Python with CSV
import pandas as pd
df = pd.read_csv("police_station.csv")
df.head()
판다스는 또 뭐지…? csv를 불러오는 형식인가? 아무튼…
결과는 CSV에 있는 파일내용이 결과값으로 온다.
cursor = conn.cursor(buffered=True)
sql = "INSERT INTO police_station VALUES(%s, %s)"
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit() ###execute한 내용은 commit을 만나는 순간 테이블에 적용됨
이 결과를 police_station이라는 테이블에 넣어준다.
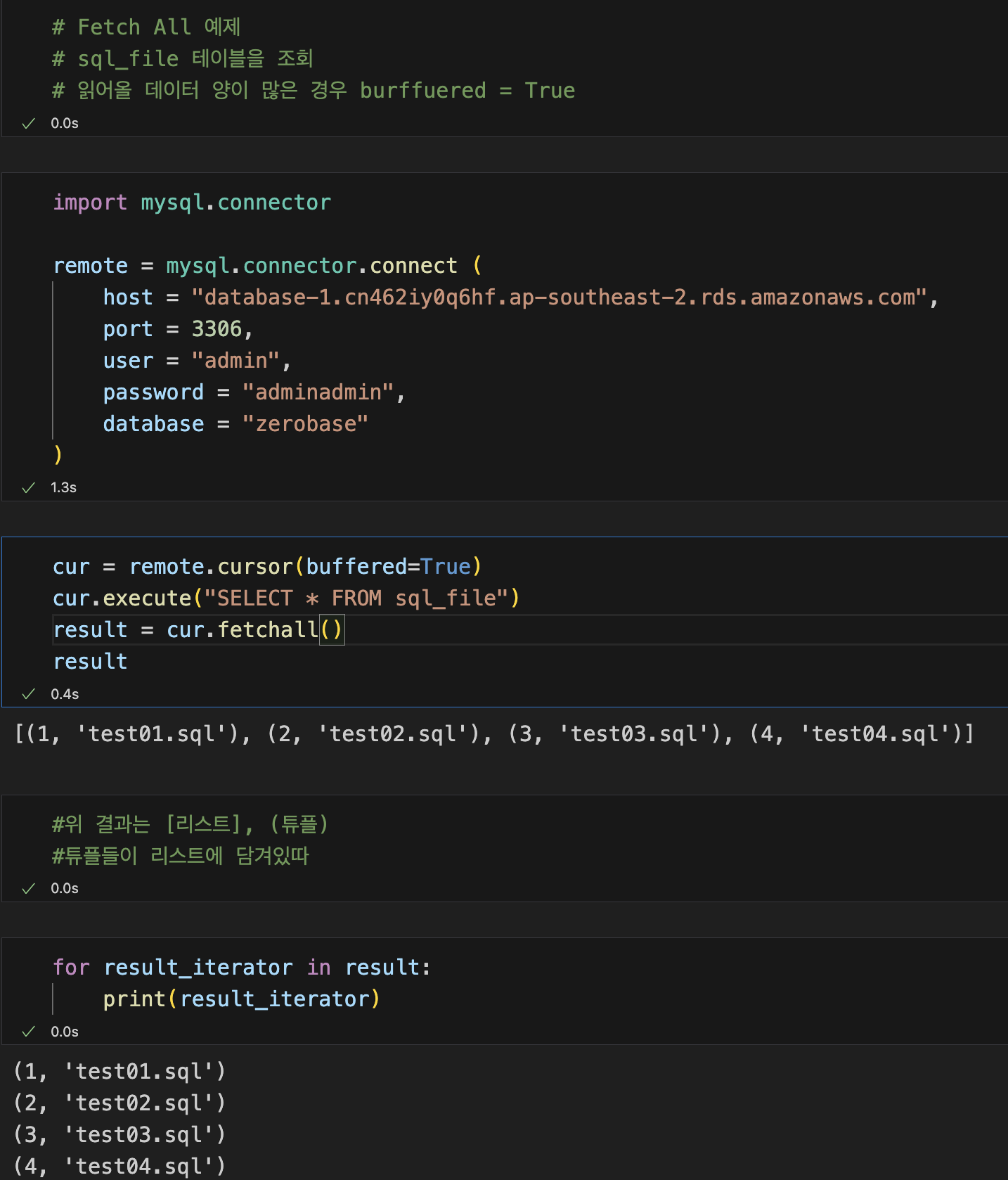
cur = remote.cursor(buffered=True)
cur.execute("SELECT * FROM sql_file")
result = cur.fetchall()
result
remote 해온 부분에 cursor라는 메서드가 적용된 변수 cur
cur는 셀렉트라는 동작을 할 것이다. cur.execute("SELECT * FROM sql_file")
cursor에서 작업한 것을 result 변수에다가 fetchall 한다.
참고 Pandas를 통해 데이터 읽기
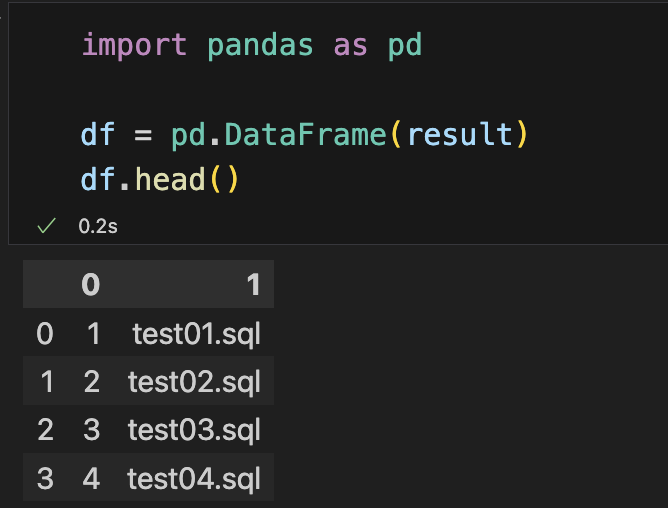
위에서 파이썬으로 sql한것을 pandas형태로 변환
import pandas as pd
df = pd.DataFrame(result)
df.head()
실습
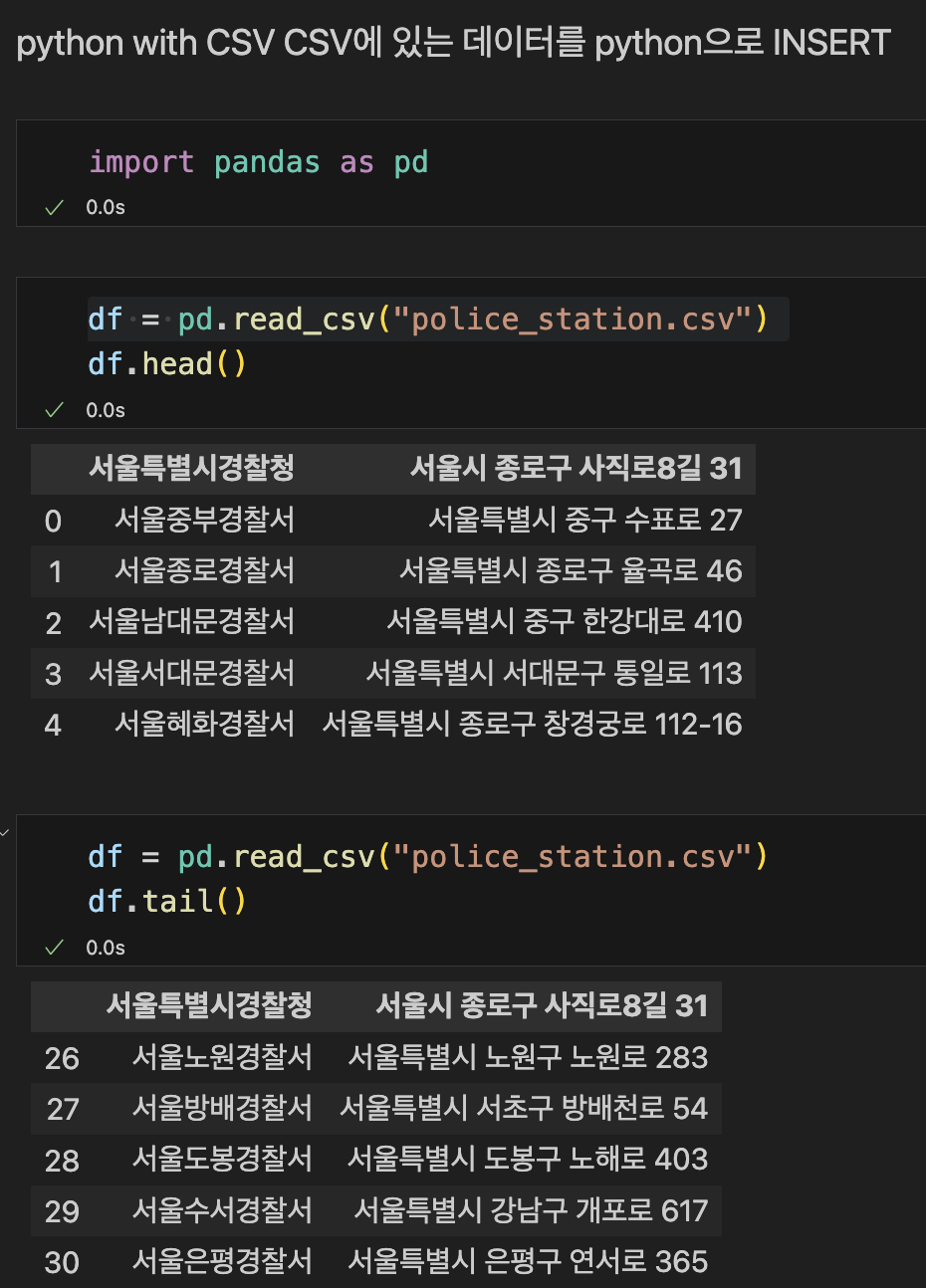
df를 통해 CSV를 읽는다. 자세히 보면
df.head 와 df.tail의 차이점은
상위 5개 또는 하위 5개가 찍힌다.
CSV파일에서는 서울청이 1번으로 되어있으나, head와 tail둘다 번호없이 서울청이 찍힘
예제1) crime_status테이블에 2020_crime 내용 넣기
import mysql.connector
conn = mysql.connector.connect (
host = "database-1.cn462iy0q6hf.ap-southeast-2.rds.amazonaws.com",
port = 3306,
user = "zero",
password = "zerobase",
database = "zerobase"
)
↑ 파이썬과 SQL을 커넥팅해주는 구문
import pandas as pd
df = pd.read_csv("2020_crime.csv",encoding="euc-kr")
df.head()
↑ CSV파일을 판다스로 읽어와서, df라는 곳에 저장
sql = "INSERT INTO crime_status values('2020',%s, %s, %s, %s)"
cursor = conn.cursor(buffered=True)
for i, row in df.iterrows() :
cursor.execute(sql,tuple(row))
conn.commit() for문이 한번 돌 때, 한열씩 입력이 됨
↑ 여기서 이제 INSERT INTO 해줌. 기본적인 매커니즘 이해가 필요하다.
이거는 3가지 CSV파일로 여러번 실습해볼 예정 일단 오늘은 5번.
