
🔖 목차
- Product Category
- Olive Young Review Page
- Data Features
- Crawling
- Data Frame
1. Product Category

- 올리브영의 제품 전체를 분석하는 것은 시간적 제약으로 어려움이 있어 특정 카테고리로 범위를 좁혀 진행
- 범용성이 있고 다양한 속성(화장품의 특성)을 분석할 수 있는 스킨케어 제품군으로 선정
- 스킨케어 제품군의 전체 카테고리(토너/로션/올인원/에센스/크림/미스트/오일) 크롤링 진행
2. Olive Young Review Page
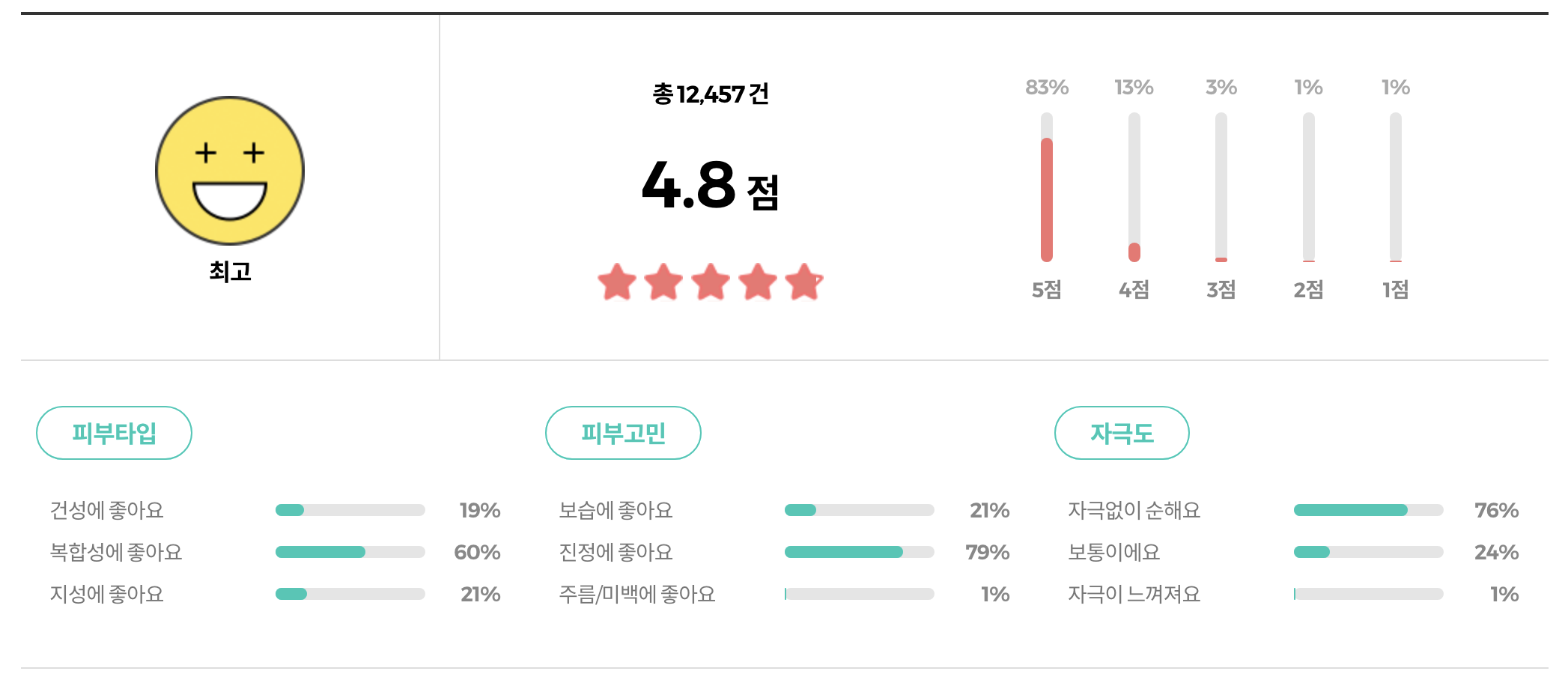
- 평점과 같은 수치 자료와 피부타입, 피부고민, 자극도 등의 설문에 대한 결과가 시각화되어 있다.
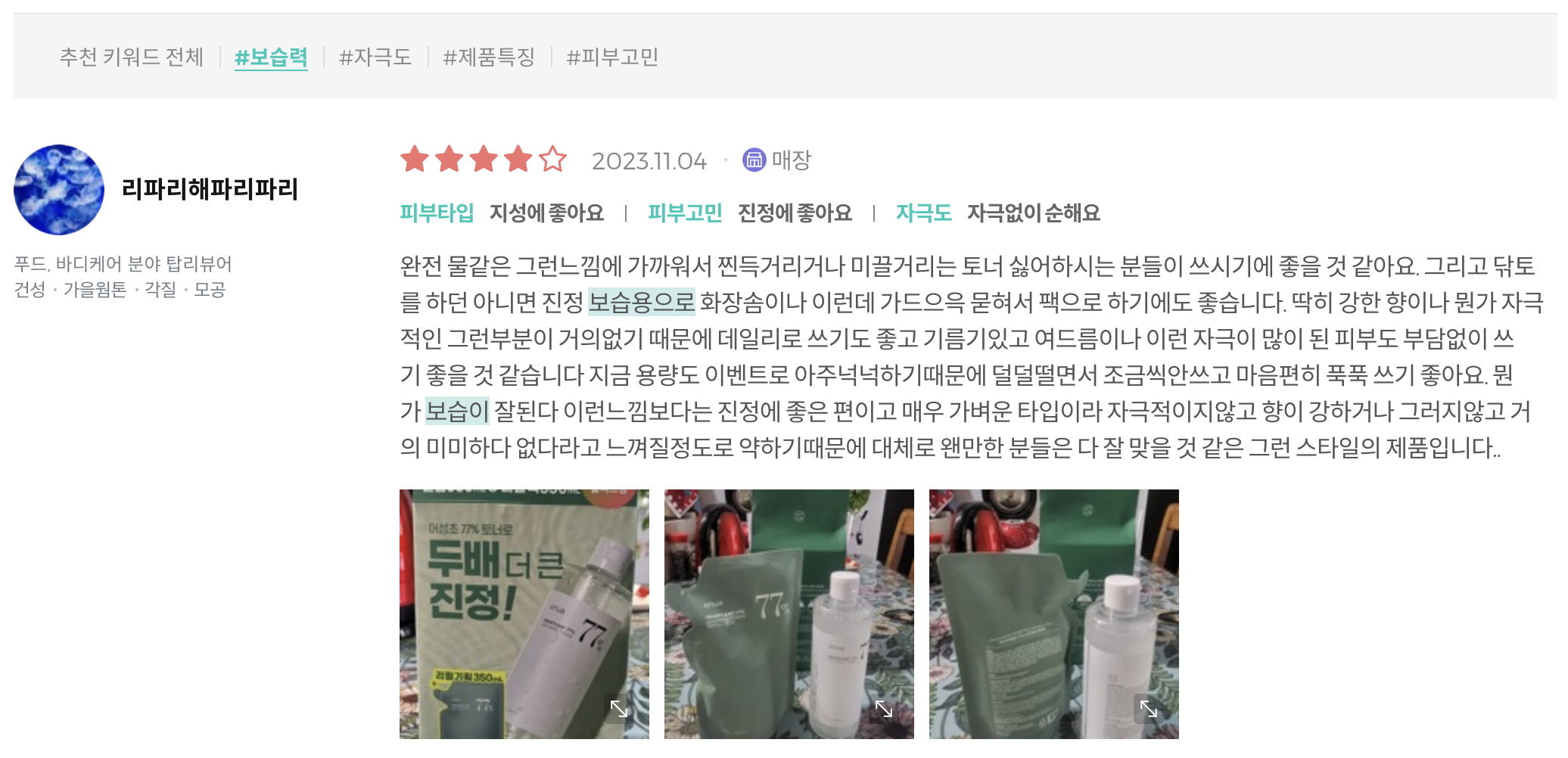
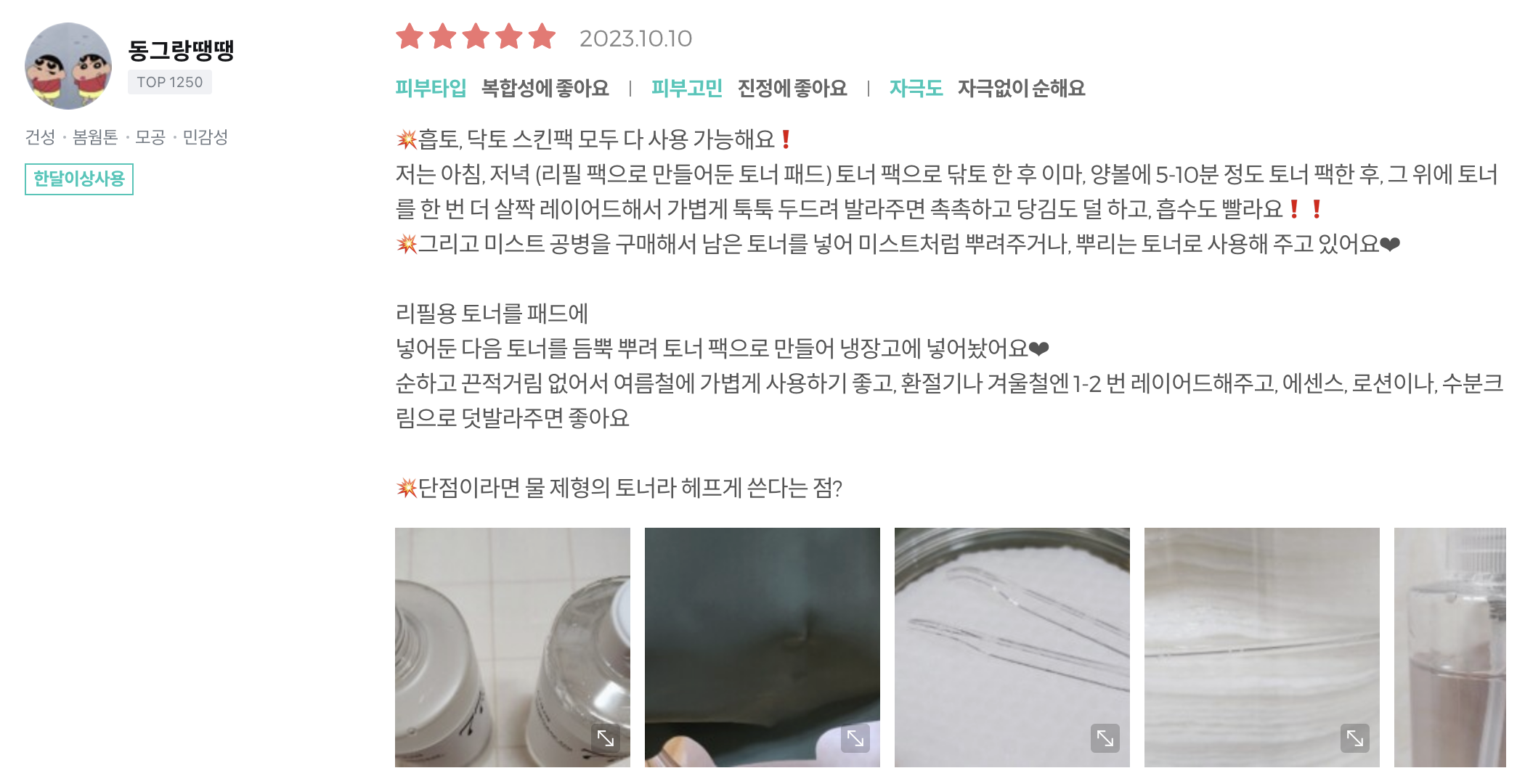
- 리뷰 텍스트를 활용해서 추천 키워드 필터가 적용된 것을 확인할 수 있다.
- 리뷰에 대한 보다 심층적인 화장품 속성에 대한 감성 분석을 수행하여 리뷰 페이지 개선 및 마케팅 인사이트를 도출하는 프로젝트를 수행할 계획
3. Data Features
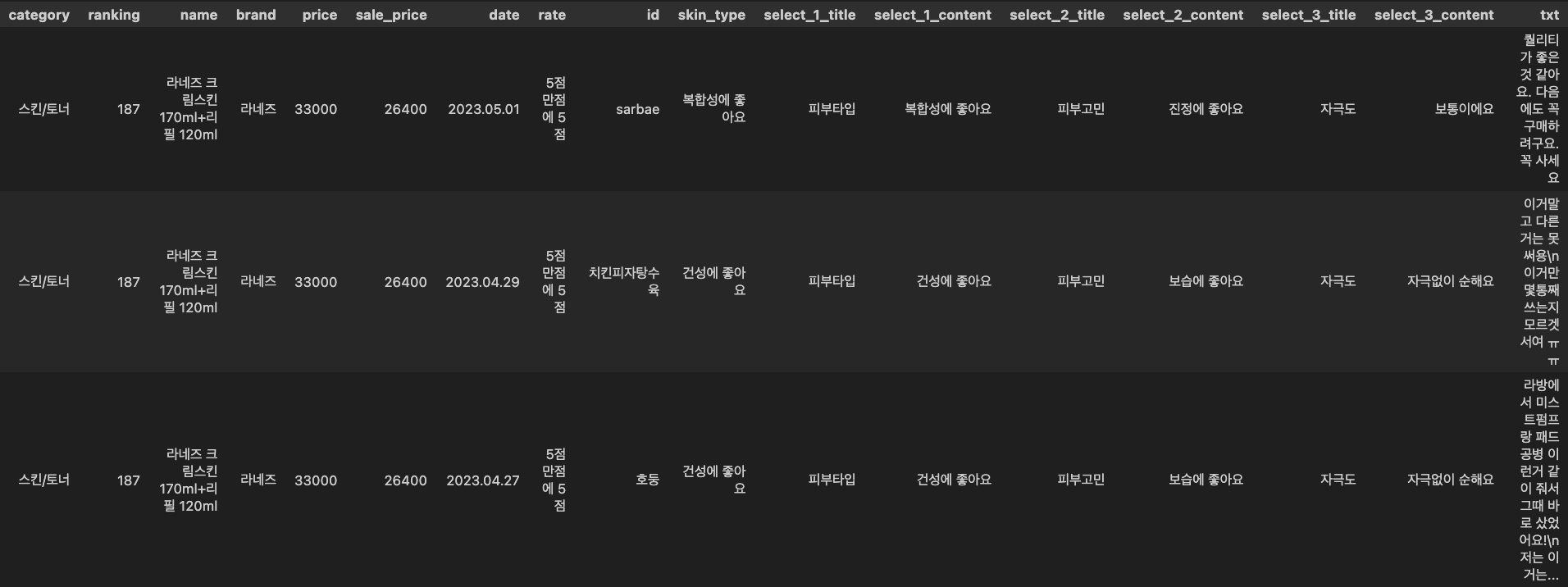
[제품 정보]
- category: 카테고리
- ranking: 순위
- name: 제품명
- brand: 제품 브랜드
- price: 정가
- sale_price: 할인가
[리뷰 정보]
- ID: 작성자 아이디
- date: 작성 일자
- rate: 평점
- skin_type: 제품 권장 피부타입
- select1_title: 피부타입
select_1_content: 지성에 좋아요, 복합성에 좋아요, 건성에 좋아요- select_2_title: 피부고민 or 세정력
- select_2_content: 진정에 좋아요, 보습에 좋아요, 주름/미백에 좋아요, 아주 만족해요, 보통이에요
- select_3_title: 자극도
- select_3_content: 자극없이 순해요, 보통이에요, 자극이 느껴져요
- txt: 리뷰 텍스트
*_select는 올리브영 리뷰 작성 시 선택하는 설문항목으로 제품 혹은 카테고리 별로 설문 내용에 차이가 있음
4. Crawling
- 크롤링을 한꺼번에 진행하는 것은 시간이 너무 많이 소요되어 카테고리 별로 세분화하여 진행
- 상품 수가 너무 많은 카테고리의 경우 파트를 나눠서 크롤링 병렬적으로 수행
import time
from tqdm import tqdm_notebook
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.oliveyoung.co.kr/store/display/getCategoryShop.do?dispCatNo=10000010001&gateCd=Drawer&t_page=%EB%93%9C%EB%A1%9C%EC%9A%B0_%EC%B9%B4%ED%85%8C%EA%B3%A0%EB%A6%AC&t_click=%EC%B9%B4%ED%85%8C%EA%B3%A0%EB%A6%AC%ED%83%AD_%EB%8C%80%EC%B9%B4%ED%85%8C%EA%B3%A0%EB%A6%AC&t_1st_category_type=%EB%8C%80_%EC%8A%A4%ED%82%A8%EC%BC%80%EC%96%B4"
driver = webdriver.Chrome("../driver/chromedriver")
driver.get(url)
# 데이터 프레임 생성
df_review_cos1 = pd.DataFrame(columns=['category', 'ranking', 'name', 'brand', 'price', 'sale_price', 'date', 'rate', 'id', 'skin_type', 'select_1_title', 'select_1_content', 'select_2_title', 'select_2_content', 'select_3_title', 'select_3_content', 'txt'])
df_review_cos1
# 상품 리뷰 크롤링 함수
def review_crawling(df, page_num):
for current_page in range(1, page_num):
# 리뷰의 인덱스는 한 페이지 내에서 1~10까지 존재
for i in range(1, 10): # 한 페이지 내 10개 리뷰 크롤링
try:
date = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.score_area > span.date').text
rate = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.score_area > span.review_point > span').text
id = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.info > div > p.info_user > a.id').text
skin_type = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(1) > dd > span').text
select_1_title = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(1) > dt > span').text
select_1_content = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(1) > dd > span').text
select_2_title = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(2) > dt > span').text
select_2_content = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(2) > dd > span').text
select_3_title = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(3) > dt > span').text
select_3_content = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.poll_sample > dl:nth-child(3) > dd > span').text
txt = driver.find_element(By.CSS_SELECTOR, f'#gdasList > li:nth-child({i}) > div.review_cont > div.txt_inner').text
df.loc[len(df)] = [category, ranking, name, brand, price, sale_price, date, rate, id, skin_type, select_1_title, select_1_content, select_2_title, select_2_content, select_3_title, select_3_content, txt]
except:
pass
try:
if current_page % 10 != 0: # 현재 페이지가 10의 배수가 아닐 때
if current_page // 10 < 1: # 페이지 수가 한 자리수 일 때
# 리뷰 10개 긁으면 next 버튼 클릭
page_button = driver.find_element(By.CSS_SELECTOR, f'#gdasContentsArea > div > div.pageing > a:nth-child({current_page%10+1})')
page_button.click()
time.sleep(2)
else: # 페이지 수가 두자리 수 이상일 때
# 리뷰 10개 긁으면 next 버튼 클릭
page_button = driver.find_element(By.CSS_SELECTOR, f'#gdasContentsArea > div > div.pageing > a:nth-child({current_page%10+2})')
page_button.click()
time.sleep(2)
else:
next_button = driver.find_element(By.CSS_SELECTOR, '#gdasContentsArea > div > div.pageing > a.next')
next_button.click() # 현재 페이지가 10의 배수일 때 페이지 넘김 버튼 클릭
time.sleep(2)
except:
pass
print(f'{current_page}페이지 크롤링 완료')5. Data Frame
- 약 30만건의 리뷰 데이터 크롤링 완료

머신러닝 딥러닝 학습기록
안녕하세요. 마케팅 계열 학생인데요. 똑같은 코드로 url만 바꾸어서 올리브영 썬케어 제품 리뷰를 크롤링해보려고 하는데, 코드 실행이 안되네요. ㅠㅠ
페이지 대기시간을 늘려보고,
셀레니움 관련 파라미터가 바뀌어서 그걸 수정해보긴 했습니다만, 그래도 빈 데이터 프레임이 나옵니다.
다른 것을 건들여야 할까요?
CSS 문법이 바뀐걸까요??