1. 학습 방법 분류
- 지도 학습 : 정답을 주고 규칙성인 데이터의 패턴을 배우게 하는 학습 방법
- 비지도 학습 : 정답이 없는 데이터 만으로 배우게 하는 학습 방법
- 강화 학습 : 선택한 결과에 대해 보상을 받아 행동을 개선하게 하는 학습 방법
2. 과제에 따른 분류
- 분류 문제 : 분류된 데이터를 학습하여 규칙을 기반으로 주어진 데이터를 적절히 분류하는 것을 목적으로 함 -> 범줏값을 예측하는 것
ex) 내일 주가가 오를까?
- 회귀 문제 : 값과 결과 값의 연관성을 찾고, 기반하여 새롭게 주어진 데이터의 값을 예측하는 것을 목적으로 함 -> 연속적인 연산값을 예측 및 확인하는 것
ex) 내일 주가가 얼마일까?-클러스터링 : 분류 문제의 비지도 학습 방법이다.
3. 과대/과소 적합
- 과대 적합 :
학습 데이터를 너무 과하게 학습하여, 학습 데이터에서는 성능이 매우 좋지만, 평가 데이터에서는 성능이 매우 안좋다.
- 과소 적합 :
학습 데이터를 너무 적게 학습하여, 학습 데이터보다 평가 데이터에 대해 성능이 매우 좋거나 안좋은 경향을 띈다.
머신러닝 과정
1) 환경준비 > 2) 데이터 이해 > 3) 데이터 준비 > 4) 모델링
1) 환경준비
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings(action='ignore') %config InlineBackend.figure_format = 'retina' #시각화 고해상도 출력
2) 데이터 이해
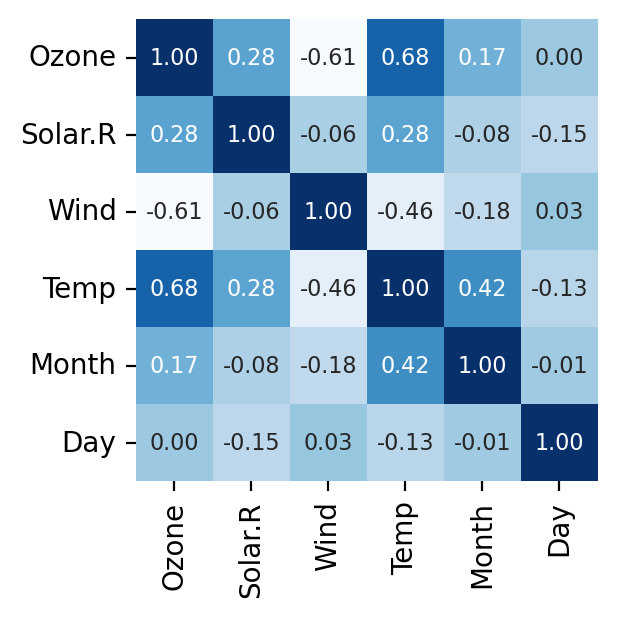
data.head(3) data.tail(3) data.describe() data.info() # 만약 dtype = object인 경우, 필히 숫자형으로 바꿔줘야 됨. # 상관관계 확인 k = data.corr() # 상관관계 시각화 sns.heatmap(k, annot = True, #글자 출력 cmap='Blues', fmt='.2f', #소수점 자리 수 표현 cbar=False, #colorbar = False square=True, annot_kws={'size':8}, #글자 크기 조절 )
3) 데이터 준비
#1. 결측치 처리 data.isna().sum() data['Solar.R'].fillna(method='ffill', inplace = True) __________________ #2. 변수 제거 drop_cols = ['Month', 'Day'] data.drop(drop_cols, axis = 1, inplace = True) __________________ #3. x,y 분리 1) target 확인 target = 'Ozone' 2) 데이터 분리 x = data.drop(target, axis = 1) y = data.loc[:, target] y.head() # 시리즈는 열(columns) 없음, values라고 부름 ________________________________________________________________________ +++++++++) 가변수화 -> data에서 작업하는게 아니라, x에서 가변수화를 진행해야 함.(꼭 기억할 것) -> target의 dtypes은 object여도 된다. ________________________________________________________________________ # 가변수화 대상: Pclass, Sex, Embarked dumm_cols = ['Pclass', 'Sex', 'Embarked'] # 가변수화 x = pd.get_dummies(x, columns = dumm_cols, drop_first=True) 3) 학습용-평가용 데이터 분리 - 1) 모듈 불러오기 from sklearn.model_selection import train_test_split - 2) 데이터 분리 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1, shuffle=True, stratify=y) # shuffle : 랜덤으로 섞는다. # stratify = y : 분할 할 때, 각 각 그룹을 균일하게 분할 될 수 있게 해준다. # random_state=1 or 3 ... : 동료와 동일하게 분할하게 하려면 이렇게 같은 숫자 입력해주면 됨
4) 모델링
1) 함수 불러오기 > 2) 모델 선언하기 > 3) 모델 학습하기 > 4) 모델 예측하기 > 5) 평가하기
1) 회귀 문제
알고리즘 : from sklearn.linear_model import LinearRegression
평가지표 : from sklearn.metrics import mean_absolute_error, r2_score
시각화 : plt.plot()을 대체로 사용한다.
- 2) 분류 문제
- 알고리즘 : from sklearn.neighbors import KNeighborsClassifier
- 평가지표 : from sklearn.metrics import confusion_matrix, classification_report
- 시각화 : plt.bar() or sns.barplot()을 대체로 사용한다. LogisticRegression의 경우 그래프의 양상을 확인하기 위해서 plt.plot()을 사용한다.
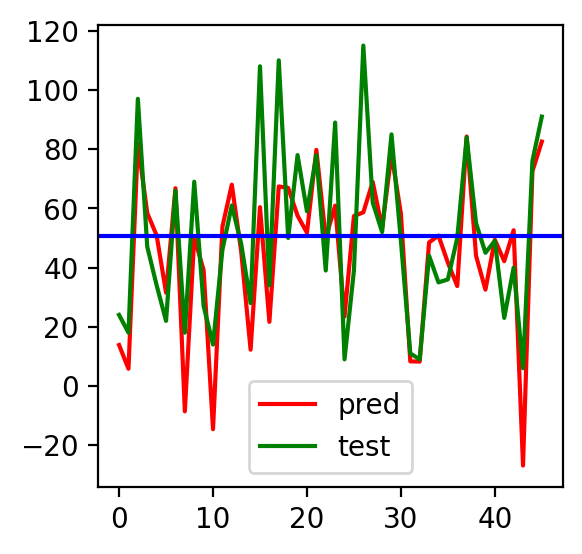
# 2단계: 선언하기 model = LinearRegression() # 3단계: 학습하기 model.fit(x_train, y_train) # 4단계: 예측하기 y_pred = model.predict(x_test) # 5단계: 평가하기 print('MAE :', mean_absolute_error(y_test, y_pred)) y_test.values[:10] #실제값 확인, array 형태로 만들어서 사용해야 됨. y_pred[:10] #예측값 확인, array 형태 # 6단계: 시각화 mean_ozone = y_test.mean() plt.plot(y_pred, color = 'r', label = 'pred') # 예측값 plt.plot(y_test.values, color = 'g', label = 'test') # 실젯값 plt.axhline(mean_ozone, color = 'b') plt.legend() plt.show()

큐브가 필요하다...!!!