Boosting Contrastive Learning with Relation Knowledge Distillation (AAAI/ 2022)
paper review
Motivation & Contribution
-
이 논문에서는 self-supervised representation learning이 large model에서는 effective함이 입증되어있지만 lightweight model에서는 여전히 supervised method와 큰 gap이 존재한다는 사실을 지적하고 있다.
-
또한 lightweight model이 instance-wise contrast를 수행할 때 더 쉽게 semantic space에서 collapse를 겪는 경향이 있음을 발견하였다고 한다.
-
이러한 문제를 해결하기 위하여, 이 논문에서는 contrastive learning을 위한 relation knowledge distillation framework를 제안하고 있다. 이 framework는 cluster-based SSL와 contrastive-based SSL을 매개하는 bridge역할을 한다. (SSL: Self-Supervised Learning)
-
이러한 ReKD는 여러 lightweight model들에서 큰 성능향상을 이루었음을 보여주고 있다.
Background: Instance Discriminative Learning
-
instance discriminative based method들은 하나의 positive와 여러개의 negative를 대비시킴으로써 feature representation을 학습하는 contrastive learning을 수행한다.
-
instance discrimination work들은 모든 instance들을 independent class로 본다는 결점이 있다.
-
이러한 결점은 instance간의 semantic simillarity를 상관하지 않고 모든 instance들을 멀어지게 만든다. 이는 결국 model의 semantic-level representation을 해치게 된다. (특히 lightweight model에서 더 그렇다.)
Background: Knowledge Distillation
-
knowledge distillation은 larger model에서 습득한 knowledge를 smaller model에 중요한 information의 손실 없이 transfer하는 것을 목표로 하고 있다.
-
몇몇 연구들에서는 knowledge distillation을 self-supervised learning에 extend시키고 있으며, 이러한 method들은 보통 offline teacher라고 불리는 (longthime pre-trainig을 요구로 하는) teacher model에 많이 의존한다.
-
이 논문에서는 offline teacher보다는 online teacher에 주목을 하고 있으며 semantic contrastive objective에 적합한 online knowledge distillation을 제안하고 있다.
Background: Knowledge Distillation (+append)
-
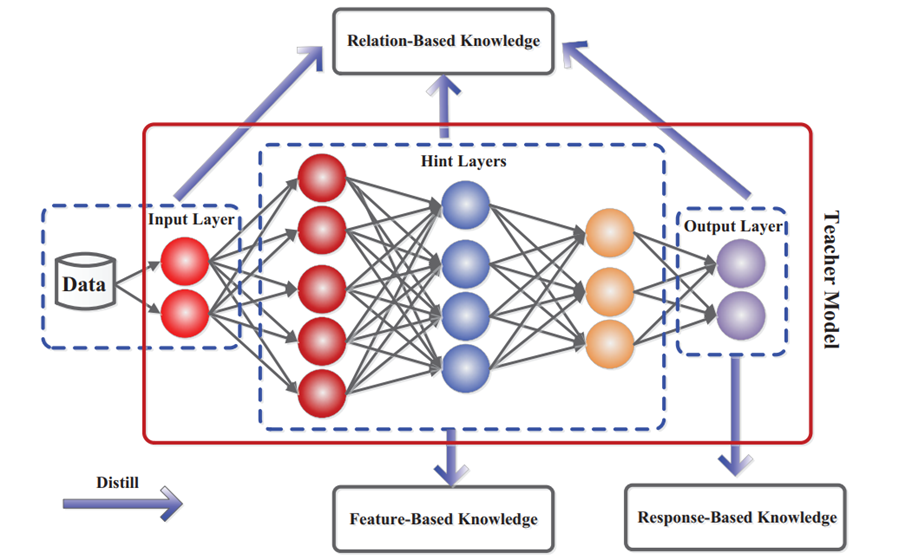
Knowledge Distillation에서 distill되는 knowledge의 종류에는 Response-based Knowledge, Feature-Based Knowledge, Relation-based Knowlegde 이렇게 3가지가 있다. 이 중 논문에서 사용되는 개념인 Response-based Knowledge와 Relation-based Knowledge에 대해서만 다루겠다.
-
Response-based Knowledge
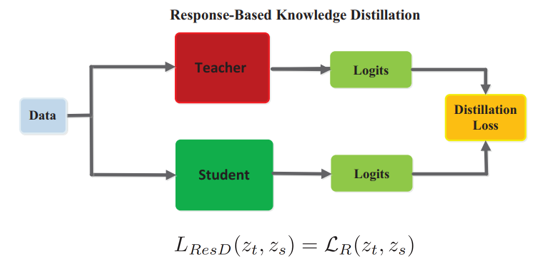
Response-based Knowledge를 이용하는 방식은 student module이 teacher로부터 나온 output값을 mimic하도록 한다. -
Relation-based Knowledge
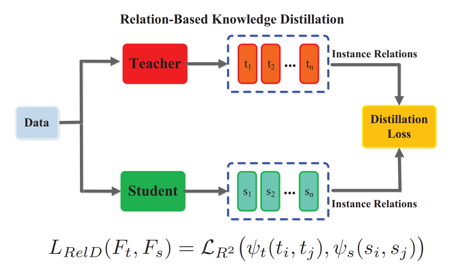
Relation-based Knowledge를 이용하는 방식은 teacher module에서 서로 다른 layer간의 혹은 서로 다른 data간의 relation을 포착하여 student module에게 transfer해주는 방식이다.
-
-
Heterogeneous teacher vs mean teacher
-
Heterogeneous teacher
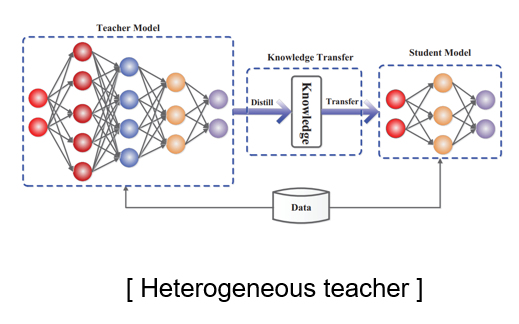
Heterogemeous teacher는 teacher model과 student model의 architecture가 서로 다른 것을 의미한다. -
mean teacher
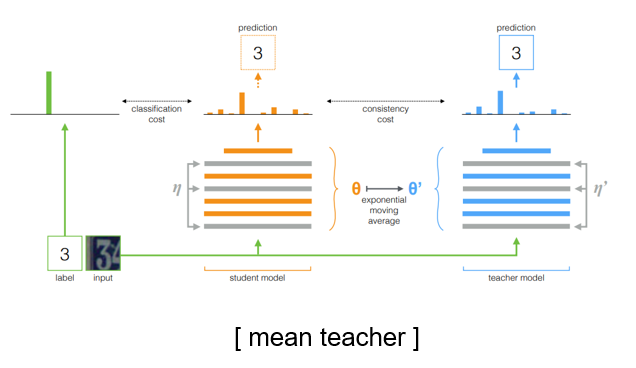
mean teacher는 student model로부터 teacher model을 moving average 방식을 통해 update하는 방식을 취하는데 student와 teacher가 서로 같은 architecture를 가진다는 특징이 있다.
-
Preliminary: Knowledge Distillation
-
knowledge distillation은 influential한 teacher model로부터 transfer된 knowledge가 student model이 배우기에 rich한 information을 제공해 줄 수 있음을 주장하고 있다.
-
KD에서 사용되는 objective는 teacher과 student간의 prediction error를 minimize하는 것을 목표로 하며 다음과 같은 식으로 정의가 된다. zT와 zS은 각각 teacher와 studnet의 representation을 의미하고 Dist()는 similarity metric을 의미한다.

Preliminary: Instance Discriminative Learning
-
Instance discriminative based method는 positive와 negative를 대비시킴으로써 representation을 학습하도록 instance-wise contrastive objective를 설계한다.
-
training set의 각 image xi에 대해서, encoder f()는 xi를 zi에 mapping시켜준다. ( zi = f(xi) )
-
이 때 사용되는 encoder는 NCE같은 loss function을 통하여 optimize된다.
-
mean teacher-based method 관점에서 positive는 mean teacher로부터 생성되고 아래와 같은 loss function을 통하여 optimize될 수 있다.
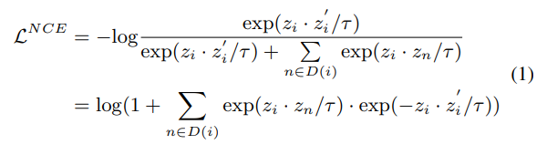
-
distillation 관점에서, 위의 수식은 student가 teacher의 historical distillation을 mimic하도록 하는 historical distillation으로 취급될 수 있다. 이러한 방식은 mean-teacher based model에서 response knowledge를 학습할 때 사용된다.
-
그렇지만 이 때 사용되는 negative set이 전부 다 옳은 것은 아니다. NCE는 모든 instance들을 negative로 취급하기 때문에 같은 category에 속하는 positive들도 negative로 포함되게 된다.
-
게다가 이 논문에서는 historical version으로부터 얻어진 하나의 positive가 contrastive objective에 대하여 충분한 information을 제공하여 줄 수 없고 이는 곧 student의 potential을 제한한다고 말한다.
Method: Online Heterogeneous Teacher
-
이 논문에서는 teacher와 student model의 architecture가 서로 다른 heterogeneous teacher를 사용했다. 그리고 보통의 self-supervised knowledge distillation method와 다르게 online teacher를 사용하였다.
-
여기서 사용하는 online heterogeneous teacher에서 teacher는 distillation stage에서 student와 동시에 update되며 parallelly efficient함을 보인다.
Method: Relation Knowledge
-
response knowledge로부터 생기는 semantic collpase의 영향을 줄이기 위하여 여기서는 더 diverse한 positive를 제안하였다.
(semantic collapse: 가까워야 하는 instance들이 intrinsic semantic과 관계 없이 embedding space내에서 멀리 떨어지는 현상, 결국에는 잘못된 optimization을 야기할 수 있음.) -
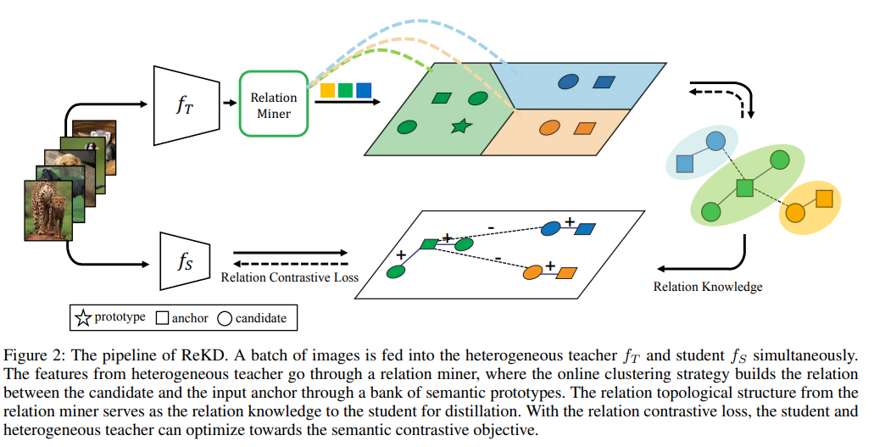
이를 위하여 이 논문에서는 anchor zi와 candidate uj의 positive/negative를 포착하는 relation knowledge를 도입하였다.
-
이 relation은 heterogeneous teacher의 embedding space에서 relation minor로부터 얻어진다. 그리고나서 이러한 relation은 student에게 contrastive objective의 guidance로서 transfer된다.
-
이를 하기 위해서, semantic prototype bank P를 구축하였다. bank의 각각의 prototype들은 independent한 semantic category로 취급이 되며 학습초기에는 spherical k-means cluster의 centroid로 초기화된다.
-
prototype bank를 얻은 후에 relation minor는 connection step과 update step을 번갈아가며 수행하면서 evolve된다.
Method: Connection
-
이 단계에서 bank P의 prototype을 embedding간의 relation의 reference로서 사용하였다고 한다.
-
anchor embedding zi와 candidate embedding uj가 주어졌을 때, 두 embedding 각각을 pk에 대해서 pairwise similarity를 측정하였다고 한다.
-
그리고나서 각각의 embedding e에 대해서 prototype assignment Q(e)를 다음과 같이 부여하였다.

-
만약 maximum similarity가 Θ보다 작으면 prototype에 -1을 부여하여 embedding이 어떠한 prototype에 matching 되는 것을 실패하였음을 의미하였다.
-
anchor와 candidate에 corresponding prototype을 assing한 후, 각 anchor candidate pair의 관계를 define하였다. 만약 anchor와 candidate가 서로 같은 prototype assignment Q를 가지면 positive pair로 그렇지 않으면 negative pair로 relation을 정의하여 주었다.
-
이렇게 정의된 sample들로 구축된 positive set과 negative set을 이용하여서 student에게 더 diverse한 semantic positive를 제공하여 줄 수 있었다고 한다.
Method: Update
-
이 단계에서는 prototype을 momentum하게 update하는 과정을 행하였다.
-
각각의 mini-batch에서 다음 식과 같이 pk을 update하였다.
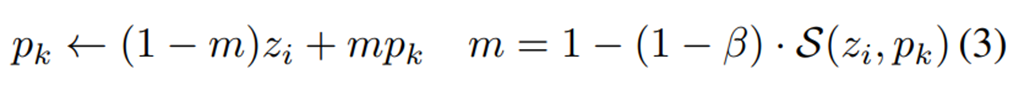
(m: similarity-based coefficient controlling the weight of the anchor embedding when updating the prototype.)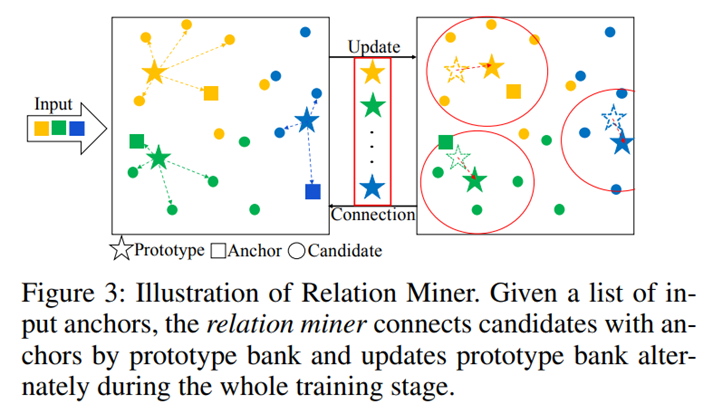
위의 그림과 같이 connection과 update 단계를 통하여 relation minor가 구축될 수 있다.
Method: Relation Contrastive Loss
- 앞서 본 historical distillation관점에서의 NCE loss와 달리 여기서 제안하는 relation contrastive objective는 semantic positive들과 negative들의 likelihood를 maximize하도록 설계가 되었다. 이는 semantic 관점에서 더 reasonable한 optimization을 제공하여 준다.
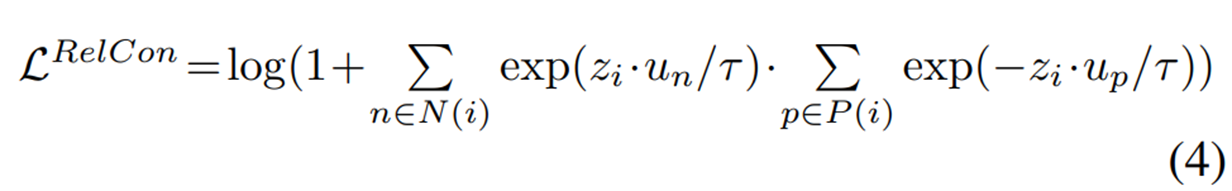
- 이러한 semantic relation knowledge를 통하여 self-supervised model은 semantic information을 포함할 수 있게되었고, 기존의 instance-wise contrast method들보다 더 generalize된 representation을 학습할 수 있도록 되었다고 한다.
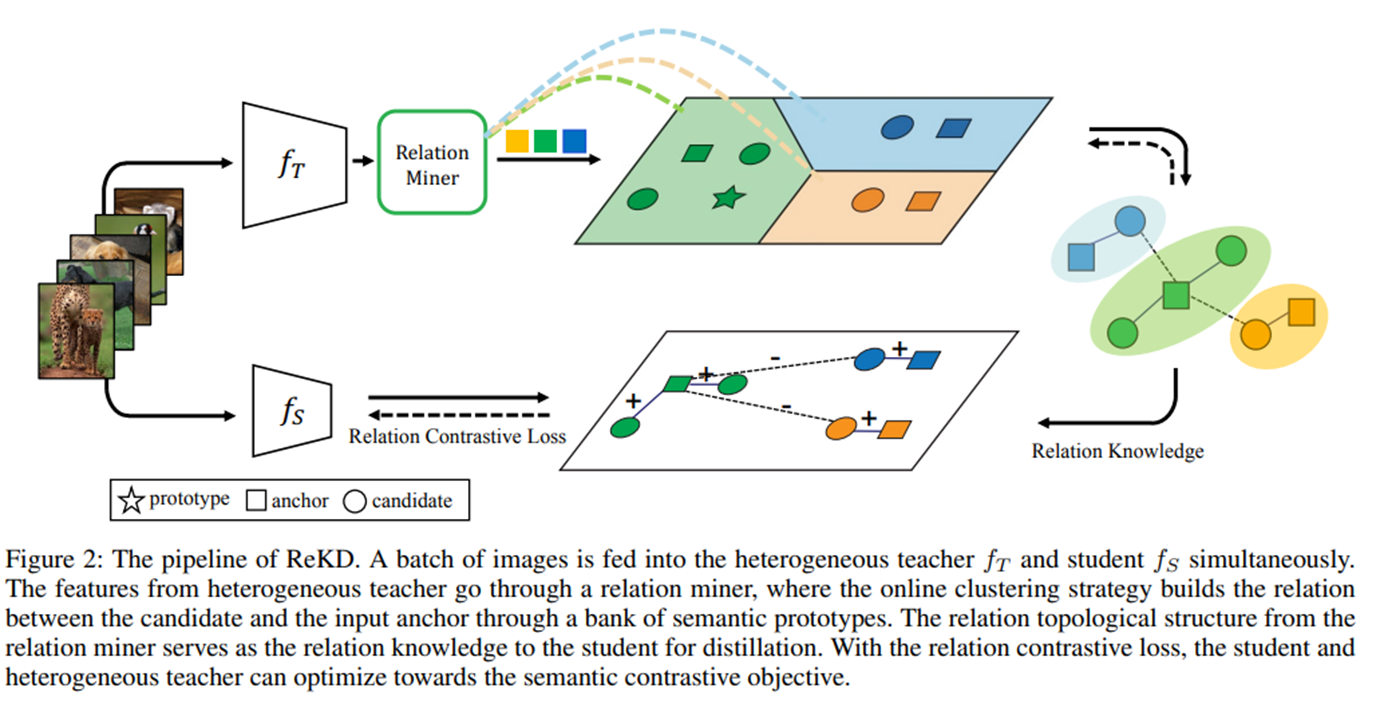
Pipeline of ReKD
Experiments
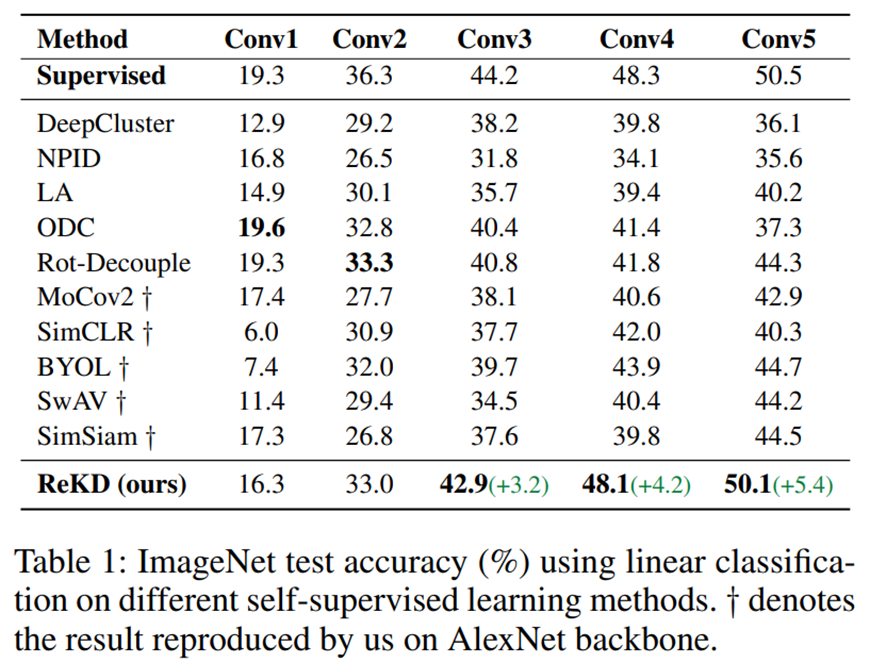
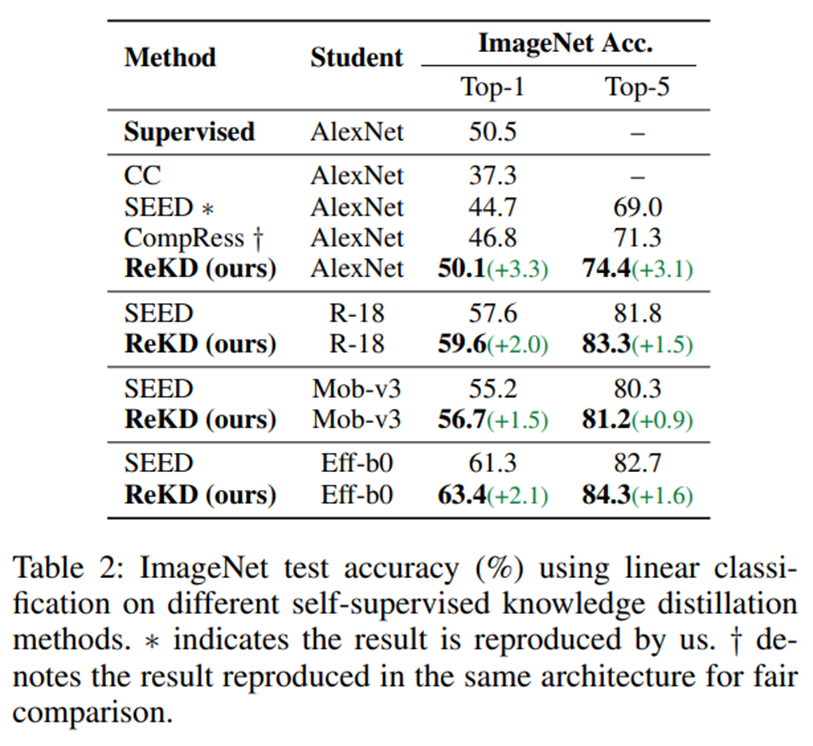
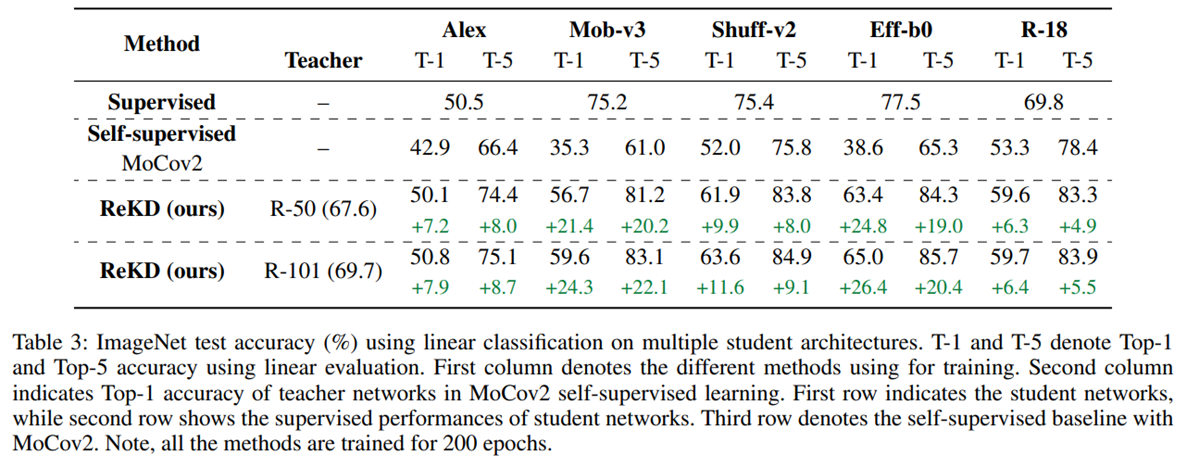
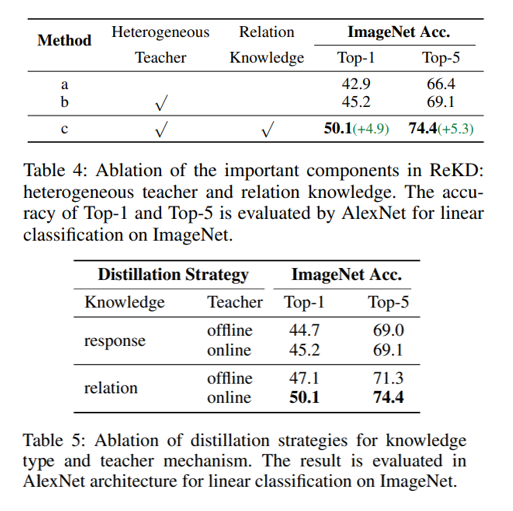
대부분의 experiment에서 좋은 성능을 거둔 것을 확인할 수 있다.
Conclusion
-
이 논문에서는 semantic collapse를 완화하기 위하여 Relation Knowledge Distillation(ReKD)를 제안하였다.
-
특히, ReKD는 lightweight model을 semantic contrastive objective로 guide해줄 수 있는 semantic relation을 제공해주었다고 한다.
-
이 논문에서 보여주고 있는 self-supervised learning과 self-supervised knowledge distillation의 benchmark들에서의 실험은 ReKD의 effectiveness를 증명하고 있다.
