앞서 이론적으로 공부한 RNN/LSTM을 Pytorch를 통해 작성하여
이더리움 가격 그래프를 분석하고 Ethereum의 가격을 예측하는 실습을 진행했다.
김훈 교수님의 기초 딥러닝 강의를 통해 앞선 포스트에 추가적으로 이론적인 내용을 학습했다.
LSTM을 이용한 이더리움 분석
몇일 연속의 데이터를 이용하여 다음 날의 가격을 예측하는 것은 Many-To-One 방식이다.
물론 다음 날 하루가 아닌 미래의 연속된 몇 일의 가격을 예측하는 것은 Many-To-Many가 될 것이다.
기본적인 코드의 흐름은 아래와 같다.
Data Preprocessing
- 데이터 불러오기
1.a Train/Test dataset 분할, 불러온 데이터를 split하여 생성 - Data Scaling
2.a 사이킷 런의 minmaxscaler 또는 standardscaler를 활용하거나 직접 함수를 작성할 수 있다. - Datase을 Tensor 형태로 변환한다.
3.a GPU를 사용할 것인지 CPU를 사용할 것인지에 따라 형태를 결정한다.
LSTM 설계
- Python Class로 torch.nn.Module을 상속한다.
- init함수로 필요한 내용을 초기화하고 forward 함수로 순전파 진행
Training and Test, Evaluation
- 학습 함수 작성
- 모델 가중치 또는 모델 저장
- 검증 및 시각화
Code Review
코드 리뷰에 앞서 딥러닝 학습 과정 및 용어에 대한 복기를 수행한다.
학습의 과정
- 임의의 가중치 설정
- 선택된 가중치로 손실 값 계산, 손실 함수의 Gradient 계산
- 계산된 Gradient와 설정한 Learning Rate를 이용해 다음 가중치로 이동하고 파라미터를 업데이트. 이동 거리는 경사 하강법을 통해 구함
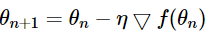
- 이동 지점에서 손실 함수의 Gradient 계산, 3번의 과정 반복
- 손실 함수가 Minima(이 때, Local minima에 도달할 수도 있음)에 도달하면 중지
Epoch, Batch size, iteration
빅데이터를 사용하는 경우에 모든 샘플 학습을 한 번에 진행하게 되면 메모리 사용량이 너무 높아지고, 계산 시간이 상당 소요된다.
따라서 샘플을 나누어 학습을 해야 하고 이 때 위와 같은 용어들을 사용한다.
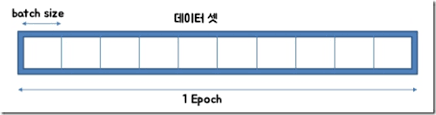 [출처] https://www.slideshare.net/w0ong/ss-82372826
[출처] https://www.slideshare.net/w0ong/ss-82372826
1 Epoch = 전체 데이터 셋을 한 번 학습하는 것을 의미한다, 전체 데이터 셋이 하나의 모델에서 Forwarding, Backwarding을 한 번 수행한 것
Epoch을 높이게 되면 여러 무작위 가중치를 통해서 학습을 수행하기 때문에 적절한 값을 찾을 확률이 높아진다. 하지만 지나치게 높은 Epoch은 Overfitting의 원인이 된다.
Batch size = 데이터 셋을 쪼갤 크기를 의미한다.
Batch size가 너무 크면 한 번에 처리할 양이 많아지므로 속도가 느려지고 메모리가 부족하다.
Batch size가 너무 작으면 업데이트가 지나치게 자주 일어나 훈련이 불안정해진다.
Iteration = 하나의 minibatch를 학습하는 것을 의미한다.
각 batch마다 파라미터 업데이트가 이루어지기 때문에 iteration은 파라미터 업데이트 횟수이자 전체 데이터의 총 배치의 수가 된다.
Code Review
- Initialization

필요한 라이브러리를 추가하고 모델과 데이터 셋을 생성하여 학습하는 데 필요한 파라미터들을 초기화한다.
- Data Preprocessing



판다스를 이용해서 데이터 셋을 읽어 온 뒤 필요한 Feature만 사용한다. 위에서는 읽어오는 방식을 사용했는데 drop을 이용해서 필요 없는 Feature를 제거하는 방식도 가능하다.미리 만들어 둔 build_dataset을 통해서 sequence 데이터의 형태로 학습 데이터를 생성한다.학습에 사용하기 위해 scaling을 진행 한 뒤에 tensor의 형태로 변형한다. 이 때 사용하는 디바이스가 cpu냐 gpu냐에 따라서 데이터를 변형한다.
- LSTM 설계

python class로 LSTM model을 설계, pytorch의 nn의 Module을 상속함forward 함수와 init이 핵심이고 reset_hidden_state는 은닉층을 초기화하기 위해서 추가한 함수
- Training/Test

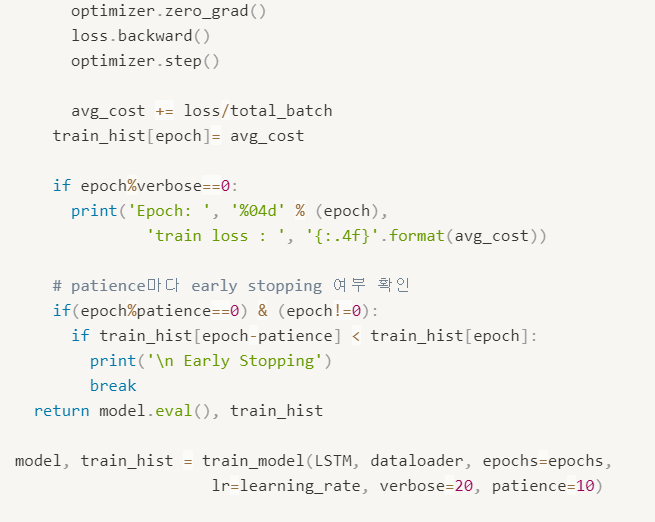

training function, 손실함수를 계산하고 손실함수를 최적화하는 방향으로 학습, zero_grad 함수가 중요한 데 의미를 더 정확히 파악해야겠음Early stopping을 통해서 학습을 더 효율적으로 하려고 함evaluation을 통해서 학습을 잘했는 지 확인, 이후 시각화 코드를 작성하여 확인했음마지막 7개의 값을 통해서 마지막 날의 다음 날 주가를 예측해보았음.
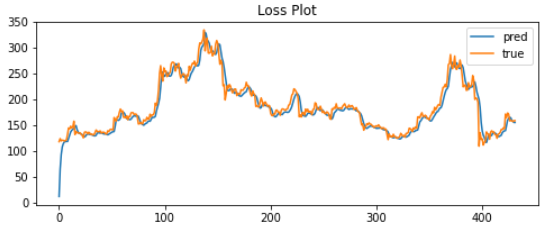
Result
예측 그래프와 실제 그래프의 차이를 확인할 수 있고 그 아래는 마지막 날의 다음 날 이더리움 가격을 예측한 결과이다.
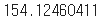
데이터 셋은
Kaggle, Ethereum dataset을 이용했다.
