k-최근접 이웃, 선형회귀 실습 문제
📌문제
# 드라이브의 fish_market.zip 파일을 이용하여 분류와 회귀 모델 적용
# https://www.kaggle.com/datasets/vipullrathod/fish-market 에서 다운로드 가능
# length1: 머리 끝부터 생선 꼬리 시작부까지의 길이
# length2: 생선의 대각선 길이
# length3: 머리 끝부터 생선 꼬리 끝까지의 길이(최대 길이)
# 1. Bream(도미 계열)과 Perch(농어 계열)을 k최근접 이웃 분류기를 사용하여 분류
# 2. Bream(도미 계열)을 k최근접 이웃 회귀 학습기를 사용하여 예측
# 3. Bream(도미 계열)에서 length3와 weight를 선형 회귀로 예측
# 4. Bream(도미 계열)에서 특성 공학을 이용하여 모든 특성으로 무게를 예측1. Bream(도미 계열)과 Perch(농어 계열)을 k최근접 이웃 분류기를 사용하여 분류
필요한 모듈 및 데이터 불러오기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
df = pd.read_csv("/content/Fish.csv")행 추출을 위해 열 이름 및 Species 열의 unique value 확인
print(df.columns)
print(df['Species'].unique())
'''
Index(['Species', 'Weight', 'Length1', 'Length2', 'Length3', 'Height',
'Width'],
dtype='object')
['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']행 선택
df_two = df[df['Species'].isin(["Bream", "Perch"])]print(df_two['Species'].value_counts())
'''
Species
Perch 56
Bream 35
Name: count, dtype: int64차원의 저주는 생각하지 않고 모든 특성으로 데이터를 분할
# 차원의 저주는 생각하지 않고 모든 특성으로 데이터를 분할
features = ['Weight', 'Length1', 'Length2', 'Length3', 'Height', 'Width']
X = df_two[features]
y = df_two["Species"]X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state=42)데이터 정규화
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)학습셋의 평균과 표준편차를 계산해서 구한 평균과 표준편차를 이용해 테스트셋 정규화
knn 분류기 생성 및 학습(데이터셋 메모리에 저장)
kn = KNeighborsClassifier()
kn.fit(X_train_scaled, y_train)예측값 확인 및 점수
print(kn.predict(X_test_scaled))
print(y_test)
print(kn.score(X_test_scaled, y_test))
'''
['Perch' 'Bream' 'Perch' 'Bream' 'Bream' 'Perch' 'Bream' 'Perch' 'Perch'
'Bream' 'Perch' 'Perch' 'Perch' 'Perch' 'Bream' 'Perch' 'Perch' 'Bream'
'Perch' 'Perch' 'Bream' 'Perch' 'Bream']
80 Perch
20 Bream
115 Perch
25 Bream
14 Bream
92 Perch
22 Bream
108 Perch
122 Perch
28 Bream
118 Perch
123 Perch
96 Perch
110 Perch
6 Bream
78 Perch
75 Perch
34 Bream
89 Perch
85 Perch
18 Bream
74 Perch
7 Bream
Name: Species, dtype: object
1.02. Bream(도미 계열)을 k최근접 이웃 회귀 학습기를 사용하여 예측
필요한 모듈 및 데이터 불러오기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
df = pd.read_csv("/content/Fish.csv")데이터 행 추출, 입력값 및 타겟 설정
df_bream = df[df["Species"] == "Bream"]
X = df_bream[["Length1", "Length2", "Length3", "Height", "Width"]]
y = df_bream["Weight"]데이터 크기 확인
print(len(df_bream))
'''
35데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)데이터 정규화
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.fit_transform(X_test)knn 학습기 생성 및 학습(데이터 메모리에 저장)
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(X_train_scaled, y_train)점수 확인
print(knr.score(X_train_scaled, y_train))
print(knr.score(X_test_scaled, y_test))
'''
0.9760431806318826
0.7707612055641422과대적합 발생
mae(mean absolute error) 확인
from sklearn.metrics import mean_absolute_error
y_pred = knr.predict(X_test_scaled)
print(mean_absolute_error(y_test, y_pred))
'''
72.3703703703703872그램이나 차이남
3. Bream(도미 계열)에서 length3와 weight를 선형 회귀로 예측
필요한 모듈 및 데이터 불러오기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
df = pd.read_csv("/content/Fish.csv")열 추출해서 형태 확인
bream = df["Length3"]
print(bream)
'''
0 30.0
1 31.2
2 31.1
3 33.5
4 34.0
...
154 13.4
155 13.5
156 13.8
157 15.2
158 16.2
Name: Length3, Length: 159, dtype: float641차원 배열
bream = df[["Length3"]]
print(bream)
'''
Length3
0 30.0
1 31.2
2 31.1
3 33.5
4 34.0
.. ...
154 13.4
155 13.5
156 13.8
157 15.2
158 16.2
[159 rows x 1 columns]2차원 배열로 추출하니 열 이름 나타나는 것을 확인 가능
원하는 데이터 추출 및 2차원 배열 생성
bream = df[df['Species'] == 'Bream']
X = bream[['Length3']]
y = bream['Weight']데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)선형 학습기 생성 및 학습
lr = LinearRegression()
lr.fit(X_train, y_train)검증
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
'''
0.9623495264186923
0.8442765734488408과대적합 발생
Regulation(규제)
📌벡터(행렬)에서의 제곱합(= L2 )
행렬 곱 A×A가 성립하려면
A의 열 개수 = A의 행 개수가 되어야 함.
행렬 x 전치행렬
거리계산에서도 전치가 필수
Overfitting(과적합)과 손실함수
머신러닝 및 딥러닝 알고리즘은 모델 성능을 높이기 위해 손실 함수(Loss, 비용함수)를 최소화할 수 있는 방향으로 학습을 진행
모델을 만들 때, 한정된 일부 데이터만을 학습 데이터로 사용하게 됨
그러다 보니 학습 데이터에만 존재하는 특징(노이즈)들이 과하게 모델에 반영되어 손실함수가 필요 이상으로 작아지게 되는 경우가 발생
⇒ 모델은 손실함수를 최소화할 수 있는 것만 생각하므로, 그것이 과해지면 과적합이 발생하게 되는 것
📌가중치 규제
모델의 손실 함수값이 너무 작아지지 않도록 특정한 값(함수)를 추가하는 방법
이를 통해 weight 값이 과도하게 커져서 일부 특징에 의존하는 현상을 방지하고, (곡선이 들쭉날쭉하면 희소값에도 크게 영향을 받고 있다는 뜻)
데이터의 일반적인 특징(일반화, Generalization)을 잘 반영할 수 있도록 해줌
📌L1 규제, L2 규제
L1 Regularization 과 L2 Regularization 은 모델의 손실함수(Loss Function, Cost Function)에 각각 L1 Loss Function, L2 Loss Function 을 추가해준 것을 말함
Norm
: 유한 차원의 벡터 공간에서 벡터의 절대적인 크기(Magnitude) 혹은 벡터 간 거리
Lp 공간(Lp space) 혹은 르베르 공간(Lebesgue Space)
: 특정한 속성을 만족하며, 특정 가능한 기능의 공간
Lp norm
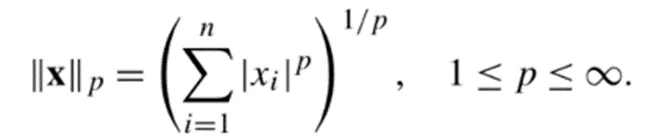
위 수식에서 n 과 p는 실수이며, p는 norm의 차수, n은 벡터의 차원 수를 나타냄
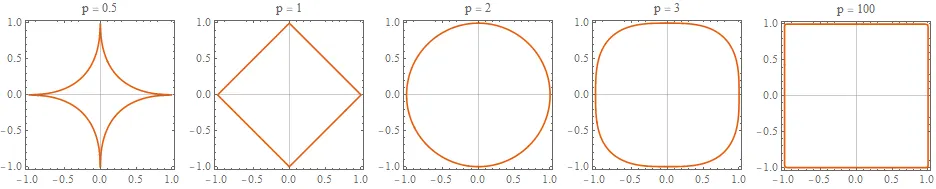
p의 차수에 따라서 Lp norm 은 아래와 같은 형태를 띄게 됨
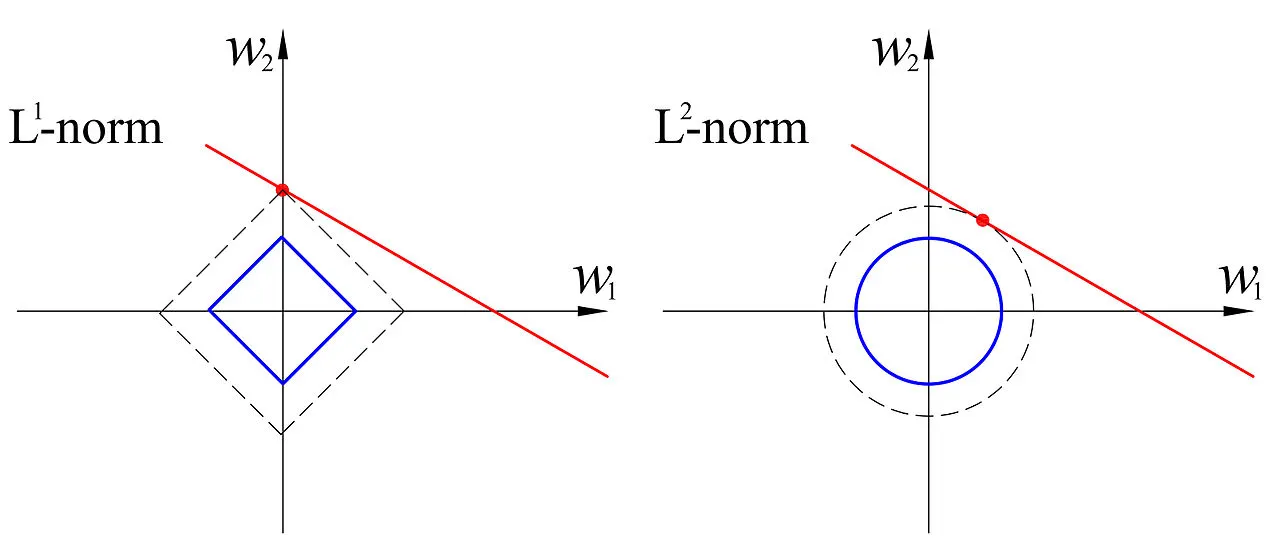
2차원 벡터 공간에서 L1 norm 의 분포는 마름모꼴을, L2 norm은 원을 나타내고 있으며, p가 무한대로 갈수록 정사각형의 형태를 띄게 됨
L1 규제
📌L1 norm (Manhattan distance), p=1
- L1 norm 은 맨하탄 거리 혹은 택시 거리라고 많이 알려져 있으며, 택시가 도시의 블록 사이를 이동해 다른 지점으로 이동하는 것과 같이 표현됨
- 특정 방향으로만 움직일 수 있는 조건이 있는 경우, 두 벡터 간의 최단 거리를 찾는데 사용되는 방법
- L1 loss 는 아래 수식과 같이 실제 값과 예측 값 오차들의 절대값들에 댓한 합을 나타냄
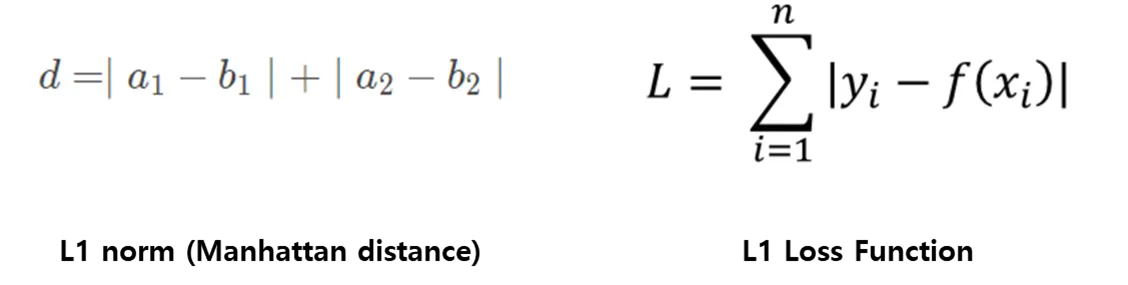
norm 과 규제
L1은 맨해튼 거리 방식, L2는 유클리드 거리 방식으로
”가중치 벡터가 원점(0,0)과 얼마나 떨어졌는가”
를 측정해서 페널티를 준다(손실함수에 페널티항을 더해줘서 Loss를 더 키움)
⇒ 가중치 벡터(W)가 원점에서 떨어진만큼, 즉 W의 크기가 커질수록 W가 0에 가까워지도록 규제함
L1 규제항
전체 손실 함수(예: 선형회귀, Lasso Regression)
L2 규제항
전체 손실함수(예: Ridge Regression)
L2 규제(Lidge Regulation) - 유클리드
오차제곱합은 예시로 쓴 손실함수(비용함수)
L2 규제는 페널티 항
가중치 발산 문제를 해결하기 위해 등장한 개념이므로,
가중치가 크면 클수록 손실을 인위적으로 증가시킴
L2 규제가 과대적합의 해결책 중 하나인 이유
가중치가 크면 모델은 입력의 작은 변화에도 예측이 크게 변한다.
즉, 민감하고 불안정한 함수가 된다 → 과대적합에 매우 취약.
반대로, 가중치가 작으면
- 기울기가 완만해지고
- 입력 변화에 둔감해지고
- 훨씬 “부드러운 함수”가 된다
이런 함수는 훈련 데이터의 잡음이나 세부 패턴에 휘둘리지 않고
일반화 능력이 향상된다.
L2 규제는 학습 과정에서 “가중치를 0 쪽으로 조금씩 당기는 힘”을 만든다
이 효과의 다른 이름이 Weight Decay(가중치 감소).
| 항목 | L1 규제 | L2 규제 |
|---|---|---|
| 수식 | (\lambda \sum | w_j |
| 노름 | L1 norm (맨해튼 거리) | L2 norm (유클리드 거리) |
| 기하학적 형태 | 마름모(꼭짓점 존재) | 원/구(매끄러움) |
| 가중치 감소 방식 | 일부 가중치를 0으로 만듦 | 가중치를 전체적으로 부드럽게 줄임 |
| 효과 | 특성 선택(feature selection) | 과적합 방지, 안정성 향상 |
| 해의 희소성 | 높음 (Sparse) | 낮음 (Dense) |
| 미분 가능 여부 | 0에서 미분 불가능 | 전체 구간에서 미분 가능 |
| 최적화 난이도 | 난이도 높음 (비매끄러움) | 쉬움 (Convex + Smooth) |
| 해석 | 어떤 feature가 중요한지 자동 선택 | 모든 feature를 조금씩 반영 |
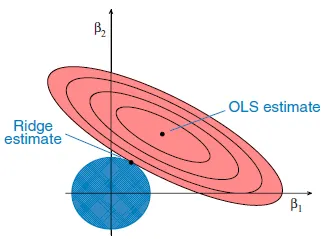
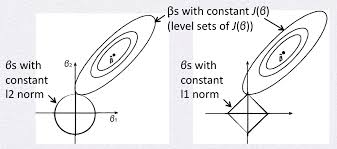
L2 규제
“원형/구형” 제약 영역
- 매끄럽고 둥글다
- 꼭짓점이 없다 → 가중치가 정확히 0이 되기 어려움 → 대신 전체적으로 “작아진다”
L1 규제
“마름모(다이아몬드)” 제약 영역
!https://joshnguyen.net/files/l1_proj_figs/l1_gif.gif?utm_source=chatgpt.com
{kind=link}
- 꼭짓점이 있음
- 최소점이 꼭짓점에 닿기 쉬움 → 자연스럽게 가중치가 0이 됨 (Sparse) → 중요한 feature 몇 개만 남기고 나머지는 제거됨
릿지 규제 실습
# 규제
# 릿지
"""
집 값 예측
방 개수: 조금 영향
평수: 큰 영향
층수: 조금 영향
엘레베이터 유무: 조금 영향
지하철 거리: 영향 있음
연식: 영향 있음
난방 방식: 영양 적음
"""
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
'''
0.9896101671037343
0.9790693977615387규제 강도 테스트
규제 강도 값이 높으면 규제가 세짐
import matplotlib.pyplot as plt
train_score = []
test_score = []alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
ridge = Ridge(alpha = alpha)
ridge.fit(train_scaled, train_target)
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))plt.plot(alpha_list, train_score)
plt.plot(alpha_list, test_score)
plt.xscale("log")
plt.xlabel("alpha")
plt.ylabel("R^2")
plt.show()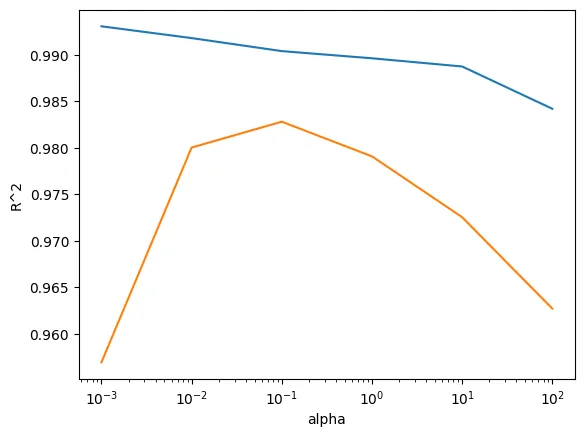
라쏘 규제 실습
# 라쏘
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
'''
0.989789897208096
0.9800593698421883train_score = []
test_score =[]
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
lasso = Lasso(alpha = alpha)
lasso.fit(train_scaled, train_target)
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel("alpha")
plt.ylabel("R^2")
plt.show()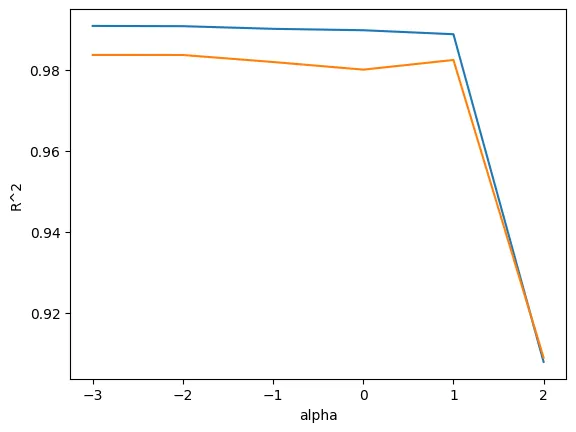
버려진 가중치의 개수 확인
print(np.sum(lasso.coef_==0))로지스틱 회귀
📌-
Odds 정의
어떤 사건이 일어날 확률 vs 일어나지 않을 확률의 비율
- p = 사건이 일어날 확률
- 1-p = 사건이 일어나지 않을 확률
- Odds = “일어난다” : “안 일어난다”
확률 p의 범위는 0~1
오즈 p/(1−p)는 0~∞
즉, 절대로 음수가 될 수 없음
그러나 우측항에 선형식을 두기 위해선 선형식의 범위가 전체 실수 범위이므로 범위 확장이 필요함
-
Odds Ratio, 오즈 비
두 그룹의 odds 를 나눈 값
두 그룹 중 어느 그룹이 사건이 일어날 오즈가 얼마나 큰지를 나타내는 상대적인 지표
-
Log Odds, 로그 오즈
오즈를 로그로 변환한 값
완전한 실수 범위(−∞ ~ ∞)
⇒ , 선형식과 연립 가능(범위가 같아짐)
-
시그모이드
: 로그 오즈에서 확률로 변환하는 함수
시그모이드는 임의의 실수(−∞~+∞)를 확률(0~1)로 변환
시그모이드의 입력 z는 바로 로그 오즈
즉,
- z가 크면 → 확률 1에 가까워짐
- z가 작으면 → 확률 0에 가까워짐
이 “z”가 바로 로지스틱 회귀의 선형식(로그 오즈):
로지스틱 회귀에서 Odds Ratio
로지스틱 회귀는 확률 p를 직접 예측하지 않고,
log-odds(로그 오즈)를 예측(어떤 클래스의 확률이 더 높은지)
로지스틱 회귀의 핵심 식
이걸 정리하면:
즉, 로지스틱 회귀의 가중치 w 는 곧 오즈비를 곱하는 상수가 됨
📌오즈와 로그오즈의 관계
오즈에서 로그를 취하면 로그오즈가 되고,
로그오즈를 지수(exponential)하면 다시 오즈가 된다.
서로 정확히 역함수 관계!
📌로그오즈는 선형적으로 증가한다 (해석이 쉬워짐)
오즈는 비례 증가가 아니라 비선형 증가를 한다.
예를 들어 오즈 2 → 4 → 8 → 16
이런 식으로 지수적으로 커진다.
그러나 로그오즈는 이렇게 변한다:
log(2) → log(4) → log(8) → log(16)
= 1 → 2 → 3 → 4 같은 선형 증가
그래서,
특성 x가 1 증가할 때 log-odds가 “w만큼 증가한다”는 해석이 가능해진다.
즉, 해석이 선형 모델과 동일해진다.
Rogistic Regression 로지스틱 회귀 실습
데이터 불러와서 확인
# 로지스틱 회귀
import pandas as pd
fish = pd.read_csv("/content/Fish.csv")
print(fish.head())
'''
Species Weight Length1 Length2 Length3 Height Width
0 Bream 242.0 23.2 25.4 30.0 11.5200 4.0200
1 Bream 290.0 24.0 26.3 31.2 12.4800 4.3056
2 Bream 340.0 23.9 26.5 31.1 12.3778 4.6961
3 Bream 363.0 26.3 29.0 33.5 12.7300 4.4555
4 Bream 430.0 26.5 29.0 34.0 12.4440 5.1340종의 unique value 확인
print(pd.unique(fish["Species"]))
'''
['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']입력 데이터와 타깃 데이터를 분류
print(fish.columns)
'''
Index(['Species', 'Weight', 'Length1', 'Length2', 'Length3', 'Height',
'Width'],
dtype='object')fish_input = fish[['Weight', 'Length1', 'Length2', 'Length3', 'Height',
'Width']].to_numpy()
fish_target = fish['Species'].to_numpy()to_numpy() : 모델 입장에서는 열 이름(특성의 이름)이 필요 없으므로 그냥 2차원 배열로 바꿔줌
입력값 배열 잘 생성됐는지 확인
print(fish_input[:5])
'''
[[242. 23.2 25.4 30. 11.52 4.02 ]
[290. 24. 26.3 31.2 12.48 4.3056]
[340. 23.9 26.5 31.1 12.3778 4.6961]
[363. 26.3 29. 33.5 12.73 4.4555]
[430. 26.5 29. 34. 12.444 5.134 ]]데이터 분할
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)데이터 정규화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)k-최근접 이웃으로 분류기 생성
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)점수
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
'''
0.8907563025210085
0.825약간의 overfitting (과대적합)
target 값과 예측 값 비교
print(test_target)
print(kn.predict(test_scaled))
'''
['Perch' 'Smelt' 'Pike' 'Whitefish' 'Perch' 'Bream' 'Smelt' 'Roach'
'Perch' 'Pike' 'Bream' 'Whitefish' 'Bream' 'Parkki' 'Bream' 'Bream'
'Perch' 'Perch' 'Perch' 'Bream' 'Smelt' 'Bream' 'Bream' 'Bream' 'Bream'
'Perch' 'Perch' 'Whitefish' 'Smelt' 'Smelt' 'Pike' 'Perch' 'Perch' 'Pike'
'Bream' 'Perch' 'Roach' 'Roach' 'Parkki' 'Perch']
['Perch' 'Smelt' 'Pike' 'Perch' 'Perch' 'Bream' 'Smelt' 'Perch' 'Perch'
'Pike' 'Bream' 'Perch' 'Bream' 'Parkki' 'Bream' 'Bream' 'Perch' 'Perch'
'Roach' 'Bream' 'Smelt' 'Bream' 'Bream' 'Bream' 'Bream' 'Perch' 'Perch'
'Perch' 'Smelt' 'Smelt' 'Pike' 'Perch' 'Roach' 'Pike' 'Bream' 'Perch'
'Roach' 'Perch' 'Parkki' 'Perch']k-최근접 이웃은 차원의 저주 한계가 있으므로 다중분류에서는 취약한 모습을 보임
k-최근접 이웃도 확률 구하기 가능
import numpy as np
print(kn.classes_)
proba = kn.predict_proba(test_scaled[:10])
print(np.round(proba, decimals=4))
'''
['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[1. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]]로지스틱 회귀로 이진 분류
입력, 타겟 설정
# **조건식(도미, 빙어)**
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]로지스틱 회귀 학습기 생성 및 학습
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)점수
print(lr.score(train_bream_smelt, target_bream_smelt))
print(lr.score(test_scaled, test_target))
'''
1.0
0.4클래스 확인 및 학습셋으로 예측 확률 확인
print(lr.classes_)
print(lr.predict_proba(train_bream_smelt[:5]))가중치 및 편향 확인
print(lr.coef_, lr.intercept_)
'''
[[-0.36781969 -0.50365695 -0.52507176 -0.60515406 -0.92933501 -0.66853977]] [-2.35561914]특성별 가중치, 편향
로지스틱 회귀를 이용한 다중 분류
max_iter: 학습 횟수
C: 규제 강도(C가 클수록 규제가 약해짐)
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
'''
0.9411764705882353
0.925print(test_target)
print(lr.classes_)
print(np.round(lr.predict_proba(test_scaled[:10]), decimals=3))
'''
['Perch' 'Smelt' 'Pike' 'Whitefish' 'Perch' 'Bream' 'Smelt' 'Roach'
'Perch' 'Pike' 'Bream' 'Whitefish' 'Bream' 'Parkki' 'Bream' 'Bream'
'Perch' 'Perch' 'Perch' 'Bream' 'Smelt' 'Bream' 'Bream' 'Bream' 'Bream'
'Perch' 'Perch' 'Whitefish' 'Smelt' 'Smelt' 'Pike' 'Perch' 'Perch' 'Pike'
'Bream' 'Perch' 'Roach' 'Roach' 'Parkki' 'Perch']
['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
[[0. 0.014 0.839 0. 0.137 0.007 0.003]
[0. 0.002 0.042 0. 0.006 0.949 0. ]
[0. 0. 0.03 0.936 0.01 0.024 0. ]
[0.012 0.034 0.27 0.004 0.597 0. 0.083]
[0. 0. 0.906 0.002 0.088 0.003 0.001]
[0.999 0. 0. 0. 0. 0. 0. ]
[0. 0.001 0.05 0. 0.003 0.945 0. ]
[0.001 0.007 0.341 0.012 0.62 0.001 0.017]
[0. 0.002 0.809 0.002 0.176 0. 0.011]
[0. 0. 0.02 0.98 0. 0. 0. ]]predict_proba()
- 이진 분류 → Sigmoid 사용
- 다중 분류 → Softmax 사용
가중치 및 편향 확인
print(lr.coef_, lr.intercept_)
print(lr.coef_.shape, lr.intercept_.shape)
'''
[[-1.32466659 -1.29978832 -0.61890993 2.96842056 7.69693838 -0.95893352]
[ 0.30637186 -1.19877735 -1.66634215 -3.46711038 6.6116846 -1.72169239]
[ 3.45202092 1.63422834 5.38353469 -9.02069511 -5.77351682 3.73345984]
[-0.55127353 2.65892374 2.60983132 2.96167617 -3.54754492 -1.96739553]
[-1.28722207 -1.29346623 -5.37303804 5.78583705 -0.85926695 1.83501464]
[-1.41518136 1.66088556 0.92333872 0.84058215 -5.79021729 -4.61191099]
[ 0.81995077 -2.16200575 -1.25841463 -0.06871044 1.661923 3.69145795]] [-0.04180256 -0.30993599 3.22778828 -0.48293366 2.71821779 -6.53659842
1.42526456]
(7, 6) (7,)Softmax 분류기에서는
각 클래스마다 자체적인 선형식 z 를 하나씩 가진다.
- k = 클래스 번호 (7개)
- x = 입력 벡터 (6차원)
- w_k = 해당 클래스에 대한 가중치 벡터 (6차원)
즉,
각 클래스마다 “가중치 6개 + bias 1개”가 필요한 구조
그래서 가중치 전체는 이렇게 생긴다:
- 클래스 7개 × 특성 6개 → shape = (7, 6)
- bias도 클래스마다 1개씩 → shape = (7,)
