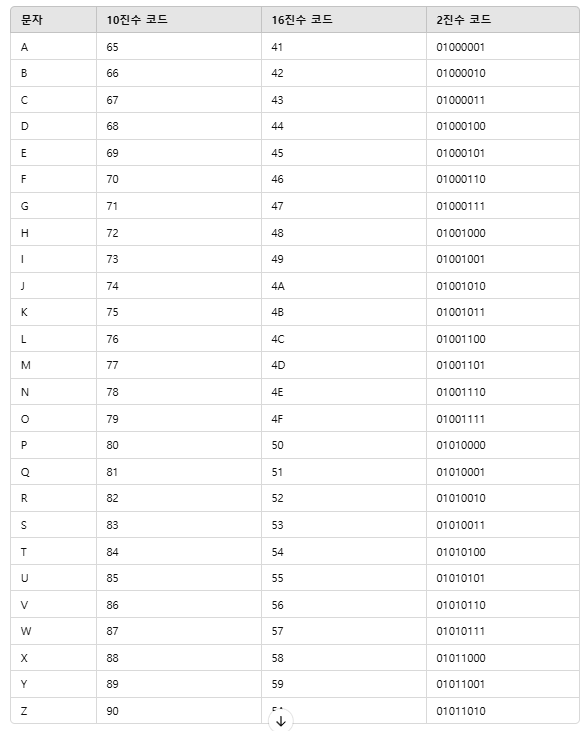
ascii 코드는 모든 문자열이 들어있지 않아서 한계가 있다.
그래서 그 뒤에 생겨난 것이 Unicode입니당
유니코드(Unicode)란?
전 세계 모든 언어의 문자를 고유한 코드 값으로 정의하는 문자 인코딩 표준이다.
컴퓨터 시스템에서 다양한 언어와 문자를 일관성 있게 표현하고 처리하기 위해 만들어졌다.
과거에는 ASCII와 같은 표준이 영어 중심으로 만들어져서 한글, 중국어, 일본어 등 다른 언어를 표현하기 어려웠다.
유니코드는 이러한 문제를 해결하기 위해 등장해서 전 세계 모든 문자를 단일 표준으로 통합하고자 했다.
ASCII는 128개의 문자만 표현할 수 있었지만 유니코드는 전 세계 언어의 문자를 포함하여 수백만 개의 문자를 표현 가능.
유니코드 코드 포인트(문자 코드 값)는 16진수로 표기되며 범위는 U+0000 ~ U+10FFFF.
예:
영어 A: U+0041
한글 가: U+AC00
이모지 😊: U+1F60A
새로운 언어와 문자가 추가될 가능성을 열어두고 최신 유니코드 버전에서는 다양한 이모지와 특수 문자가 지속적으로 추가되고 있다.
유니코드는 기존 ASCII와 하위 호환되도록 설계되어 유니코드의 첫 128개 문자는 ASCII와 동일.
이런 bit와 byte에 대해서 이해하는 것이 왜 중요할까?
프로그래밍에서 변수를 선언할 때 어떤 데이터 타입이냐에 따라서 메모리에 공간이 얼마나 크게 확보되는지 정해진다. 메모리가 넉넉하지 못한 환경에서 동작하는 경우에는 이런 데이터 타입을 알맞게 효율적으로 사용해서 작성하는 것이 중요하기 때문이죠.
