Basic components
CPU -> system bus
Memory(DRAM) -> memory bus
I/O module -> I/O bus
Every instruction executed by the CPU requires memory access
Data is moved from secondary storage to primary memory for CPU execution.
-> memory로 이동할때 bus를 사용.
-> 데이터를 처리하기 위해 bus를 사용해 memory에서 cpu로 가져옴.
Processor
Arithmetic/logic unit
performs mathematical calculations and makes logical comparisons
Central processing unit(CPU)
A hardware component that performs an instruction set utilizing the ALU, control unit, and registers
Memory
Random access memory
static RAM -> cache
density가 낮다. 비싸다. access 시간이 짧다. refresh가 필요하지 않다.
Dynamic RAM -> Main Memory
transitor/capacitor pair로 density가 높다. 느리다. dynamic refresh가 필요하다.
Flash memory
nonvolatile memory
asymmetric read and write -> 읽기가 쓰기보다 빠르다.
no in-place update
Limited endurance
Solid State Disk
based on flash memory
일반적인 I/O bus의 디스크 슬롯으로 들어가 다른 디스크(HDD)처럼 작동함.
Flash Translation Layer(FTL)
flash memory의 특이점을 가리는 동시에 HDD의 기능을 모방하는 software layer
Processor Registers
General purpose registers
register use를 최적화 하면서 memory의 참조를 최소화 하는 목적.
intermediate result or date values를 hold하고 있다.
Special-Purpose Registers
Program counter
Program counter는 현재 실행 중인 명령어의 주소를 저장하는 레지스터입니다. 즉, CPU가 다음 실행할 명령어의 주소를 계산하는 데 사용되는 값이 Program counter에 저장된 주소입니다.
CPU는 Program counter의 값을 사용하여 메모리에서 다음 실행할 명령어를 가져오게 됩니다. 명령어가 실행되면, Program counter는 다음 명령어의 주소를 가리키도록 업데이트됩니다. 이렇게 Program counter는 CPU가 현재 실행 중인 명령어와 다음 실행할 명령어를 추적하는 데 사용됩니다.
따라서 Program counter는 현재 실행 중인 명령어의 주소를 저장하고, 다음 실행할 명령어의 주소를 계산하는 데 사용됩니다.
chatgpt로 따옴.
Instruction register
Instruction register는 CPU에서 현재 실행 중인 명령어를 저장하는 레지스터입니다.
CPU가 메모리에서 명령어를 읽어오면, 이 명령어는 Instruction register에 저장됩니다. 그리고 CPU는 Instruction register에서 명령어를 디코딩하여 실행합니다. Instruction register는 명령어의 주소를 저장하는 Program counter와 함께 동작하여 CPU가 다음에 실행할 명령어를 추적합니다.
MAR
MAR은 주소 레지스터(Address Register)이며, CPU가 메모리에 접근할 때 사용하는 레지스터입니다. MAR은 CPU가 읽거나 쓰려는 메모리 주소를 보유하고 있습니다. 즉, CPU가 메모리에서 읽거나 쓰려는 데이터가 있는 주소를 나타냅니다.
반면에, PC(Program Counter)는 CPU가 다음으로 실행할 명령어의 주소를 저장하는 레지스터입니다. CPU는 PC가 가리키는 명령어를 가져와 실행하고, 다음 명령어로 PC를 증가시킵니다. 이 과정을 반복하여 프로그램을 실행합니다.
즉, MAR은 메모리 주소를 저장하고, PC는 다음으로 실행할 명령어의 주소를 저장합니다. 따라서 MAR과 PC는 서로 다른 목적을 가지고 있습니다.
instructon 동작 흐름
PC에 메모리 주소 저장, MAR에 저장되고 MBR에 그 데이터 저장.그리고 IR에 그 명령어가 저장되고 opcode/ operand 분리되어 ALU로 감. 그리고 ALU를 통해 MAR에 다시 operand의 address가 저장되고, MBR에 값 저장. 그리고 다 되면 PC에 다음 주소가 옴.
-> 강의 한번 더봐도 될거같음.
Interrupt
interrupt mechanism 강노
일반적으로 CPU에서는 인터럽트가 발생하면 현재 실행 중인 프로세스나 작업을 중단하고 인터럽트 핸들러(Interrupt Handler)라고 불리는 특수한 루틴으로 제어를 이전시킵니다. 인터럽트 핸들러는 인터럽트의 원인을 식별하고 해당 작업을 처리한 후, 다시 중단된 프로세스나 작업으로 제어를 반환합니다.
인터럽트가 발생하면 CPU는 현재 실행 중인 명령어를 중단하고, 이전에 실행하던 명령어 주소를 저장하기 위해 현재 PC(Program Counter) 값을 저장합니다. 그런 다음, 인터럽트 핸들러의 시작 주소를 PC에 저장하여 제어를 이전합니다. 인터럽트 핸들러가 완료되면, PC는 저장된 이전 명령어 주소로 복원되고, 실행 중인 프로세스나 작업으로 제어가 반환됩니다.
따라서, 프로세서에서는 PC(Program Counter)를 인터럽트 핸들러의 시작 주소로 사용하여 인터럽트가 발생하면 효율적으로 인터럽트 처리를 할 수 있습니다.
interrputs and exception
there are two kinds of interrupts
Asynchronous interrupt -> interrupts
generated by other H/W devices
external interrupt
Synchronous interrupts -> exception
generated by cpu
interrupts and Exception are all handled in the same way at linux
Memory
computer's memory
3 design components
1. Capacity
2. Cost
3. Access time
not only rely on a single memory component or technology, but also employ multiple memory components(hierarchy)
Memory Hierarchy
자주쓰는건 위에, 아닌건 아래에 둔다.
Locality
-
Temporal locality
만약 한 item이 참조된다면, 그것이 곧 다시 참조될 경향. -
Spatial locality
만약 한 item이 참조된다면, item과 가까운 주소를 가진 items들이 참조될 경향.
Cache Memory
하나의 instruction에서, processor는 적어도 memory를 한번 접근한다. 그러므로 processor가 instruction을 접근하는 것은 memory cycle time에 의해 제한된다. -> because of the mismatch between processor and memory speeds
그러므로 cache라고불리는 작고, 빠른 메모리를 processor와 memory 사이에 제공한다.
-> 메모리에 자주 접근되는 부분을 cache에 hold한다.
strategies for exploiting spatial locality and temporal locality
Spatial locality
larger cache blocks을 사용하거나 prefetching을 한다.
Temporal locality
by keeping recently used instruction and datavalues in cache memory
-> os chat rr
~ 옛날 강의 한번 보기
I/O Device Overview
I/O communication Techniques
Programmed I/O(Polling)
processor가 반복적으로 I/O module의 상태를 체크하면서(busy waiting), 다 되면 I/O module에서 read하고, write word into memory.
Interrupted-Driven I/O
busy waiting을 하지 않고 I/O module이 done하면 interrupt을 내는 방식.
busy waiting을 없애 병행성을 높인다.
DMA (Direct Memory Access)
CPU의 간섭 없이 Divice controller가 blocks of data를 buffer storage부터 memory로 직접 보낸다.
8. Linux Scheduing
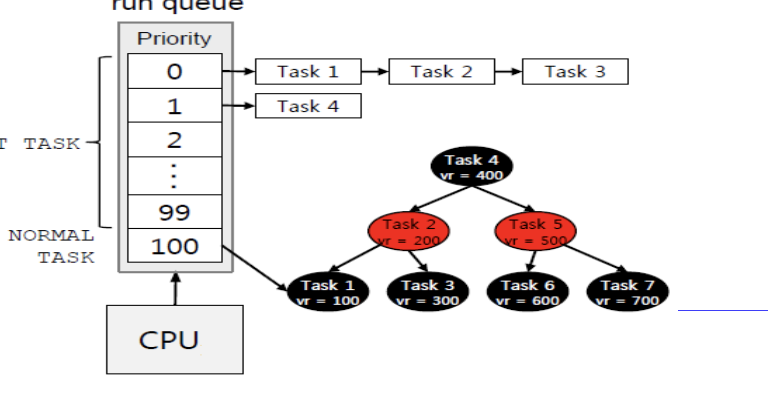
O(1) scheduler
우선순위에 기반한 스케줄러 이다.
각각의 우선순위에 해당하는 queue가 있고, 그 우선순위에 따른 프로세스가 있는지는 bitmap을 통해 나타낸다.

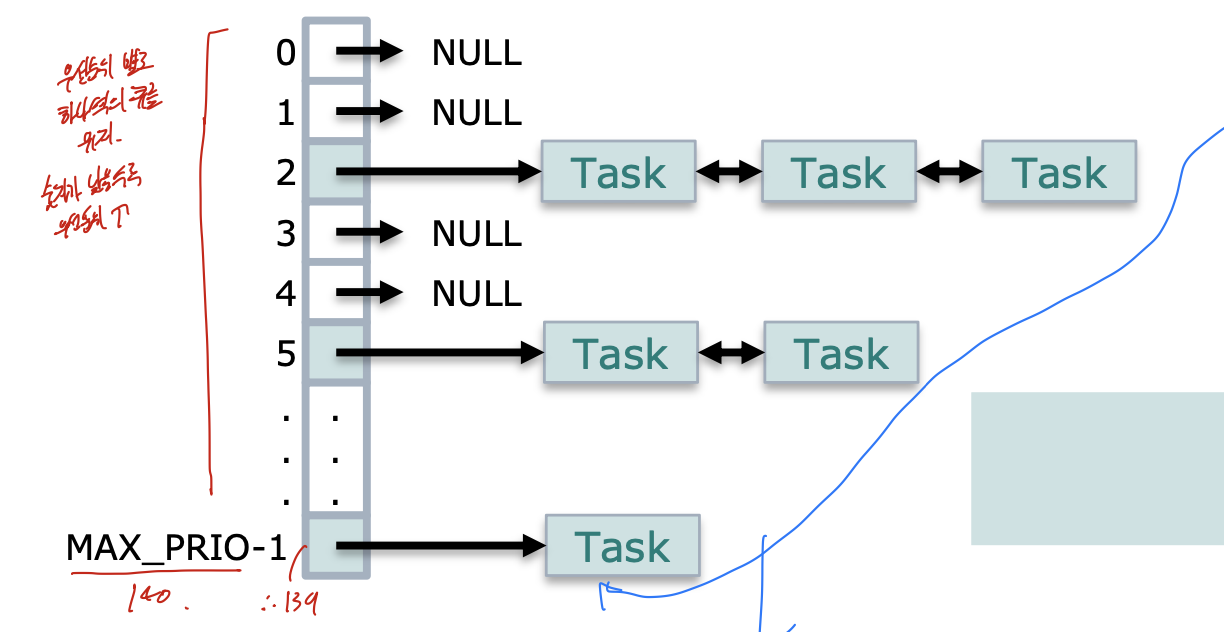
이 두개를 묶어서 run queue라고 한다. 그리고 이 run queue에는 두종류가 있다. active, expire이다.
active에 있는 task들이 시간 할당량을 소진하면 expire로 옮겨진다.
그리고 active에 있는 것들이 다 expire로 옮겨지면, 둘을 바꾼다.
이를 통해 우선순위가 낮은 task들의 starvation 방지하고, Real time task의 재시간성을 보장한다.
또한 task migration도 적용하여 부하가 많은 큐에서 task를 부하가 적은 큐로 옮기는 것도 한다.
Propartional Share Scheduling
시간이 지날 수록 단일 시스템에서 app의 수가 증가하면서, 확장성 문제가 생겨 O1 scheduler가 나왔다. 여기에서 더 나아가서, 멀티미디어가 많이 생기면서 서비스 질에 관심이 생기게 되었고, 그로 인해 CPU 사용시간을 보장하는 것이 필요하게 되었다. 그렇기 때문에 나온 것 이다.
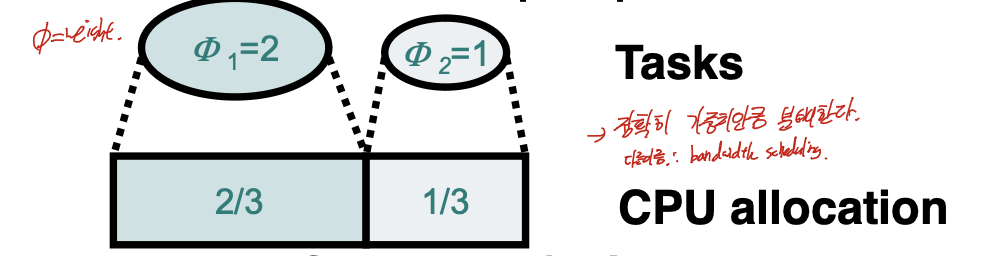
각각의 프로세스를 정확한 가중치 만큼 분배하는 것으로,
1. Fair queueing( Network 관점)
WFQ
2. Propational share( OS 관점)
CFS
로 나뉜다.
Criteria
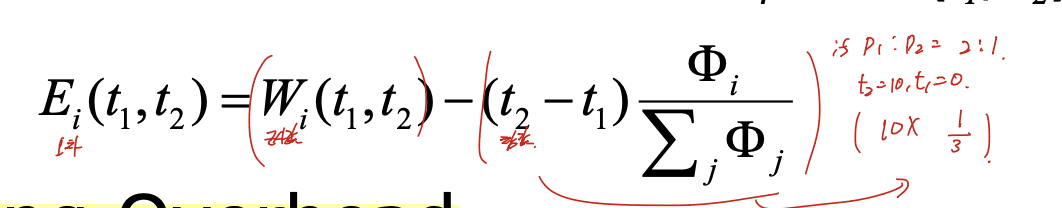
우선 W(t1, t2) 는 t1, t2시간 동안 실제로 할당된 시간이다.
(t2 - t1) ~~ 식은 시간 그 프로세스의 가중치 / 가중치들의 총합으로,얼만큼은 이 프로세스가 할당 받아야 되는 지에 대한 내용이다.
예를 들어 p1 : p2 = 2 : 1이라 하고, t2 = 10, t1 = 0이라 하면
10 * 1/3으로, 3은 이 프로세스가 받아야 하는 양이다.
이 실제로 받은 값과, 받아야 하는 값을 차이를 구해서 이를 오차로 사용한다.
이거랑 Scheduling Overhead도 고려해야 한다.
WFQ(Weighted fair queueing)
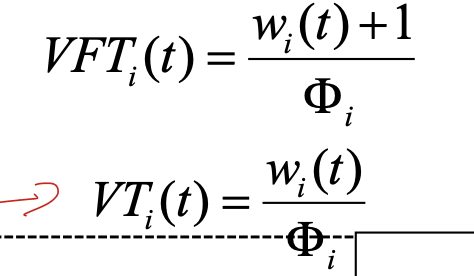
가중치 대비 현재 진행한 값으로 scheduling하는 방법이다.
VFT, VT는 어떤 프로세스 i의 t초까지의 누적 수행시간을 가중치로 나눈 것 이다.
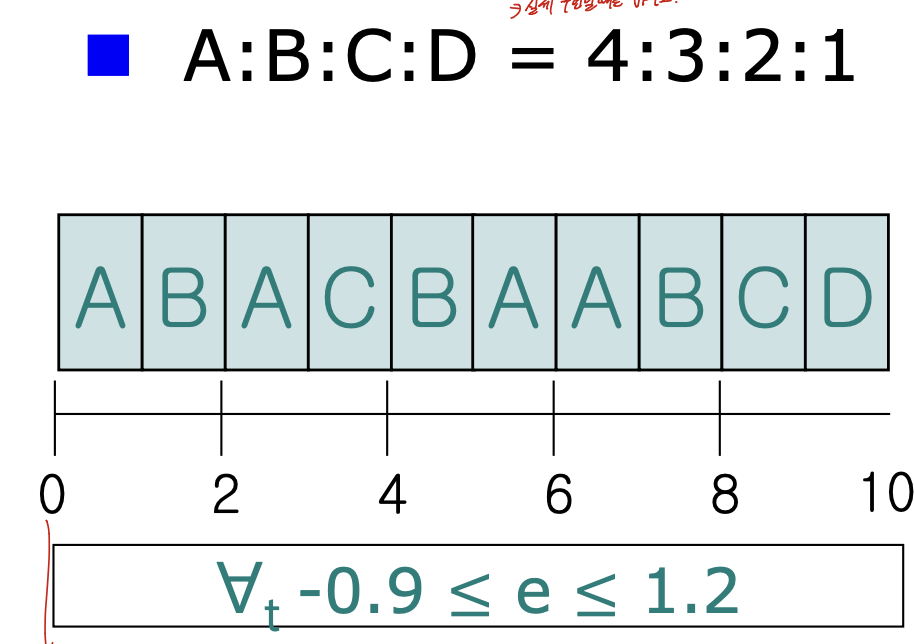
이러한 예시에서 생기는 큐 이다. 진행 과정을 한번 보자.
0초부터 시작한다면, 분자가 전부 0이므로 다 0이다. 그러므로 VFT를 사용한다. 그렇게 되면 A 1/4, B 1/3, C 1/2, D 1 이 되어 가장 작은 A가 선택된다.
그 다음을 보면, A의 수행시간이 1초가 되었으므로 A 1/2, B 1/3, C 1/2, D 1이 되어 B가 들어간다. 이런 방식으로 계속 넣어주는 것 이다.
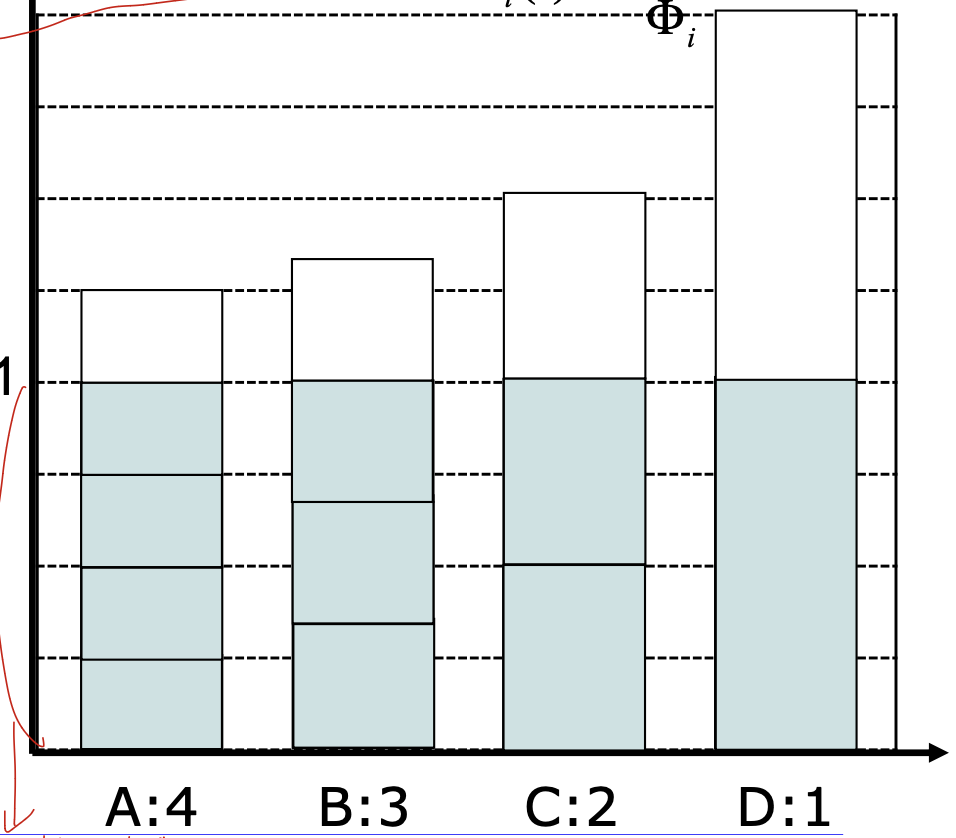
이 그래프 결과를 보면 A 4번, B 3번, C 2번, D 1번으로 다 fair하게 들어온 것을 볼 수 있다.
그렇다면 그냥 round robin과 같은 scheduling과 뭐가 다르냐고 생각할 수 있는데, 중간 어떤 지점을 보면 이 방법을 사용하지 않으면 자신의 가중치를 보장하지 않는다. 그러므로 이 방법을 사용해야 한다.
CFS( Completely Fair Scheduler)
multiple queue를 사용하는데, red black tree로 항상 균형을 맞춘 방식. WFQ랑 비슷하게 동작하지만 VFT의 최소값을 찾는 과정을 레블트로 하여 시간을 최소화 하였다.
9. Thread and Synchronization
Process and Thread
Process
실행중인 프로그램.
두가지 성격으로 구분됨.
1. 자원 소유권으로의 단위
main memory, IO channel, IO device, file와 같은 자원의 관리/소유의 단위.
-> process, task
- 실행 단위 (the unit of scheduling)
프로세스는 실행 상태와(running, ready, etc) 우선순위를 가지고있고 이를 통해 scheduling 될 수 있음.
프로세스의 실행 단위 -> 실행의 주체.
하나 이상이 있을 수 있음.
-> thread (or lightweight process)
Multithreading
여러개의 실행 흐름을 가짐.
single process에서 여러개의 concurrent paths를 가지게 함.
여러개의 쓰레드들은 같은 프로세스 내에서 같은 자원을 공유한다는 장점이 있다!
최초의 쓰레드를 main thread라고 함.
Concurrency
한개 이상의 task가 동시에 진행되도록 하는 것.
Concurrency와 Parallelism을 구별해야함.
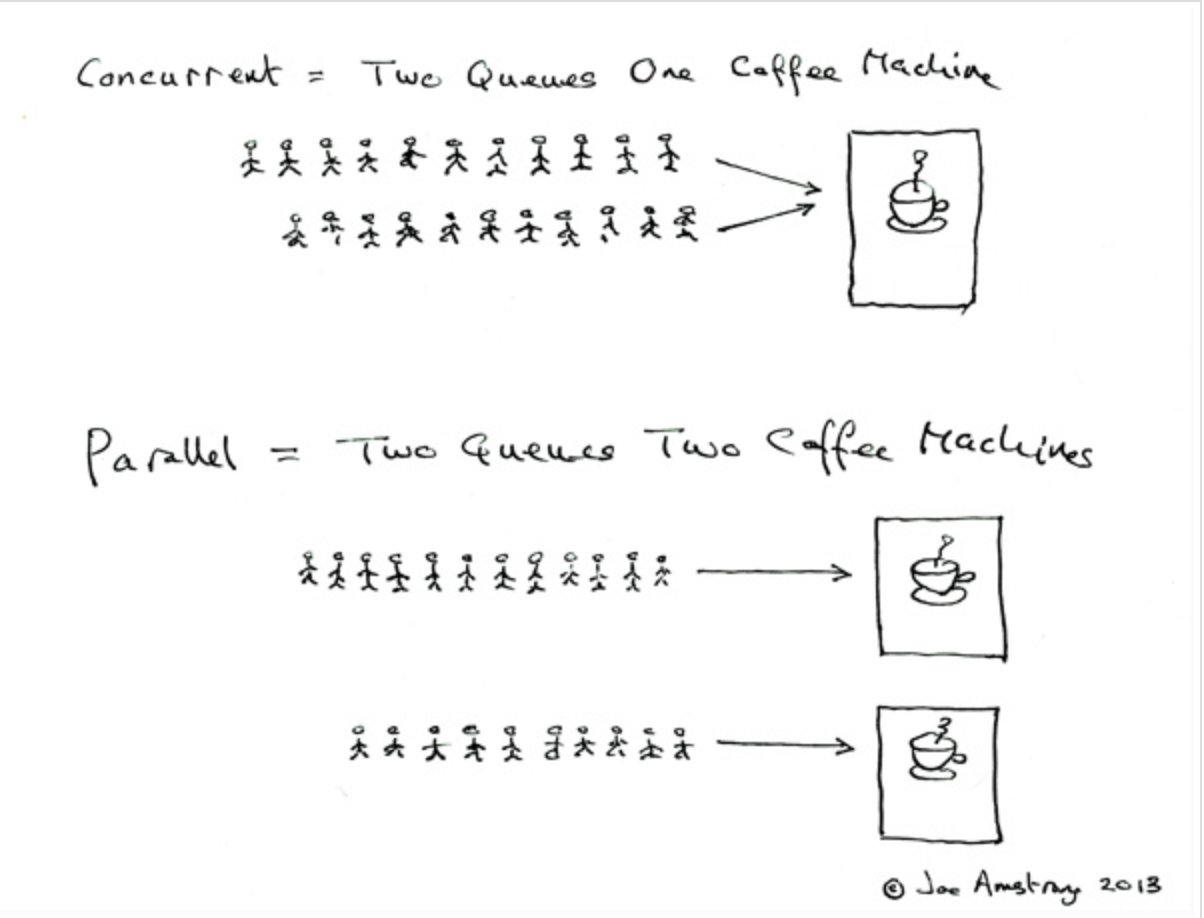
Concurrency -> 동시 진행(병행성)
-> 동시에 실행되는 것 처럼 보이는 것.

이런 interleaving과 같은 경우, looks like parellel 하지만, concurrency를 보장한다.
-> 병렬성 없이 병행성을 가지는 것이 가능하다.
Parallelism -> 동시 실행(병렬성)
-> 실제로 동시에 작업이 처리.
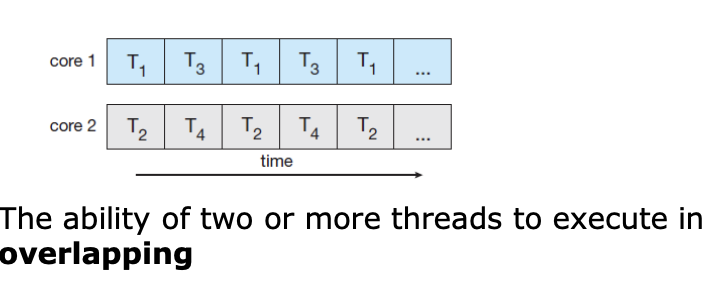
이런게 동시 실행.
강노에서는 하나 이상의 task을 동시에 실행한다고 표현함.
병행성에서는 진행을 하도록 한다 함.
이것이 차이다.
Example
uniprocessor 상에서, multiprogramming은 multiple processes의 multiple threads의 끼어들기를 가능하게 한다.

Motivation
application 은 여러개의 task를 가지고 있고, 각 task가 blocking되지 않고 진행하는 것을 원함.
Traditional single threaded process
Multi-processing solution -> fork()
Multi-threading solution 순으로 진화.
Multi-threading solution -> 요청이 오면, 다른 프로세스를 만들지 않고 새로운 쓰레드를 만들어 요청을 해결함.
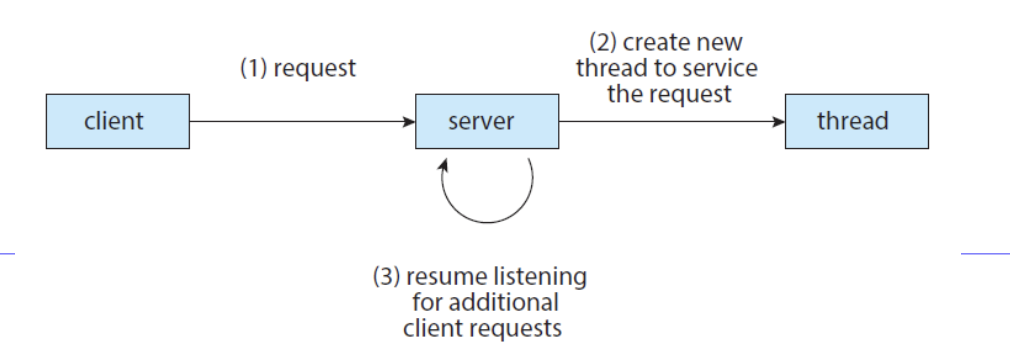
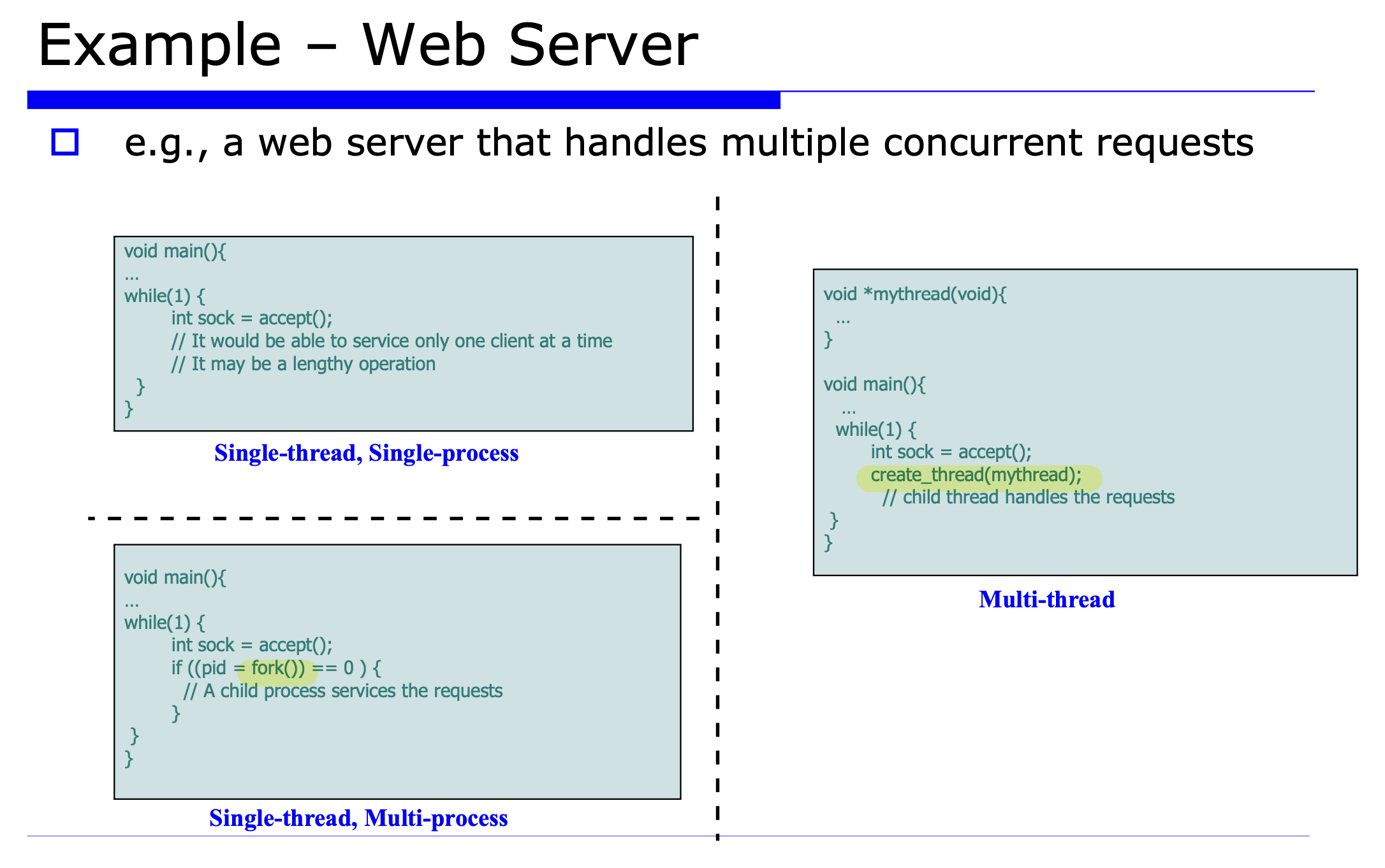
Benefits
1. Faster Response
프로그램이 부분적으로 blocked되거나 lengthy operation을 수행하더라도, 지속적으로 실행되게 함. -> 응답성 향상.
2. Creation/Communication Cost
2.1) Economy of time
전체적인 PCB를 새로 만들지 않아도 된다. -> 생성시간이 fork보다 efficient. -> light weight process라고도 불림.
switch도 또한 process switch보다 빠르다.
2.2) Resource sharing
process간의 자원 공유는 IPC를 사용하므로 복잡하다.
thread는 메모리에 같은 데이터를 읽고 쓸 수 있음. -> communication cost 좋아짐.
3. Parallel Processing
multicore 구조에서 multithreading의 장점이 극대화됨.
process가 multiple CPU에서 실행 가능(parallel) -> 성능 강화.
Multithreading on Multicore
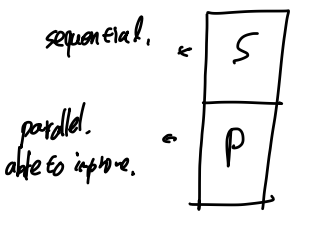
amdahl's law에 의해서 parallel한 부분만 성능 증가 가능.
-> thread가 무한정 증가하더라도 무한정 성능 증가 X
Programming Challenges
- Identifying tasks
task가 서로 독립적이여야 parallel하게 동작 가능하다. - balance
각 task가 balance를 가져야 하낟. - data dependency
데이터 동기화가 보장되어야 한다.
Multithreading Process Model
1. 각각의 thread에 분리된 스택이 필요하다.
각 쓰레드는 execution stack을 가져야 한다. (user/kernel)
thread change -> changing of call-stack 이기 때문.
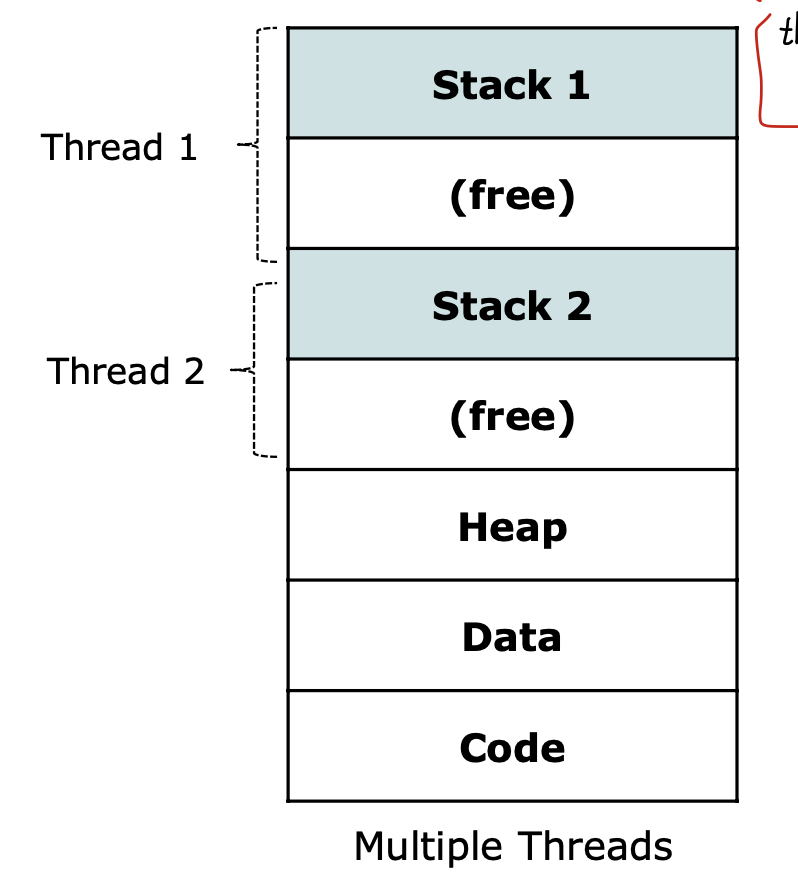
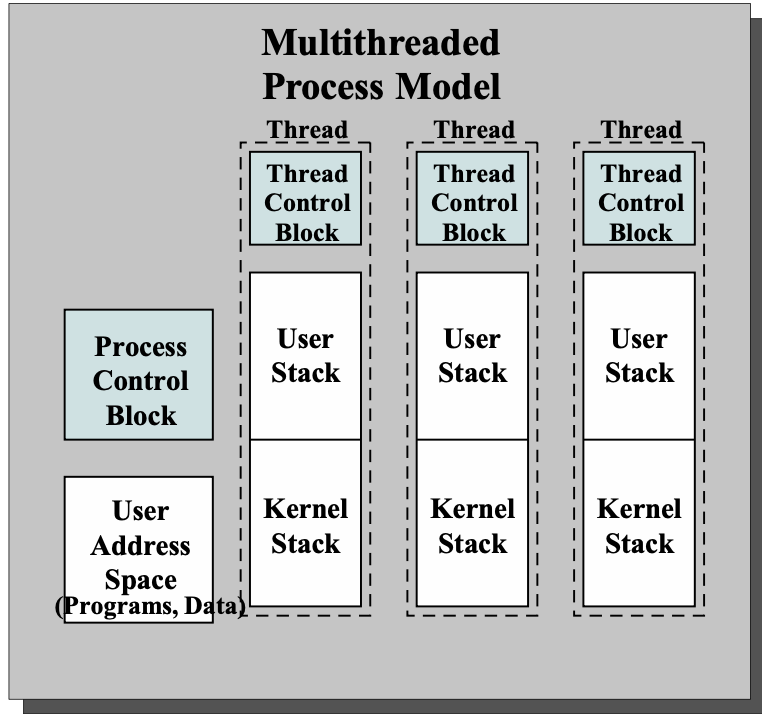
2. Thread Control Block(TCB)
thread -> stack, TCB added.
각각의 thread에 register value, other thread-related scheduling, state information을 가진 thread-related control block을 주어야 한다.
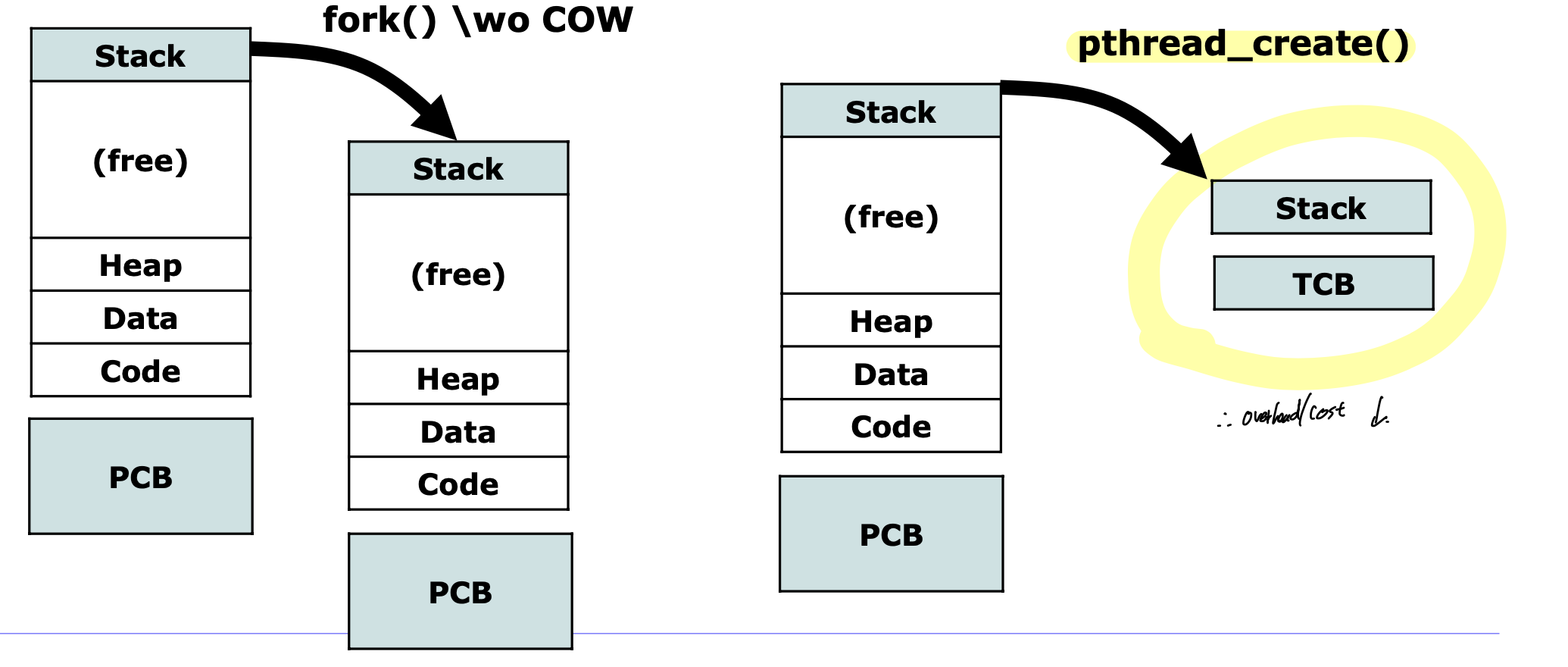
Thread Creation
새로운 프로세스 만드는거 보다는 시간 훨씬 덜걸린다.
stack하고 TCB만 넣어주면 되니까.
switch도 시간 덜걸림.
Multithreading Models
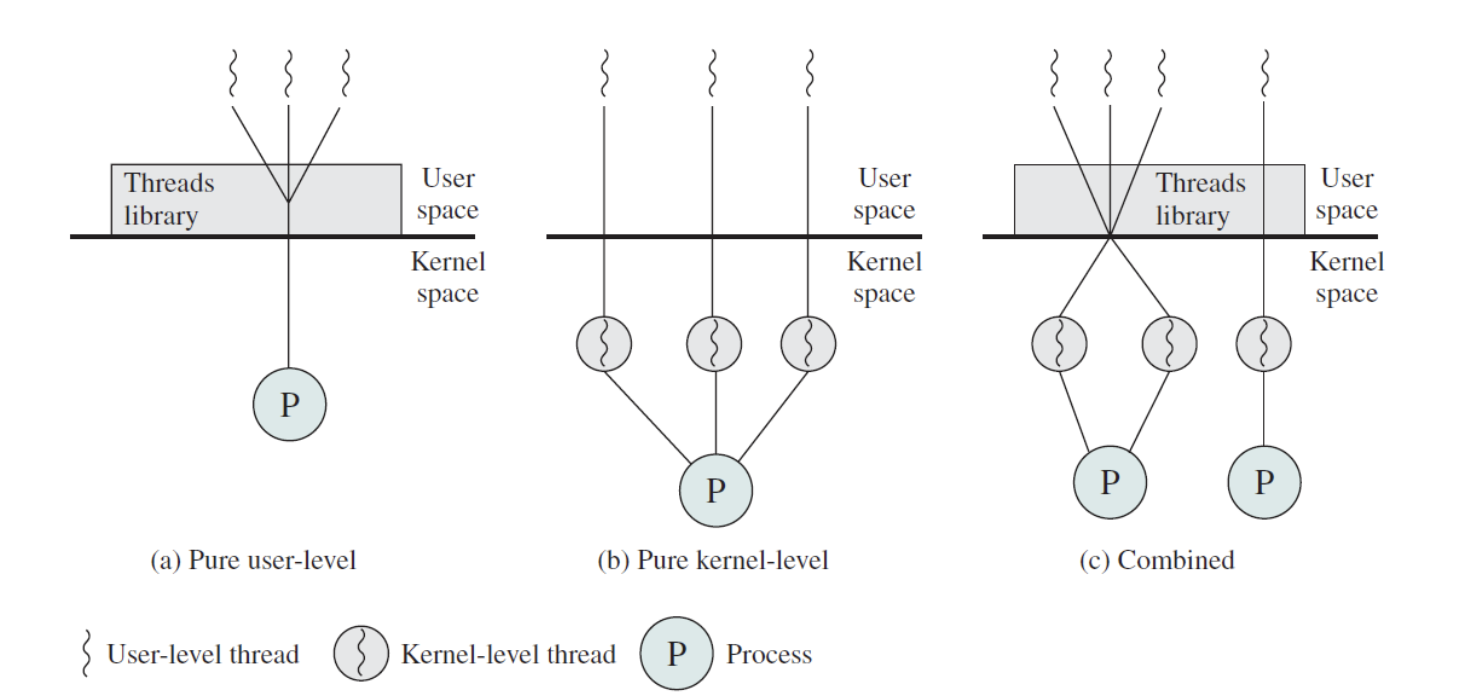
1. ULTs(User level thread)
Thread Library가 생성, 제거, passing message and data between thread, scheduling thread excution, save, restore thread context의 전 과정을 수행하고, Thread library는 user Space에 있다.
Switching Thread과정은 library 안에 저장된 TCB를 save/load 하는 것.
장점 : 빠르다. (kernel mode switch 없이 user에서 다함.)
확장성 좋음.
단점 : Multithreading의 key-pros 완전히 사용 못함.
ex. 하나의 커널 쓰레드(프로세스) 가 여러개의 user level thread 관리,
하나의 쓰레드가 block되면 그 프로세스 자체가 block -> parallelism 없음.
단점 해결 : blocking system call을 non blocking으로 바꿈. -> jacketing
2. KLTs(Kernel Level Threading)
OS managed thread == kernel level thread
모든 Thread management가 kernel 에서 수행. -> 상대적으로 mode-switch에 따른 cost 발생.
1 Thread per 1 kernel로, 각각의 쓰레드에 context information을 유지한다.
장점 : multiprocessor에서 multiple threads가 parallel하게 동작할 수 있다.
하나가 blocking system call을 만들어도, 다른 쓰레드 실행 가능 -> more concurrency
단점 : kernel mode로의 swithch를 통한 overhead 발생.
3. Combined ULT/KLT
thread creation은 user space에서 하고
single application에서 여러개의 ULTs는 동일하거나 더 적은 개수의 KLT에 매핑됨.
프로그래머가 KLT의 숫자를 조절할 수 있음.

Posix Threads(Pthreads) Interface

일단 머 외우고
여기 뒤엔 코드보고 해야되서 일단 강노로.
10. Synchronization1
thread는 multithreaded program에서 shared resources에 접근함.
-> 동시에 접근한다면 race condition 발생할 수 있음.
-> 동기화 해야됨.
Race Condition
공유자원에 접근하는 thread들의 결과가 비결정적/재현불가능

execution timing의 관점에서는
Multithreading -> CPU scheduler에 의해 Interleaving 될 수 있음.
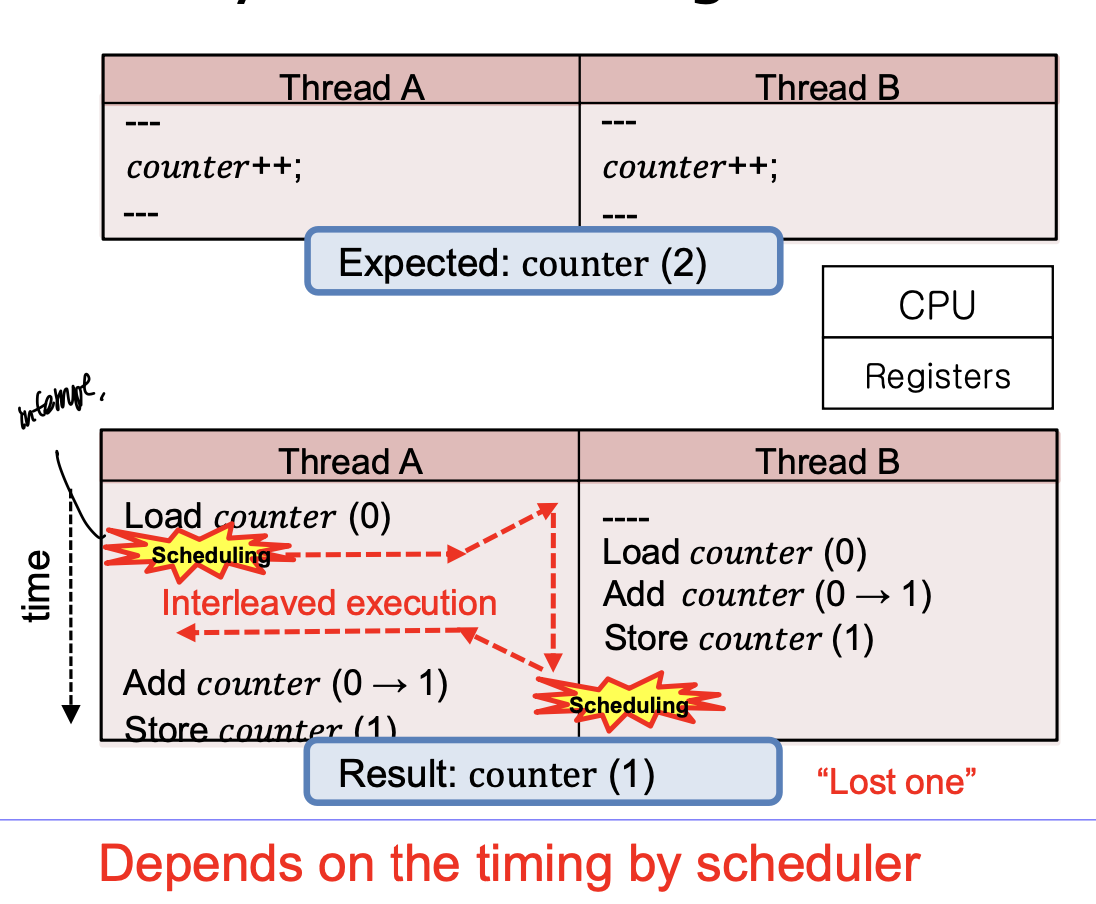
Thread A에서 counter = 0을 가져오고 interleaving(reScheduling)된다면 Thread B에서 다시 counter = 0 , counter <= 1로 바꾸는 과정을 먼저함. 그 후 다시 Thread A로 온다면 counter = 0 인 상태이기 때문에, 두개의 쓰레드가 수행됬음에도 결과는 counter = 1 이 된다. -> race condition
Multiprocessor -> multiprocess 각각의 실행 타이밍이 다양하다.
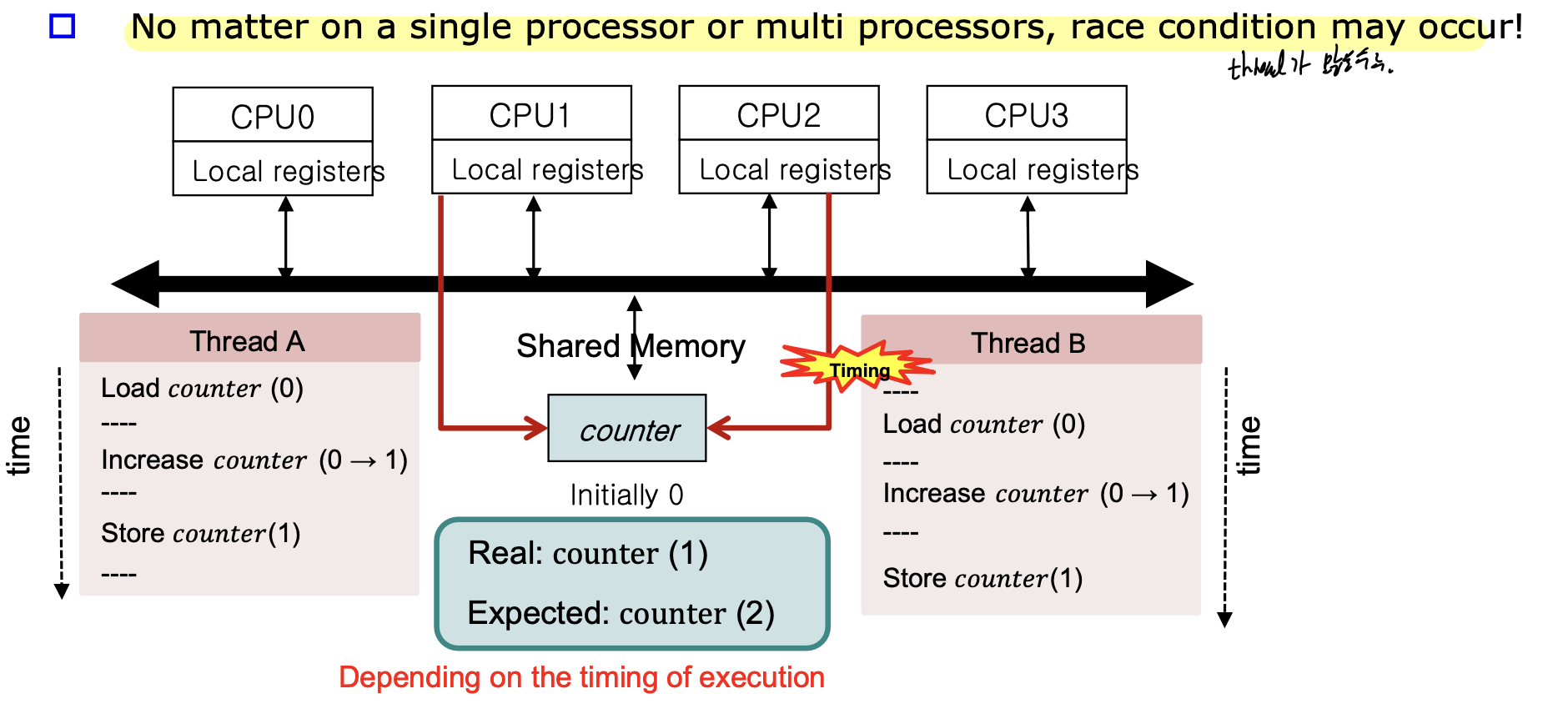
Thread A와 B의 time을 주의깊게 보자. A가 counter(0)한 후에 변화가 생기지 않은 상태로 B가 counter(0)을 하기 때문에 실행 타이밍의 문제로 결과가 0이 나오게 된다.
Race Condition 은 쓰레드 간의 문제이다
공유자원을 Atomic operation으로 접근하는 것은 어렵다.
(Atomic operation : interrupted 될 수 없는 operation, "entirely or not at all")
Single operator가 여러개의 insturction으로 complie될 수 있다. -> 그 중간에 interleaving 된다면 답 없음.

Critical Resource
각각의 쓰레드는 자신의 stack을 가지고 있고, 자신을 위한 CPU register의 복사본을 가지고 있지만
정적 데이터, heap memory, file, IO devices는 모든 쓰레드에 대해 공유된다.
Critical Resource는 하나의 쓰레드만 한번에 접근할 수 있는 자원을 의미한다.
Critical Section은 Critical Resource에 접근하는 코드를 의미한다.
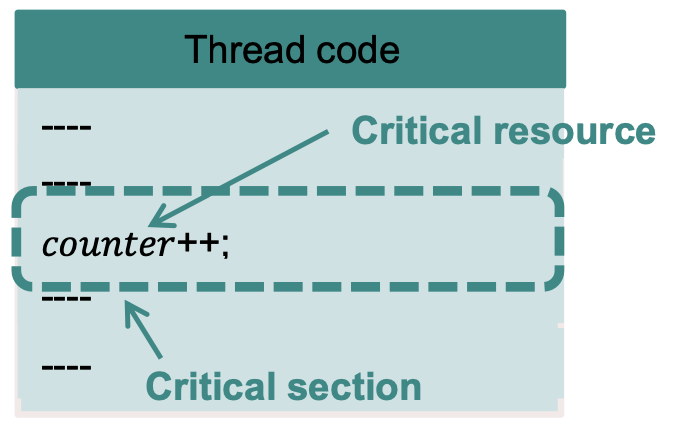
Mutual Exclusion
오직 하나의 쓰레드만 critical section을 한번에 실행해야 한다.
그러므로 Critical section을 상호배제 해야 한다.

프로세스/쓰레드 동기화는 race condition을 피하고 실행의 정확성을 위해 critical section에 상호배제를 제공하는 과정이다.

상호배제는 entercritical(), exitcritical()을 제공해 다른 프로세스가 critical section에 접근하려는 것을 기다리게 한다.
-> 이 두개를 통해 critical section을 atomic하게 만들어야 한다.


3 conditions of Critical SEction Problem
3.1) Mutual Exclusion
상호배제 해야한다.
3.2) Progress
Critical Section 사용중인 쓰레드가 없다면 실행하고 싶은 쓰레드를 바로바로 실행할 수 있게 해야한다.
3.3) Bounded Waiting
기다리더라도 한정된 시간을 기다려야 한다. 즉, 언젠가는 실행되어야 한다.
1. Naive approach(incorrect)
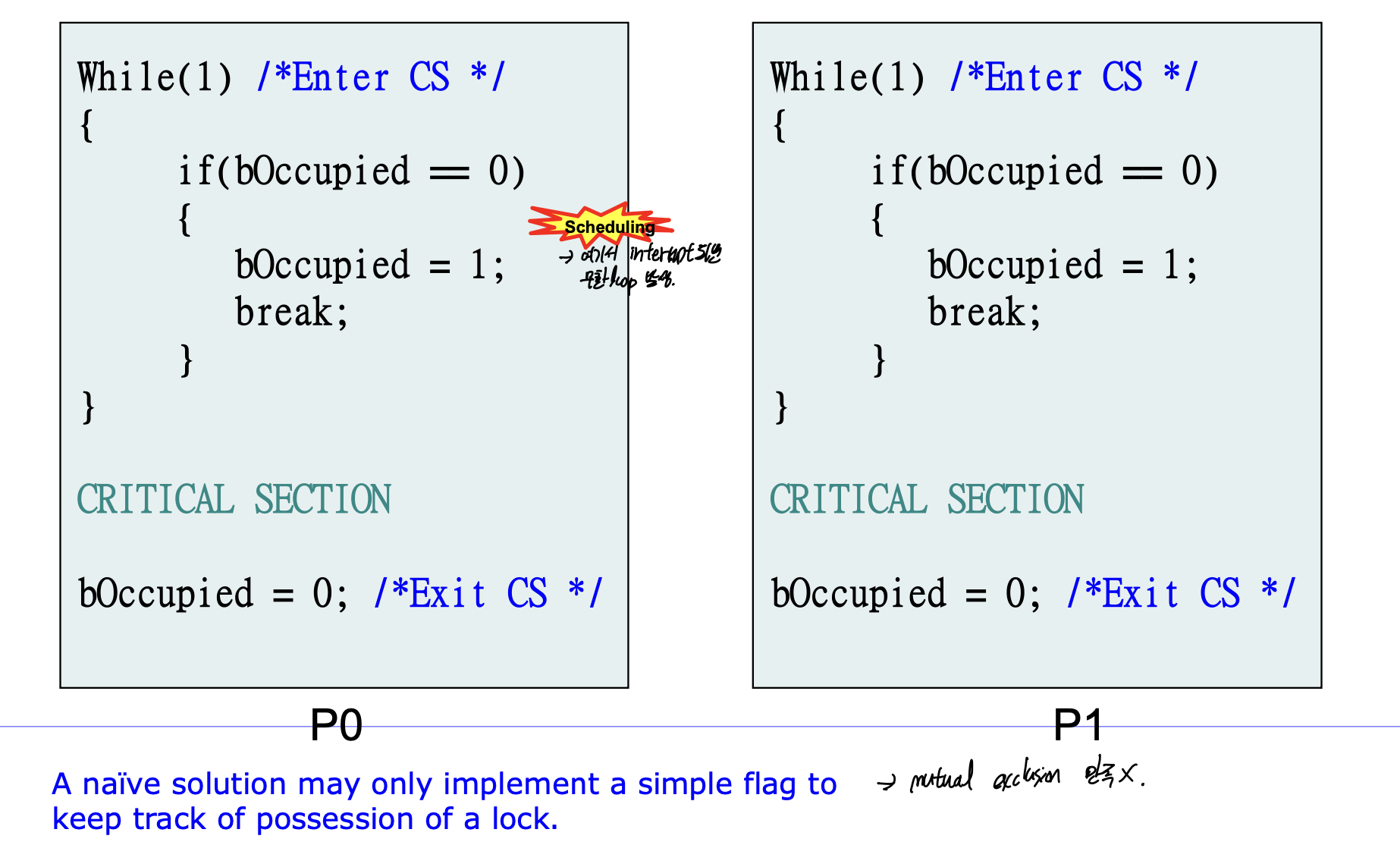
단순한 flag를 하나 만들어서, critical section을 감싸 준 모습이다.
하지만 P0의 bOccupied 이전에 reschedule될 수 있기 때문에, 이렇게 하면 안된다.
-> Mutual Exclustion 만족 X
2. SW approach(1)

단순히 각각의 프로세스에 대한 flag를 만들어서 이를 서로 갱신하고, 체크하는 코드이다.
P0에서 while(flag[1]) 이전에 scheduleing이 된다면, p1으로 가게되어 time slice가 다 사용될 때까지 무한루프를 계속 돌고, 그 후에 다시 p0에 와서 무한루프를 돌게 된다. 그러므로 이는 Progress 조건을 만족하지 못한다.
3. SW approach(peterson)

2. 에 turn이라는 flag를 하나 추가한다.
flag 배열은 둘다 true가 될 수 있는데, turn은 1 또는 0인 값을 가진다.
이를 통해 하나가 Critical section을 실행할때 다른 것은 실행되지 못하도록 하고, 실행이 끝나면 다른 것이 실행되도록 한다.
모든 아키텍쳐에서 동작 X, 효율성 떨어짐
4. Disabling Interrupts
critical section에서의 interrupt를 불가능하게 만드는 방법.
uniprocessor에서만 가능하다.
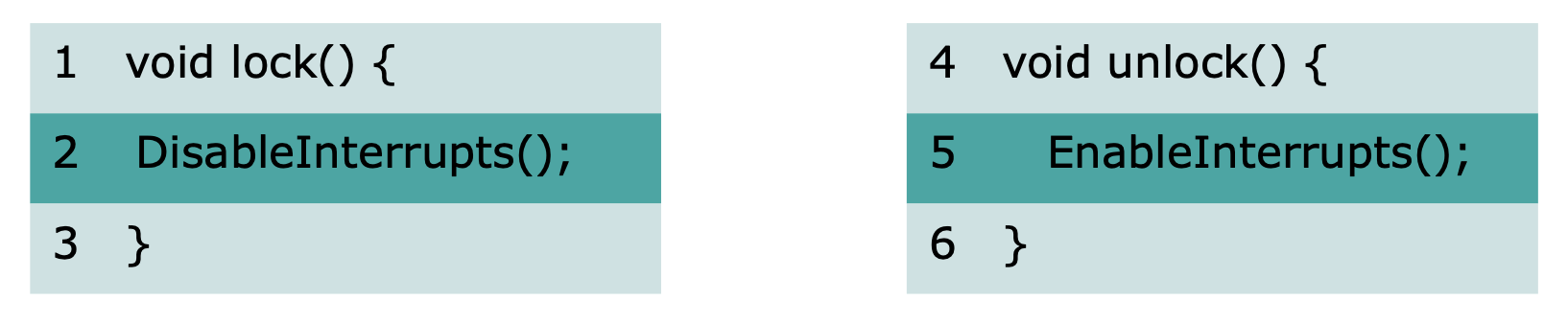
장점 : 단순함
단점 : multiprocessor에서 적합하지 않다, interrupt를 잃어버리는 결과를 낳을 수 있다.
Special Machine Instructions
하드웨어에서도 lock mechanism을 위해 추가적인 Instruction을 지원한다고 한다.
CAS(Compare and Swap Instruction)
비교하고 값을 바꾸는 것을 atomic한 하나로 만들어 놓은 것.

Spin Lock
while과 같이 반복을 통해서 lock을 체크하고, 기다리게 하는 것.

busy waiting, spin waiting은 이것이 critical section에 들어가기 위한 허락이 떨어지기 까지 아무것도 안하고 기다리는 것 이다.
mutual exclusion 을 제공하는가?
임계영역에 한번에 한 쓰레드만 들어가도록 한다. 그러므로 제공된다.
하나 이상의 프로세서가 있으면 적용 가능하다.
cost
spin lock은 허락될때까지 loop를 돌며 기다리는 과정이다. 그러므로 single processor일때는 하나가 loop를 돌면 나머지는 기다려야 한다.
fairness
기다리는 프로세스를 선택하는 것은 임의적이다. 그러므로 spin lock은 pairness를 보장하지 않고, starvation이 나올 수 있다.
Semaphore
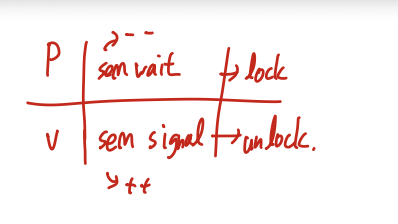
semaphore는 병행적인 시스탬에서 접근을 통제하는데 일반화된 동기화 기법이다
Semaphore S는 int value를 가진 객체로 현재 사용 가능한 자원 유닛의 숫자를 가진다.


Implemented with no Busy Waiting
busy waiting을 피하기 위해, semaphore는 큐를 사용하여 프로세스를 기다리게 한다.
n-process critical section problem을 처리할 수 있다.
Binary semaphore
semaphore의 값이 0, 1로 고정.
mutex lock임

Semwait에서 process를 block하고
sem wait에서 sleep queue에 있는 프로세스를 꺼내서 ready list에 넣는다.
오래 기다린 순으로 먼저 ready list에 넣으면 -> 강성 세마포어
그렇지 않으면 -> 약성 weak semaphore
Counting semaphore
general semaphore, 제한된 값 까지 semaphore값이 올라갈 수 있음.

음수의 의미 -> 대기하고있는 (blocked) thread의 수
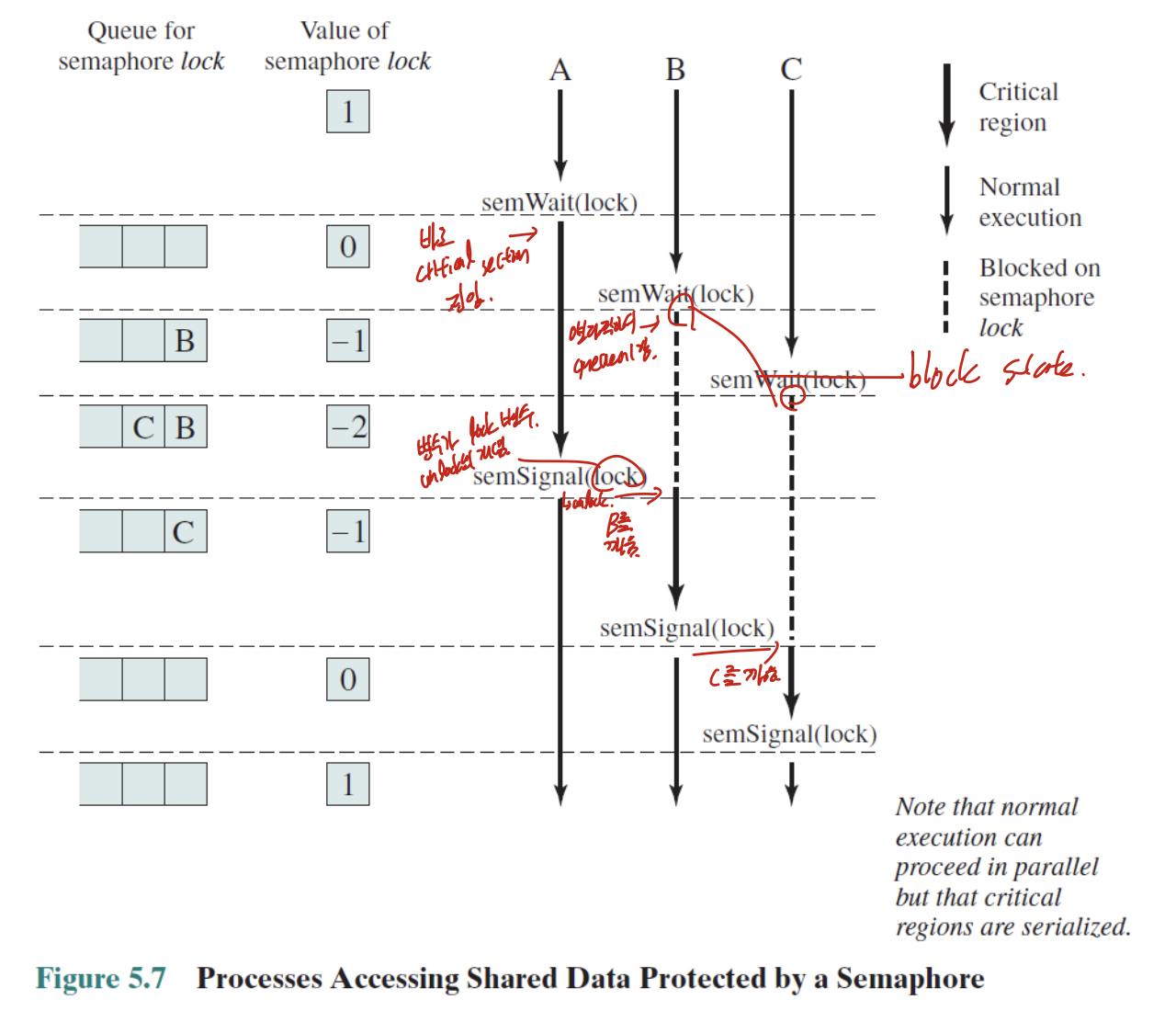
Implementation
semaphore 변수 자체도 전역변수 이기 때문에 race condition발생 할 수 있음.
따라서 구현할때 spin lock(CAS), interrupt disabling

Deadlock
semaphore와 waiting queue를 사용하게 된다면 Deadlock이 생길 수 있음.

프로세스 간에서 서로를 기다리느라 둘 다 진행을 못하는 것.
11. Synchronization2
Condition Synchronization
조건에 따라 재개하거나, 중단하는 조건에 따른 제어.
execution ordering
Condition Variables
특정한 조건이 만족할 때 까지 프로세스나 쓰레드를 block하는 데이터.
wait() -> 조건이 충족되지 않으면, go to sleep한다.
signal() -> Waiting thread중 하나를 깨운다.
broadcast() -> 전부를 깨운다.

이렇게 사용하며, mutex와 관련이 있다는 것을 알아야 한다.
사용의 예시로는 join()이 있다.
child가 종료될 때 까지 block상태로 기다려야 하므로, Loop로 지속적으로 조건을 맞춰서 재우고, thr_exit()이 된다면 done = 1로 바꿔 루프를 지워주고, signal을 해준다.

Scenario
scheduler에 따라 비 결정적이므로 두개의 시나리오가 나올 수 있다.
1) 부모가 먼저 실행(join() -> exit())
위에 쓴 순서처럼 T1에서 mutex lock 걸고, loop로 들어가서 condition wait가 된다. 그 후에 exit가 실행되어 done = 1, condition signal을 하고, join으로 돌아와서 loop가 꺠지고 mutex unlock이 된다.
2) 자식이 먼저 실행(exit() -> join())
done = 1, cond_signal이 먼저 수행되므로 T1에서 따로 루프에 들지 않고 종료된다.
Broken Solution
1) mutex가 없다면?

wait와 signal 과정을 상호배제 하지 않는다면, 만약
while(done == 0) 이후에 rescheduling이 되어 exit이 수행되었을때, done = 1이 되고, signal이 수행된 다음 wait이 수행이 된다.
이러면 wait된 쓰레드는 signal로 깨어날 수 없다. 그러므로 영원히 잔다.
-> wait(), signal()은 mutex lock을 유지해 주어야 한다.
2) 상태변수(done)이 없다면?
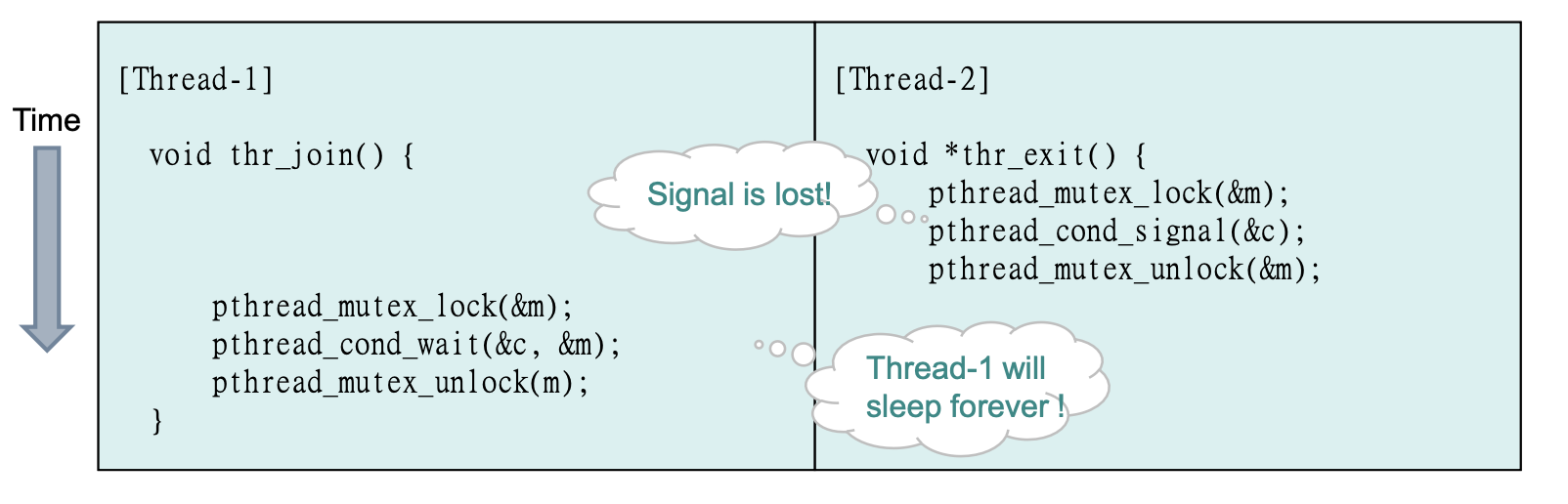
while로 계속 체크해 주지 않는다면, child가 먼저 수행되는 경우 문제가 생긴다.
signal되고 exit()이 종료한 후에 join이 들어가게 된다면, cond_wait()하고 영원한 잠에 들어간다.
-> state variable로 loop를 통해 check해 주어야 한다.
Producer/Consumer problem

producer -> 자원 생성/추가
consumer -> 자원 삭제/해제
둘다 버퍼에 관여하는 writer.
Infinite Buffer

버퍼가 무한정 늘어난다는 가정이기 때문에, consumer만 제한을 걸어준다.
consumer에서 보면, if라 되어있는데 이거 while로 바꿔야 한다.
Bounded Buffer
버퍼에 사이즈가 정해져 있는 것.
1.

보면 consumer에 if로 CV를 wait해주고 있다.
if를 사용하면 한번만 체크해주기 때문에, c1 -> c2 -> c4로 하나 먹고, c5 -> c6 -> c4가 되어 비어있는데 get()이 수행된다.
그러므로 while()로 바꾸어서 지속적으로 re checking해주어야 한다.
2.
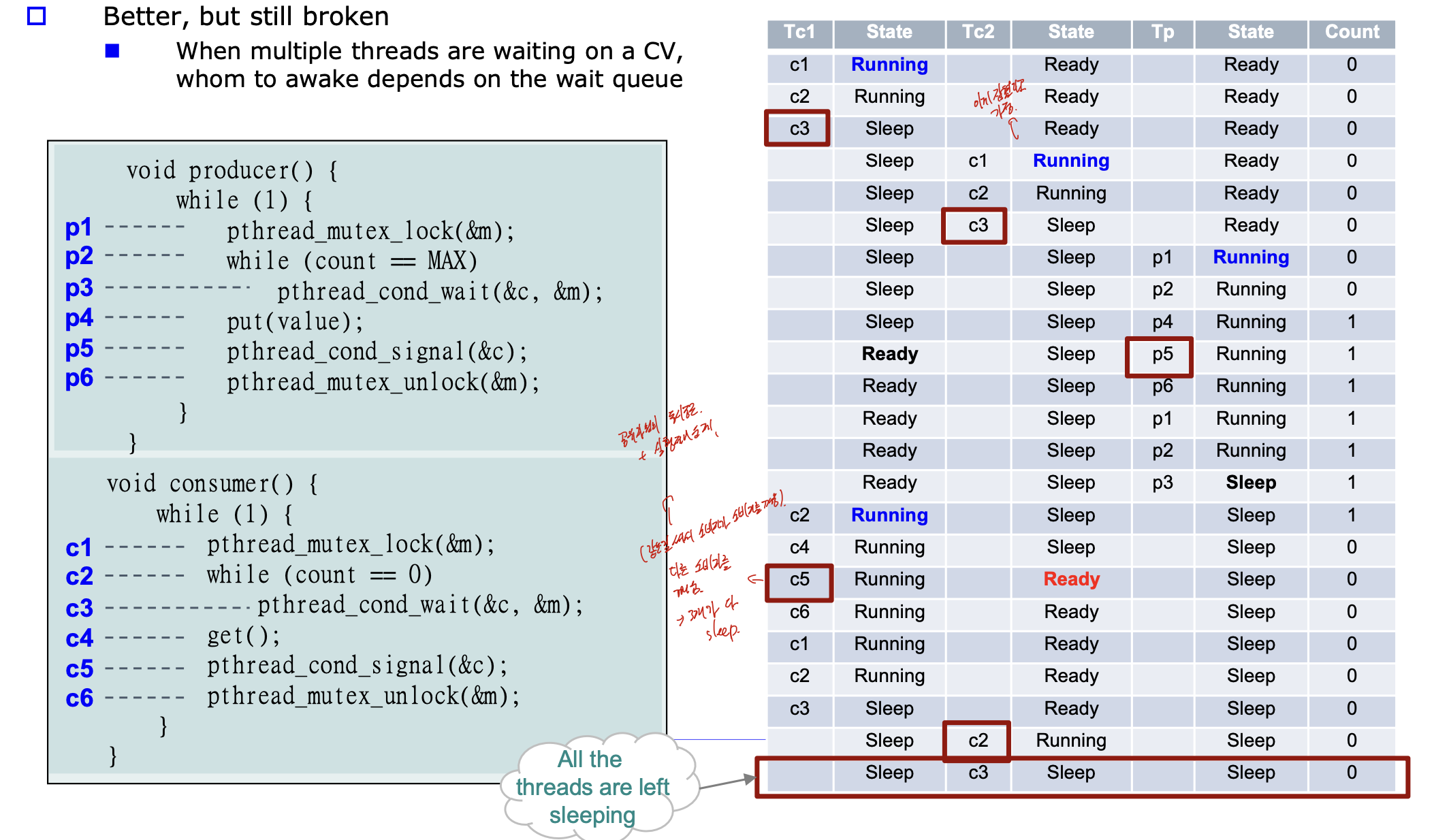
while로 바꿔도 문제가 생긴다.
같은 CV에 producer와 consumer의 wait, signal이 동시접근하기 때문에다.
p5로 signal을 보내 Tc1이 깨고, Tc1의 c5로 인해 Tc2가 깬다.
하지만 버퍼의 max는 1 이므로, 두개가 연속으로 먹으면 안되다.
-> 공유자원의 동시접근 -> 실행제어 문제.
3. solution
producer가 consumer 깨우고, consumer가 producer 깨우면 된다.
-> 두개의 CV를 사용하면 된다(fill, empty)

-> 여기서 모든걸 semaphore를 사용해서 바꿀 수 있음.
semaphores are used for both
1. mutual exclusion
2. condition synchronization

이거 왜 0인지 모르겠음
-> semaphore 구현 보면, ++, -- 연산 먼저 수행하고 비교.
그러므로 0 되야됨.
-> 이 예제에서는 무조건 멈춰줘야 하니까 0 주는거고, 상호배제 할때 1 주는거는 일단 진행하고, 그 뒤에 오는것들 막아주는거니까 1 주는거임.

이게 최종본 전 단계.
P, V를 semaphore로 사용.
하지만 이 경우에서는 락을 걸고, 비었는지 차있는지를 확인한다. 그렇기 때문에 그 사이에 reschduling이 된다면 다른건 그냥 수행 못함.

그래서 이렇게 가야 된다.
Disadvantage of semaphore
semaphore를 사용한다면 P, V가 프로그램 상에서 흩어지는 경우가 많다.
이러면 디버깅이 힘들어지고, 옳음을 찾기 힘들다.
그리고 Deadlock이 발생할 수 있다.
Readers-Writers Problem
생산자, 소비자 문제는 둘다 writer이다. -> 실행흐름문제.
이 문제에서는 Reader가 shared memory에 따로 변화를 주지 않기 때문에, 동시접근해도 무방하다는 가정을 한다.
기본은
첫번째 reader가 들어왔을때 lock(1 -> 0)
마지막 reader가 나갈때 unlock(0->1) -> reader preference 밑에서 볼거다.
이를 위해 wsem이라는 writer를 제한하는 semaphore -> 1이 생기고.
readcount를 위한 semaphore X가 생긴다.
Reader preference
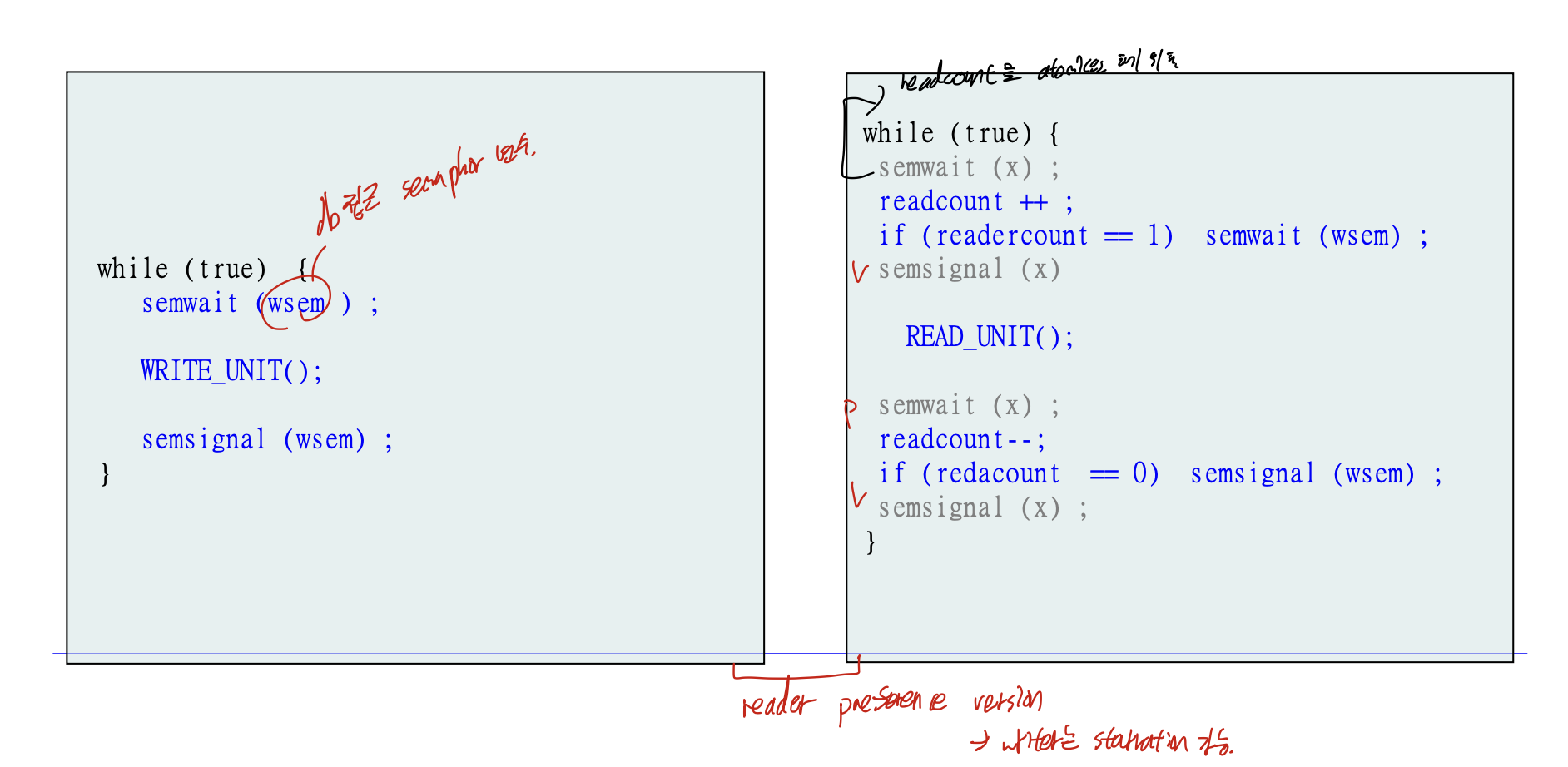
위의 설명대로
첫번째 reader가 들어왔을때 wsem lock(1 -> 0)
마지막 reader가 나갈때 wsem unlock(0->1)
을 통해 reader가 있는 상황에서는 writer가 계속 대기해야 하는 경우이다.
이 경우에서는 reader에 우선순위가 있다 할 수 있고 writer가 starvation이 생길 수 있다.
Writer preference
writer가 대기하고 있을 때, reader가 더이상 못들어오도록 해 writer에게 우선권을 준 방법이다.

rsem이 추가되어 wsem으로 writer를 막기 전에 writer가 대기하고 있으면 rsem을 wait해 reader를 막는 것을 볼 수 있다.

여기서 rsem을 p, v하는 것을 다시 z로 묶에 한번에 rsem이 하나씩만 비교할 수 있도록 한다.
이를통해 writer의 우선권을 더욱 높인다.
12. Deadlocks
Priority Inversion
우선순위 기반의 선점 스케줄링 방식에서 나타날 수 있음.

이렇게 P2가 P3 후에 끼어들어서 P1이 실행되지 않고 있다.
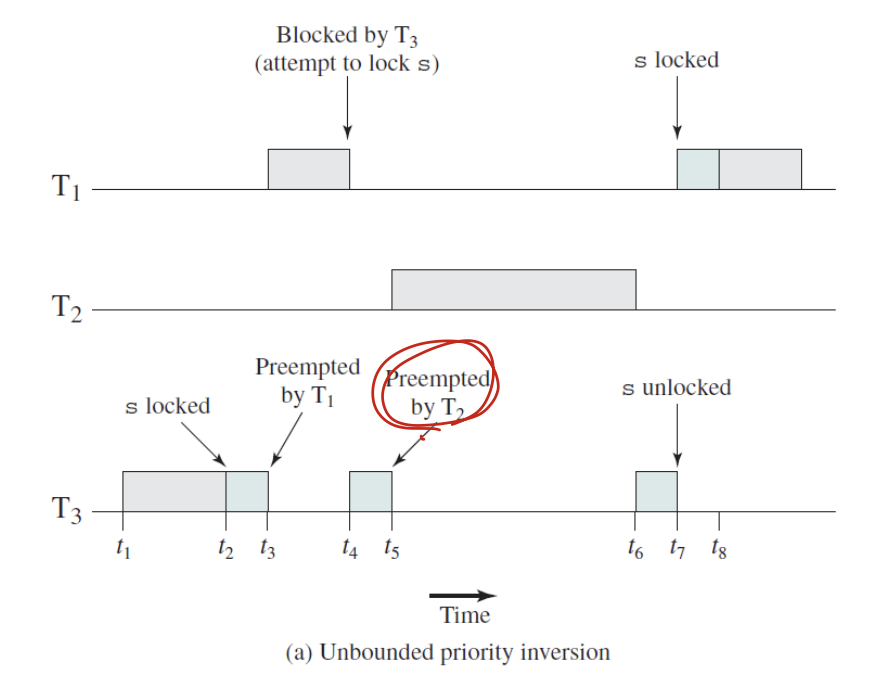
해결책 -> Priority Inheritance

이렇게 우선순위가 낮은 것이 우선순위가 높은 것을 block했을때 ( 이 경우에선t4의 경우로, T3가 T1을 block해서 실행됨) 우선순위가 높은 것의 우선순위를 그 block한 쓰레드에 상속하는것.
Deadlock
서로 자원이나 통신을 경쟁하는 프로세스 간의 영구적인 blocking. -> 교착상태
각각의 프로세스가 서로에 의해 야기될 수 있는 이벤트를 기다릴 때 발생함.
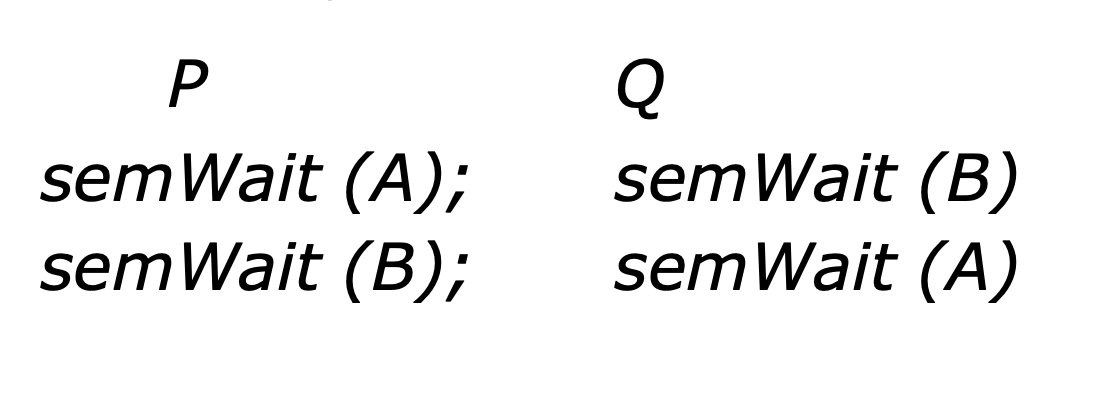
여기서 A wait하고 스케줄링 다시 돼서 B wait하면 데드락 걸림.
Resources
reusable
memory, device, processor 등 재사용 할 수 있는 것.
근데 누가 쓰면, 다른사람들은 기다려야 됨.
consumable
소모되는거.
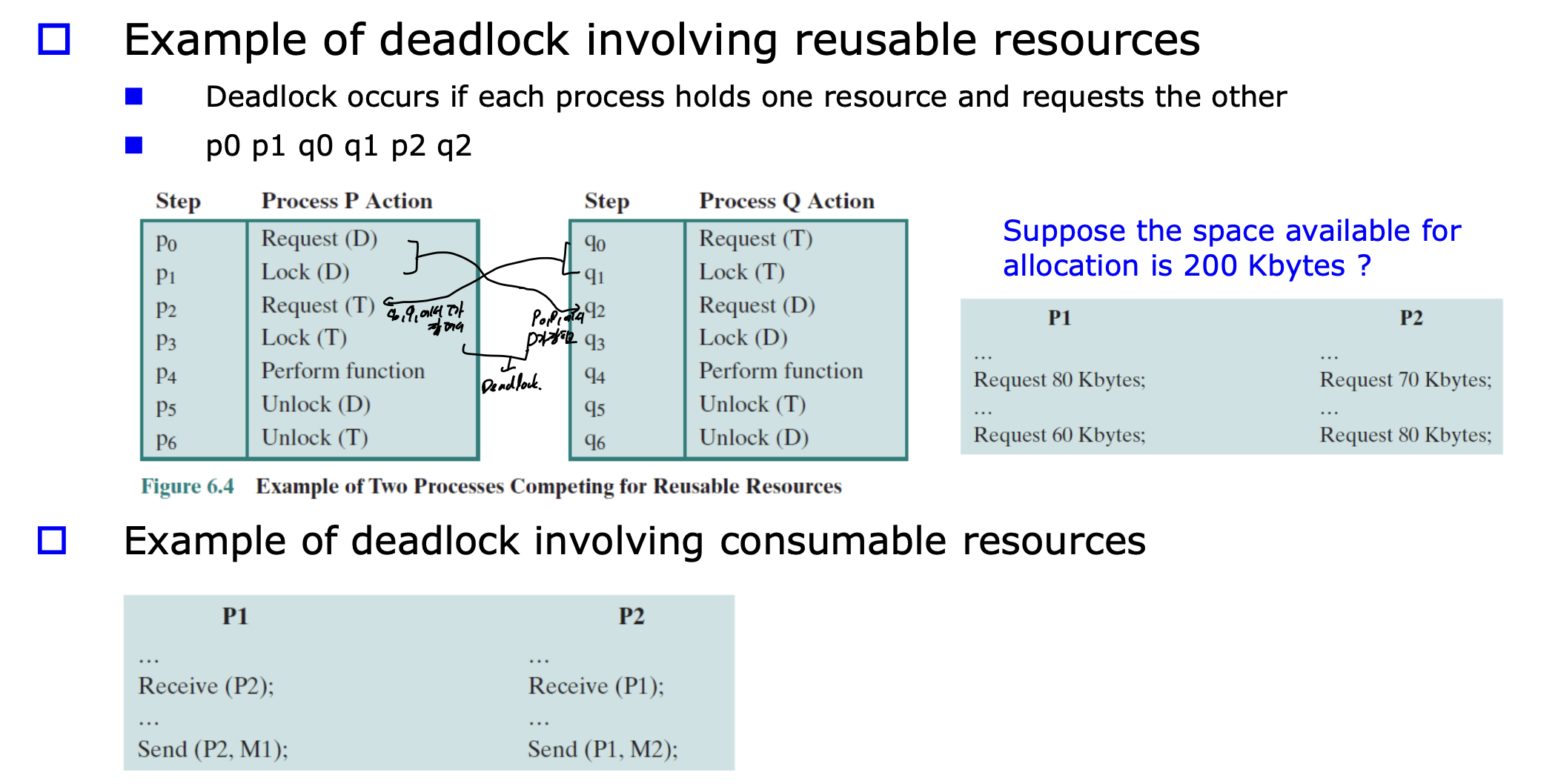
둘다 deadlock 걸린다.
Resource Allocation Graphs
동그라미는 process, 네모는 resource로
동그라미에서 네모로 가는 화살표는 request, 반대는 held이다.
즉, process가 자원을 필요로 하여 요청을 보내는 것과 프로세스가 이미 어떤 자원을 가지고 있는 상태를 digraph로 나타낸 것 이다.
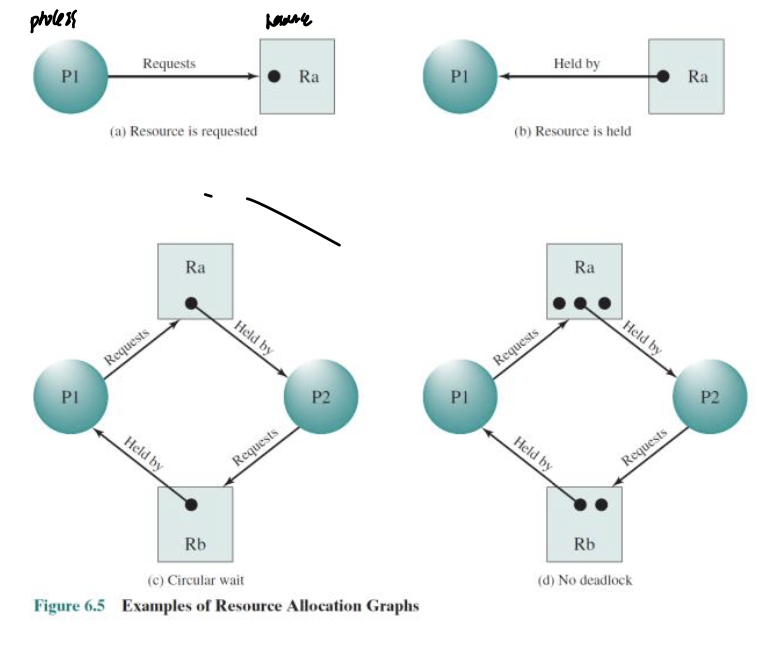
이것이 만약 사이클을 돈다면, 이것이 deadlock에 걸릴 수 있다는 것 이다.
Condition of Deadlock
- Mutual Exclusion -> 자원을 한번에 한 프로세스만 사용 가능
- No preemption -> 자원을 누가 가져가는 것이 안됨.
- Hold and wait -> 두개의 자원이 필요하다 할떄, 하나의 자원을 가지고 있다면 다른 하나가 구해질 때 까지 계속해서 가진채로 기다리는 것.
-> 동시에 자원을 두개 잡도록 하면 해결 가능. 그러나 비효율적 - Circular wait -> cycle -> 사용순서를 정하면 되긴 함.(선형의 순서를 정해줌)
->
이 네가지 조건을 모두 만족해야 한다.
Handling Deadlocks
- Deadlock Prevention
Deadlock의 조건을 만족하지 못하게 하는 방법. - Deadlock Avoidance
자원의 상태에 따라 request자체를 승인 또는 거절 하는 방법.
Dining Philosophers Problem
1. 1st solution

다섯명의 철학자가 있지만, 동시에 4명만 밥을 먹을 수 있게 하는 것이다.
이러면 자연스럽게 데드랍이 해결되긴 하지만, 교착상태를 근본적으로 해결하지는 않는다.
2. 2nd solution

한번에 한명의 철학자가 두개의 포크를 집도록 한다.
이를 통해 Hold and wait을 방지하여 데드락을 막을 수 있다.
포크를 집는 과정에 semaphore를 둔 것을 볼 수 있다.
3. 3rd solution

0일때 0, 1번 1일때 1, 2번 ~~ 3일때 3, 4번까지는 선형적인 순서로 포크를 사용하지만, 4일때는 4, 0번으로 사이클을 돌게 된다.
이를 방지하여 Resource에 선형적인 순서, ordering을 하게 된다.
Deadlock Avoidance
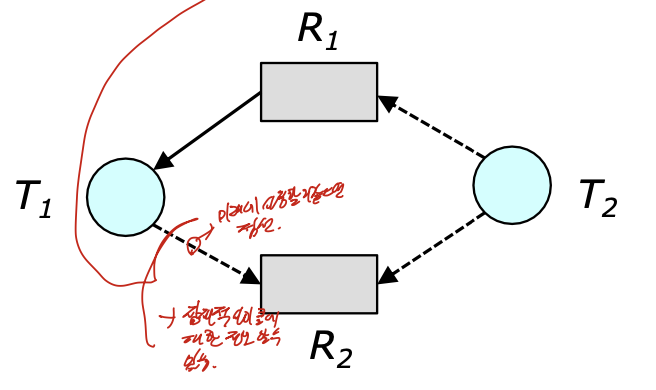
Deadlock을 피하기 위한 방법.
resources allocation graph에서 점선, 실선을 통해 미래에 사용할 것 같은 것을 점선으로 두고, 잠재적으로 사이클에 대한 정보 알 수 있음.
이것으로 safe, unsafe한 상태를 구별.
claim -> assignment로 바뀌는 것을 통해 사이클 판별이 가능하다.
Process Initial Denial

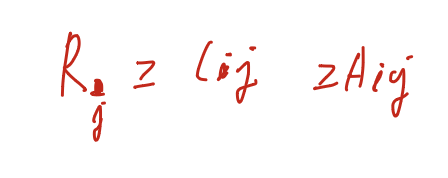
시작상태를 통해 데드락이 발생할 것 같으면 시작을 거부함.
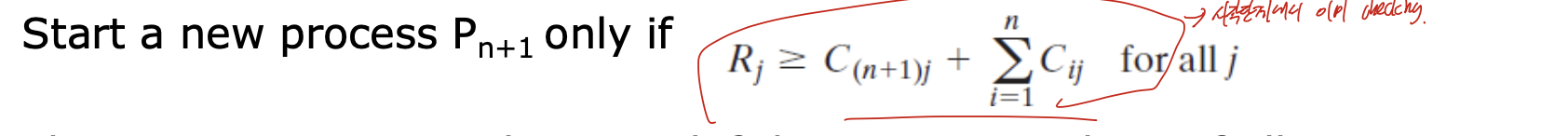
resourece의 값이 claim의 합 보다 크거나 같아야 된다는 것 으로, 이 조건이 만족하지 않으면 실행하지 않는다.
Resource allocation Denial
자원 할당 시 마다, safe/unsafe를 판단하는 것.
Bankers algorithm

claim은 가질 수 있는 정보의 양이고, allocation은 이미 할당된 정보의 양 이다.
이 instance에서, R = 12라고 정하자.
그 중, 현재 가용 가능한 V = 3이다. 이는 12 - Allocation의 합 이다.
그렇다면 어떤 순서로 주어야 할까, 먼저 Ci - Ai가 3보다 작은 것에 할당해 주어야 하므로 P2에 주어야 한다. 그러면 P2가 끝난 이후, V = 5가 된다. 그 다음 P1에 할당하고, V = 10이 되고, 그 다음 P3에 할당하면 V = 12가 된다.
만약 처음에 P1, P3에 할당한다면 데드락에 걸리게된다.

13. Memory Management
코딩된 순서대로 실행될 것 인가에 대한 프로그래머와 시스템의 괴리.
Main memory는 두가지 파트로 나누어진다.
user part와 OS part로
kernel이 동적으로 유저파트를 할당하는 것. 을 메모리 관리라 한다.
Sequential Consistency Example
우리가 생각하는, 명령어는 순서대로 실행되는 것 이다.
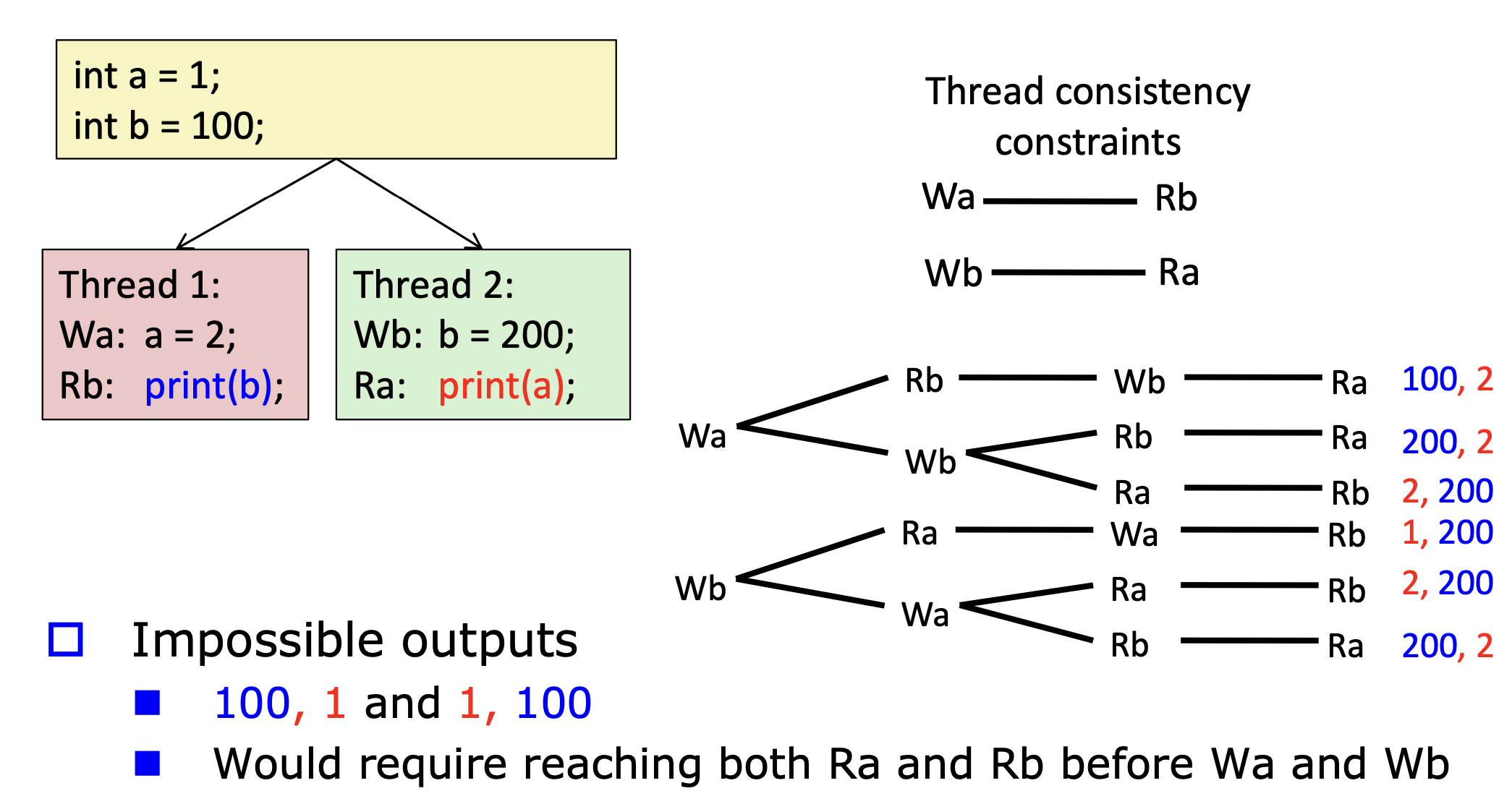
이 예시를 보면, reordering이 된다고 해도 옆에 여섯개의 output만 나올 수 있다.
100,1 1,100과 같은 것은 나올 수 없다. 하지만 Relaxed(weaker) consistency를 가지게 된다면 나올 수 있다.
이 방법은 instruction이 reorder되지 않도록 한다. 그러므로 많은 최적화를 막고, 성능을 저하시킨다.
Relaxed Consistency
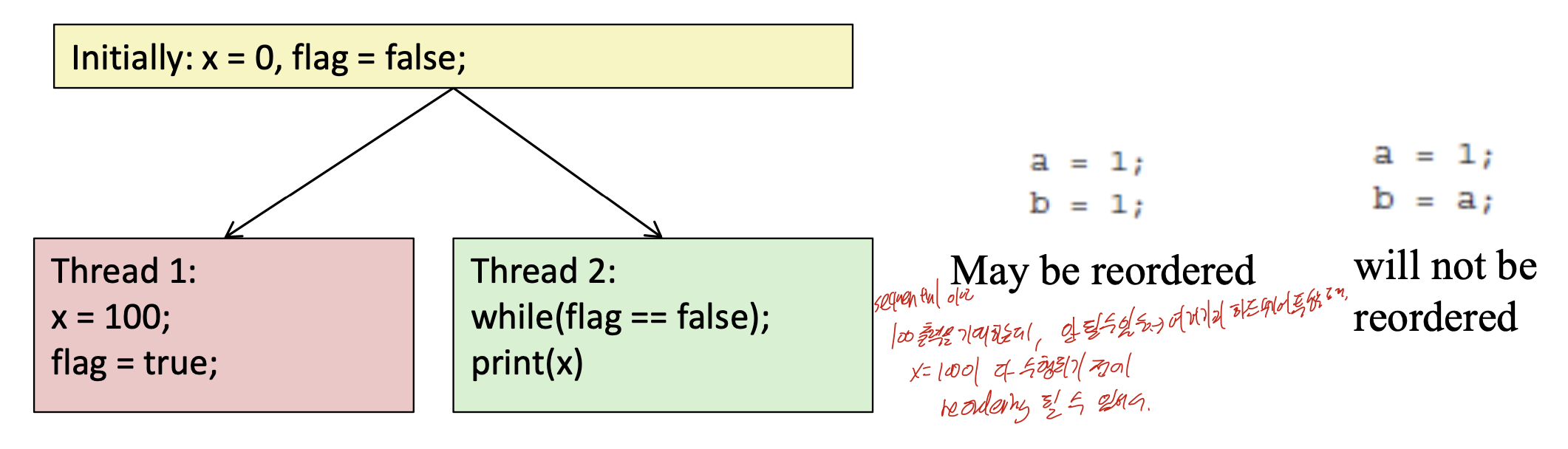
sequential로 보면 이 것은 x가 100이 출력되도록 기대할 수 있다.
하지만 이렇게 돌려보면 이상한 값들이 나온다. 왜냐하면 x = 100이 제대로 수행되기 전에 reorder되어 print(x)가 수행될 수 있기 때문이다.
Memory Management Requirements
1. Relocation
multiple process가 메인 메모리를 공유하기 떄문에 utilization을 최대화 하기 위해서는 process간의 swap과 같은 재배치가 이루어 져야 한다.
2. Protection
각각의 프로세스는 다른 프로세스에 의해 원하지 않게 참조되는 것을 막아야 한다.
3. Sharing
메인 메모리에서 특정 부분은 같이 접근할 수 있어야 한다. 유용성
4. Logical Organization
논리적인 조각 단위로 할당.
5. Physical Organization
메모리 계층 구조와 같은 물리적인 구성을 알아야 한다.
Types of Address
Symbolic address
소스코드에서 사용되는 주소.
Logical address( relative address)
0으로 시작하는 상대 주소로 이다. (process의 view)
모든 logical address는 프로그램에 의해 생성된다.
Physical address( absolute address)
메민 메모리 상에서의 실제 주소이다.
Dynamic Address Translation

virtual(logical) address를 MMU를 통해서 메모리 상의 real address와, Secondary memory의 disk address로 바꾸는 과정이다.

이런식으로 offset + Base를 통해 실제 주소를 구한다.
Memory Allocation
Contiguous allocation (연속할당)
Fixed partitioning(equal size)
이렇게 메모리의 가용 공간이 정해져 있을떄, 그것을 모두 같은 사이즈로 분할하는 것 이다. 이 분할된 한 공간에 하나씩의 프로세스가 들어가게 된다.
이 방식을 사용한다면, 올라올 수 있는 프로세스의 수가 정해지게 되고 크기도 또한 정해지게 된다. 그렇기 때문에 각 partition에 남는 공간이 생겨,
Internal fragmentation, 내부 단편화가 발생한다.
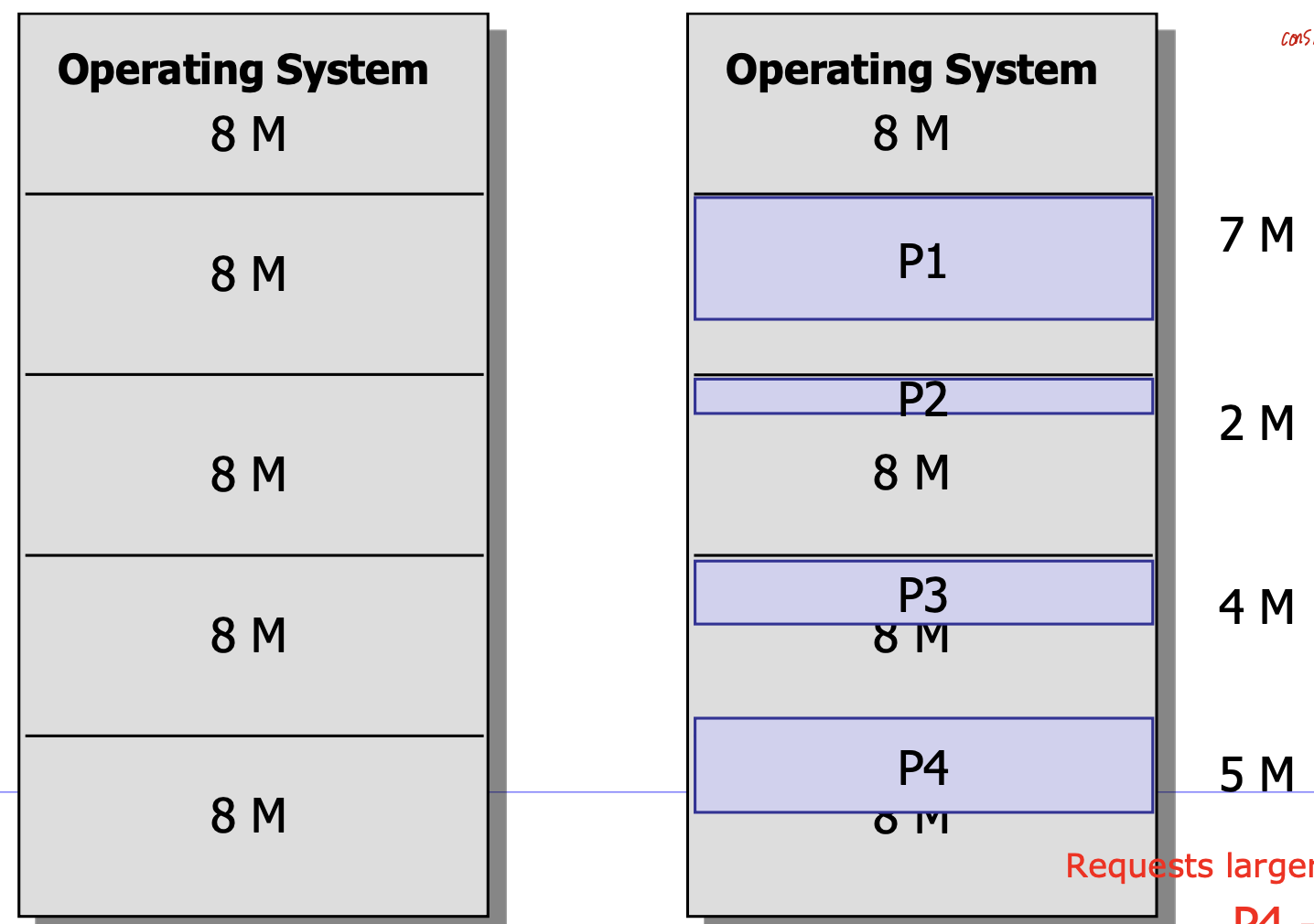
Fixed partitioning (unequal size)
이전과 비교했을때 그냥 partition을 균등하지 않게 분할한 것 이다.
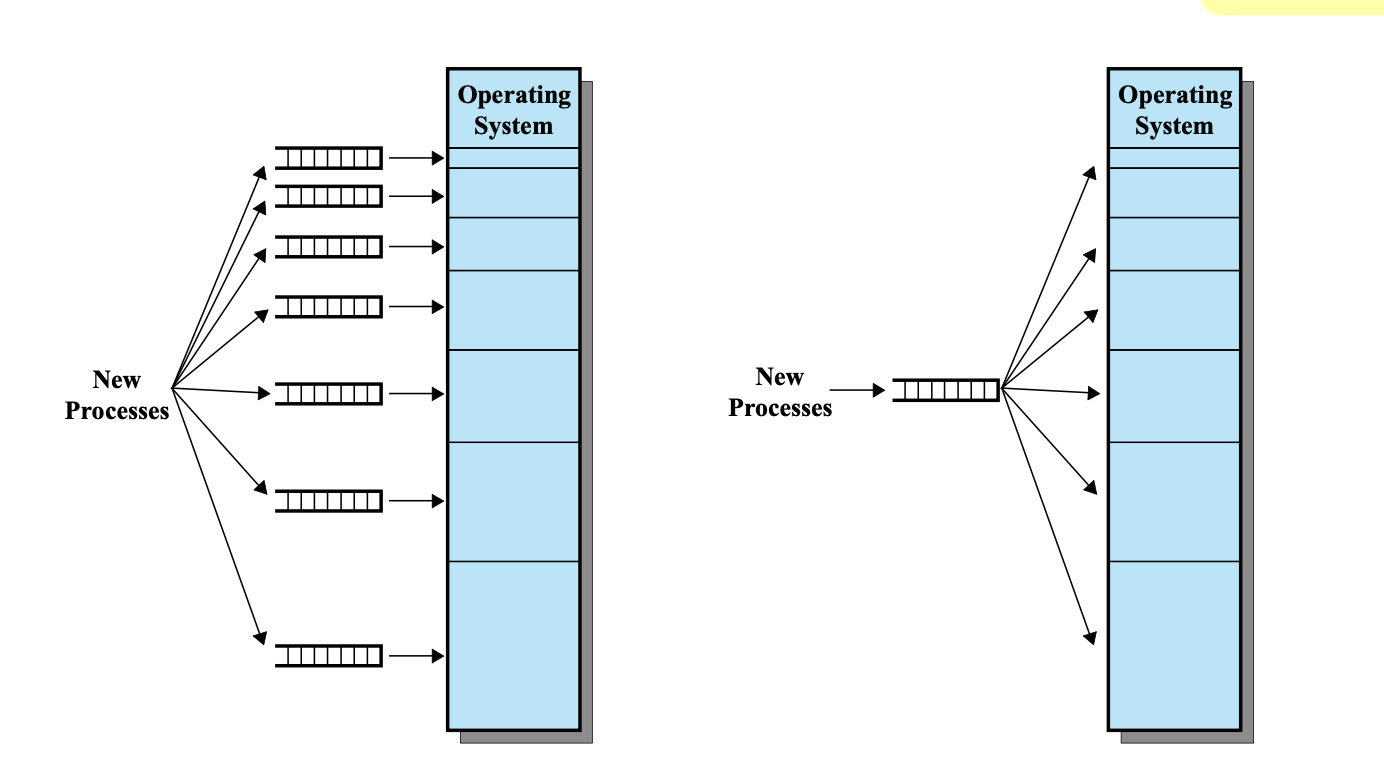
multiple queue로 구현한다면 사이즈에 가장 비슷한 것을 대기하고, 넣어줄 수 있기 때문에 internal fragment를 최소화 할 수 있고
single queue로 구성한다면 가장 작은 사이즈 부터 순서대로 넣어줄 수 있기 때문에 유연하다.
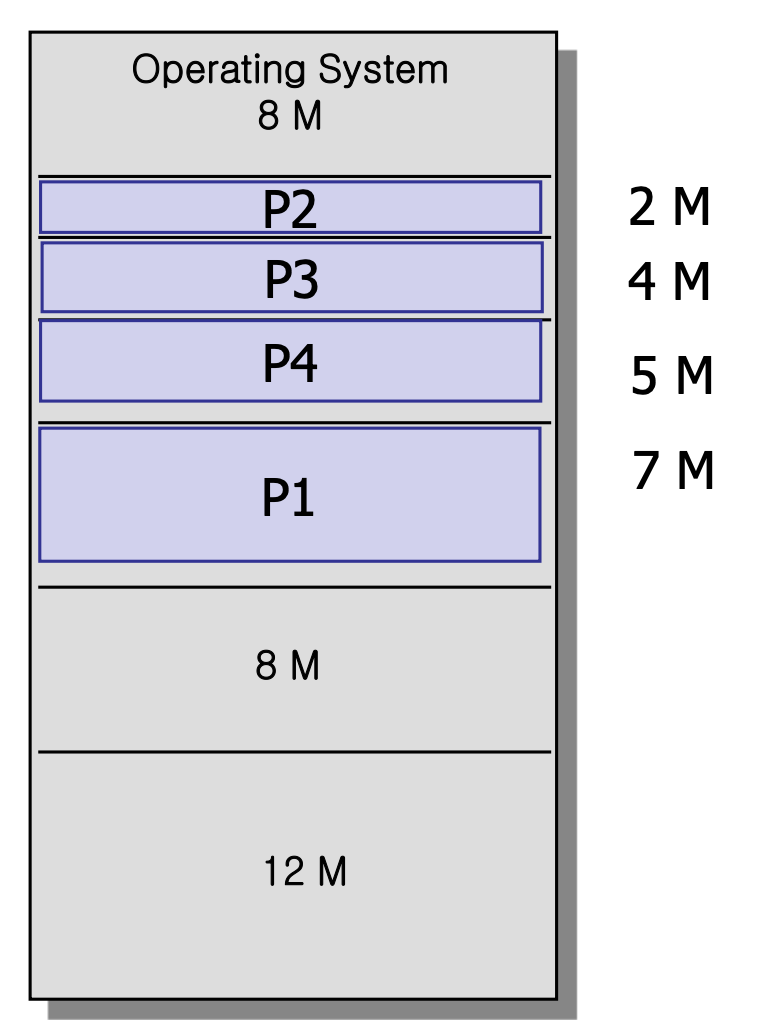
Dynamic Partitioning
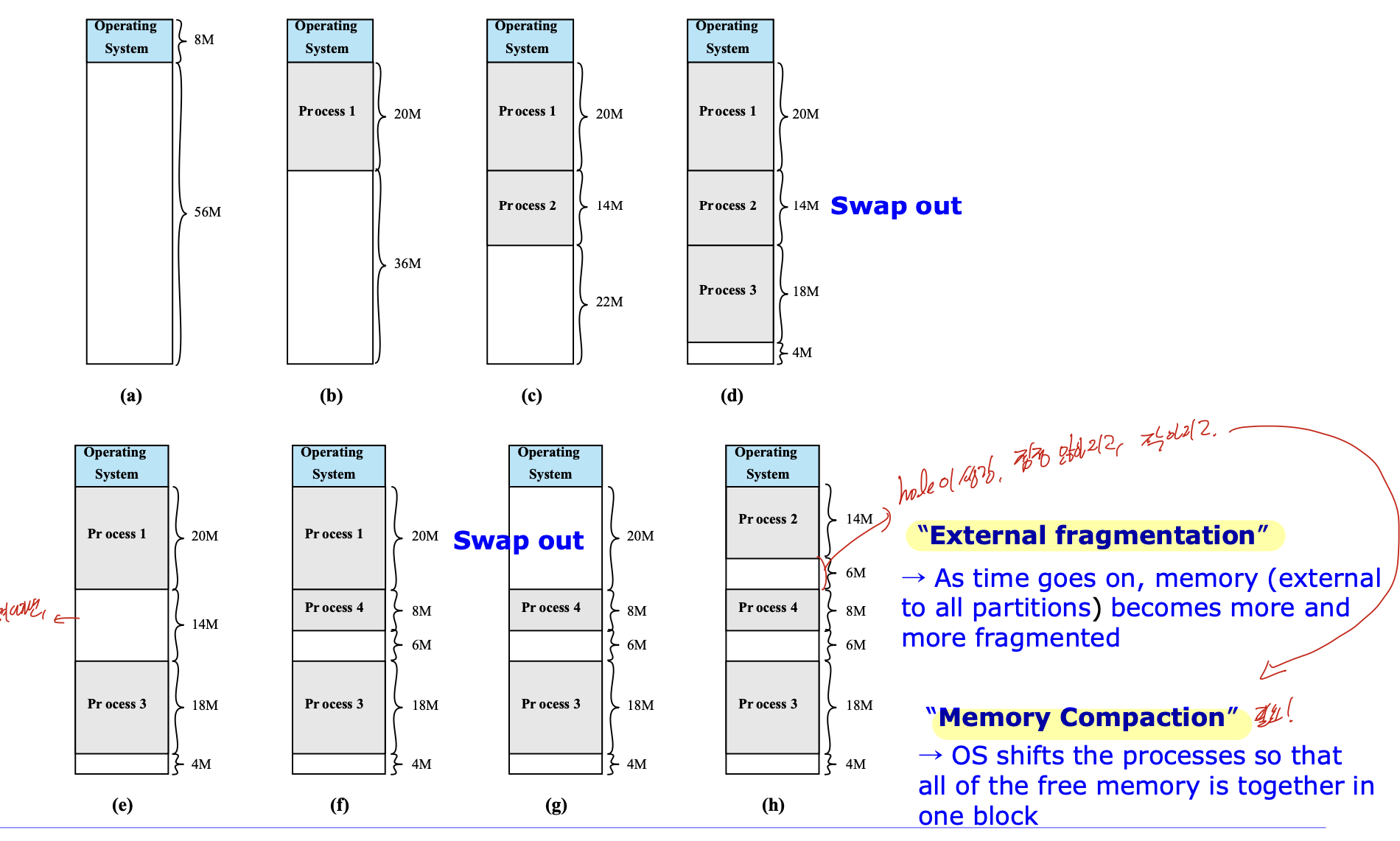
프로세스가 올라올 때 마다, 동적으로 할당해 주는 방식.
나가고 다시 들어오고 하는 과정을 통해 hole이 생긴다. 이는 점점 많아지고, 작아지며 이를 External Fragmentation, 즉 외부 단편화 라고 한다.
그리도 이 외부단편화 때문에 Memory Compaction과정이 필요하다.
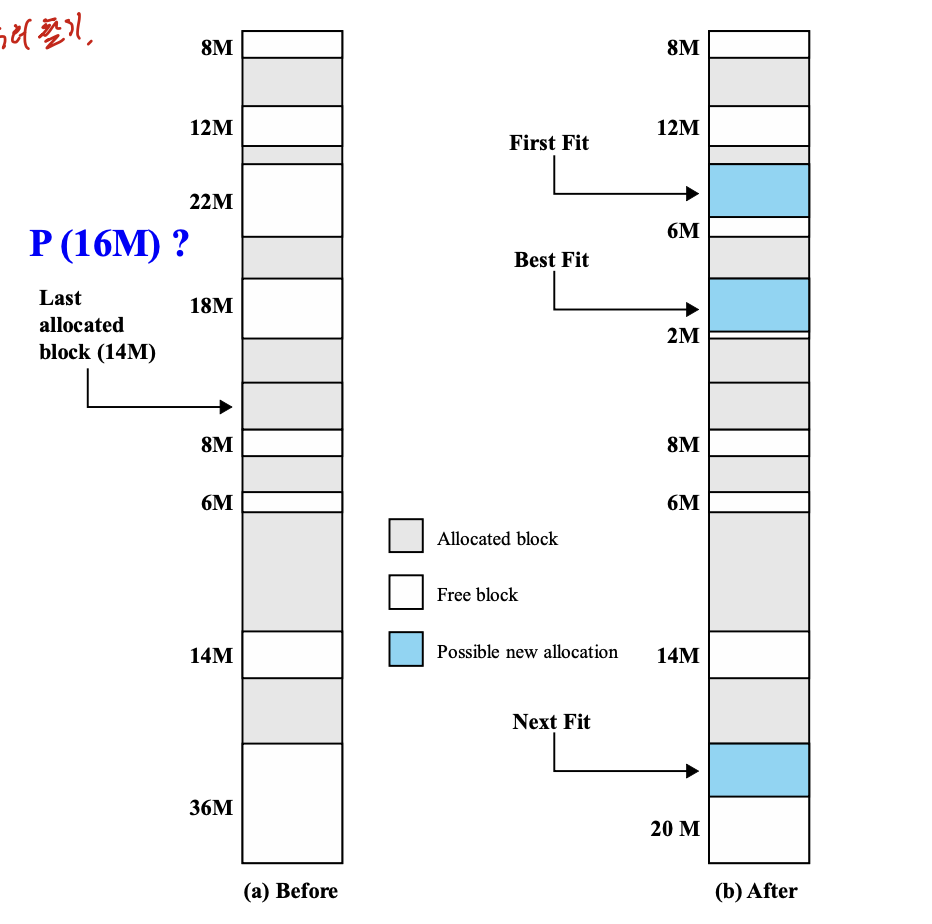
First fit
빈 공간을 순서대로 찾다가 사이즈가 맞는게 있으면 바로 넣어주는 방식.
Next fit
전체 탐색을 한 다음에 마지막에 넣어주는 방식.
best fit
가장 사이즈에 잘 맞는 곳에 넣어주는 방식
오래걸리고, fragment가 작게 생기기 때문에 성능이 가장 안좋다.
그러므로 동적할당은 내부단편화가 없고, 메모리 사용이 더 효율적이라는 장점이 있지만
외부단편화가 발생하고, compaction때문에 추가적인 cost가 발생한다.
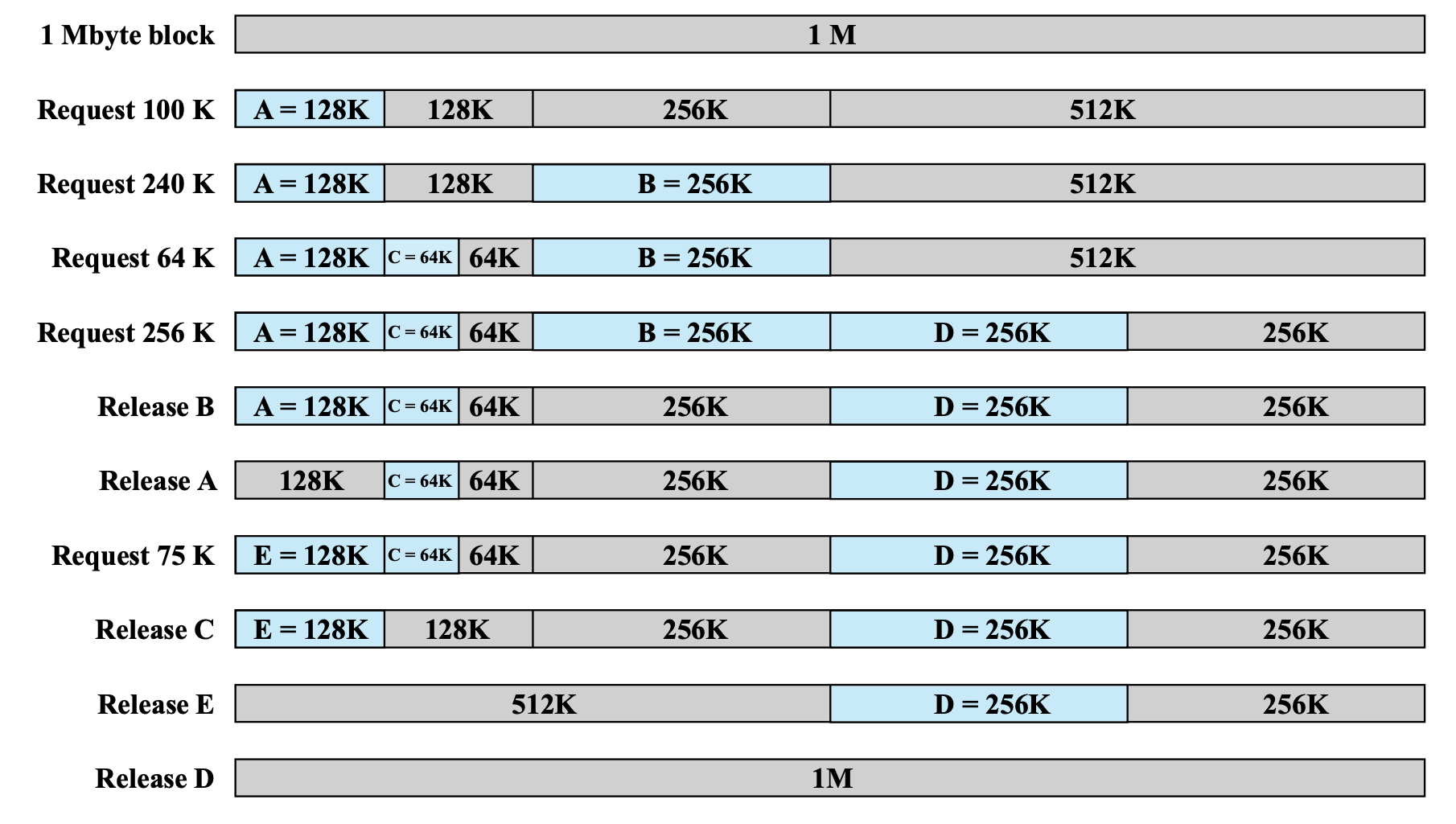
Buddy System
fixed, dynamic의 하이브리드 버전이다.
메모리는 2^n으로 관리되기 때문에 이를 프로세스가 들어올때 마다 2^n-1씩으로 쪼개서, 사이즈가 맞다면 넣어주는 방식이다.
Non-contiguous allocation
프로세스를 논리적으로 분할하여 불연속적으로 할당하는 것 -> 분산적재.
분할하는 단위에는 page, segmentation이 있다.
Paging
메모리와 프로세스를 고정 크기 조각으로 나눈다. 이때 나눠진 메모리 조각은 Frame, 프로세스 조각은 Page라고 한다.

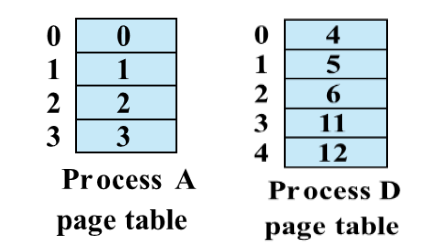
나눠진 페이지들을 분산적으로 적재하기 때문에 page가 들어간 frame의 번호를 알아야 한다. 이것을 page table에 저장하여 관리한다. 그리고 그 번호를 통해 물리 메모리의 실제 위치를 찾을 수 있다.
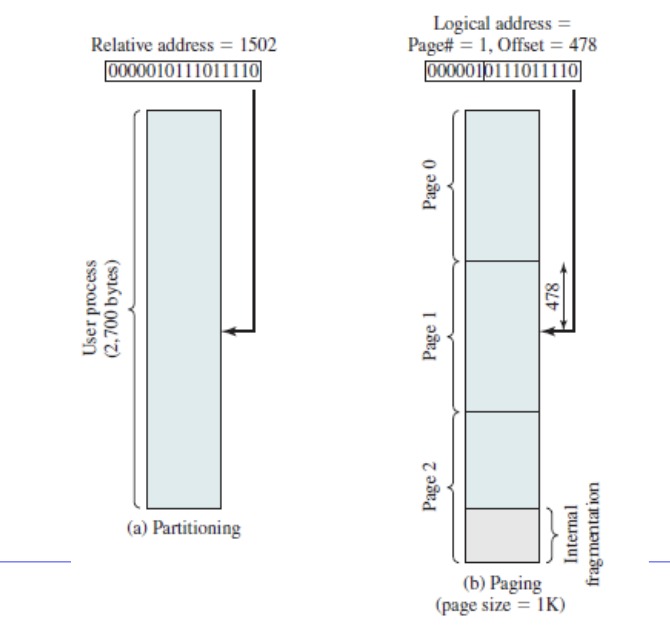
단점 : 프로세스에 마지막 페이지에 해당하는 곳에서는 내부단편화가 일어날 수 있다.
장점 : 외부단편화 발생 안함
분산적재를 사용한다면, 주소가 연속적이지 않기 때문에 Base, Bound 레지스터 만으로는 제어하기 힘들다.
그러므로 하단에 서술하는 방법으로 Physical address와 logical address를 변환한다. frame size와 page size가 2의 거듭제곱 꼴이여야 한다는 것은 필수이다.
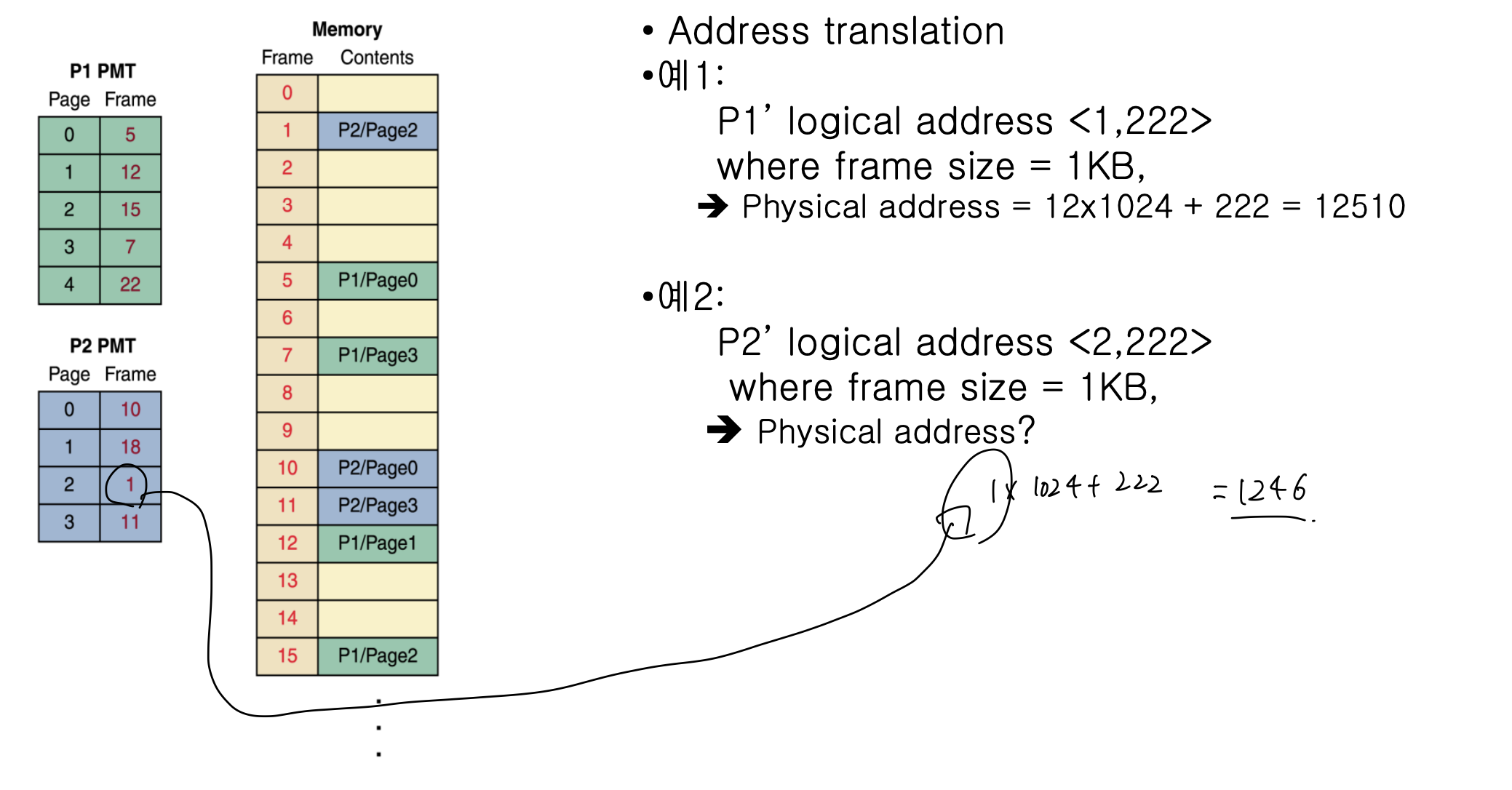
1. P1의 logical address가 (1, 222) (pagenum, offset)이고, frame size가 1kb일때 물리주소는 우선 pagenum이 1 이므로 이는 12번째 frame에 있다는 것을 알 수 있다. 그러므로 12 * 1024 + 222 = 12510이다.
- (2, 222) 0> P2 의 page 2는 1 frame에 들어가 있으므로 1 * 1024 + 222 이다.
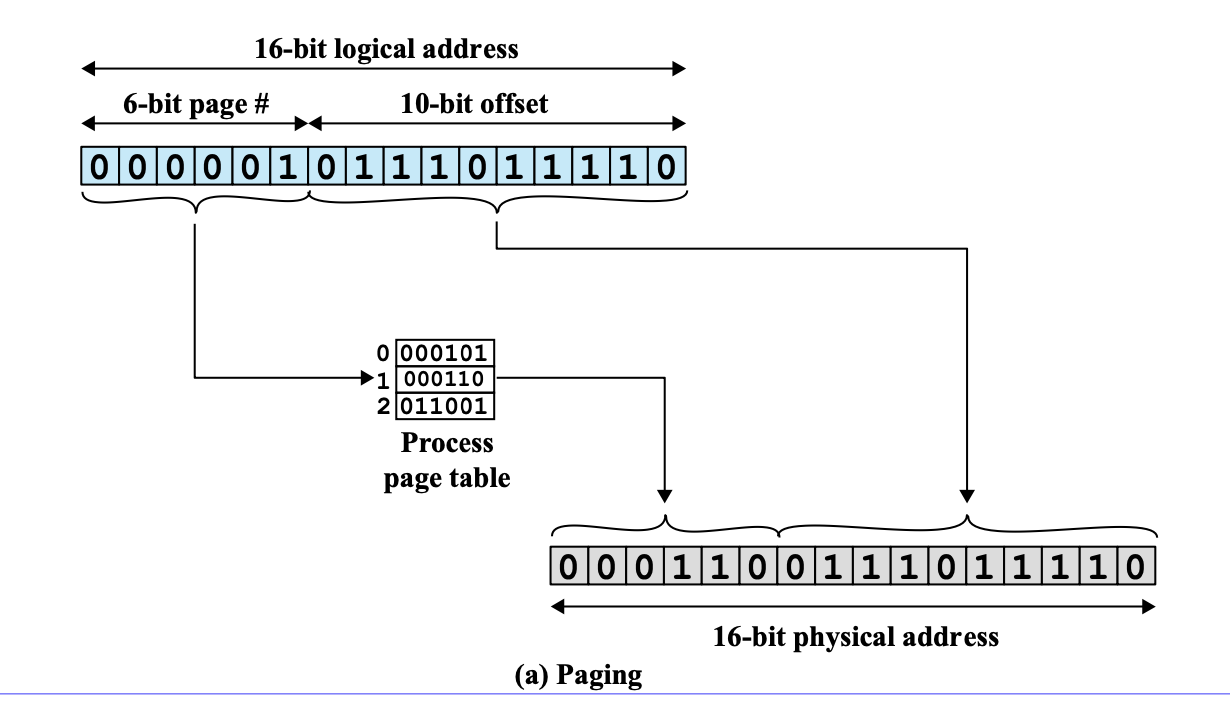
page# -> 6 bit, frame size = 10일때,
page num을 확인해 page Table을 찾아가 frame num k를 ㅇ라아낸다.
k*2^m은 해당 frame의 physical address이므로, 이런 식으로 offset을 앞에 더하면 physical address를 알 수 있다.
Segmentation
프로세스를 역학에 따라 가변크기 조각으로 나눈다. 가변크기 이기 때문에 Base(시작주소) 와 Limit(제한)을 Table로 관리한다.
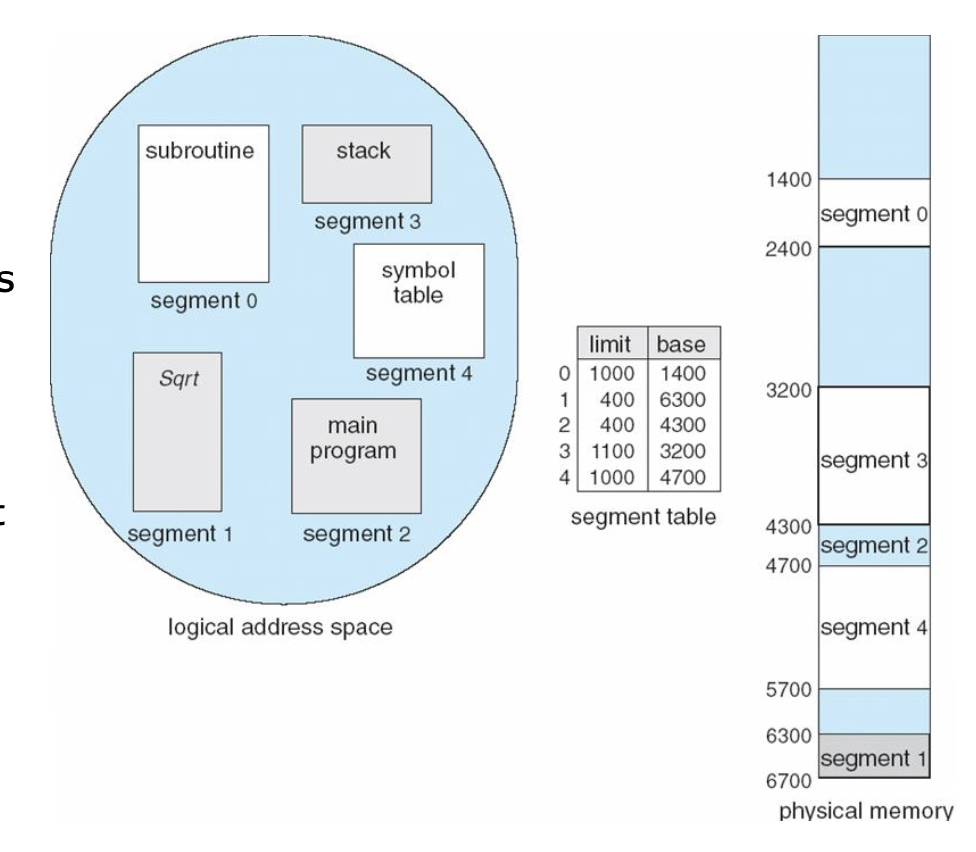
장점 : 내부단편화가 없다. 각 조각의 특성에 따라 Segmentation을 나눴기 때문에 Protection 과 Sharing이 편해진다.
단점 : 외부단편화 발생.
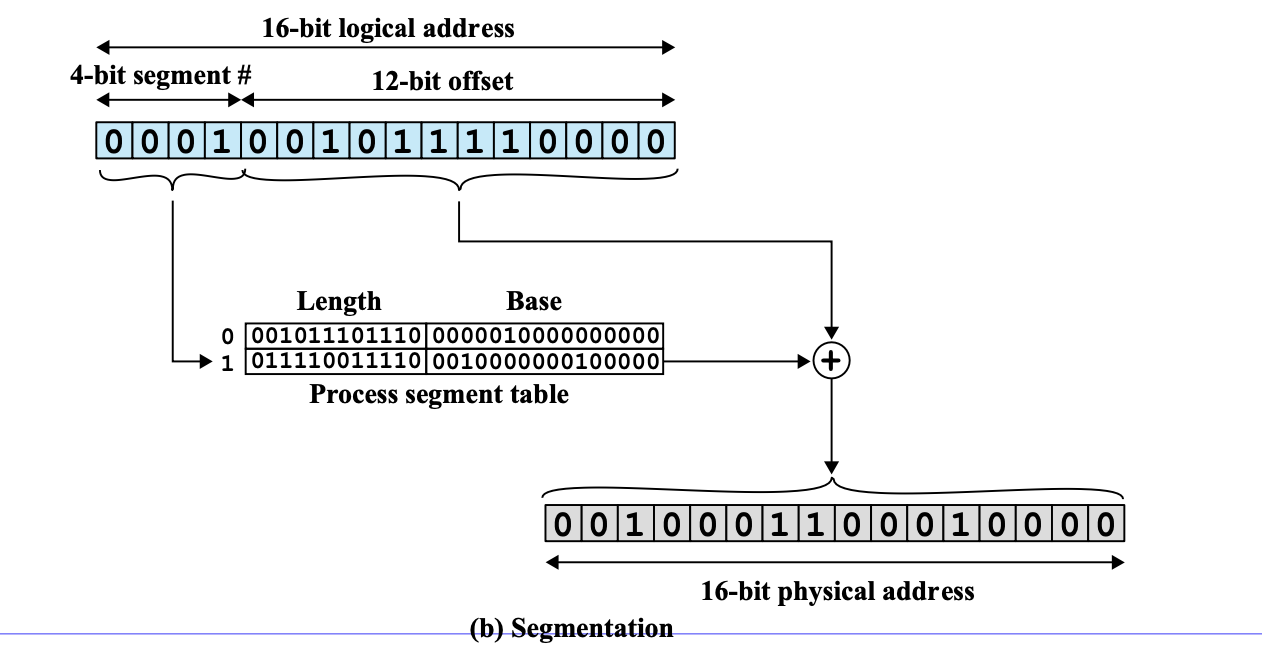
table 찾아서, 12 bit offset이랑 Base랑 더하면 물리주소 나온다.
14. Virtual Memory
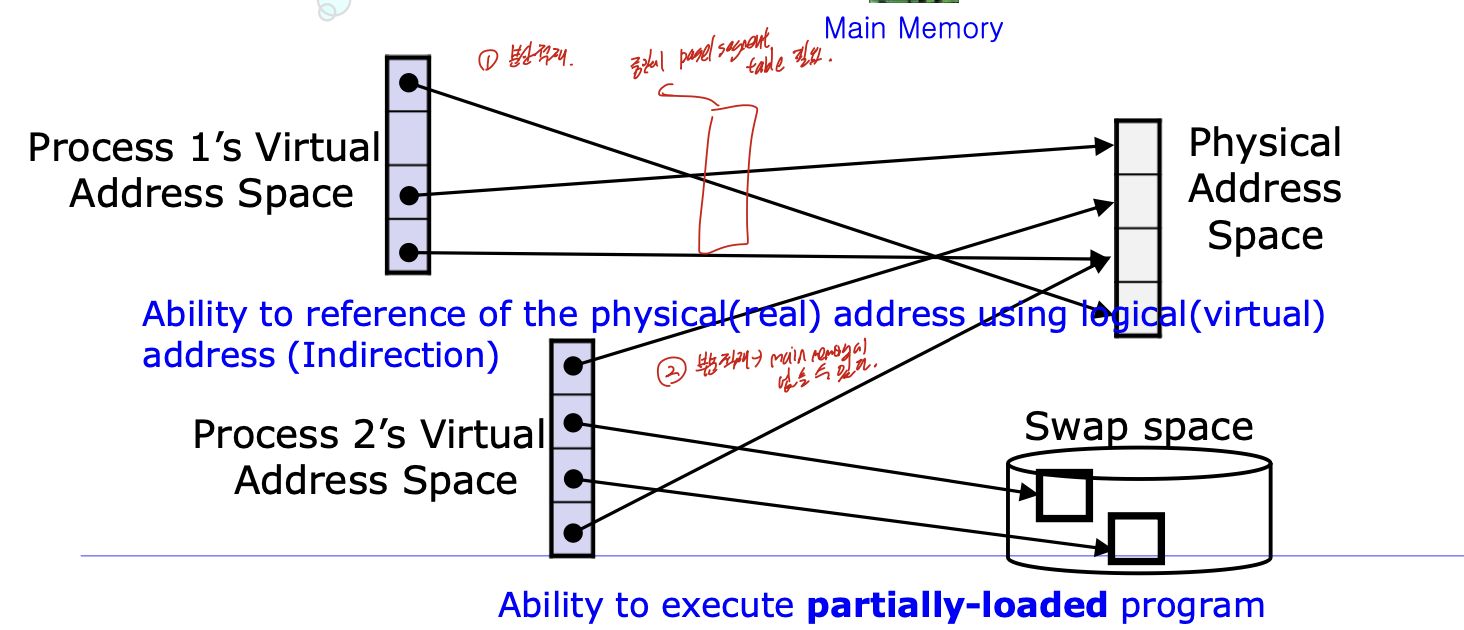
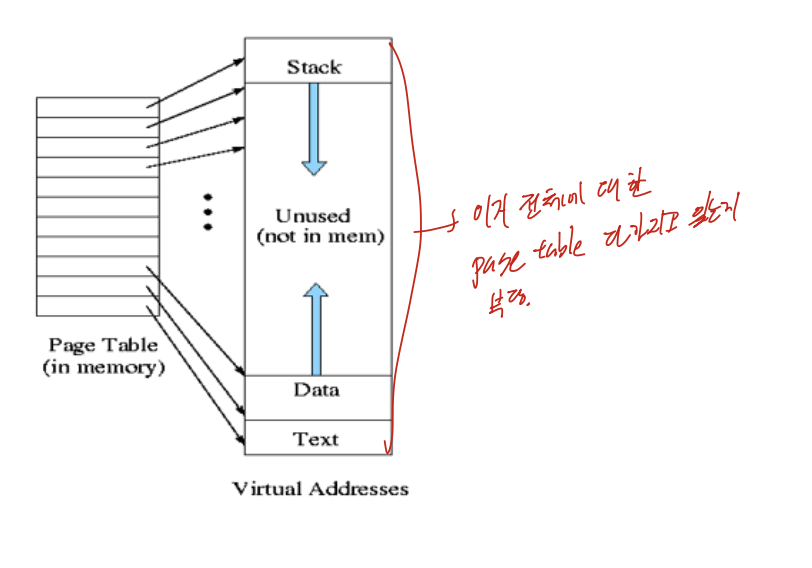
프로세스를 조각으로 나누었다(page, segment) -> 다른시간에 다른 위치, 꼭 이것이 메모리에 있을 필요가 없다 -> 부분적재
resident set이라는 적재 집합 개념이 나온다. 만약, 적재집합에 없는 부분을 원한다면 그때 Disk에서 가져오면 되는 것 이다.
가상 메모리를 사용한다면, 부분적으로 메모리에 적재하기 때문에 더 많은 프로세스 들이 메모리에 있을 수 있다. 심지어 메모리 전체 크기보다 큰 프로세스도 메인 메모리에 넣을 수 있다.
virtual address, Real address 개념이 나오는데, logical, physical이라 생각하면 된다.
OS policies for Virtual Memory
Fetch Policy
페이지가 메인 메모리에 언제 가져와져야 하는지.
Demand paging
그 페이지가 필요한 시점에 가져오는 전략.
Prepaging
미리 요구되었을때 미리 읽어오는 전략
Placement Policy
프로세스 조각이 메인 메모리의 어느 곳에 위치되어야 하는지.
Replacement Policy
실질적 영향.
가용할 space가 부족할때, 어떤 페이지를 내보낼까.
미래에 가장 사용 안될것을 찾는것이 중점이고, 과거의 데이터를 사용한다. 뒤에 여러가지 알고리즘을 설명.
Frame Locking
중요한 Frame이 있다면 그것은 lock될 수 있다.
lock bit = 1로 세팅한다.
placement policy에서는 page fault수가 줄어들 수록, overhead가 증가한다는 것을 알아야 한다.
Replacement Algorithm
기본적으로 frame수가 늘면, fault도 줄어야 된다는 측면에서도 보자.
Optimal
최적의 페이지 교체 방법으로, 미래의 정보를 가져와서 가장 사용되지 않는 순으로 뺴는 방법. 미래에 정보를 가져온다는 점에서 구현할 수 없고, 최적의 방법이기 때문에 이론적인 평가 기준으로 사용된다.
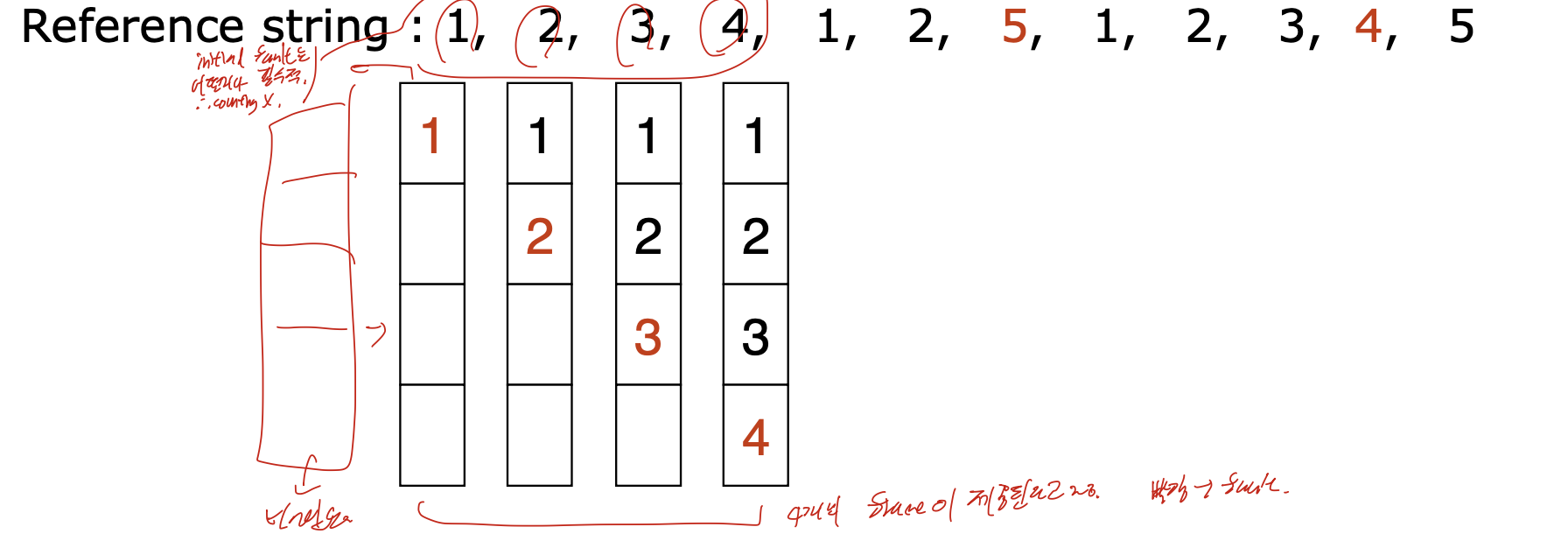
page fault를 세는 방법이 중요하다.
일단 , 모든 페이지가 처음에 들어올때는 무조건 fault가 된다는 것을 알아야 한다.
그리고 위의 예시에서는 기본적으로 4개의 frame이 제공되었다고 하는 예시이다.
일단 처음 1, 2, 3, 4가 들어오게 된다면, 채워지지 않은 상태에서 오는 것 이므로 모두 fault가 뜬다. 이는 계산에 포함 안한다고 하는데, 뒤에보면 대충 묶어서 한다.
그 다음 1, 2 가 오는데, 이는 이미 있기 때문에 fault가 뜨지 않는다.

그 다음 5가 들어오는데, 이 페이지는 지금 없기 때문에 fault가 뜬다. 그러므로 하나를 교체해주어야 하는데. 이는 optimal이기 때문에 우리가 미래의 정보를 알고있다는 가정을 한다. 근미래에 1, 2, 3 순으로 사용하기 때문에 4를 5로 교체한다. 이런식으로 가는 것이 optimal이고, 최적의 방법이다.
FIFO
먼저온거 먼저 빼주기.
구현 간단한데,
오래전에 왔지만 자주 사용하는 것을 빼 줄 수도 있고, Belady's anomaly가 생길 수 있다.

과정은 간단하다. 그냥 오래된 순서대로 빼면서 교체하면 된다.
중점적으로 봐야하는 것은
4frame이 있을떄, 4 + 6의 fault가 생긴다.
하지만 3frame이 있을때, fault가 더 많이 생기는 것이 정상이지만, 3 + 6으로 오히려 전체 fault의 수가 줄어든다.
이것이 Belady's Anomaly라고 한다.
LRU(Least Recently Used)
미래는 못보니까 과거의 정보를 사용하는 방법이다.
Optimal 대비 성능이 가장 좋지만, 비용이 많이 들기때문에 주로 clock을 사용한다.
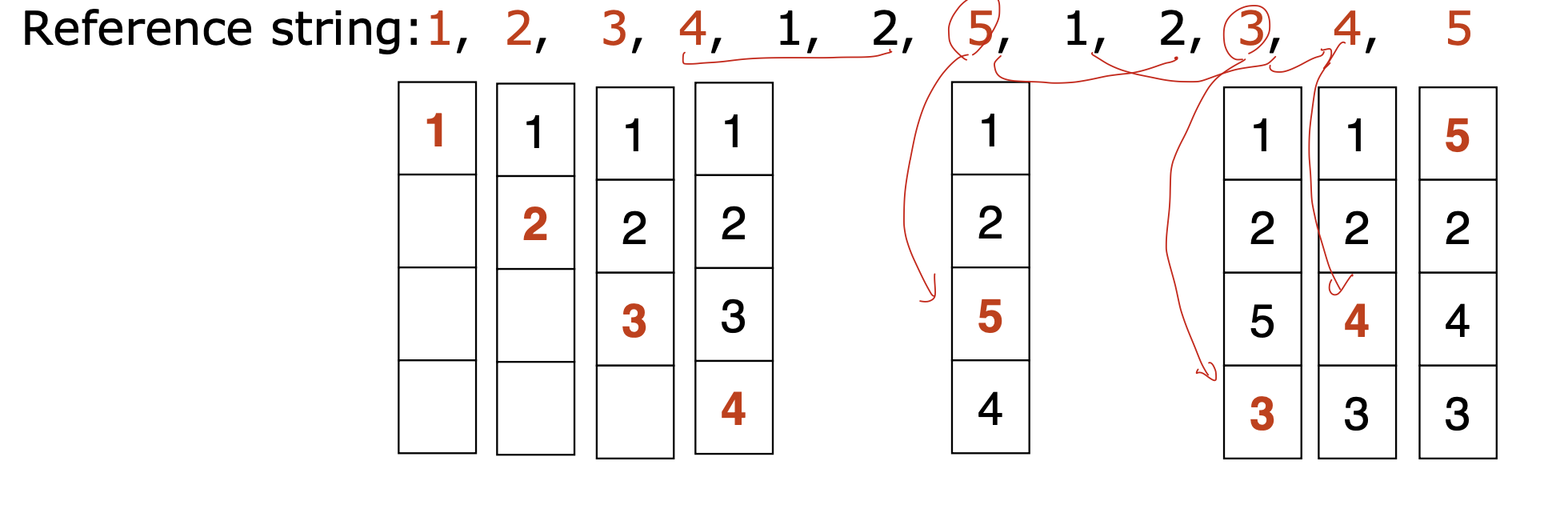
fault수가 4로, fifo보다 좋은 것을 볼 수 있다.
그리고 또한 belady anomaly도 해결한 것을 볼 수 있다.
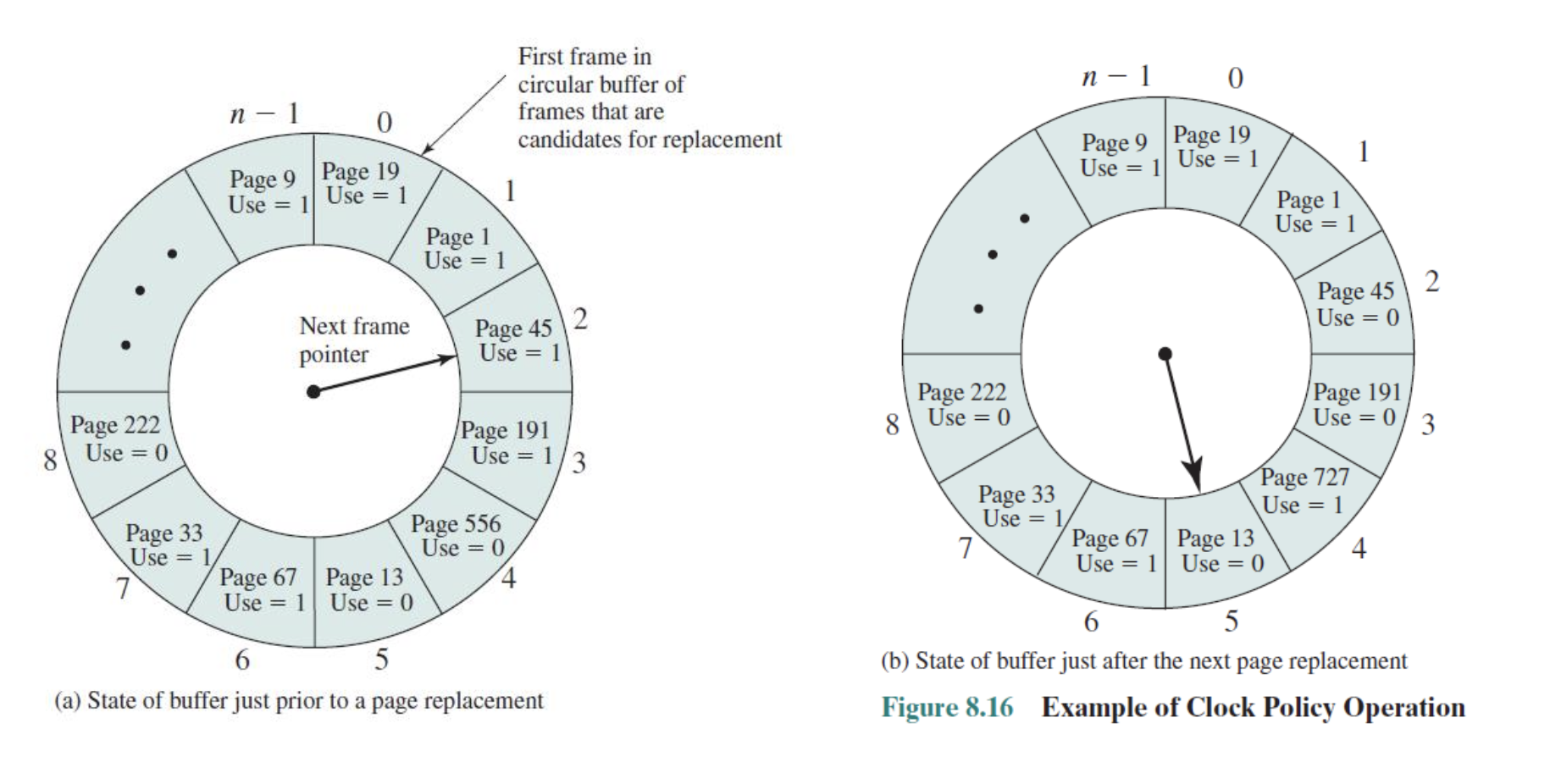
Clock (second chance)
page frmae을 환형 버퍼로 생각하고, 각각에 reference bit을 넣어
page가 들어왔을때 1로 초기화 해준다(second chance)
reference bit은 참조된 적이 있다는 것을 표현해주는 것 으로 환형버퍼에서 포인터가 시계방향으로 돌면서 1이면 0으로 바꾸어 준다. 만약 0인것이 있다면 그것을 victim으로 하고, 교체 대상이 된다.
Cleaning Policy
페이지는 메모리와 디스크 둘다 있다.
만약에 페이지가 수정된다면, memory, disk 둘다 바꾸어 주어야 하는데, 그 시점을 언제 할 것인지에 대한 것이다.
Precleaning
페이지가 메모리에서 교체되기 이전에, 변경된 페이지를 disk에 적용하는 것 이다. 하지만 계속 변경되면 효율이 떨어지고, 중복적인 IO가 늘어난다.
Demand cleaning
교체될때 쓴다.
Page Buffering
그래서 페이지 버퍼링을 걸어준다.

왼쪽 그림부터 보자.
2번 page frame이 변경되었다고 하고, 이것이 victim으로 지정되었다고 하자. 그리고 3이 요청됬는데 fault여서 memory로 불러와야 하는 상황이다.
그렇다면, 2'가 pageout되어서 disk에 써져야 하고, 3이 pagein 되어서 메모리에 불러와야 한다. 만약 바쁜 상태라면, 이 두번에 연산을 한번에 진행하는 것이 비효율 적일 수 도 있다.
그렇기 때문에 오른쪽 그림을 사용한다.
똑같이 2'가 victim이고, 3이 들어와야 하는 상태이다.
그렇다면 우선 victim으로 선정된 2에 해당하는 frame을 free list로 바꾼다. 그 다음, 다른 free list에 3을 page in 시킨다. 그리고 편할때 free list에 넣어둔 2'를 page out시키는 것 이다. 이렇게 된다면 응답성이 좋아지고 또한 성능도 좋아진다. 그리고 page out을 늦추기 때문에 2가 다시 요청되었을때 바로 메모리에서 다시 접근이 가능해진다.
Enhanced Second-Chance
I/O를 줄이기 위해 reference bit을 2 bit으로 바꾸는 방법이다.
첫번째 비트는 reference bit, 두번째 비트는 modify 비트로 한다.
만약 이 modify bit가 설정되었다면, page out을 해 disk에 써주어야 하기 때문에 위에서 서술한 논리대로 조금 늦추자는 것이다. 수정된 페이지가 메모리에 좀 더 남아있게 하여 재접근 용이하게하고, 편할때 보내는 것 이다.
Thrashing

Resident set은 주어진 시간에 메인 메모리에 존재하는 process page의 set으로, multiprogramming level이 증가한다면 각 프로세스의 resident set의 크기가 줄어든다. 그렇게 된다면 fault가 많이 발생하게 되고, 이를 통해 cpu utilization이 증가하게 된다.
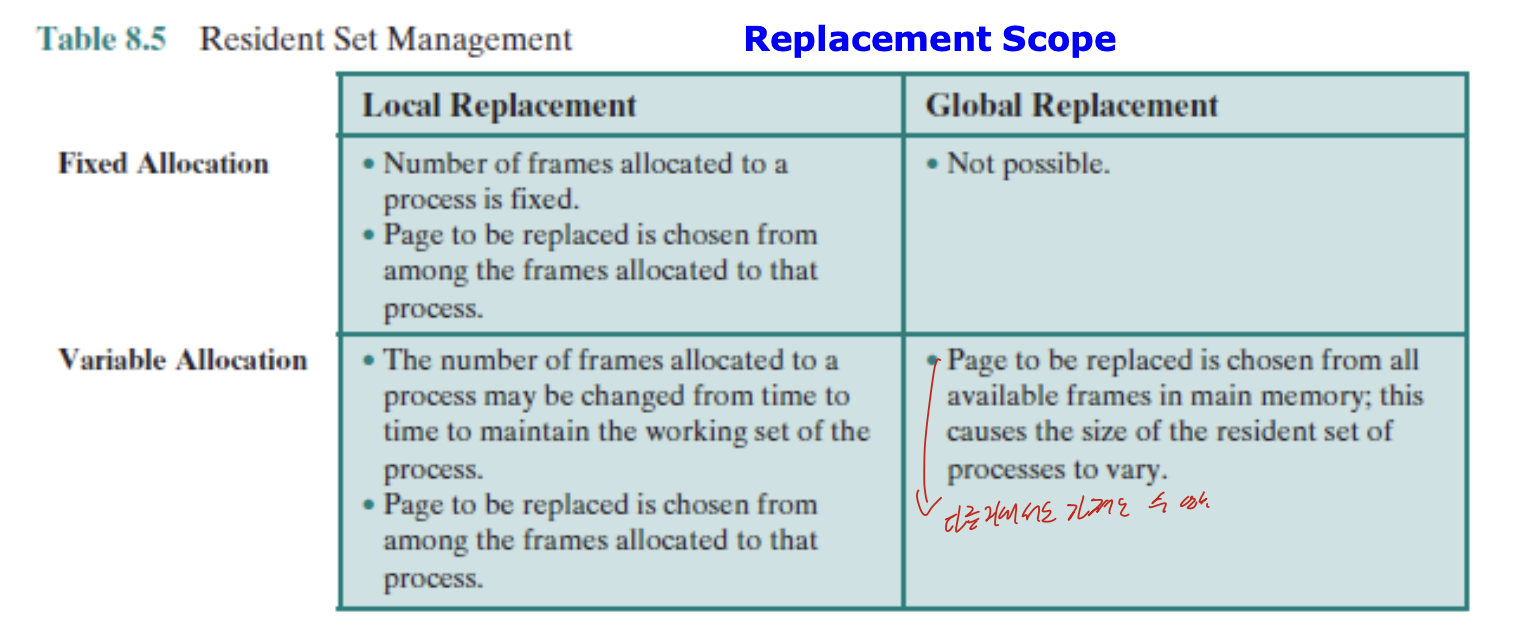
Resident Set Policy
프로세스마다 Resident Set의 크기를 얼마나 할당할 것 인가?
Fixed-allocation policy
프로세스마다 고정된 숫자의 frame이 제공되고
만약 부족하다면 자신의 프레임을 교체하는 방법.
딴거 못가져옴!
Variable-allocation policy
동적으로 frame 수 가 할당되고, 딴거에서도 가져올 수 있음!
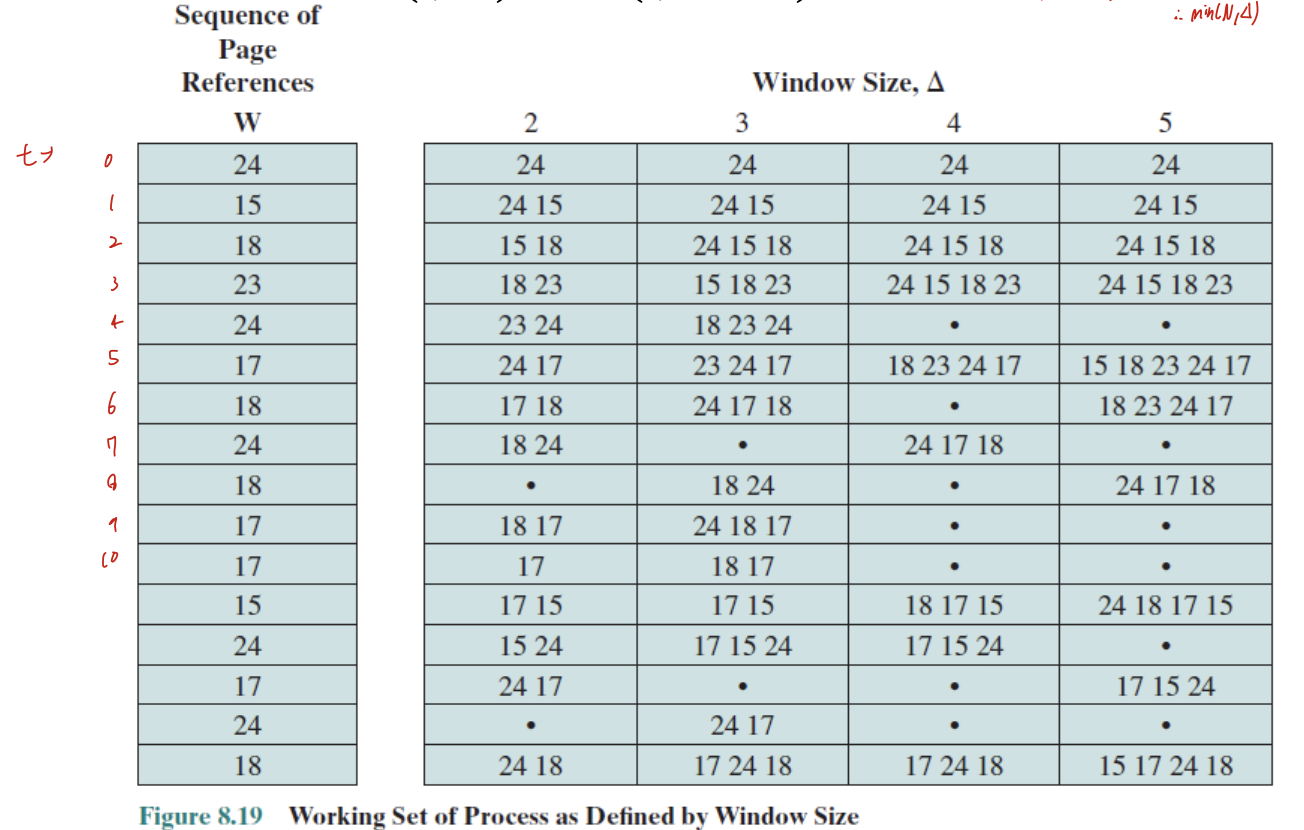
Working Set Model
locality를 기반으로 함.
W(t, delta) -> t 시간 대비, 과거에 delta시간 동안 어떤 page을 접근했는가?
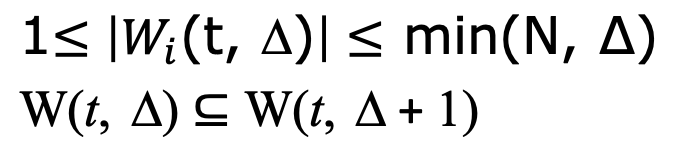
1. delta가 아무리 작더라도, 자기 자신은 포함하기 때문에 1이상이고 아무리 크더라도 전체 사이즈인 N보다는 작기 때문에 Min(N, delta) 이하이다.
2. 당연
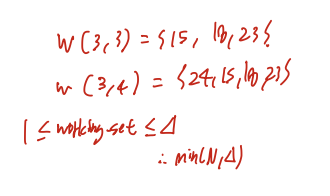
후술하겠지만, Working set의 크기가 작을수록 locality가 증가한다.
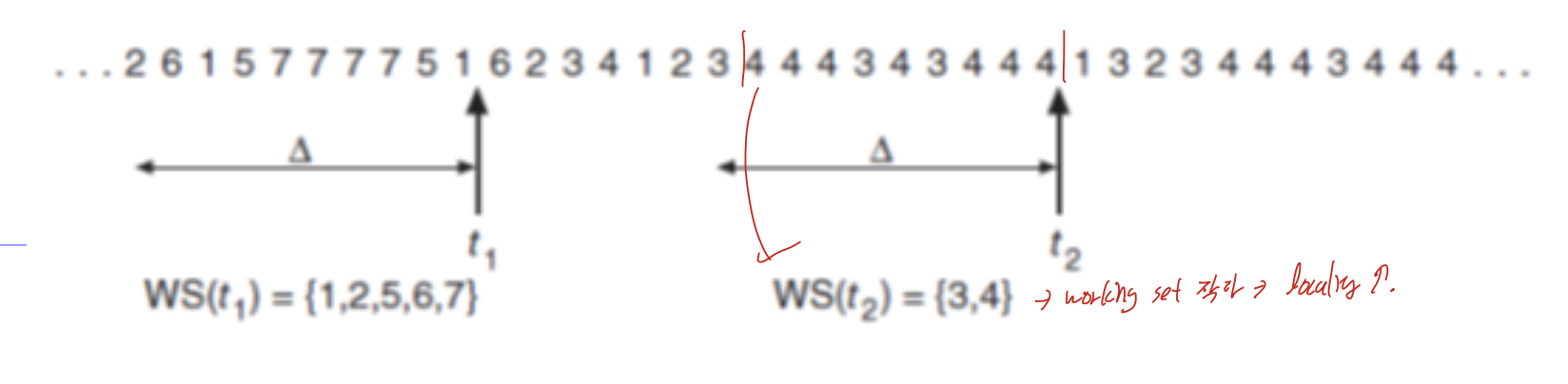
같은 델타를 가지고 있더라도, 여러개를 참조하여 WS의 크기가 증가한다면 딱 봐도 locality가 낮다는 것을 알 수 있다.
반면 같은 델타에서 3, 4만 참조했으므로 이는 locality가 높다는 것을 알 수 있다.
델타의 좋은 크기는 아직 못찾았다. 아마 못찾을거다.
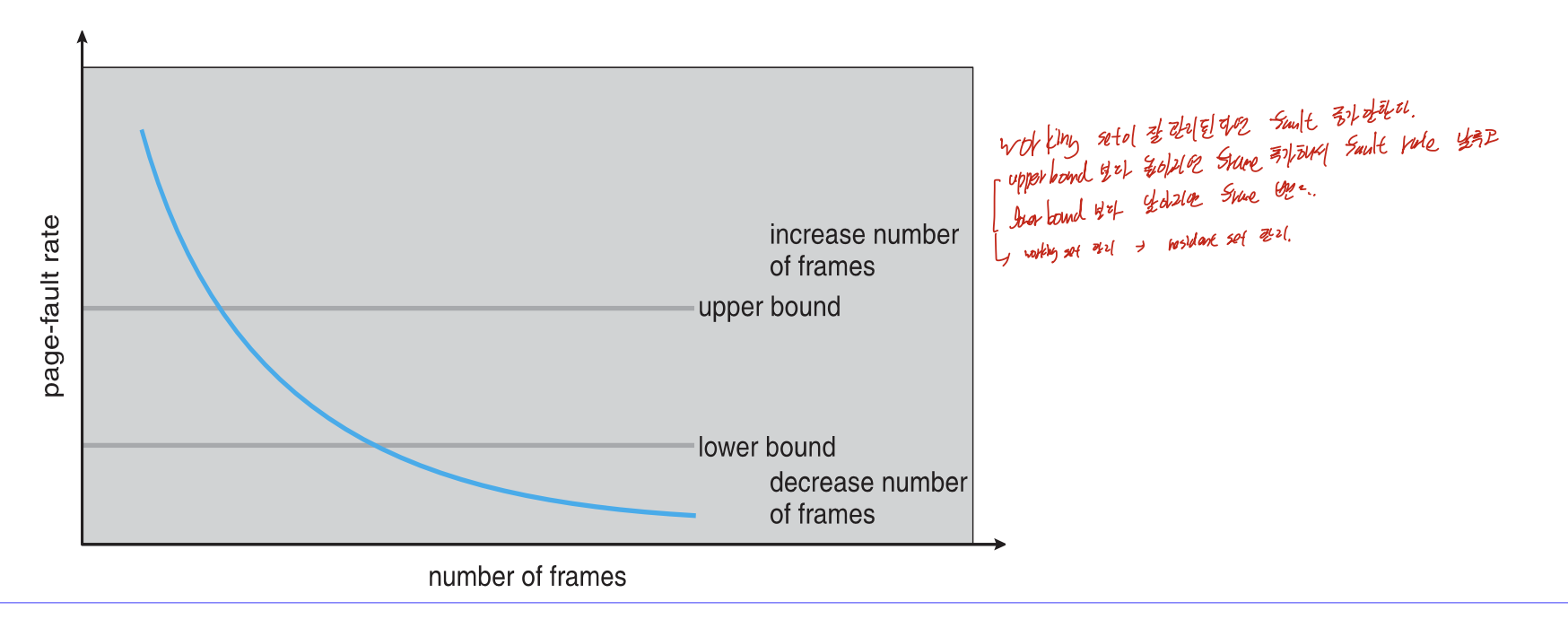
상단에 서술한 전략으로 working set을 통해 resident set을 관리하는 것은 LRU와 비슷하게 사용하지 못한다. 그러므로 대략적인 방법으로 upper bound, lower bound를 정해 upper bound보다 높아지면 frame 추가해서 fault rate 낮추고, lower bound보다 낮아지면 반대로 해서 resident set을 관리할 수 있다.
Hardware
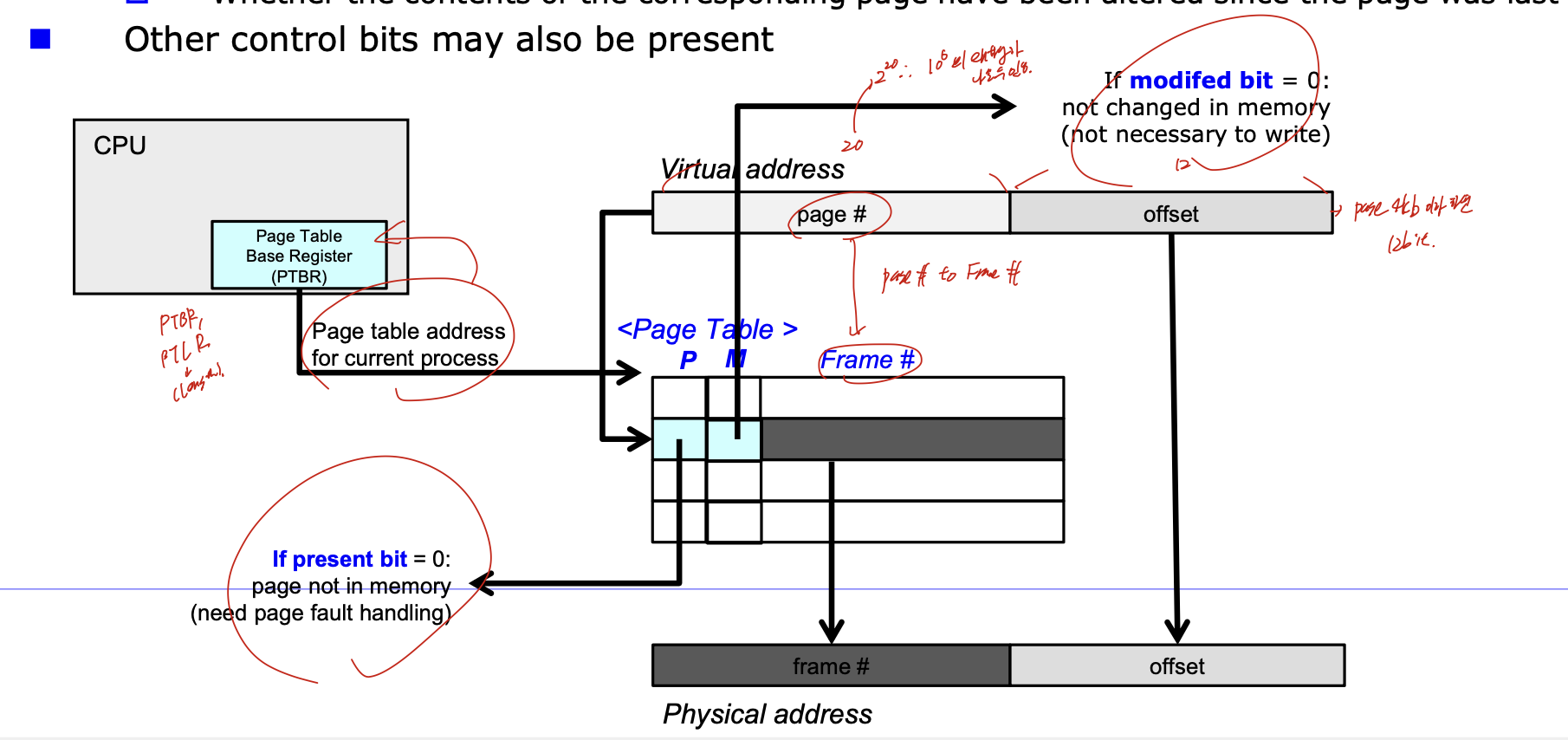
아악
page table의 정보를 cpu register에 저장할수 없다. 커서
그러니까 PTBR로 table의 주소를 저장한다. 추가로 PTLR도 있어 이건 Page Table length를 저장한다. 그리고 이 정보들로 메모리에 저장된 page table로 가면, 일단 앞에 비트가 붙어있다. P는 present bit, 즉 부분적재에 해당하는 페이지가 있는지, M은 modify bit, 변경된적 있는지 에 관한 정보이다. 그리고 가상주소를 통해 page#으로 Frame#을 가져오고, 오프셋 그대로 가서 physical address 구한다.
TLB
Translation Lookaside Buffer로
Page Table Entry(PTE)에 대한 캐시이다.
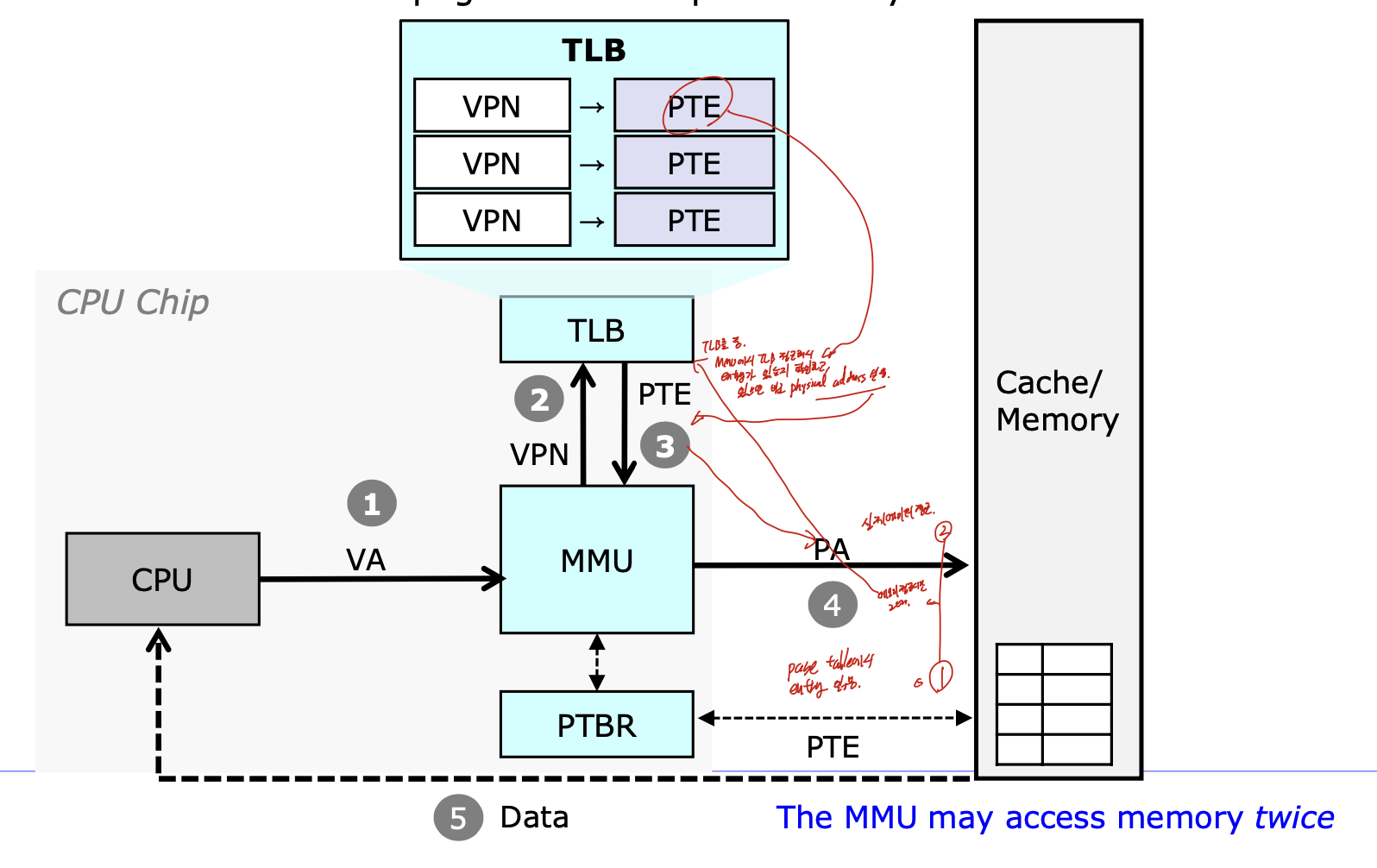
MMU에서 TLB을 접근해서, entry가 있으면 frame#을 return해 physical address 얻어서 접근하는 것 이다.
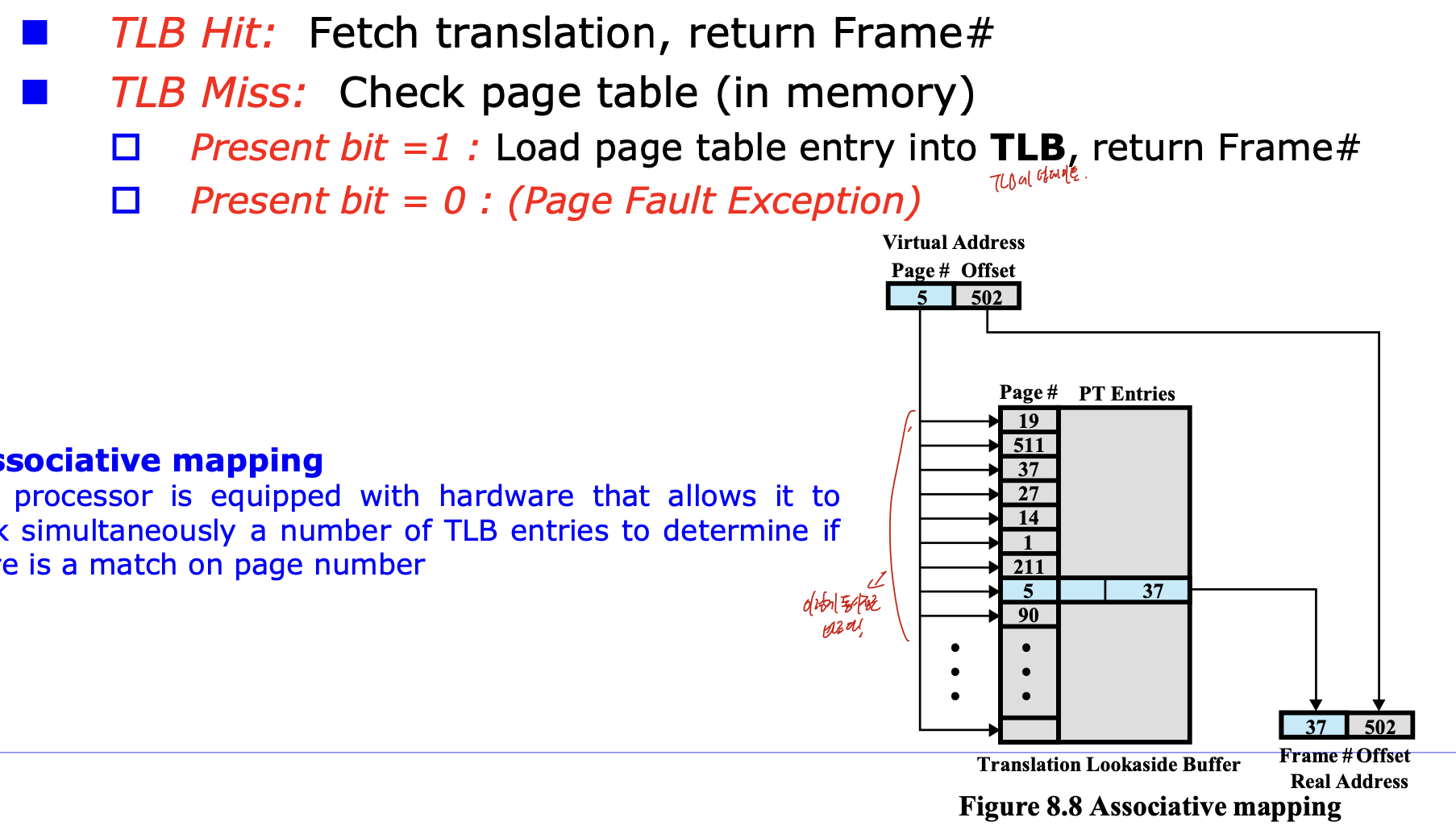
TLB hit하면 이전에 서술했듯이 바로 return하고
Miss가 된다면 page table을 확인하다.
그리고 present bit = 1이면 page table entry를 TLB로 가져오고, Frame#을 return하며
0이면 fault가 된다.
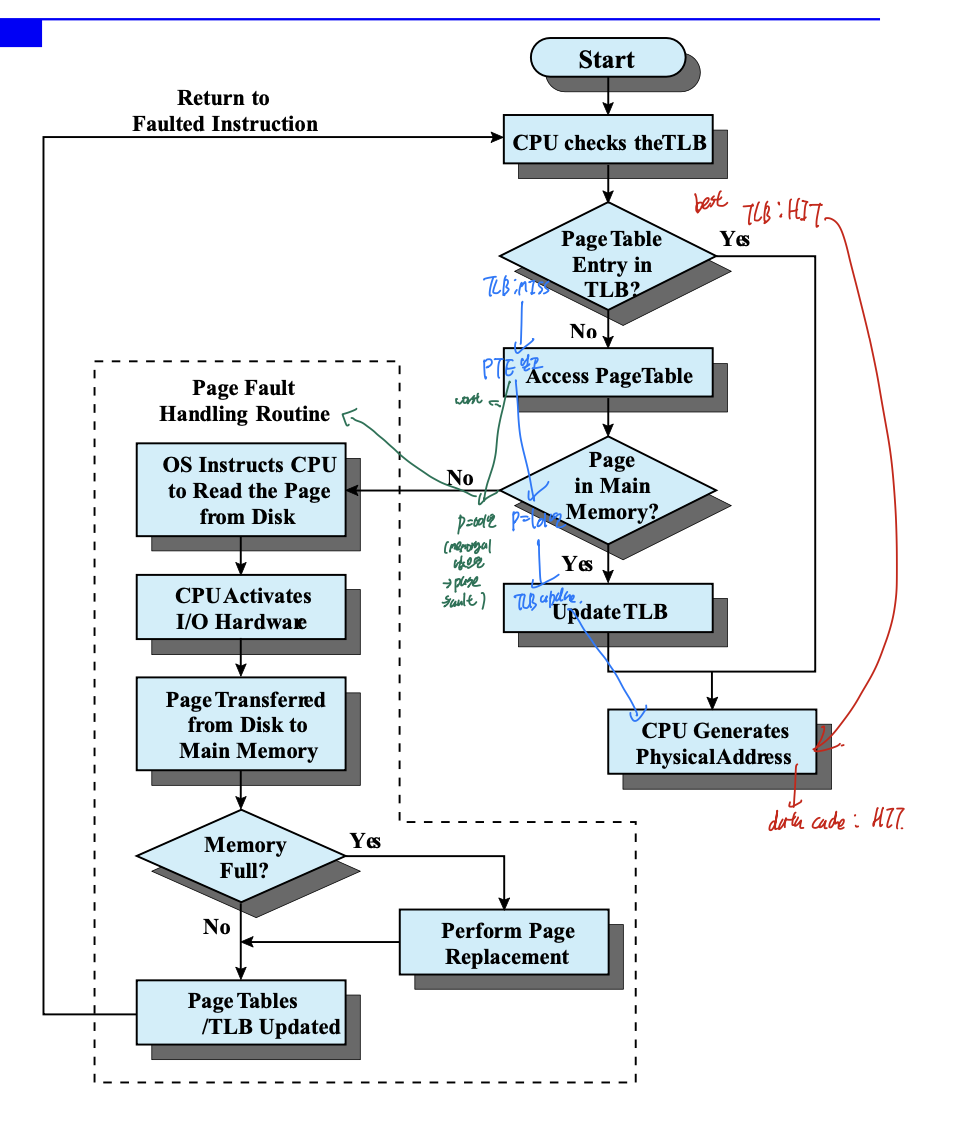
Virtual Memory Issue - Page size
page size가 증가한다면 , page table의 수가 감소한다. ->
장점 : 공간적인 측면에서 이득, I/O 적인 측면에서도 이득, TLB로 접근하는 성능도 좋아짐.
단점 : 최소 할당 크기가 커짐 -> 내부단편화 문제.
- Faster Translation
TLB의 이슈 -> Context Switch
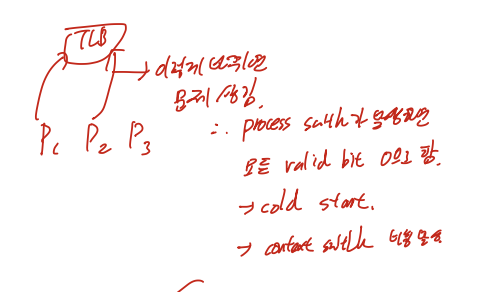
P1의 정보가 TLB에 들어가 있는 상태에서, P2로 스위치가 일어난다면 어떻게 해야할까.
Flush
process switch가 발생했을때 모든 valid bit을 0으로 바꾸는 방법.
P2가 왔을때 모든 비트가 0이기 떄문에, 무조건 fault가 뜬다.
cold start라고도 한다.
매 context switch마다 비용이 많이 발생한다
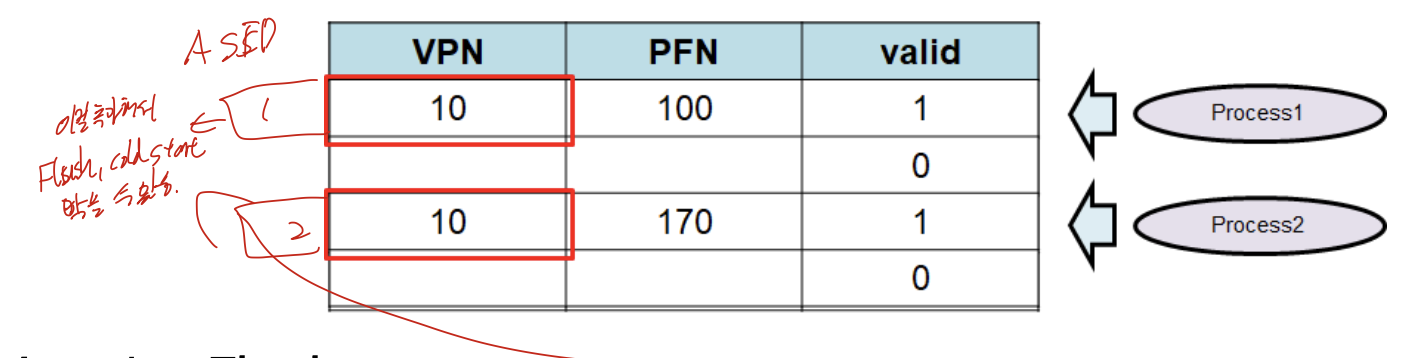
ASID(Address space Identifier)
위의 그림처럼 ASID를 하나씩 추가해주는 것.
process identifier로 사용하는 것으로 TLB가 여러 프로세스의 정보를 가지고 있을 수 있고, 자연스럽게 Flush를 막을 수 있다.
- Smaller Tables
Table이 커질 수록, 용량이 너무 늘어난다
이 그림처럼, 사용하지 않는 부분까지도 page table을 만들어야 하기 때문에 부담이 된다.
Combined Segmentation and Paging
장점 : table size를 줄여 memory overhead를 막을 수 있다.
단점 : paging보다 복잡하다.

각 segment table에 page의 base, bound 로 표시된 offset, 다른 control bit가 들어가 segment에 따른 page를 접근할 수 있다.
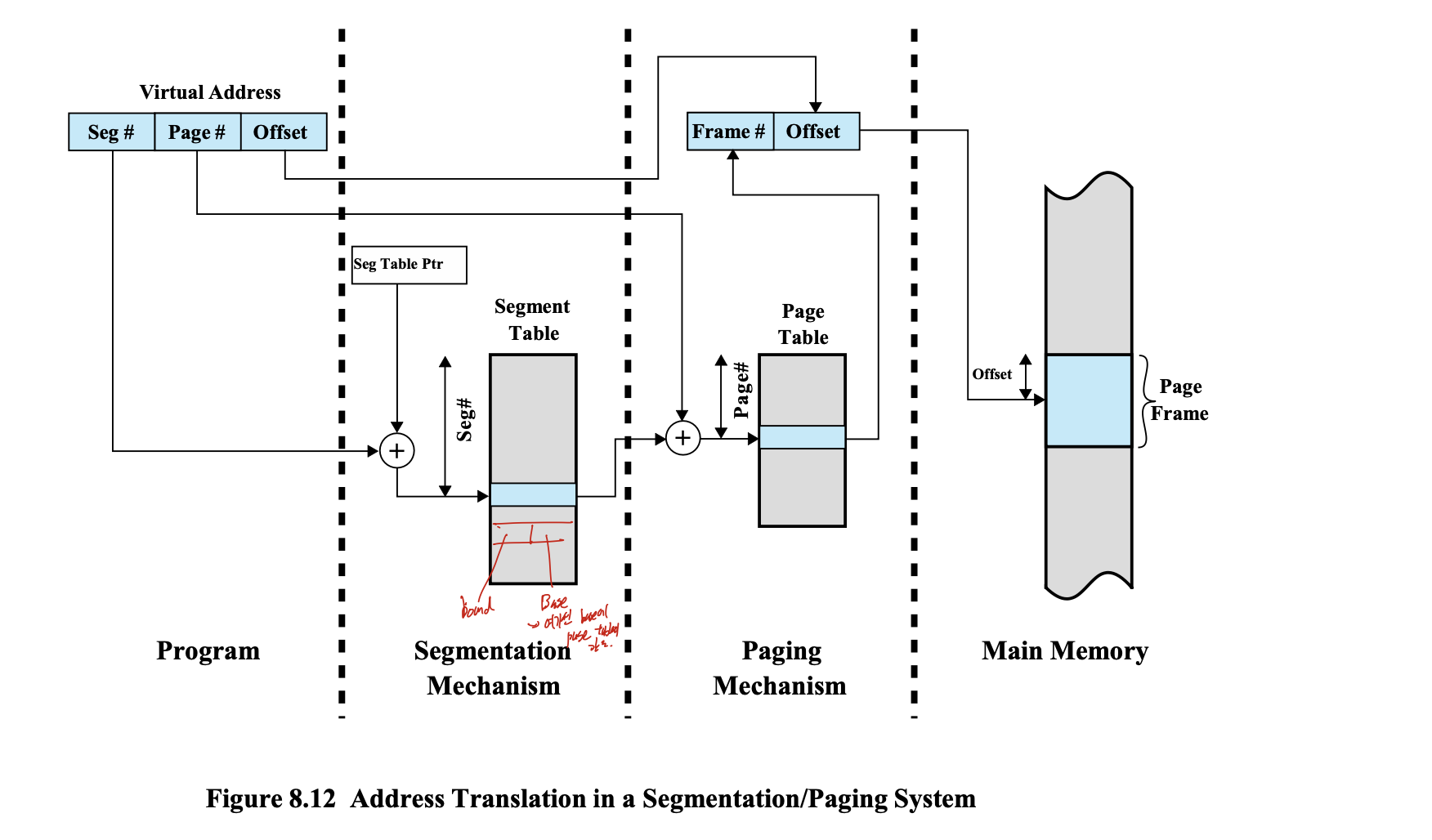
virtual address에는 seg#, page#, offset이 들어가고
segment table 내부에는 bound, base가 들어가서 page를 바로 들어갈 수 있다.
Hierarchical Paging
page table을 multiple page table chunk로 나누는 것.
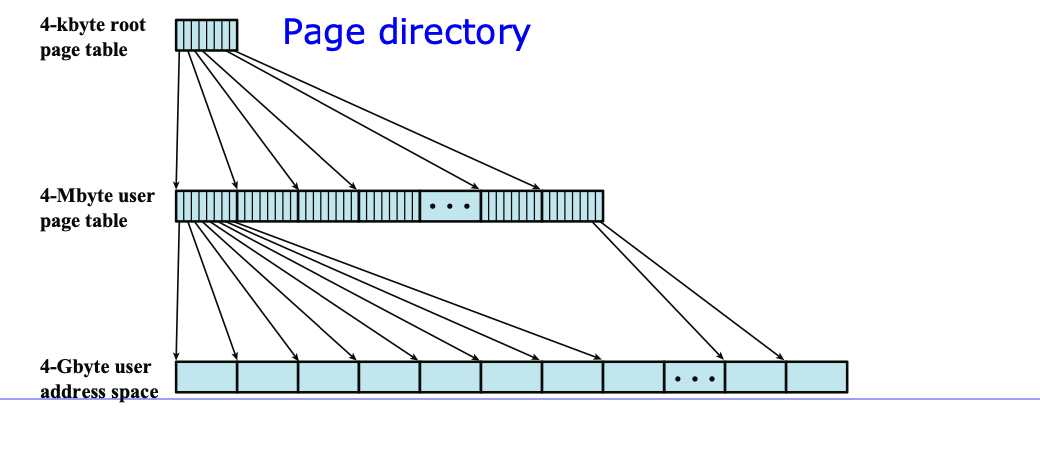
장점 : waste가 적고, page table은 물리 메모리 상에서 연속될 필요가 없다.
단점 : 메모리에서 추가적인 요청이 필요하다.
Inverted Page Tables

frame# 을 index로 사용하는 것.
index에 해당하는 page를 탐색해야 하는데 비용이 들기 때문에, hash function 활용.
15. Disk Scheduling
HDD

Disk layout

고정길이의 섹터에서, 기하학 적으로 밖으로 나갈수록 density가 줄어드는 현상이 발생하여 Multiple zone으로 밖으로 갈수록 많은 sector가 생기도록 변함.
I/O latency
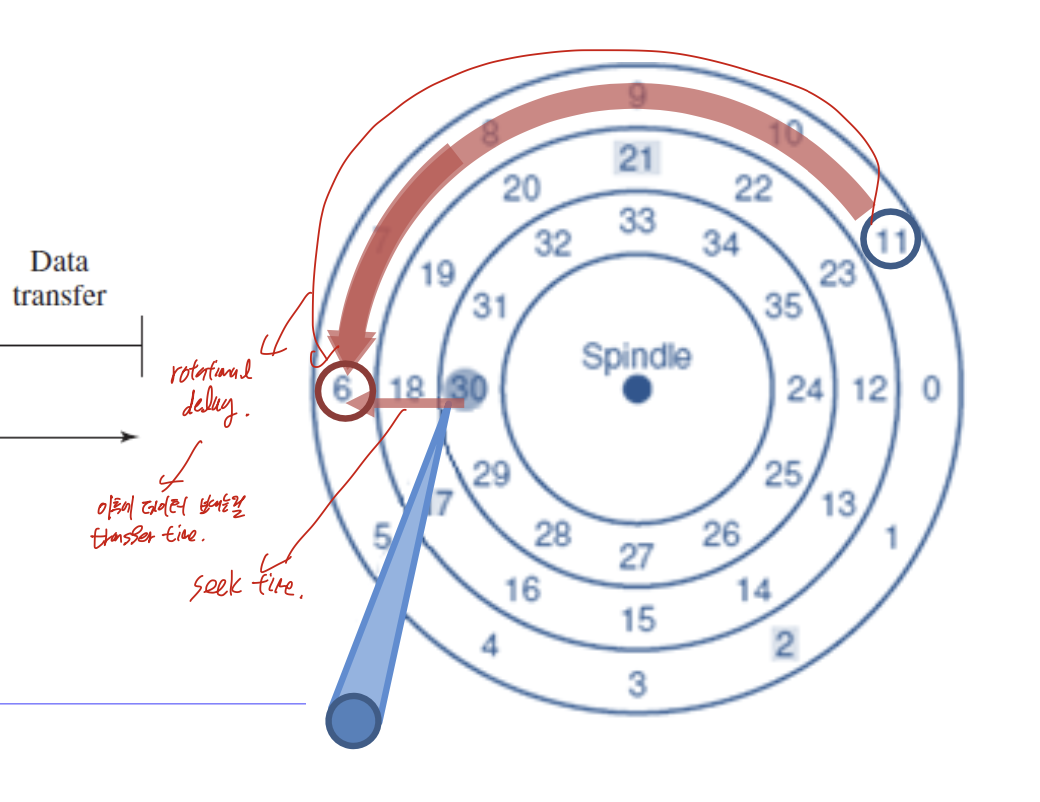
다른 트랙으로 옮기는거 -> seek time
섹터 찾기 -> rotational delay
데이터 찾았으니까, 보내기 -> transfer time
FIFO
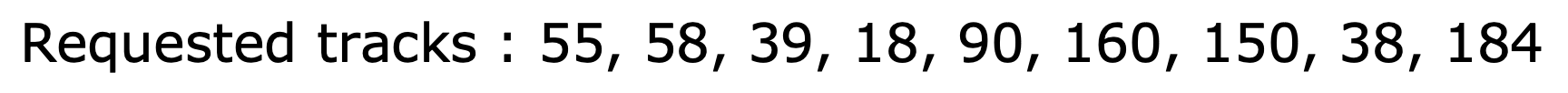
뒤의 예시들에서도 사용할 고정 인풋
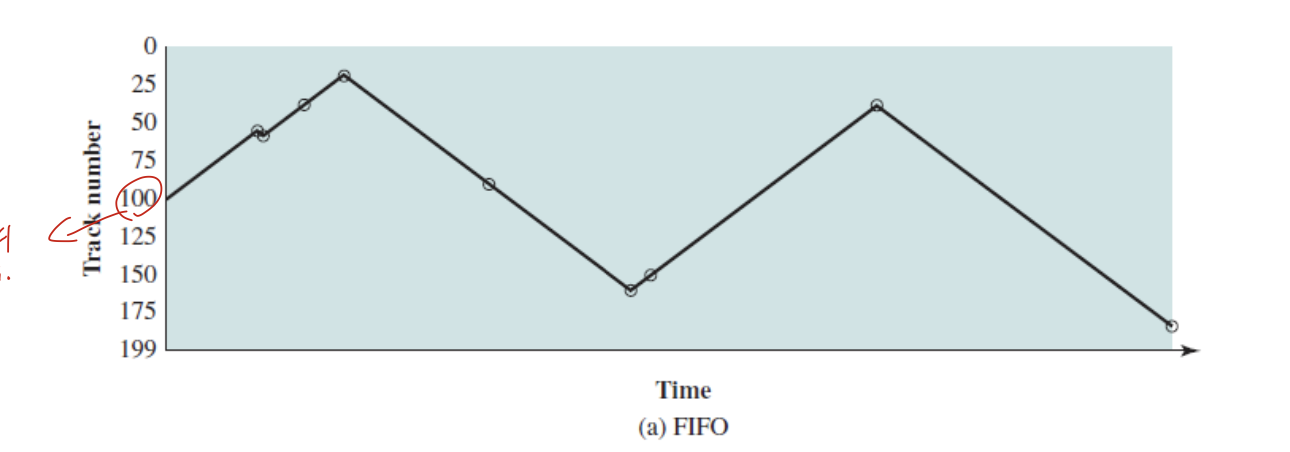
starvation 없고, 공평하지만
성능이 구림.
SSFT(Shortest Seek time First)
seek time -> track 찾는거. 그러니까 그냥 같은 track부터 돌림.
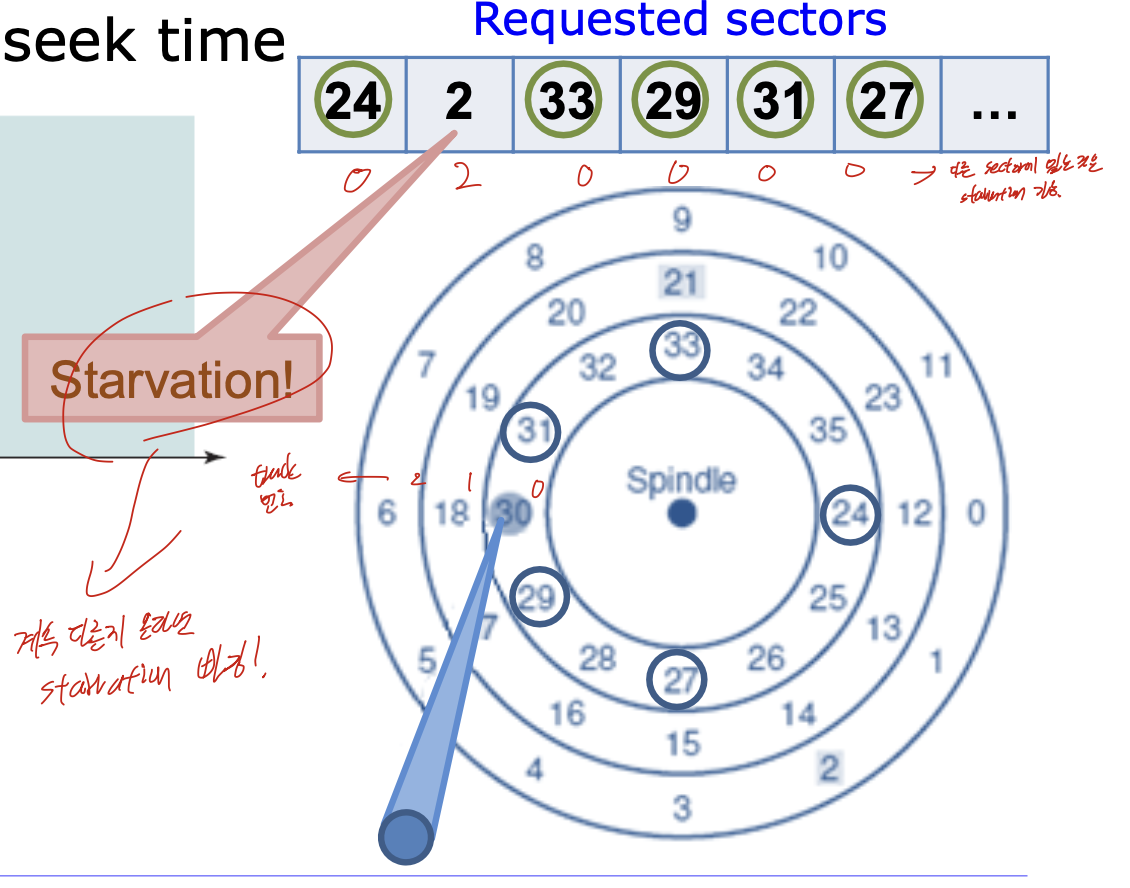
이 그림 보면, 같은 track에 있는거 하고, 계속 같은 트랙의 다른게 올라온다면 다른 트랙에 있는 2는 starvation 걸림.
SCAN(Elevator algorithm)
기준점이 있고, 그 기준점으로 한쪽 방향으로 움직이는 것. 그리고 마지막까지 가면 그때 방향바꿔서 다시 처리

new arrival 이 없으면 나쁘지 않은데, new arrival이 있으면, 어떤 해당 방향에 있는 것들만 계속 처리된다. 그러므로 한쪽에 latency가 쌓이게 된다. -> fairness 낮다
C-SCAN(Circular Scan)
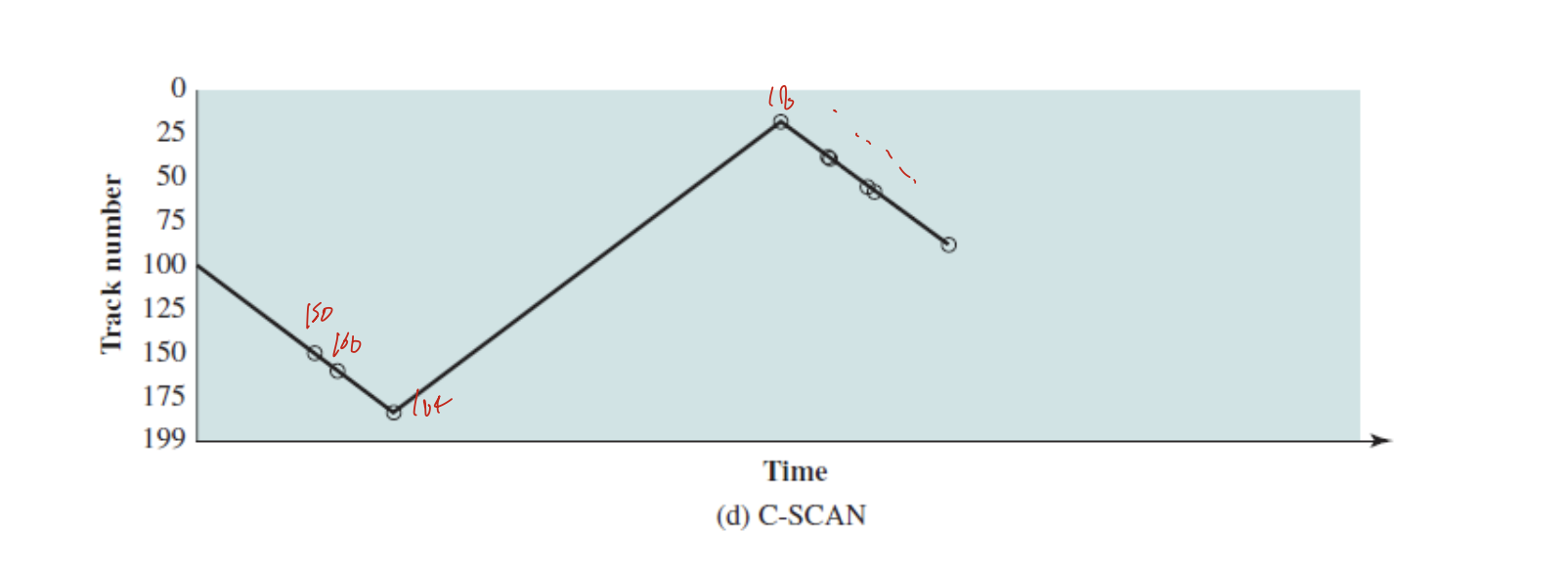
SCAN에서 양 극단에 갈때, 방향 바꾸는데 이건 그렇게 안하고 양 극단에 가면 다른 양 극단으로 보내는거. 그림보면 150, 160, 184, 18~~~
이렇게 감.
N-Step SCAN
특정 트랙에 데이터가 많이 들어온다면, 독점당할 수도 있다.
그러므로 segment queue를 N으로 잠아서, 어떤 queue가 실행되고 있으면, 다른 N size Q에 new arrival 들어가는 것.
이거 N사이즈 들어나면 Scan하고 똑같음.
