form 태그
: 하위의 input 태그들에서 수집된 데이터들을 백엔드로 전달하는 역할
- method 속성
post: 입력창에 입력한 내용이 드러나지 않음(로그인, 게시물 작성)
get: url 에 입력한 내용이 input 의 name 속성과 같이 드러남(북마크)- 링크를 타고 넘어가는 방식(페이지를 이동하는 요청)도 get 방식
- action 속성
- 백엔드의 파일명
- 웹 프레임워크에서 인식할 수 있는 url 주소
get 요청
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form method="get" action="action.php">
<input name="search" type="text"/>
</form>
</body>
</html>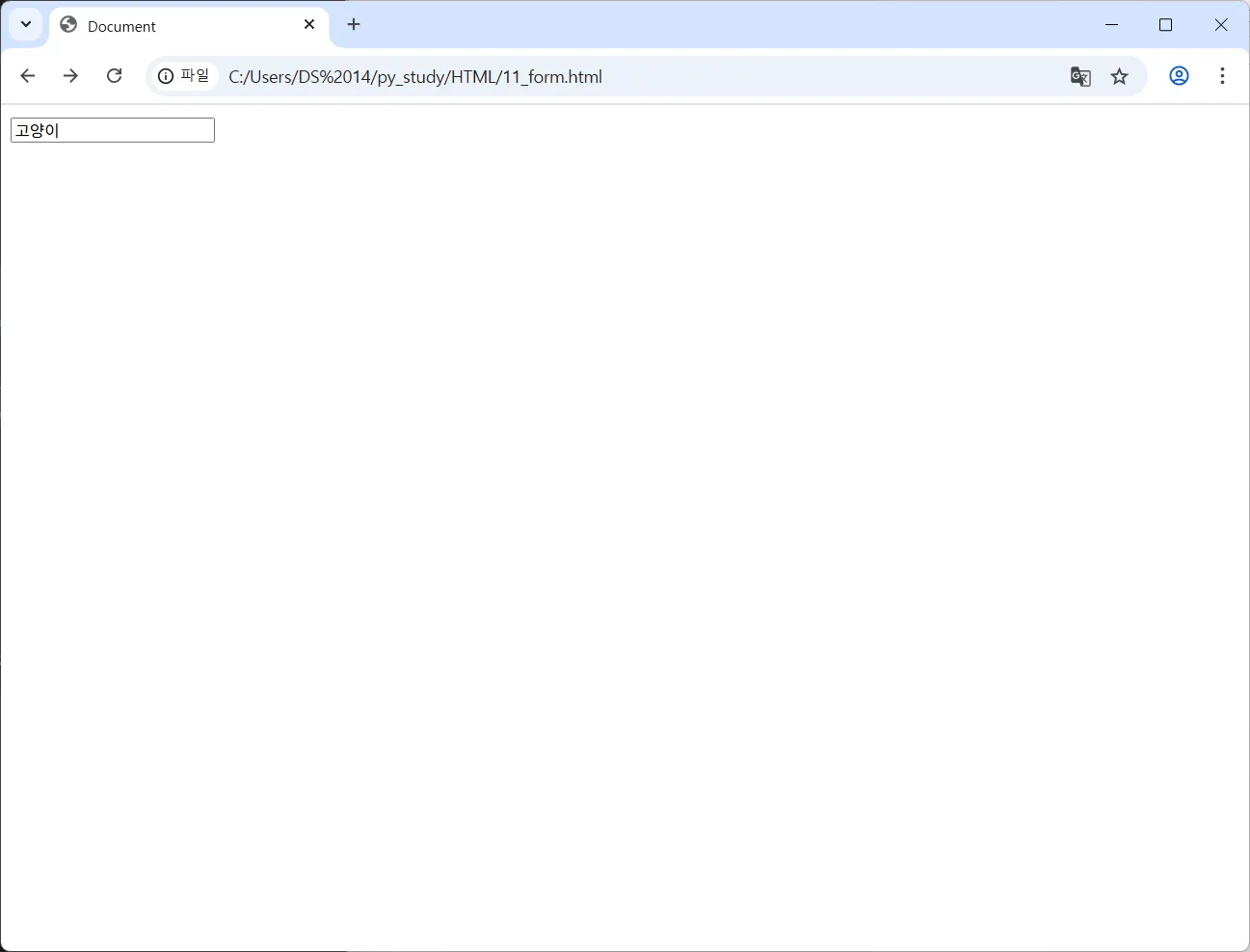
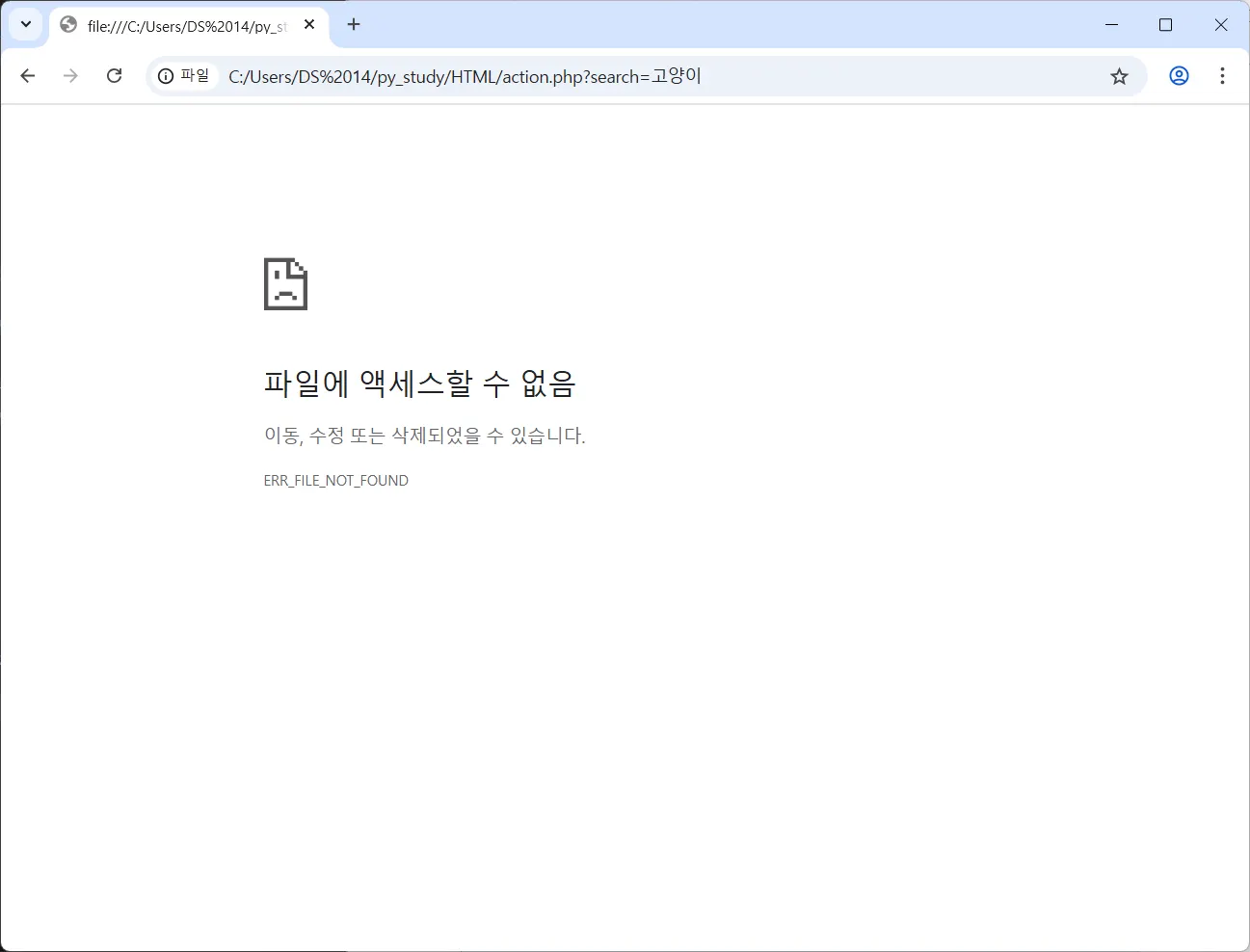
고양이 입력 후 엔터치면 action.php 로 search=고양이 쿼리를 보내 get 요청이 가므로 action.php 가 존재하지 않기에 “파일에 액세스할 수 없음” 에러 발생
post 요청
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form method="post" action="action.php">
<input name="search" type="text"/>
<input type="submit"/>
</form>
</body>
</html>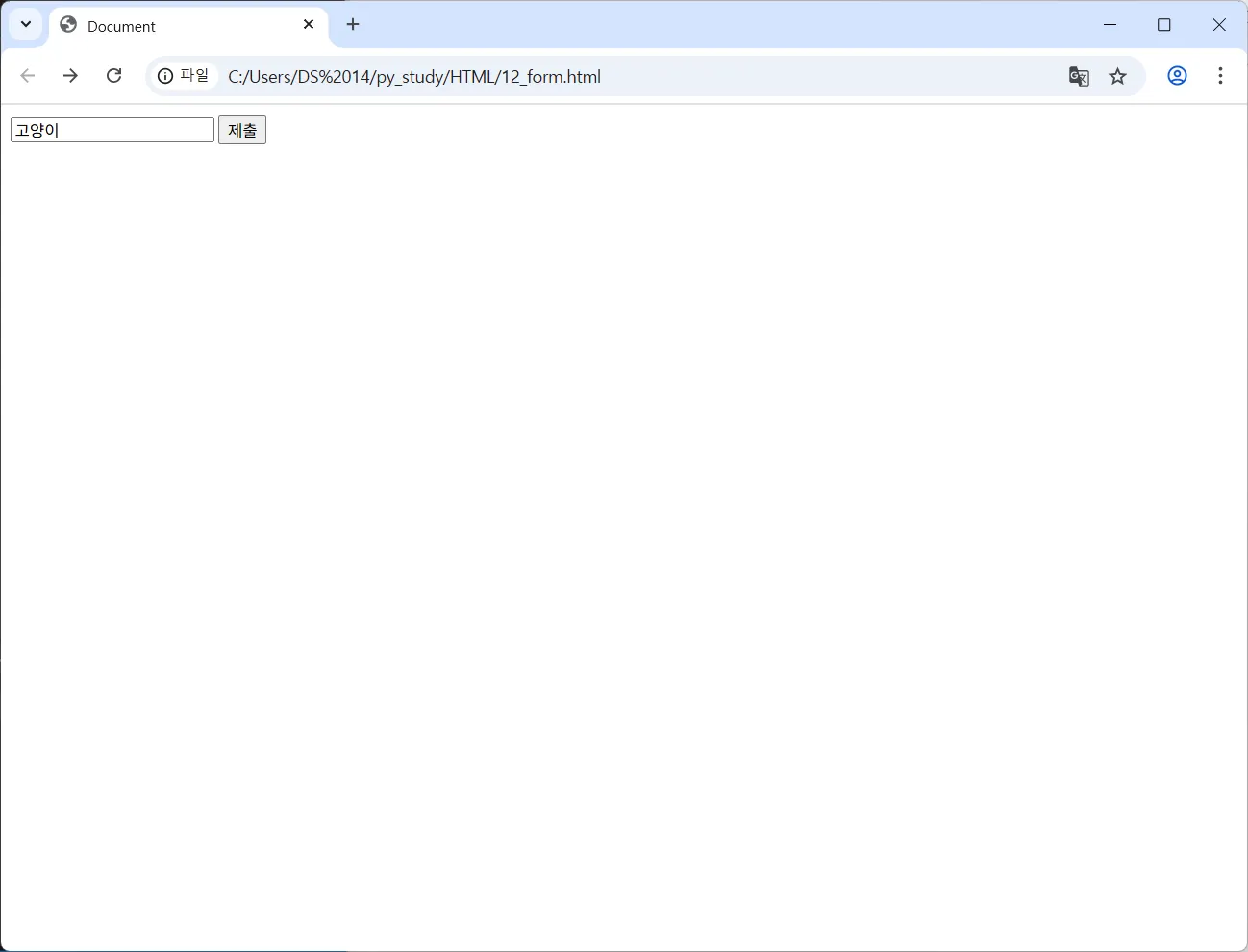
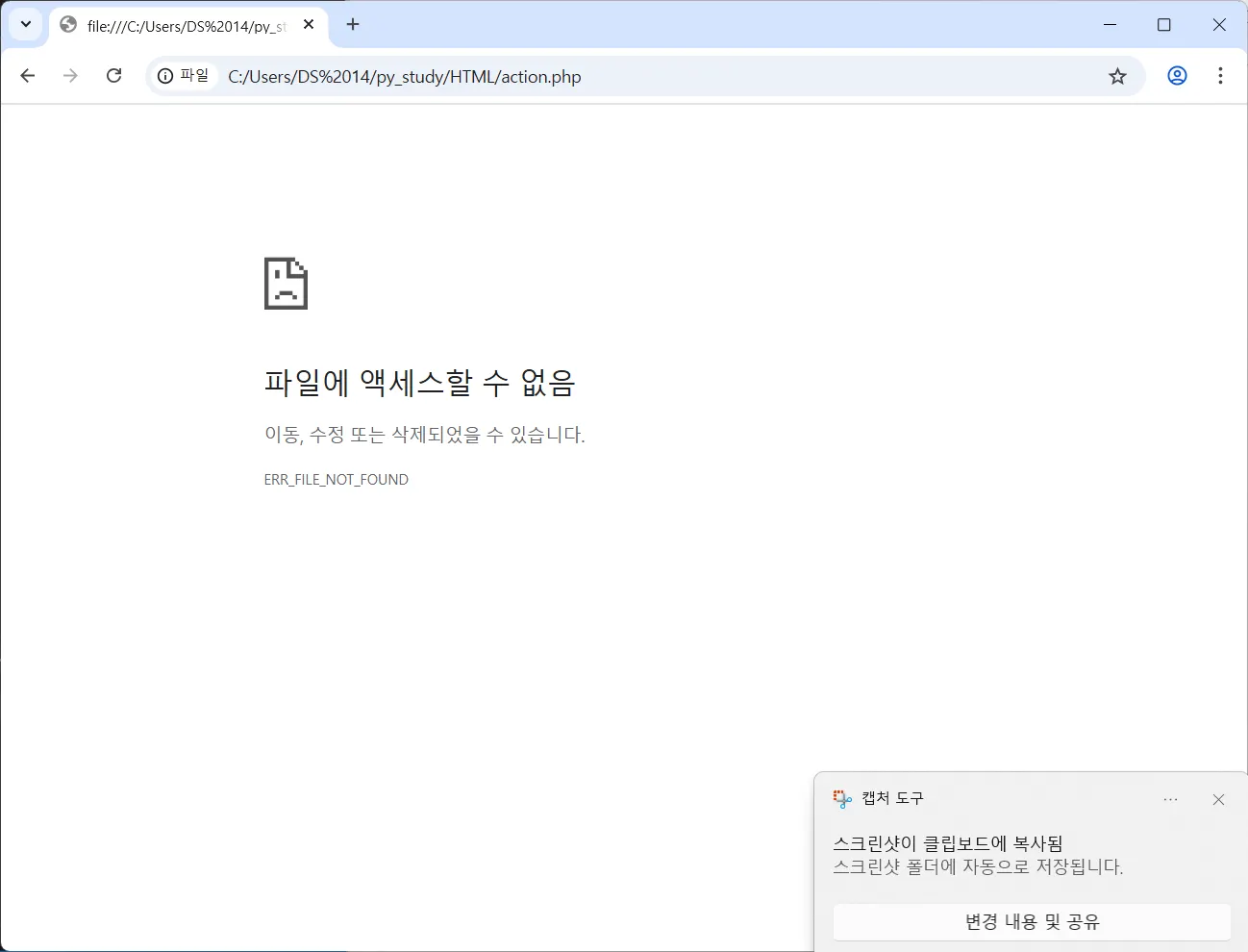
url 에 쿼리가 아닌 action.php 로 post 요청이 간 것을 확인 가능
label 태그
<!-- label 태그를 사용할 경우 -->
<!-- css 적용이 잘 되는 코드(권장 O) -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form method="post" action="action.php">
<!-- 텍스트와 입력란이 하나로 묶여 있음을 명시-->
<!-- input 태그에 id 속성 사용-->
<!-- label 태그에 for 속성 사용-->
<label for="id">아이디(6자 이상)</label>
<input type="text" name="id" id="id"/>
</form>
</body>
</html>라벨 사용시 다음 줄 표현
→ br 태그를 사용하여 강제 줄 바꿈
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form method="post" action="action.php">
<label for="id">아이디(6자 이상)</label>
<input type="text" name="id" id="id"/>
<br>
<label for="pw">비밀번호</label>
<input type="password" name="pw" id="pw"/>
</form>
</body>
</html>리스트 태그를 이용해 자연스럽게 줄바꿈
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<-- css 태그: ul 에서 불릿 제거 -->
<style>
ul {
list-style-type: none;
}
</style>
<title>Document</title>
</head>
<body>
<form method="post" action="action.php">
<br>
<ul>
<li>
<label for="id">아이디(6자 이상)</label>
<input type="text" name="id" id="id"/>
</li>
<li>
<label for="pw">비밀번호</label>
<input type="password" name="pw" id="pw"/>
</li>
</ul>
</form>
</body>
</html>input 태그
: 입력을 받음
: form 내부에 위치해야 함
type 속성
- hidden : 사용자에게는 보이지 않지만 서버로 넘겨줘야 하는 값이 있을 때 사용
- text : 한 줄짜리 텍스트를 입력할 수 있는 상자 제공
- search : 검색 상자 제공
- tel : 전화번호 상자 제공
- url : url 입력 상자 제공(http 또는 https 가 포함되어야 함)
- email : email 입력 상자 제공(@가 포함되어야 함)
- password : 비밀번호 입력 상자 제공(입력할 때 가려줌)
- number : 숫자 입력 상자 제공(숫자만 입력 가능, 스핀 박스 제공)
- radio : 라디오 버튼(단일 항목 선택)
- checkbox : 체크 박스 버튼(다중 항목 선택)
값이 넘어가야 하면 name 속성은 무조건 붙는다고 봐야 함
크롤링(Crawling)
: 페이지의 정보를 긁어오는 것
- selenium : 웹 매크로
- beautifulsoup : 태그의 내용으로 데이터를 가져오는 것
필수 모듈
- beautifulsoup : html 태그 정보를 긁어오기 위해 필요
# 설치 pip install beautifulsoup4 - requests : html 태그 정보를 가져오려면 요청을 먼저 보내야 함
# 설치 pip install requests
쿼리 뒤에는 삭제해도 똑같이 결과가 나오는지 규칙 찾기
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=고양이
url에서 어떤 부분을 바뀌면 바뀌는지를 잘 체크해야 해서 패턴을 파악해야 함
- 입력값을 직접 넣기 위해
- for 문 사용을 위해
# 검색할 부분에 입력될 내용을 직접 입력 받기
query = input('검색할 키워드를 입력하세요: ')
url = f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query={query}"# 완성된 url 주소로 요청을 보내고 응답을 받아야 html 태그들의 정보를 수집할 수 있음
response = requests.get(url)- 여기서
requests.get()은 requests 라이브러리의 함수 - 반환되는
response는requests.models.Response객체 - 이 객체 안에는 서버에서 받은 HTTP 응답 정보가 들어 있음
response.status_code: HTTP 상태 코드 (예: 200, 404)response.headers: 응답 헤더 정보 (dict 형태)response.text: 응답 본문을 문자열(유니코드)로 변환한 값response.content: 응답 본문을 원본 bytes 형태로 반환response.json(): JSON 응답을 바로 파싱 가능 (JSON일 경우)
# 넘어온 응답 html text 로 변경
html_text = response.text- BeautifulSoup 은 HTML/XML을 파싱해서 트리 구조로 만들어 주는 라이브러리
"html.parser"로 파서 지정- 파서(parser) = HTML 문서를 해석해서 태그 트리를 만드는 도구
"html.parser"는 파이썬 표준 라이브러리에 내장된 HTML 파서
# beautifulsoup 가공을 통해서 html 정보를 파싱하고, 변수에 저장
soup = bs(html_text, "html.parser")
# html 구조를 정렬해서 출력
print(soup.prettify())prettify() 의 역할
- BeautifulSoup 객체(
soup)를 사람이 보기 좋게 정렬해서 문자열로 반환. - 들여쓰기(indent)와 줄바꿈을 넣어 HTML 구조를 보기 쉽게 해줌.
- 예: 원래는 한 줄로 쭉 늘어져 있는 HTML → 계층 구조에 따라 정리된 코드로 출력.
크롤링 전체 코드
# 페이지의 정보를 긁어오는 것: 크롤링
from bs4 import BeautifulSoup as bs
import requests
# https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query={}
# 검색할 부분에 입력된 내용을 직접 입력 받기
query = input('검색할 키워드를 입력하세요: ')
url = f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query={query}"
# 완성된 url 주소로 요청을 보내고 응답을 받아야 html 태그들의 정보를 수집할 수 있음
response = requests.get(url)
# 넘어온 응답 html text 로 변경
html_text = response.text
# beautifulsoup 가공을 통해서 html 정보를 파싱하고, 변수에 저장
soup = bs(html_text, "html.parser")
# html 구조를 정렬해서 출력
# print(soup.prettify())
# 실제 데이터를 가져올 경우 가져오지 않을 것과 구별 필요
# 속성 구분 필요(class)
news_title = soup.select("a.Vyg_WCkzlKBSk8usfmMA.Kv_vr2pgKJ1YQu5GxPEk")
# 정보 수집 출력
for i in news_title:
title = i.get_text()
print(title)실행 결과
검색할 키워드를 입력하세요: 추석
"35만원에 팝니다"...李 대통령 추석선물 벌써 당근 매물로
SK하닉, 추석 앞두고 협력사 거래대금 2655억 조기 지급
SK하이닉스, 추석맞아 협력사 거래대금 2655억 조기 지급
로보락, 추석 맞이 팝업스토어 열어입력: 추석
출력: 네이버에 추석 검색어 입력시 나오는 뉴스의 제목들

새싹 개발자