Matching the Blanks : Distributional Similarity for Relation Learning (ACL 2019) paper review
paper review

Contribution
-
text로부터 직접 relation representation을 배우는 새로운 method인 Matching The Blanks(MTB)를 제안
-
Transformer sequence model 상단에 부착되는 relation encoder fθ를 위한 새로운 architecture를 고안
-
fθ가 entity linked text form의 distant supervision에서 널리 사용가능함을 보임
-
FewRel dataset에서 어떤 task training data를 사용하지 않고도 outperform함을 보임
-
MTB의 task agnostic representation으로 initialize되고 relation extraction dataset에 tuning된 model이 SemEval 2020 Task8, KBP37, TACRED dataset에서 outperform함을 보임
Primary goal
-
model이 text로부터 직접 relation representation을 생성하도록 develop
-
relation statement로부터 relation representation으로의 mapping에 초점을 맞춤
-
relation statement를 hr에 mapping 시키는 function hr = fθ(r)을 학습
(hr: sentence X 내의 s1과 s2로 mark된 entity간의 relation을 represent하는 fixed length vector)
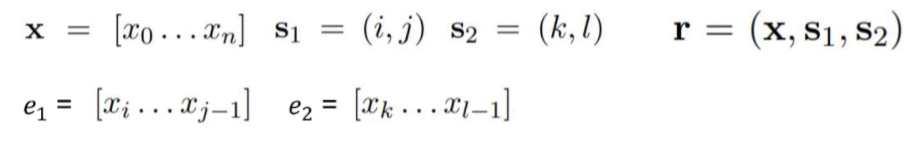
Relation Extraction task in MTB
-
Fully supervised relation extraction
relation statement r이 주어졌을 때, relation type t ∈ τ를 predict하는 task
(τ: fixed dictionary of relation types) -
Few-shot relation matching
query relation statement에 따라 relation statement의 candidate set을 rank를 매기고 match 시킴
즉, query relation statement rq에 따른 tq을 predict
Architecture
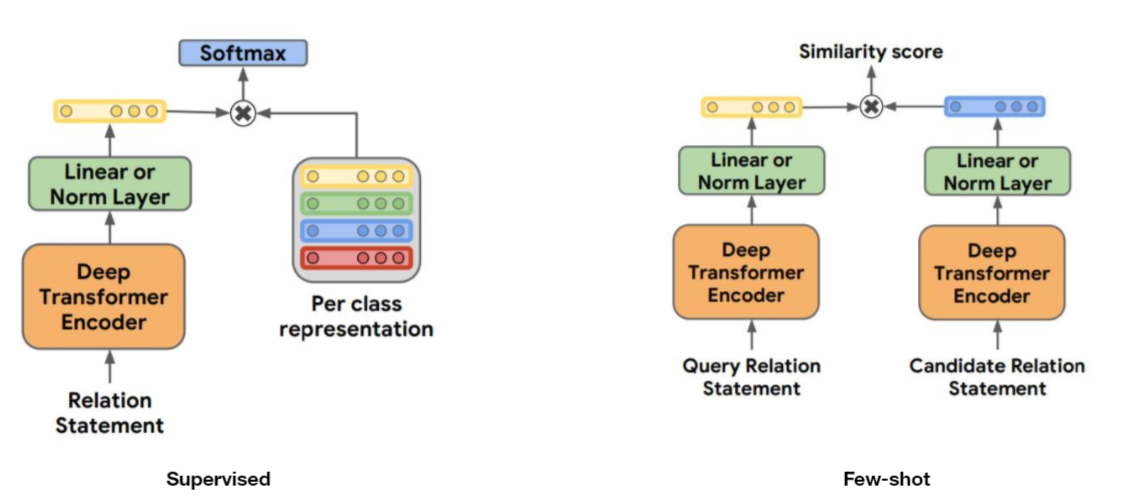
Entity span identification (input encoding)
-
standard input
entity span s1과 s2에 어떠한 explicit identification도 없는 형태의 input
-
Positional embeddings
span s1과 관련된 모든 token에 대해 s1 segmentation embedding을, span s2과 관련된 모든 token에 대해 s2 segmentation embedding을 더한다
-
Entity marker tokens
relation statement의 각 entity mention의 시작과 끝에 marker token을 도입
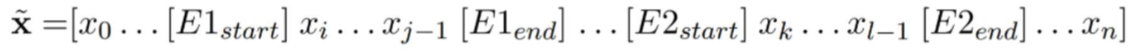
Fixed length relation representation (output relation representation)
-
[CLS] token
relation representation으로 [CLS] output, 즉 h0을 선택
-
Entity mention Pooling
각 entity mention의 word piece에 관련된 final hidden layer의 max-pooling 값으로부터 hr을 얻어 그것을 output representation으로 사용
-
Entity start state
input embedding에서 ENTITY MARKERS가 사용됐을 때, entity의 각 [start] token의 final hidden state를 concatenation하여서 output representation으로 사용
Variants of architectures for extracting relation representations from deep Transformers network
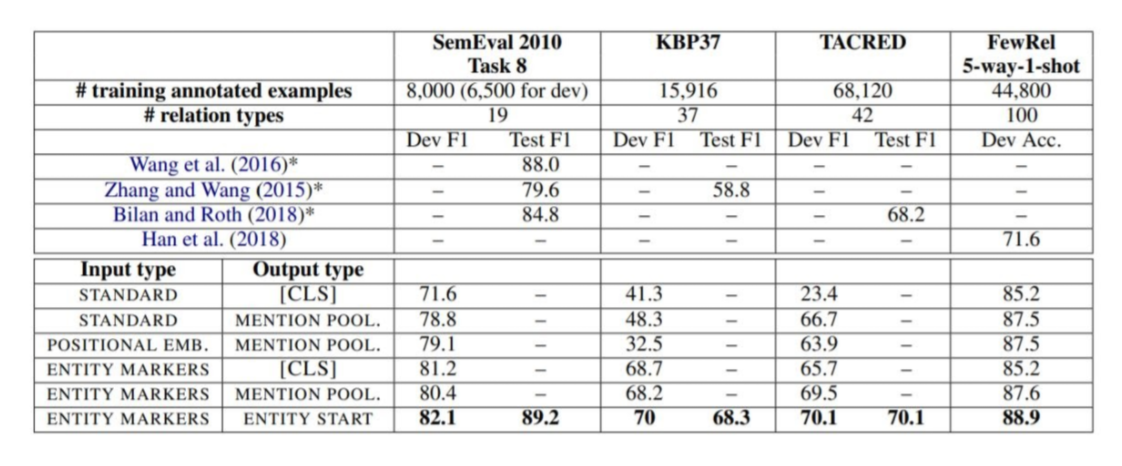
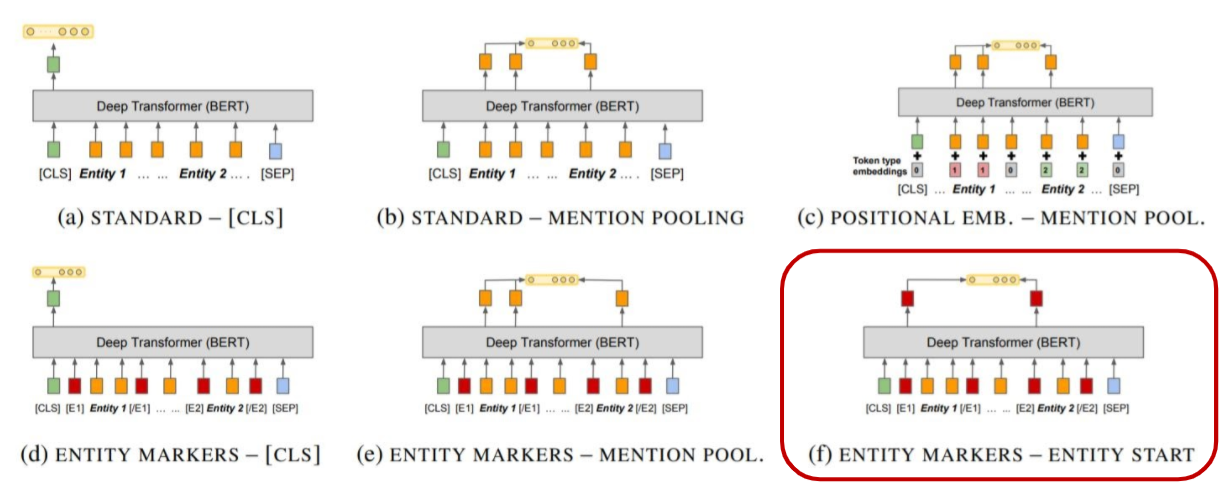
Entity Marker tokens와 Entity Start state를 같이 사용했을 때 가장 좋은 성능을 보였다고 한다.
Learning by Matching the Blanks
-
Hypothesis
-
어떤 relation statement r과 r' 쌍이 정의되어있을 때, 만약 두 relation statement가 semantically similar relation을 나타낸다면 내적 fθ(r)Tfθ(r')은 높을 것이라는 전제 하에 모델을 설계하였다고 한다.
-
r = (x, s1, s2)과 r' = (x', s'1, s'2)이 있을 때, s1과 s'1가 같은 entity를 지칭하고, s2과 s'2이 같은 entity를 지칭할 때 r과 r'이 같은 semantic relation으로 encode될 확률이 높다고 한다.
-
따라서 fθ가 두 relation statement가 같은 relation인지 아닌지를 판단할 수 있도록 학습을 시키는 것이 목적이다.
-
-
Learning setup
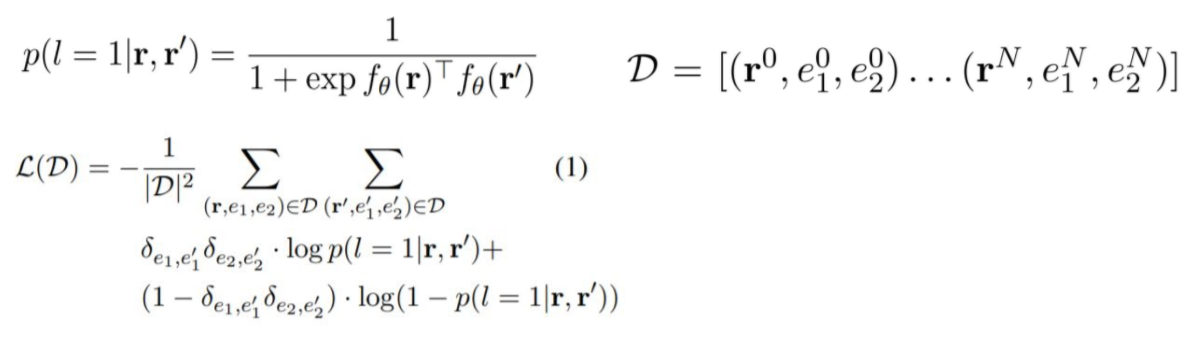
두 relation이 같으면 l = 1, 아니면 l = 0으로 두었을 때, r, r'이 주어졌을 때의 l = 1일 확률을 계산하고 그 값을 토대로 NLL loss를 구하여 사용한다. 위의 식에서 δ로 표기된 kronecker delta가 사용되는데, kronecker delta는 두 변수가 같은 값이면 1, 아니면 0의 값을 가진다고 한다. 즉 entity 1과 entity 2가 같은 값일 때는 l = 1을, 다른 값일 때는 l = 0을 계산하는 식이 된다.
( p(l=1|r,r') + p(l=0|r,r') = 1이므로 ) -
Introducing Blanks
- fθ가 좀 더 meaningful relation representation을 배우게 하기 위하여 위에서 소개된 D 대신에 modified corpus D~를 사용한다.
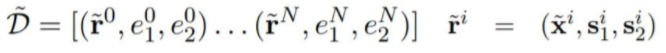
-
x~는 α의 확률로 s로부터 정의된 span을 가진다고 한다. 즉, 1-α의 확률로 [BLANK] token으로 대체된다. 따라서 L(D~)를 minimize하는 것은 fθ가 단순히 r의 named entity를 identify하는 것 이상을 요구한다.
-
그러므로 D~에서 train하는 것은 fθ가 두 개의 ([BLANK] 처리 될 수도 있는) entity span 간의 semantic relation을 encode하도록 한다.
-
Use noise-contrastive estimation
-
same entity를 가진 relation statement의 모든 positive pair를 사용한다.
-
easier negatives :
모든 relation statement pair set으로부터 randomly sample된 negative set을 사용한다. -
hard negatives :
하나의 entity는 공유를 하는 relation statement set으로부터 sample된 negative set을 사용한다.
위의 Table에서, rA와 rB는 서로 같은 entity를 가지므로 positive pair이고, rB, rc같은 경우는 하나의 entity만 공유를 하므로 negative pair(그 중에서도 hard negative)이다.
-
Experiments
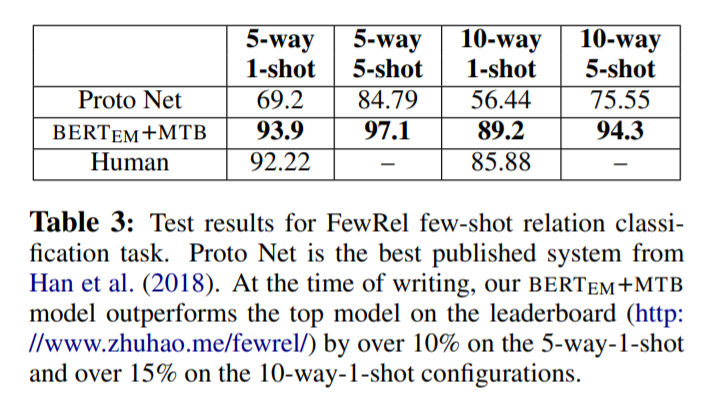
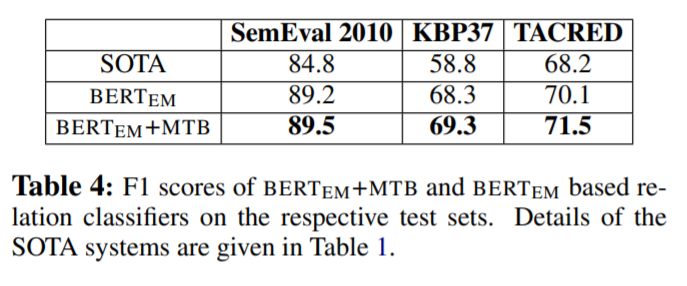
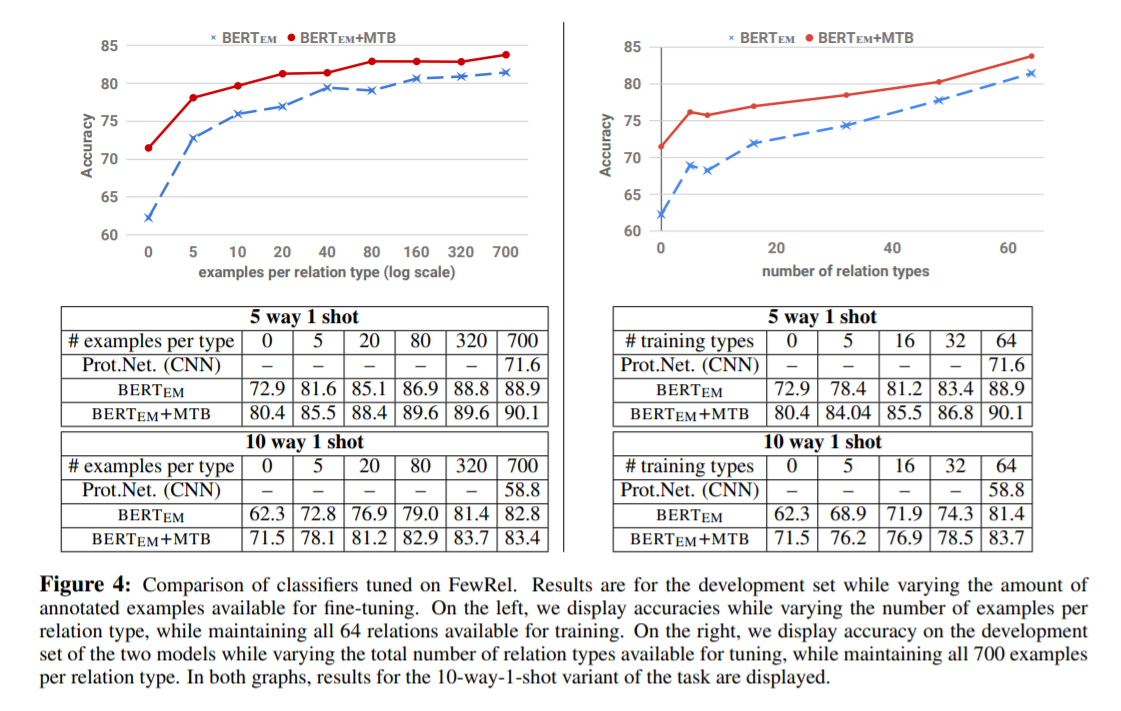
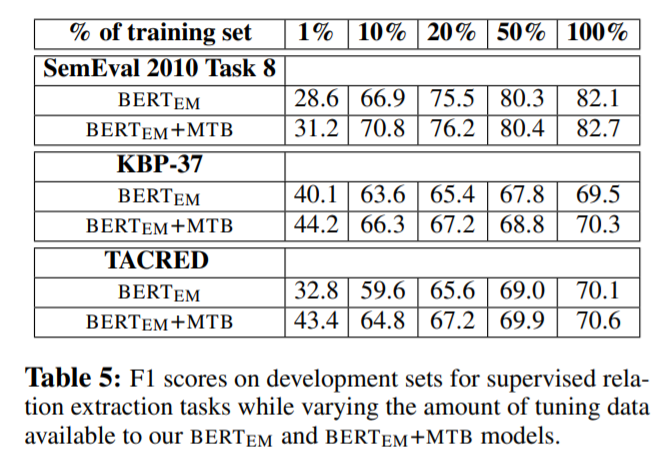
Figure 4를 봤을 때, type당 example을 하나도 사용하지 않았을 때에도 MTB를 사용한 model이 더 좋은 성능을 내는 것을 확인할 수 있다. 이는 MTB가 low resource에서 더 effective함을 증명하고 있다.
Conclusion
-
text로부터 직접 useful relation representation을 만드는 method를 도입하였다.
-
MTB model은 앞서 소개한 3개의 relation extraction task에서 state-of-the-art를 달성하였고, few-shot relation matching에서는 human accuracy를 outperform함을 보였다.
-
MTB model이 low-resource regimes에서 얼마나 effective한지를 보였고, 이는 relation extractor를 만들기 위하여 요구되는 사람의 노력을 상당히 줄일 수 있을 것이라고 주장한다.
