#Pandas 데이터 처리
#머신러닝
#거친코딩
#"파이썬 기초 라이브러리부터 쌓아가는 머신러닝"
DataFrame의 데이터를 집계 및 요약
데이터에 대한 해석
아래의 데이터를 가지고 학습을 진행한다.

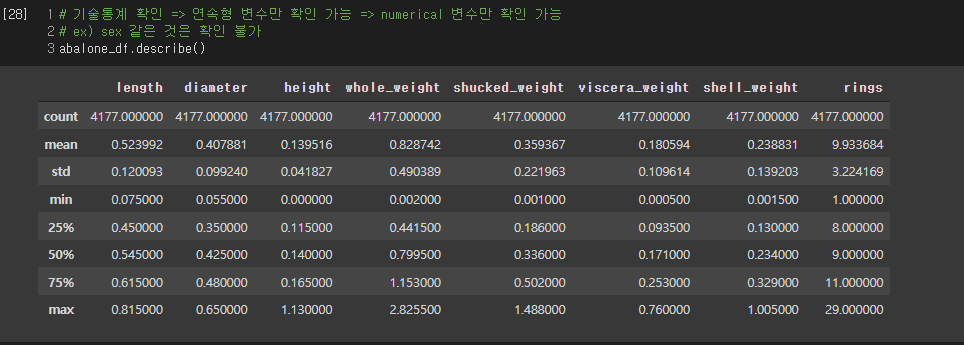
주어진 데이터를 내가 분석하고자 하는 대상을 기준으로 그룹을 지어줄 수 있다.
아래의 예시는 전복의 성별에 따른 총 몸무게를 분석한 결과이다.

이 때, 그룹을 지을 변수를 1 개보다 더 많이 잡을 수 도 있다.
DataFrame은 duplicated 함수를 통해서 중복되는 데이터를 확인할 수 있고 drop_duplicates() 를 통해서 이를 제거할 수 있다.
keep='last' 라는 option을 사용하면 나중에 나온 Row를 남겨둘 수 있다.


데이터 해석을 바탕으로 결측치 채우기
결측치는 보통 nan 으로 표현된다. (np.nan임)
기존 데이터에 결측치의 수는 아래와 같이 계산할 수 있다.
이는 열에 상관없이 총 결측치의 수를 반환했다.
.sum() 을 한 번 사용하면 각 열마다의 결측치 계산이 가능하다.

결측치는 데이터의 최빈 값, 최댓 값, 중앙 값, 평균 값 등등 의미있는 데이터로 채워넣을 수 있다.
Categorical한 값은 평균으로 채울 수 없기 때문에 아래에서는 최빈 값으로 대체했다.

데이터 프레임의 꽃 "apply" 함수
apply 함수를 통해서 본인이 원하는 행과 열에 파이썬에 정의된 연산 혹은 사용자 정의 함수를 적용할 수 있다.

이렇게 작성된 데이터를 재가공해서 새로운 데이터를 만들어낼 수 있고
그 데이터를 다시 데이터 프레임에 삽입하여 새로운 데이터 프레임을 생성할 수 있다.

나는 복잡하게 데이터프레임에 붙히는 방식으로 작성했는데 ablaone_df['answer']=abalone_sum 처럼 훨씬 간단하게 가능하다.

Whiplash We Flash