Neighborhood Contrastive Learning for Novel Class Discovery (CVPR / 2021) paper review
paper review
Contribution
-
이 논문에서는 NCD task에 대하여 주어진 query의 embedding space에서 local neighborhood를 이용한 Neighborhood Contrastive Learning method를 제안하였다.
-
또한 labeled sample을 이용하여 feature mixing을 통해 hard negative를 생성함으로써 추가적인 성능개선을 이루었다.
-
3가지 NCD benchmark에서 state-of-the-art보다 좋은 성능을 보이고 있다.
Background : Novel Class Discovery
-
이 논문에서 다루는 Novel Class Discovery task는 unlabeled set의 sample들을 다른 semantic category로 classify하는 목적을 가진다.
-
이 task가 기존의 unsupervised clustering과 다른 점은 이 task는 labeled set으로부터 얻은 knowledge를 이용하여 unlabeled set을 classify한다는 점이다.
-
전형적인 Novel Class Discovery method는 먼저 labeled data에 대하여 모델을 훈련하고 이를 unlabeled data에 대한 unsupervised clustering을 수행할 때 initialization 값으로 사용한다.
Overall Framework
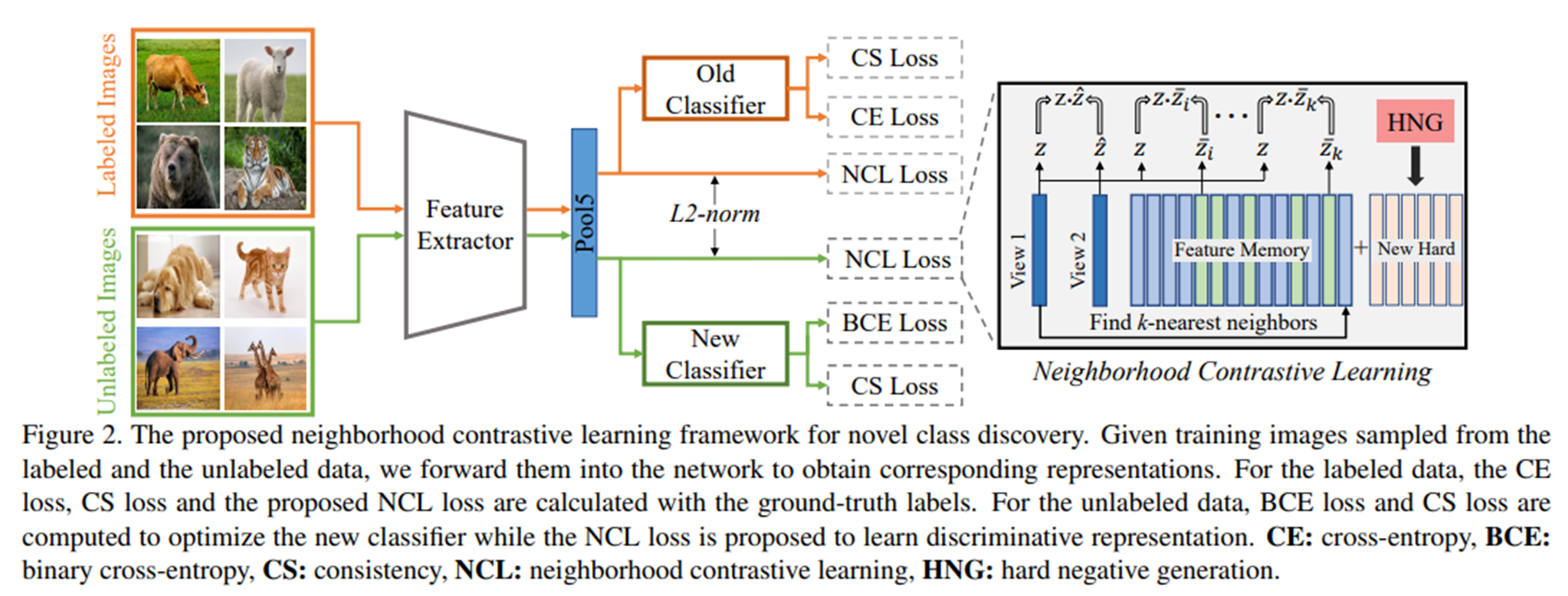
-
이 논문에서 제안하는 model의 전체적인 framework는 위의 figure2와 같다. 이 model에서는 labeled data와 unlabeled data에 대한 share feature extractor Ω와 각각 labeled, unlabeled data와 관련된 classifier Φl, Φu가 사용된다.
-
labeled image feature는 classifier Φl을 통과하며 이때는 Cross-Entropy loss가 계산된다.
-
unlabeled image feature는 classifier Φu를 통과하며 이때는 Binary Cross Entropy loss가 계산된다.
-
두 classifier는 consistent한 prediction을 생성하기 위하여 consistency loss를 사용한다.
-
share feature extractor로부터 나온 representation z는 이 논문에서 제안하는 Neighborhood Contrastive Loss (NCL)로부터 정제된다.
Baseline for Novel Class Discovery
-
우선 labeled data와 unlabeled dat에 대하여 self-supervision learning을 수행하여 label agnostic image representation을 학습한다.
-
그리고나서, labeled dataset을 이용하여 supervised learning을 수행하여 high-level feature를 학습한다.
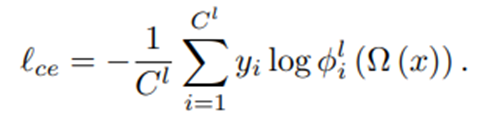
-
그리고 cluster discovery step에서 unsupervised learning을 통하여 classifier를 학습한다. 자세한 방법은 다음과 같다.
-
우선 두 sample에 대한 representation 값의 cosine similarity를 계산한다.
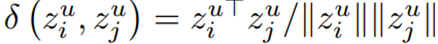
-
그 후, 위에서 계산한 cosine similarity가 일정 lambda보다 크면 1의 pseudo label을 가지고 그렇지 않으면 0의 pseudo label을 가지게 한다. 그리고 각 sample의 representation을 Φu에 통과시켜 얻은 값에 inner product를 취하여 P 값을 얻는다.
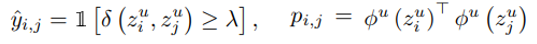
-
위에서 얻은 값을 이용하여 아래 bce loss를 계산하여 Φu를 훈련시킨다..
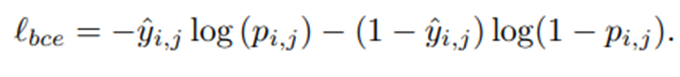
-
-
그리고 앞서 설명한대로 network가 image xi와 correlated view x^i에 대하여 비슷한 prediction을 생산하도록 consistency loss를 사용한다.
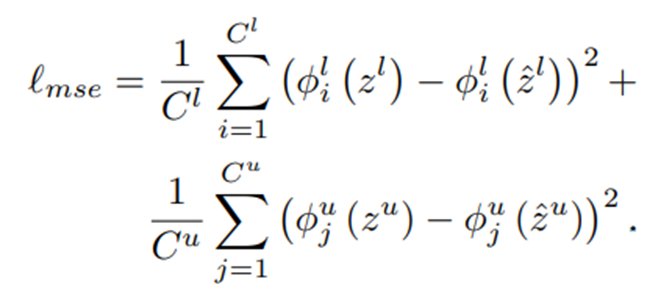
-
정리하자면, Novel Class Discovery의 Baseline loss는 아래와 같다.
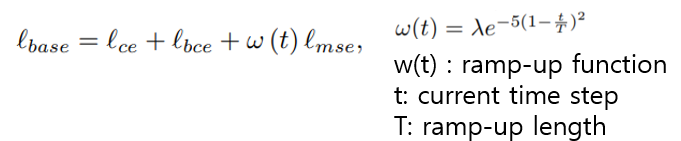
Neighborhood Contrasitve Learning
- 다음으로 이 논문에서 제안하는 Neighborhood Contrasitve Learning에 대한 설명이다.
- 우선 stochastic image transformation을 거쳐 생성한 두 correlated view
(xu, x^u)를 positive pair로 사용한다.
- 또한 이전 training step에서 얻은 feature를 queue Mu에 저장한다. 그리고 nagetive set z-u로 사용한다.
-
그리고 다음과 같은 loss를 계산할 수 있다.
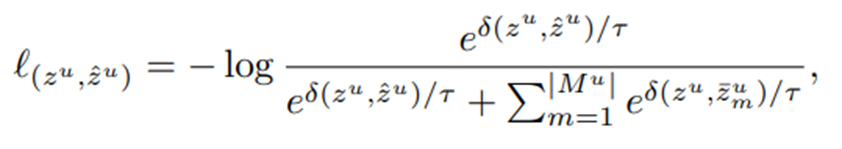
-
그렇지만 위의 loss를 사용하게 되면, contrastive learning의 약점인 같은 class가 negative로 잘못 분류되는 문제(false negative)가 발생할 수 있다.
-
이를 해결하기 위하여 이 논문에서는 representation zu의 neighbor를 같은 class instance로 사용하였다고 한다.
-
구체적으로 보자면 다음과 같다.
- 우선 pretrained된 network Ω가 주어졌을 때, query zu과 가장 유사한 topk개의 feature를 뽑을 수 있다.
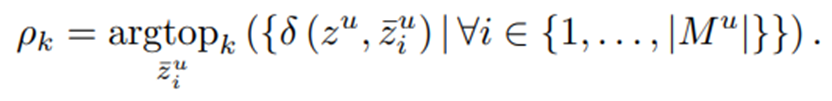
- 위에서 얻은 ρk를 false-negative로 가정하여, 이 논문에서는 ρk를 pseudo-positive로 사용하여 다음 loss를 계산한다.
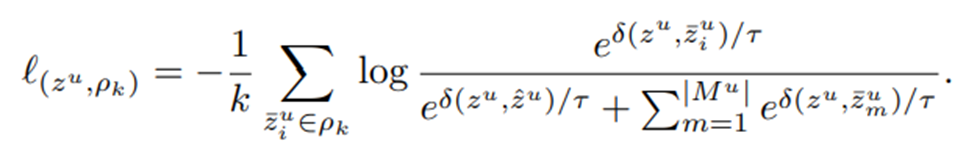
- 그리고 최종적으로 앞서 구한 positive pair 관련 loss와 여기서 구한 pseudo positive 관련 loss를 일정 비율 섞어 ncl loss로 사용한다.
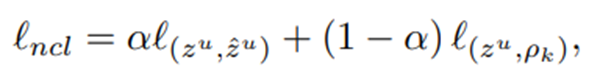
- 우선 pretrained된 network Ω가 주어졌을 때, query zu과 가장 유사한 topk개의 feature를 뽑을 수 있다.
Supervised Contrastive Learning
-
Novel Class Discovery task에서는 labeled dataset이 주어지기 때문에 ground truth label을 이용할 수 있다.
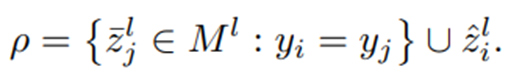
-
supervision을 이용하여 아래처럼 Supervised Contrastive Loss를 구할 수 있다. (같은 class에 속하면 positive pair, 다른 class에 속하면 negative pair)
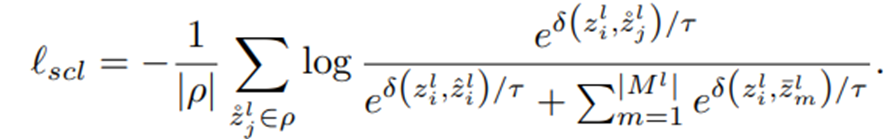
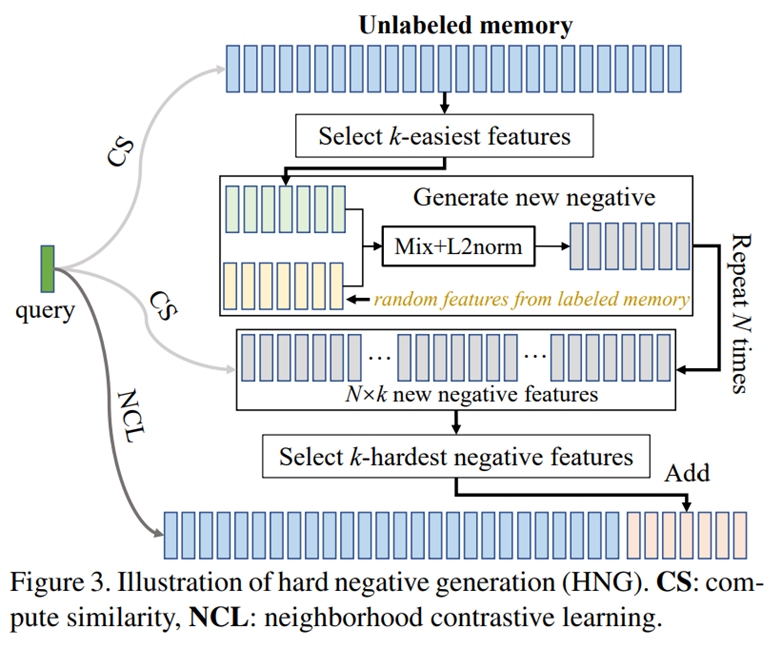
Hard Negative Generation
-
이 논문에서는 앞서 나온 queue에서 easiest negatives를 제거하는 것이 performance에 큰 영향이 없다는 것을 발견하였다고 한다.
-
그리고 NCD task에서 labeled set과 unlabeled set의 class들이 disjoint하다고 가정할 수 있다. (task의 특성) 이는 즉, labeled set과 unlabeled set들이 서로 negative로 사용될 수 있음을 의미한다.
-
이러한 가정 하에, 이 논문에서는 hard negative sample generation을 통해 추가적인 성능개선을 이루고 있다.
-
우선 다음과 같이 unlabeled dataset에서 anchor sample zu와 가장 유사하지 않은 sample을 찾는다.
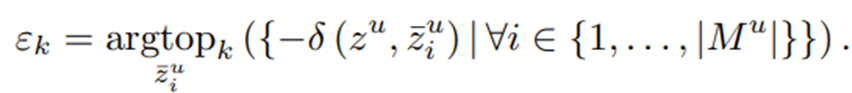
-
그래서 찾은 sample들을 easiest sample로 두고 이 sample들에 random으로 뽑은 labeled sample을 섞어 (mixture) negative sample을 만든다.
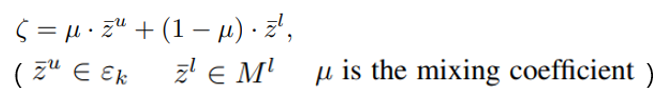
-
그렇게 만든 negative 중에서 anchor sample zu와 가장 유사한 sample을 찾는다. (유사할수록 model의 입장에서 어려운 sample이기 때문에)
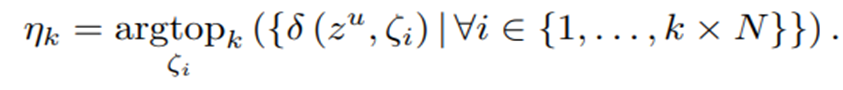
-
이러한 과정을 통하여 얻은 set ηk는 true negative일 확률이 높고, network가 query로부터 구분하기 힘들다는 property를 가진다고 한다.
-
그래서 최종적으로 위에서 얻은 ηk를 앞서 나온 queue Mu에 섞어 negative set으로 사용하게 된다.
Overall Loss
- 그래서 이 논문에서 제안하는 최종 loss는 다음과 같다.
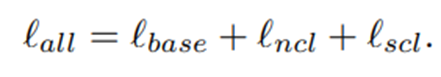
(baseline model + neighborhood contrastive learning on unlabeled data + supervised contrastive learning on labeled data)
(+ hard negative generation on unlabeled data)
Experiments
-
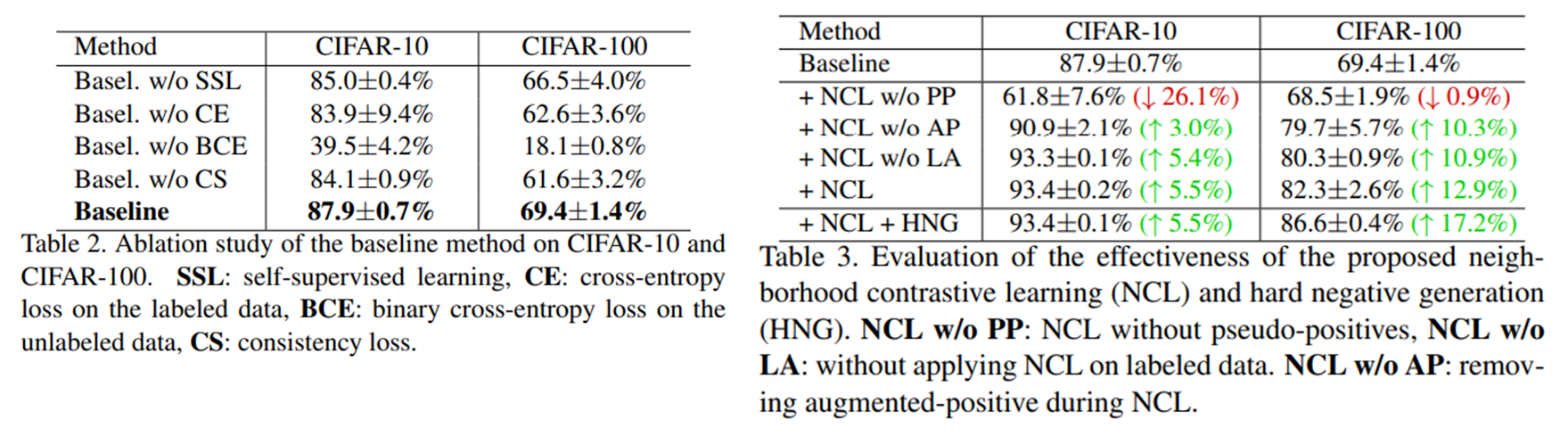
ablation study를 통해 각 구성요소의 중요성을 보이고 있다.
-
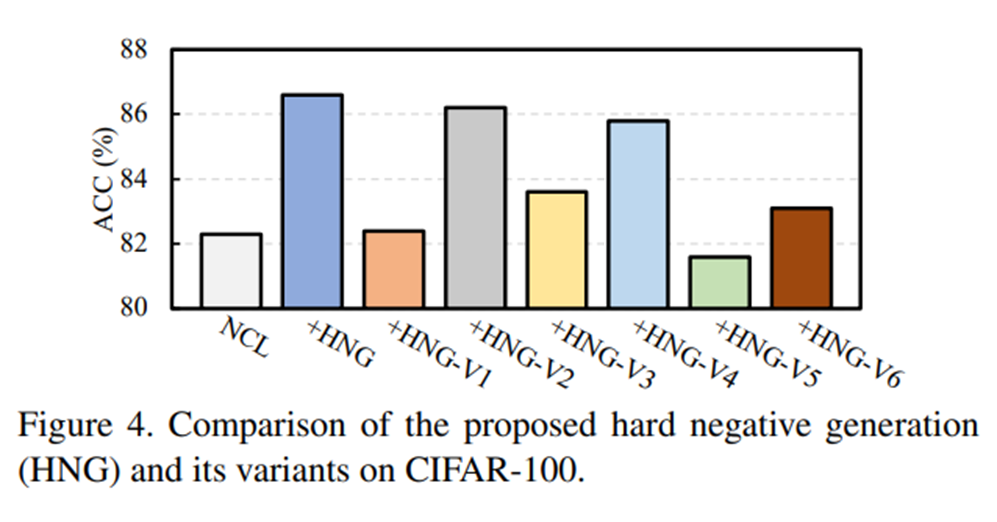
hard negative generation에서 option을 바꾼 후, accuracy에 대하여 비교하고 있다.

-
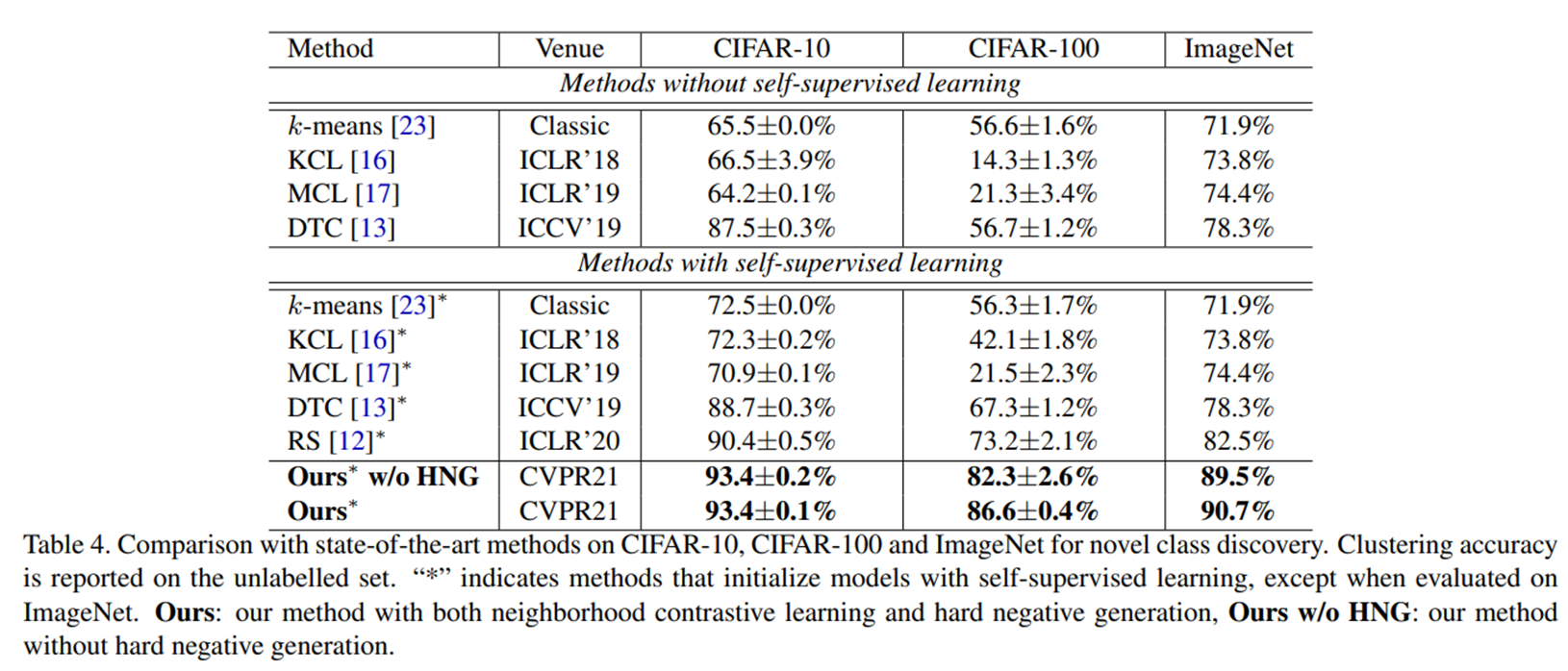
여러 task에서 state-of-the-art보다 좋은 성능을 보여주고 있다.
- cifar10에서의 t-sne를 통하여 제안하는 model을 사용하였을 경우, 분포가 더 동그랗게 뭉치는 모습을 보여주고 있다. 이러한 이유를 논문에서는 model이 representation의 neighbor들을 주변에 위치하도록 강제하기 때문이라고 말하고 있다.

Conclusion
-
이 논문에서는, Novel Class Discovery task에 대하여 contrastive learning을 도입하여 전반적인 learning framework를 제안하고 있다.
-
embedding space의 local neighborhood를 효과적으로 사용하기 위하여 Neighborhood Contrastive Learning을 제안하고 있다.
(더 많은 positive sample으로부터 knowledge를 얻고 그에 따라 cluster accuracy를 향상시킬 수 있음) -
또한 Hard Negative Generation을 도입하여 추가적인 성능개선을 이루었다.
