K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters (IJCNLP 2021) paper review
paper review
Contribution
-
new kinds of knowledge가 pre-trained model에 주입될 때 발생하는 catastropic forgetting 문제를 해결하기 위하여 고안되었으며, Pre-trained Language Model의 parameter들은 fix를 시키고 adapter를 부착하여 knowledge를 주입하는 모델이다.
-
relation classification, entity typing, question answering의 task에서 성능을 향상시켰다.
Architecture
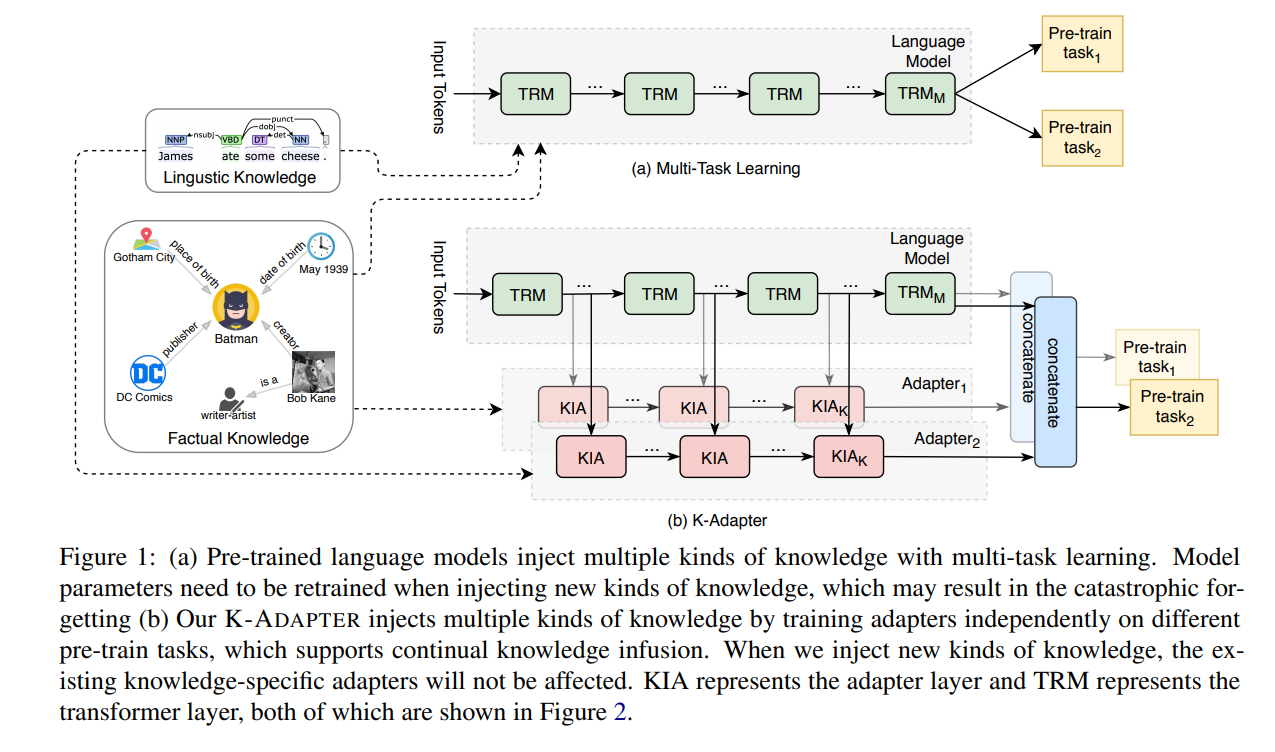
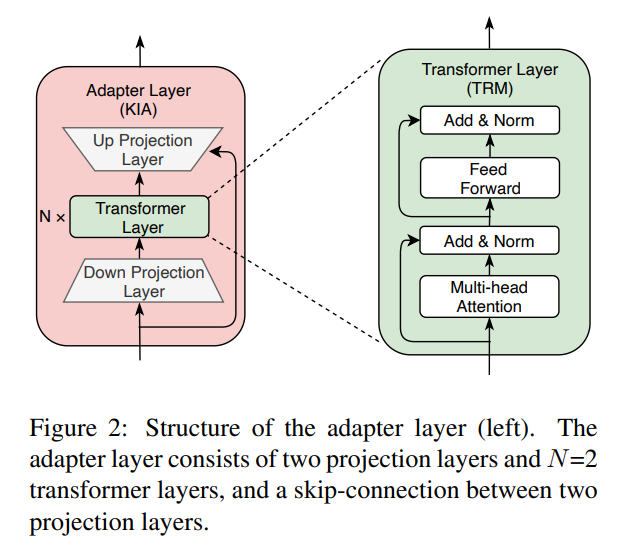
Figure 1-(a)의 architecture는 기존의 PLM이 multi-task learning으로 multiple kind의 knowledge를 주입하는 방식이다. 위의 방식에서는 PLM의 parameter들을 update하면서 모델을 훈련하고 있다.
Figure 1-(b)의 architecture는 이 논문에서 제안하는 K-ADAPTER의 방식이다. Transformer Layer(TRM)의 Intermediate layer에서 나온 output hidden state가 Adapter Layer(KIA)에 input으로 들어가서 Adapter를 훈련하게 된다. 그리고 최종적으로 TRM의 final hidden state와 KIA의 final hidden state를 concat하여서 output representation으로 사용하게 된다. Figure 1에서 보면 Adapter 1과 Adapter 2로 Adapter를 2개 사용하고 있는데 이 두 adapter는 각각 facutal Adapter, linguistic Adapter를 의미한다. (future work로 adapter의 개수를 늘려보는 것도 언급이 되고 있어 다른 knowledge를 주입한 adapter를 추가하면 또 성능 개선이 이루어질 가능성이 있어보인다.)
Factual Adapter
-
facutal adapter는 factual knowledge를 학습하는 adapter이다. factual knowledge란 fact와 관련된 basic information을 의미한다. (ex: tom의 아빠는 james이다.)
-
이러한 factual knowledge는 natural language의 entity간의 relationship으로부터 얻어질 수 있다.
-
따라서 adapter에 factual knowledge를 주입하기 위하여 K-ADAPTER는 factual adapter를 relation classification task에서 pre-train을 한다고 한다.
Linguistic Adapter
-
linguistic knowledge는 systactic하고 semantic한 information을 의미한다.
-
이러한 linguistic knowledge는 natural language text의 word간의 dependency relationship으로부터 얻어질 수 있다.
-
adapter에 linguistic knowledge를 주입하기 위하여 K-ADAPTER는 linguistic adapter를 dependency relation prediction task에서 pre-train을 한다고 한다.
Architecture (fine tuning)
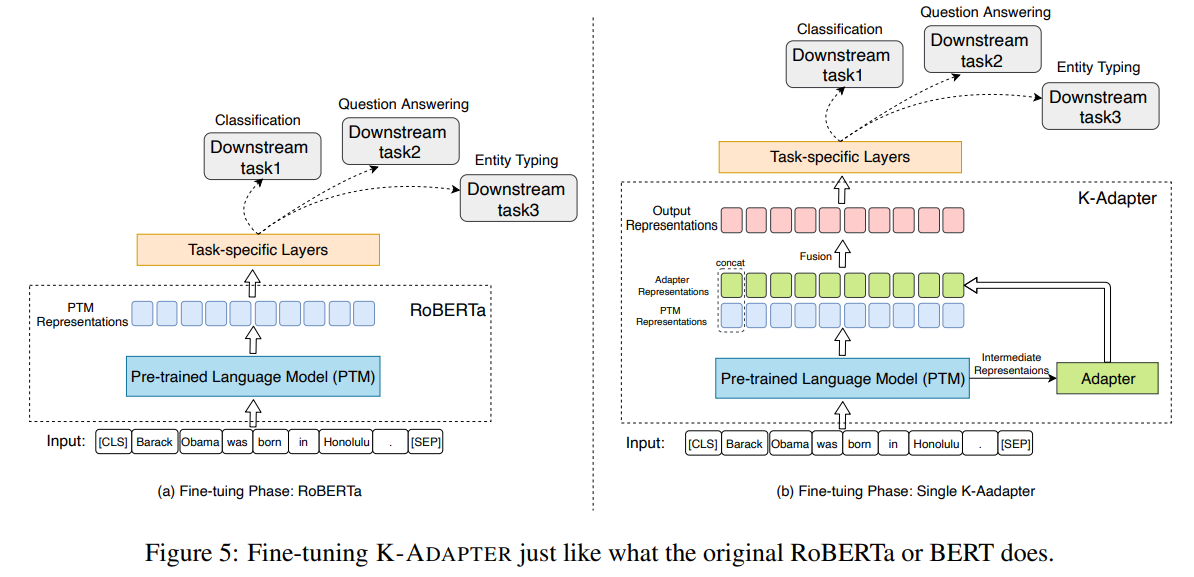
만약 multiple adapter라서 multiple adapter representation이 나오게 되면 output representation에서 PTM representation과 모든 adapter representation들을 concat을 하여서 output representation으로 사용을 한다고 한다.
Experiments

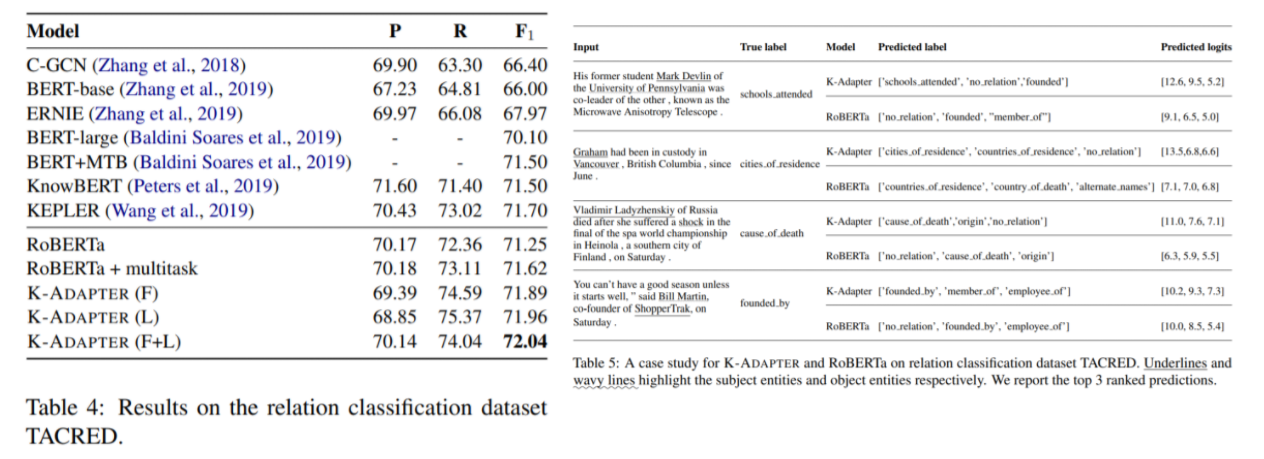
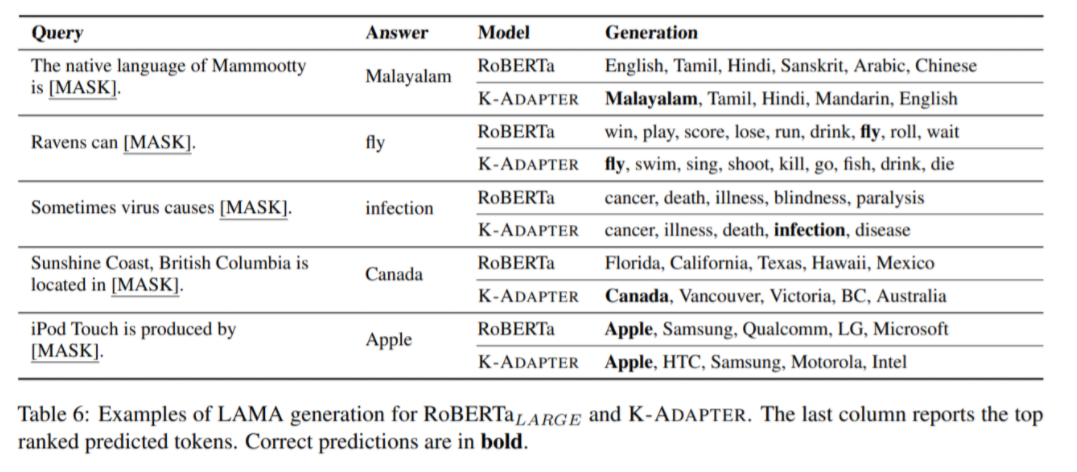
Table 6의 LAMA probe는 model이 factual knowledge를 얼마나 잘 memorize했는지 test하기 위한 cloze-style qa의 zero shot task이다. 위 두번째 예시를 보면 Rabens can [MASK]라는 문장이 주어졌을 때, RoBERTa보다 K-ADAPTER가 해당 단어가 fly라는 것을 더 높은 rank로 예측하는 것을 확인할 수 있다.
Conclusion
-
K-ADAPTER는 기존 pre-trained model의 paramter를 update하지 않으면서 새로운 knowledge를 주입하는 flexible하고 simple한 모델이다.
-
위의 3가지 task를 통하여 adapter를 이용했을 때의 성능향상에 대하여 보여주고 있다.
