강노에 그림이 많으니 참조하면서 읽기.
chapter 2
Internet -> TCP/IP 라는 통신 프로토콜로 연결된 컴퓨터 네트워크
ISO(International Standards Organization) 이 네트워크 연결의 기준으로 만든 것이
OSI(Open Systems Interconnection) model
OSI model
7 layers -> module(분업화)
layer 7 -> Application
layer 6 -> Presentation
layer 5 -> Session
layer 4 -> Transport
layer 3 -> Network
layer 2 -> Data link
layer 1 -> Physical
TCP/IP Proctocol suite에서는 layer 7, 6, 5 를 통합해서 Application layer로 생각.
-> 그러므로 TCP/IP Protocol suite은 layer가 5개임.
참고(전달 방식)
Circuit Switching Network : 중앙제어 전달 방식
Packet Switching Network : 목적지 주소 전달 방식
목적지 주소 전달 방식이 현재의 인터넷에 해당한다.
분산 관리를 하고 (layers)
모든 데이터를 packet화 해서 전송한다 (layer를 header와 payload로 구분 -> 외부 글에서 따옴)
layers
Physical layer
unit of communication -> bit
Data link layer
unit of communication -> Frame
hop - to - hop delivery
Network layer
unit of communication -> Datagram
source - to - destination
Transport layer
unit of communication
TCP - segment
UDP - user datagram
or
Packet -> 통칭
process - to - process
Application layer
unit of communication -> Message
Addresses in the TCP/IP protocol suite
Application layer -> Application-specific addresses
Transport layer -> port addresses
transport layer는 application각각의 process에 전달하기 때문에 (process to process)
port address를 가진다.
-> port address is a 16-bit address represented by one decimal number ex) 753
Network layer -> Logical addresses
source to destination을 기반으로 IP(Logical address)를 가진다.
강의노트의 그림을 보면 변하지 않는 것을 알 수 있다.
Data link layer -> Physical addresses
hop to hop으로 전달하는 MAC(physical address)를 가진다.
hop to hop을 할 때마다 MAC은 바뀌고, IP는 바뀌지 않는 것을 볼 수 있다.
-> most local area networks use a 48-bit physical address written as 12 hexadecimal digits ex) 07:01:02:01:2C:4B
Ethernet implementation
Repeater
physical layer에서 작동.
신호가 너무 약해지기 전에 신호를 재생산.
중요한 점은 신호를 재생산 할때 증폭시키지 않는다는 점. 재생산 할때 신호를 비트단위로 복사하고 원래의 세기로 생산함.
Hub
multiport repeater로 생각하면 됨.
정보를 거를 수 없기 때문에 모든 연결된 장치로 정보를 보내며, 이로 인해 비효율성이 발생.
Bridge
data link layer에서 작동.
source와 destincation의 MAC address를 읽어 내용을 filtering할 기능을 가진 repeater이다.
같은 프로토콜에 있는 두개의 LANS를 상호연결하는데 사용하기도 한다.
Switch
Multi port bridge로 data link layer에서 작동.
데이터를 앞으로 보내기 전에 error checking을 하여 (filtering) error가 있는 packets을 보내지 않고, 옳은 port로만 보낸다.
실습 1
네트워크 프로그래밍
소켓을 기반으로 프로그래밍을 하기 때문에 소켓프로그래밍이라고 함.
네트워크로 연결된 둘 이상의 컴퓨터 사이에서의 데이터 송수신 프로그램의 작성을 의미.
소켓이란
네트워크 (인터넷) 의 연결 도구
운영체제에 의해 제공이 되는 소프트웨어적인 장치
소켓은 프로그래머에게 데이터 송수신에 대한 물리적, 소프트웨어적 세세한 내용을 신경 쓰지 않게 한다.
-> 우리가 짜는건 application layer의 소켓을 짜는것.
TCP 소켓은 전화기에 비유될 수 있다.
소켓은 socket함수의 호출을 통해 생성된다.
#include <sys/socket.h>
int socket(int domain, int type, int protocol)socket의 return은 file descripter? -> 확인
전화를 거는 용도의 소켓 (client) 와 전화를 수신하는 용도의 소켓 (server)의 생성 방법에는 차이가 있다.
소켓의 주소 할당 및 연결
전화기에 전화번호가 부여되듯이 소켓에도 주소정보가 할당된다.
소켓의 주소정보는 IP와 PORT번호로 구성이 된다.
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen);
//( 소켓 번호, 주소, )
// 성공시 0, 실패시 -1반환연결 요청이 가능한 상태의 소켓
연결 요청이 가능한 상태의 소켓은 걸려오는 전화를 받을 수 있는 상태에 비유할 수 있다.
전화를 거는 용도의 소켓은 연결요청이 가능한 상태의 소켓이 될 필요가 없다. 이는 걸려오는 전화를 받는 용도의 소켓에서 필요한 상태이다.
ex) 연결요청 가능한 상태로 변경 -> 내가 연결 요청하는게 아니라, 상대방이 연결요청 하는 것을.
#include <sys/socket.h>
int listen(int sockfd, int backlog);-> 일반소켓을 서버소켓으로 바꿈.
-> 일반 소켓은 전화를 거는것 밖에 안됨.
소켓에 할당된 IP와 PORT번호로 연결요청이 가능한 상태가 된다.
연결요청의 수락
걸려오는 전화에 대해서 수락의 의미로 수화기를 드는 것에 비유할 수 있음.
연결 요청이 수락되어야 데이터의 송수신 가능.
수락된 이후에 데이터의 송수신은 양방향으로 가능.
ex) 연결 요청 가능한 상태로 변경
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
// 성공시 파일 디스크립터(소켓), 실패시 -1 반환
// 이 리턴된 소켓에서 대화를 담당.연결요청을 허용하는 소켓의 생성과정 (server)
- 소켓의 생성 -> socket 함수 호출
- IP와 PORT 번호의 할당 -> bind 함수 호출
- 연결요청 가능상태로 변경 -> listen 함수 호출
- 연결요청에 대한 수락 -> accept 함수 호출
-> 이러면 파일 디스크립터라 불리는 소켓이 생성되고,
이렇게 생성된 소켓을 서버소켓 또는 리스닝 소켓이라 한다.
연결을 요청하는 소켓의 구현 (client)
전화를 거는 상황.
리스닝 소켓과 달리 구현의 과정이 매우 간단.
소켓의 생성과 연결의 요청으로 구분.
socket -> bind -> connect
ex) 연결의 요청
#include <sys/socket.h>
int connect(int sockfd, struct sockaddr *serv_addr, socklen_t addrlen);
(소켓 번호, 내가 접속할 상대방의 주소, )파일 열기와 닫기
file descriptor
0, 1, 2 는 이미 할당되어 있음.
file으로 descriptor가 생긴다면 3부터 생김.
open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcnt1.h>
int open(const char * path, int flag);
// 성공 시 파일 디스크립터, 실패시 -1 반환close
#include <unistd.h>
int close(int fd); //descriptor 값이 들어감.
// 성공 시 0, 실패 시 -1 반환open 함수 호출 시 반환된 파일 디스크립터를 이용해서 파일 입출력을 진행하게 된다.
파일에 데이터 쓰기
write
#include <unist.h>
ssize_t write(int fd, const void * buf, size_t nbyte);
// 데이터 전송 대상 파일 디스크립터, 전송할 데이터가 저장된 버퍼의 주소 값, 전송할 데이터의 바이트 수 전달.
// 성공 시 전달한 바이트 수, 실패 시 -1 반환파일에 저장된 데이터 읽기
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t nbytes);
// 데이터의 수신대상을 나타내는 파일 디스크립터, 수신할 데이터를 저장할 버퍼의 주소값, 수신할 최대 바이트 수 전달
// 성공 시 수신한 바이트 수(단 파일의 끝을 만나면 0), 실패 시 -1 반환프로토콜의 이해와 소켓의 생성
프로토콜
개념적으로 약속의 의미를 담고 있음.
컴퓨터 상호간의 데이터 송수신에 필요한 통신 규약
소켓을 생성할 때 기본적인 프로토콜을 지정해야 한다
int socket(int domain, int type, int protocol)
// domain -> 소켓이 사용할 프로토콜 체계 정보 전달. -> 이번학기에는 IPv4만 씀.
// type -> PF_INET의 TCP(SOCK_STREAM), UDP(SOCK_DGRAM)첫번째, 두번째 인자로 전달된 정보를 통해 소켓의 프로토콜이 사실상 결정되기 때문에 세 번째 인자로 0을 전달해도 된다.
두 타입의 소켓
연결지향형 소켓 (SOCK_STREAM)(TCP)
- 중간에 데이터 소멸되지 않는다. -> 소멸이 되도 TCP가 재전송 하기 때문에 소멸되지 않는 것 처럼 보인다.
- 전송 순서대로 데이터가 수신된다. -> 이것도 또한 어플리케이션 입장에서 보면 맞다. 전송중에 순서가 바뀔 수 있다.
- 데이터의 경계가 존재하지 않는다.
- 소켓 대 소켓의 연결은 반드시 1대 1의 구조
비 연결지향형 소켓 (SOCK_DGRAM)(UDP)
- 전송순서 상관없이 빠른 속도의 전송을 지향 -> 이거도 틀림.
- 데이터 손실 및 파손의 우려 있다. -> 이거도 어플리케이션 입장에서 봤을때만임.
- 데이터의 경계가 존재한다.
- 한번에 전송할 수 있는 데이터의 크기가 제한된다. -> 이거도 이상하다.
인터넷 주소
IP, PORT, MAC
실습때는 한 컴퓨터에 부여되는 번호가 IP라고 이해하면 됨.
PORT는 16비트로 표현.
0~1023dms Well-known port로 이미 용도가 결정되어 있음.
이이이이
bind에 첫번째 인자에 쓰이는 파일 디스크립터에 IP와 port를 할당해야한다. 거기에 할당하는 것이 구조체이다.
그 구조체 안에 IP와 PORT를 보내주어 할당한다.
IPv4 기반의 주소표현을 위한 구조체
struct sockaddr_in
{
sa_family_t sin_family; //주소체계 -> ip가 v4(AF_INET)인지 v6(AF_INET6)인지
uint16_t sin_port; // PORT번호
struct in_addr sin_addr; // 32비트 IP주소
char sin_zero[8]; // 사용되지 않음
}5 IP address
IP addresssms 32비트 정수.
IP주소가 껐다 키면 바뀜 -> 유동주소.
안바뀜 -> 고정주소
서버는 보통 고정 쓰고, 나머지는 대부분 유동 씀.
IP는 전세계에 딱 하나만 있어야됨. (unique) -> 예외가 있긴 함(loop back 주소 - 127.0.0.1 local에서 테스트 하기 위한거,
192.168~ - 공유기(사설망))
내부적으로는 32비트 숫자 하나지만, 읽고 쓰기의 용이성을 위해 8비트씩 나눔.
ip로 못쓰는 경우
111.56.045.78 -> 0으로 시작하면 안됨.
221.34.7.8.20 -> 점이 하나 더있음
75.45.301.14 -> 한칸에 맥스가 255임
110=100010.23.14.67 -> 형태 맞춰서 써줘야됨.
146.102.29.0 ~ 146.102.32.255 사이의 개수
0.0.3.255이다. 그러므로
11.11111111이므로 1023 + 1 -> 1024개 이다.
classful -> IP를 나눈거.
0
10
110
1110 -> multicast address
1111 -> reversed for future use
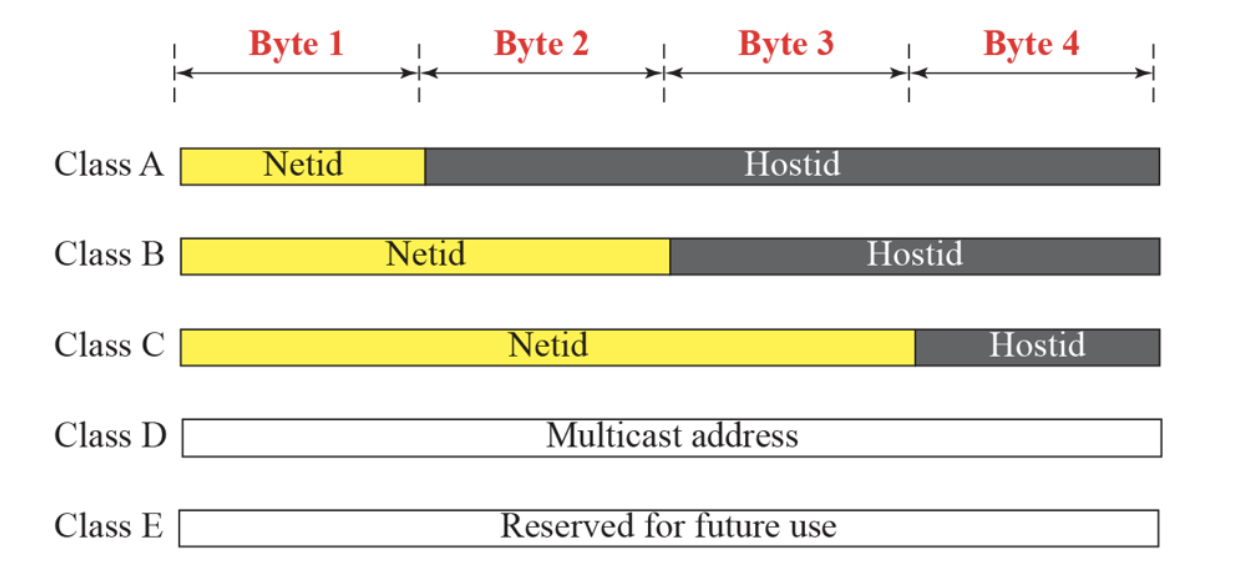
netid는 할당해주고, hostid는 맘대로 쓸 수 있게 함.
-> A, B 너무 많이 낭비됨.
but, routing이 앞을 보고 움직이기 떄문에 남아도 주지 못한다.
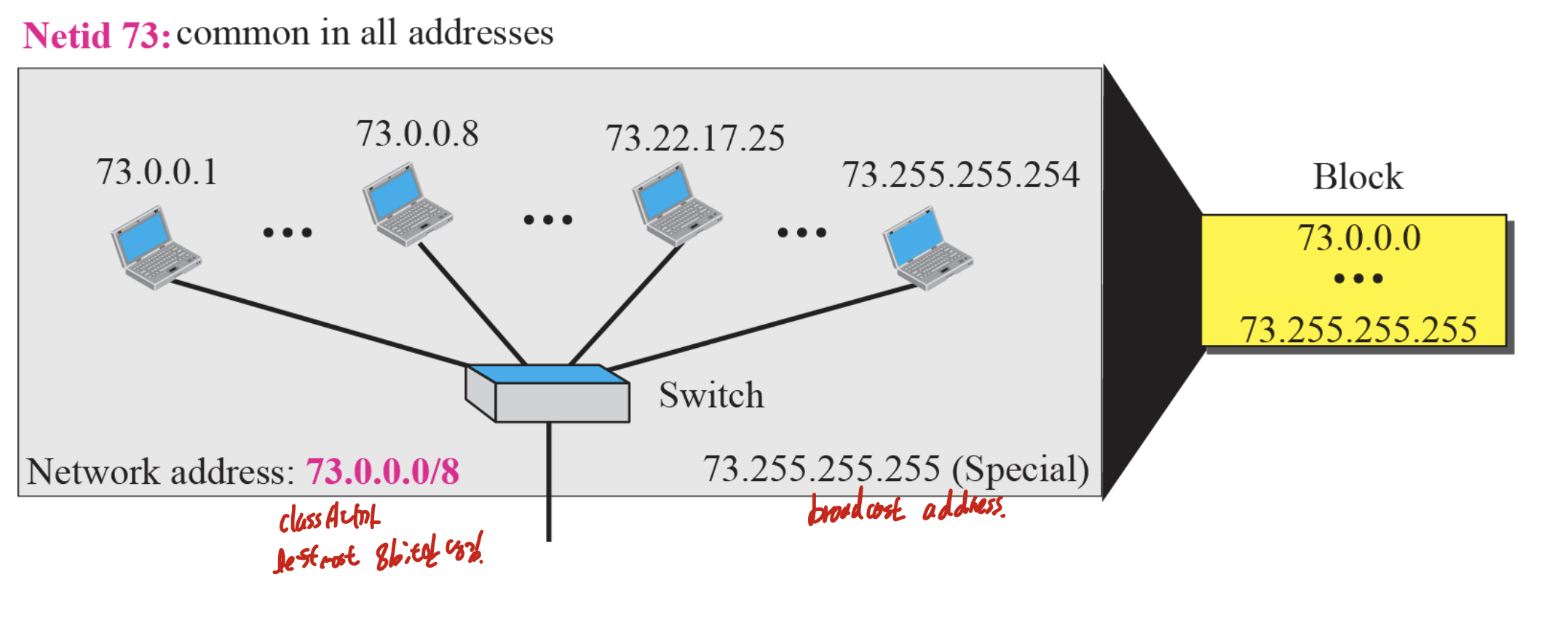
시작주소 -> netid 빼고 나머지 다 0 -> Network의 대표 번호
마지막주소 -> broadcast 주소
CH15. TCP 70p~
TCP timers
Retransmission
패킷 보내고, ack이 와야하는데 안오면 패킷 loss를 간주해야됨. 그러므로 retransmission timer를 켜서 체크.
Persistence
영속 타이머, deadlock 막기 위해 probe 보냄.
keepalive
client가 하드웨어적 문제가 생겼을때, 서버가 이걸 모르고 recv, send buffer 유지-> 2시간 기다리다 안오면 server가 probe 보냄.
Timewait
Fin, Fin ack, ack 주고 받고
2msl 기다리고 close

RTTs -> 평균.
처음 -> 아무값도 설정 안됨.
첫번째 측정 -> RTTs = RTTm
그 이후 -> RTTs = (1-a)RTTs + a * RTTm, a = 1/8

RTTd -> 편차.
RTTm -> 지금 측정된거.
처음 -> 아무값도 설정 안됨.
첫번째 측정 -> RTTd = RTTm/2
그 이후 -> RTTd = (1-b)RTTd + b|RTTs - RTTm|, b = 1/4

처음 -> 초기값
그 이후 -> RTO = RTTs + 4*RTTd

초기 RTO는 6.0이다.
그 후 1.5의 RTTm이 나왔으므로
RTTs = 1.5, RTTd = 0.75, RTO = 4.5이다.
syn은 다른거로 detect 못하고, timeout으로만 detect -> retransmission timer로 detect
packet을 보내면 측정을 한다.
그동안 다른 패킷을 ㅂ내지만, 첫번째로 보낸걸로 RTT, RTO 계산하면 다른거는 RTT 측정 X
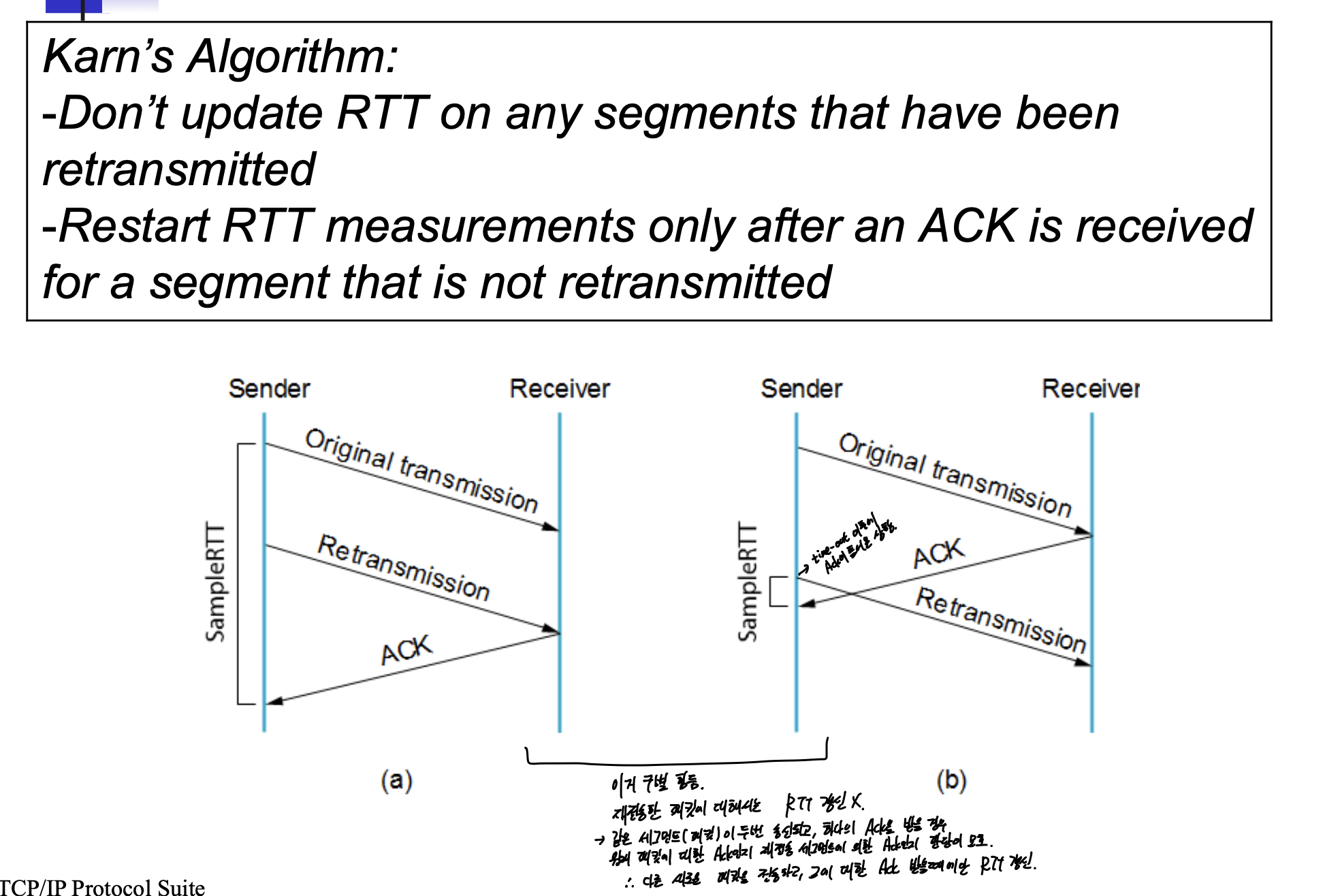
같은 패킷을 두번 전송하고 하나의 ACK을 받은 경우 원래 패킷에 대한 ACK인지 재전송 패킷에 의한 ACK인지 구별이 모호하다.
-> 재전송 한 패킷에 대해서는 RTT를 업데이트하지 않고, 다른 새로운 패킷을 보냈을때 업데이트 한다.
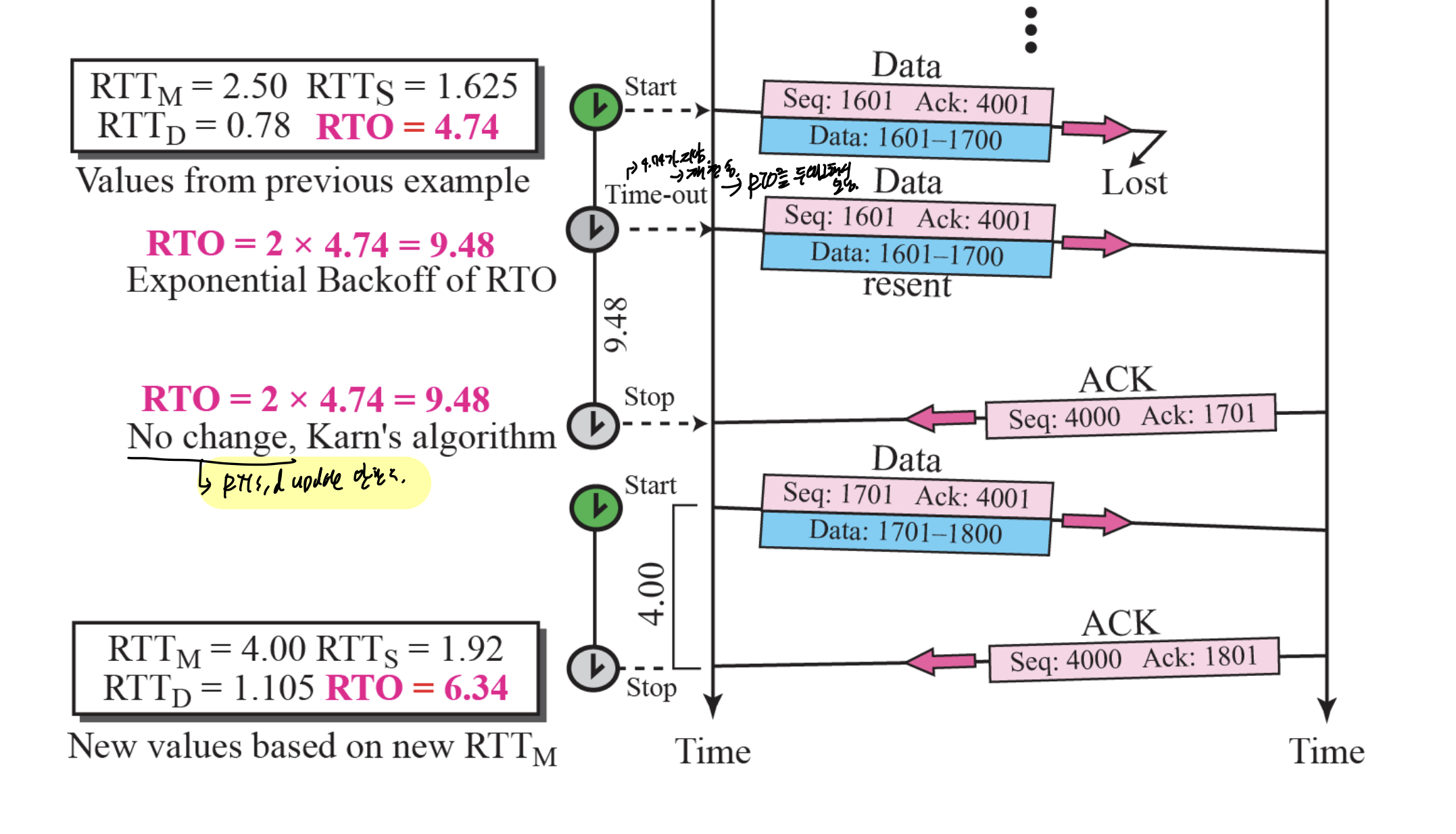
재전송할때는, RTO를 두배해서 보낸다. 시간이 부족해서 그럴수도 있으니까.
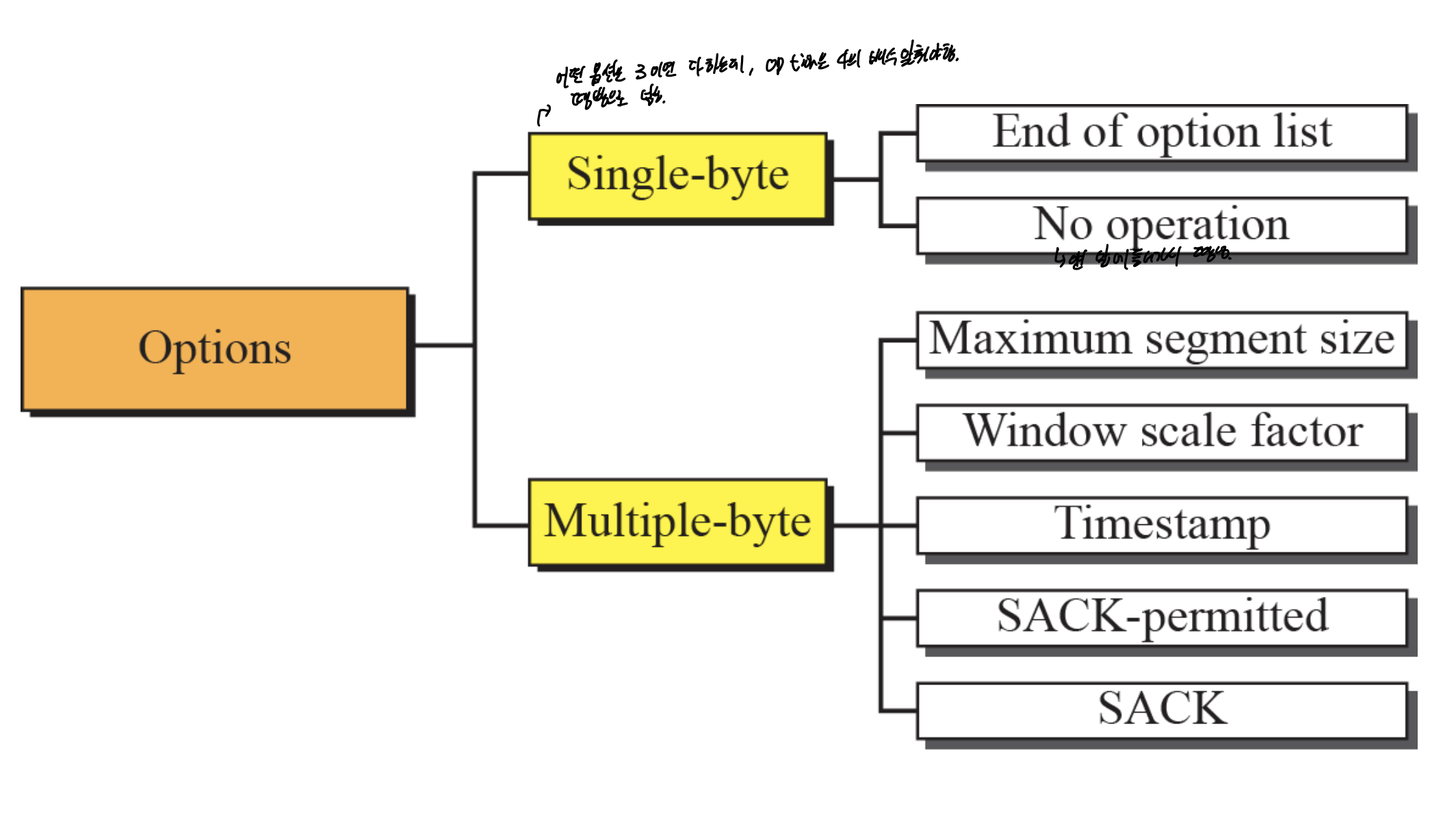

MSS : TCP data의 maximum
syn, syn ack, ack 요청할때
receiver가 sender에게 받고싶은 사이즈를 알려주는 옵션.
-> MSS는 setup 과정에서 설정됨.

window scale factor
window size때문에 문제가 생기는 경우를 방지해준다.
세팅과정에서 한다.
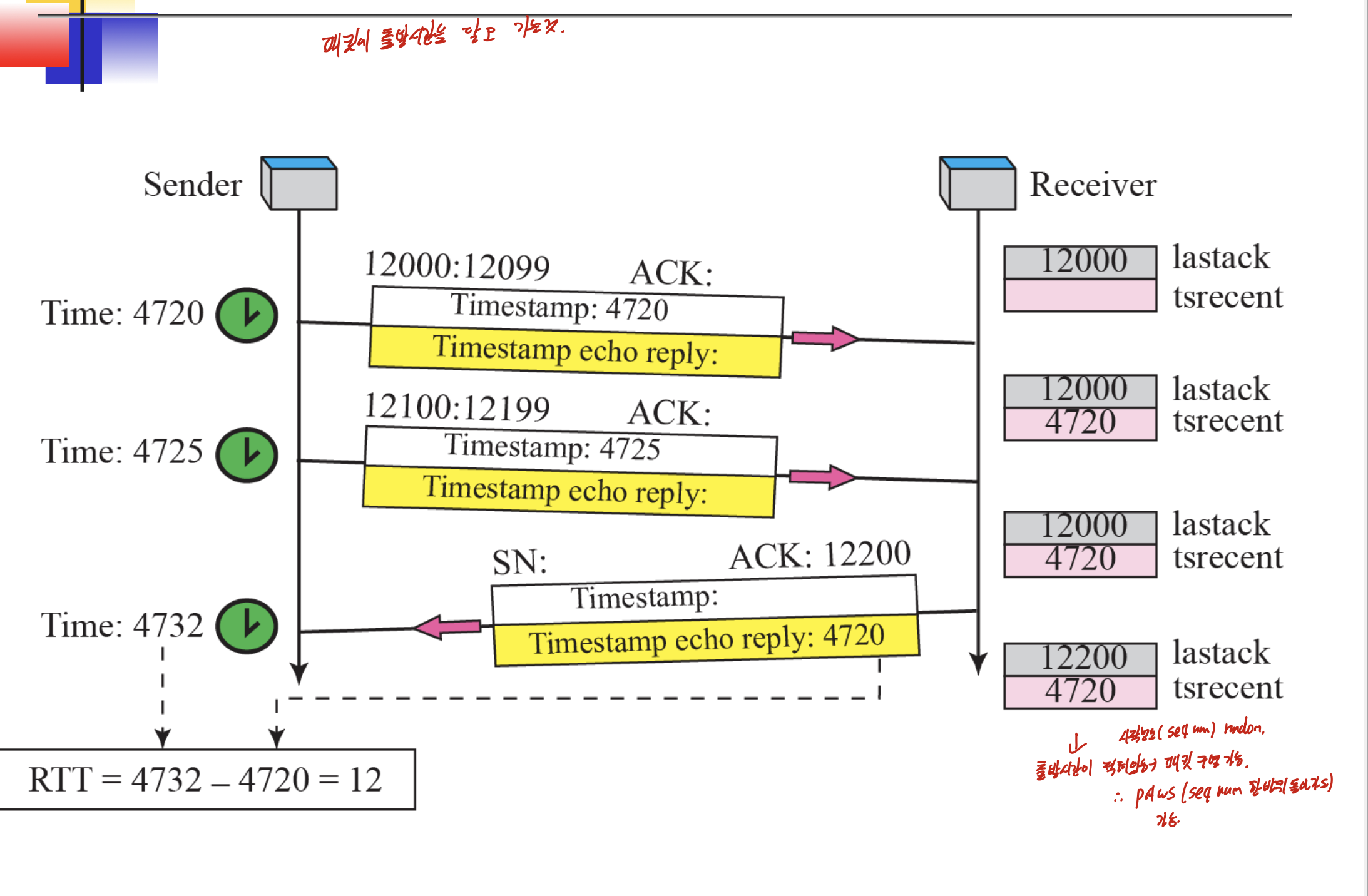
출발시간이 적혀있음 -> 패킷 구별 가능.
PAWS -> seqnum이 한바퀴돌아가도 구분 가능.
CH05. IP address
IP 안되는 조건

a. 0으로 시작하면 안됨.
b. 네개로 나뉘어야 함.
c. 8비트이므로 한칸에 255가 최대.
d. 단위통일
개수

256 + 256 + 256 + 256
1024개.
29.0 ~ 29.255 -> 256개
30.0 ~ 30.255 -> 256개
31.0 ~ 31.255 -> 256개
32.0 ~ 32.255 -> 256개

range 32 -> 0.31
-> 14.11.45.127
Classful
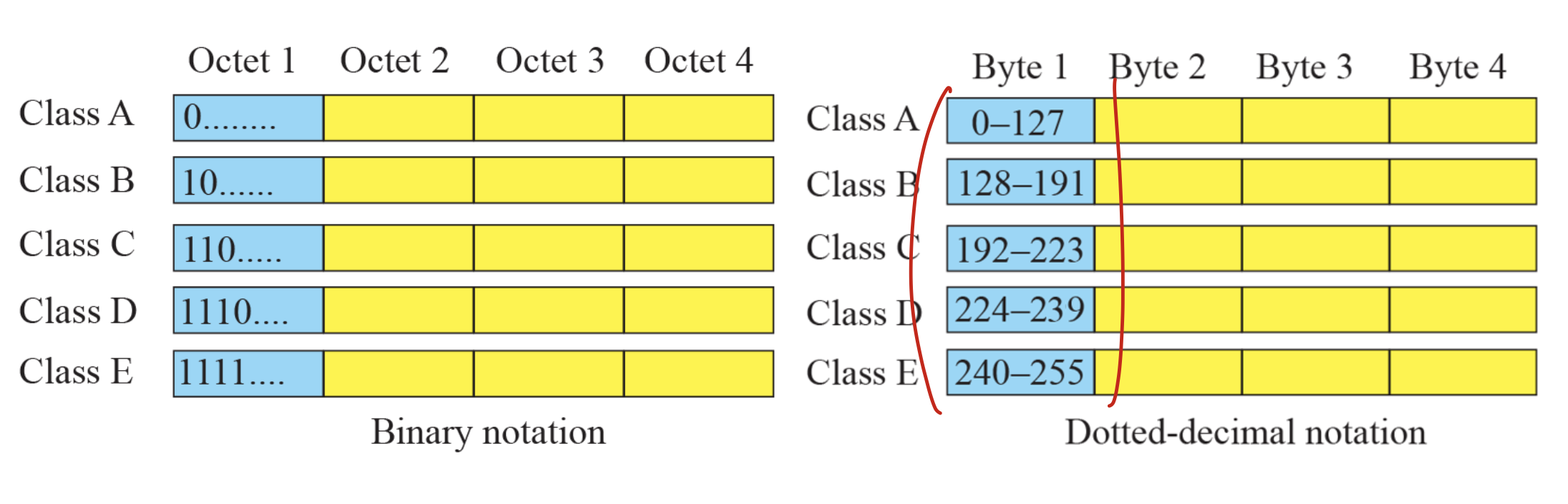
A, B, C만 사용하고, D,E는 다른 목적으로 사용.(multicast(radio app, IPTV), ordering for future)

1. 0 -> A
2. 110 -> C
3. 10 -> B

1. D
2. C
3. A
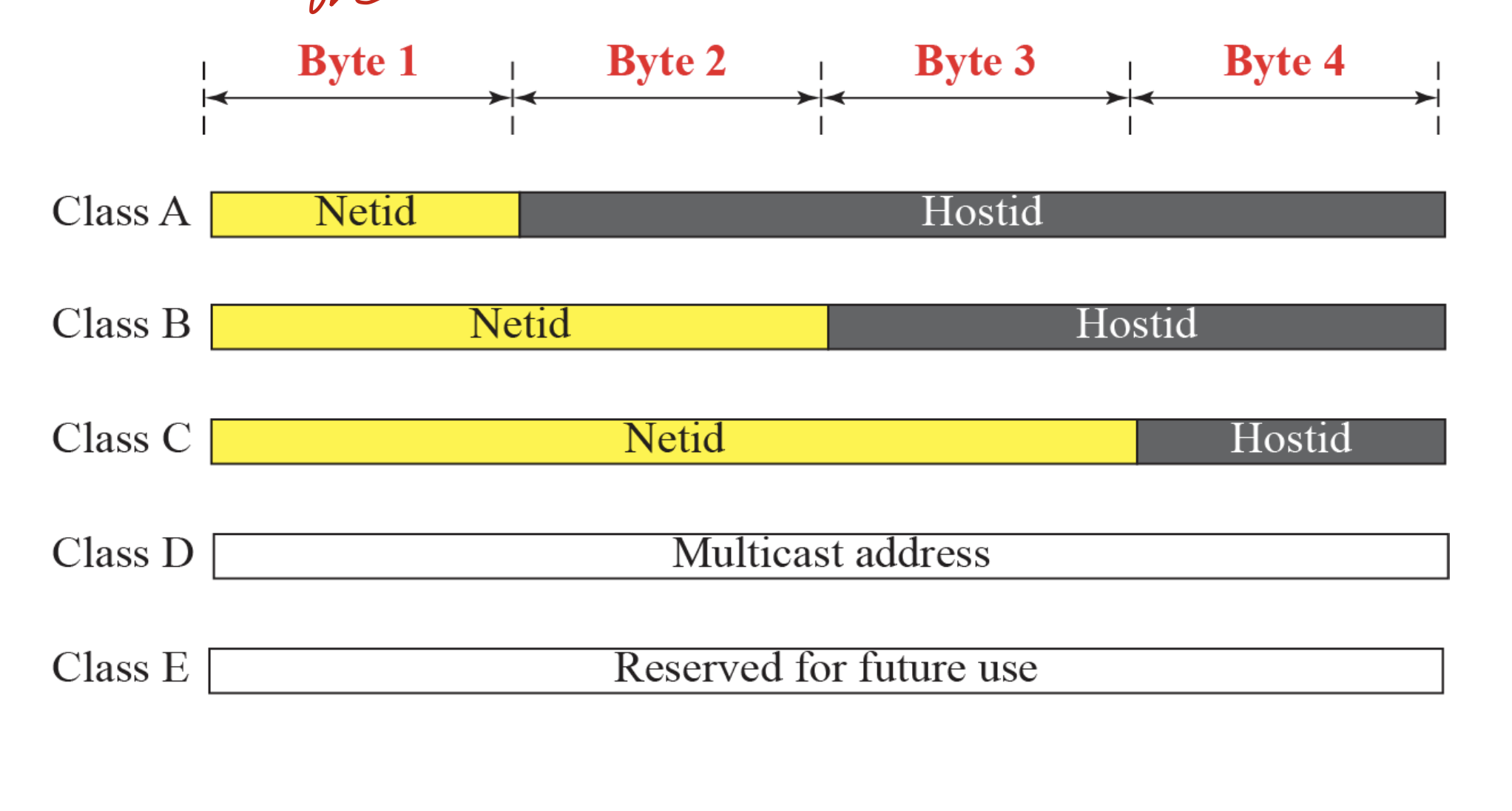
앞을 netit라고 하고, 뒤를 host id라고 함.
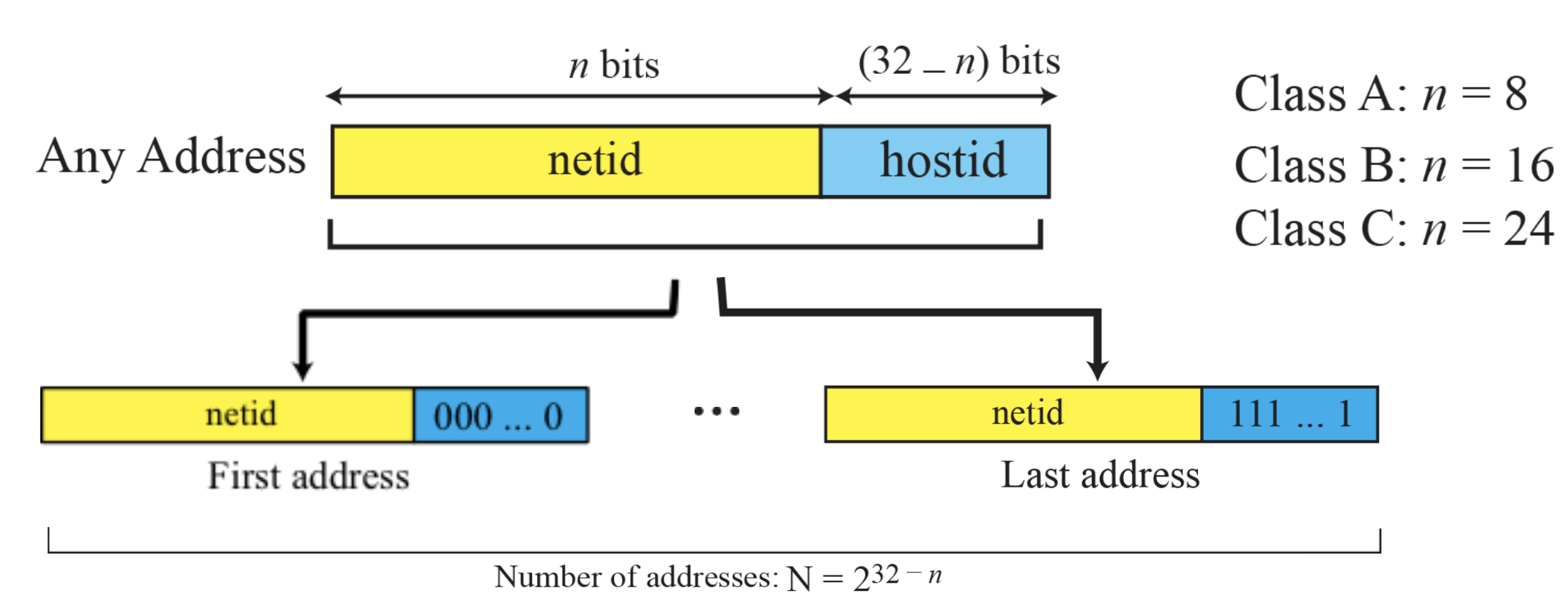
첫번째 주소는 hostid가 전부 0, 마지막 주소는 전부 1
주로 이렇게 되어있고, 첫번째 주소는 Network의 address를 의미한다.(Network의 대표 번호)
마지막 주소는 broadcast address로, 주소가 특정되어 있지 않고 모든 host에게 전송할때 사용.
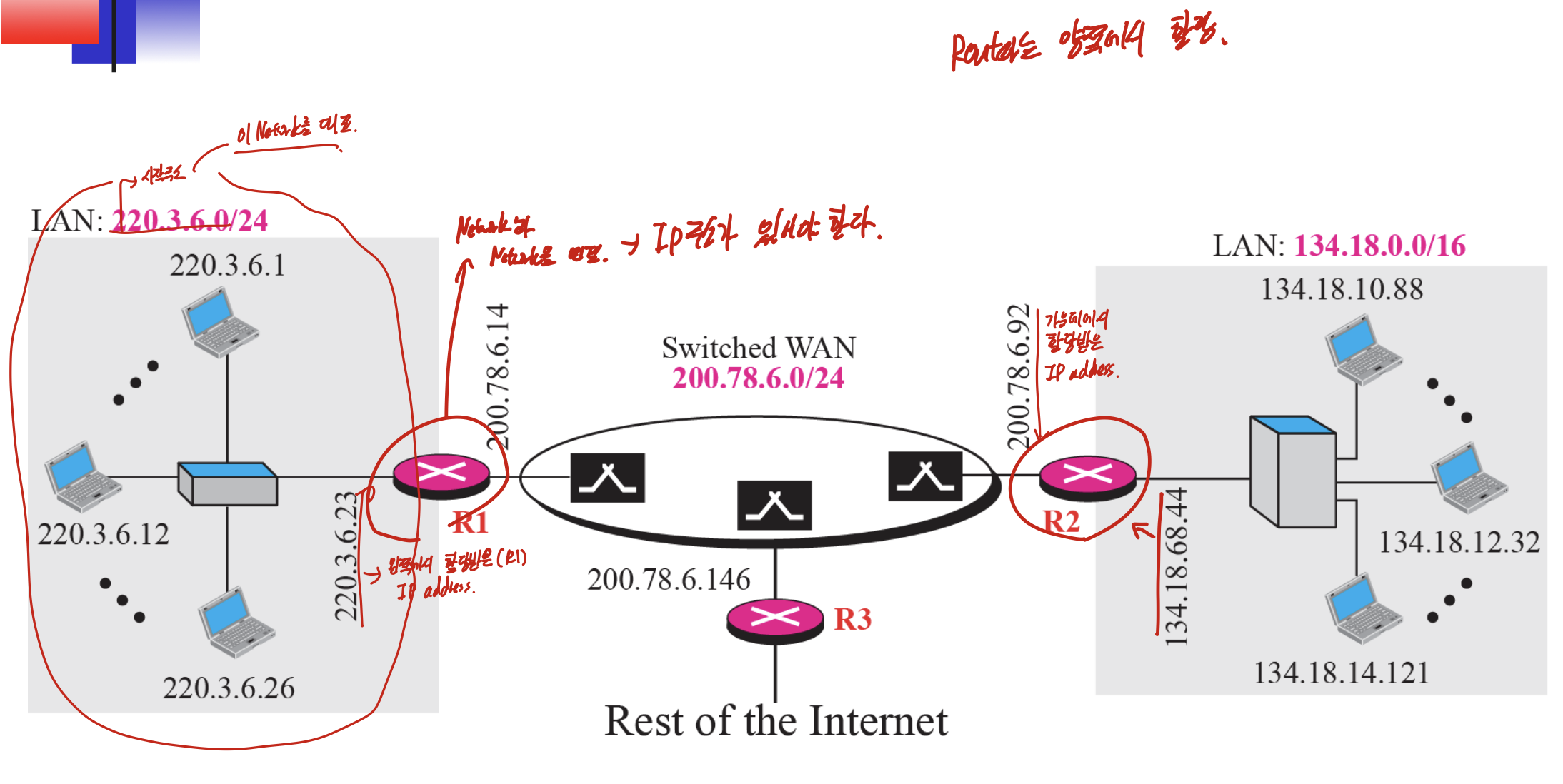
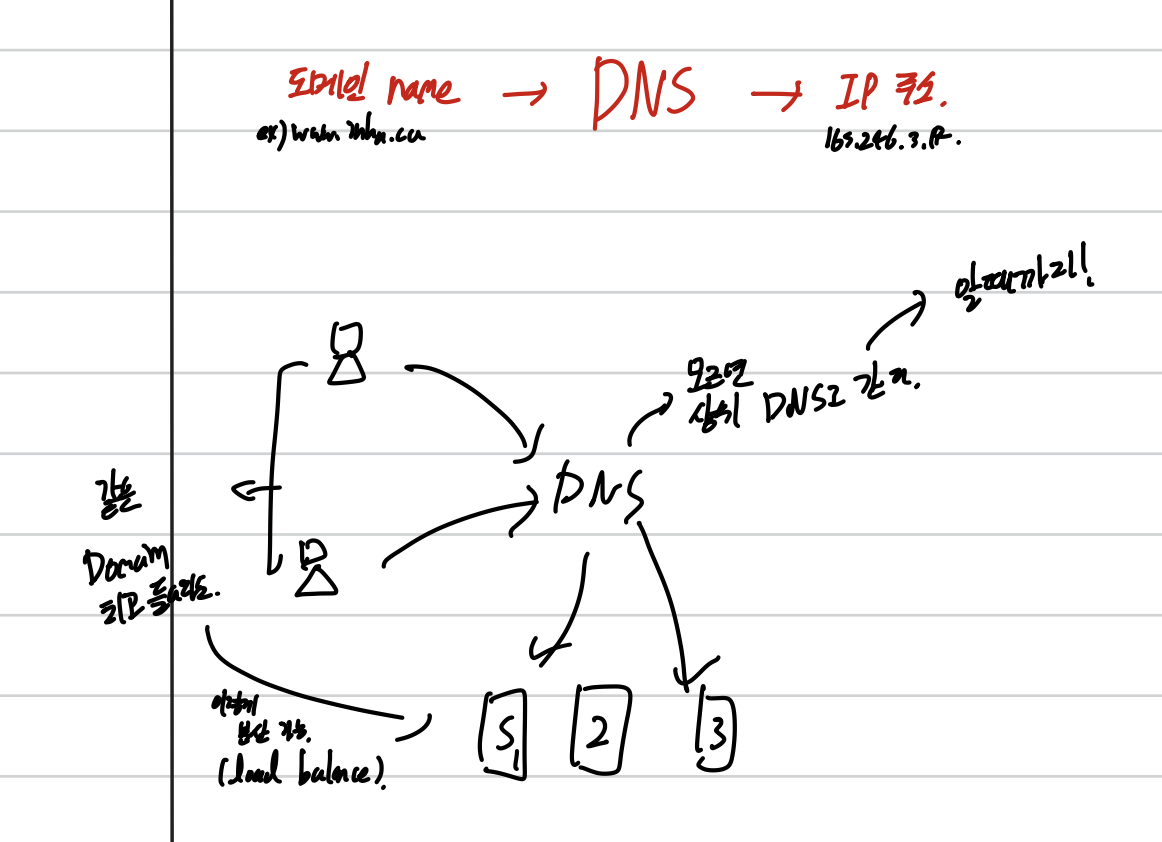
인터넷의 구조에 대한 그림이다.
그림과 같이 Router는 왼쪽과 오른쪽 네트워크에서 IP를 할당 받는다. 그러므로 Router로 연결하기 위해서는 IP가 필요하다.
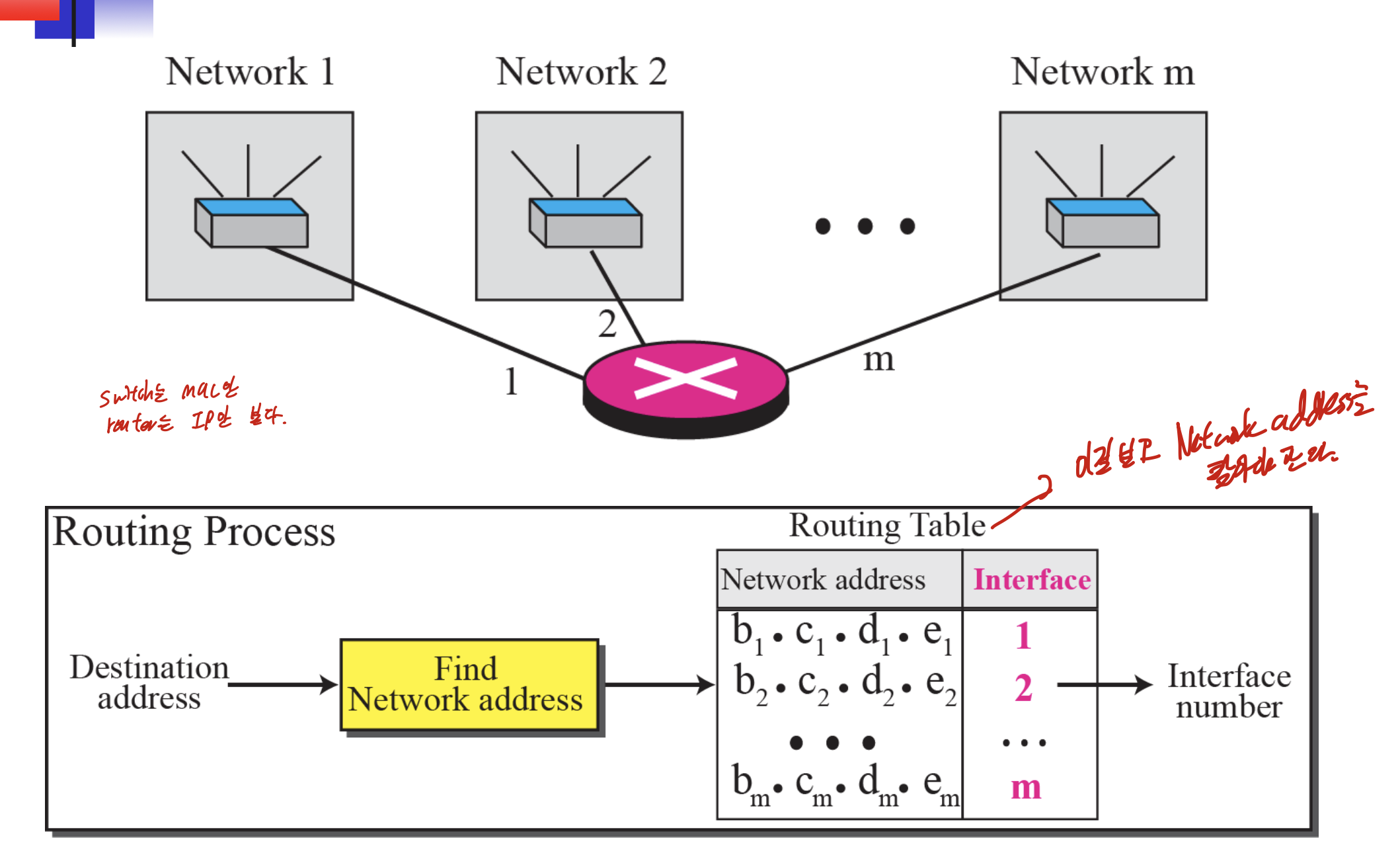
라우터와 여러 네트워크가 연결되어 있는 그림이다.
밑의 그림이 라우터를 통해 연결하는 과정을 나타낸 것인데
도착지 주소(IP)를 받으면 그것의 Network address를 라우팅 테이블에서 찾아서 Interface number를 꺼내주는 것을 볼 수 있다.
Network address는 masking이랑 and 연산을 하여 구할 수 있다.
추가적으로 switch는 MAC, router는 IP만 보는 것을 알아두면 된다.
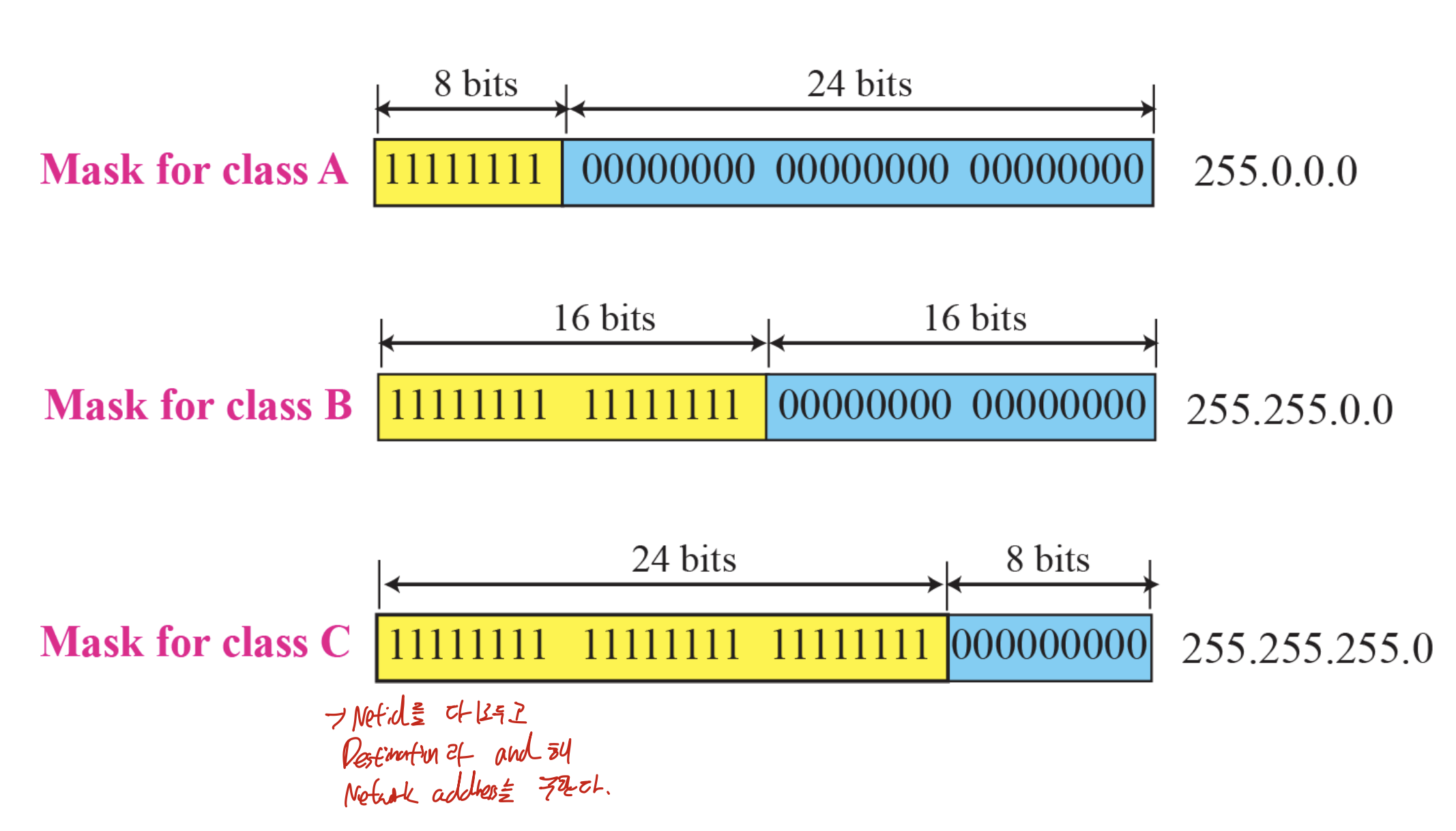
MASK
Netid를 다 1로 두고, Hostid는 0으로 둔다.
그리고 이것을 Destination과 and 해 network address를 구한다.

2의 16승 개의 host -> class B
one single connection으로 연결되어 있음.

그러므로 이렇게 그려질 수 있다. 스위치는 네트워크 무조건 안에
하지만 이렇게 하나의 네트워크로 구축하면 비효율적이고, 보안에 취약하다.
그러므로 Subnet이라는 것을 만들어 준다.
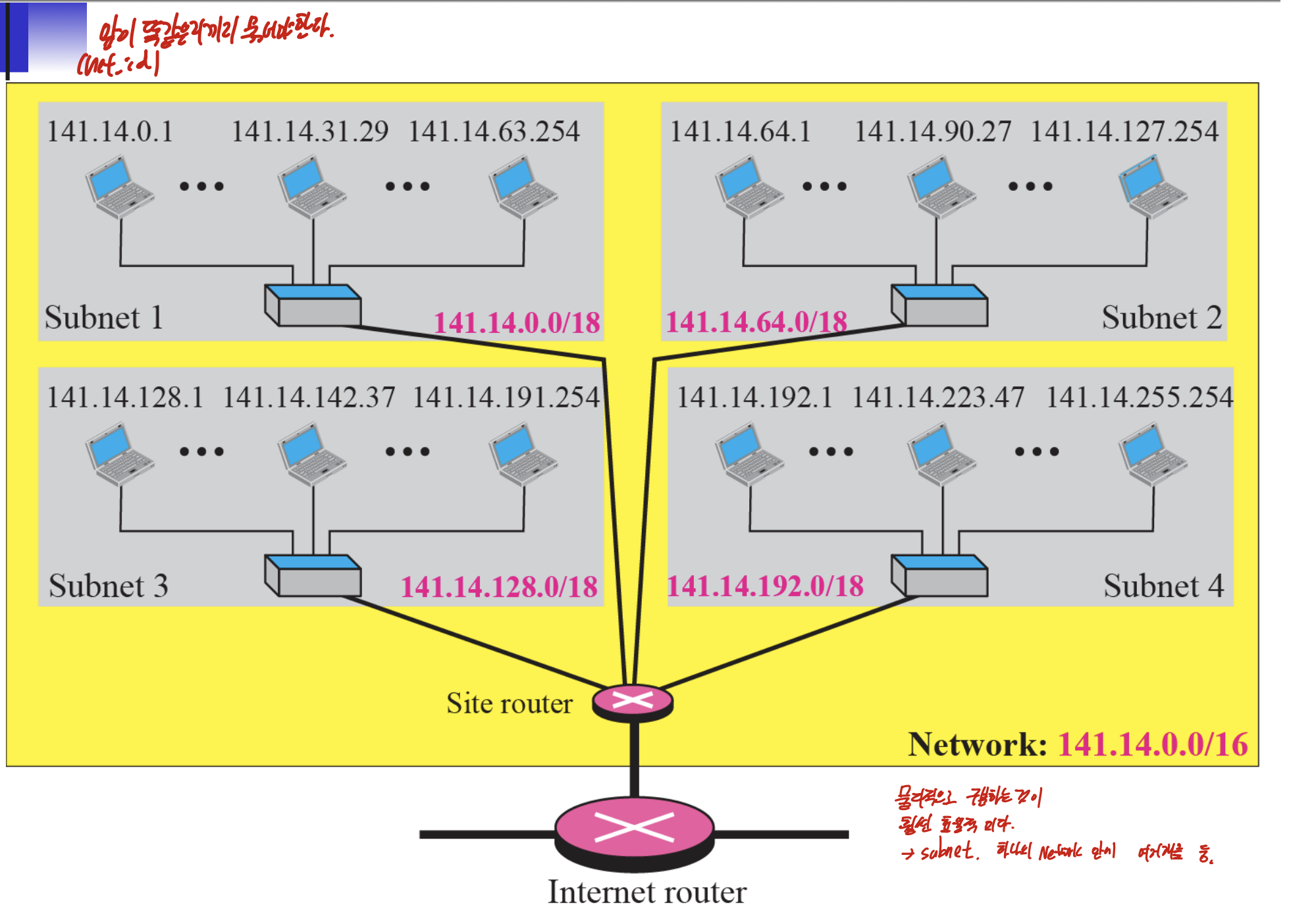
이게 이전그림 대비 Subnet으로 바꾸어 준 것이다.
네개의 subnet를 구성했기 때문에 /16에서 /18이 되었다. 그리고 hostid는 /14가 되었다.

특정 주소가 주어지고, 그 주소의 네트워크가 4개의 서브넷으로 나뉘여 있다고 하면 Mask를 네트워크의 클래스에 해당하는 것 에서 2 늘려주면 된다.
그러므로 120(01111000) and 11000000이므로 01000000, 64가 된다.

subnet mask, default mask 구분.
Classless
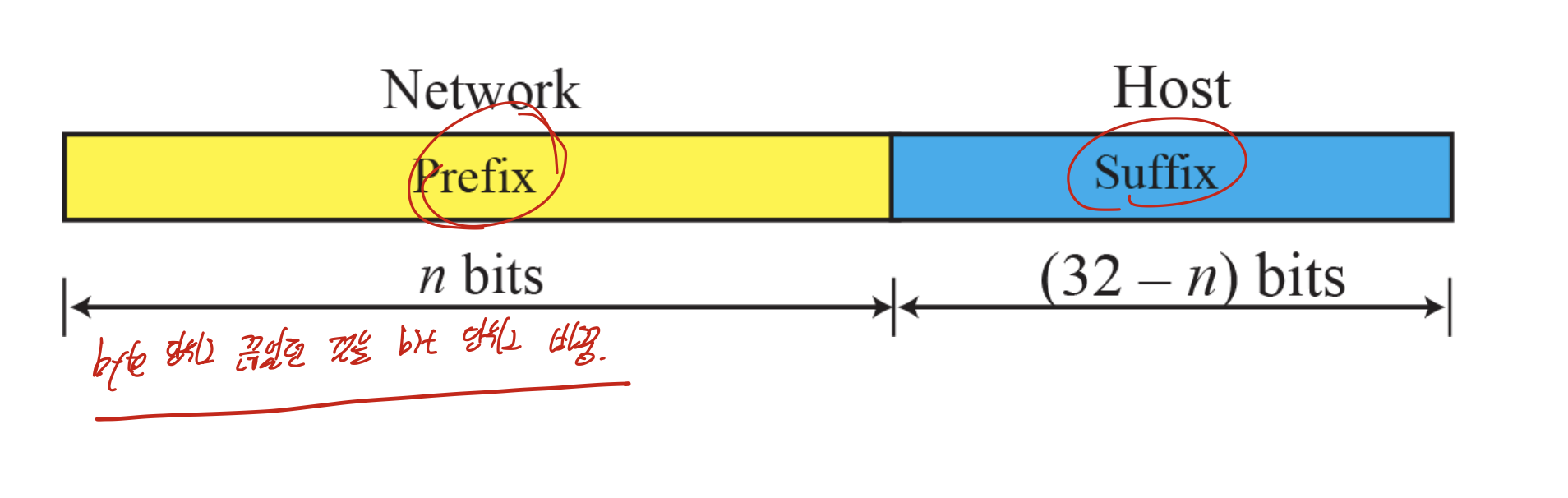
class를 없애고, byte단위로 나누었던 것을 bit단위로 나누었다.
이젠 Prefix, suffix로 용어를 바꾸었다.
prefix는 block의 수, suffix는 주소의 수 이다.

1 block에 저만큼의 주소이므로, prefix = 0, suffix = 32
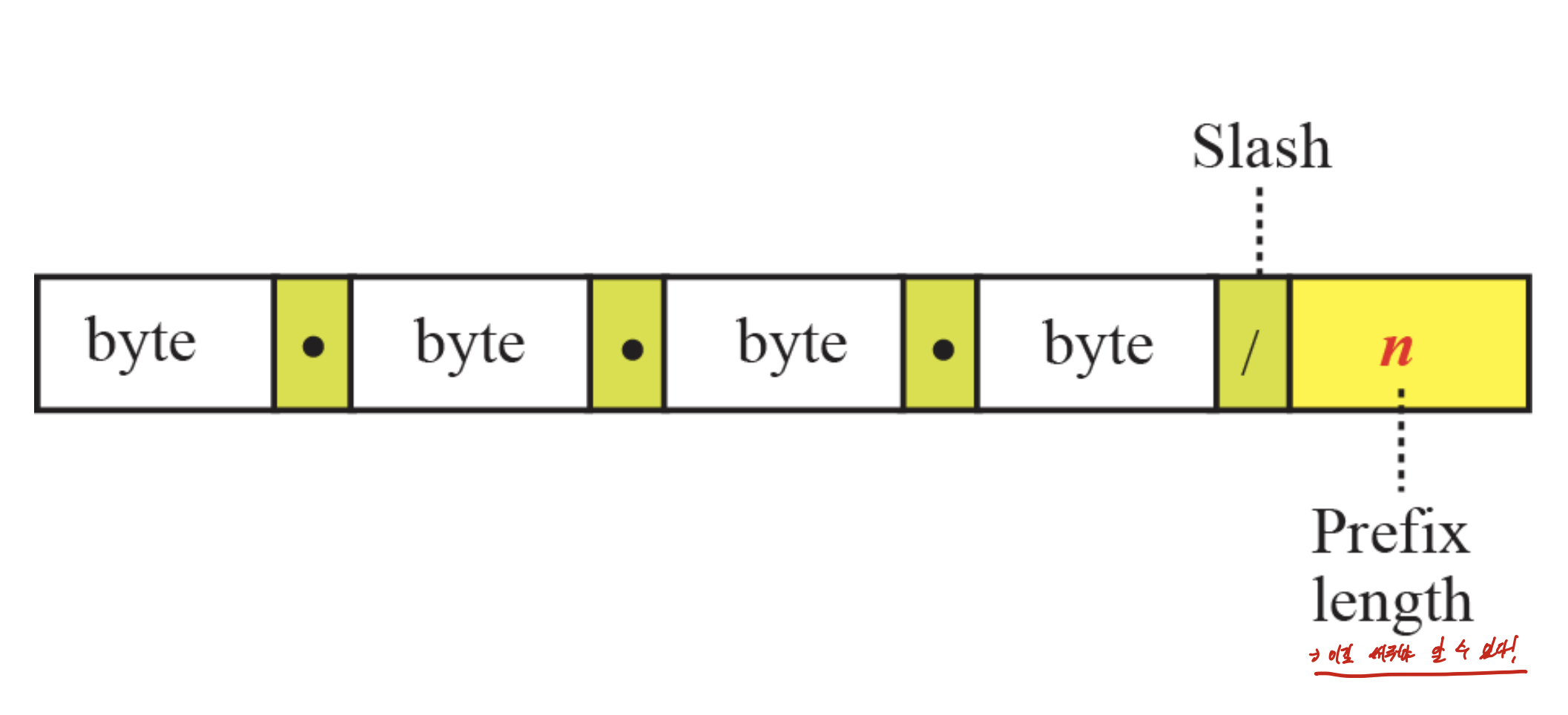
이전처럼 class로 구분하지 않으므로, 이젠 slash notation을 사용해 prefix length를 써주어야 한다.


이제 첫주소는 prefix에 1넣고 and, 마지막 주소는 suffix에 1넣고 or해주면 된다.
classful에서 classless로 바뀌었는데, 그냥 기존꺼에서 뒤에 slash annotation으로 표기만 해주면 됨.
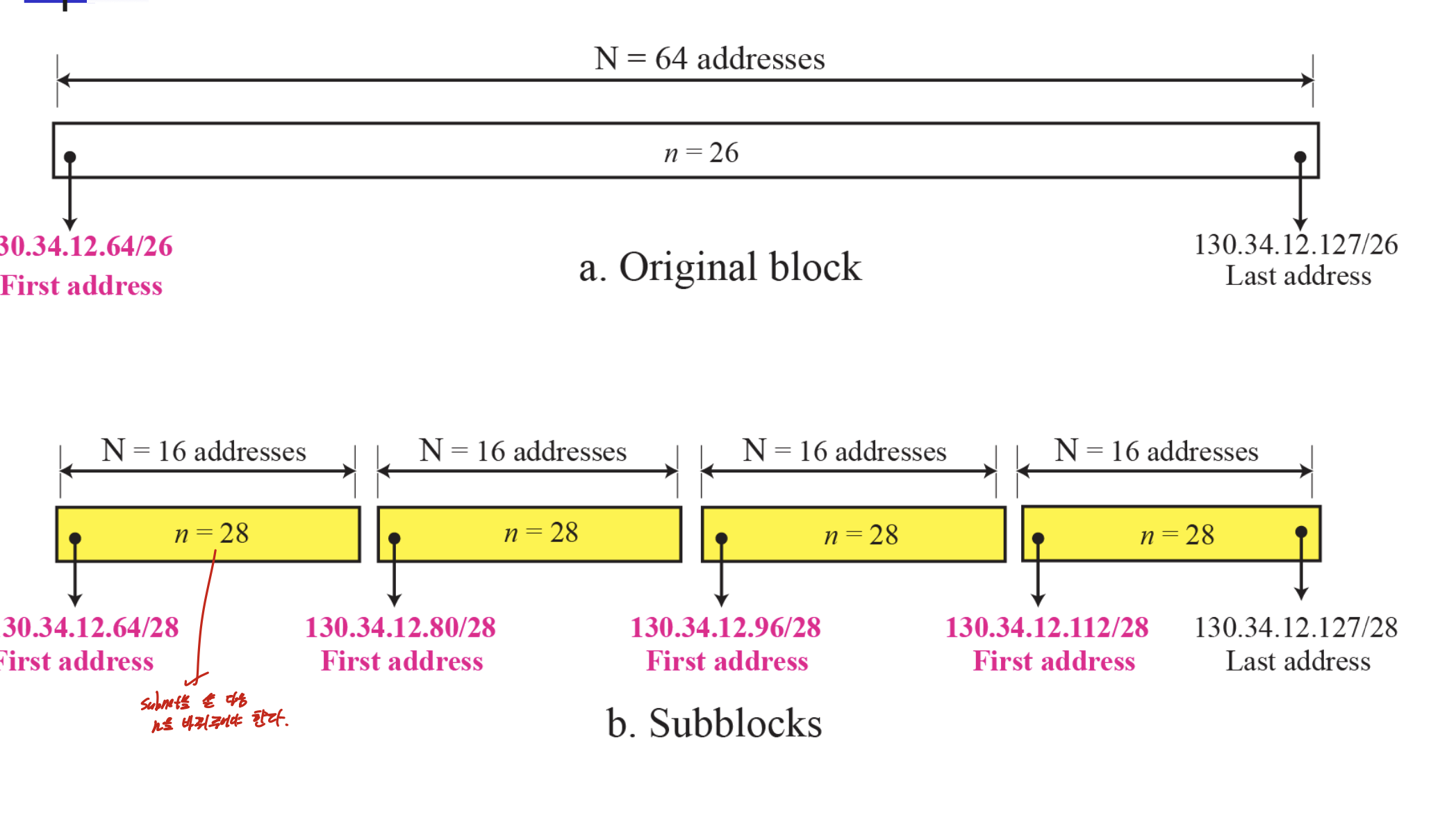
classless의 subneting이다.
똑같음!



subblock을 다양한 크기로 만들어 줄 수 있는데, 큰거부터 만들어주는게 좋다.
주소 할당에 의한 못쓰는 주소의 크기를 줄여줄 수 있기 때문이다.
위의 예시 두개로 보면 됨.
서브넷의 하나하나가 서브블락.


first group은 2^6 * 2^8이니 190.100.0.0/18이 그룹의 시작주소 이다.
이런식

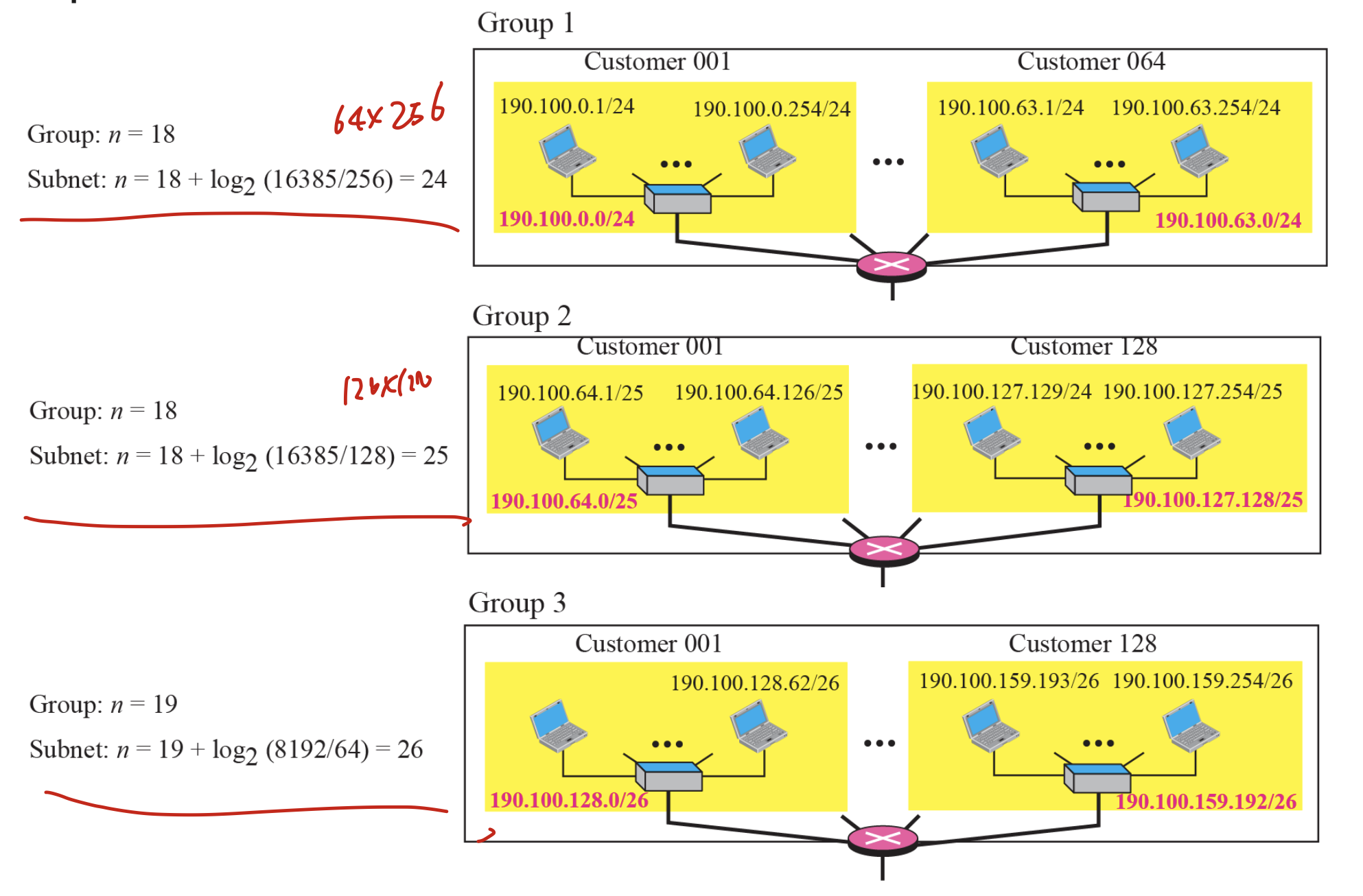
이게 낫다. 그룹은 N 18이고, 각각의 손님에 대한 block을 만드면 n이 저렇게 변한다.
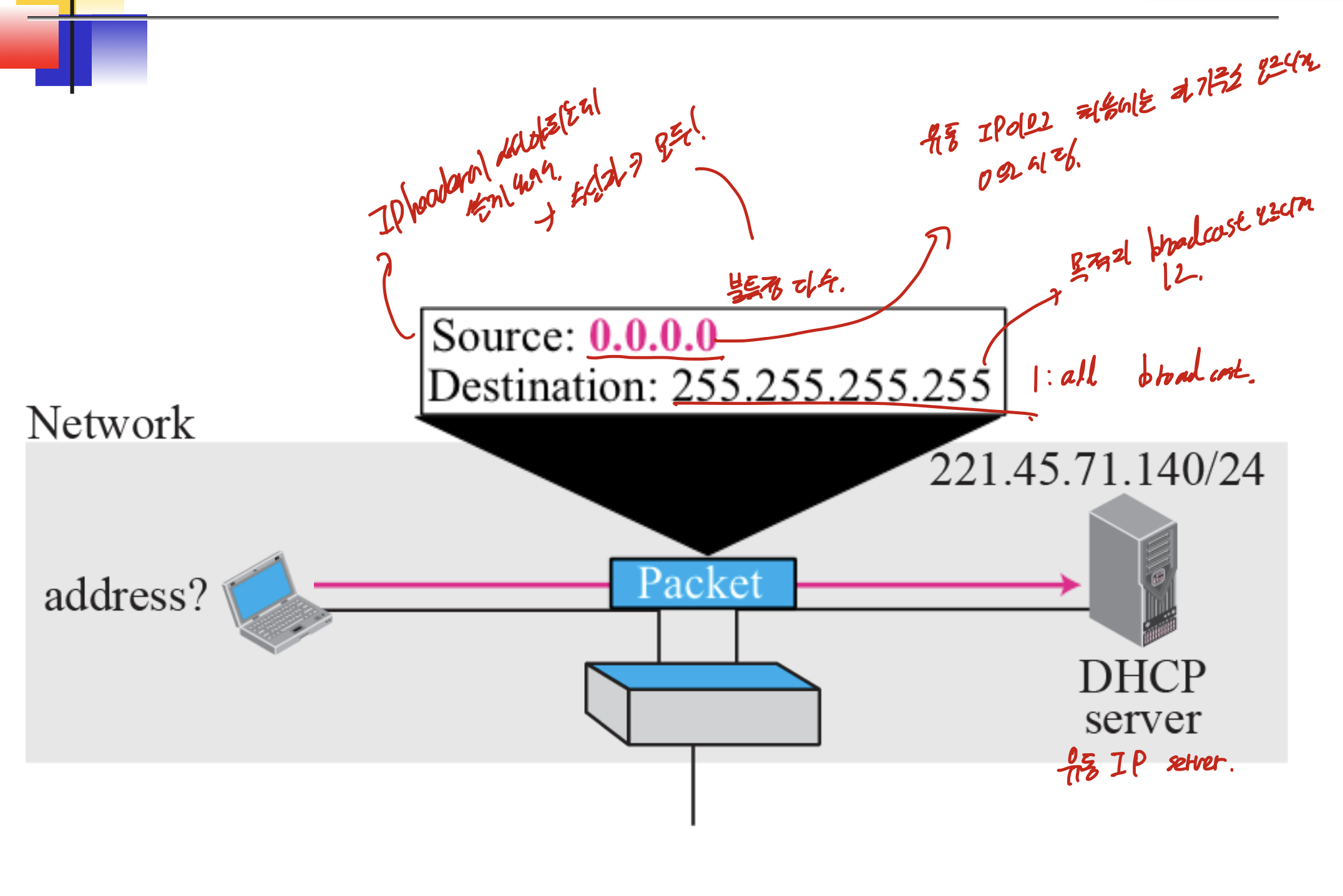
0,0,0,0 -> 주소를 모를때(DHCP에서 처음 주소를 얻어올때, 자기주소 모르니까.)
255.255.255.255 -> 모든 네트워크에게 전송. Router는 broadcast가 목적지인 패킷을 막는다 -> limited broadcast -> local network에서만 모든 호스트에게 전송.
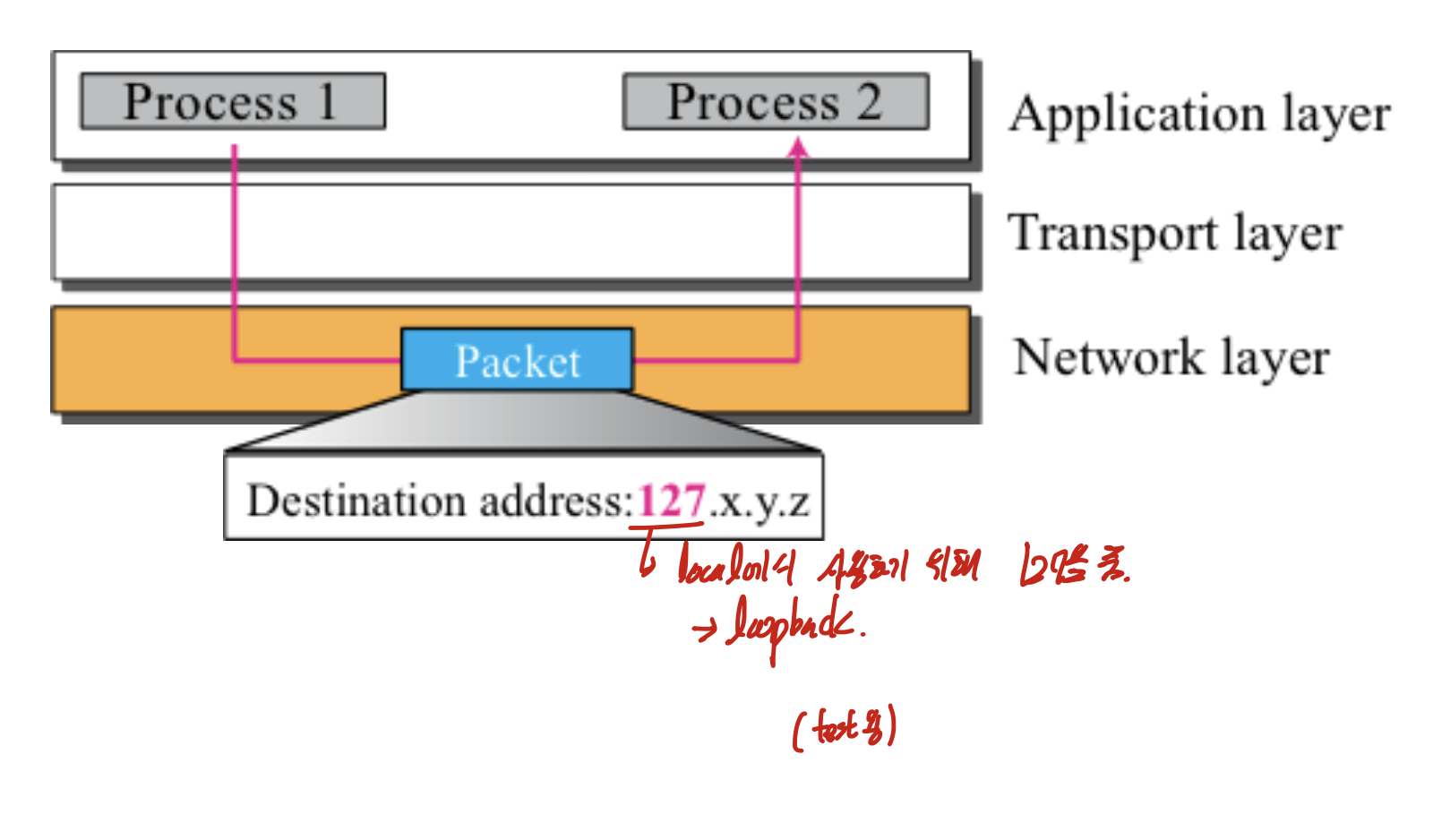
local computer에서 사용하게 하기 위해 127로 시작.
loopback 주소.
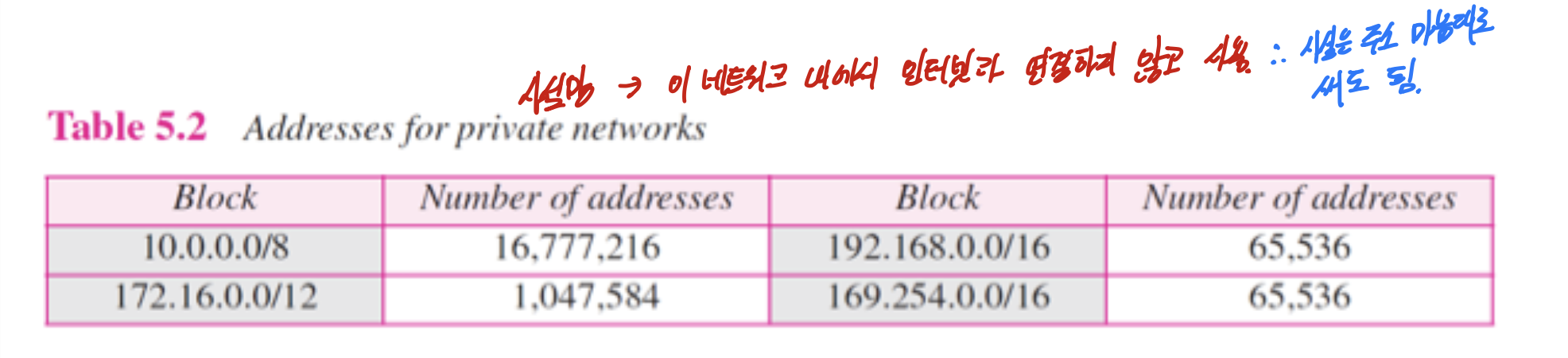
사설망은 한 네트워크 안에서 인터넷과 연결하지 않고 사용하는 것.
사실 아무거나 줘도 되는데, 주로 저 번호들을 씀.
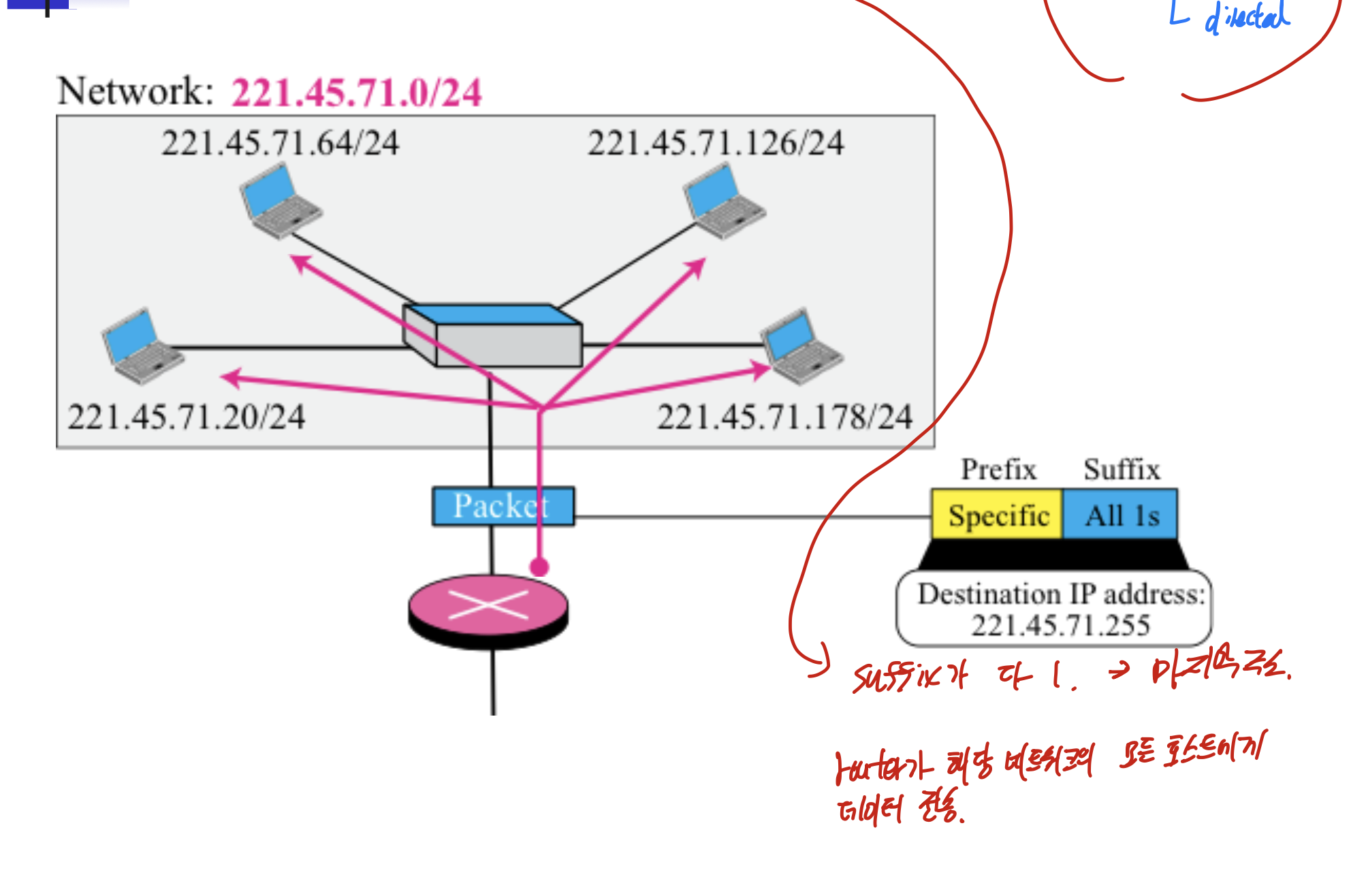
Directed broadcast란
suffix를 다 1로하여 라우터가 해당 네트워크의 모든 호스트에게 데이터를 전송하는 것.
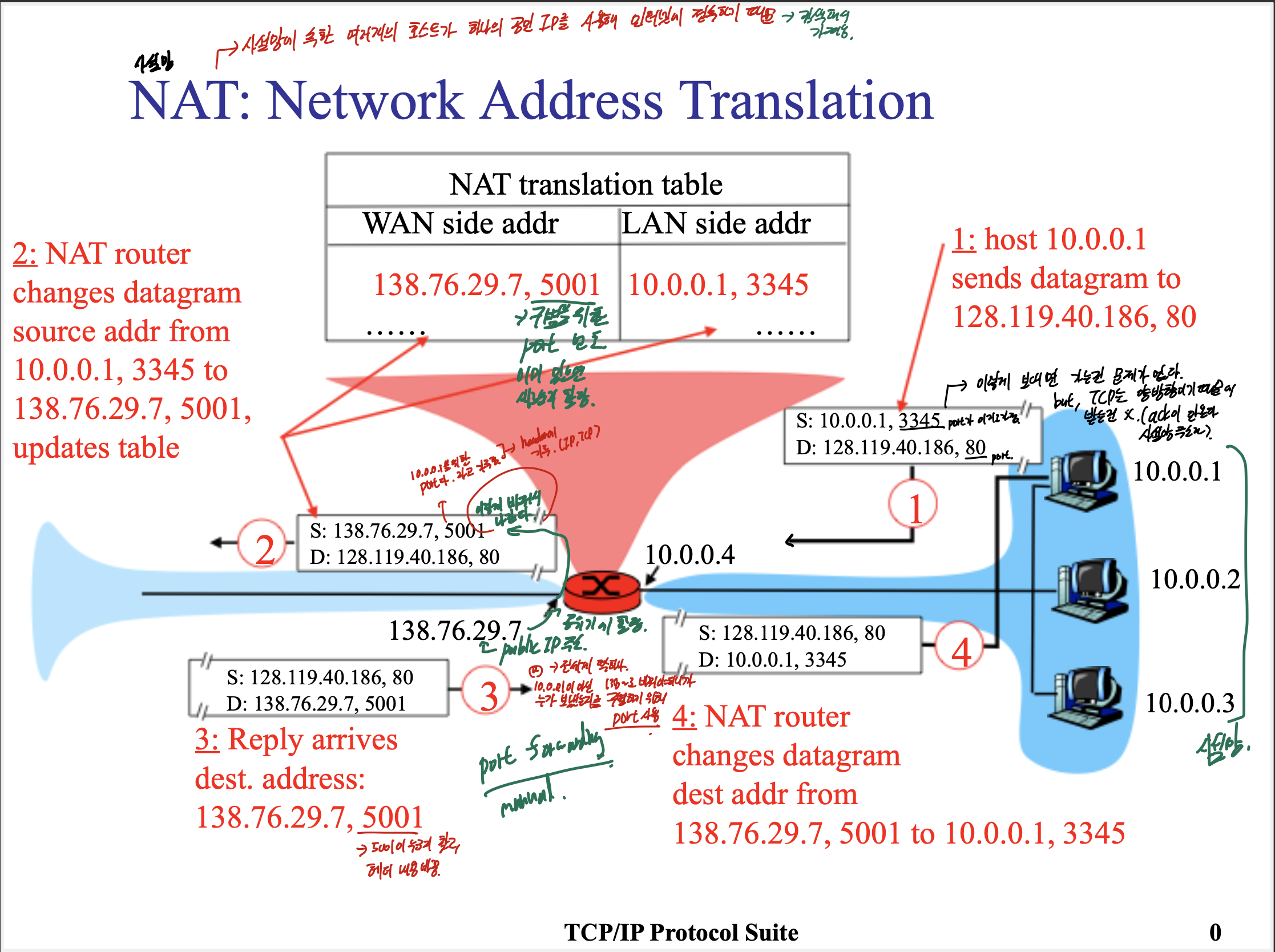
NAT란, 사설망에 속한 여러개의 호스트가 하나의 공인 IP를 사용해 인터넷에 접속하기 위해 사용.
처음에, source로 사설망 내 호스트가 자기 주소를 찍어서 보낸다. 그러면 가는건 문제가 안되는데, ack을 받아야되는데 이걸 못받는다. (TCP의 양방향 통신 불가)
그러므로 나갈때, 그림처럼 NAT translation table에 나갈때 변환 주소와 포트, 원래 사설망의 주소와 포트를 적어서 구별한다. 구별을 위해 포트번호를 사용한다는 것을 알아야 한다.
다 똑같은 IP로 나가서, 처음에 138.76.29.7이 공유기에 할당이 되어있다.
TCP에서 응답이 오면, 포트로 구별해서 사설망의 호스트에 보내준다.
CH06 Delivery and forwarding of IP packet
Direct, inDirect delivery
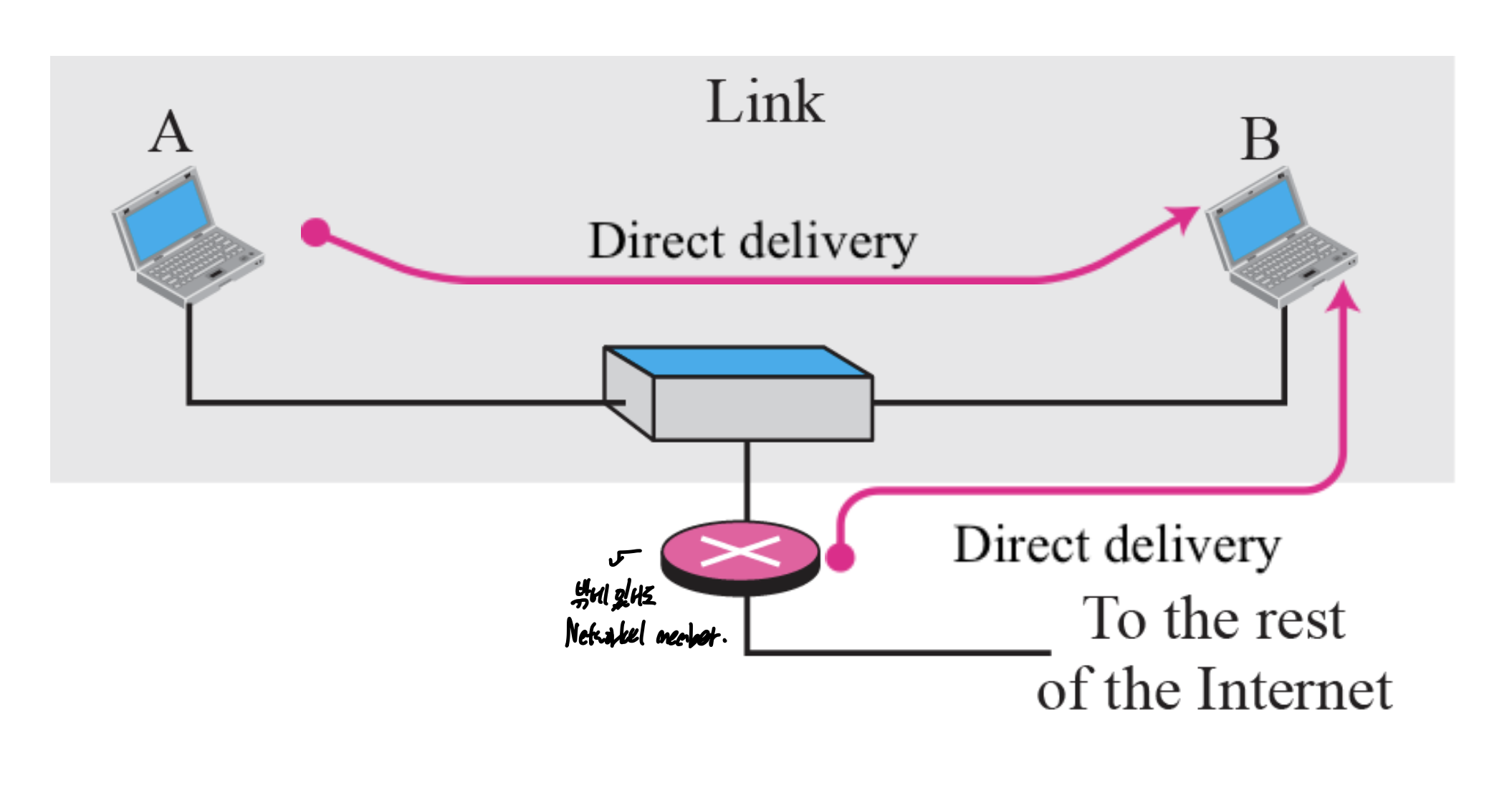
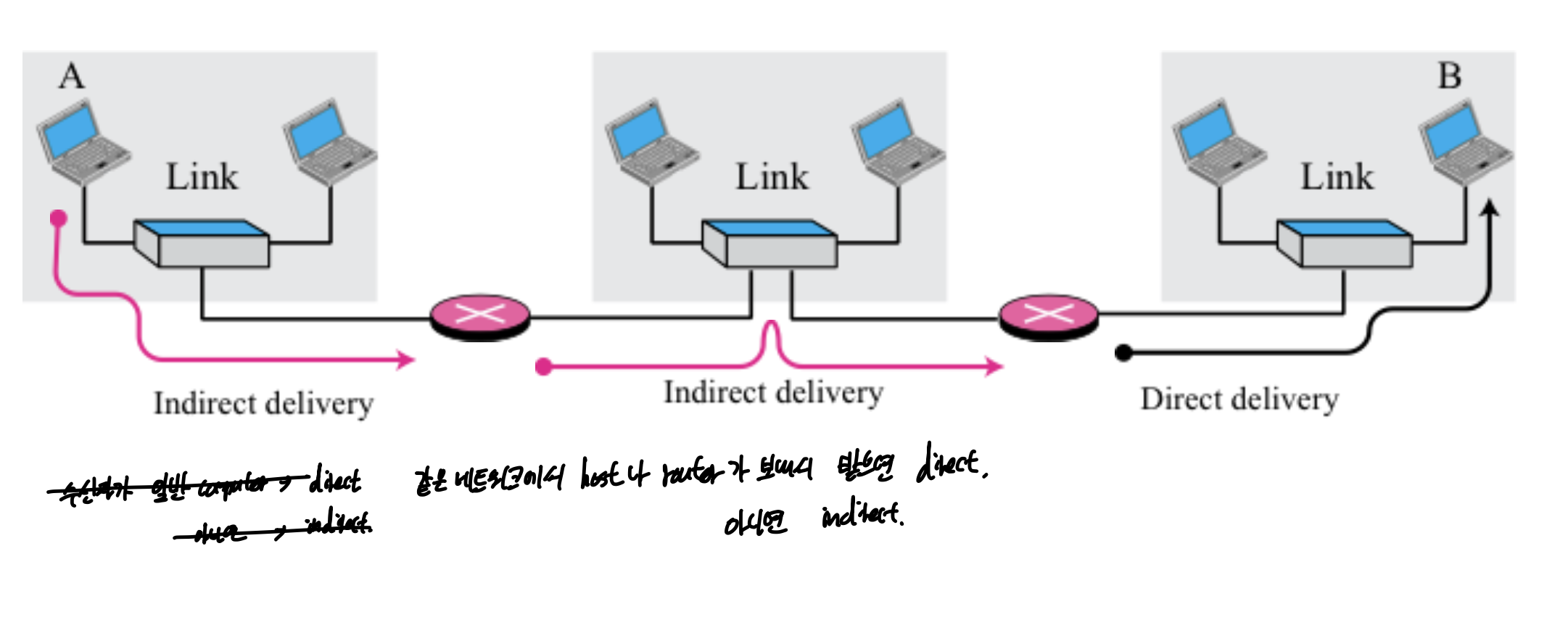
같은 네트워크에서 호스트나 라우터가 보내서 받으면 다이렉트
아니면 인다이렉트
Next hop Forwarding
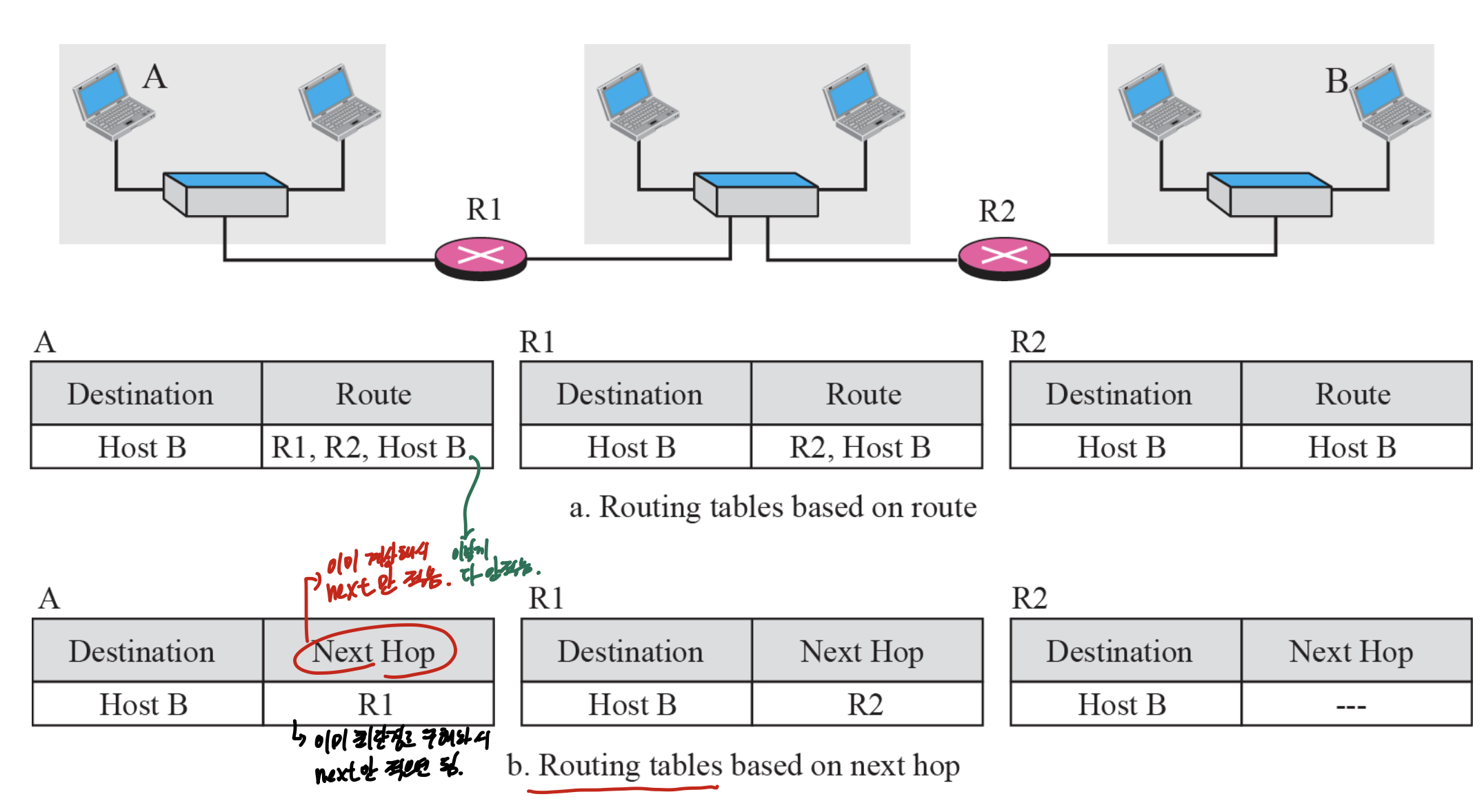
이미 최단경로를 구해놓은 상태이고, 밑의 그림처럼 다음에 갈거, Next Hop만 구해서 적어준다.
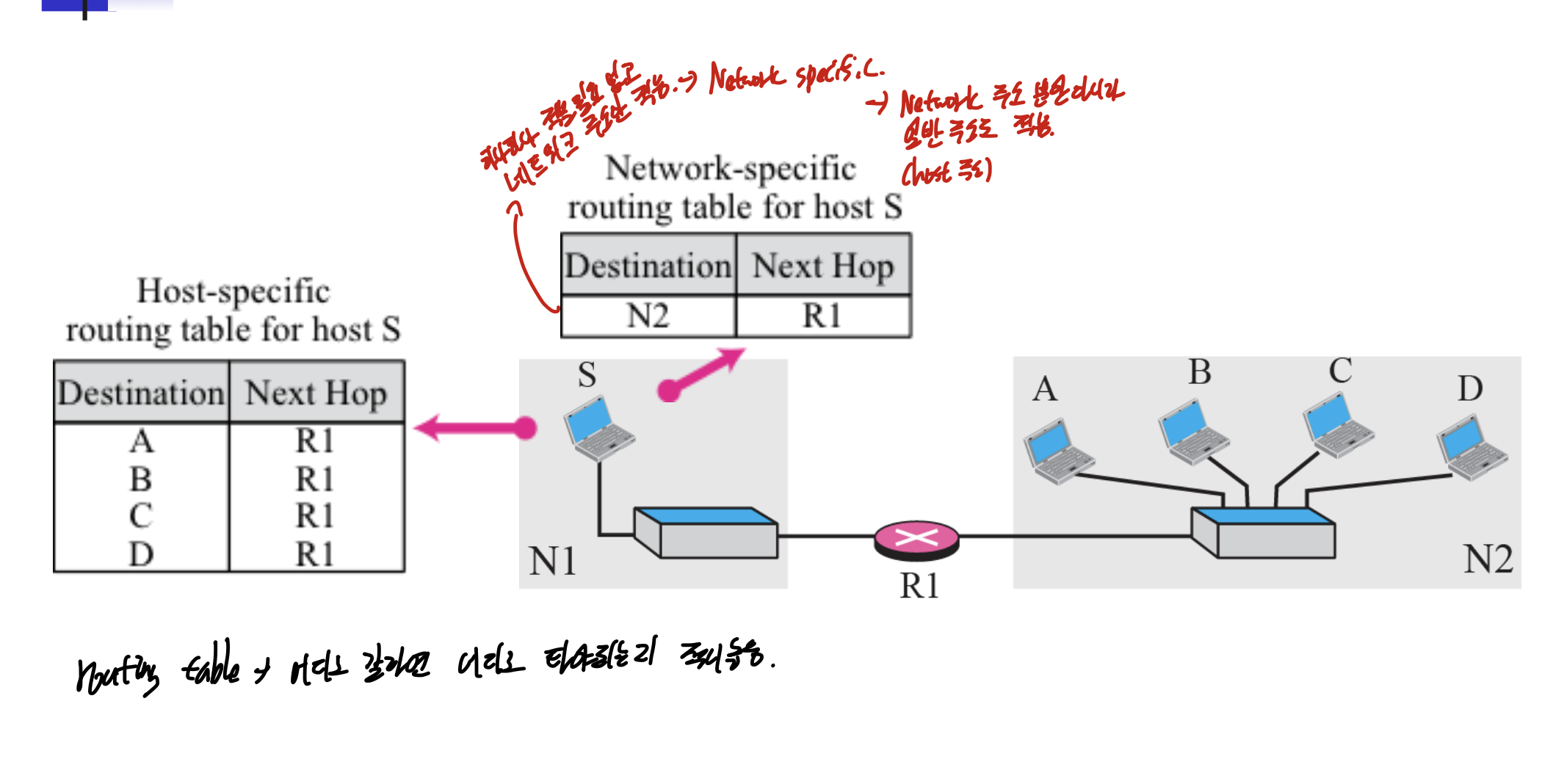
이거 적어놓는 것을 라우팅 테이블이라 하는데, 하나보다 적을 필요 없고, 네트워크 주소만 적는다면 Network Specific이라 하며 네트워크 주소만 적을 필요 없고, host주소 적어도 된다.
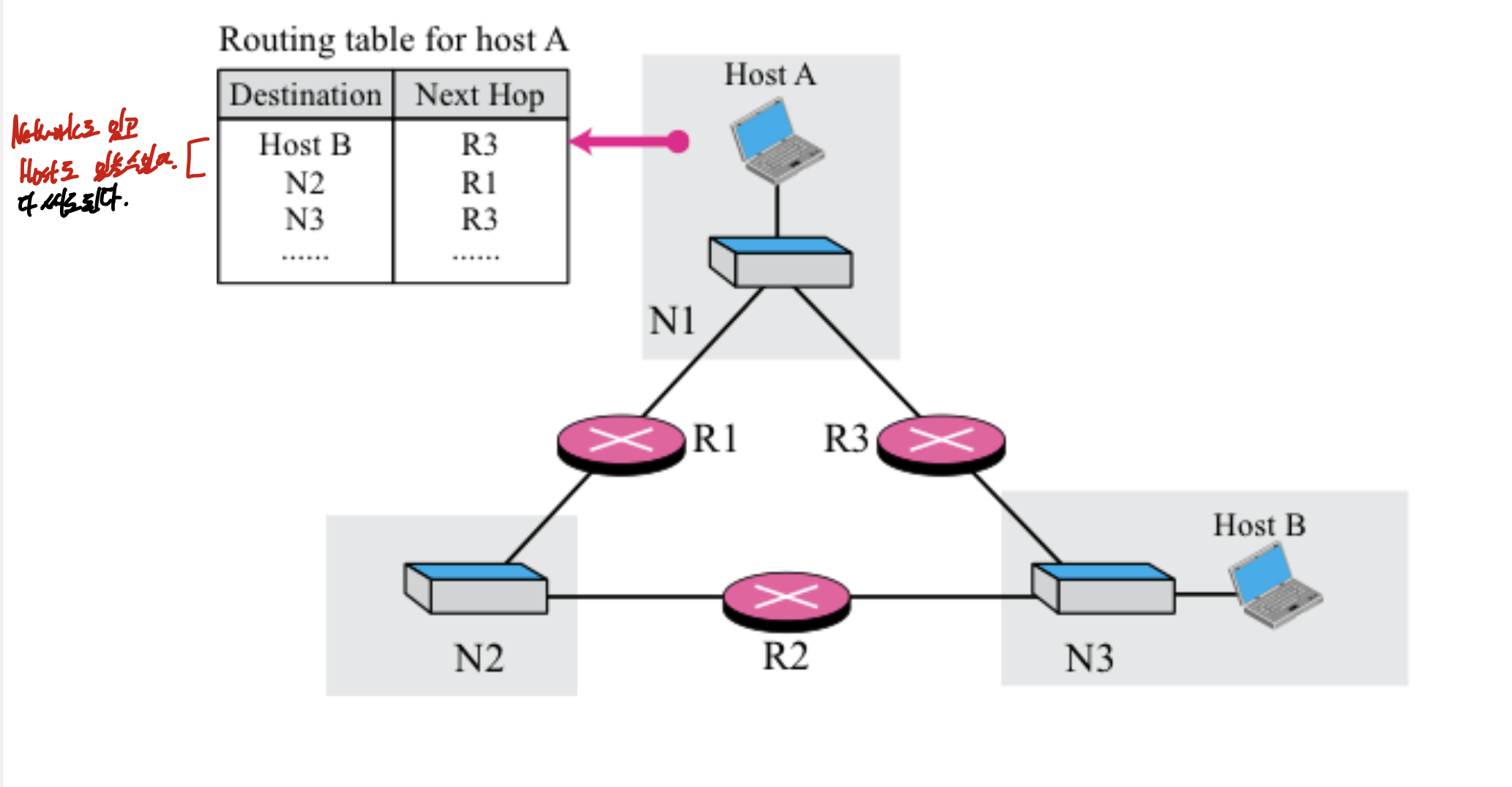
이렇게.
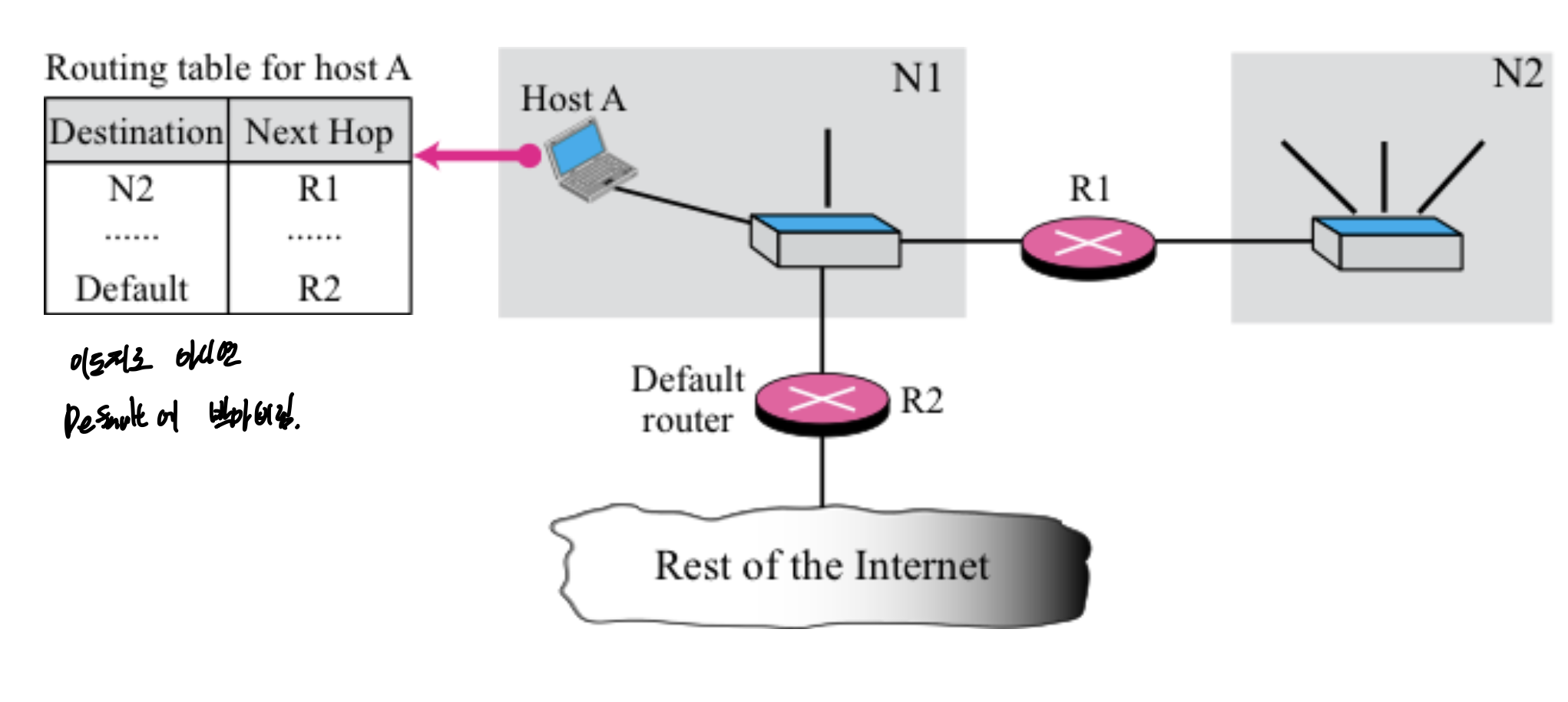
이도 저도 아니면, 이렇게 default쓰고 박아버린다.
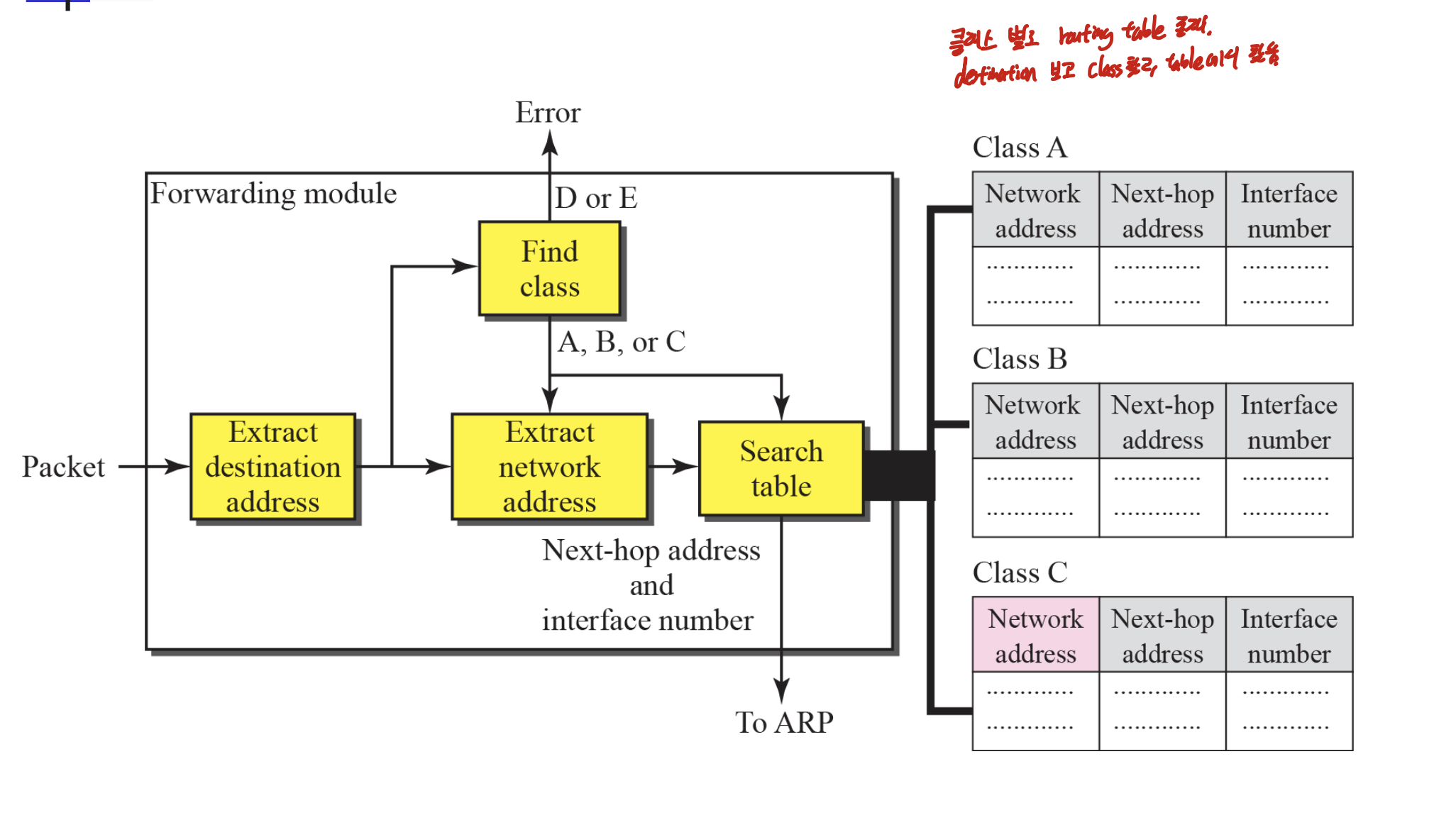
서브넷이 없는 classful에서는 이렇게 클래스 별로 routing table이 존재한다. destination 보고 class 찾고, table에서 next hop 찾는다.
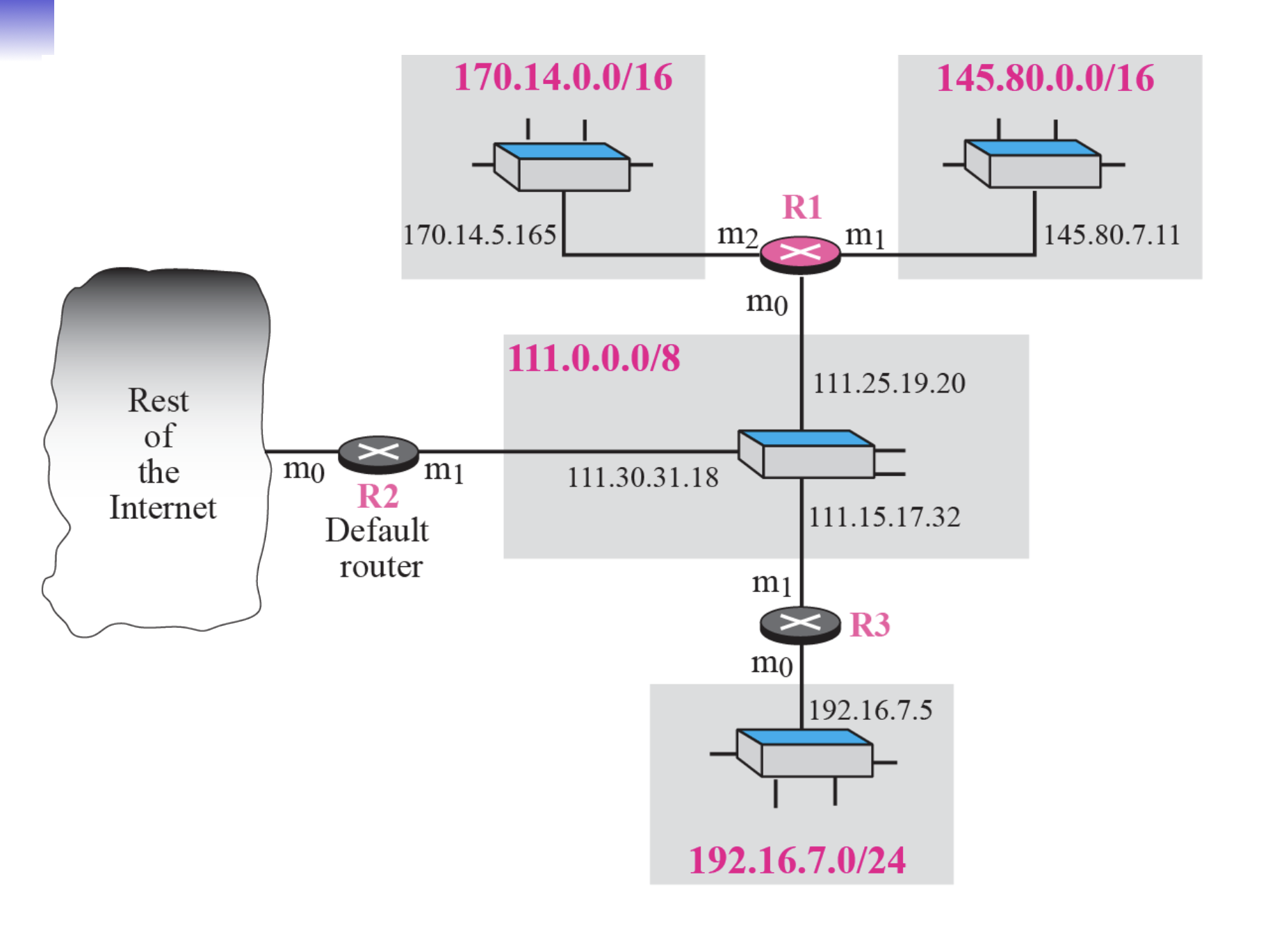
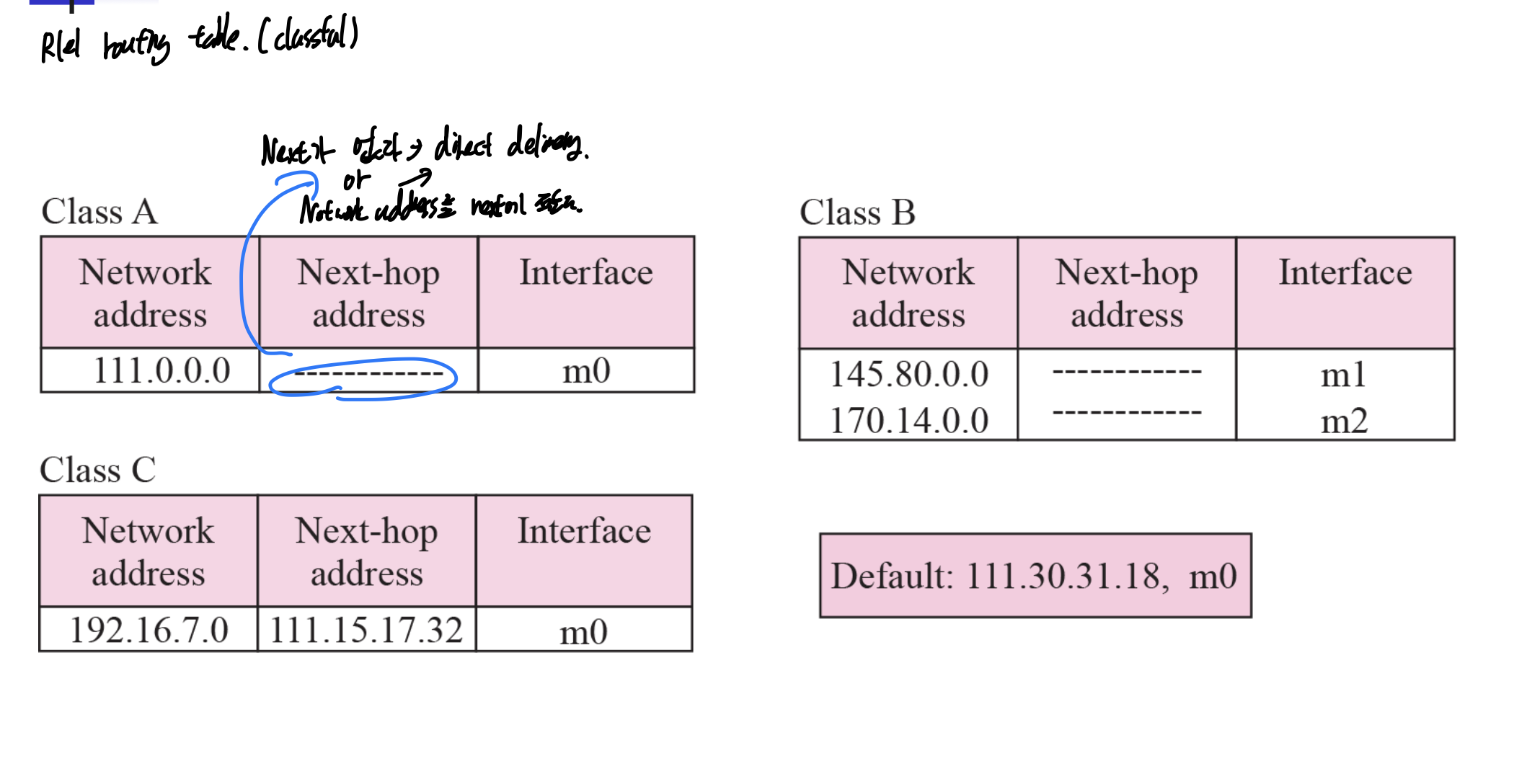
1번 그림을 보고 R1의 라우팅 테이블을 만든 것 이다.
일단 classful이다. 그러므로 class별로 나누어주어야 한다.
주의해서 봐야할 것은 Next-hop address가 없는 경우이다. 이는 direct delivery를 의미하는 것 인데 밖에있는 라우터도 네트워크에 포함되기 때문에 direct이다.
아니면 next hop의 주소를 적어준다. 111.15.17.32를 통해 192.16.7.0으로 갔기 때문에 적어주었다.
그리고 default 적어주는것도 까먹지 말기.

이어지는 문제인데, 192.16.7.14가 목적지 주소라면 일단 클래스 판단하고, 네트워크 주소 구해준 다음 라우팅 테이블에서 Next hop address, interface 찾아주고 그걸 ARP에 넘겨준다.
만약 라우팅 테이블에 없으면, default로 보낸다.
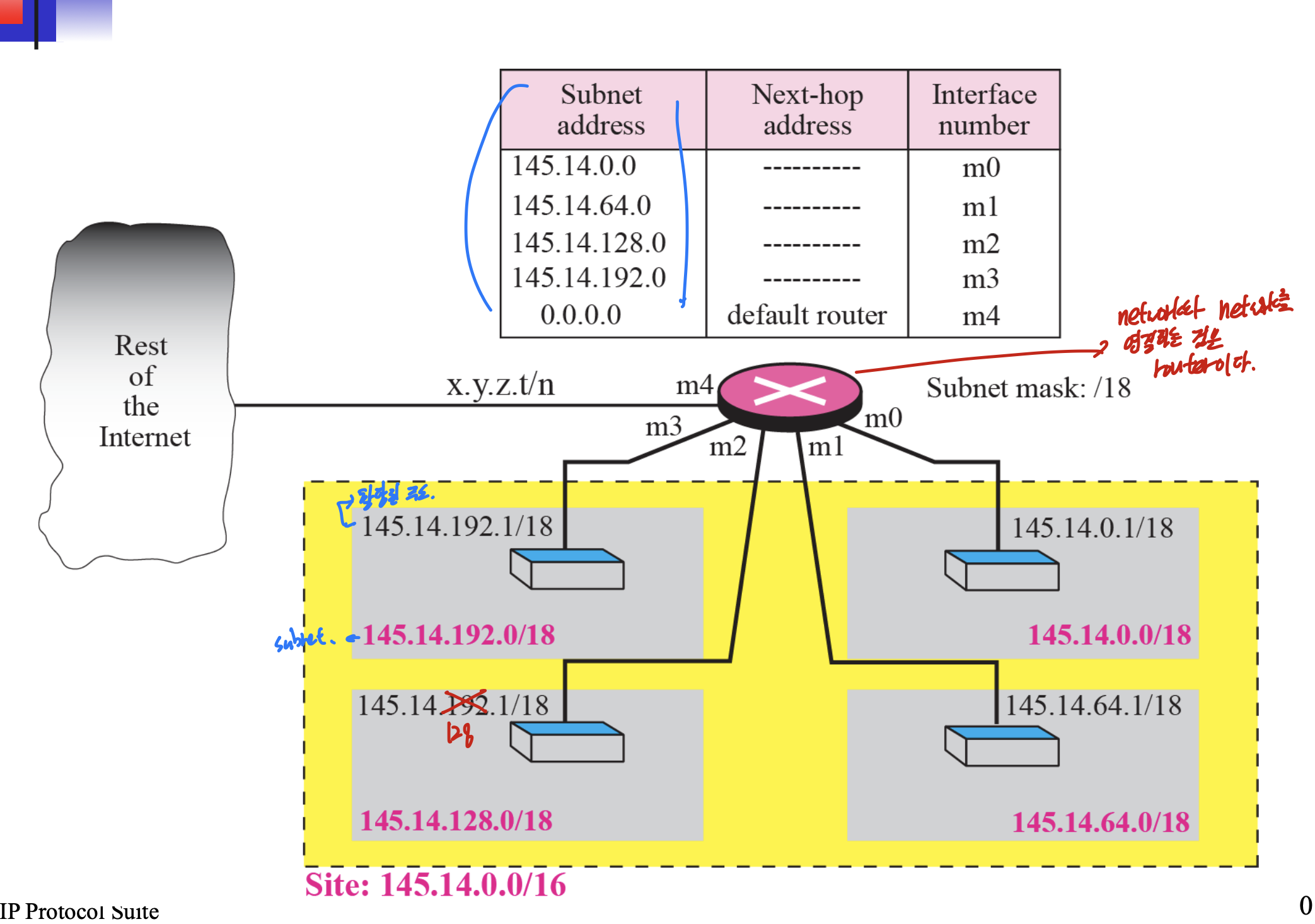
서브넷 있을때(classful이란다)
일단 145.14.0.0 Network address이므로 이것과 145.14.255.255 사이가 찍힌 모든 도착지 주소는 m4로 라우터에 보내지고, 라우터에 의해 분배된다.
default는 다시 받으로 쫒아낸다.
라우터의 서브넷마스크가 18로 되어있어 이거 and하고 subnet address찾아서 보낸다.
교수님 수업에서 안한지, 내가 못들은지는 모르겠는데 뒤에 설명 보면
도착지가 145.14.32.78일때, 일단 subnet mask 18로 되어있으니 서브넷 주소 구하면 145.14.0.0이다. 그러므로 interface m0, next-hop address 145.14.32.78가지고 ARP에 보내진다고 한다.

classful에서는 라우팅 테이블이 Network address, next hop address, interface 세가지만 있으면 된다.
하지만 classless에서는 적어도 네개가 있어야 된다.
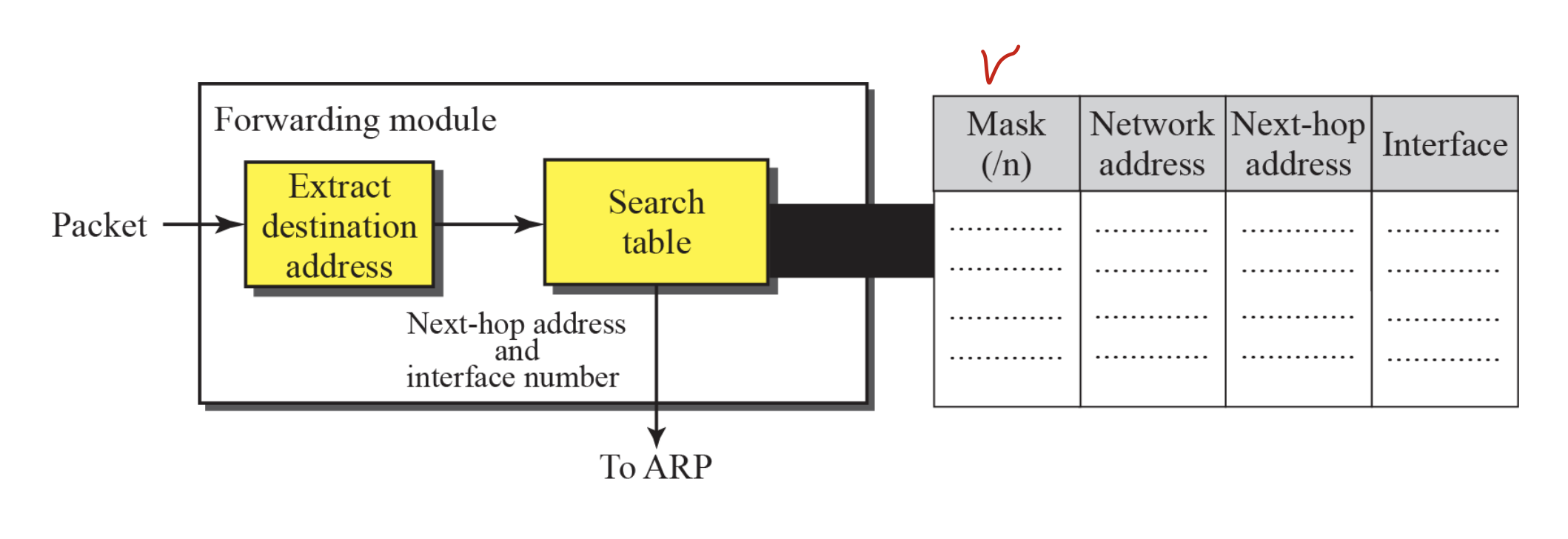
당연하게 MASK있어야지.

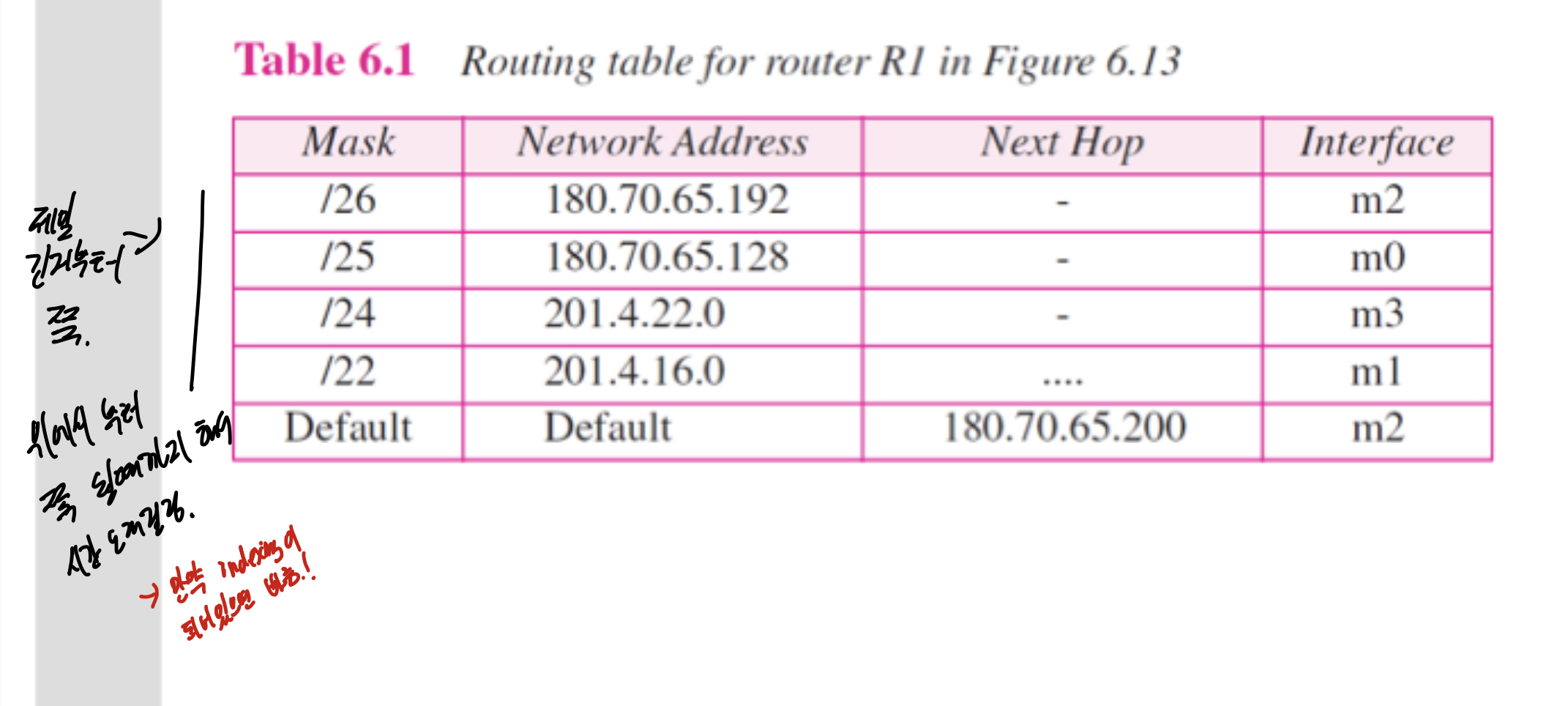
이젠 그럼 1번그림, classless로 라우팅 테이블을 만들어보자.
간단하다. Mask 숫자만 앞에 넣어주면 된다.
중요한건 제일 긴거부터 순서대로 넣어준다는 것이다. 그리고 위에서부터 맞는거 찾을때까지 검사하기 때문에 오래걸린다는 단점이 있다(classful은 클래스마다 나눠놓았기 때문에 비교적 빠르다). 라벨링하면 빨라지는데, 이건 뒤에서 나온다.

도착지 주소가 주어졌을때, 찾는 문제이다.
주어진 도착지 주소에 대해 라우팅 테이블 처음부터 쭉 보면서 마스킹 하고, 네트워크 주소 맞는거 있으면 next-hop address랑 interface 가지고 ARP로 감.
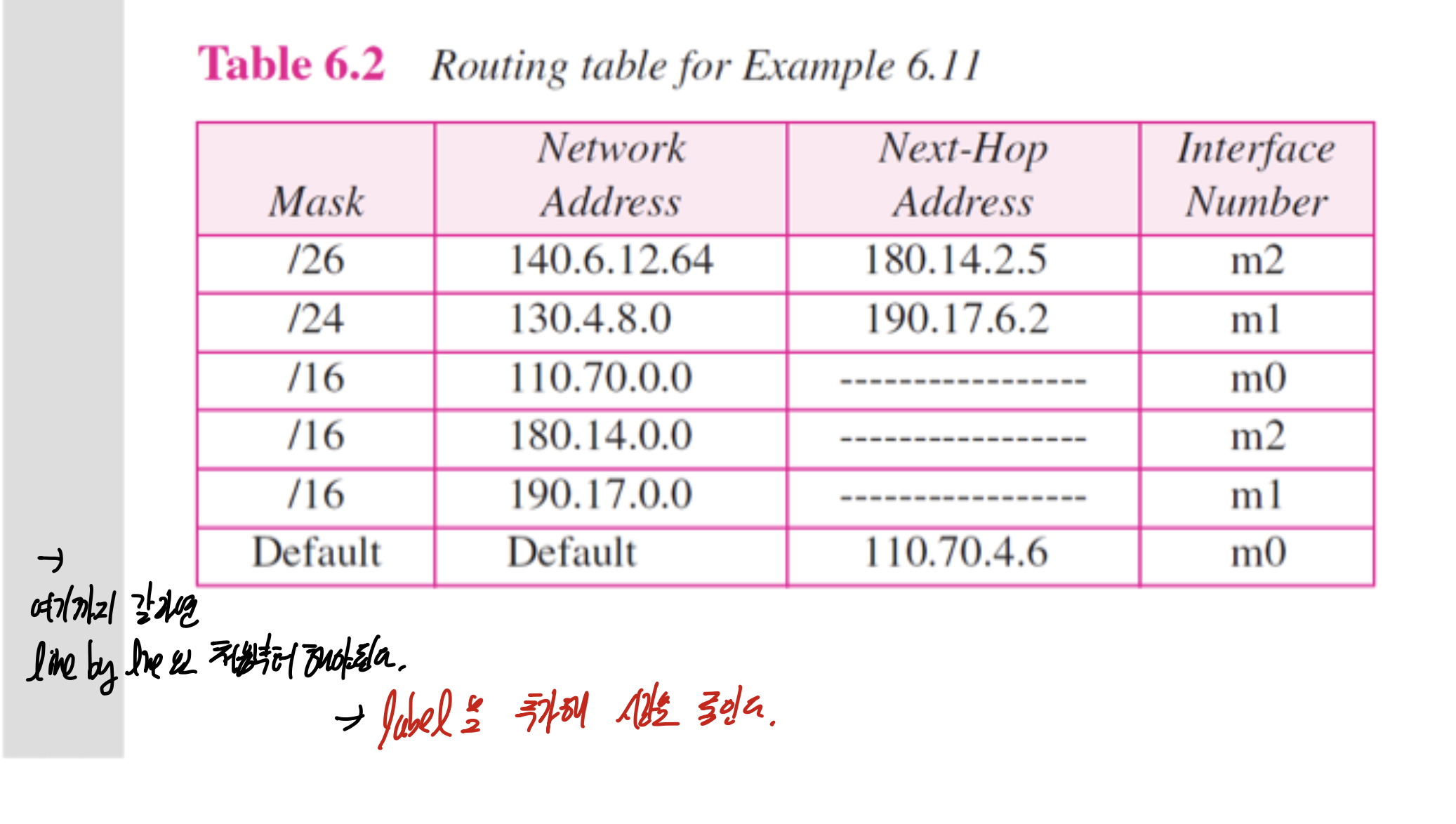
이제 테이블 보고, topology 만드는거.
일단 direct부터 봐야된다. 라우터가 포함된 네트워크 들이니까.
그래서 그 다이렉트 세개 먼저 만들어준다. 그 다음, next hop 찍힌거 만들어주고, default 만들어 주면되는데, 무조건 사이사이에 라우터 들어가는거 까먹으면 안된다.
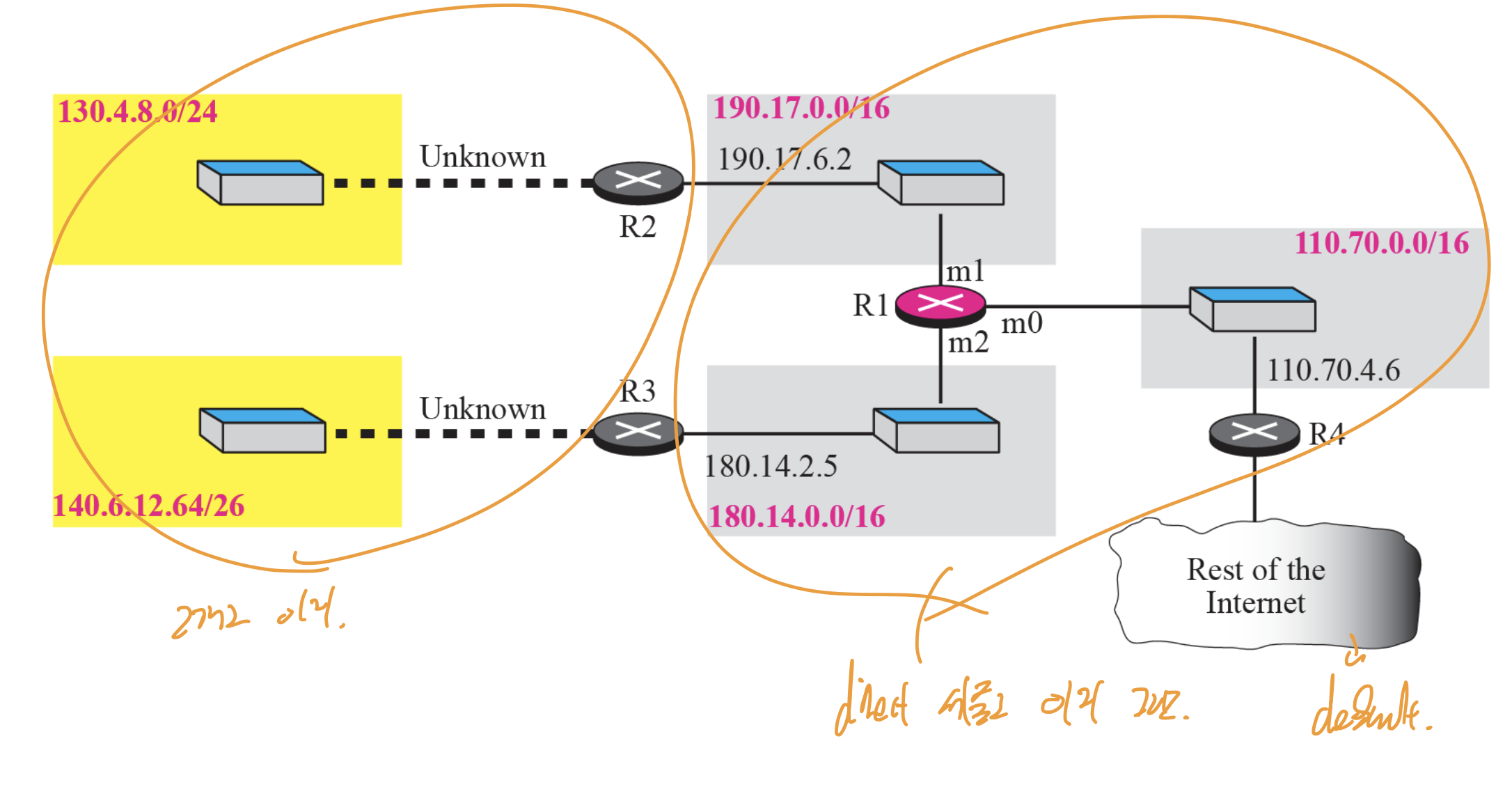
우선 R1, R2가 direct하게 연결되어 있지 않다는 가정.
그렇다면 R2에서 m0, m1, m2, m3에 해당하는 주소가 목적지 주소로 찍혀서 받았을때, 굳이 이걸 나눠서 해줄 필요가 없다.
그러므로 이 모든 그룹(서브넷)을 한번에 모아줘서 한방에 적어준다.(여기선 서브넷 4개 -> /26 에서 /24로 바꿈.)
aggregation
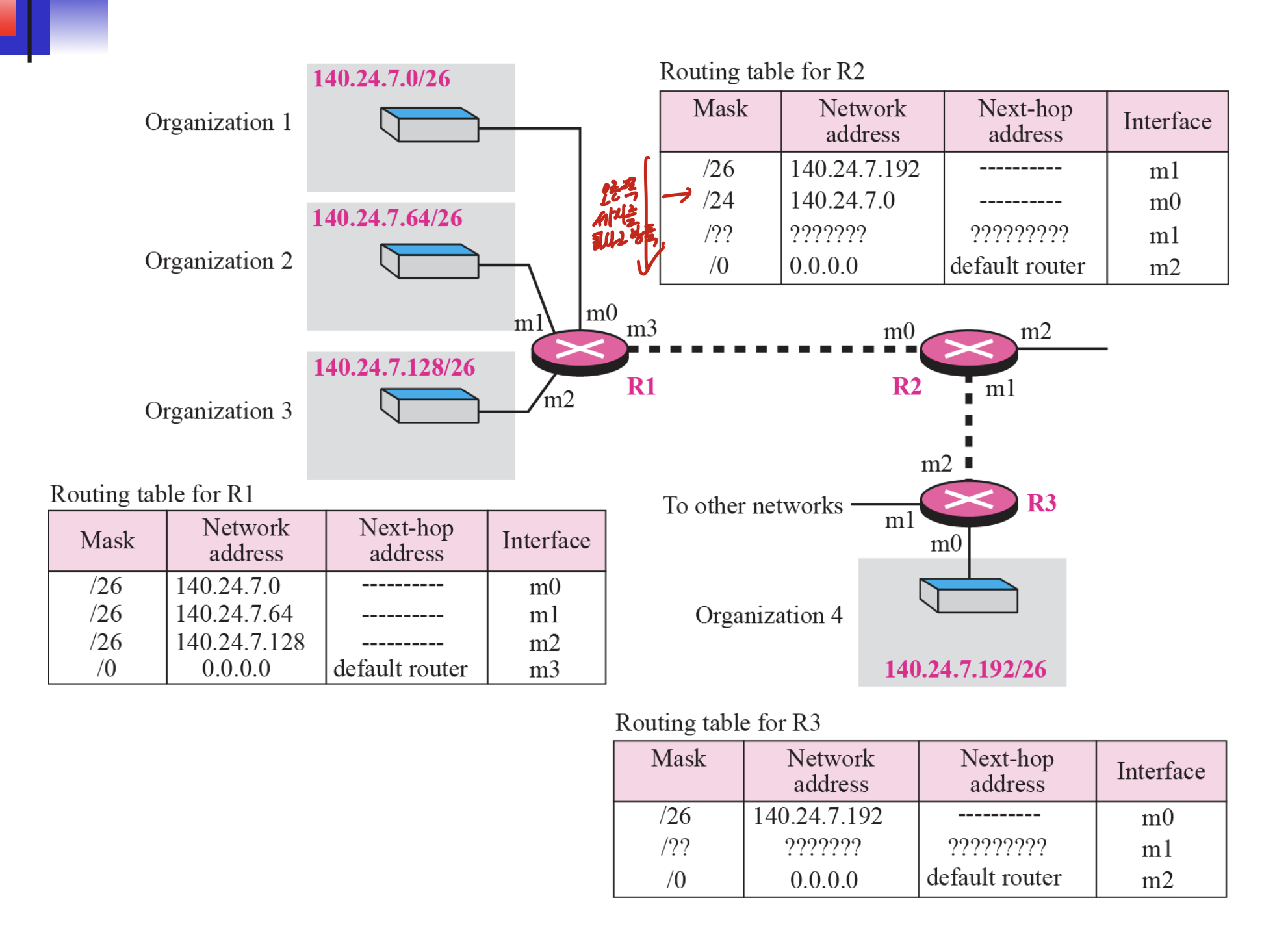
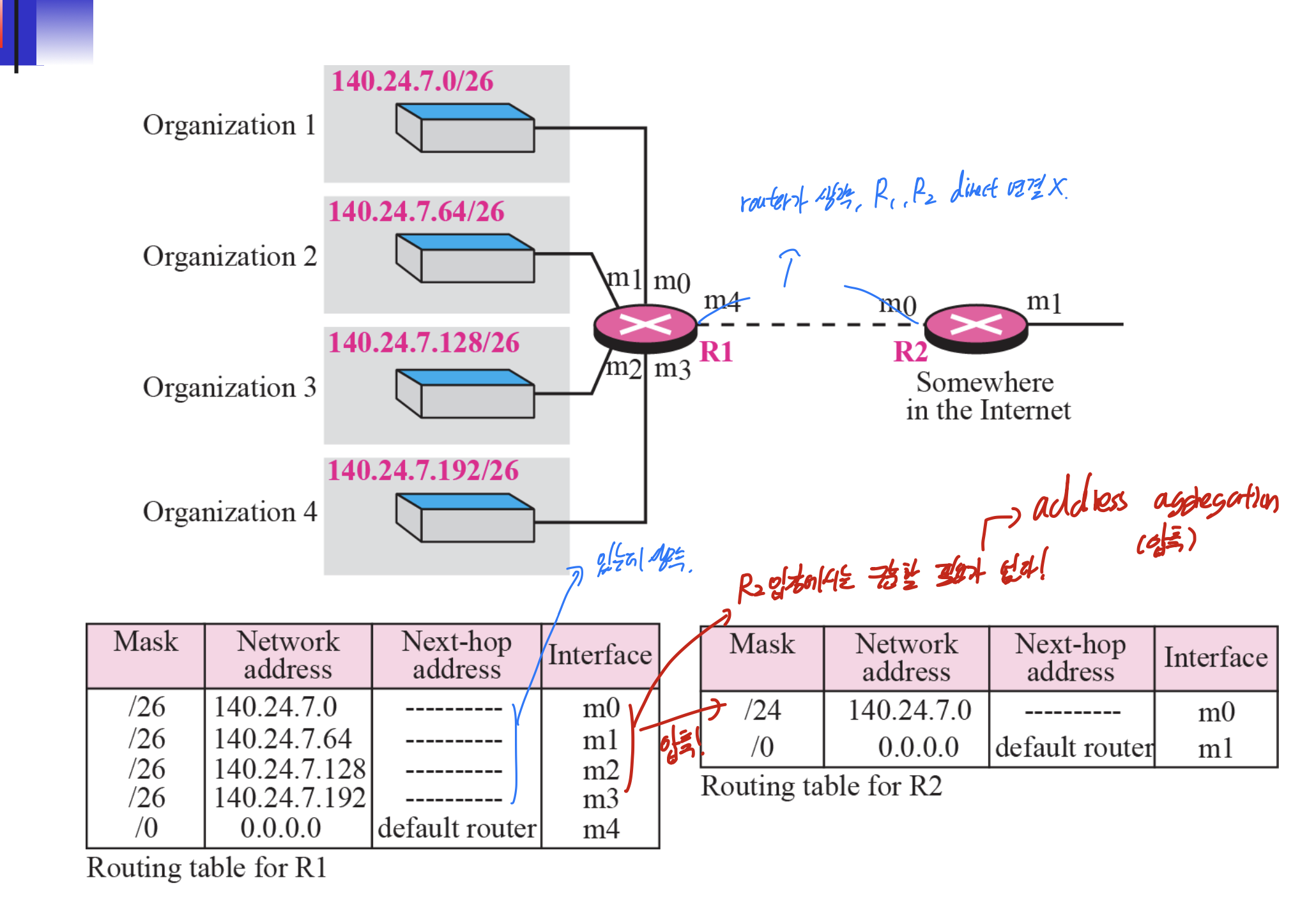
aggregation을 쓰면 좋은거
일단 R1, R2. R2, R3는 indirect이다.
여기서 R2가 140.24.7.~~/26을 도착주소로 받았다 하면, 일일히 확인하지 않으면 m1으로 갈지 m0으로 갈지 모른다고 생각할 수 있다.
aggregation을 해놨으면, 무조건 mask가 긴 것부터 비교한다. 그러므로 서브넷을 aggregation해놓은 것을 뒤에 비교가 된다.
그러므로 걱정하지 않아도 된다.
delivery, forwarding, routing 전과정 쓰기
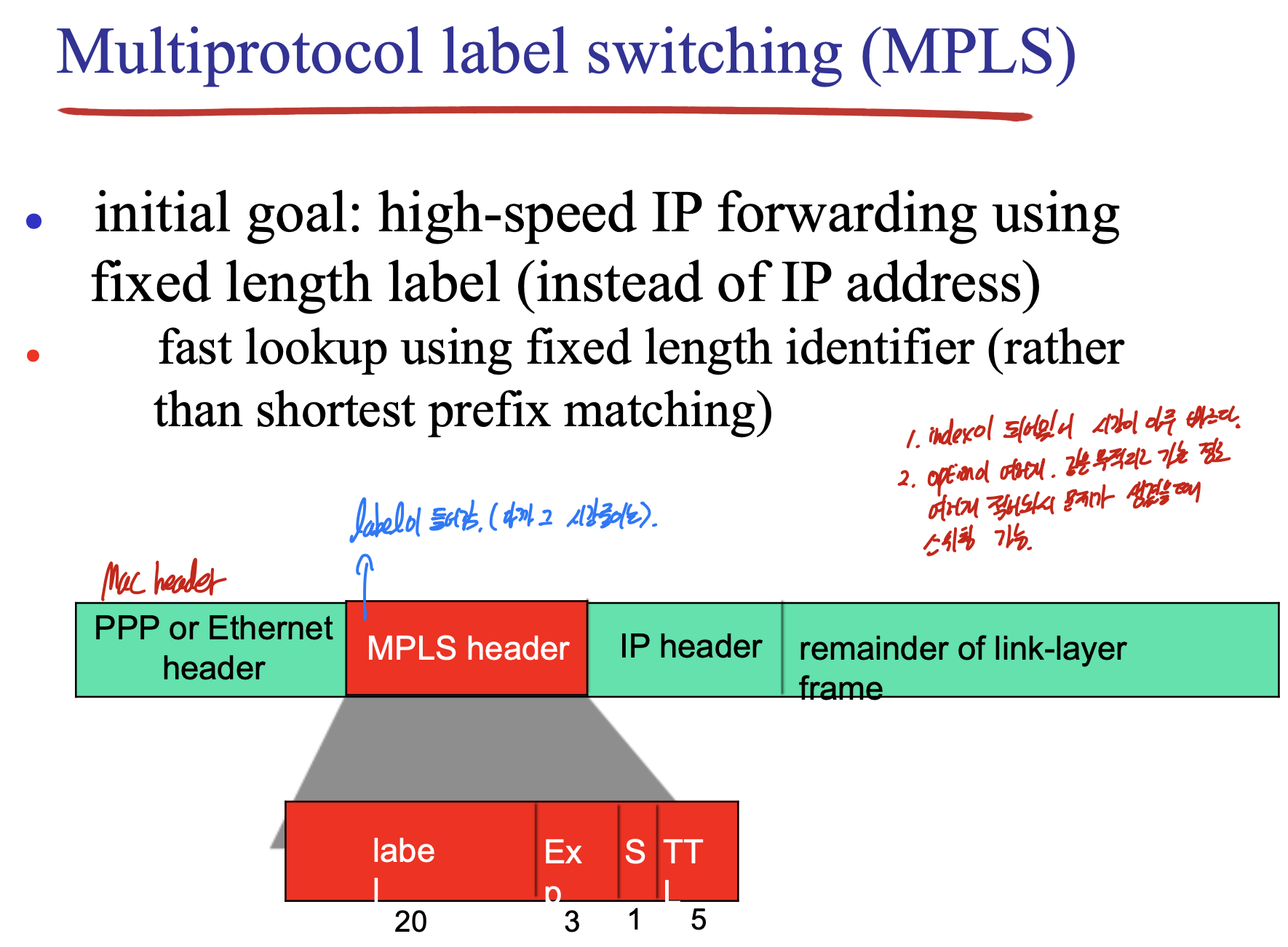
index가 되어있어서 시간이 아주 빠르다.
option이 여러개, 같은 목적지로 가는 경로 여러개 적어놔서 문제가 생겼을때 스위칭 가능.
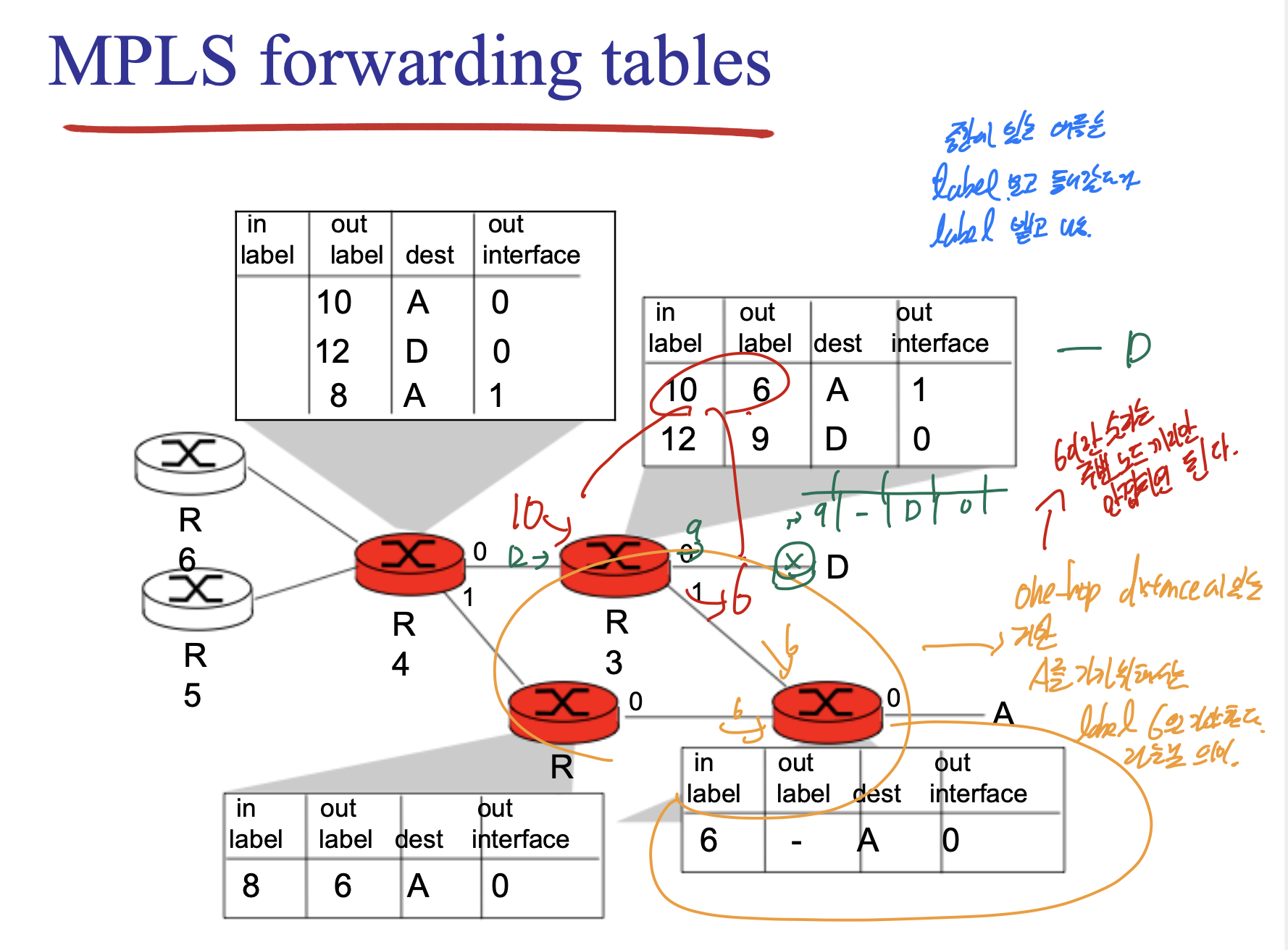
one hop distance만 적어놓음.
CH07. IP
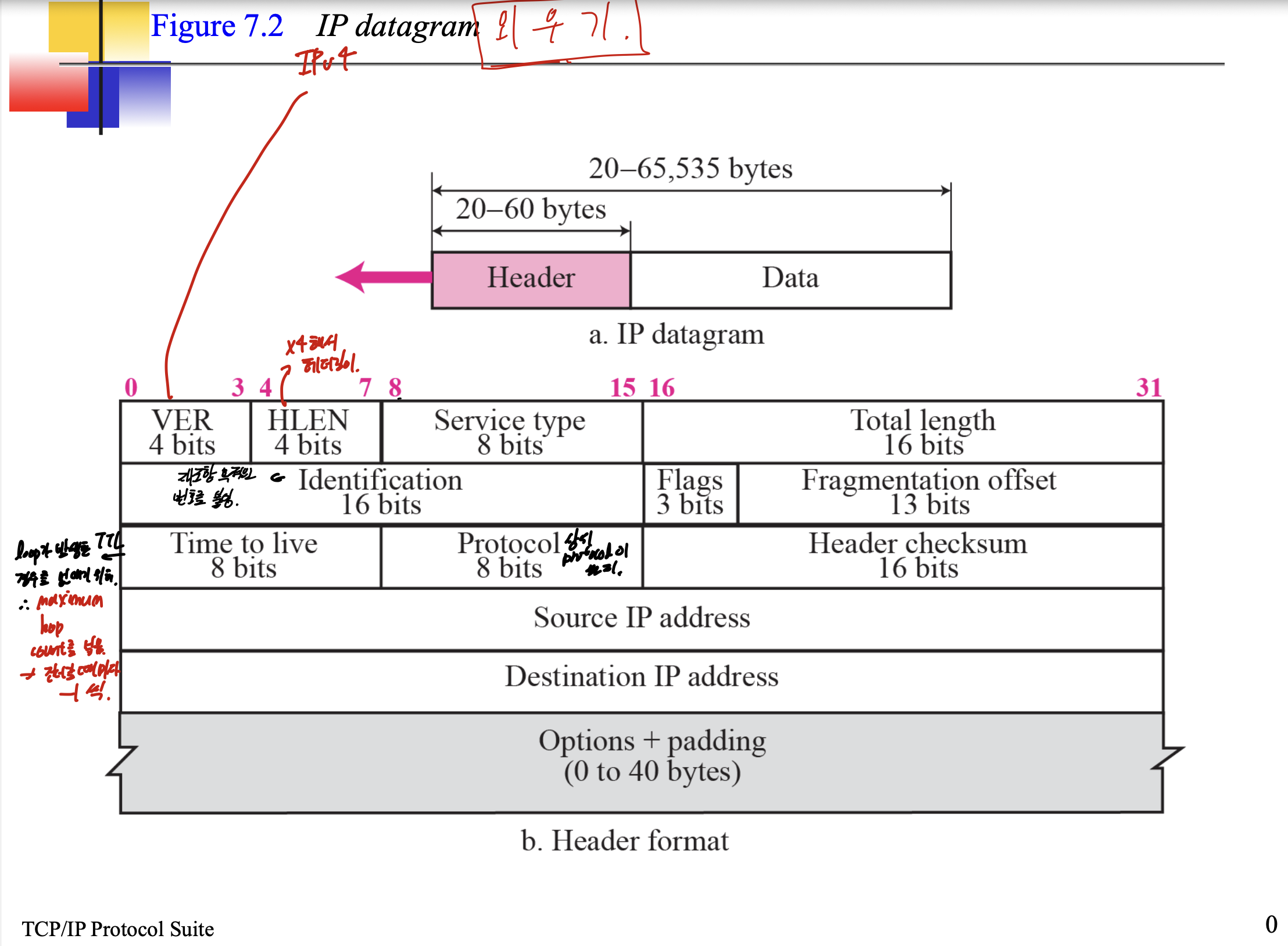
datagram은 헤더와 데이터로 구성되어 있음.
헤더는 20~60바이트. 20이 최소
밑에 다 외우기
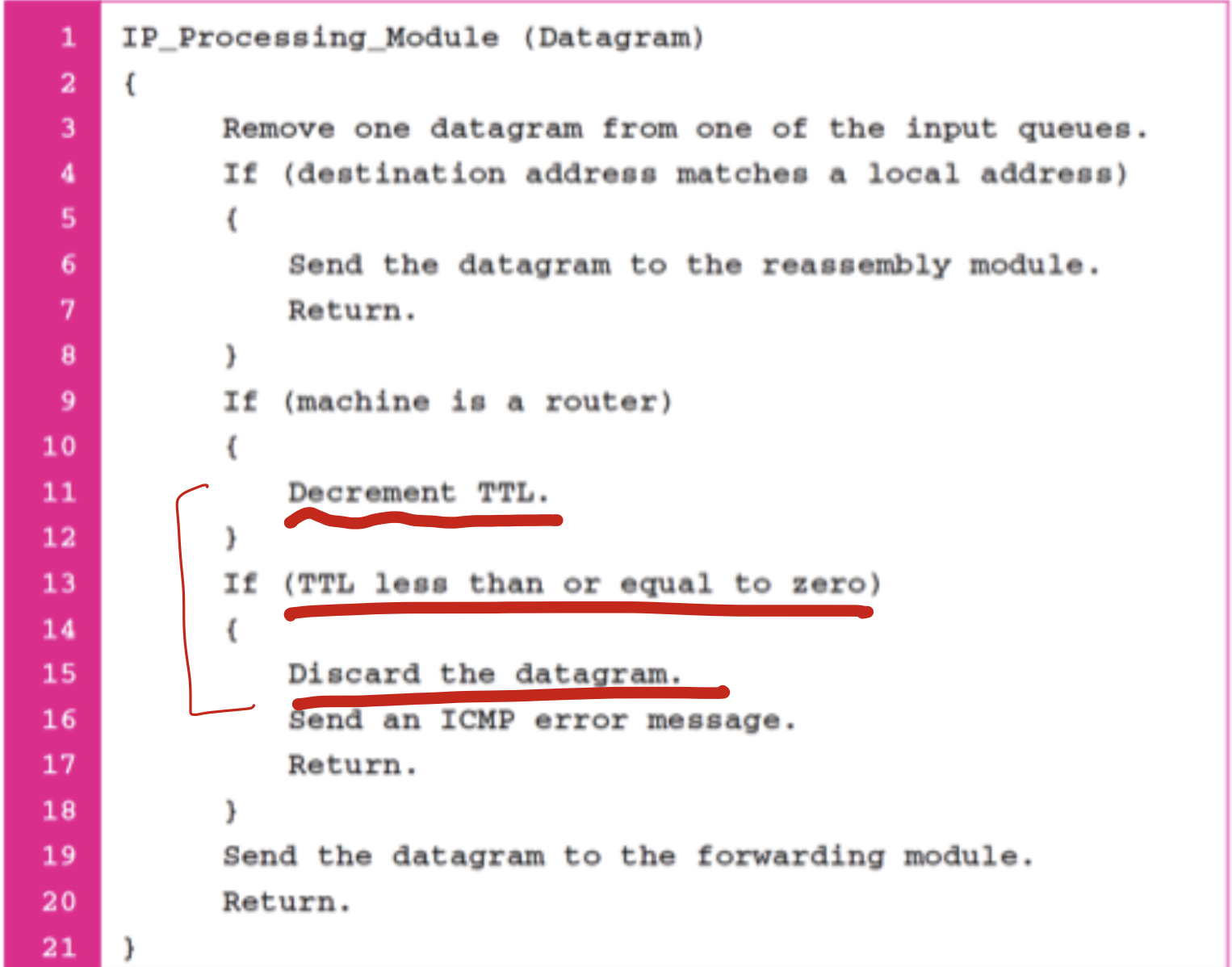
TTL(Time to live) -> loop가 발생하는 경우를 없애기 위해 Maximum hop count를 넣음. -> 건너갈때마다 -1씩.
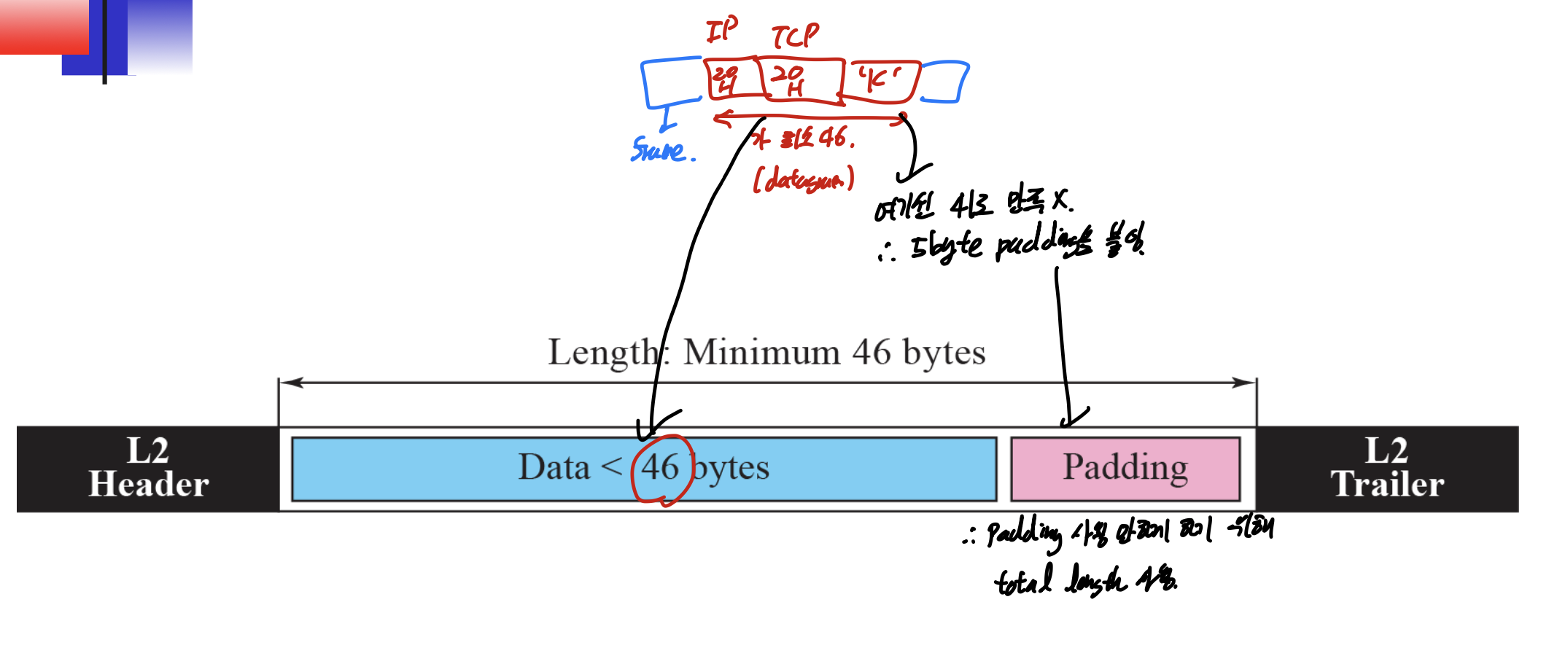
frame 구조이다.
안에 datagram이 들어가 있는데, 이는 IP header 20, TCP header 20을 포함해 최소 46 바이트가 있어야 한다.
만약 이 그림처럼 46바이트보다 작아 만족하지 못한다면, padding을 붙여준다.
padding을 사용 안하게 하기 위해 total length 사용한다? 이거 뭐임

IP packet의 첫 8개 비트정보이다.
앞에 4개는 버전, 뒤에 4개는 HLEN이다.
header의 길이는 최소 20인데, 여기선 2 -> 8로 번역이 된다. 그러므로 문제가 있으므로, 이 패킷은 버린다.

1000이면 8, 고로 헤더가 32바이트 이다.
이러면 첫 20바이트는 base header, 나머지 12바이트는 옵션이라고 한다.

5/16, 28/16이다.
헤더가 20바이트 , 전체가 40바이트 이므로 데이터의 크기는 20바이트 이다.

16진수로 나타냈다. 하나가 4비트 이다. how many hops라고 했으므로 TTL을 봐야한다. TTL이 1이므로 hop은 한번만 가능하다.
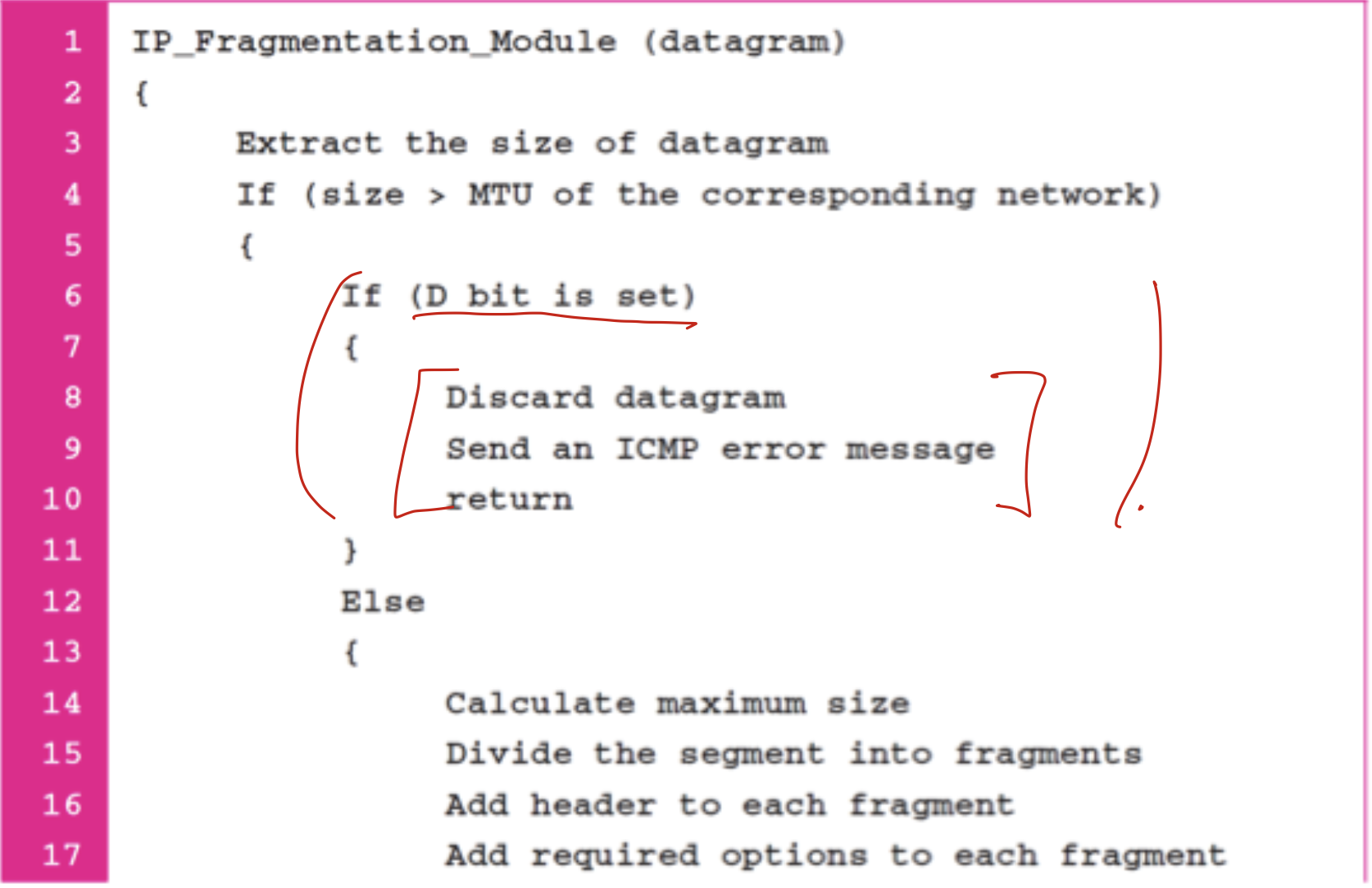
Fragmentation
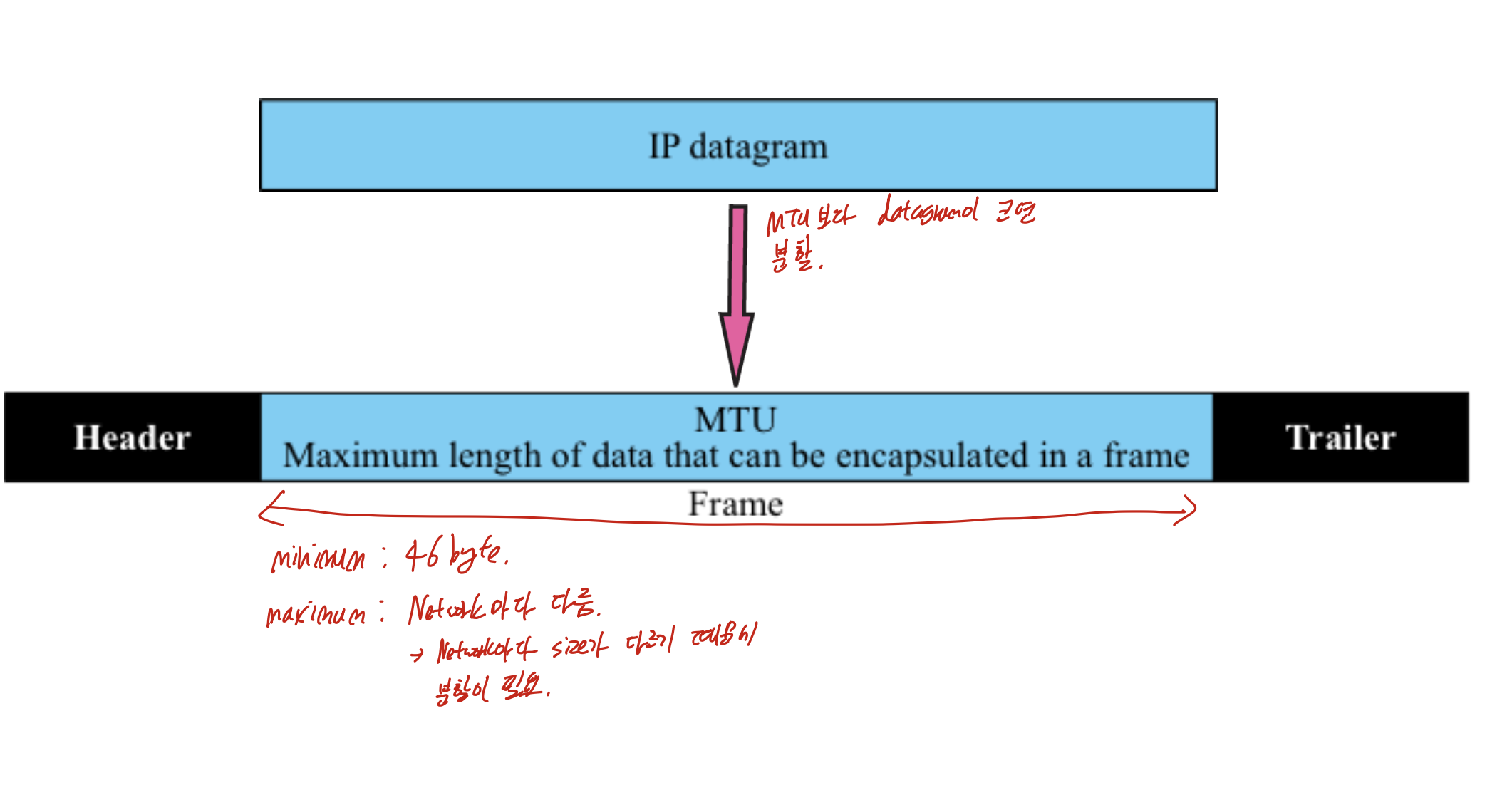
datagram을 frame에 넣어주는데, MTU보다 datagram이 더 크면 분할한다.
MTU는 maximum size로, Network마다 다르다.

데이터만 짤린다!
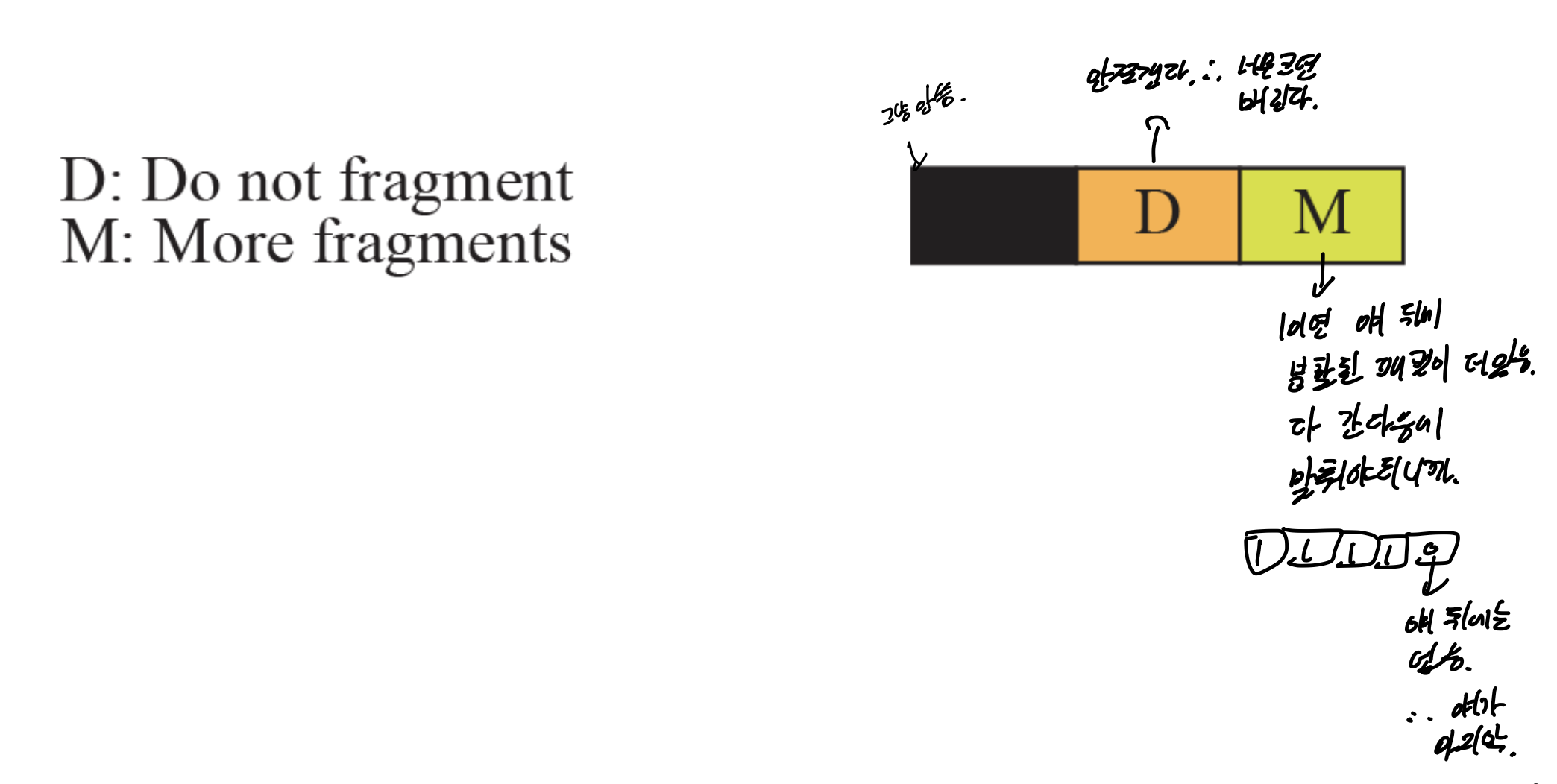
헤더에 flag 3비트에 대한 정보.
첫비트는 그냥 안쓰고, D랑 M으로 나눠져 있다.
D는 안쪼갠다는 것으로, 만약 MTU보다 큰게 들어오면 그냥 버린다.
M이 1이란 것은 얘 뒤에 분할한 패킷이 더 있다는 얘기다. 얘가 0이 되면, 그게 마지막이 된다.
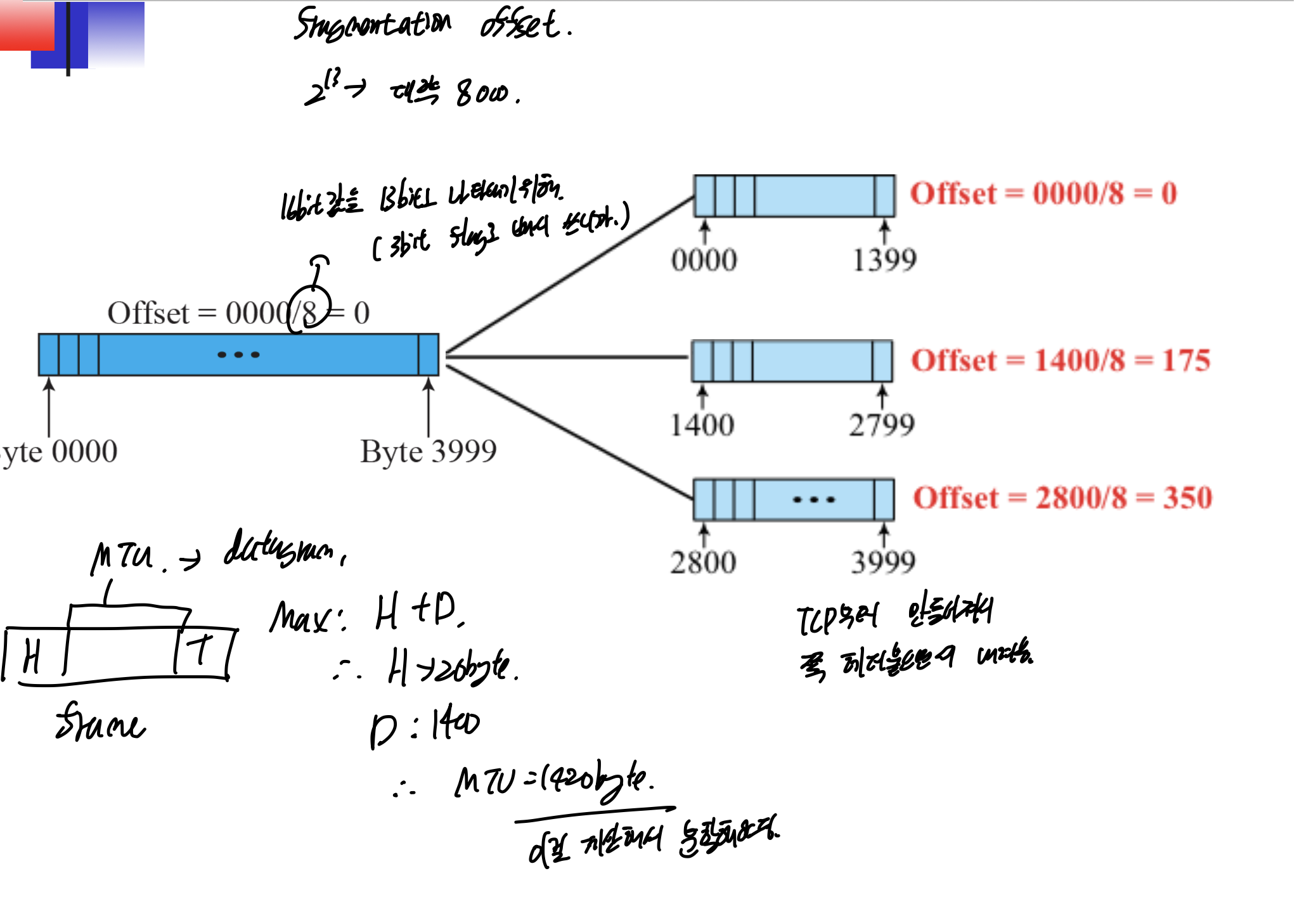
fragmentation offset이다.
16bit의 정보를(total length) 13비트에 넣어야 하므로, 8을 나누어서 넣는다.
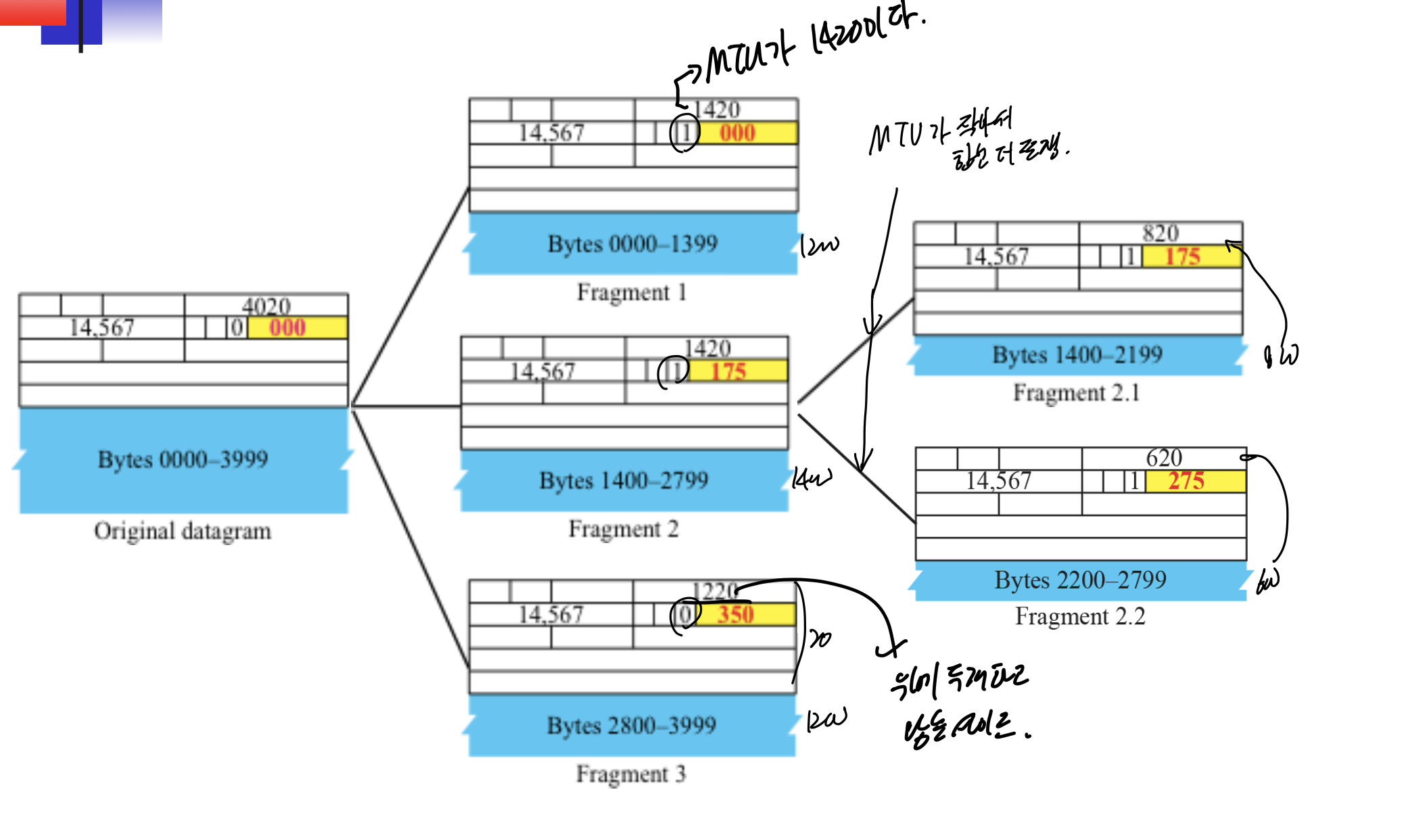
MTU 1420인건 일단 데이터 1400에 헤더 20 붙어서 1420이다.
offset을 보면 처음껀 0이고, fragment 2는 1400이 지난 후 부터 이기 때문에 1400/8 -> 175가 들어간다. fragment 3에 M flag가 0이고, offset이 350인것도 확인.
만약 offset 계산하라고 나오면, MTU - 헤더길이 가 데이터 이동한 양이고, 그걸 /8해서 더해주면 된다.

아까 m flag가 0이면 마지막이라고 했다. 근데 이게 분할된건지 아닌지는 모른다. 분할되지 않은 패킷은 last fragment라고 여겨진다고 한다.

m 1인데 offset 0이니까 첫번쨰.

플래그 정보 없이 , offset만 오면 일단 *8 하여 데이터의 시작 번호는 알 수 있다. 800이다. 마지막 번호는 모른다.

offset 100, HlEN 5, total length 100이다.
HLEN이 5이므로 헤더는 20이다. 그러므로 이 패킷의 데이터의 길이는 80이라는 것을 알 수 있다.
offset 100이므로 800부터 시작한다. 그러므로 800~879이다.
Option

20빼고 나머지 옵션
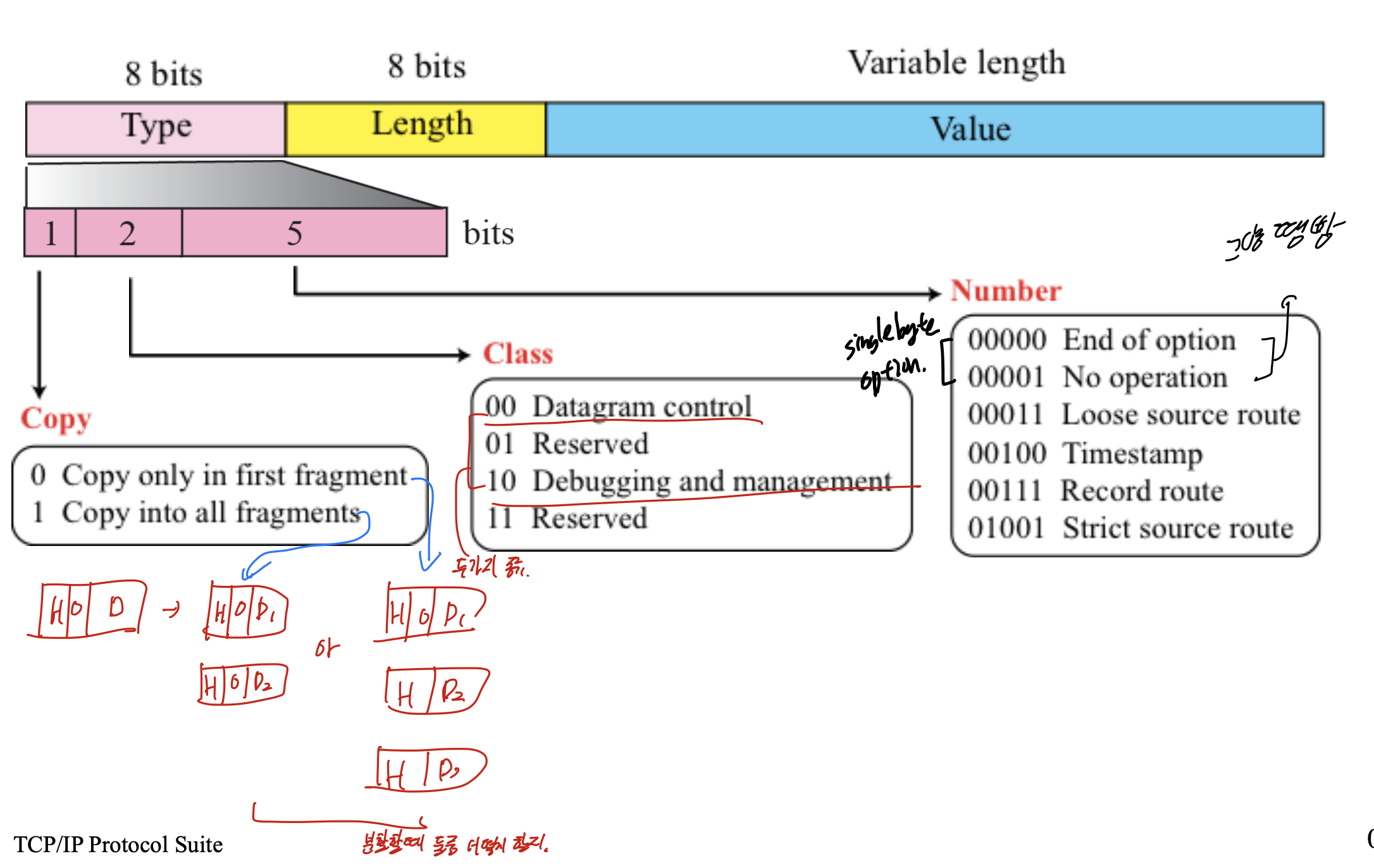
옵션의 구성이다.
첫 1바이트는 Copy에 대한 정보이다.
0일때는 분할되었을때 오직 첫 fragment에만 옵션을 복사해 넣고,
1일때는 모든 fragment에 옵션을 넣어준다.
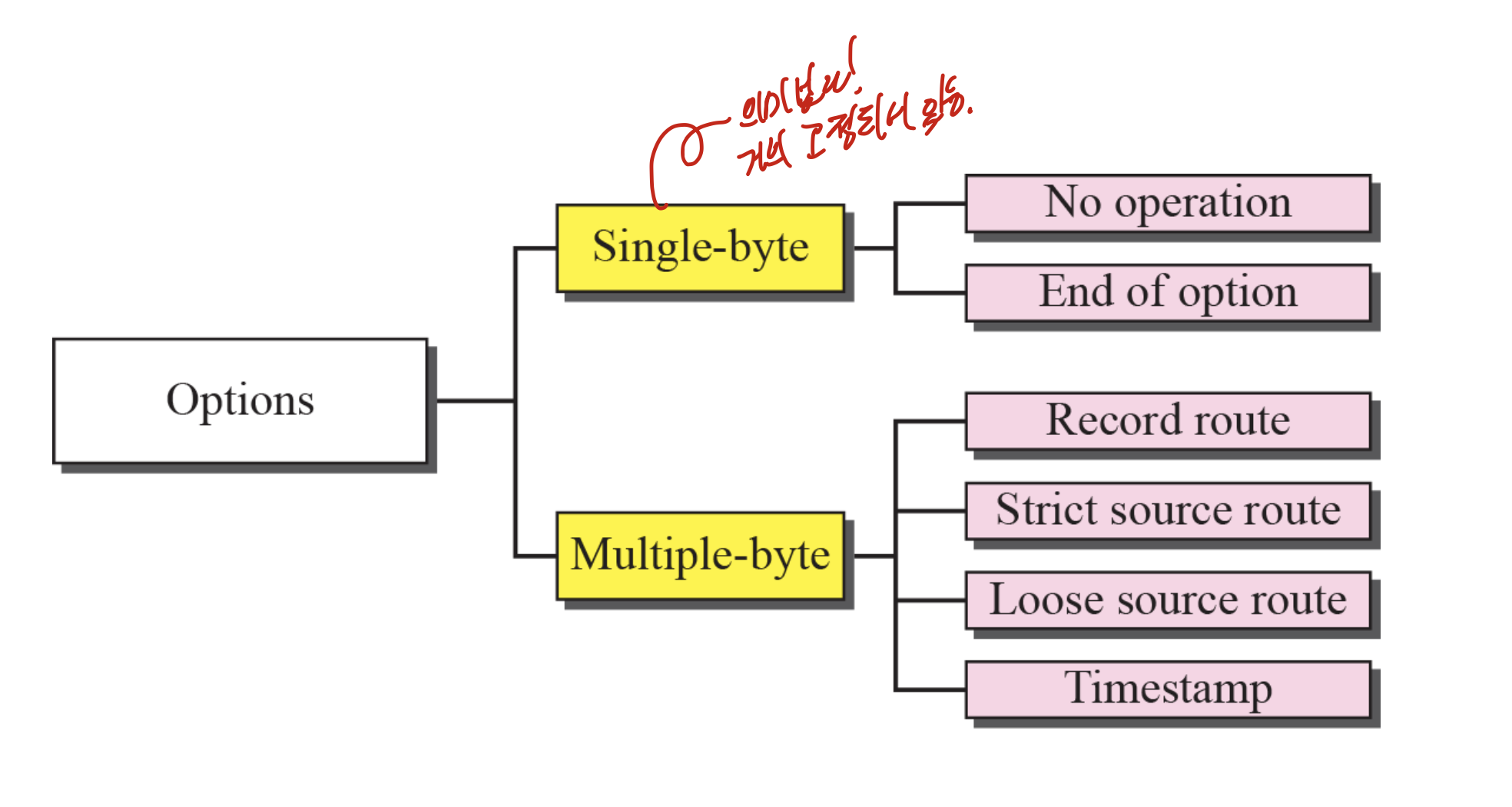
저 single byte option은 땜빵용이다.
record route
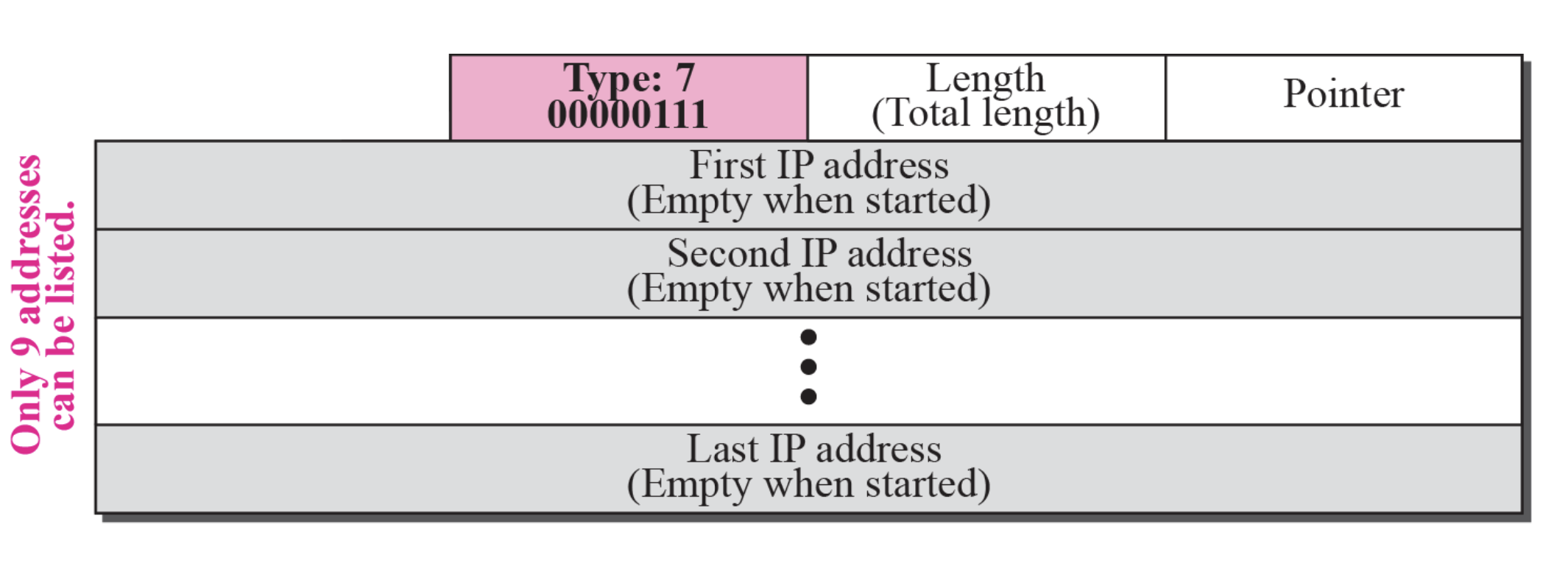
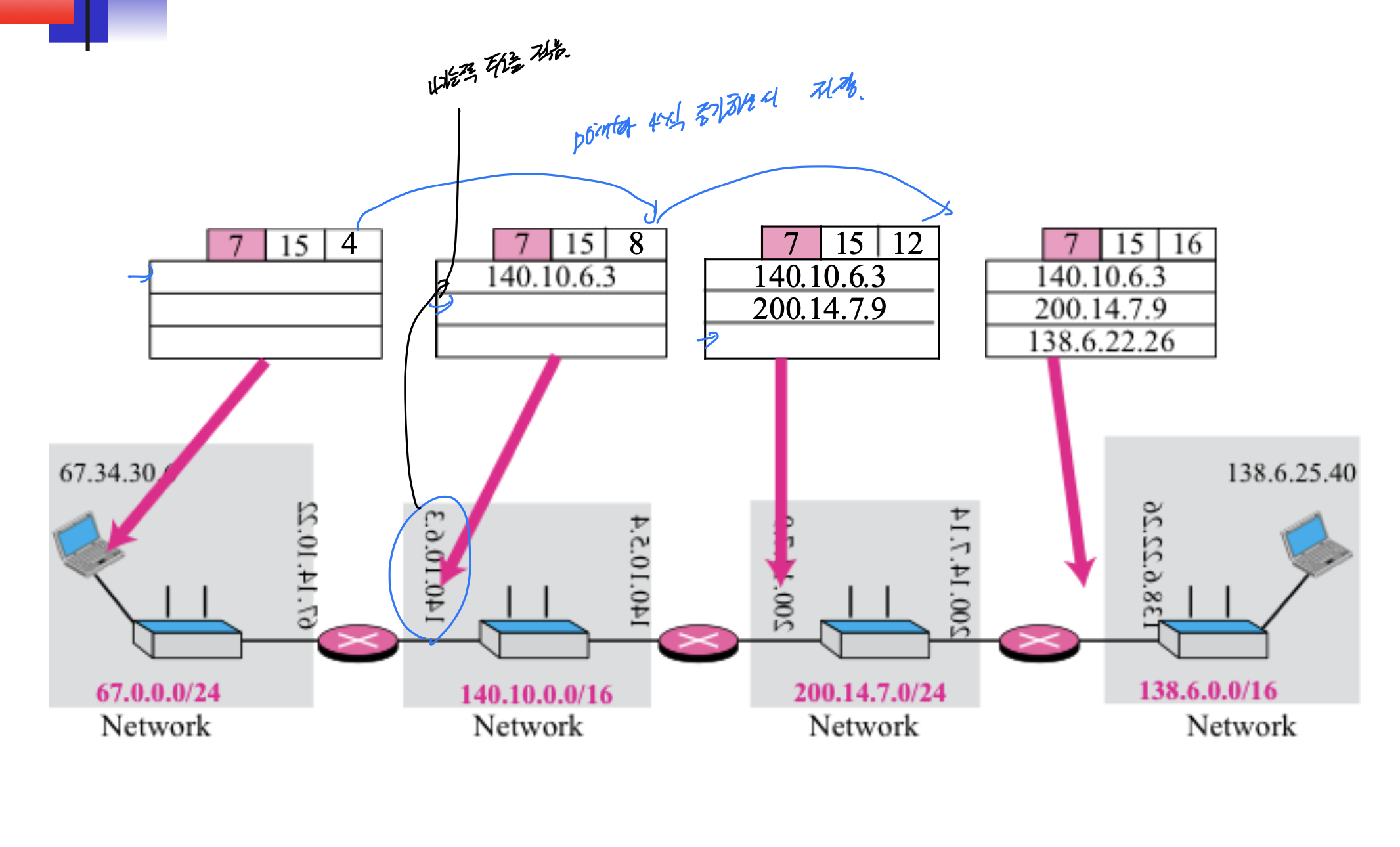
이렇게 나가는쪽 주소를 저장해주고, 포인터를 4씩 증가시켜주는게 기본 개념이다.
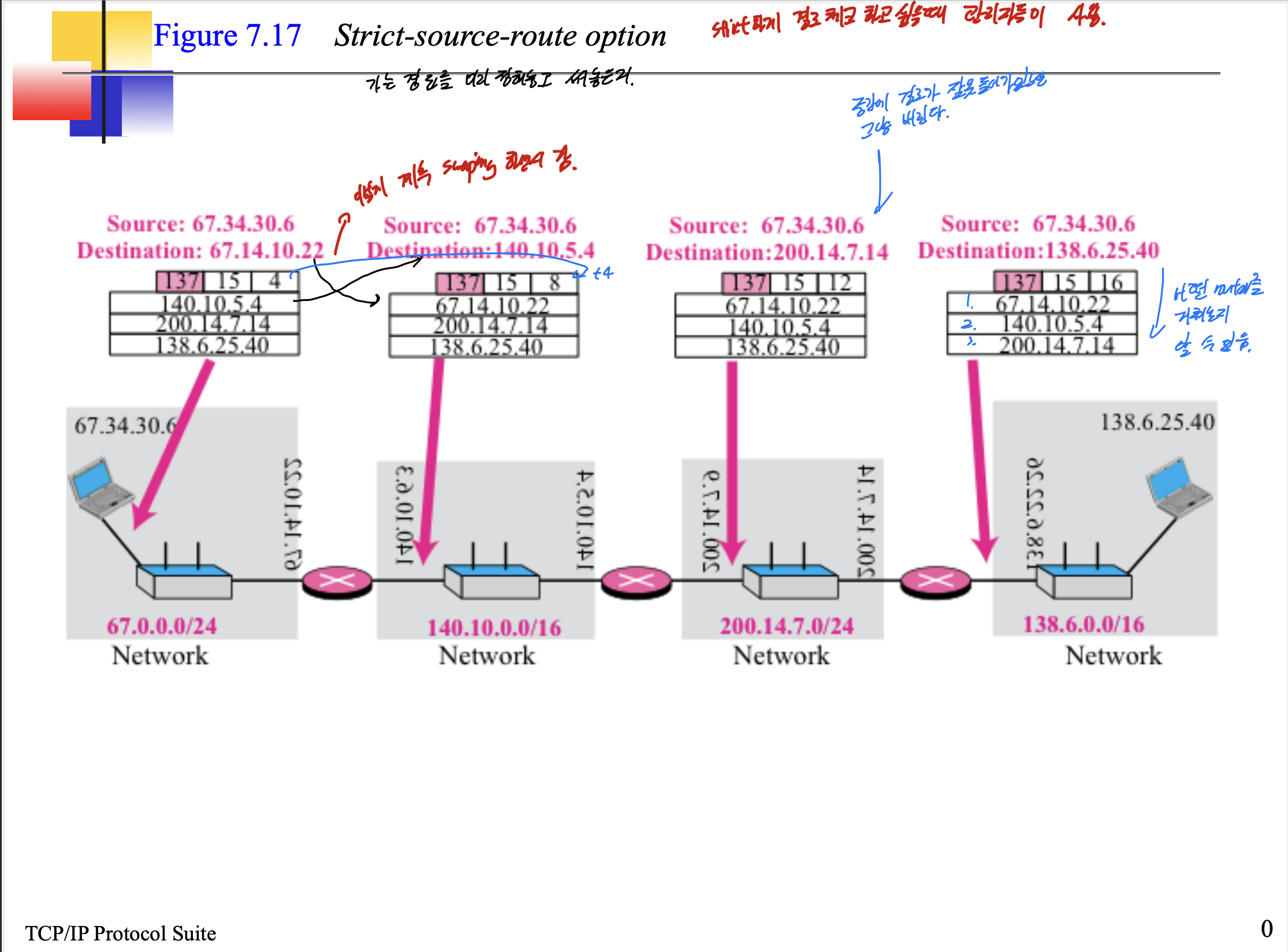
Strict source route option이다.
이건 미리 가는 경로가 다 정해져 있는 것 이다.
strict하게 경로를 체크하고싶은 관리자들이 주로 사용한다.
중간에 경로가 잘못 들어가있으면 그냥 버리고, 이전 네트워크의 도착주소 정보를 다음 테이블에 갔을때, 그 네트워크의 도착주소가 적혀 있던 곳에 다시 적기 때문에 어떤 경로를 거쳐서 왔는지 알 수 있다.
loose source route option
timestamp option
어디서 어디로 갈때, 누굴 거쳐서 가는지 확인하기 위해.

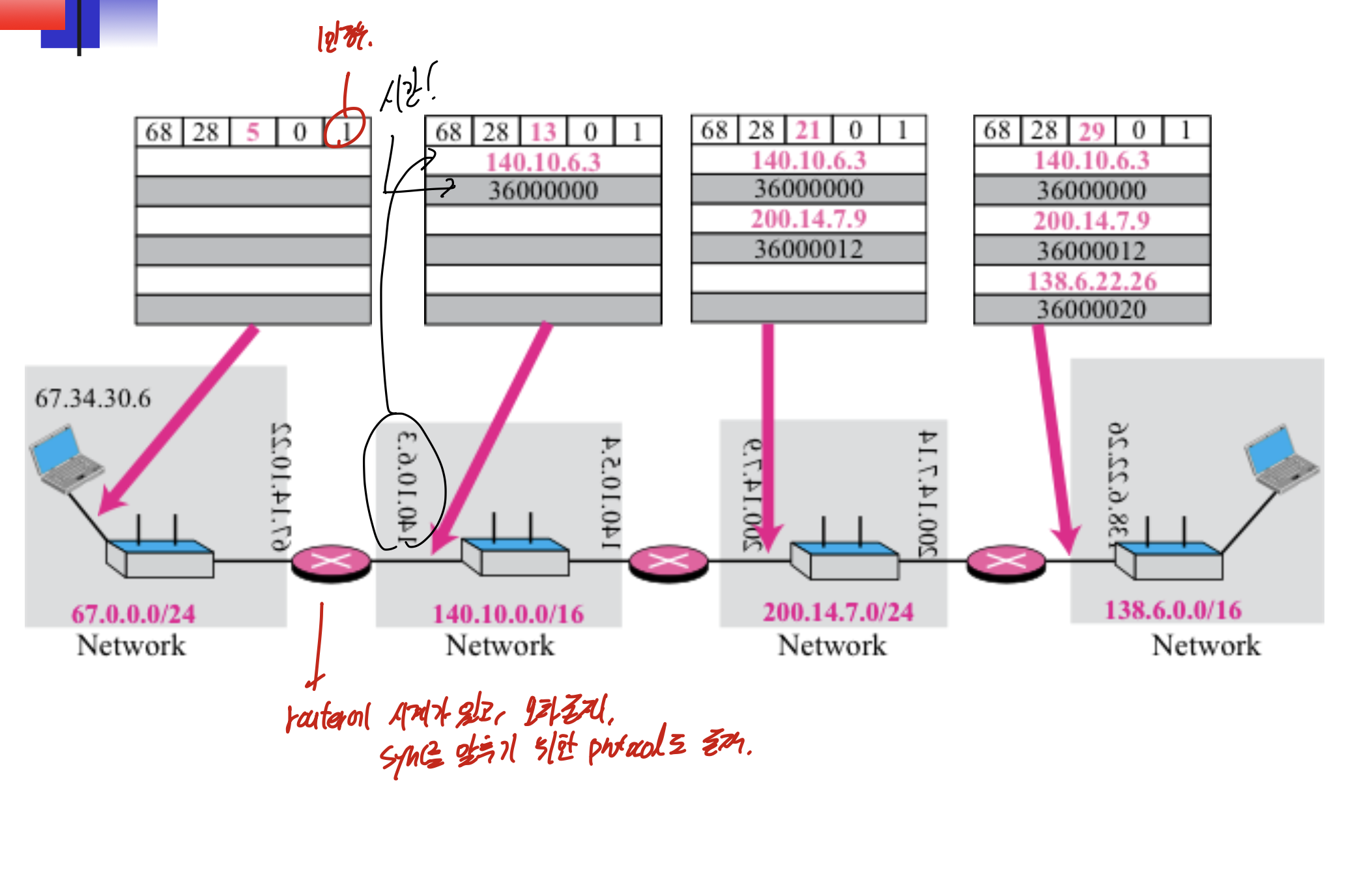
밑은 1일때, 즉 timestamp를 적는 과정과 동시에 IP를 적는 과정이다.
딱 도착하면 그 도착지 주소랑, 시간 적는다.


이거 뭔가 나올거같은데, Time stamp(2, 3번째 비트가 1 0)를 제외한 나머지는 datagram control을 위해 사용되고, Time stamp는 debugging and management control을 위해 사용된다.

띠용 첵썸할때 헤더만 본다고 한다. IP에서는
Package


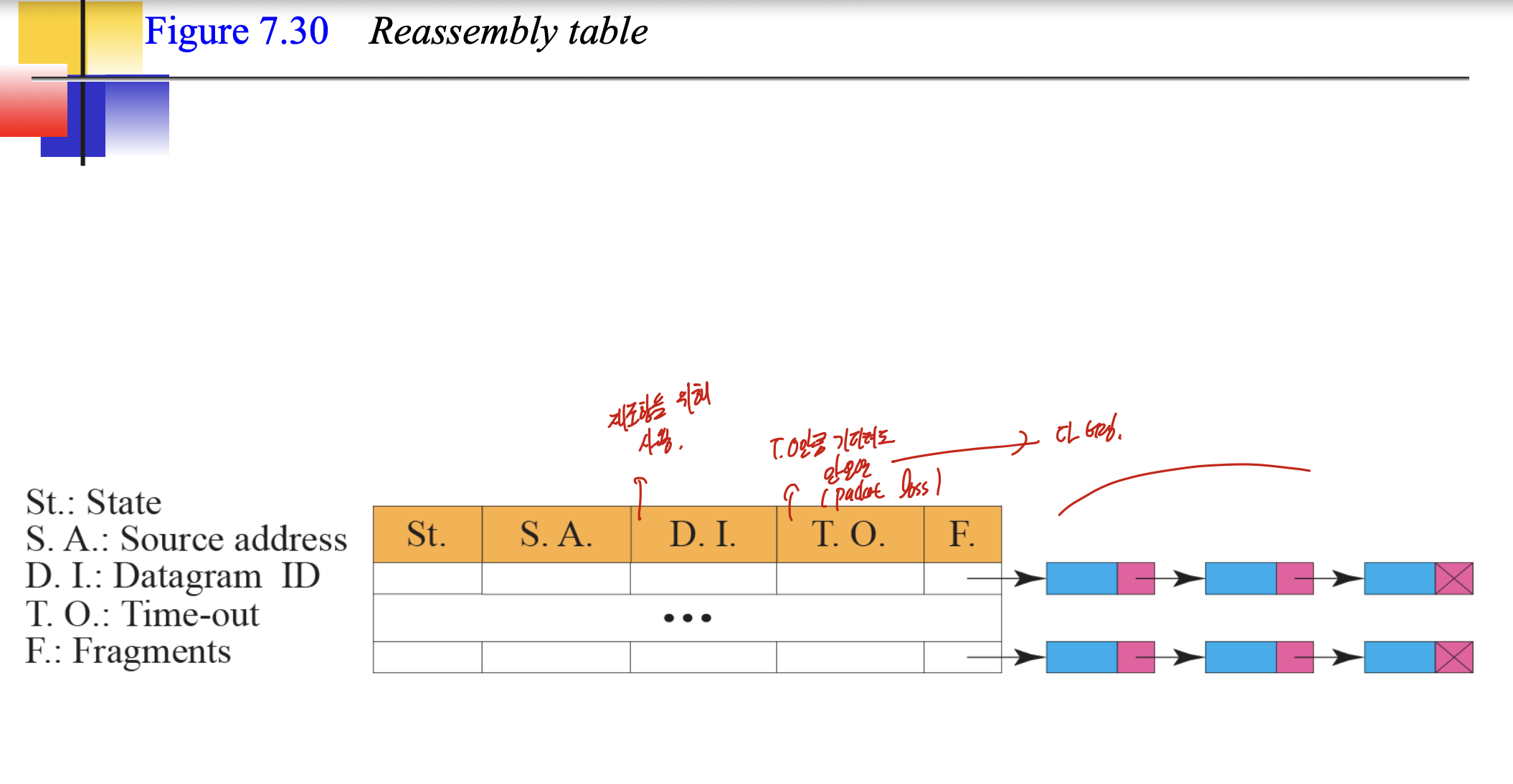
패킷 재조합을 위해서.

CH09 ICMP
IP에서는 따로 error를 탐지하지 않는다. 그래서 있는 프로토콜.
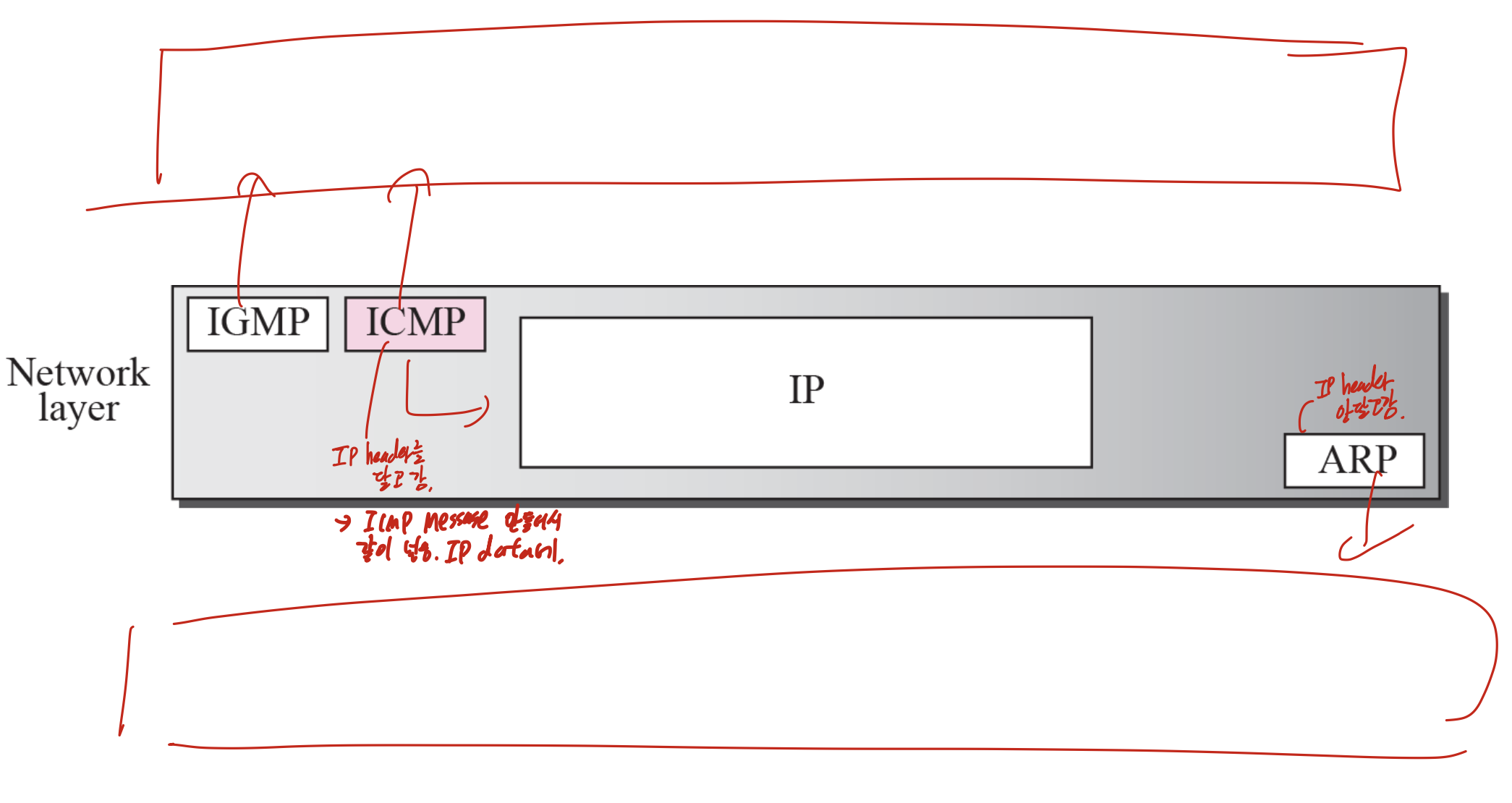
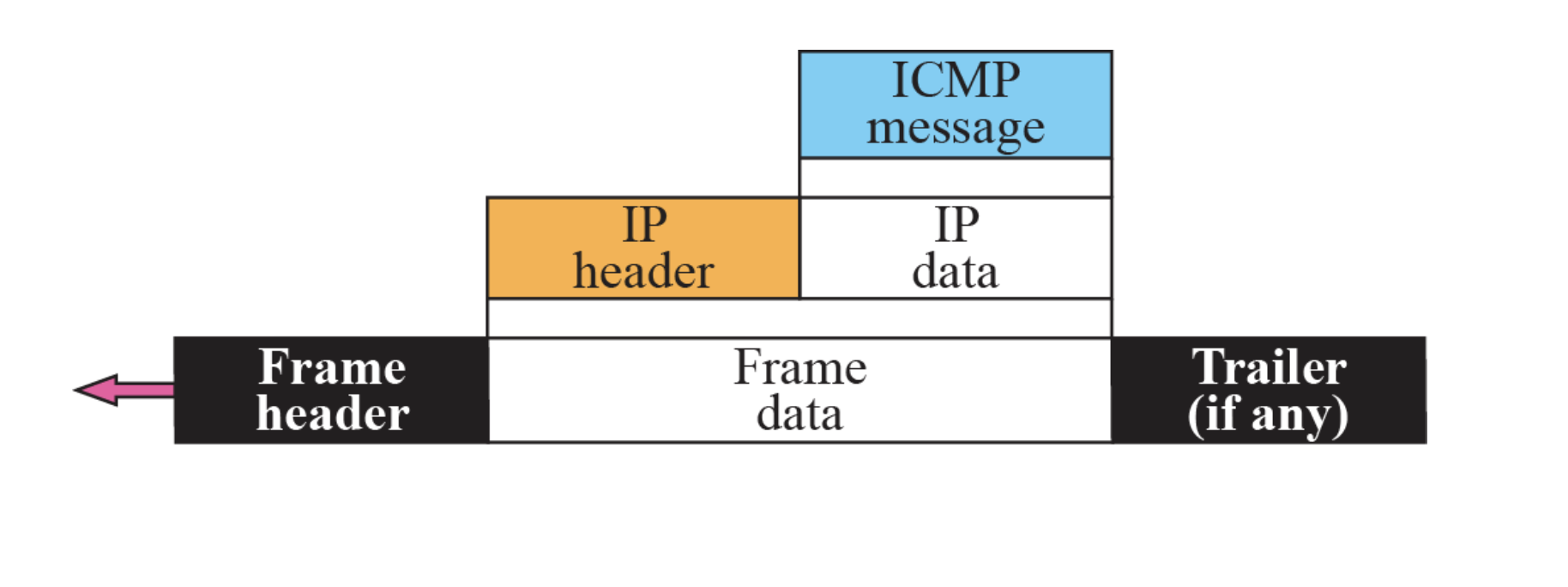
IP헤더는 ICMP를 달고 간다. ICMP message를 만들어서 IP data에 같이 넣는 것 이다.
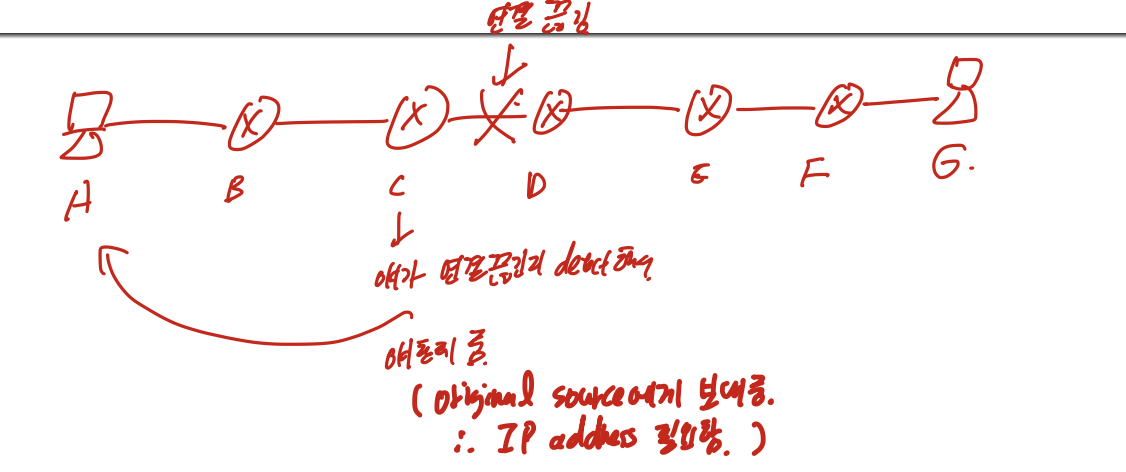
만약 C, D사이가 끊겼을때, c가 끊긴것을 detect하여 A에게 준다. (original source에게 보내줘야 하므로 IP address가 필요하다.)
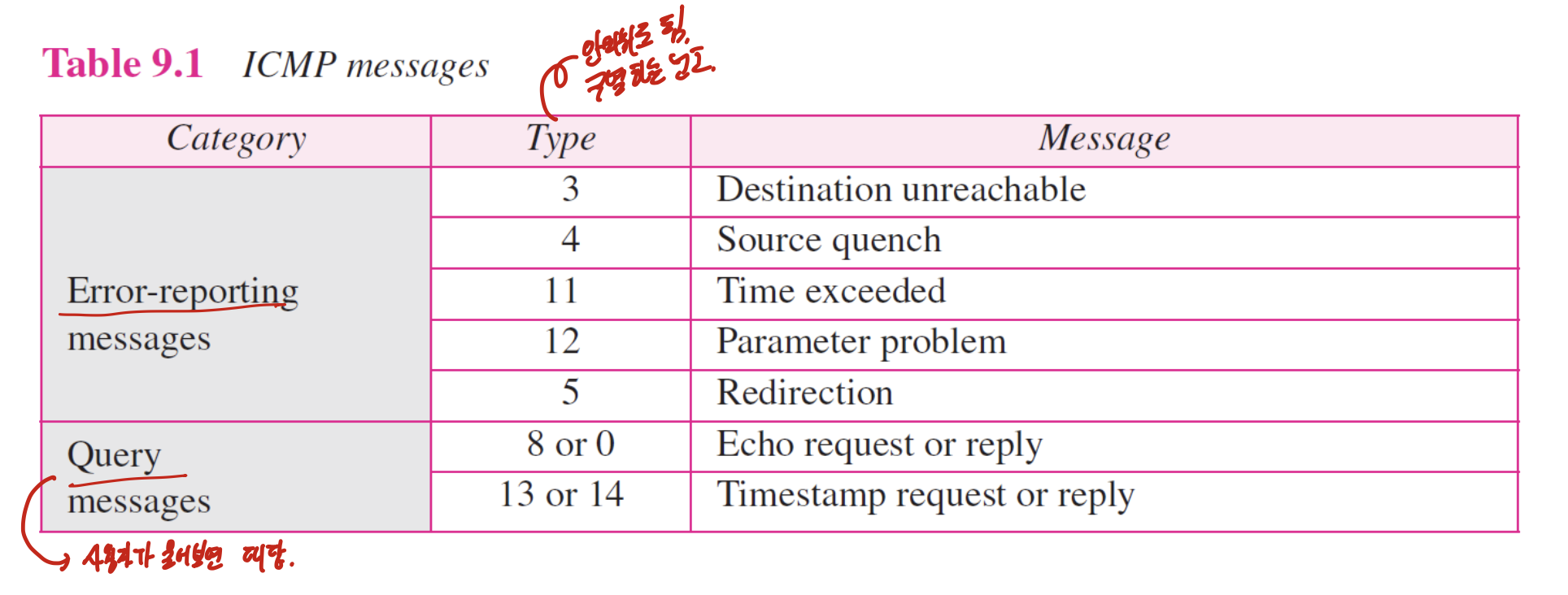
ICMP message는 두가지로 나뉜다.
Error reporting message -> 에러 알려줌
Query message -> 사용자가 물어보면 대답해줌
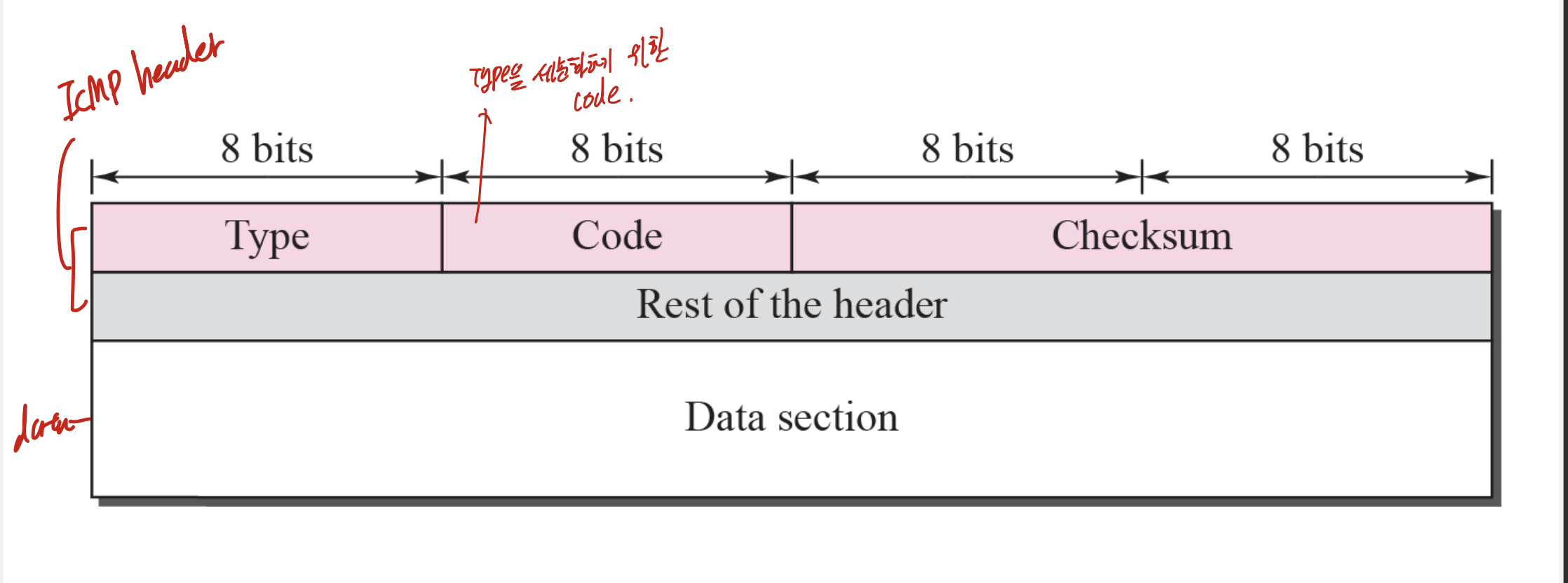
ICMP message의 구조로, 위에 두줄은 ICMP header에 해당하고, 밑은 data에 해당한다. 첵썸 있다!
type과 그것을 세분화 할 code로 나뉘어져 있다.

ICMP는 항상 original source에 error message를 보낸다.
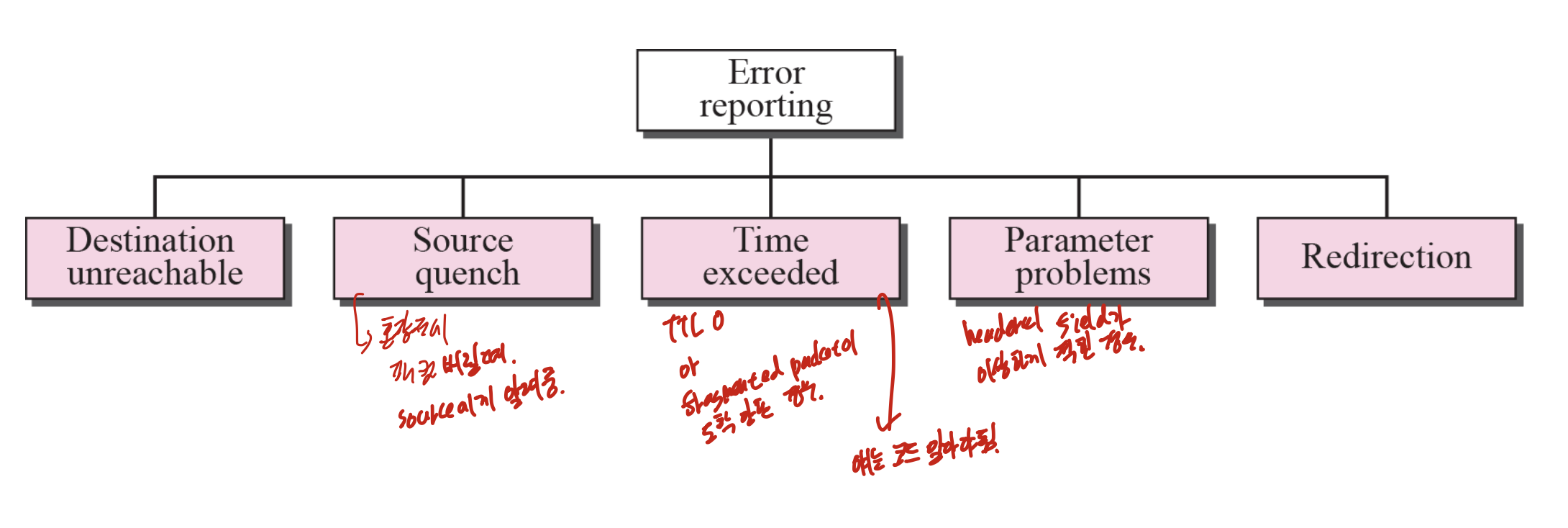
Destination unreachable -> 목적지 도달 불가.
Source quench -> 혼잡제어시에 패킷을 버릴때, source에게 알려주는 것 이다.
Time exceeded -> TTL이 0이 되었을때, 또는 fragmented packet이 도착하지 않았을때(얘도 타이머 키니까)
Parameter problem -> header의 field가 이상한 경우
redirection -> 새로운 경로 있을때인데, 이거 뒤에서 자세히 함.
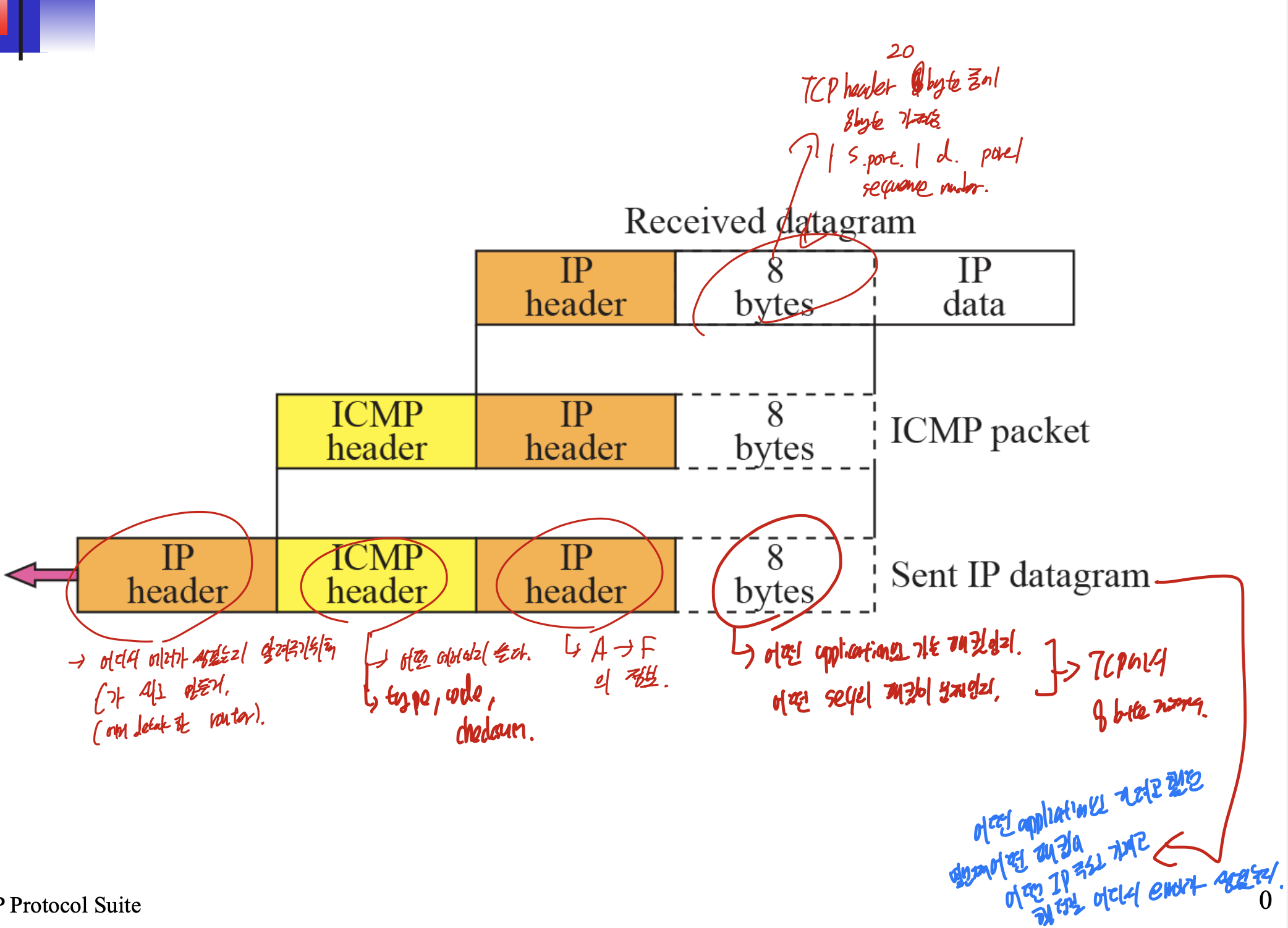
우선, 첫번째 IP header는 에러를 Detect한 곳에서 어디서 에러가 생겼는지 알려주기 위해 새로 만든 것 이다. ICMP header에는 어떤 에러인지, type, code, checksum이 들어간다. 그 다음 IP header에는 원래 정보, original source에서 destination까지의 정보가 들어간다. 그 다음 8byte에는 TCP의 Source port, dest port, sequence number의 정보가 들어온다.
어떤 어플리케이션으로 가려고 했던 몇번째 어떤 패킷이 어떤 아이피 주소로 가려고 했던게 어디서 에러가 생겼는지.


flow control이나 congestion control은 TCP에서는 하는데 IP에서는 안한다.
Destination unreachable


코드 2, 3을 가진것은 destination host에서, 나머지는 다른 라우터에서 만들어질 수 있다고 하는데, 케이스 바이 케이스 라는 것만 알아두면 되나.
Source quench

혼잡제어일때 버려진 패킷이 나왔을때, 그 정보를 가지고 가서 혼잡제어를 하도록 하는것이 이것의 목표이다. 하지만, IP에서는 혼잡제어를 하지못하고, TCP에서 한다.

버려지는 패킷 각각에 대한 error message를 전부 보내준다.
Time exceeded

이전에 봤던것 처럼 TTL 0되면 패킷을 버린다. 그리고 source에게 time exceeded message를 보내주는 것 이다.

만약 도착지가 모든 fragment를 받지 않았고 정해진 시간이 지났다면, 지금까지 받은거 다 버리고 time exceeded message 를 original source에게 보내준다.
Parameter problem
라우터나 목적지 호스트한테서 만들어짐.
Redirection message
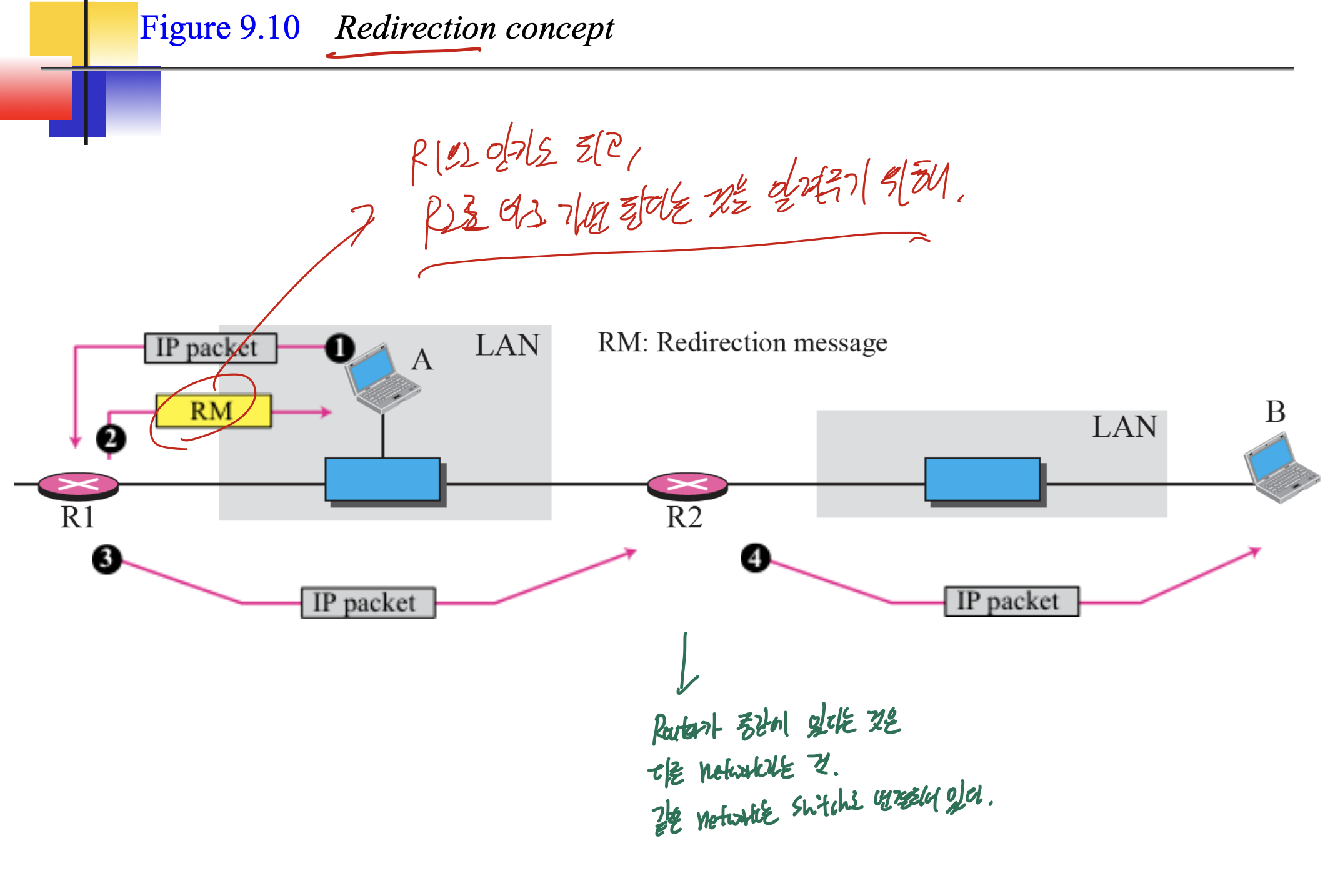
A에서 B로 갈때, 그냥 R2로 보내주면 되는데 R1을 통해 보내주는 경우가 있다. 그렇다면 R1에서 A에게 Redirection message를 보내주어 다른 경로가 낫다고 알려준다.
라우팅 테이블은 redirection message와 같은 방법으로 계속 업데이트가 된다.


Redirection message는 이전 그림과 같이 A, R1, R2가 전부 같은 네트워크에 있는 경우에 보내줄 수 있는 것 이다.
query message - echo request, reply


내 컴퓨터가 네트워크에 붙어있는지, 상대방 컴퓨터에서 내 컴퓨터로 올 수 있는지!
timestamp request, reply
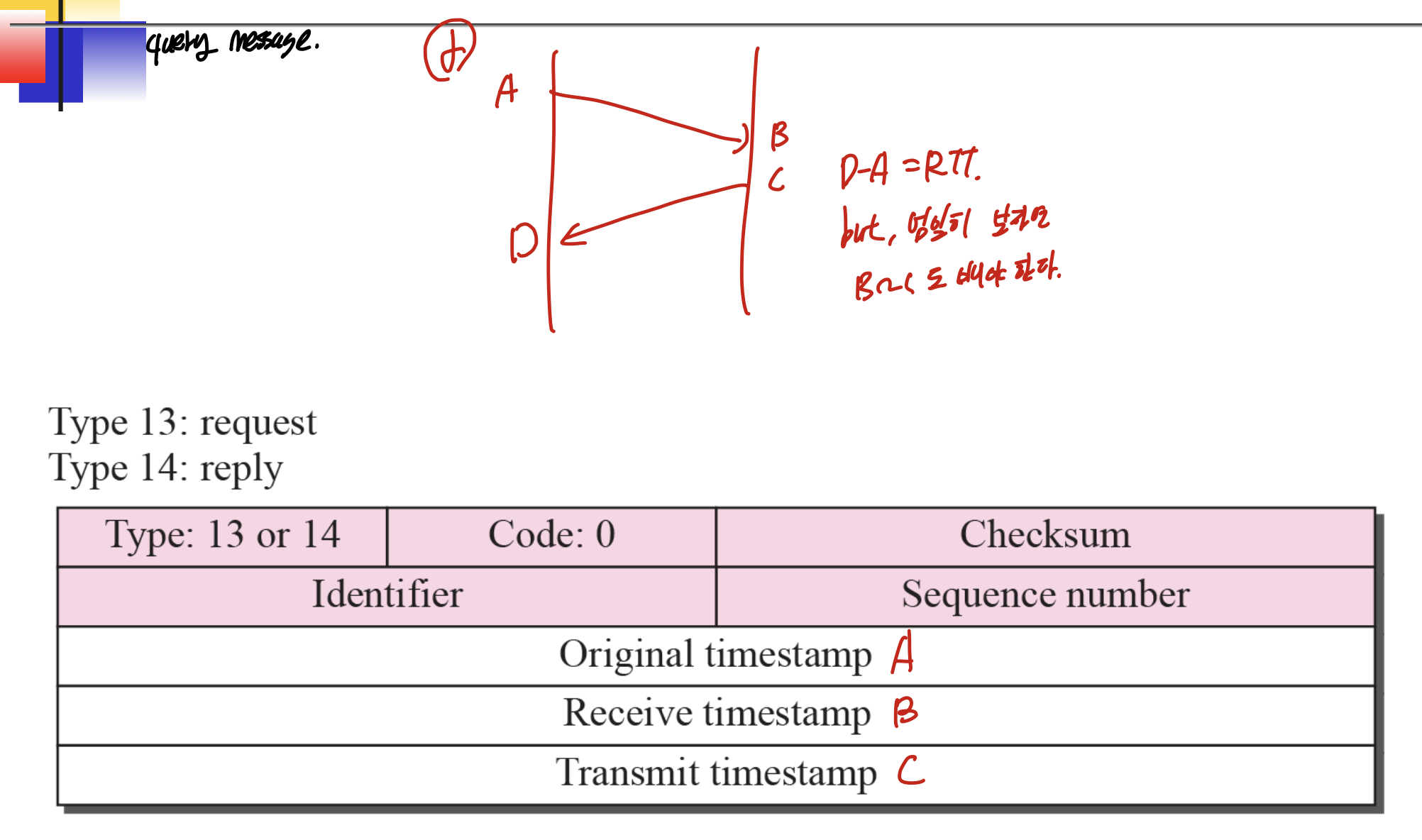

Timestamp request, reply는 RTT(round trip time, 패킷 보내고, 그 패킷에 대한 ack이 오는 시간)를 계산하거나 시간을 동기화하는데 사용될 수 있다.

한쪽으로 가는 시간만 안다면, 정확히 동기화를 할 수 있다고 한다.
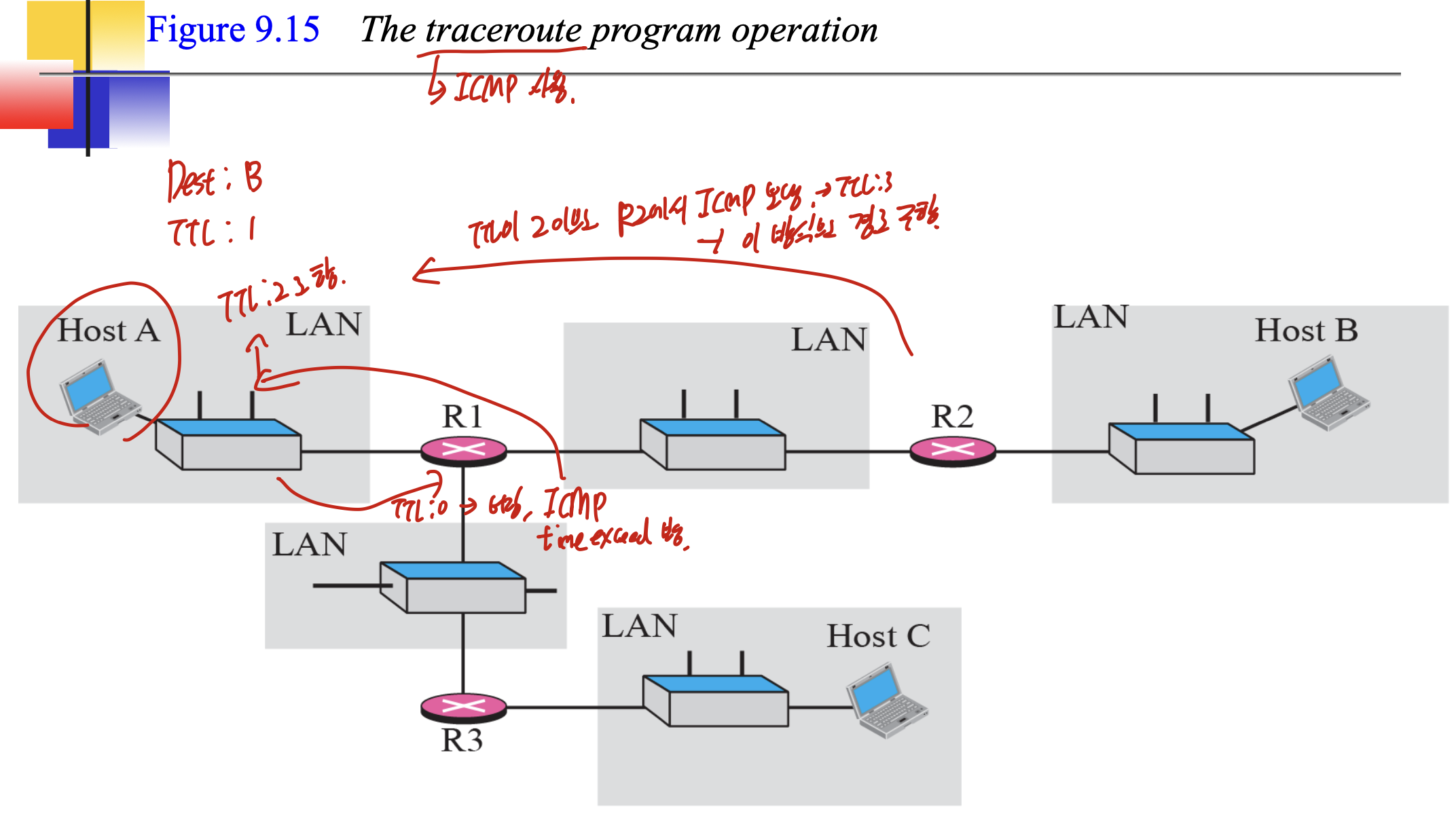
traceroute인데, TTL에 초점 맞춰서 보자.
CH11 Unicast Routing
인터넷이 점점 커지면서, 하나의 라우팅 프로토콜로는 모든 라우터를 관리하기 어려워 졌다. 그러므로 인터넷을 Autonomous system으로 나누었다.
AS는 하나의 관리자를 가진 네트워크와 라우터의 그룹으로, AS안에서 routing하는 것을 intra-domain routing이라 한다.
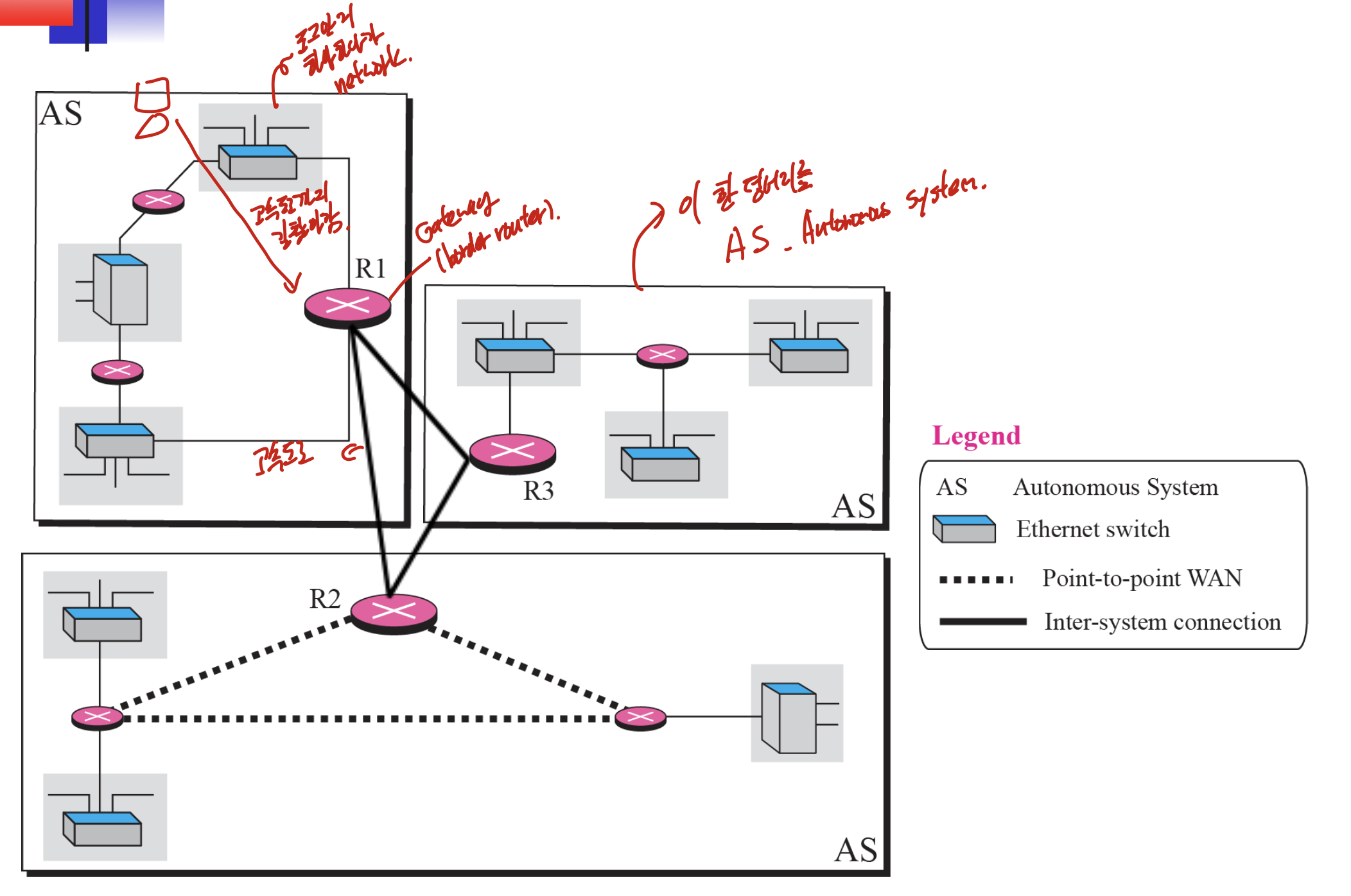
하나의 큰 덩어리들이 AS이고, 그 안에 네트워크와 router가 들어가있다.
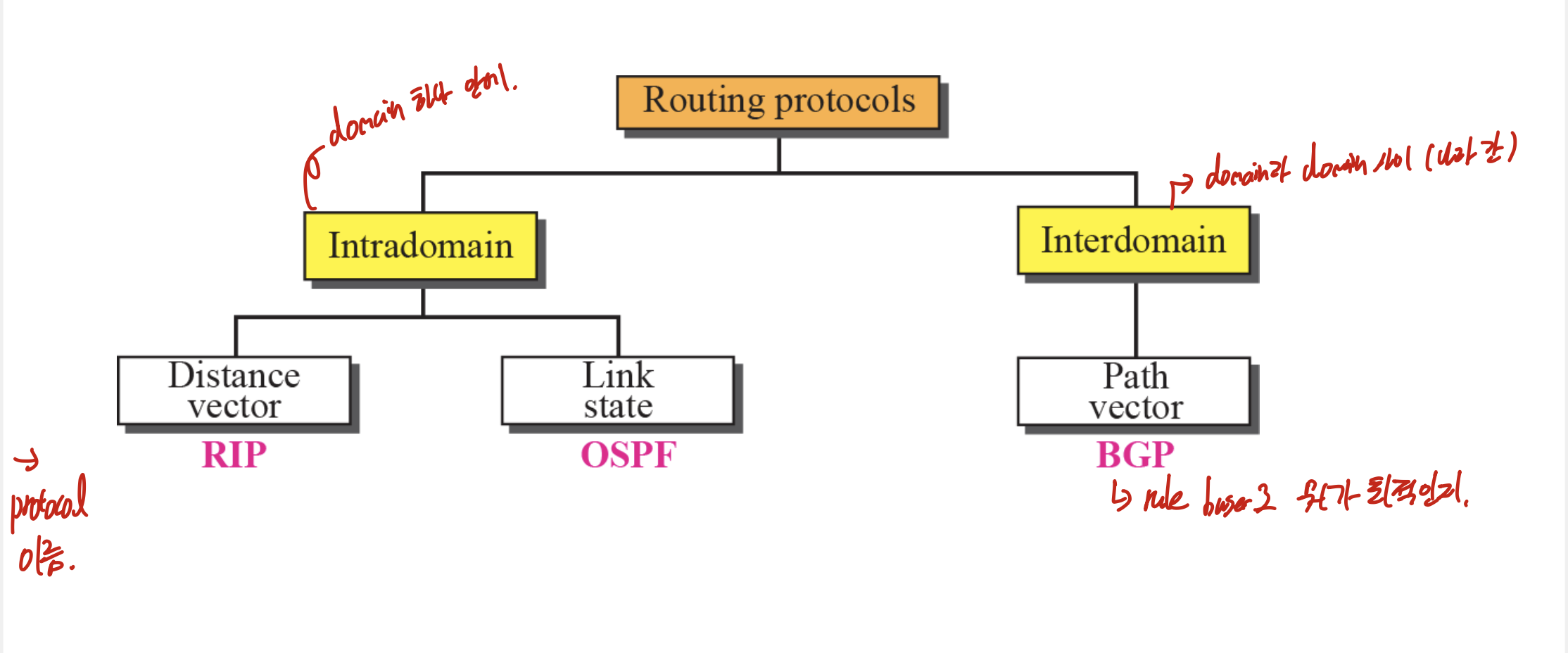
하나에 AS안에서 작동하는 것을 Intradomain, domain과 domain사이를 Interdomain이라 한다.
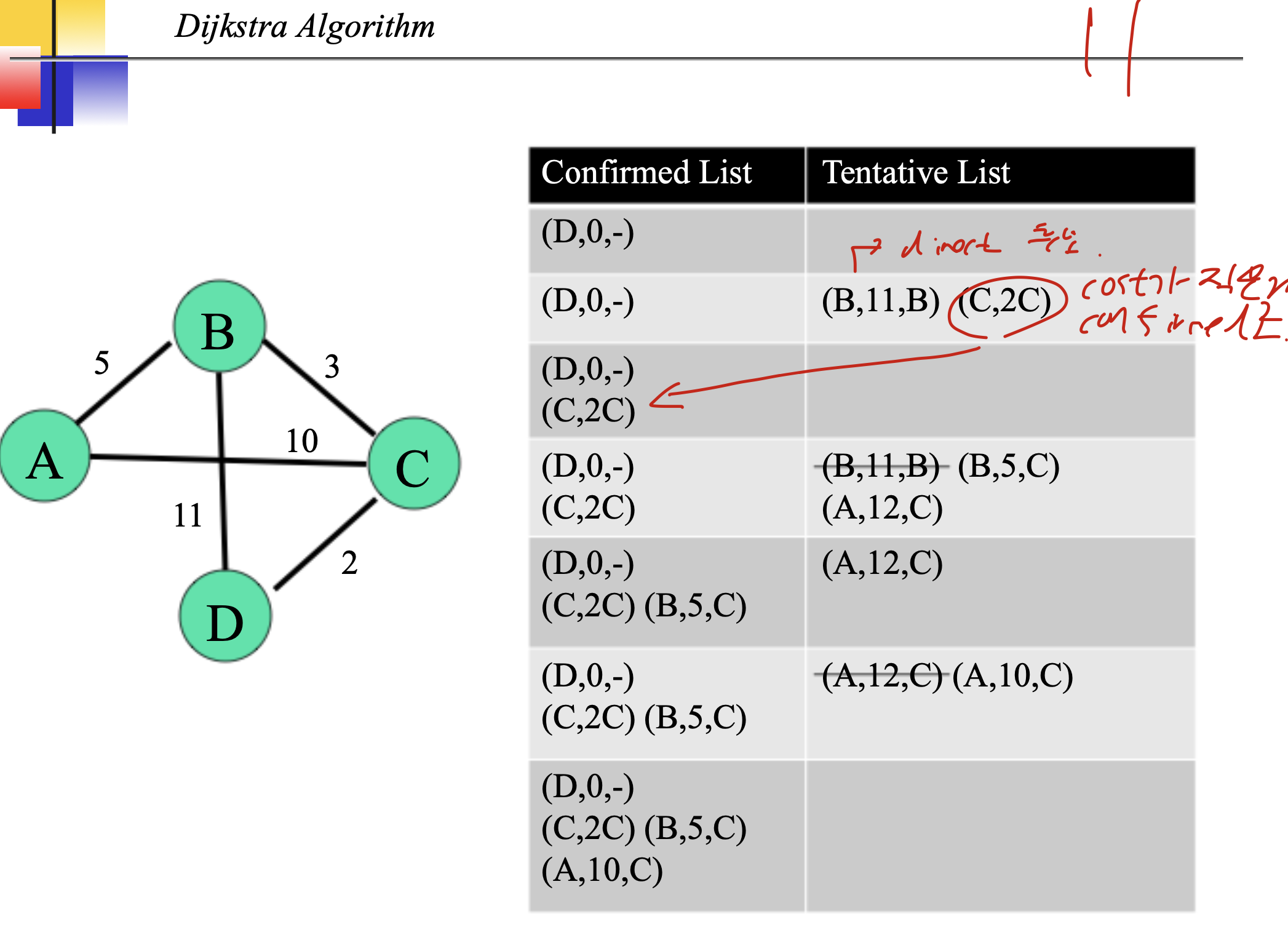
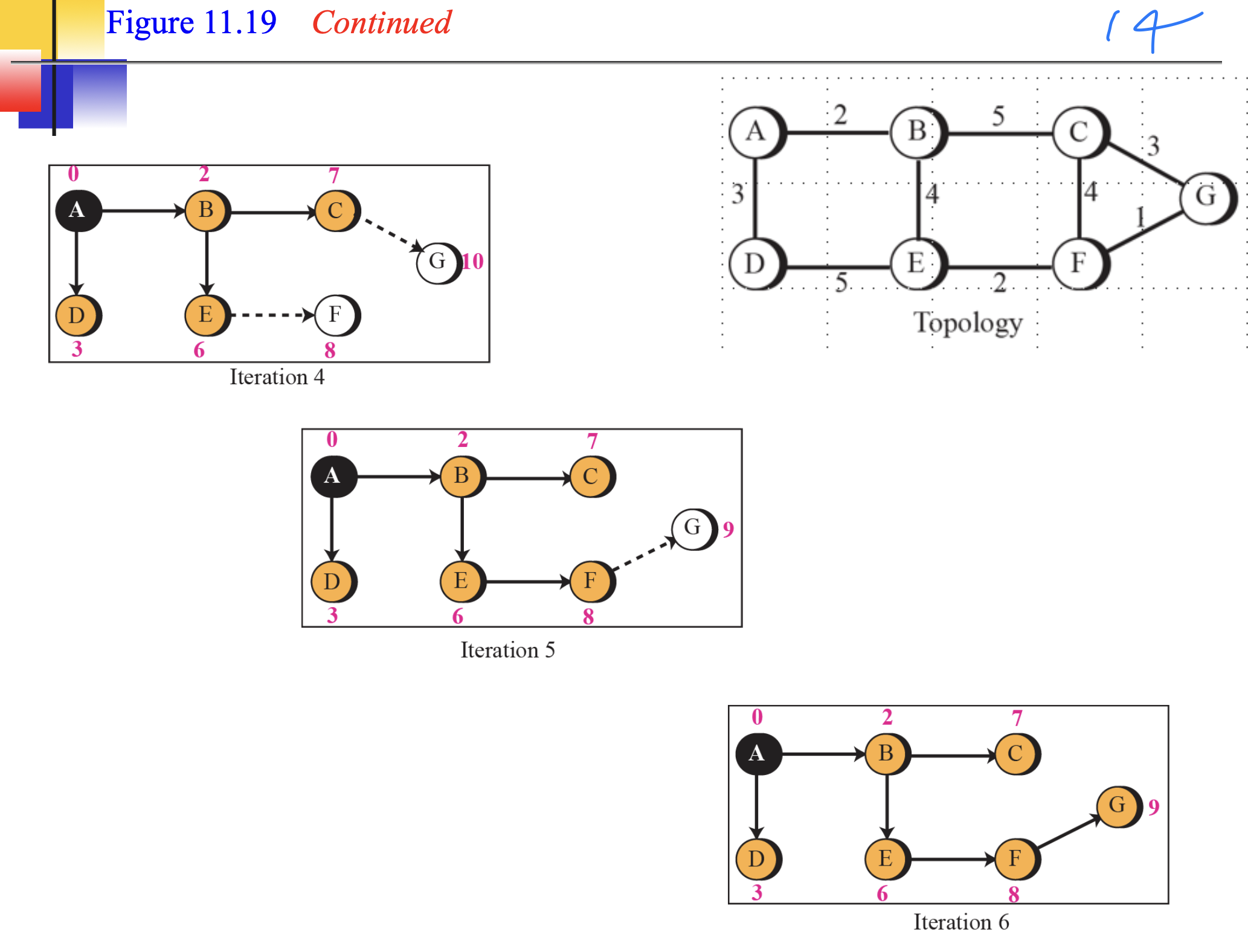
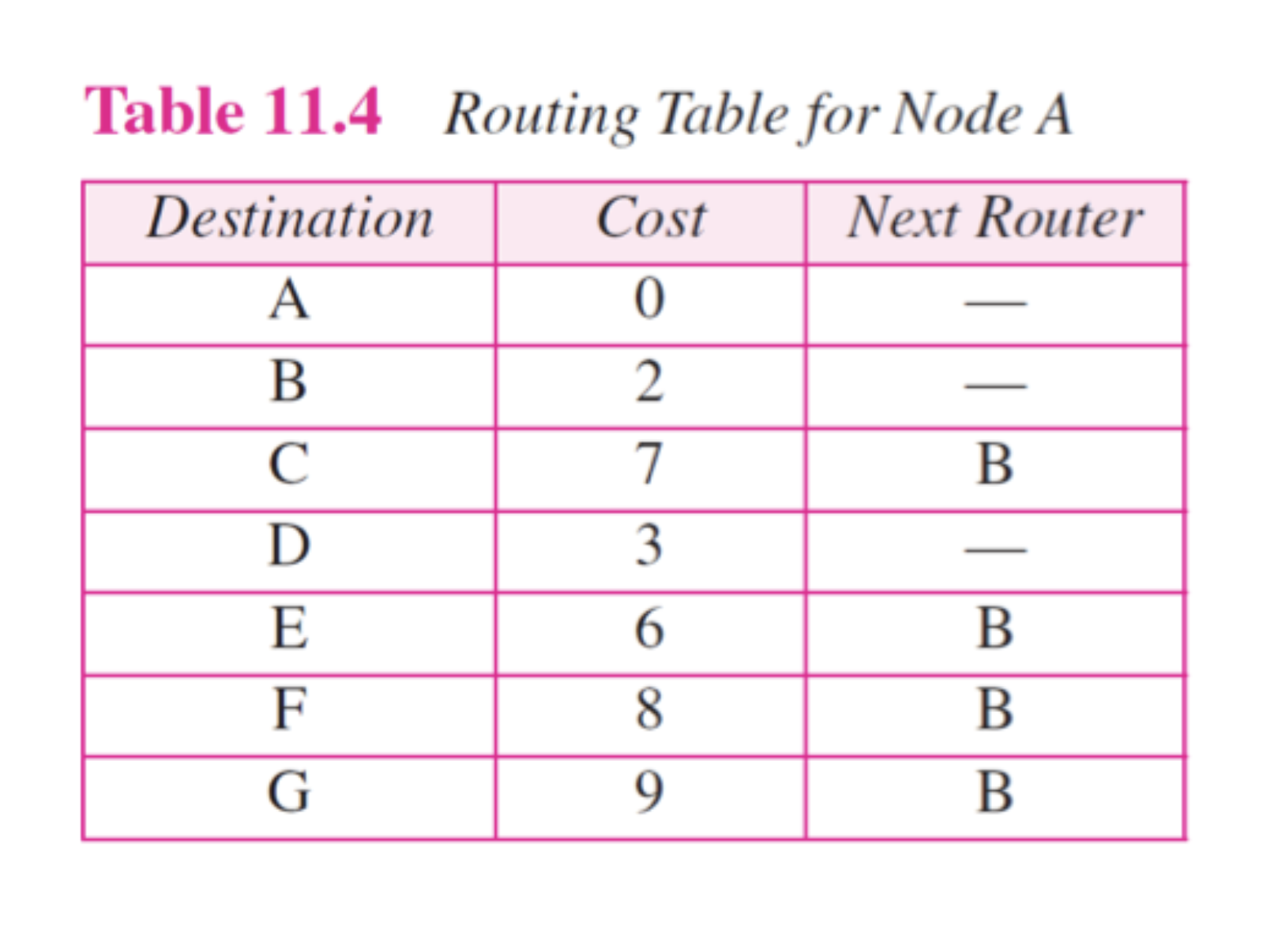
Distance vector(RIP)
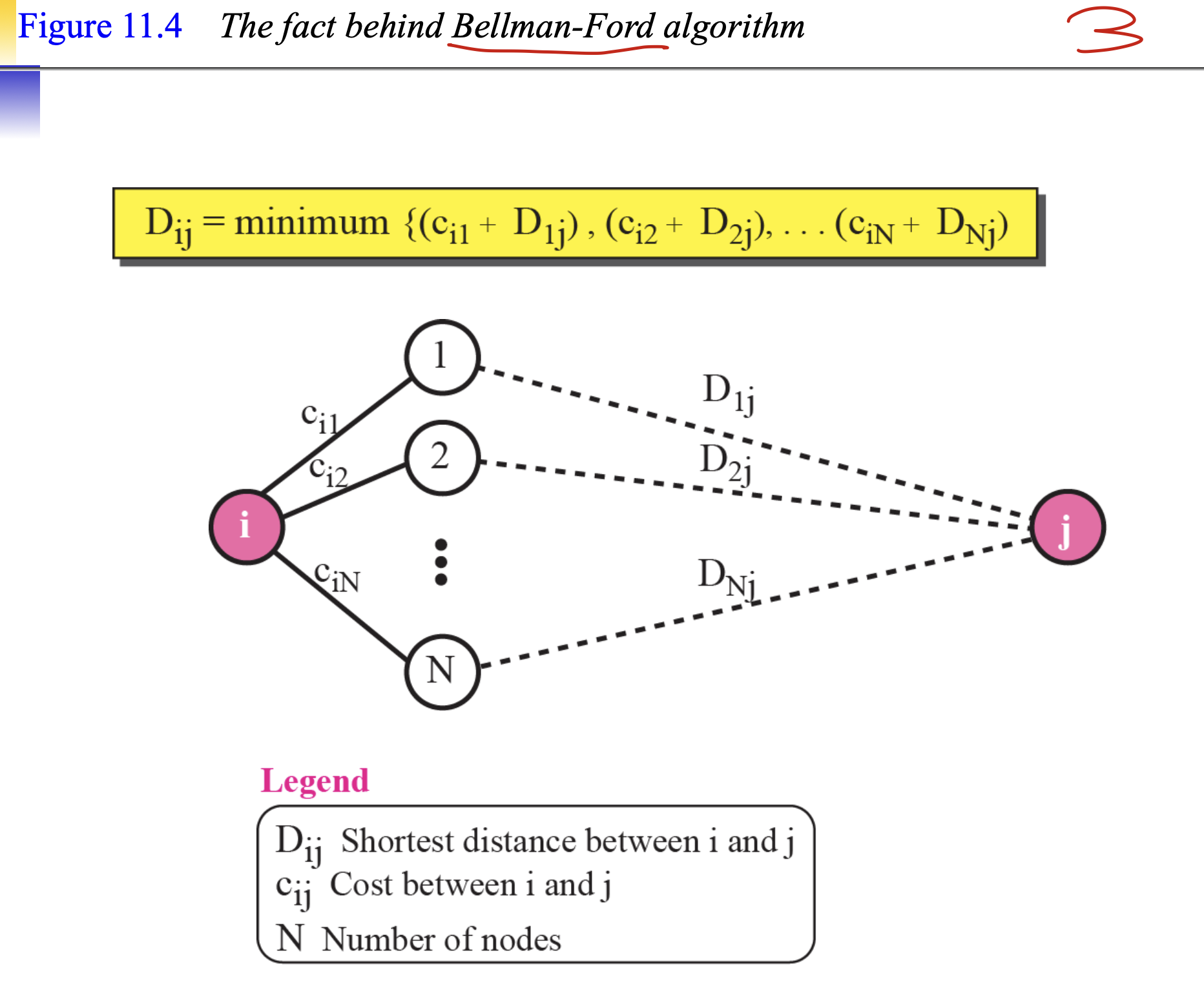
기본적으로 bellman ford algorithm을 사용한다. 간선 젤작은거대로 가는거.
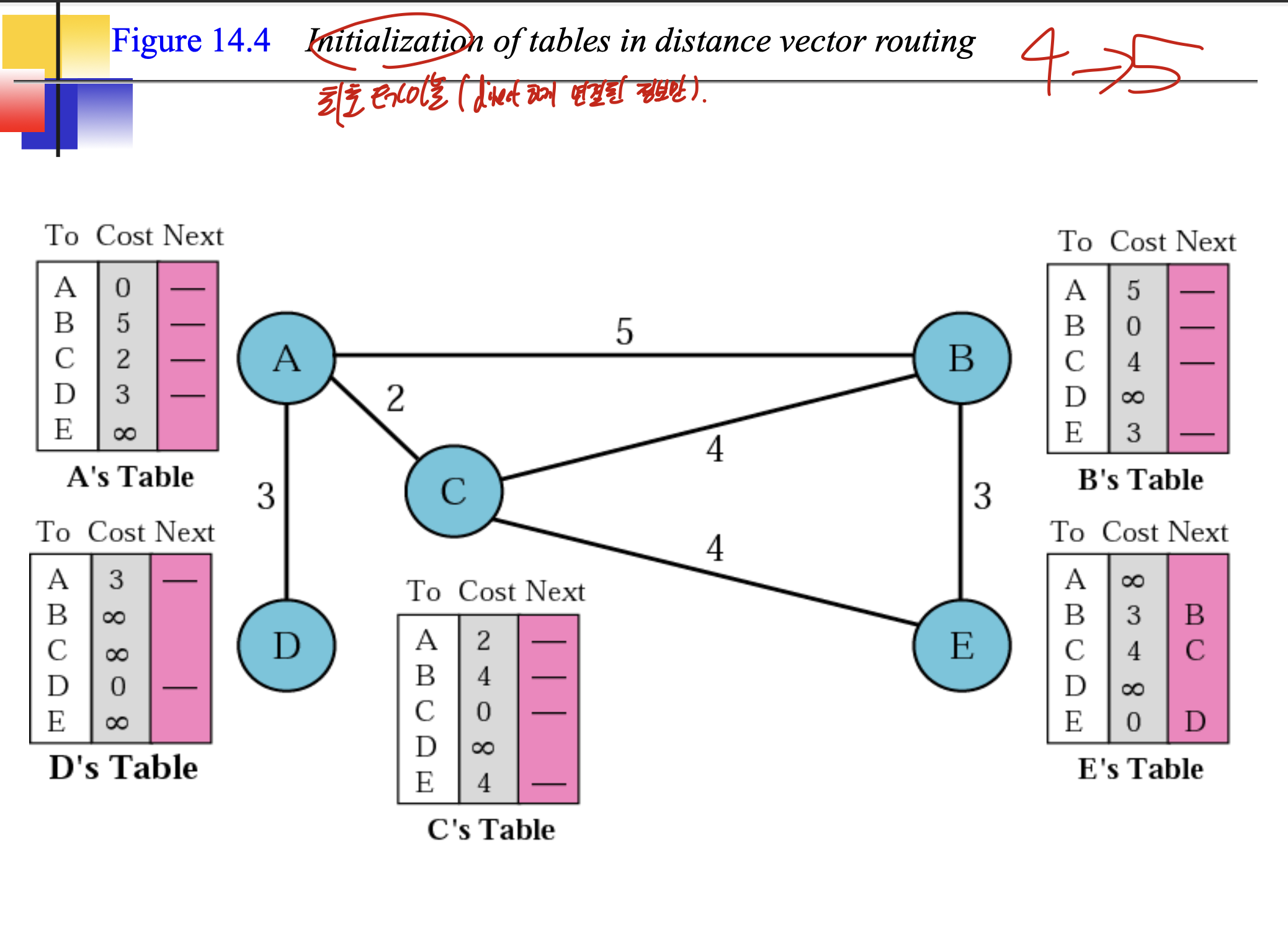
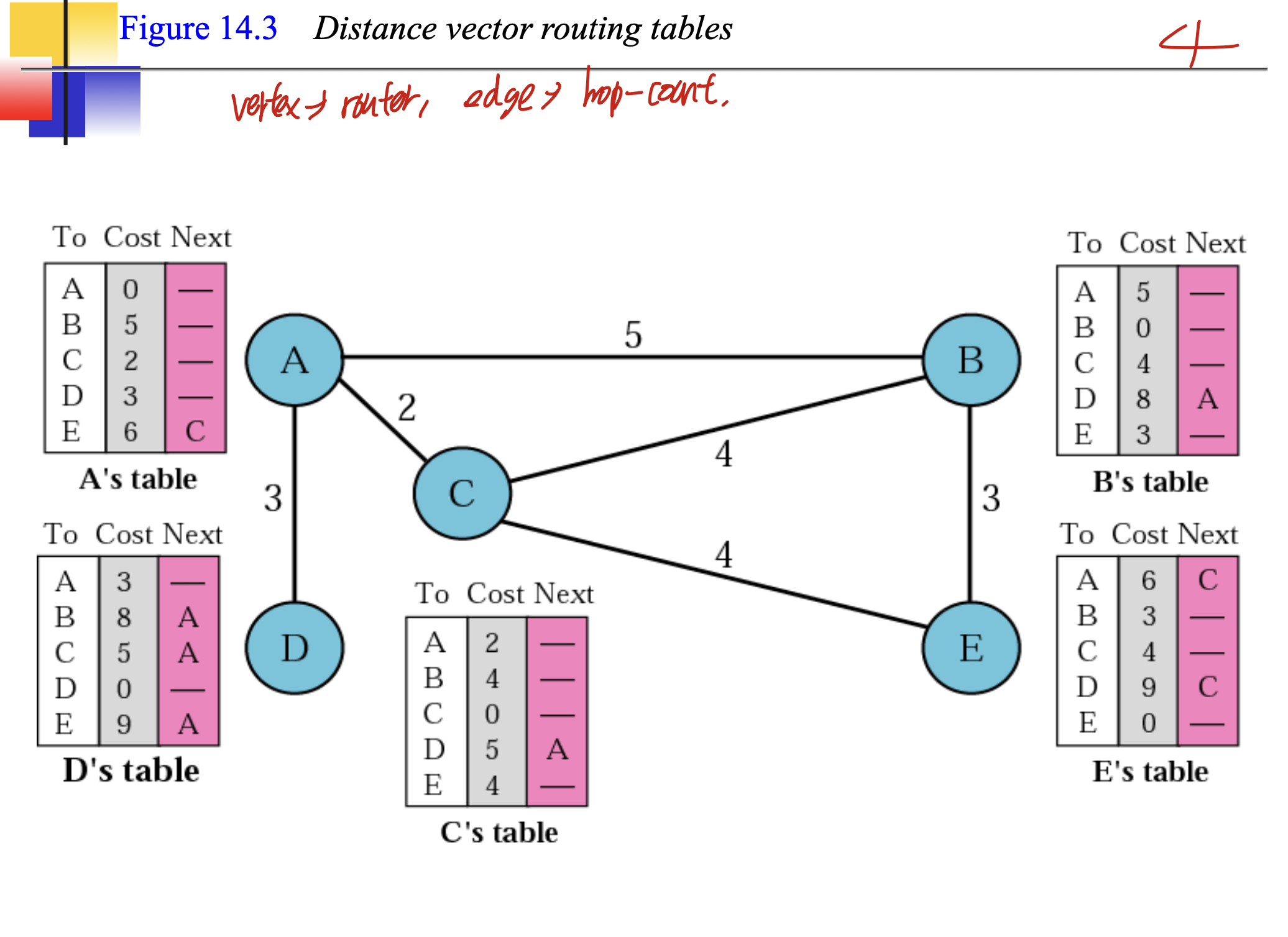
distance vector routing table의 최초 모습과 다 변한후 모습으로,
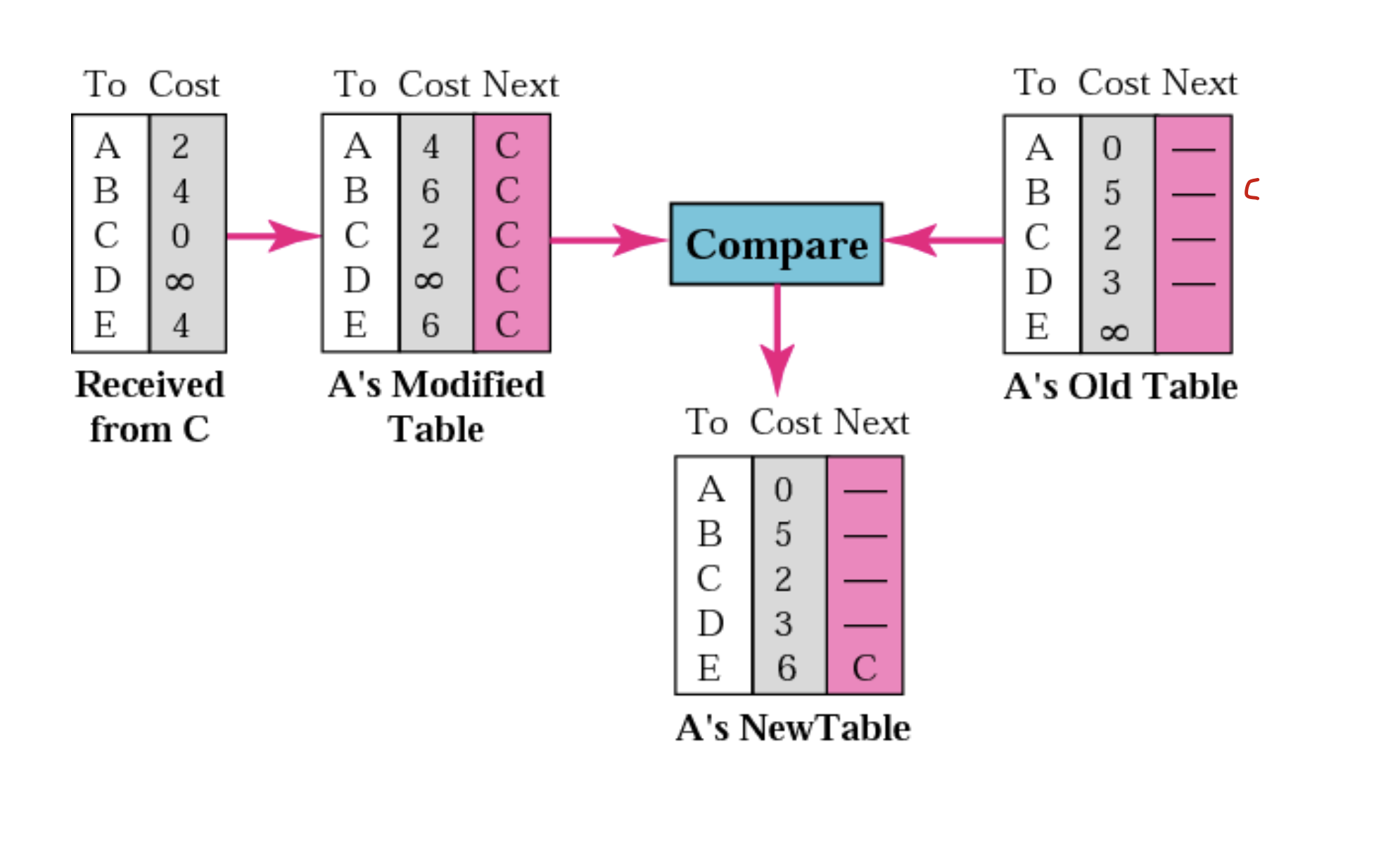
이 과정을 통해서 바꾼다고 한다.
그중 작은거를 택해서 바꿈.
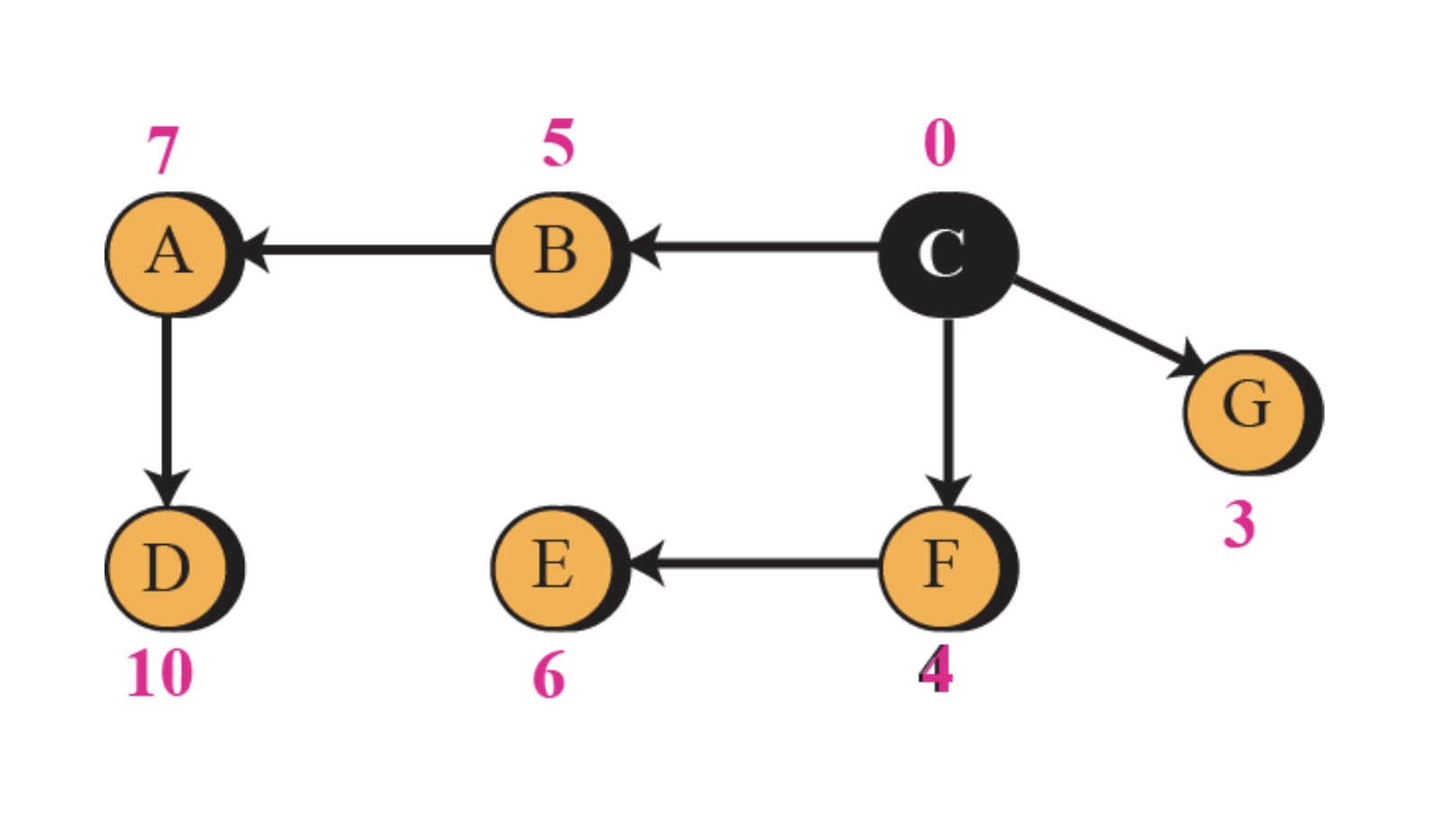
A's Modified Table을 보면, C에서 가져왔고 A->C가 2니까, 무조건 A에서 C를 지나 다른곳으로 가는 Table을 만드는 것 이다. 그러므로, C에서 받은 것에 다 2를 더해준다. 그것과 원래 A테이블을 비교해 갱신하는 것 이다.

intradomain
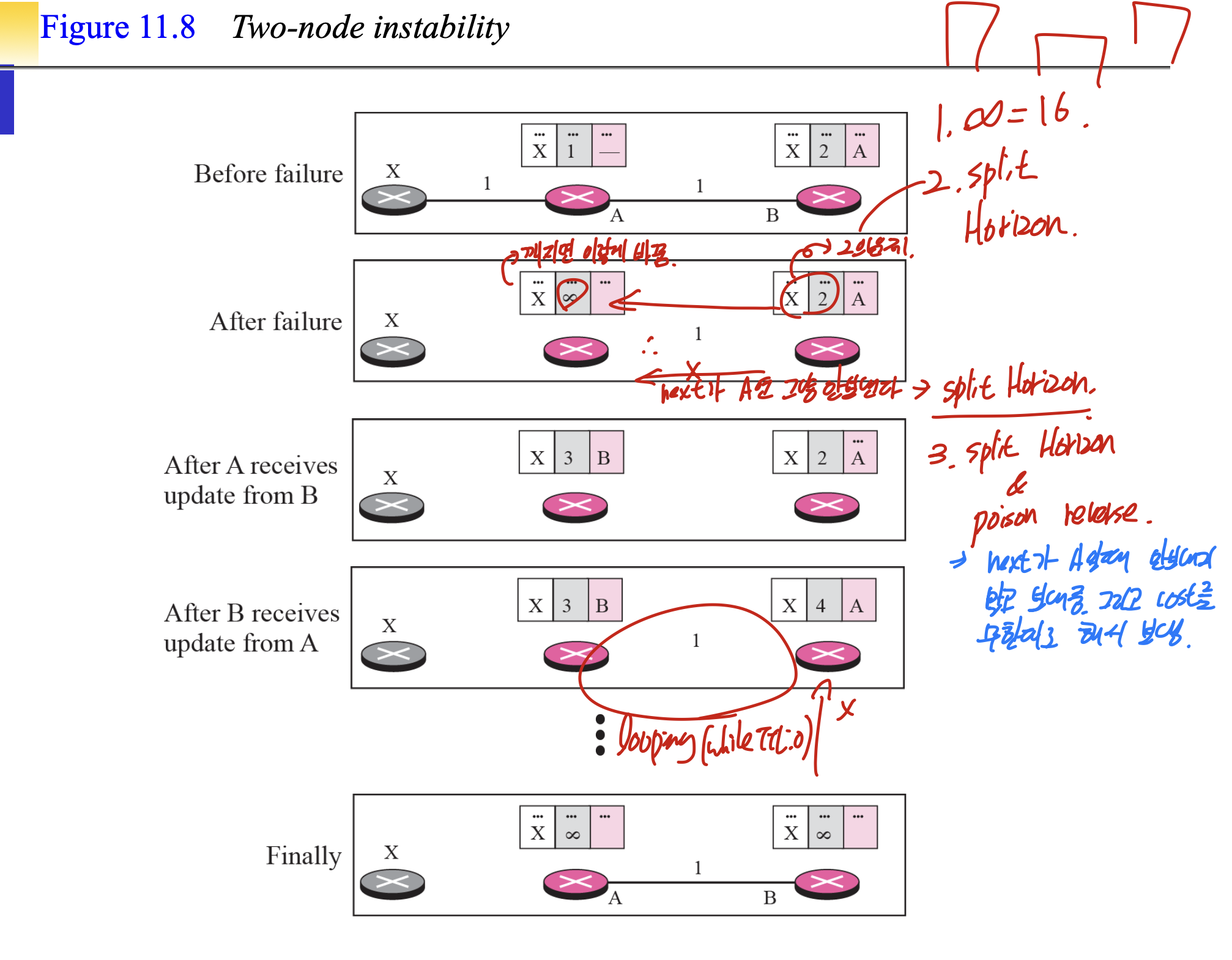
1. 무한대 자체를 16으로 놓아서 loop가 발생했을때, 16만큼 돌면 무한대로 설정되게 함.
애초에 16번을 돈다는거 자체가 문제가 있는 것.
2. Split Horizon
next가 A면, 그냥 안보내는 방식이다.
3. Poison reverse
next가 A일때 그냥 보냄, 그리고 cost를 무한대로 해서 보냄.
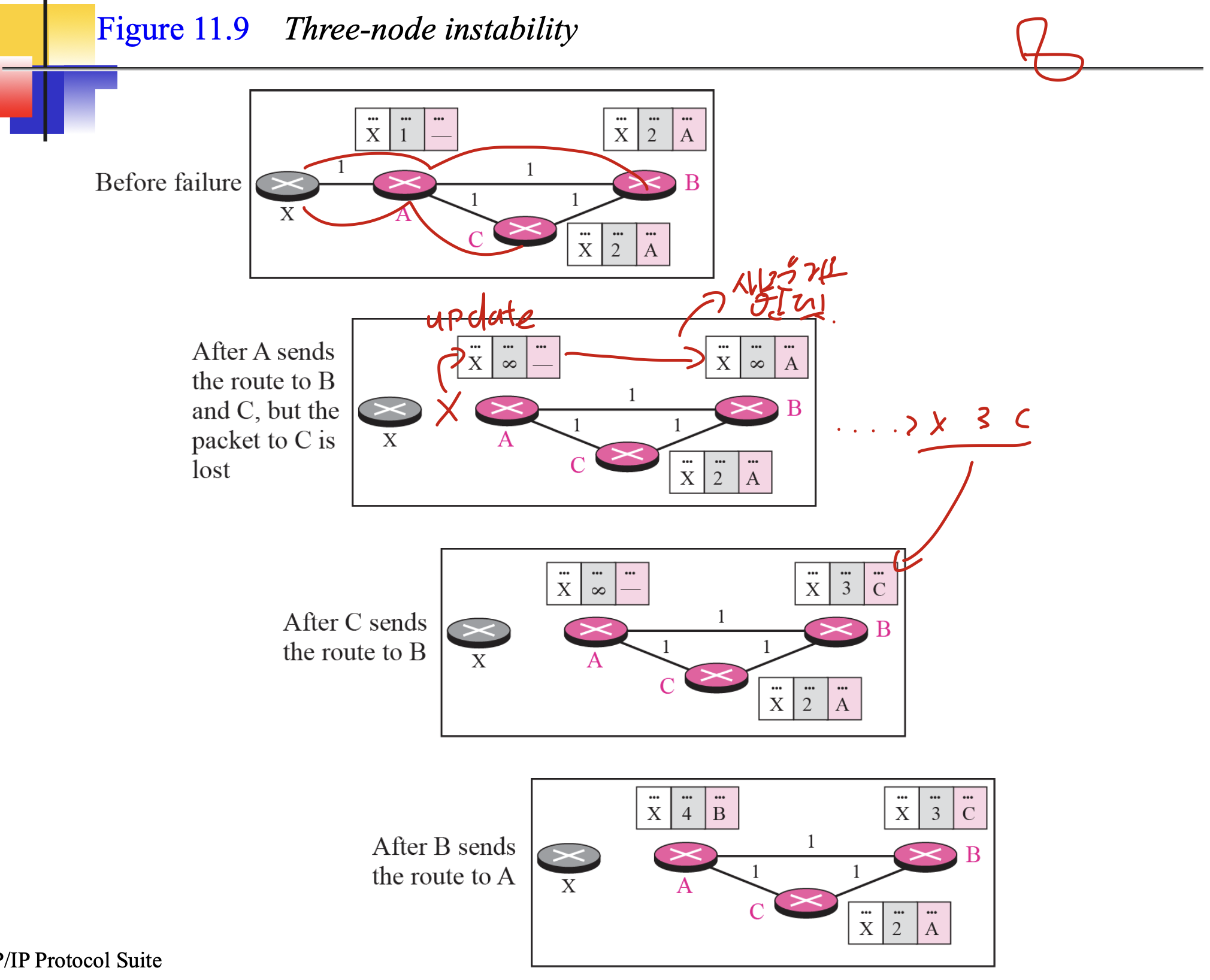
2, 3번 방법으로 해결할 수 없는 상황이 있음.
이럴때는 그냥 loop로 무한대 16넣어서, 해결해야됨.
Link state(OSPF)
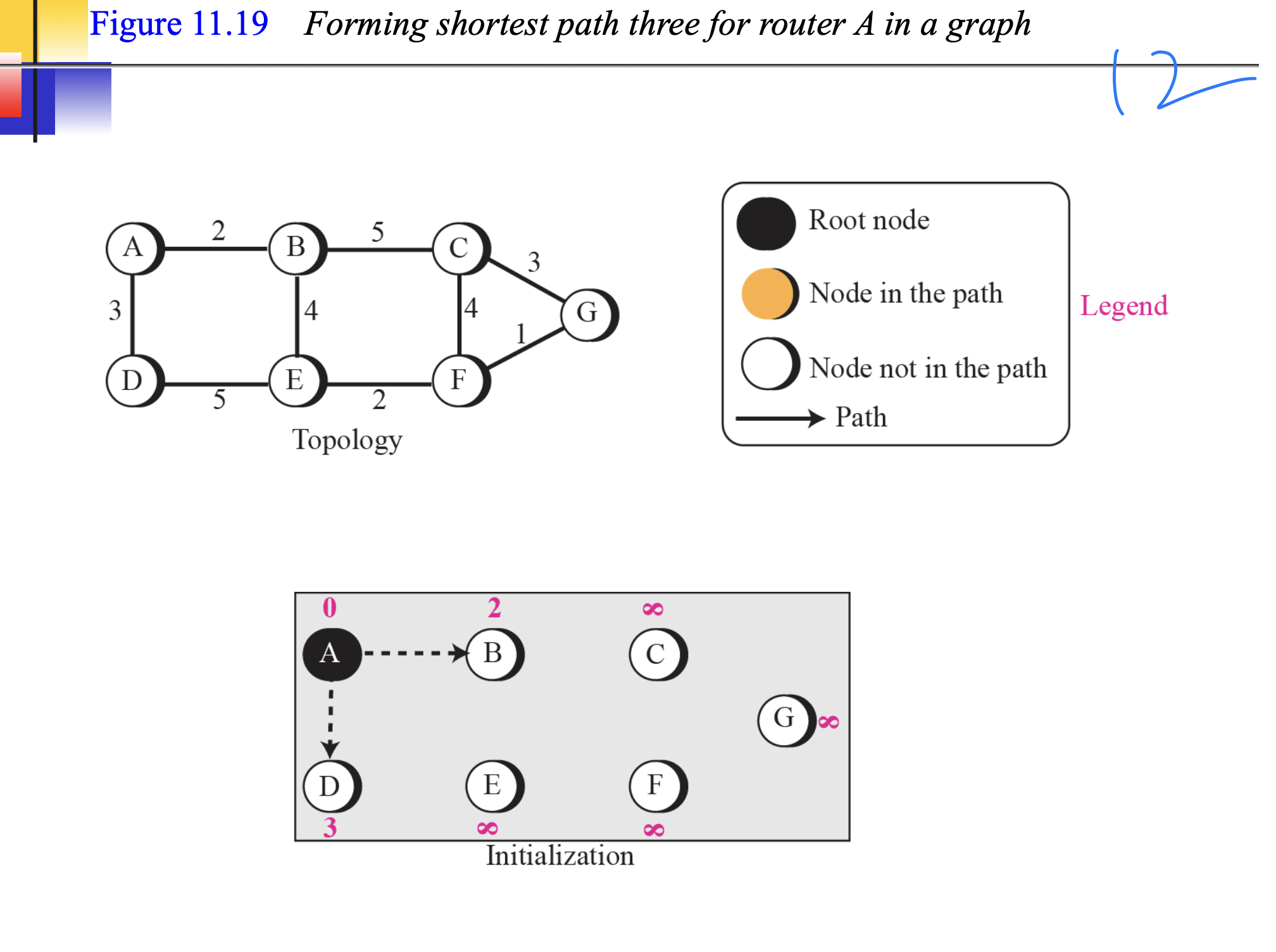
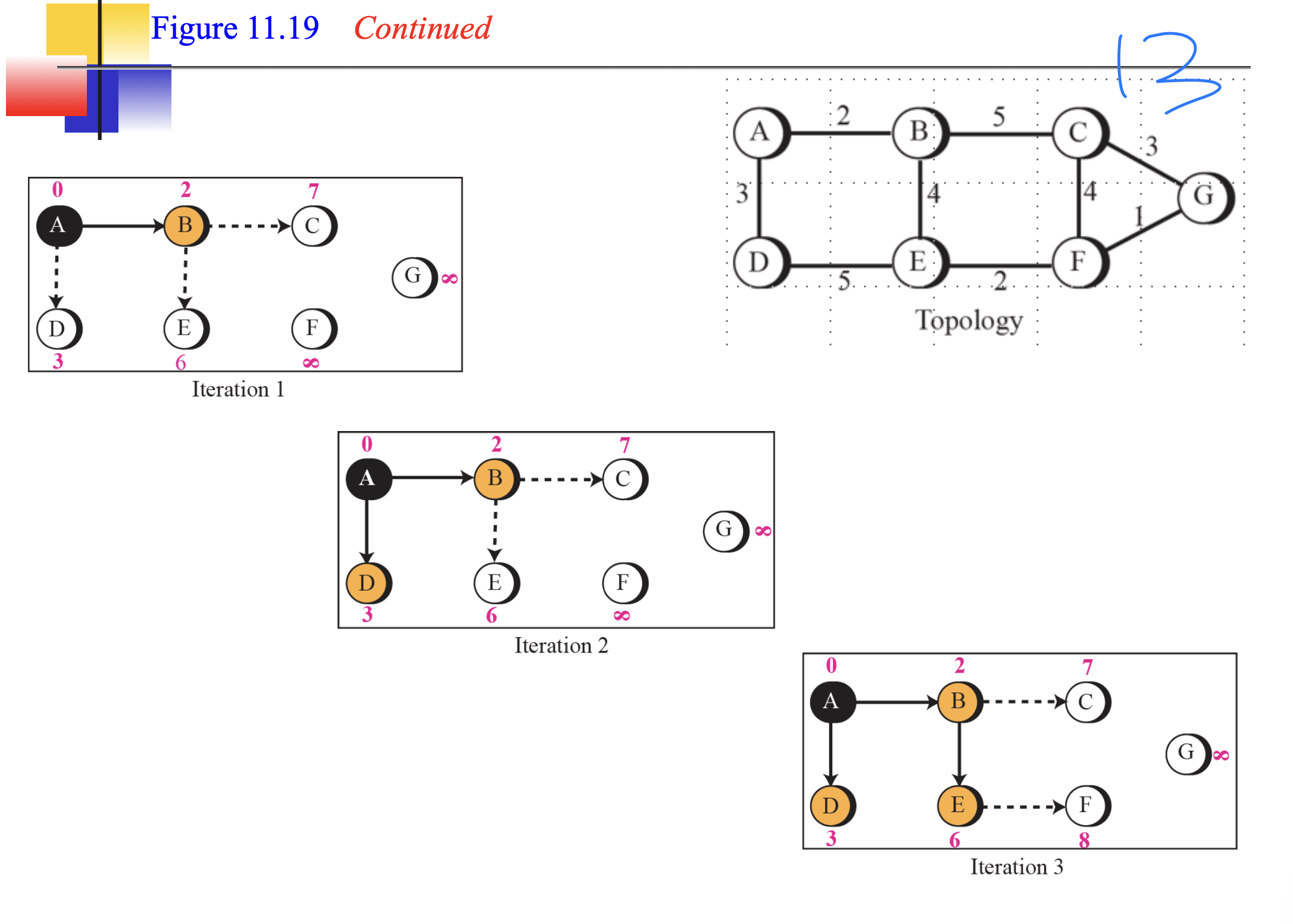
하나의 AS안의 노드들이 모든 정보를 알고있다는 가정.
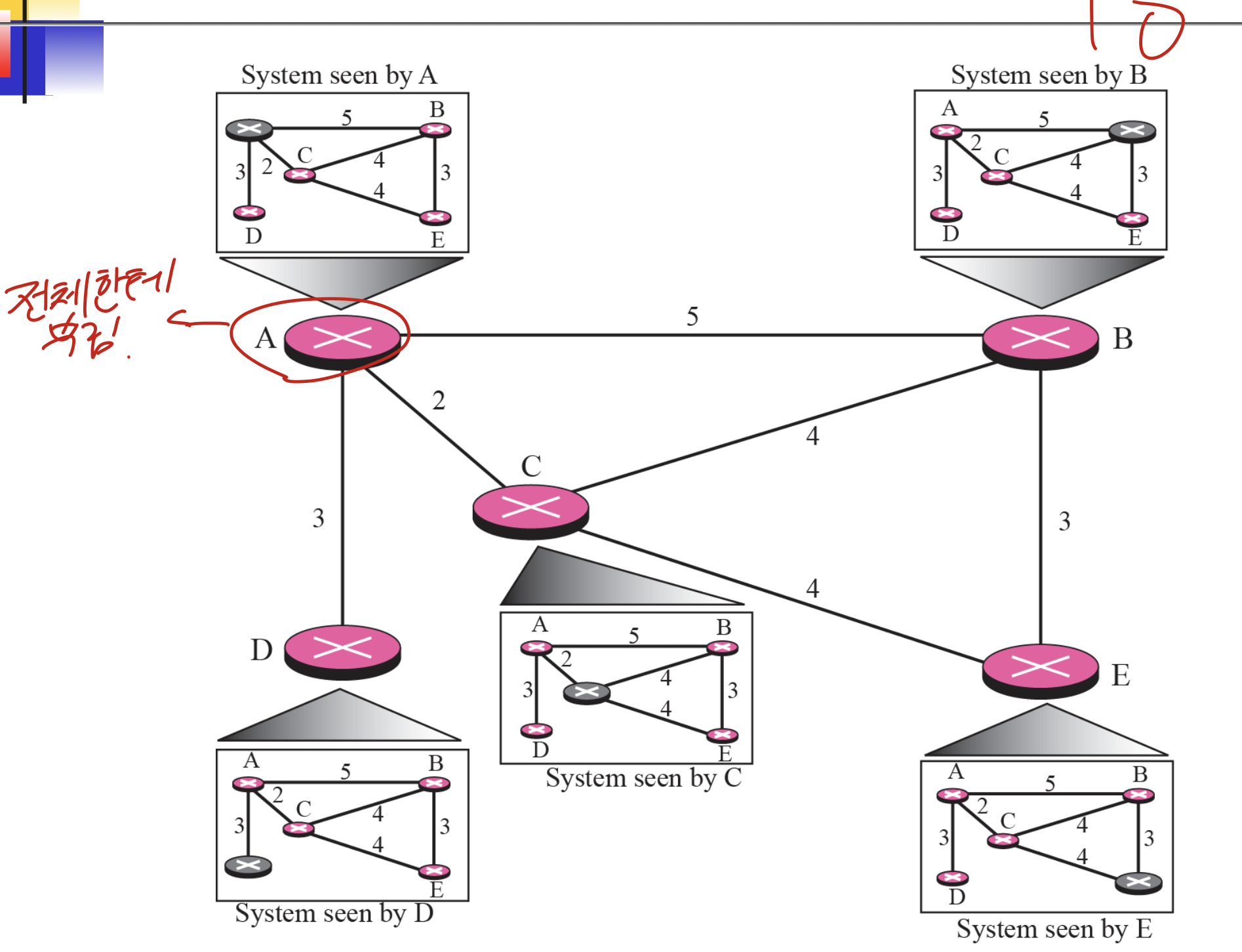
다익스트라 사용함.
CH08 ARP

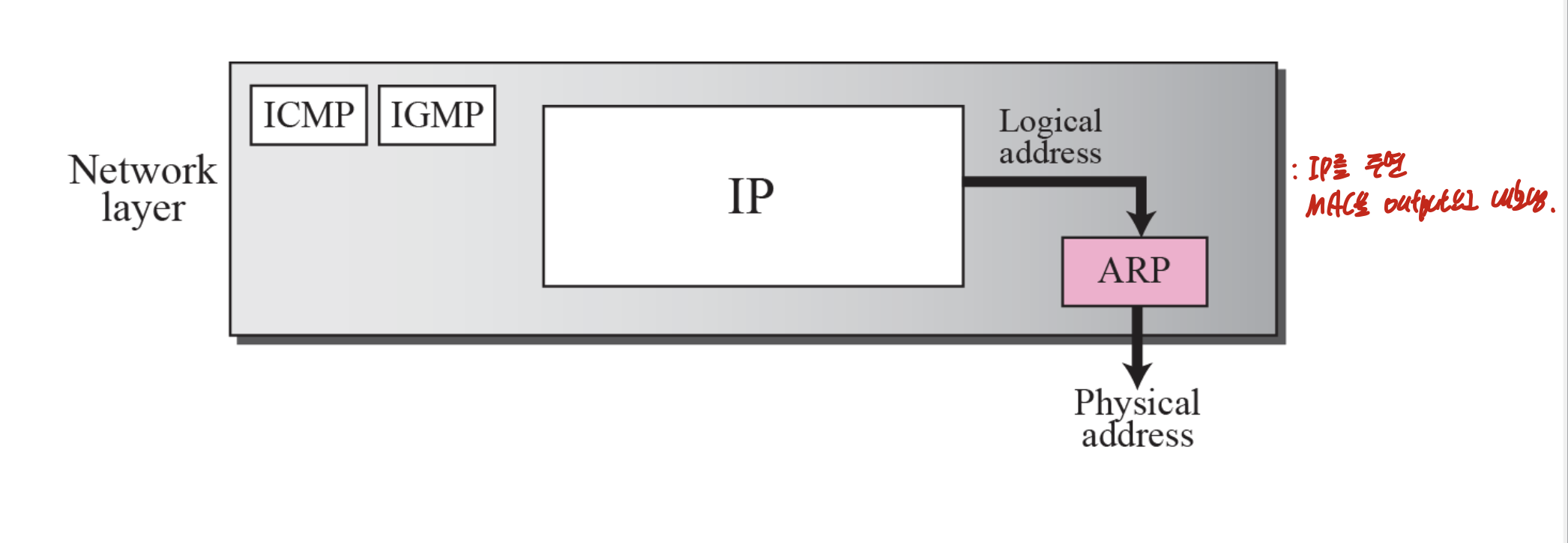
delivery 하기 위해서는 logical, physical address가 필요하다. 그러므로 logical에 physical을 mapping해주고, 그 반대도 요구된다.
그 과정은 static, dynamic mapping으로 할 수 있다.

IP datagram은 Frame안에 encapsulated되어 들어가야 한다.그러므로 ARP로 logical address를 주어 대응하는 physical address를 찾아 이를 data link layer로 보내주어야 한다.
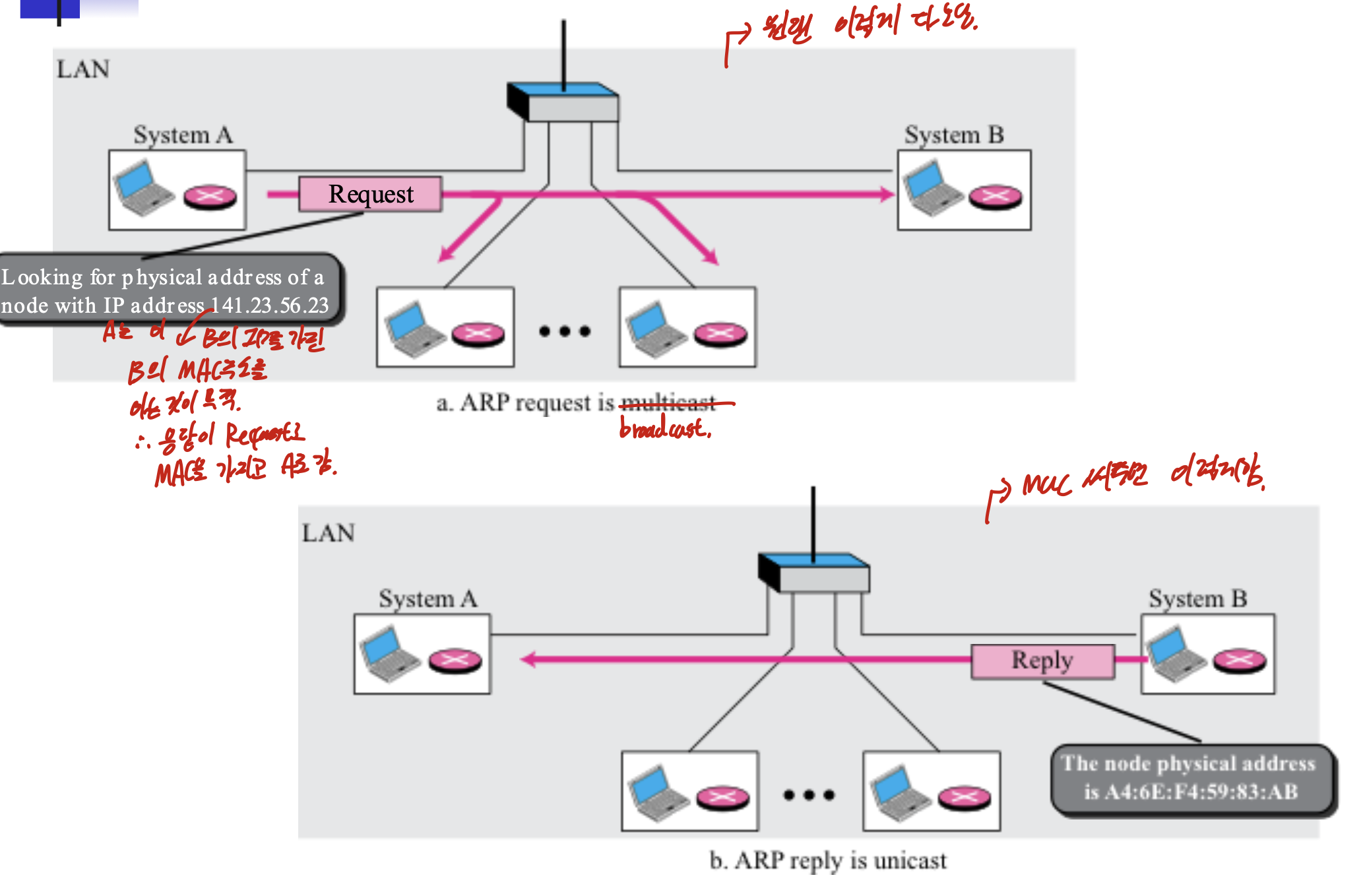
B의 응답이 MAC을 가지고 A로 간다. 그러면 이제 다 안보내고, MAC에 해당하는 곳에만 보낼 수 있다.
이 그림에서 볼 수 있듯이 ARP request는 broadcast, reply는 unicast이다.

source, destination 의 ip, mac을 가지고 있다는 것, operation code가 1, 2일때 ARP라는 것.
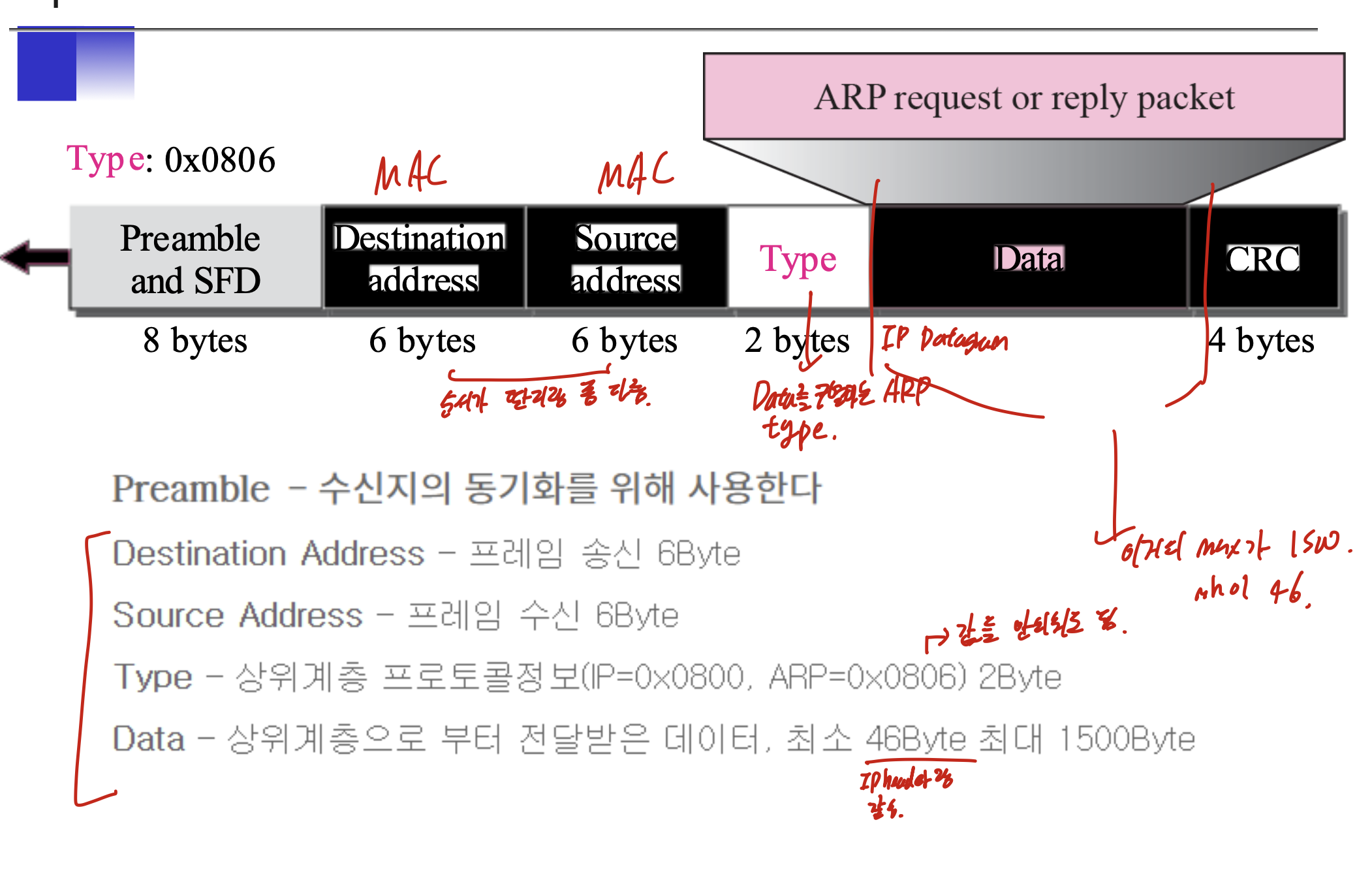
MAC이므로 받는곳 보내는곳의 순서이고, 그 다음 Ip인지, ARP인지 type을 써준다. Data는 IP datagram에 해당하는 부분이다. CRC는 오류검출이었나
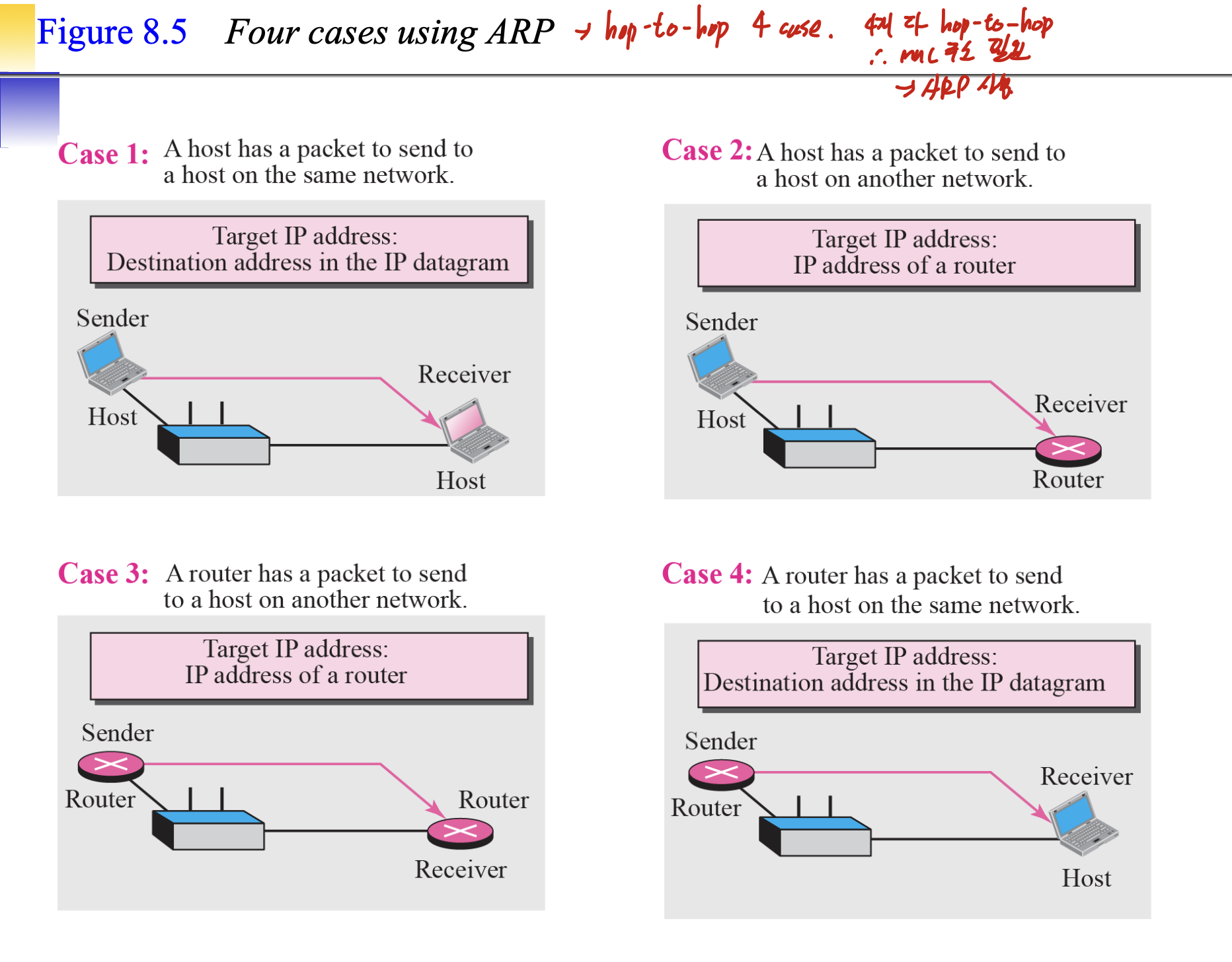
ARP를 사용하는 네가지 경우인데, 4개 다 hop-to-hop이므로 MAC 주소가 필요하다.
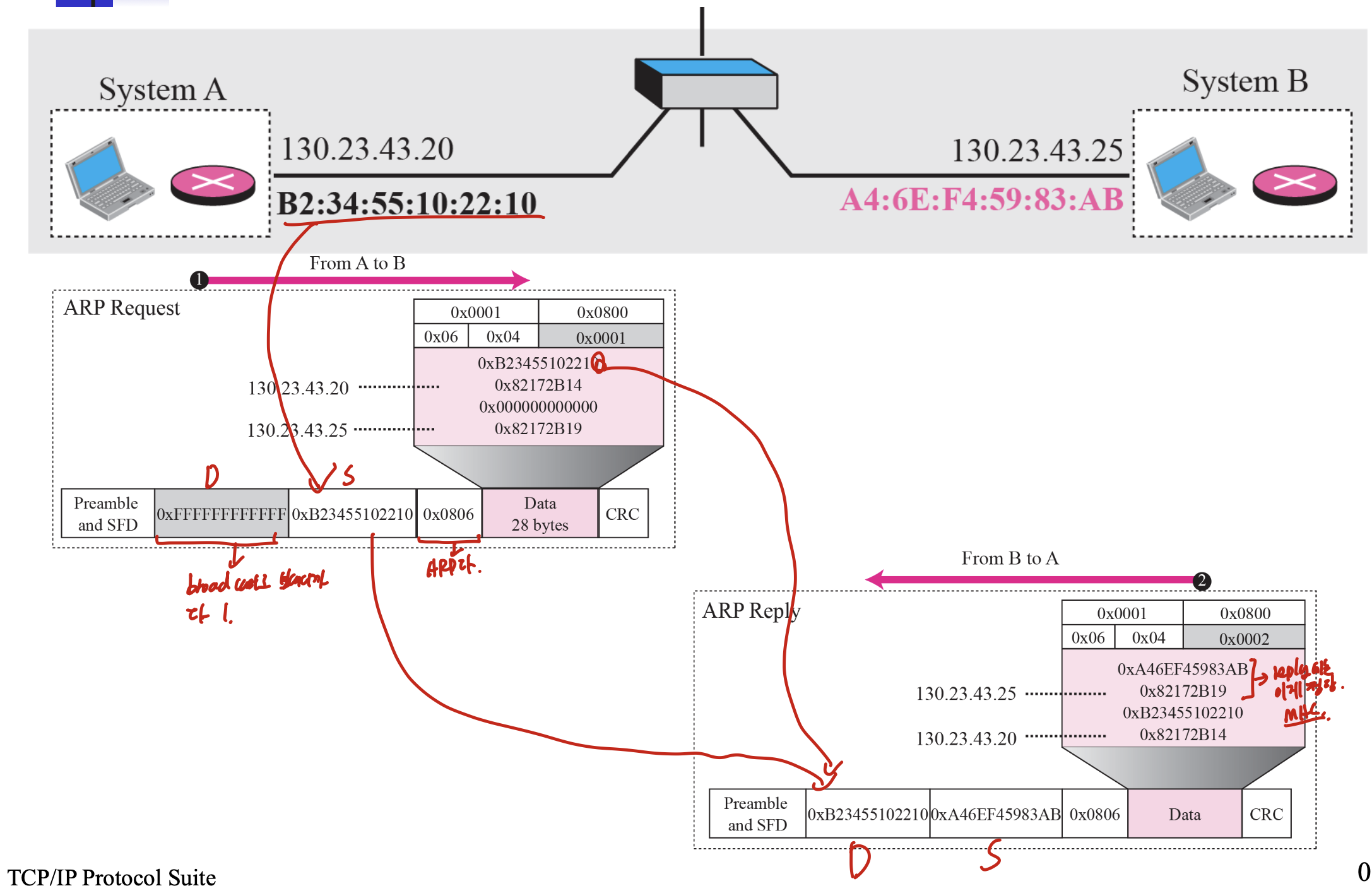
총정리같은 페이지인데, 우선 request는 broadcast이므로 destination이 전부 1이다. 그 후 reply에서 Destination의 MAC을 source에 넣고 보내준다.

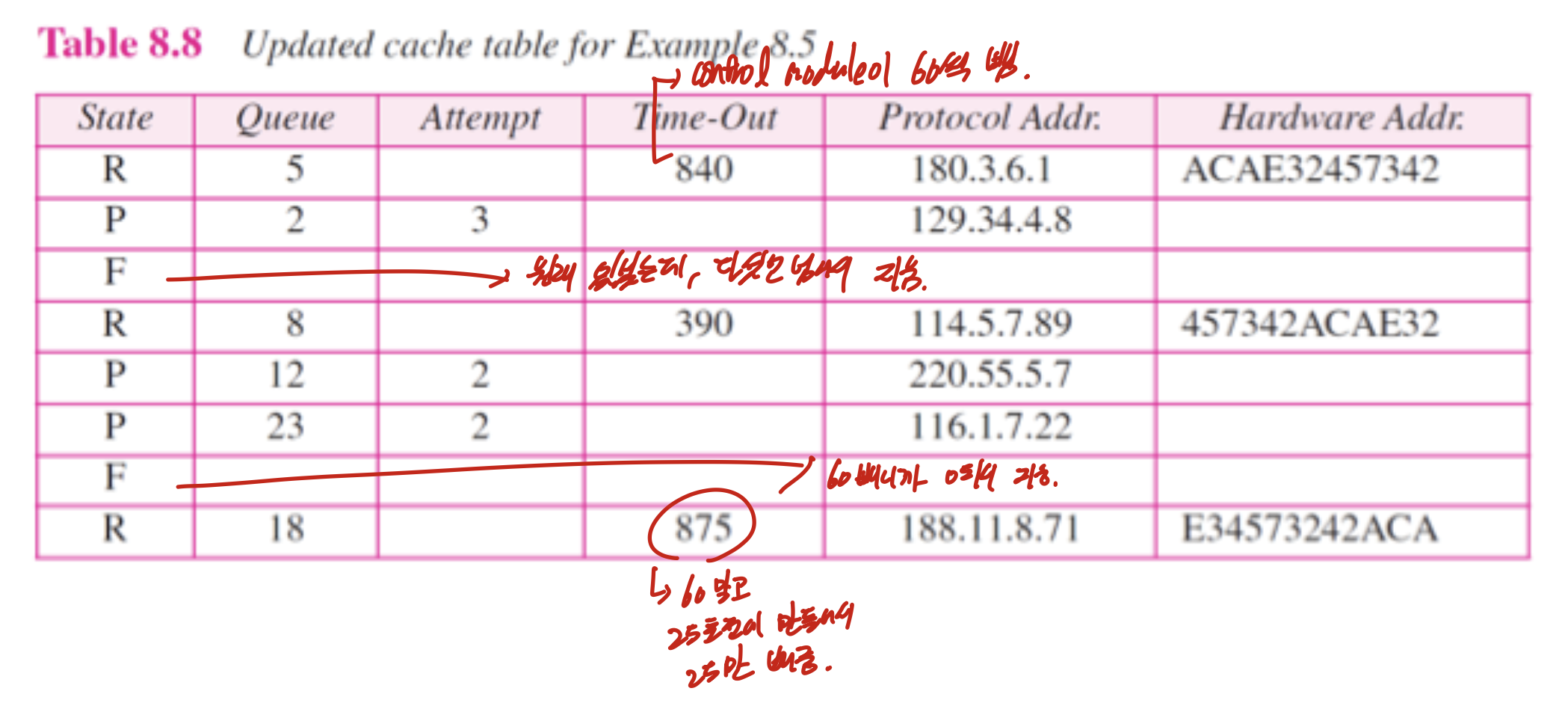
output module ->
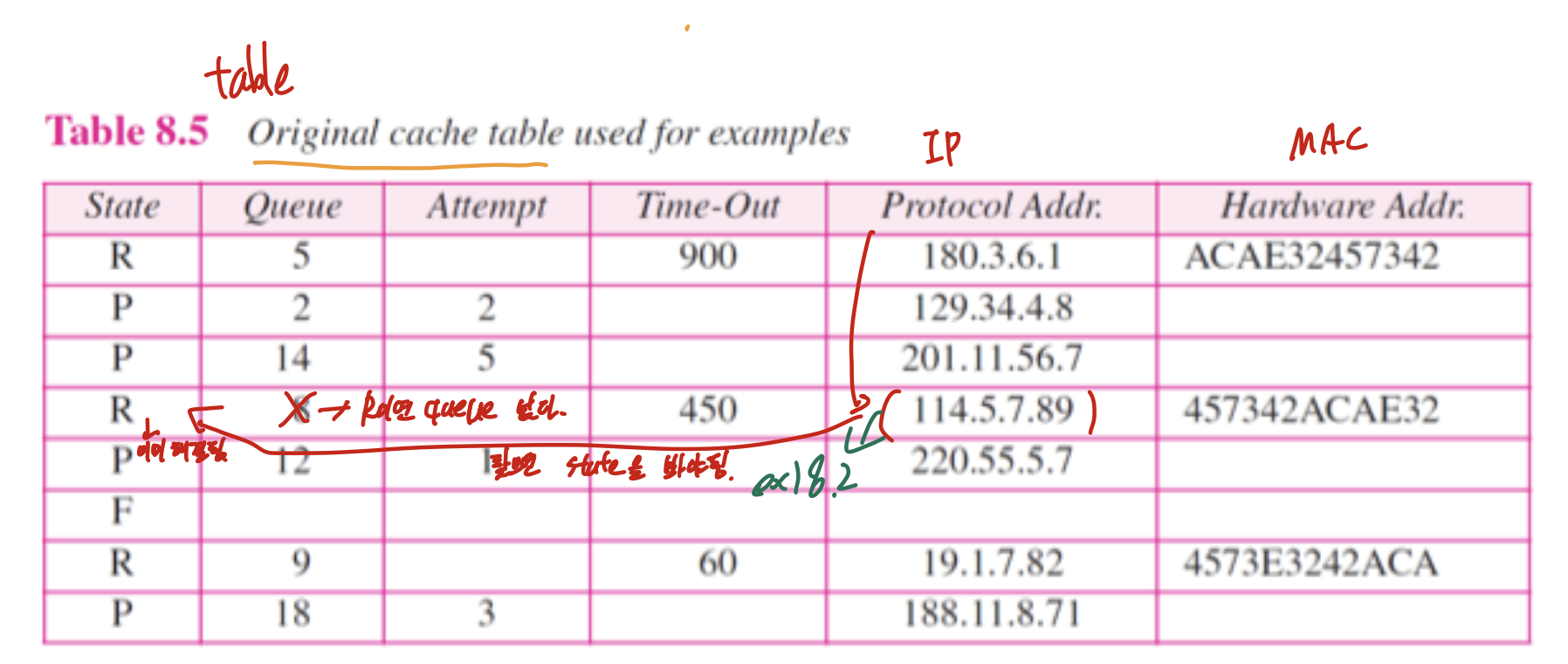
IP packet이 들어오면 Cache table 확인.
없으면 만들고 packet queue에 넣어줌. 그리고 P(pending)상태로 해준다음에 attempt(시도 횟수) 1로 해줌. 그리고 ARP request 보냄.
있는데 P이면, queue에 넣어준다.
있는데 R이면 기존 정보 바탕으로 보내줌.
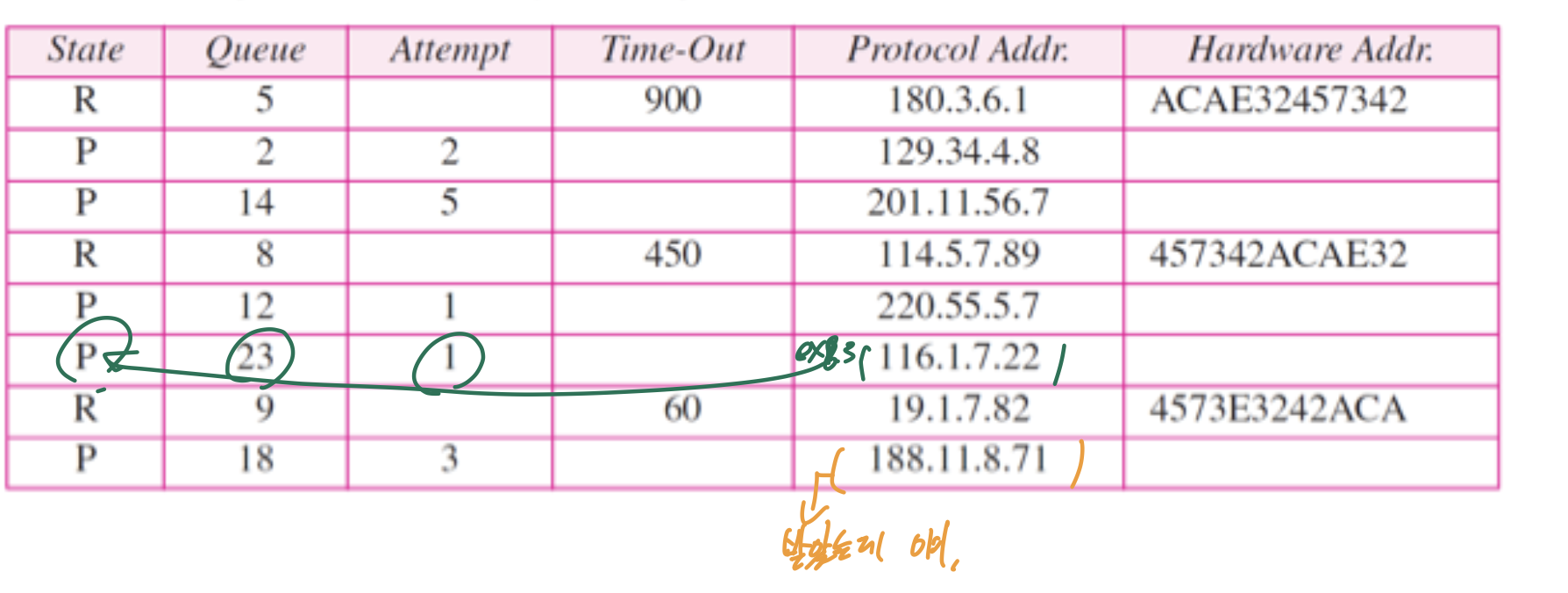
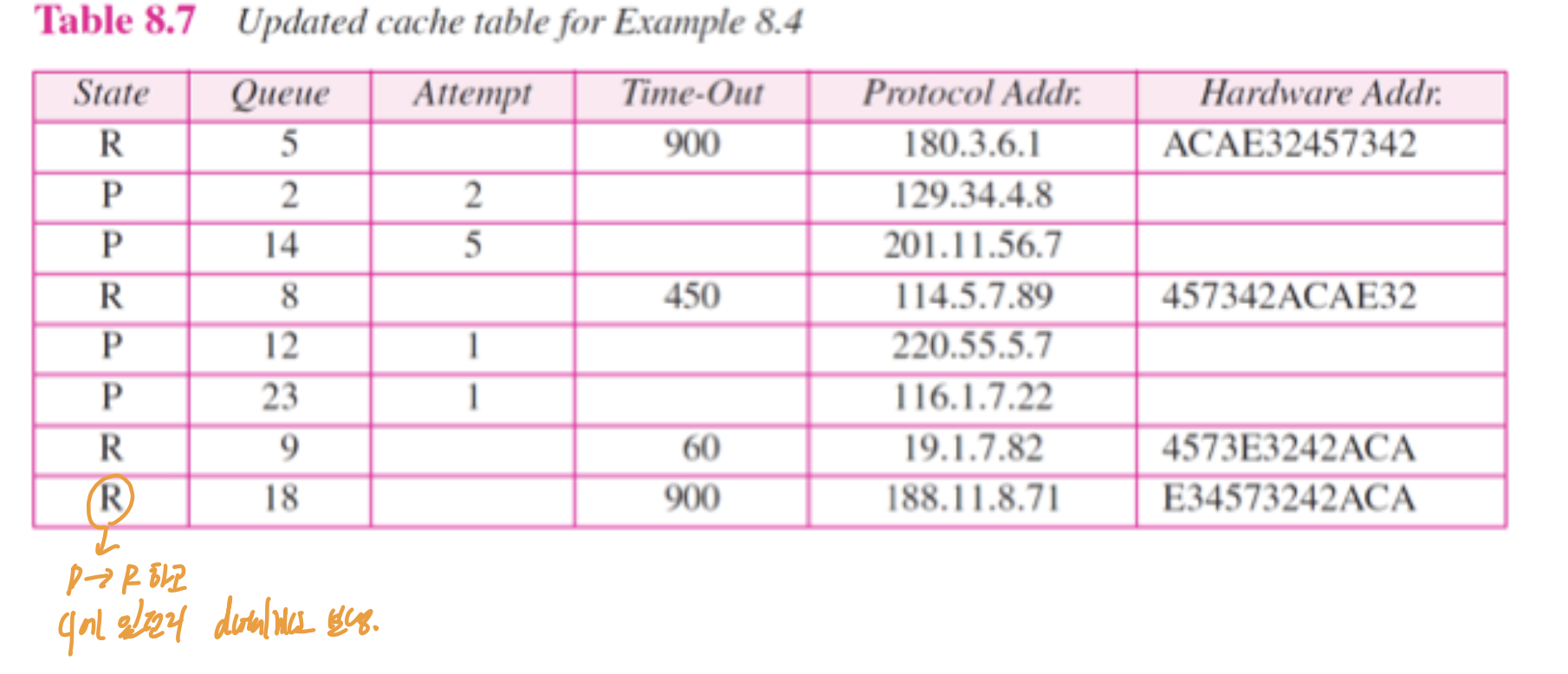
input module ->
APR reply 받음.
table에 있고, P이면 R로 바꾸고 해당하는 queue에 있는 패킷 다 처리.
R이면 업데이트 해준다.
table에 없으면 업데이트 해준다. (queue에 넣어주나?)
ARP request가 들어온다면 Reply를 보내준다.
cache-control module
주기적으로 일어나서 table 확인(주로 60s)
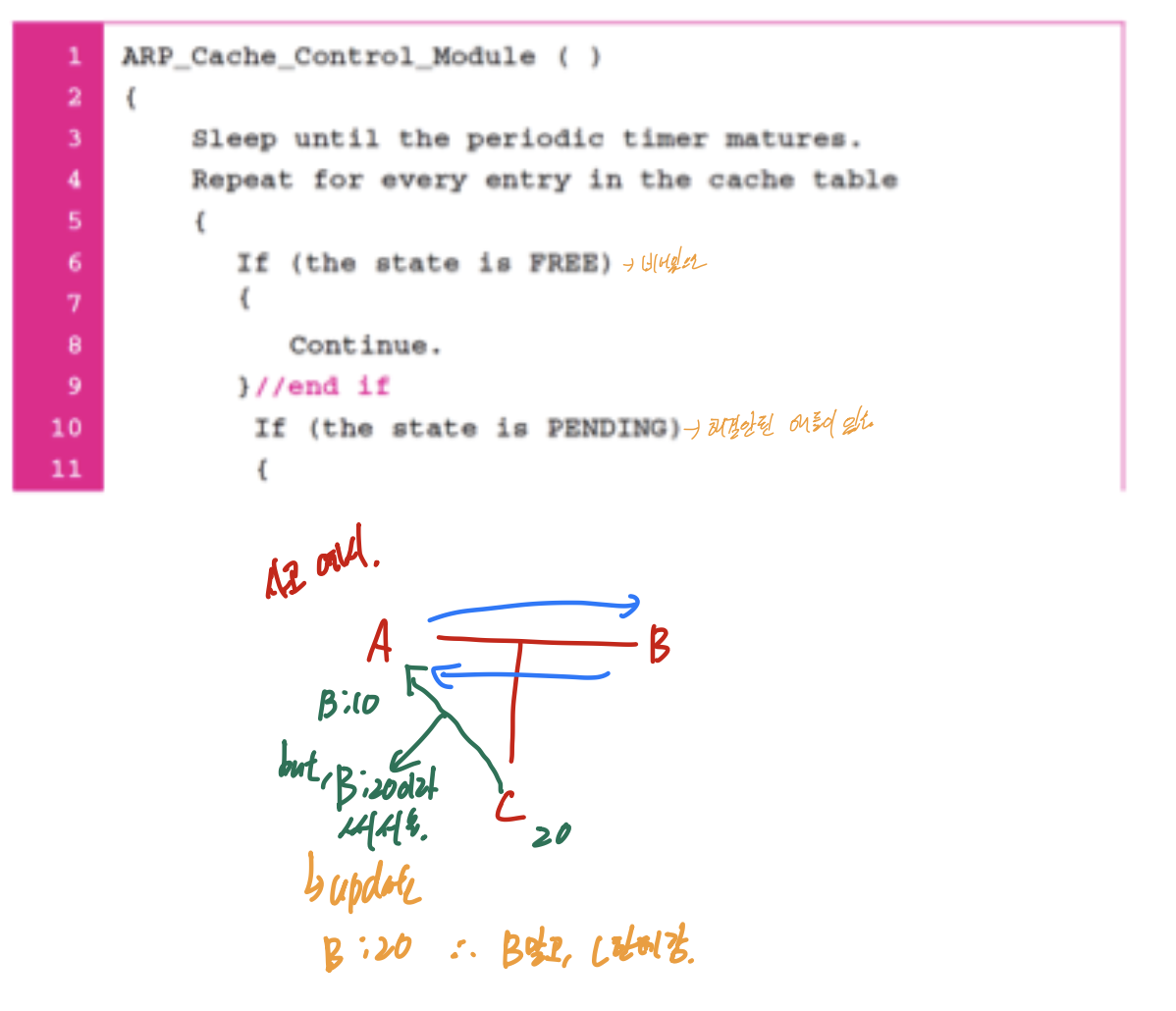
timeout되었는데 해당하는 cache table이 p상태이면, request를 보내고 attempt 1 올림 5보다 커지면 free
timeout 되었는데 R상태이면 Timeout 60 줄이고 0보다 작거나 같으면 free