numpy
수치해석용 파이썬 패키지
숫자를 리스트로 처리할 시 메모리의 사용이 상대적으로 큼
numpy는 C 언어를 기반으로 한 패키지이므로 적은 메모리로 빠른 연산이 가능배열 vs. 리스트
리스트 연산
# 리스트에서 곱하기 2한 결과를 출력
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(data * 2)
''' 결과
[1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 리스트에서 곱하기 2한 결과를 출력
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = []
for dl in data:
result.append(dl * 2)
print(result)
'''결과
[2, 4, 6, 8, 10, 12, 14, 16, 18]배열 연산
# 배열에서 곱하기 2한 결과를 출력
data = [1,2,3,4,5,6,7,8,9]
ar = np.array(data)
print(ar * 2)
'''결과
[ 2 4 6 8 10 12 14 16 18]API 활용
인증키 받아오기
https://www.data.go.kr/index.do
-
회원가입 후 로그인
-
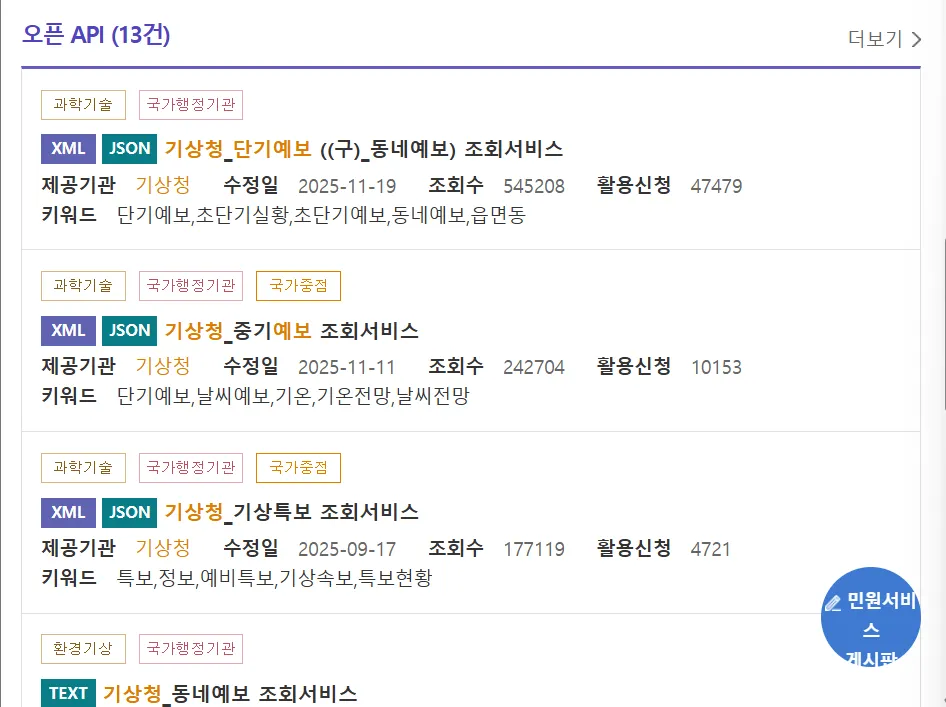
기상청 단기예보 검색
-
오픈 API 탭에서 선택
-
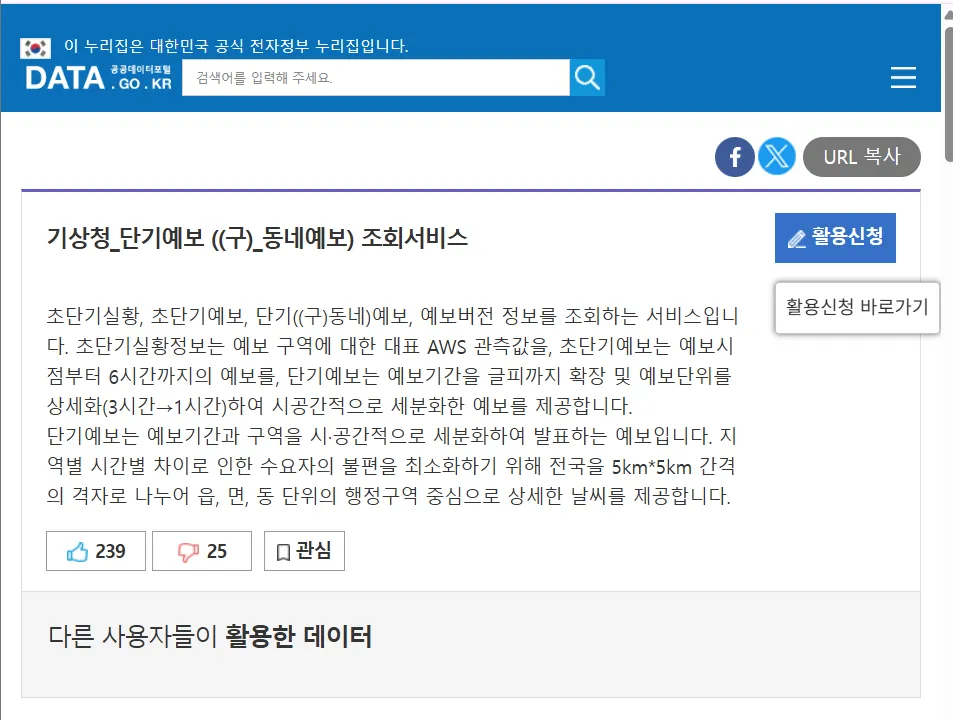
활용 신청 클릭
-
활용 목적 작성 후 신청
-
마이페이지 - API 신청 - 활용신청 현황
-
인증키 복사
모두 회원가입
https://data.kma.go.kr/cmmn/main.do
https://kosis.kr/index/index.do
데이터 결합하고 분해하기
데이터 연결하기
📌데이터프레임 살펴보기
df.index()
: 데이터프레임의 축
df.columns()
: 데이터프레임의 열 이름
df.values()
: 값으로 구성된 넘파이 배열 반환
행 방향 연결하기
row_concat = pd.concat([df1, df2, df3])
print(row_concat) A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
0 a4 b4 c4 d4
1 a5 b5 c5 d5
2 a6 b6 c6 d6
3 a7 b7 c7 d7
0 a8 b8 c8 d8
1 a9 b9 c9 d9
2 a10 b10 c10 d10
3 a11 b11 c11 d11
행 이름(인덱스)에서 0부터 3까지의 숫자가 반복되는 것을 알 수 있음
print(row_concat.iloc[3, :])A a3
B b3
C c3
D d3
Name: 3, dtype: object연결한 데이터프레임도 일반 데이터프레임과 마찬가지로 원하는 데이터 추출 가능
시리즈 생성하여 데이터프레임에 연결
# 시리즈 직접 생성 후 데이터프레임과 행 결합
new_row_series = pd.Series(['n1', 'n2', 'n3', 'n4'])
print(pd.concat([df1, new_row_series])) A B C D 0
0 a0 b0 c0 d0 NaN
1 a1 b1 c1 d1 NaN
2 a2 b2 c2 d2 NaN
3 a3 b3 c3 d3 NaN
0 NaN NaN NaN NaN n1
1 NaN NaN NaN NaN n2
2 NaN NaN NaN NaN n3
3 NaN NaN NaN NaN n4의도한 결과와 다르게 데이터프레임 생성됨
시리즈를 데이터프레임의 새로운 행으로 추가하려고 했으나 뜻대로 되지 않음
📌Why?
- 시리즈에 데이터프레임과 일치하는 열이 없으므로 시리즈가 새로운 열로 추가됨
- 이를 새로운 행으로 데이터 프레임 가장 아래에 덧붙이고 기존 인덱스는 그대로 유지함
이 문제를 해결하기 위해선 시리즈를 데이터프레임으로 바꿔야 함
new_row_df = pd.DataFrame(
data=[['n1', 'n2', 'n3', 'n4']],
columns=['A', 'B', 'C', 'D'],
)
print(new_row_series)0 n1
1 n2
2 n3
3 n4
dtype: object생성한 데이터프레임을 df1 에 연결
print(pd.concat([df1, new_row_df]))
'''결과
A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
0 n1 n2 n3 n4새로운 인덱스 설정하기
이전 실습에서는 행 인덱스를 단순히 덧붙이면서 중복 값이 생김
기존 데이터의 행 인덱스를 무시하고 새로운 인덱스를 부여하려면 매개변수 ignore_index 를 사용하면 됨
# 행 인덱스 재지정
row_concat_i = pd.concat([df1, df2, df3], ignore_index=True)
# 행이 지정되어 있는 경우에서는 사용하지 않음
print(row_concat_i)
'''결과
A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
5 a5 b5 c5 d5
6 a6 b6 c6 d6
7 a7 b7 c7 d7
8 a8 b8 c8 d8
9 a9 b9 c9 d9
10 a10 b10 c10 d10
11 a11 b11 c11 d11열 방향 연결하기
# 좌우로 열 합치기
col_concat = pd.concat([df1, df2, df3], axis = 1)
print(col_concat)
'''결과
A B C D A B C D A B C D
0 a0 b0 c0 d0 a4 b4 c4 d4 a8 b8 c8 d8
1 a1 b1 c1 d1 a5 b5 c5 d5 a9 b9 c9 d9
2 a2 b2 c2 d2 a6 b6 c6 d6 a10 b10 c10 d10
3 a3 b3 c3 d3 a7 b7 c7 d7 a11 b11 c11 d11열 이름 중복
열 이름이 다른 데이터 행 방향 연결하기
# 열이름을 재지정하여 다르게 만들고 행 합치기
df1.columns = ['A', 'B', 'C', 'D']
df2.columns = ['E', 'F', 'G', 'H']
df3.columns = ['A', 'C', 'F', 'H']
print(pd.concat([df1, df3]))
'''결과
A B C D F H
0 a0 b0 c0 d0 NaN NaN
1 a1 b1 c1 d1 NaN NaN
2 a2 b2 c2 d2 NaN NaN
3 a3 b3 c3 d3 NaN NaN
0 a8 NaN b8 NaN c8 d8
1 a9 NaN b9 NaN c9 d9
2 a10 NaN b10 NaN c10 d10
3 a11 NaN b11 NaN c11 d11공통된 열을 이용하여 행 합치기 (join=’inner’)
# 결측치의 값이 필요없다면 공통된 열을 이용하여 행 합치기 가능
print(pd.concat([df1, df3], join='inner'))
'''결과
A C
0 a0 c0
1 a1 c1
2 a2 c2
3 a3 c3
0 a8 b8
1 a9 b9
2 a10 b10
3 a11 b11인덱스가 다른 데이터 열 방향 연결하기
# 행 이름을 다르게 지정하여 열로 합치기
df1.index = [0, 1, 2, 3]
df2.index = [4, 5, 6, 7]
df3.index = [0, 2, 5, 7]
print(df1)
print(df2)
print(df3)
'''결과
A B C D
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
E F G H
4 a4 b4 c4 d4
5 a5 b5 c5 d5
6 a6 b6 c6 d6
7 a7 b7 c7 d7
A C F H
0 a8 b8 c8 d8
2 a9 b9 c9 d9
5 a10 b10 c10 d10
7 a11 b11 c11 d11열 방향 합치기
row_concat = pd.concat([df1, df2, df3], axis=1)
print(row_concat)
'''결과
A B C D E F G H A C F H
0 a0 b0 c0 d0 NaN NaN NaN NaN a8 b8 c8 d8
1 a1 b1 c1 d1 NaN NaN NaN NaN NaN NaN NaN NaN
2 a2 b2 c2 d2 NaN NaN NaN NaN a9 b9 c9 d9
3 a3 b3 c3 d3 NaN NaN NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN a4 b4 c4 d4 NaN NaN NaN NaN
5 NaN NaN NaN NaN a5 b5 c5 d5 a10 b10 c10 d10
6 NaN NaN NaN NaN a6 b6 c6 d6 NaN NaN NaN NaN
7 NaN NaN NaN NaN a7 b7 c7 d7 a11 b11 c11 d11# 두 개의 데이터프레임 열 방향으로 연결하기
col_concat = pd.concat([df1, df3], axis=1)
print(col_concat)
'''결과
A B C D A C F H
0 a0 b0 c0 d0 a8 b8 c8 d8
1 a1 b1 c1 d1 NaN NaN NaN NaN
2 a2 b2 c2 d2 a9 b9 c9 d9
3 a3 b3 c3 d3 NaN NaN NaN NaN
5 NaN NaN NaN NaN a10 b10 c10 d10
7 NaN NaN NaN NaN a11 b11 c11 d11그냥 덧붙여짐
공통된 행을 가진 열의 값 출력
print(pd.concat([df1, df3], axis=1, join='inner'))
'''결과
A B C D A C F H
0 a0 b0 c0 d0 a8 b8 c8 d8
2 a2 b2 c2 d2 a9 b9 c9 d9axis=0, join='inner'
: 공통된 열을 가진 행의 값 출력
print(pd.concat([df1, df3], join='inner'))
'''결과
A C
0 a0 c0
1 a1 c1
2 a2 c2
3 a3 c3
0 a8 b8
1 a9 b9
2 a10 b10
3 a11 b11axis=1, join='inner'
: 공통된 행을 가진 열의 값 출력
print(pd.concat([df1, df3], axis=1, join='inner'))
'''결과
A B C D A C F H
0 a0 b0 c0 d0 a8 b8 c8 d8
2 a2 b2 c2 d2 a9 b9 c9 d9분할된 데이터 연결하기
다수의 파일을 불러오기 위해 패턴 만들기
from pathlib import Path
billboard_data_files = (
Path('.').glob('./billboard-*.xlsx')
)
# 리스트로 변환 후 정렬
billboard_data_files = sorted(list(billboard_data_files))
print(billboard_data_files)[PosixPath('billboard-01.xlsx'), PosixPath('billboard-02.xlsx'), PosixPath('billboard-03.xlsx'), PosixPath('billboard-04.xlsx'), PosixPath('billboard-05.xlsx'), PosixPath('billboard-06.xlsx'), PosixPath('billboard-07.xlsx'), PosixPath('billboard-08.xlsx'), PosixPath('billboard-09.xlsx'), PosixPath('billboard-10.xlsx'), PosixPath('billboard-11.xlsx'), PosixPath('billboard-12.xlsx'), PosixPath('billboard-13.xlsx'), PosixPath('billboard-14.xlsx'), PosixPath('billboard-15.xlsx'), PosixPath('billboard-16.xlsx'), PosixPath('billboard-17.xlsx'), PosixPath('billboard-18.xlsx'), PosixPath('billboard-19.xlsx'), PosixPath('billboard-20.xlsx'), PosixPath('billboard-21.xlsx'), PosixPath('billboard-22.xlsx'), PosixPath('billboard-23.xlsx'), PosixPath('billboard-24.xlsx'), PosixPath('billboard-25.xlsx'), PosixPath('billboard-26.xlsx'), PosixPath('billboard-27.xlsx'), PosixPath('billboard-28.xlsx'), PosixPath('billboard-29.xlsx'), PosixPath('billboard-30.xlsx'), PosixPath('billboard-31.xlsx'), PosixPath('billboard-32.xlsx'), PosixPath('billboard-33.xlsx'), PosixPath('billboard-34.xlsx'), PosixPath('billboard-35.xlsx'), PosixPath('billboard-36.xlsx'), PosixPath('billboard-37.xlsx'), PosixPath('billboard-38.xlsx'), PosixPath('billboard-39.xlsx'), PosixPath('billboard-40.xlsx'), PosixPath('billboard-41.xlsx'), PosixPath('billboard-42.xlsx'), PosixPath('billboard-43.xlsx'), PosixPath('billboard-44.xlsx'), PosixPath('billboard-45.xlsx'), PosixPath('billboard-46.xlsx'), PosixPath('billboard-47.xlsx'), PosixPath('billboard-48.xlsx'), PosixPath('billboard-49.xlsx'), PosixPath('billboard-50.xlsx'), PosixPath('billboard-51.xlsx'), PosixPath('billboard-52.xlsx'), PosixPath('billboard-53.xlsx'), PosixPath('billboard-54.xlsx'), PosixPath('billboard-55.xlsx'), PosixPath('billboard-56.xlsx'), PosixPath('billboard-57.xlsx'), PosixPath('billboard-58.xlsx'), PosixPath('billboard-59.xlsx'), PosixPath('billboard-60.xlsx'), PosixPath('billboard-61.xlsx'), PosixPath('billboard-62.xlsx'), PosixPath('billboard-63.xlsx'), PosixPath('billboard-64.xlsx'), PosixPath('billboard-65.xlsx'), PosixPath('billboard-66.xlsx'), PosixPath('billboard-67.xlsx'), PosixPath('billboard-68.xlsx'), PosixPath('billboard-69.xlsx'), PosixPath('billboard-70.xlsx'), PosixPath('billboard-71.xlsx'), PosixPath('billboard-72.xlsx'), PosixPath('billboard-73.xlsx'), PosixPath('billboard-74.xlsx'), PosixPath('billboard-75.xlsx'), PosixPath('billboard-76.xlsx')]- 빌보드 차트 데이터 합치기
- 판다스는 다수의 파일을 한 번에 불러오는 것이 불가능함
- 파일에 대한 패턴을 먼저 만들고 불러와야 함
각 파일을 데이터프레임으로 불러옴
# 데이터프레임 객체 생성
billboard01 = pd.read_excel(billboard_data_files[0])
billboard02 = pd.read_excel(billboard_data_files[1])
billboard03 = pd.read_excel(billboard_data_files[2])
print(billboard01)
'''
year artist track time date.entered \
0 2000 2 Pac Baby Don't Cry (Keep... 04:22:00 2000-02-26
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02
2 2000 3 Doors Down Kryptonite 03:53:00 2000-04-08
3 2000 3 Doors Down Loser 04:24:00 2000-10-21
4 2000 504 Boyz Wobble Wobble 03:35:00 2000-04-15
.. ... ... ... ... ...
312 2000 Yankee Grey Another Nine Minutes 03:10:00 2000-04-29
313 2000 Yearwood, Trisha Real Live Woman 03:55:00 2000-04-01
314 2000 Ying Yang Twins Whistle While You Tw... 04:19:00 2000-03-18
315 2000 Zombie Nation Kernkraft 400 03:30:00 2000-09-02
316 2000 matchbox twenty Bent 04:12:00 2000-04-29
week rating
0 wk1 87
1 wk1 91
2 wk1 81
3 wk1 76
4 wk1 57
.. ... ...
312 wk1 86
313 wk1 85
314 wk1 95
315 wk1 99
316 wk1 60
[317 rows x 7 columns]각 데이터프레임의 shape 확인
print(billboard01.shape)
print(billboard02.shape)
print(billboard03.shape)
'''
(317, 7)
(317, 7)
(317, 7)concat()으로 불러온 데이터 연결
# concat() 함수로 행 합치기(샘플 합치기)
billboard = pd.concat([billboard01, billboard02, billboard03])
print(billboard)
'''
year artist track time date.entered \
0 2000 2 Pac Baby Don't Cry (Keep... 04:22:00 2000-02-26
1 2000 2Ge+her The Hardest Part Of ... 03:15:00 2000-09-02
2 2000 3 Doors Down Kryptonite 03:53:00 2000-04-08
3 2000 3 Doors Down Loser 04:24:00 2000-10-21
4 2000 504 Boyz Wobble Wobble 03:35:00 2000-04-15
.. ... ... ... ... ...
312 2000 Yankee Grey Another Nine Minutes 03:10:00 2000-04-29
313 2000 Yearwood, Trisha Real Live Woman 03:55:00 2000-04-01
314 2000 Ying Yang Twins Whistle While You Tw... 04:19:00 2000-03-18
315 2000 Zombie Nation Kernkraft 400 03:30:00 2000-09-02
316 2000 matchbox twenty Bent 04:12:00 2000-04-29
week rating
0 wk1 87.0
1 wk1 91.0
2 wk1 81.0
3 wk1 76.0
4 wk1 57.0
.. ... ...
312 wk3 77.0
313 wk3 83.0
314 wk3 91.0
315 wk3 NaN
316 wk3 29.0
[951 rows x 7 columns]데이터프레임이 올바르게 연결되었는지 assert 문으로 행의 개수를 비교해 확인
assert (
billboard01.shape[0]
+ billboard02.shape[0]
+ billboard03.shape[0]
== billboard.shape[0]
)데이터프레임 하나하나 생성하지 말고 리스트로 한 번에 관리
list_billboard_df = []
for xlsx_filename in billboard_data_files:
df = pd.read_excel(xlsx_filename)
list_billboard_df.append(df)
print(len(list_billboard_df))
'''
76데이터프레임 리스트를 concat() 함수로 연결
billboard_loop_concat = pd.concat(list_billboard_df)
print(billboard_loop_concat.shape)
'''
(24092, 7)리스트 컴프리헨션으로 여러 개 파일 불러오기
from pathlib import Path
billboard_data_files = (
Path('.').glob('./billboard-*.xlsx')
)
billboard_dfs = [pd.read_xlsx(data) for data in billboard_data_files]여러 데이터셋 병합하기
데이터 불러와서 데이터프레임 생성
# 탐사일지 데이터프레임 생성
person = pd.read_excel('/content/survey_person.xlsx')
site = pd.read_excel('/content/survey_site.xlsx')
survey = pd.read_excel('/content/survey_survey.xlsx')
visited = pd.read_excel('/content/survey_visited.xlsx')merge()
<기준 데이터프레임>.merge(<합칠 데이터프레임>)
left join, right join, inner join, outer join 가능
# merge() 로 데이터 병합할 데이터프레임 생성
visited_subnet = visited.loc[[0, 2, 6], :]
print(visited_subnet)
'''
ident site dated
0 619 DR-1 1927-02-08
2 734 DR-3 1939-01-07
6 837 MSK-4 1932-01-14visited 데이터프레임의 site 열에 중복값이 없도록 일부 데이터만 떼어 실습에 사용
print(site)
'''
name lat long
0 DR-1 -49.85 -128.57
1 DR-3 -47.15 -126.72
2 MSK-4 -48.87 -123.40site 열에 있는 값의 개수를 살펴보면 중복이 없다는 점을 알 수 있음
print(visited_subnet["site"].value_counts())\
'''
site
DR-1 1
DR-3 1
MSK-4 1
Name: count, dtype: int64concat() 함수로 열 합치기
print(pd.concat([visited_subnet, site], axis=1))
'''
ident site dated name lat long
0 619.0 DR-1 1927-02-08 DR-1 -49.85 -128.57
2 734.0 DR-3 1939-01-07 MSK-4 -48.87 -123.40
6 837.0 MSK-4 1932-01-14 NaN NaN NaN
1 NaN NaN NaT DR-3 -47.15 -126.72일대일 병합하기 (merge())
# merge() 함수로 열 합치기
o2o_merge = site.merge(visited_subnet, left_on="name", right_on='site')
print(o2o_merge)
'''
name lat long ident site dated
0 DR-1 -49.85 -128.57 619 DR-1 1927-02-08
1 DR-3 -47.15 -126.72 734 DR-3 1939-01-07
2 MSK-4 -48.87 -123.40 837 MSK-4 1932-01-14merge() 메서드는 매개변수 how 의 기본값이 ‘inner’ 이므로 내부 조인을 실행하며 메서드를 호출한 데이터프레임 site 를 왼쪽으로, 인수로 전달한 visited_subnet 을 오른쪽으로 지정함
⇒ 즉, 왼쪽 데이터프레임 site 의 name 열(left_on=’name’)과 오른쪽 데이터프레임 visited_subnet 의 site 열 값(right_on='site')이 같으면 왼쪽 데이터프레임을 기준으로 연결함
다대일 병합하기(merge())
이번에는 visited 데이터프레임의 일부가 아닌 전체를 대상으로 병함
→ site 데이터프레임에 중복된 site 값이 있으므로 다대일 병합이 일어남
다대일 병합에서는 한쪽 데이터프레임의 키를 여러 번 사용
visited 의 site 열에 있는 중복값의 개수
print(visited["site"].value_counts())
'''
site
DR-3 4
DR-1 3
MSK-4 1
Name: count, dtype: int64다대다 병합
m2o_merge = site.merge(visited, left_on='name', right_on='site')
print(m2o_merge)
'''
name lat long ident site dated
0 DR-1 -49.85 -128.57 619 DR-1 1927-02-08
1 DR-1 -49.85 -128.57 622 DR-1 1927-02-10
2 DR-1 -49.85 -128.57 844 DR-1 1932-03-22
3 DR-3 -47.15 -126.72 734 DR-3 1939-01-07
4 DR-3 -47.15 -126.72 735 DR-3 1930-01-12
5 DR-3 -47.15 -126.72 751 DR-3 1930-02-26
6 DR-3 -47.15 -126.72 752 DR-3 NaT
7 MSK-4 -48.87 -123.40 837 MSK-4 1932-01-14병합 기준이 되는 name 열에 관측값이 하나씩만 있는 데이터프레임 site 는 site 열에 중복값이 있는 visited 데이터프레임과 병합될 때 값을 여러 번 반복함
기준이 되는 데이터프레임을 바꿔도 상관없음
m2o_merge = visited.merge(site, left_on='site', right_on='name')
print(m2o_merge)
'''
ident site dated name lat long
0 619 DR-1 1927-02-08 DR-1 -49.85 -128.57
1 622 DR-1 1927-02-10 DR-1 -49.85 -128.57
2 734 DR-3 1939-01-07 DR-3 -47.15 -126.72
3 735 DR-3 1930-01-12 DR-3 -47.15 -126.72
4 751 DR-3 1930-02-26 DR-3 -47.15 -126.72
5 752 DR-3 NaT DR-3 -47.15 -126.72
6 837 MSK-4 1932-01-14 MSK-4 -48.87 -123.40
7 844 DR-1 1932-03-22 DR-1 -49.85 -128.57역시 name 열이 반복됨
다대다 병합하기
책 참고(p.241)
데이터 정규화하기
표 분할하여 데이터 정규화하기
깔끔한 데이터 만들기
깔끔한 데이터란?
📌깔끔한 데이터란 R 커뮤니티의 해들리 위컴이 한 논문에서 처음 소개한 개념으로, 데이터셋을 구조화하는 프레임워크
이 프레임워크를 사용하면 데이터셋을 분석하고 시각화하기 쉬움
즉, 데이터를 정리하는 가장 이상적인 목표라고 볼 수 있음
깔끔한 데이터는 다음 조건을 만족해야 함
📌(1) 행은 관측값을 나타내야 한다
(2) 열은 변수를 나타내야 한다
(3) 관측 단위별로 데이터 표를 구성해야 한다
- 변수는 열로 나타내야 한다
- 관측값은 행으로 나타내야 한다
- 값은 셀로 나타내야 한다
열 이름이 값일 때
변수가 아닌 값 자체를 열 이름으로 표현할 때가 있다
데이터를 수집하고 구성하기 편리한 방식이기 때문
그러나 데이터를 쉽게 분석하고 시각화하려면 깔끔한 데이터로 만들어야 함
넓은 데이터 확인하기
# 데이터프레임을 입맛에 맞춰 바꾸기
pew = pd.read_excel('pew.xlsx')
print(pew)
'''
religion <$10k $10-20k $20-30k $30-40k $40-50k \
0 Agnostic 27 34 60 81 76
1 Atheist 12 27 37 52 35
2 Buddhist 27 21 30 34 33
3 Catholic 418 617 732 670 638
4 Don’t know/refused 15 14 15 11 10
5 Evangelical Prot 575 869 1064 982 881
6 Hindu 1 9 7 9 11
7 Historically Black Prot 228 244 236 238 197
8 Jehovah's Witness 20 27 24 24 21
9 Jewish 19 19 25 25 30
10 Mainline Prot 289 495 619 655 651
11 Mormon 29 40 48 51 56
12 Muslim 6 7 9 10 9
13 Orthodox 13 17 23 32 32
14 Other Christian 9 7 11 13 13
15 Other Faiths 20 33 40 46 49
16 Other World Religions 5 2 3 4 2
17 Unaffiliated 217 299 374 365 341
$50-75k $75-100k $100-150k >150k Don't know/refused
0 137 122 109 84 96
1 70 73 59 74 76
2 58 62 39 53 54
3 1116 949 792 633 1489
4 35 21 17 18 116
5 1486 949 723 414 1529
6 34 47 48 54 37
7 223 131 81 78 339
8 30 15 11 6 37
9 95 69 87 151 162
10 1107 939 753 634 1328
11 112 85 49 42 69
12 23 16 8 6 22
13 47 38 42 46 73
14 14 18 14 12 18
15 63 46 40 41 71
16 7 3 4 4 8
17 528 407 321 258 597 데이터셋을 살펴보면 일부 열 이름이 변수가 아닌 값을 나타낸다는 것을 알 수 있음
religion 을 제외한 모든 열은 소득 범위를 나타내고 각 소득 범위에 해당하는 사람 수를 값으로 설정
⇒ 즉, 소득이라는 변수 하나를 여러 범위로 나누어 여러 열로 분산한 것
표로 데이터를 나타낼 때는 아무런 문제가 없지만 데이터를 분석할 때는 종교(relgion), 소득(income), 사람 수(count)를 변수로 설정하고 각 변수가 각 열에 나타나도록 데이터를 수정하는 것이 좋음
📌변수 하나를 여러 개의 열로 표현한 데이터
→ 넓은 데이터
위와 같은 데이터를 한 열로 표현한 긴 데이터
→ 긴 데이터
넓은 데이터를 긴 데이터로 바꾸기 위해선 피벗 되돌리기가 필요함
이 작업은 melt 또는 gather 라고 표현하기도 함
긴 데이터로 만들기
pew_long = pew.melt(id_vars = 'religion')
print(pew_long)
''' religion variable value
0 Agnostic <$10k 27
1 Atheist <$10k 12
2 Buddhist <$10k 27
3 Catholic <$10k 418
4 Don’t know/refused <$10k 15
.. ... ... ...
175 Orthodox Don't know/refused 73
176 Other Christian Don't know/refused 18
177 Other Faiths Don't know/refused 71
178 Other World Religions Don't know/refused 8
179 Unaffiliated Don't know/refused 597
[180 rows x 3 columns]- religion 열은 살려두고 나머지 열을 교체
- 기존 열이었던 수입 구간은 variable 열 내부의 값으로 들어감
- 기존에 담겨있던 값들은 value 열 내부에 재배치됨
⇒ 행의 개수가 늘어남(긴 데이터)
열 이름 지정
pew_long = pew.melt(id_vars = 'religion', var_name = 'income', value_name = 'count')
print(pew_long)
'''
religion income count
0 Agnostic <$10k 27
1 Atheist <$10k 12
2 Buddhist <$10k 27
3 Catholic <$10k 418
4 Don’t know/refused <$10k 15
.. ... ... ...
175 Orthodox Don't know/refused 73
176 Other Christian Don't know/refused 18
177 Other Faiths Don't know/refused 71
178 Other World Religions Don't know/refused 8
179 Unaffiliated Don't know/refused 597
[180 rows x 3 columns]- variable 기본값 -> income
- value 기본값 -> count
apply() 메서드로 함수 적용하기
간단한 함수 만들기
apply()
: 특정 열 or 특정 행에 함수를 적용한 연산 수행
apply() 메서드 사용하기
# apply() 함수
df = pd.DataFrame({
"a": [10, 20 ,30],
"b": [20, 30 ,40]
})
print(df)
'''
a b
0 10 20
1 20 30
2 30 40결측값 알아보기
결측값이란?
: NaN
결측값은 왜 생길까?
visited = pd.read_excel('survey_visited.xlsx')
print(visited)
print(type(visited.loc[5]['dated']))
'''
ident site dated
0 619 DR-1 1927-02-08
1 622 DR-1 1927-02-10
2 734 DR-3 1939-01-07
3 735 DR-3 1930-01-12
4 751 DR-3 1930-02-26
5 752 DR-3 NaT
6 837 MSK-4 1932-01-14
7 844 DR-1 1932-03-22
<class 'pandas._libs.tslibs.nattype.NaTType'>NaT(NaN) 결측값 존재
결측값이 안보이도록 처리 keep_default_na=False
visited = pd.read_excel('survey_visited.xlsx', keep_default_na=False)
print(visited)
'''
ident site dated
0 619 DR-1 1927-02-08 00:00:00
1 622 DR-1 1927-02-10 00:00:00
2 734 DR-3 1939-01-07 00:00:00
3 735 DR-3 1930-01-12 00:00:00
4 751 DR-3 1930-02-26 00:00:00
5 752 DR-3
6 837 MSK-4 1932-01-14 00:00:00
7 844 DR-1 1932-03-22 00:00:00
<class 'str'>결측값을 빈 문자열로 처리
빈 곳을 결측값으로 처리
visited = pd.read_excel('survey_visited.xlsx', na_values=[""], keep_default_na=False)
print(visited)
print(type(visited.loc[5]['dated']))
'''
ident site dated
0 619 DR-1 1927-02-08
1 622 DR-1 1927-02-10
2 734 DR-3 1939-01-07
3 735 DR-3 1930-01-12
4 751 DR-3 1930-02-26
5 752 DR-3 NaT
6 837 MSK-4 1932-01-14
7 844 DR-1 1932-03-22
<class 'pandas._libs.tslibs.nattype.NaTType'>다시 결측값으로 처리됨
데이터를 연결할 때 생기는 결측값
visited = pd.read_excel('survey_visited.xlsx')
survey = pd.read_excel('survey_survey.xlsx')
print(visited)
print(survey)
'''
ident site dated
0 619 DR-1 1927-02-08
1 622 DR-1 1927-02-10
2 734 DR-3 1939-01-07
3 735 DR-3 1930-01-12
4 751 DR-3 1930-02-26
5 752 DR-3 NaT
6 837 MSK-4 1932-01-14
7 844 DR-1 1932-03-22
taken person quant reading
0 619 dyer rad 9.82
1 619 dyer sal 0.13
2 622 dyer rad 7.80
3 622 dyer sal 0.09
4 734 pb rad 8.41
5 734 lake sal 0.05
6 734 pb temp -21.50
7 735 pb rad 7.22
8 735 NaN sal 0.06
9 735 NaN temp -26.00
10 751 pb rad 4.35
11 751 pb temp -18.50
12 751 lake sal 0.10
13 752 lake rad 2.19
14 752 lake sal 0.09
15 752 lake temp -16.00
16 752 roe sal 41.60
17 837 lake rad 1.46
18 837 lake sal 0.21
19 837 roe sal 22.50
20 844 roe rad 11.25merge() 로 연결
vs = visited.merge(survey, left_on='ident', right_on='taken')
print(vs)
'''
ident site dated taken person quant reading
0 619 DR-1 1927-02-08 619 dyer rad 9.82
1 619 DR-1 1927-02-08 619 dyer sal 0.13
2 622 DR-1 1927-02-10 622 dyer rad 7.80
3 622 DR-1 1927-02-10 622 dyer sal 0.09
4 734 DR-3 1939-01-07 734 pb rad 8.41
5 734 DR-3 1939-01-07 734 lake sal 0.05
6 734 DR-3 1939-01-07 734 pb temp -21.50
7 735 DR-3 1930-01-12 735 pb rad 7.22
8 735 DR-3 1930-01-12 735 NaN sal 0.06
9 735 DR-3 1930-01-12 735 NaN temp -26.00
10 751 DR-3 1930-02-26 751 pb rad 4.35
11 751 DR-3 1930-02-26 751 pb temp -18.50
12 751 DR-3 1930-02-26 751 lake sal 0.10
13 752 DR-3 NaT 752 lake rad 2.19
14 752 DR-3 NaT 752 lake sal 0.09
15 752 DR-3 NaT 752 lake temp -16.00
16 752 DR-3 NaT 752 roe sal 41.60
17 837 MSK-4 1932-01-14 837 lake rad 1.46
18 837 MSK-4 1932-01-14 837 lake sal 0.21
19 837 MSK-4 1932-01-14 837 roe sal 22.50
20 844 DR-1 1932-03-22 844 roe rad 11.25set_index() vs. reset_index()
set_index()
: 열을 특정하여 행으로 지정하는 방법
vs2 = vs[:]
vs2.set_index('site', inplace=True)
print(vs2)
'''
ident dated taken person quant reading
site
DR-1 619 1927-02-08 619 dyer rad 9.82
DR-1 619 1927-02-08 619 dyer sal 0.13
DR-1 622 1927-02-10 622 dyer rad 7.80
DR-1 622 1927-02-10 622 dyer sal 0.09
DR-3 734 1939-01-07 734 pb rad 8.41
DR-3 734 1939-01-07 734 lake sal 0.05
DR-3 734 1939-01-07 734 pb temp -21.50
DR-3 735 1930-01-12 735 pb rad 7.22
DR-3 735 1930-01-12 735 NaN sal 0.06
DR-3 735 1930-01-12 735 NaN temp -26.00
DR-3 751 1930-02-26 751 pb rad 4.35
DR-3 751 1930-02-26 751 pb temp -18.50
DR-3 751 1930-02-26 751 lake sal 0.10
DR-3 752 NaT 752 lake rad 2.19
DR-3 752 NaT 752 lake sal 0.09
DR-3 752 NaT 752 lake temp -16.00
DR-3 752 NaT 752 roe sal 41.60
MSK-4 837 1932-01-14 837 lake rad 1.46
MSK-4 837 1932-01-14 837 lake sal 0.21
MSK-4 837 1932-01-14 837 roe sal 22.50
DR-1 844 1932-03-22 844 roe rad 11.25
reset_index()
: set_index() 로 설정한 거 초기화
vs3 = vs2[:]
vs3.reset_index()
print(vs3)
'''
ident dated taken person quant reading
site
DR-1 619 1927-02-08 619 dyer rad 9.82
DR-1 619 1927-02-08 619 dyer sal 0.13
DR-1 622 1927-02-10 622 dyer rad 7.80
DR-1 622 1927-02-10 622 dyer sal 0.09
DR-3 734 1939-01-07 734 pb rad 8.41
DR-3 734 1939-01-07 734 lake sal 0.05
DR-3 734 1939-01-07 734 pb temp -21.50
DR-3 735 1930-01-12 735 pb rad 7.22
DR-3 735 1930-01-12 735 NaN sal 0.06
DR-3 735 1930-01-12 735 NaN temp -26.00
DR-3 751 1930-02-26 751 pb rad 4.35
DR-3 751 1930-02-26 751 pb temp -18.50
DR-3 751 1930-02-26 751 lake sal 0.10
DR-3 752 NaT 752 lake rad 2.19
DR-3 752 NaT 752 lake sal 0.09
DR-3 752 NaT 752 lake temp -16.00
DR-3 752 NaT 752 roe sal 41.60
MSK-4 837 1932-01-14 837 lake rad 1.46
MSK-4 837 1932-01-14 837 lake sal 0.21
MSK-4 837 1932-01-14 837 roe sal 22.50
DR-1 844 1932-03-22 844 roe rad 11.25set_index() 중복 설정
vs4 = vs[:]
vs4.set_index('site', inplace=True)
print(vs4)
vs4.set_index('person', inplace=True)
print(vs4)
'''
ident dated taken person quant reading
site
DR-1 619 1927-02-08 619 dyer rad 9.82
DR-1 619 1927-02-08 619 dyer sal 0.13
DR-1 622 1927-02-10 622 dyer rad 7.80
DR-1 622 1927-02-10 622 dyer sal 0.09
DR-3 734 1939-01-07 734 pb rad 8.41
DR-3 734 1939-01-07 734 lake sal 0.05
DR-3 734 1939-01-07 734 pb temp -21.50
DR-3 735 1930-01-12 735 pb rad 7.22
DR-3 735 1930-01-12 735 NaN sal 0.06
DR-3 735 1930-01-12 735 NaN temp -26.00
DR-3 751 1930-02-26 751 pb rad 4.35
DR-3 751 1930-02-26 751 pb temp -18.50
DR-3 751 1930-02-26 751 lake sal 0.10
DR-3 752 NaT 752 lake rad 2.19
DR-3 752 NaT 752 lake sal 0.09
DR-3 752 NaT 752 lake temp -16.00
DR-3 752 NaT 752 roe sal 41.60
MSK-4 837 1932-01-14 837 lake rad 1.46
MSK-4 837 1932-01-14 837 lake sal 0.21
MSK-4 837 1932-01-14 837 roe sal 22.50
DR-1 844 1932-03-22 844 roe rad 11.25
ident dated taken quant reading
person
dyer 619 1927-02-08 619 rad 9.82
dyer 619 1927-02-08 619 sal 0.13
dyer 622 1927-02-10 622 rad 7.80
dyer 622 1927-02-10 622 sal 0.09
pb 734 1939-01-07 734 rad 8.41
lake 734 1939-01-07 734 sal 0.05
pb 734 1939-01-07 734 temp -21.50
pb 735 1930-01-12 735 rad 7.22
NaN 735 1930-01-12 735 sal 0.06
NaN 735 1930-01-12 735 temp -26.00
pb 751 1930-02-26 751 rad 4.35
pb 751 1930-02-26 751 temp -18.50
lake 751 1930-02-26 751 sal 0.10
lake 752 NaT 752 rad 2.19
lake 752 NaT 752 sal 0.09
lake 752 NaT 752 temp -16.00
roe 752 NaT 752 sal 41.60
lake 837 1932-01-14 837 rad 1.46
lake 837 1932-01-14 837 sal 0.21
roe 837 1932-01-14 837 sal 22.50
roe 844 1932-03-22 844 rad 11.25set_index() 두 번 설정하면 첫번째로 설정했던 행은 사라짐
위를 reset_index() 로 돌린다면?
vs5 = vs4[:]
vs5.reset_index()
print(vs5)
'''
ident dated taken quant reading
person
dyer 619 1927-02-08 619 rad 9.82
dyer 619 1927-02-08 619 sal 0.13
dyer 622 1927-02-10 622 rad 7.80
dyer 622 1927-02-10 622 sal 0.09
pb 734 1939-01-07 734 rad 8.41
lake 734 1939-01-07 734 sal 0.05
pb 734 1939-01-07 734 temp -21.50
pb 735 1930-01-12 735 rad 7.22
NaN 735 1930-01-12 735 sal 0.06
NaN 735 1930-01-12 735 temp -26.00
pb 751 1930-02-26 751 rad 4.35
pb 751 1930-02-26 751 temp -18.50
lake 751 1930-02-26 751 sal 0.10
lake 752 NaT 752 rad 2.19
lake 752 NaT 752 sal 0.09
lake 752 NaT 752 temp -16.00
roe 752 NaT 752 sal 41.60
lake 837 1932-01-14 837 rad 1.46
lake 837 1932-01-14 837 sal 0.21
roe 837 1932-01-14 837 sal 22.50
roe 844 1932-03-22 844 rad 11.25이전 데이터로 다시 돌아가지 않음
결측값 다루기
결측값 처리하기
📌- 결측값을 다른 값으로 바꾸기
- 결측값을 기존 데이터로 채우기
- 결측값을 아예 삭제하기
결측값 개수 구하기
NaN 이 아닌 값의 개수 확인
# 결측값 개수 확인
ebola = pd.read_excel('country_timeseries.xlsx')
print(ebola.count())
'''
Date 122
Day 122
Cases_Guinea 93
Cases_Liberia 83
Cases_SierraLeone 87
Cases_Nigeria 38
Cases_Senegal 25
Cases_UnitedStates 18
Cases_Spain 16
Cases_Mali 12
Deaths_Guinea 92
Deaths_Liberia 81
Deaths_SierraLeone 87
Deaths_Nigeria 38
Deaths_Senegal 22
Deaths_UnitedStates 18
Deaths_Spain 16
Deaths_Mali 12
dtype: int64전체 행 개수에서 이 count 값을 빼면 열별 결측값 개수를 구할 수 있음
shpae 의 첫번째 값이 행 개수이므로 shape[0] 에서 count() 를 뺌
num_rows = ebola.shape[0]
num_missing = num_rows - ebola.count()
print(num_missing)
'''
Date 0
Day 0
Cases_Guinea 29
Cases_Liberia 39
Cases_SierraLeone 35
Cases_Nigeria 84
Cases_Senegal 97
Cases_UnitedStates 104
Cases_Spain 106
Cases_Mali 110
Deaths_Guinea 30
Deaths_Liberia 41
Deaths_SierraLeone 35
Deaths_Nigeria 84
Deaths_Senegal 100
Deaths_UnitedStates 104
Deaths_Spain 106
Deaths_Mali 110
dtype: int64isnull() count_nonzero()
import numpy as np
print(np.count_nonzero(ebola.isnull()))
'''
1214print(np.count_nonzero(ebola['Cases_Guinea'].isnull()))
'''
29isnull() 은 boolean 값 반환
# isnull() vs notnull()
print(ebola.isnull())
print(ebola.notnull())
'''
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone \
0 False False False True False
1 False False False True False
2 False False False False False
3 False False True False True
4 False False False False False
.. ... ... ... ... ...
117 False False False False False
118 False False False True True
119 False False False True True
120 False False False True True
121 False False False True True
Cases_Nigeria Cases_Senegal Cases_UnitedStates Cases_Spain \
0 True True True True
1 True True True True
2 True True True True
3 True True True True
4 True True True True
.. ... ... ... ...
117 True True True True
118 True True True True
119 True True True True
120 True True True True
121 True True True True
Cases_Mali Deaths_Guinea Deaths_Liberia Deaths_SierraLeone \
0 True False True False
1 True False True False
2 True False False False
3 True True False True
4 True False False False
.. ... ... ... ...
117 True False False False
118 True False True True
119 True False True True
120 True False True True
121 True False True True
Deaths_Nigeria Deaths_Senegal Deaths_UnitedStates Deaths_Spain \
0 True True True True
1 True True True True
2 True True True True
3 True True True True
4 True True True True
.. ... ... ... ...
117 True True True True
118 True True True True
119 True True True True
120 True True True True
121 True True True True
Deaths_Mali
0 True
1 True
2 True
3 True
4 True
.. ...
117 True
118 True
119 True
120 True
121 True
[122 rows x 18 columns]
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone \
0 True True True False True
1 True True True False True
2 True True True True True
3 True True False True False
4 True True True True True
.. ... ... ... ... ...
117 True True True True True
118 True True True False False
119 True True True False False
120 True True True False False
121 True True True False False
Cases_Nigeria Cases_Senegal Cases_UnitedStates Cases_Spain \
0 False False False False
1 False False False False
2 False False False False
3 False False False False
4 False False False False
.. ... ... ... ...
117 False False False False
118 False False False False
119 False False False False
120 False False False False
121 False False False False
Cases_Mali Deaths_Guinea Deaths_Liberia Deaths_SierraLeone \
0 False True False True
1 False True False True
2 False True True True
3 False False True False
4 False True True True
.. ... ... ... ...
117 False True True True
118 False True False False
119 False True False False
120 False True False False
121 False True False False
Deaths_Nigeria Deaths_Senegal Deaths_UnitedStates Deaths_Spain \
0 False False False False
1 False False False False
2 False False False False
3 False False False False
4 False False False False
.. ... ... ... ...
117 False False False False
118 False False False False
119 False False False False
120 False False False False
121 False False False False
Deaths_Mali
0 False
1 False
2 False
3 False
4 False
.. ...
117 False
118 False
119 False
120 False
121 False
[122 rows x 18 columns]value_counts()
# 특정 열 값의 종류 확인
cnts = ebola['Cases_Guinea'].value_counts()
print(cnts)
'''
Cases_Guinea
86.0 3
112.0 2
495.0 2
390.0 2
2776.0 1
..
143.0 1
122.0 1
127.0 1
103.0 1
49.0 1
Name: count, Length: 88, dtype: int64특정 열의 각 값의 빈도수를 반환함
dropna=False 설정시 결측값의 개수도 확인 가능
cnts = ebola['Cases_Guinea'].value_counts(dropna=False)
print(cnts)
'''
Cases_Guinea
NaN 29
86.0 3
112.0 2
495.0 2
390.0 2
..
143.0 1
122.0 1
127.0 1
103.0 1
49.0 1
Name: count, Length: 89, dtype: int64결측값 대체하기 fillna()
결측값을 0으로 대체
print(ebola.fillna(0).iloc[:, 0:5])
'''
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone
0 2015-05-01 00:00:00 289 2776.0 0.0 10030.0
1 2015-04-01 00:00:00 288 2775.0 0.0 9780.0
2 2015-03-01 00:00:00 287 2769.0 8166.0 9722.0
3 2015-02-01 00:00:00 286 0.0 8157.0 0.0
4 12/31/2014 284 2730.0 8115.0 9633.0
.. ... ... ... ... ...
117 3/27/2014 5 103.0 8.0 6.0
118 3/26/2014 4 86.0 0.0 0.0
119 3/25/2014 3 86.0 0.0 0.0
120 3/24/2014 2 86.0 0.0 0.0
121 3/22/2014 0 49.0 0.0 0.0
[122 rows x 5 columns]정방향 채우기
: 데이터를 위에서 아래로 훑으면서 결측값 직전에 찾은 값(마지막으로 찾은 NaN 이 아닌 값)으로 결측값을 대체하는 방식
fillna()메서드의 매개변수method에‘ffill’을 전달하여 정방향 채우기를 적용
print(ebola.fillna(method='ffill').iloc[:, 0:5])
'''
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone
0 2015-05-01 00:00:00 289 2776.0 NaN 10030.0
1 2015-04-01 00:00:00 288 2775.0 NaN 9780.0
2 2015-03-01 00:00:00 287 2769.0 8166.0 9722.0
3 2015-02-01 00:00:00 286 2769.0 8157.0 9722.0
4 12/31/2014 284 2730.0 8115.0 9633.0
.. ... ... ... ... ...
117 3/27/2014 5 103.0 8.0 6.0
118 3/26/2014 4 86.0 8.0 6.0
119 3/25/2014 3 86.0 8.0 6.0
120 3/24/2014 2 86.0 8.0 6.0
121 3/22/2014 0 49.0 8.0 6.0
[122 rows x 5 columns]
/tmp/ipython-input-2061892795.py:1: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
print(ebola.fillna(method='ffill').iloc[:, 0:5])맨 위가 NaN 값인 건 어쩔 수 없음
역방향 채우기
: 데이터를 아래에서 위로 훑으면서 결측값 직전에 찾은 값(마지막으로 찾은 NaN 이 아닌 값)으로 결측값을 대체하는 방식
fillna()메서드의 매개변수method에‘bfill’을 전달하여 역방향 채우기를 적용
print(ebola.fillna(method='bfill').iloc[:, 0:5])
'''
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone
0 2015-05-01 00:00:00 289 2776.0 8166.0 10030.0
1 2015-04-01 00:00:00 288 2775.0 8166.0 9780.0
2 2015-03-01 00:00:00 287 2769.0 8166.0 9722.0
3 2015-02-01 00:00:00 286 2730.0 8157.0 9633.0
4 12/31/2014 284 2730.0 8115.0 9633.0
.. ... ... ... ... ...
117 3/27/2014 5 103.0 8.0 6.0
118 3/26/2014 4 86.0 NaN NaN
119 3/25/2014 3 86.0 NaN NaN
120 3/24/2014 2 86.0 NaN NaN
121 3/22/2014 0 49.0 NaN NaN
[122 rows x 5 columns]
/tmp/ipython-input-3966631446.py:1: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
print(ebola.fillna(method='bfill').iloc[:, 0:5])맨 아래가 NaN 값인 건 어쩔 수 없음
보간법으로 채우기 interpolate()
보간법으로 결측값을 채울 때는 기존 값을 사용함
채우는 방법에는 여러가지가 있으며 판다스에서는 기본적으로 결측값 양쪽 값의 중간값으로 채움
이렇게 하면 데이터가 일정한 차이를 보이는 것처럼 처리 가능
print(ebola.interpolate().iloc[:, 0:5])
'''
Date Day Cases_Guinea Cases_Liberia Cases_SierraLeone
0 2015-05-01 00:00:00 289 2776.0 NaN 10030.0
1 2015-04-01 00:00:00 288 2775.0 NaN 9780.0
2 2015-03-01 00:00:00 287 2769.0 8166.0 9722.0
3 2015-02-01 00:00:00 286 2749.5 8157.0 9677.5
4 12/31/2014 284 2730.0 8115.0 9633.0
.. ... ... ... ... ...
117 3/27/2014 5 103.0 8.0 6.0
118 3/26/2014 4 86.0 8.0 6.0
119 3/25/2014 3 86.0 8.0 6.0
120 3/24/2014 2 86.0 8.0 6.0
121 3/22/2014 0 49.0 8.0 6.0
[122 rows x 5 columns]
/tmp/ipython-input-3754662095.py:1: FutureWarning: DataFrame.interpolate with object dtype is deprecated and will raise in a future version. Call obj.infer_objects(copy=False) before interpolating instead.
print(ebola.interpolate().iloc[:, 0:5])결측값 삭제하기
필요없다면 결측값은 삭제해도 됨
하지만 무작정 삭제하면 데이터가 너무 편향되거나 개수가 너무 적어질 수도 있음
그러므로 삭제할 때는 사람이 잘 판단해야 함
dropna() 메서드를 사용하면 결측값을 삭제할 수 있음
몇 가지 매개변수를 사용하여 삭제 방법을 변경할 수 있음
print(ebola.shape)
'''
(122, 18)dropna() 메서드를 사용하여 결측값이 하나도 없는 행만 남기도록 함
ebola_dropna = ebola.dropna()
print(ebola_dropna.shape)
'''
(1, 18)데이터가 딱 한 행만 남음
→ 행 대부분에 결측값이 있음을 알 수 있음
dropna() 메서드를 사용하여 결측값이 하나도 없는 열만 남기도록 함
ebola_dropna = ebola.dropna(axis=1)
print(ebola_dropna.shape)
'''
(122, 2)| 파라미터 | 기본값 | 설명 | 자주 쓰는 값 |
|---|---|---|---|
axis | 0 | 결측치를 기준으로 삭제할 방향 지정 | 0 (행 삭제), 1 (열 삭제) |
how | 'any' | 결측치가 있을 때 삭제 조건 지정 | 'any' (하나라도 NaN이면 삭제), 'all' (전부 NaN일 때만 삭제) |
thresh | None | 최소 유지할 값 개수 지정 | 정수값 (예: thresh=3) |
subset | None | 결측치 검사할 컬럼 범위 지정 | 리스트 형태 (['col1', 'col2']) |
inplace | False | 원본 데이터 수정 여부 | True / False |
how : 특정값에 충족하는 데이터를 지울 수 있도록 만들어주는 매개변수
df = pd.DataFrame({
'A': [1, 2, None],
'B': [4, None, None],
'C': [7, 8, 9]}
)
print(df)
'''
A B C
0 1.0 4.0 7
1 2.0 NaN 8
2 NaN NaN 9how=’any’ 가 기본값
print(df.dropna())
'''
A B C
0 1.0 4.0 7print(df.dropna(how='any'))
'''
A B C
0 1.0 4.0 7동일한 결과가 나오는 것을 확인 가능
데이터를 받았는데 전체 열의 값에 NaN 이 있다면 삭제
any → all
print(df.dropna(how='all'))
'''
A B C
0 1.0 4.0 7
1 2.0 NaN 8
2 NaN NaN 9thresh : NaN 개수가 특정 이상일 경우 판단해서 제거할 때 사용
print(ebola.info())
ebola_thresh = ebola.dropna(axis = 1, thresh = 22)
print(ebola_thresh.info())
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 122 entries, 0 to 121
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 122 non-null object
1 Day 122 non-null int64
2 Cases_Guinea 93 non-null float64
3 Cases_Liberia 83 non-null float64
4 Cases_SierraLeone 87 non-null float64
5 Cases_Nigeria 38 non-null float64
6 Cases_Senegal 25 non-null float64
7 Cases_UnitedStates 18 non-null float64
8 Cases_Spain 16 non-null float64
9 Cases_Mali 12 non-null float64
10 Deaths_Guinea 92 non-null float64
11 Deaths_Liberia 81 non-null float64
12 Deaths_SierraLeone 87 non-null float64
13 Deaths_Nigeria 38 non-null float64
14 Deaths_Senegal 22 non-null float64
15 Deaths_UnitedStates 18 non-null float64
16 Deaths_Spain 16 non-null float64
17 Deaths_Mali 12 non-null float64
dtypes: float64(16), int64(1), object(1)
memory usage: 17.3+ KB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 122 entries, 0 to 121
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 122 non-null object
1 Day 122 non-null int64
2 Cases_Guinea 93 non-null float64
3 Cases_Liberia 83 non-null float64
4 Cases_SierraLeone 87 non-null float64
5 Cases_Nigeria 38 non-null float64
6 Cases_Senegal 25 non-null float64
7 Deaths_Guinea 92 non-null float64
8 Deaths_Liberia 81 non-null float64
9 Deaths_SierraLeone 87 non-null float64
10 Deaths_Nigeria 38 non-null float64
11 Deaths_Senegal 22 non-null float64
dtypes: float64(10), int64(1), object(1)
memory usage: 11.6+ KB
NoneNaN을 0으로 합산 연산
print(ebola['Cases_Guinea'].sum(skipna=True))
'''
84729.0- 모든
NaN값을 0으로 변환 -> 합산 NaN을skip(0)해주는 방식
중복데이터 처리
데이터프레임 생성
df = pd.DataFrame({
'c1': ['a', 'a', 'b', 'a', 'b'],
'c2': [1, 1, 1, 2, 2],
'c3': [1, 1, 2, 2, 2]
})
print(df)
'''
c1 c2 c3
0 a 1 1
1 a 1 1
2 b 1 2
3 a 2 2
4 b 2 2duplicated() : 중복값을 판단
print(df.duplicated())
'''
0 False
1 True
2 False
3 False
4 False
dtype: bool특정 열의 중복값 판단
print(df['c2'].duplicated())
'''
0 False
1 True
2 True
3 False
4 True
Name: c2, dtype: boolc2 열에서 1 값이 처음 나온 0번 행에선 False, 1 값이 다시 나온 1, 2번 행에서는 True, 2 값이 처음 나온 3번 행에서는 False, 2 값이 다시 나온 4번 행에서는 True
drop_duplicates() : 중복값을 제거
print(df.drop_duplicates())
'''
c1 c2 c3
0 a 1 1
2 b 1 2
3 a 2 2
4 b 2 2중복된 행 하나씩만 남기고 나머지는 제거됨
drop_duplicates(subset=[’’]) : 특정 열에서 중복값 있으면 해당 행 제거
print(df.drop_duplicates(subset=['c2']))
'''
c1 c2 c3
0 a 1 1
3 a 2 2자료형 더 알아보기
자료형 살펴보기
라이브러리 임포트
import pandas as pd
import seaborn as snstips 데이터셋 불러와서 자료형 확인
tips = sns.load_dataset('tips')
print(tips.dtypes)
'''
total_bill float64
tip float64
sex category
smoker category
day category
time category
size int64
dtype: objectobject: 문자열
category: 범주형 변수
datetime: 시계열 데이터
자료형 변환하기
타입 변경하여 열 추가
tips['sex_str'] = tips['sex'].astype('str')
print(tips.columns)
print(tips.dtypes)
'''
Index(['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size', 'sex_str'], dtype='object')
total_bill float64
tip float64
sex category
smoker category
day category
time category
size int64
sex_str object
dtype: object열 타입 변경
tips['total_bill'] = tips['total_bill'].astype('str')
print(tips.dtypes)
'''
total_bill object
tip float64
sex category
smoker category
day category
time category
size int64
sex_str object
dtype: objecttips['total_bill'] = tips['total_bill'].astype('float')
print(tips.dtypes)
'''
total_bill float64
tip float64
sex category
smoker category
day category
time category
size int64
sex_str object
dtype: objectto_numeric(): 수치형 데이터로 변환
tips_sub_miss = tips.head(10)[:]
print(tips_sub_miss)
'''
total_bill tip sex smoker day time size sex_str
0 16.99 1.01 Female No Sun Dinner 2 Female
1 10.34 1.66 Male No Sun Dinner 3 Male
2 21.01 3.50 Male No Sun Dinner 3 Male
3 23.68 3.31 Male No Sun Dinner 2 Male
4 24.59 3.61 Female No Sun Dinner 4 Female
5 25.29 4.71 Male No Sun Dinner 4 Male
6 8.77 2.00 Male No Sun Dinner 2 Male
7 26.88 3.12 Male No Sun Dinner 4 Male
8 15.04 1.96 Male No Sun Dinner 2 Male
9 14.78 3.23 Male No Sun Dinner 2 Maletips_sub_miss.loc[[1, 3, 5, 7], 'total_bill'] = 'missing'
print(tips_sub_miss)
'''
total_bill tip sex smoker day time size sex_str
0 16.99 1.01 Female No Sun Dinner 2 Female
1 missing 1.66 Male No Sun Dinner 3 Male
2 21.01 3.50 Male No Sun Dinner 3 Male
3 missing 3.31 Male No Sun Dinner 2 Male
4 24.59 3.61 Female No Sun Dinner 4 Female
5 missing 4.71 Male No Sun Dinner 4 Male
6 8.77 2.00 Male No Sun Dinner 2 Male
7 missing 3.12 Male No Sun Dinner 4 Male
8 15.04 1.96 Male No Sun Dinner 2 Male
9 14.78 3.23 Male No Sun Dinner 2 Maleastype() 메서드로 유형을 변경
tips_sub_miss['total_bill'] = tips_sub_miss['total_bill'].astype('float')
'''
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipython-input-1525283664.py in <cell line: 0>()
----> 1 tips_sub_miss['total_bill'] = tips_sub_miss['total_bill'].astype('float')
6 frames
/usr/local/lib/python3.12/dist-packages/pandas/core/dtypes/astype.py in _astype_nansafe(arr, dtype, copy, skipna)
131 if copy or arr.dtype == object or dtype == object:
132 # Explicit copy, or required since NumPy can't view from / to object.
--> 133 return arr.astype(dtype, copy=True)
134
135 return arr.astype(dtype, copy=copy)
ValueError: could not convert string to float: 'missing'
문자열이 있으므로 float 로 형 변환할 때 에러 발생
tips_sub_miss['total_bill'] = pd.to_numeric(tips_sub_miss['total_bill'])
'''
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
lib.pyx in pandas._libs.lib.maybe_convert_numeric()
ValueError: Unable to parse string "missing"
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
/tmp/ipython-input-2795684258.py in <cell line: 0>()
----> 1 tips_sub_miss['total_bill'] = pd.to_numeric(tips_sub_miss['total_bill'])
/usr/local/lib/python3.12/dist-packages/pandas/core/tools/numeric.py in to_numeric(arg, errors, downcast, dtype_backend)
230 coerce_numeric = errors not in ("ignore", "raise")
231 try:
--> 232 values, new_mask = lib.maybe_convert_numeric( # type: ignore[call-overload]
233 values,
234 set(),
lib.pyx in pandas._libs.lib.maybe_convert_numeric()
ValueError: Unable to parse string "missing" at position 1
역시 에러 발생
에러 무시 옵션 추가
tips_sub_miss['total_bill'] = pd.to_numeric(tips_sub_miss['total_bill'], errors='ignore')
print(tips_sub_miss['total_bill'].dtypes)
'''
object에러는 발생하지 않지만 의미가 없음
여전히 object (str, 문자열) 자료형인 걸 확인 가능
errors='coerce’
tips_sub_miss['total_bill'] = pd.to_numeric(tips_sub_miss['total_bill'], errors='coerce')
print(tips_sub_miss)
print(tips_sub_miss['total_bill'].dtypes)
'''
total_bill tip sex smoker day time size sex_str
0 16.99 1.01 Female No Sun Dinner 2 Female
1 NaN 1.66 Male No Sun Dinner 3 Male
2 21.01 3.50 Male No Sun Dinner 3 Male
3 NaN 3.31 Male No Sun Dinner 2 Male
4 24.59 3.61 Female No Sun Dinner 4 Female
5 NaN 4.71 Male No Sun Dinner 4 Male
6 8.77 2.00 Male No Sun Dinner 2 Male
7 NaN 3.12 Male No Sun Dinner 4 Male
8 15.04 1.96 Male No Sun Dinner 2 Male
9 14.78 3.23 Male No Sun Dinner 2 Male
float64‘missing’ 문자열이 모두 NaN 으로 대체되고 total_bill 의 자료형이 float64로 바뀜
범주형 데이터 알아보기
autompg 파일을 데이터프레임으로 만들기
df = pd.read_excel('auto-mpg.xlsx')
print(df)
'''
18 8 307 130 3504 12 70 1 chevrolet chevelle malibu
0 15.0 8 350.0 165 3693 11.5 70 1 buick skylark 320
1 18.0 8 318.0 150 3436 11.0 70 1 plymouth satellite
2 16.0 8 304.0 150 3433 12.0 70 1 amc rebel sst
3 17.0 8 302.0 140 3449 10.5 70 1 ford torino
4 15.0 8 429.0 198 4341 10.0 70 1 ford galaxie 500
.. ... .. ... ... ... ... .. .. ...
392 27.0 4 140.0 86 2790 15.6 82 1 ford mustang gl
393 44.0 4 97.0 52 2130 24.6 82 2 vw pickup
394 32.0 4 135.0 84 2295 11.6 82 1 dodge rampage
395 28.0 4 120.0 79 2625 18.6 82 1 ford ranger
396 31.0 4 119.0 82 2720 19.4 82 1 chevy s-10
[397 rows x 9 columns]header=None 으로 지정해서 데이터프레임 다시 생성
df = pd.read_excel('auto-mpg.xlsx', header=None)
print(df)
'''
0 1 2 3 4 5 6 7 8
0 18.0 8 307.0 130 3504 12.0 70 1 chevrolet chevelle malibu
1 15.0 8 350.0 165 3693 11.5 70 1 buick skylark 320
2 18.0 8 318.0 150 3436 11.0 70 1 plymouth satellite
3 16.0 8 304.0 150 3433 12.0 70 1 amc rebel sst
4 17.0 8 302.0 140 3449 10.5 70 1 ford torino
.. ... .. ... ... ... ... .. .. ...
393 27.0 4 140.0 86 2790 15.6 82 1 ford mustang gl
394 44.0 4 97.0 52 2130 24.6 82 2 vw pickup
395 32.0 4 135.0 84 2295 11.6 82 1 dodge rampage
396 28.0 4 120.0 79 2625 18.6 82 1 ford ranger
397 31.0 4 119.0 82 2720 19.4 82 1 chevy s-10
[398 rows x 9 columns]열이 생성됨
열에 이름 지정
df = pd.read_excel('auto-mpg.xlsx', header=None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleratio', 'model year', 'origin', 'name']
print(df)
'''
mpg cylinders displacement horsepower weight acceleratio \
0 18.0 8 307.0 130 3504 12.0
1 15.0 8 350.0 165 3693 11.5
2 18.0 8 318.0 150 3436 11.0
3 16.0 8 304.0 150 3433 12.0
4 17.0 8 302.0 140 3449 10.5
.. ... ... ... ... ... ...
393 27.0 4 140.0 86 2790 15.6
394 44.0 4 97.0 52 2130 24.6
395 32.0 4 135.0 84 2295 11.6
396 28.0 4 120.0 79 2625 18.6
397 31.0 4 119.0 82 2720 19.4
model year origin name
0 70 1 chevrolet chevelle malibu
1 70 1 buick skylark 320
2 70 1 plymouth satellite
3 70 1 amc rebel sst
4 70 1 ford torino
.. ... ... ...
393 82 1 ford mustang gl
394 82 2 vw pickup
395 82 1 dodge rampage
396 82 1 ford ranger
397 82 1 chevy s-10
[398 rows x 9 columns]표준화(갤런당 마일(mpg) → 리터당 킬로미터(kpl))
mpg_to_kpl = 1.60934 / 3.78541
df['kpl'] = df['mpg'] * mpg_to_kpl
df['kpl'] = df['kpl'].round(2)
print(df['kpl'])
'''
0 7.65
1 6.38
2 7.65
3 6.80
4 7.23
...
393 11.48
394 18.71
395 13.60
396 11.90
397 13.18
Name: kpl, Length: 398, dtype: float64- 1 gallon: 3.78541 L
- 1 mile: 1.60934 km
- 리터당 킬로미터(
kpl): 1.60934 / 3.78541
데이터 타입 확인
print(df.dtypes)
'''
mpg float64
cylinders int64
displacement float64
horsepower object
weight int64
acceleratio float64
model year int64
origin int64
name object
kpl float64
dtype: objecthorsepower 는 분명 숫자 데이터일텐데 데이터 타입이 object 임임
왜?
horsepower 의 고유값 확인하기
print(df['horsepower'].unique())
'''
[130 165 150 140 198 220 215 225 190 170 160 95 97 85 88 46 87 90 113 200
210 193 '?' 100 105 175 153 180 110 72 86 70 76 65 69 60 80 54 208 155
112 92 145 137 158 167 94 107 230 49 75 91 122 67 83 78 52 61 93 148 129
96 71 98 115 53 81 79 120 152 102 108 68 58 149 89 63 48 66 139 103 125
133 138 135 142 77 62 132 84 64 74 116 82]? 의 개수 확인
print(df['horsepower'].value_counts(dropna=False)['?'])
'''
6value_counts() 는 시리즈를 반환하므로 인덱스 지정해서 검색 가능
? 값을 제거하는 방법
-
horsepower 열에서 ‘?’ 값을 가지고 있는 행을 선택해서 샘플 제거
-
‘?’→NaN→dropna()사용:
replace()df.replace('?', np.nan, inplace=True) df.dropna(subset=['horsepower'], inplace=True) print(df.dtypes) ''' mpg float64 cylinders int64 displacement float64 horsepower float64 weight int64 acceleratio float64 model year int64 origin int64 name object kpl float64 dtype: object⇒ horsepower 의 데이터 타입이 float 로 바뀐걸 확인 가능
