머신러닝을 이용하지 않고 Mnist 손글씨 데이터 인식하기 Project
( 부제:ISP로 ML 이겨보기 )

프로젝트의 간단한 계획(흐름)
내가 생각한 글씨 인식 방법
1. 6만개의 트레이닝 데이터로 각 숫자에 대한 데이터 만들기
2. 0~9 각각의 데이터 보완하기(보정하기)
3. 검증
내가 생각한 글씨 인식 방법
숫자를 보면 모두 특징이 있다
0은 안쪽이 비어있고
1은 처음 부터 끝까지 모양이 같고
6은 아래쪽 오른쪽에 동그라미가 있으며
9는 6과 반대인 모양을 가지고 있다
사람은 이러한 특징으로 숫자를 구별한다
나는 숫자의 특징을 다르게 생각해보기로 했다
숫자의 부분부분을 모두 빛으로 생각을 하고 숫자를 위로 한번 세워보자
(휴대폰 화면 부분을 숫자 부분으로 생각한다면 음량 조절키가 천장을 향하도록 세우는 형식이다)
빛이 많을수록 더 밝아지는 특징과 함께 생각해 본다면
1은 모든 부분이 빛의 밝기가 같을 것이고
6과 같은 경우는 위쪽은 숫자 1과 밝기가 비슷하나 동그라미가 있는 부분은 위쪽 부분보다 더 밝을 것이다
3의 경우도 3부분의 밝기가 더 밝을것이다
7을 보면 제일 위쪽 부분이 가장 밝고 나머지 부부은 1과 같이 밝기가 같을 것이다
내 의도가 잘 전달되었을지는 모르겠지만...
이러한 특징을 살려서 프로젝트를 진행했다
실질적인 내용의 설명 조금 더 해보면
데이터들의 크기는 28*28이다
가로 픽셀 28개 세로 픽셀 28개로 이루어져 있다
각 행의 픽셀의 합을 모두 더하여 세로로 28개로로만 이루어진 배열을 만든다
이렇게 하면 숫자를 위로 세운 것과 같은 형태를 만들 수 있다
1. 6만개의 트레이닝 데이터로 각 숫자에 대한 데이터 만들기
손글씨이기 때문에 숫자의 필체가 모두 다르다
손글씨들의 모양 즉 평균적인 모양들을 잡기 위해서 각 숫자들의 데이터를 이용해서 글씨의 기준점을 잡는다
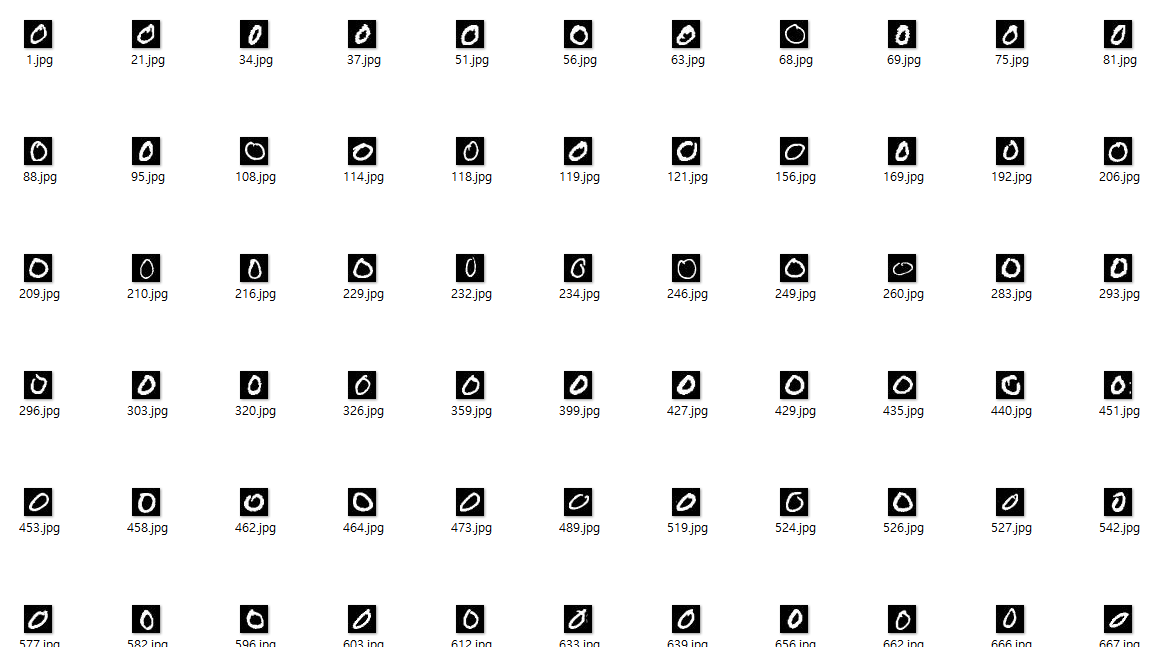
예시로 0을 보면 0의 모양은 비슷하지만 모두 같지 않다
하지만 모양이 비슷하다는 점을 이용해서 평균적인 모양을 잡아보자
0의 데이터는 5923개인데 다음 사진은 5923개의 데이터의 픽셀을 모두 더해 평균을 낸 부분이다

이것을 이진화 하여 세로 28개의 배열로 만든다

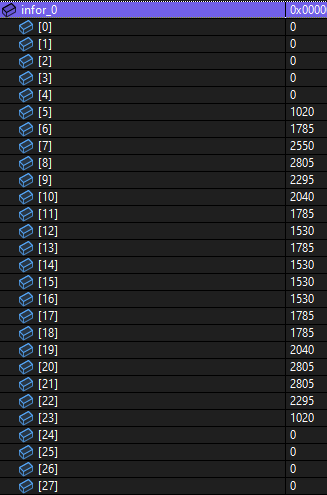
배열들의 숫자를 보면 0의 형태가 보인다
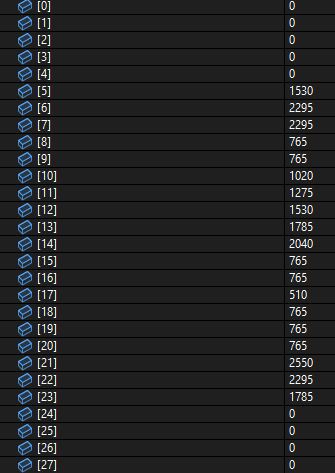
이 배열은 3인데 3의 특징을 볼 수 있다
이런 방법으로 0~9까지 모두 데이터를 만든다
int infor_whole[784] = { 0 };
string fileDir = "<경로>\\MNIST - JPG - training\\0";
vector<string> filelist;
for (const auto& list : fs::directory_iterator(fileDir))
{
cout << list.path().string() << endl;
filelist.push_back(list.path().string());
}
Mat new_2 = Mat::zeros(28, 28, CV_8UC1);
uchar* pD2 = new_2.data;
int test[28] = { 0 };
for (const std::string& filePath : filelist)
{
cout << filePath << endl;
Mat image = imread(filePath, IMREAD_COLOR);
cv::Mat gray_image;
cv::cvtColor(image, gray_image, cv::COLOR_BGR2GRAY);
Mat bin_img;
int thres_min = 100;
threshold(gray_image, bin_img, thres_min, 255, ThresholdTypes::THRESH_BINARY);
uchar* pDatabi = bin_img.data;
size_t width = bin_img.cols;
size_t height = bin_img.rows;
for (size_t k = 0; k < height; k++)
{
for (size_t l = 0; l < width; l++)
{
infor_whole[k * width + l] += pDatabi[k * width + l];
}
}
}
for (size_t k = 0; k < 28; k++)
{
for (size_t l = 0; l < 28; l++)
{
pD2[k * 28 + l] = infor_whole[k * 28 + l] / 5923;
}
}
for (size_t k = 0; k < 28; k++)
{
for (size_t l = 0; l < 28; l++)
{
test[k] += pD2[k * 28 + l];
}
}
int infor_0[28] = { 0 };
Mat bin_img_0;
int thres_min = 130; //
threshold(new_2, bin_img_0, thres_min, 255, ThresholdTypes::THRESH_BINARY);
uchar* pD0 = bin_img_0.data;
for (size_t k = 0; k < 28; k++)
{
for (size_t l = 0; l < 28; l++)
{
infor_0[k] += pD0[k * 28 + l];
}
}
cout << "int infor_0[28] = {";
for (size_t i = 0; i < 28; i++)
{
cout << infor_0[i] << ",";
}
cout << "};" << endl;int thres_min = 130; // threshold(new_2, bin_img_0, thres_min, 255, ThresholdTypes::THRESH_BINARY);
thres_min 이 부분은 숫자마다 모두 다른 값을 줘서 각 숫자의 특징을 잘 살렸다
데이터를 만드는 부분과 인식 실행하는 부분의 코드는 다른 cpp파일로 만들었다
2. 0~9 각각의 데이터 보완하기
필체가 너무 다양하기 때문에 만들어진 데이터를 약간 보정하는 과정이 필요했다
예를 들어 본다면
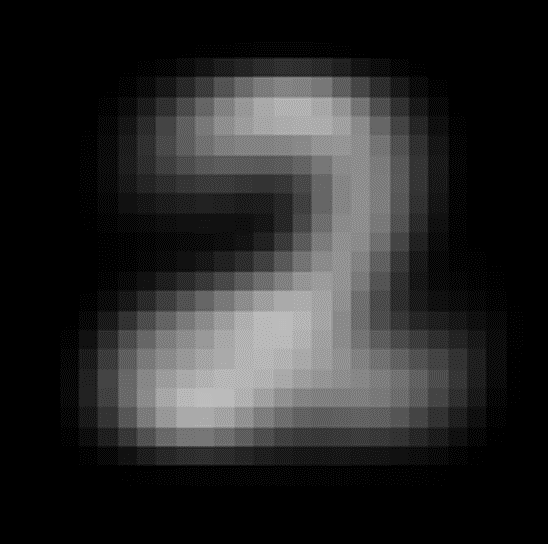

이진화의 임계값을 잘 조절은 하지만 이렇게 2의 모양이 예상했던 모습과 다른 것을 볼 수 있다
이것은 2의 트레이닝 데이터 중 한 개를 가지고 온 것이다
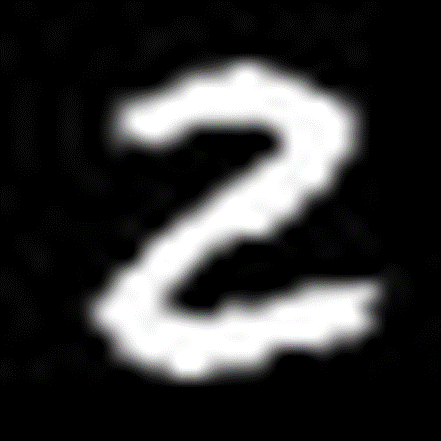
만든 데이터와 모양의 차이가 있다
그렇기 때문에 픽셀이 너무 과하게 합쳐진 부분은 조금 빼고 부족한 부분은 조금 추가하는 방법의 보정 방법을
실행했다
보정을 완료하여 실제 실행 할 때의 데이터 형태들은 배열의 형태로 나타내서 검증을 한다
int infor[10][28] = {
{0,0,0,0,0,1020,1785,2550,2805,2295,2040,1785,1530,1785,1530,1530,1530,1785,1785,2040,2805,2805,2295,1020,0,0,0,0},
{0,0,0,0,0,0,510,510,510,765,765,765,765,765,765,765,765,765,765,765,765,510,0,0,0,0,0,0},
{0,0,0,0,1020,2040,2295,2550,1020,765,765,765,1020,1020,1275,1530,2040,2550,3315,3315,3315,1785,510,0,0,0,0,0},
{0,0,0,0,0,1530,2295,2295,765,765,1020,1275,1530,1785,2040,765,765,510,765,765,765,2550,2295,1785,0,0,0,0},
{0,0,0,0,0,0,0,510,1530,2040,2040,2040,2040,2550,3315,3315,3315,2550,1275,1020,765,765,255,0,0,0,0,0},
{0,0,0,0,0,0,2550,2550,2295,1020,1020,1275,1275,2040,2040,1785,765,765,765,765,1530,2040,2040,1530,0,0,0,0},
{0,0,0,0,0,255,510,510,510,765,510,765,765,1785,2550,2550,2805,2040,2805,2805,2295,1530,0,0,0,0,0,0},
{0,0,0,0,0,0,0,1020,2805,2805,2805,765,765,1020,765,1020,765,1020,765,1020,765,510,765,510,0,0,0,0},
{0,0,0,0,0,1275,2040,2550,2295,1530,1785,1785,2295,2040,1785,1530,1530,1785,1275,1275,1275,2295,2040,2040,510,0,0,0},
{0,0,0,0,0,0,765,2040,2550,2805,1785,2040,2040,2295,2805,2805,2550,1020,1020,1020,765,765,510,0,0,0,0,0}
};3. 검증하기
0~9까지의 테스트 데이터를 가지고 검증
테스트 데이터를 세로 28개의 배열로 만들어 판단 데이터와 비교한다
2가지의 척도로 비교를 하고자 한다
- 픽셀 차이
각 숫자의 형태와 특징은 변하지 않는다
완전히 같을 수는 없기 때문에 픽셀 수 차이의 기준으로 판단 ( 1픽셀 ->255 )
2.유사도
기준에 부합하면 카운트를 올려 전체적인 유사도를 확인한다 ( 100% ->28 )
28개의 세로 배열로 만드는 코드
for (size_t k = 0; k < height; k++)
{
for (size_t l = 0; l < width; l++)
{
test[k] += pDatabi[k * width + l];
}
}비교하는 코드
for (int num_cnt_1 = 0; num_cnt_1 < 10; num_cnt_1++)
{
for (int num_cnt_2 = 0; num_cnt_2 < 28; num_cnt_2++)
{
if (abs(test[num_cnt_2] - infor[num_cnt_1][num_cnt_2]) <= 765) //255*3 4픽셀 차이
{
cnt += 1;
}
else
{
cnt += 0;
}
}
if (cnt >= 24)
{
res[num_cnt_1] += 1;
cnt = 0;
}
else
{
cnt = 0;
}
}cnt -> 유사도 확인
for (int num_cnt = 0; num_cnt < 10; num_cnt++)
{
int cnt_loop = 0;
int res[10] = { 0 };
string fileDir = "<경로>\\MNIST - JPG - testing\\" + to_string(num_cnt);
vector<string> filelist;
for (const auto& list : fs::directory_iterator(fileDir))
{
cout << list.path().string() << endl;
filelist.push_back(list.path().string());
}
.
.
.
.
int pre = 0;
for (size_t i = 0; i < 10; i++)
{
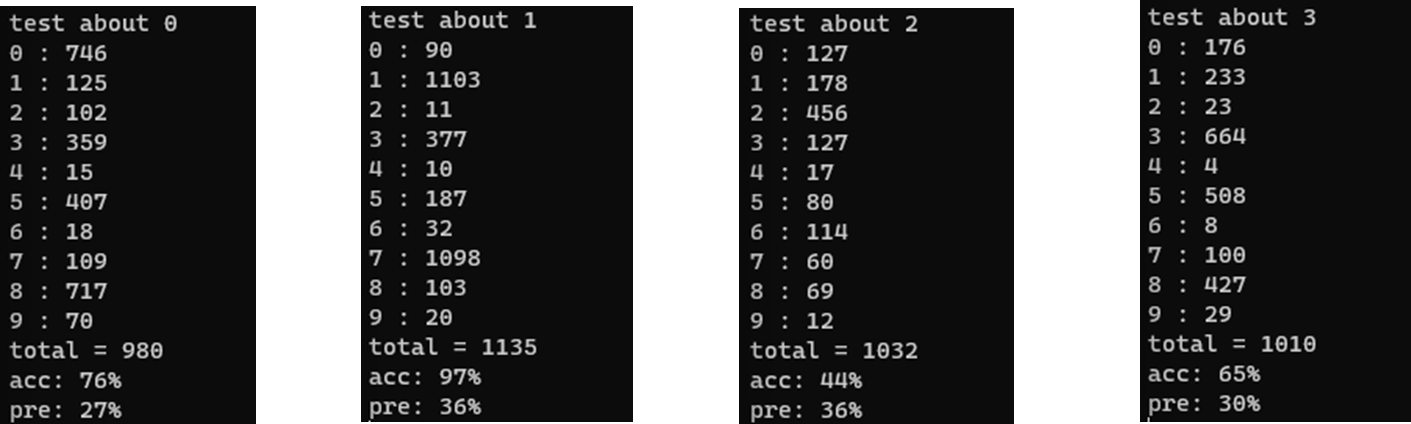
cout << "test" << num_cnt << " " << i << " : " << res[i] << endl;
}
for (size_t cn = 0; cn < 10; cn++)
{
pre += res[cn];
}
cout << "total = " << cnt_loop << endl;
cout << "acc: " << (res[num_cnt] * 100) / cnt_loop << "%" << endl;
cout << "pre: " << res[num_cnt] * 100 / pre << "% " << endl;
int a = 0;
}
}
for 반복문을 이용해 0~9의 테스트 셋 모두를 로딩하여 정확도와 정밀도를 출력한다
int a=0에 브레이크 포인트를 설정하고 결과를 확인한다
정확도와 정밀도를 잘 고려하며 몇가지의 경우로 결과를 보자
1. 픽셀 차이 3개(765) 유사도 22 (약 78.5% )
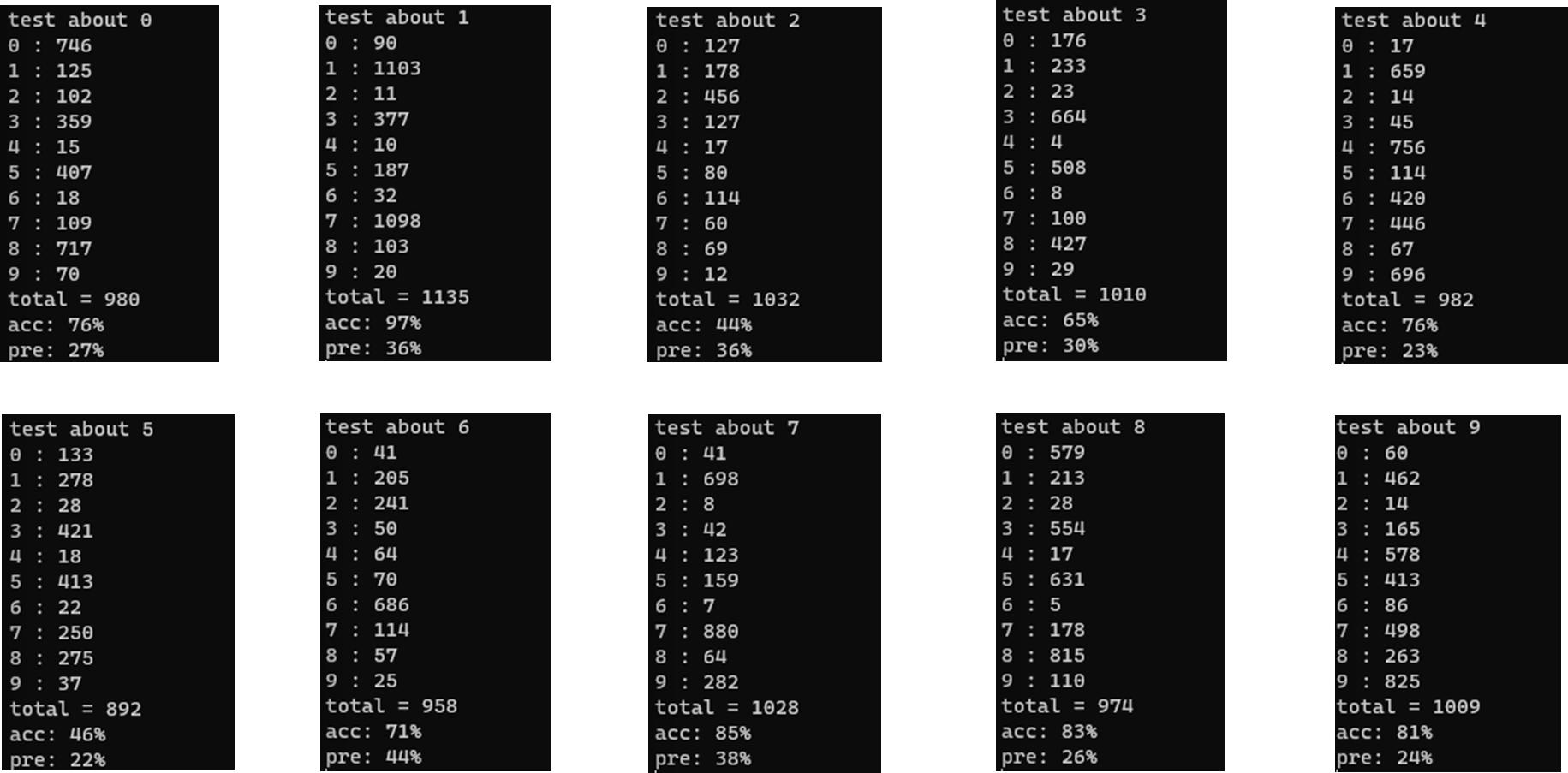
2. 픽셀 차이 3개(765) 유사도 24 (약 85.7% )
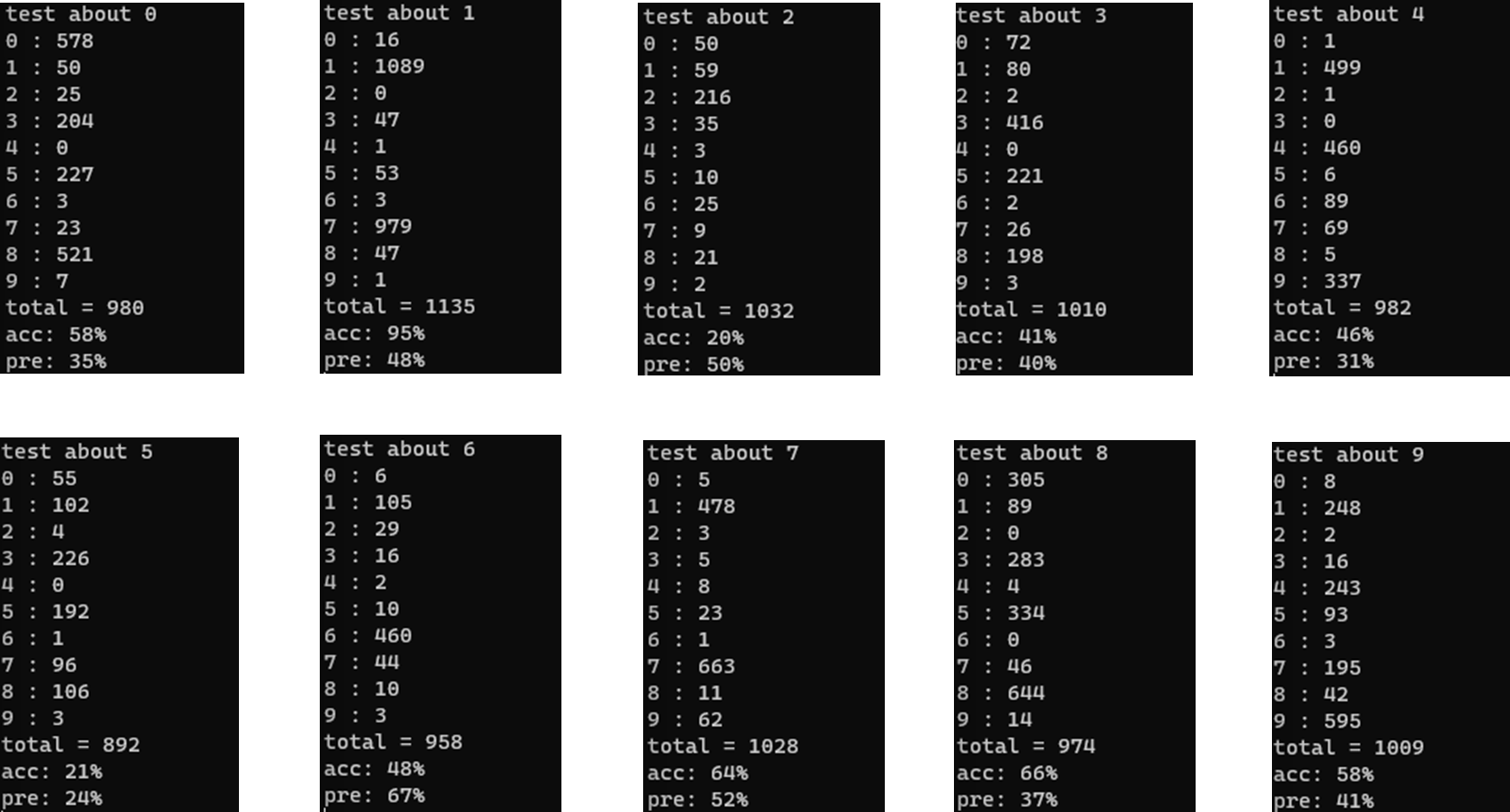
3. 픽셀 차이 2개(510) 유사도 24 (약 85.7% )
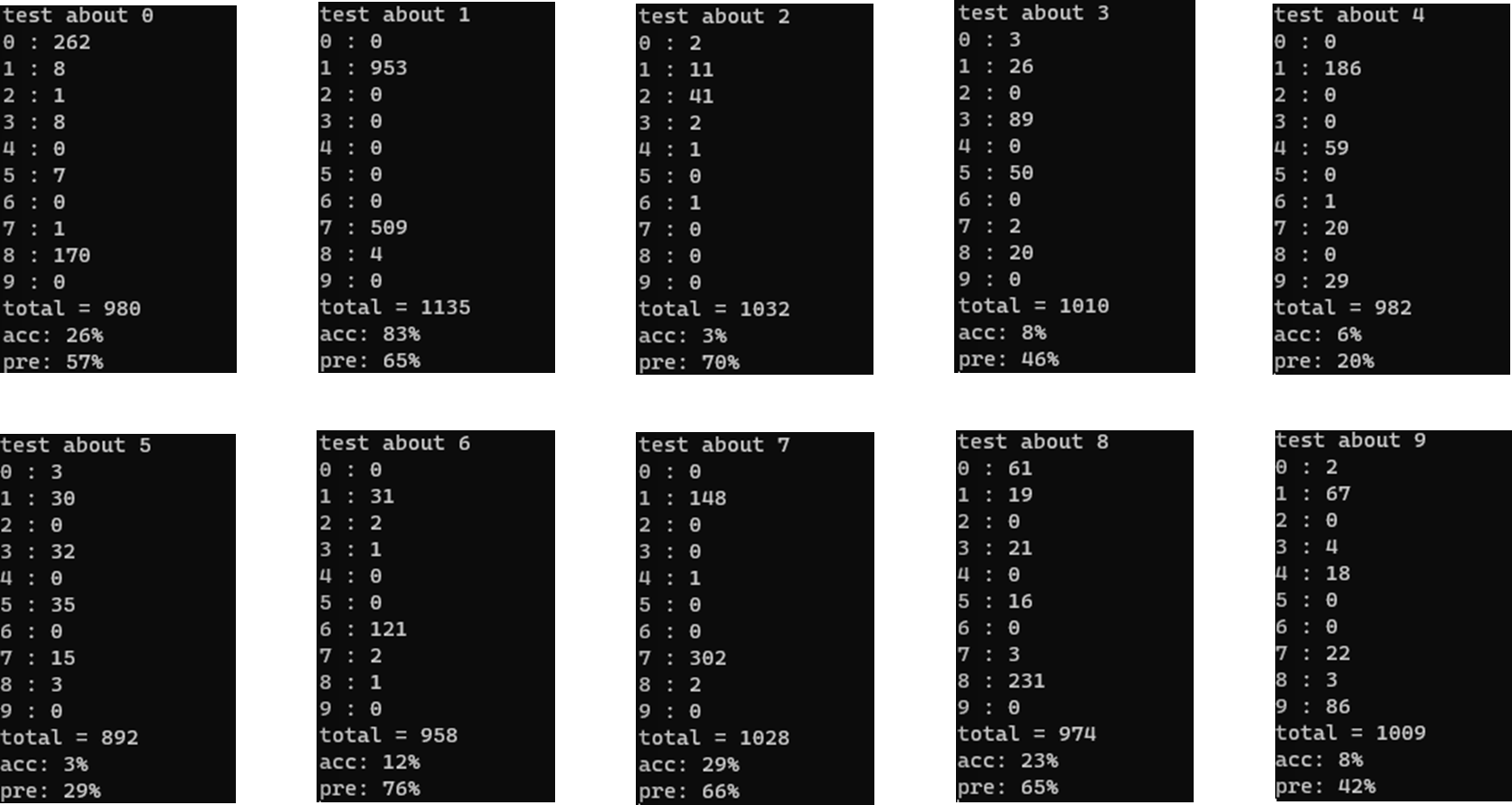
전체적으로 본다면 유사도가 높아지면 정밀도가 높아진다
2,4,5 의 결과가 다른 숫자에 비해 결과가 좋지 않다...
정밀도가 낮으면 오답을 내는 확률도 높아지는데
오답을 내는 확률을 줄이면 정화도가 떨어지게 된다
물론 좋은 결과를 본 프로젝트는 아니지만 정확도와 정밀도를 보니
어떤 값을 더 우선시 해야 할까라는 고민이 생긴다
Review
처음 이 방법을 생각했을 때 과연 이게 맞는 방법일지 의심이 굉장히 많이 들었다
내가 의도한 대로 인식을 할지 동작을 할까에 대한 확신이 없었다
물론 완벽히 인식을 한다거나 좋은 성과를 냈다고는 할 수 없지만
나만의 방법으로 프로젝트를 진행했고 나름의 인식을 하는 척(?)을 해줘서 다행이다

유익한 글이었습니다.