
CDC(Change Data Capture)가 뭔데?
-
CDC는 RDBMS와 NoSQL등의 Data Store 시스템의 변경 데이터를 내부적으로 기록하고 있는 Redo Log/Bin Log/WAL등의 내부 트랙잭션 로그 파일에서 변경데이타를 Capture하는 소프트웨어를 지칭
-
DB 내부 트랜잭션 로그 파일에서 변경 데이터를 추출하므로 소스 DB 성능에 큰 영향없이 대용량의 변경 데이터를 매우 빠르게 추출하고 (준)실시간으로 타겟 DB에 연동
-
DBMS 복제(Replication) 수준의 안정적이고 정확한 데이터 추출 가능
-
성능과 안정성이 중요한 많은 중요 DBMS시스템에서 CDC를 활용
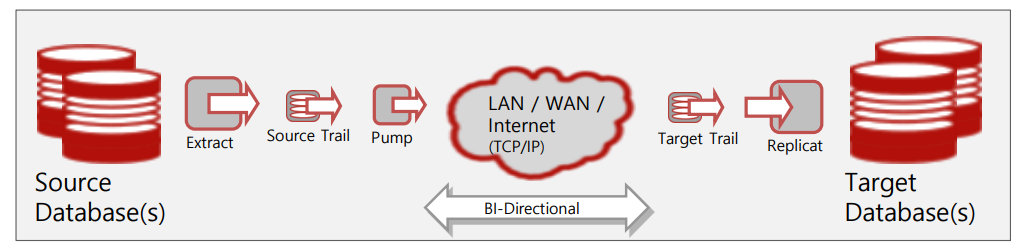
-
source db 쪽에서 리드로그를 보면서 변경사항을 감지하고 있음..
-
감지가 되면 CDC sw 가 읽고 CDC전용의 파일형식으로 만든다.
-
만들어진 파일은 네트워크를 타고 넘어가고
-
이 파일을 읽어서 SQL로 변환한 후 target db 에 넣어줌.
DBMS 별 트랜잭션 로그 파일

DB 복제(Replication)와 CDC 비교
-
데이터 복제는 DB의 가용성을 극대화 하기 위해서 Primary(Master)와 Standby(Slave)간의 데이터를 완벽하게 동기화하는데 초점을 맞추기 때문에 아키텍처 유연성이 상대적으로 떨어짐(Primary와 Standby가 DB 버전, OS 구성이 거의 동일)
-
CDC는 DB 버전이나 OS환경에 대한 구성 제약이 상대적으로 덜 엄격하며, 보다 다양한 비즈니스 활용에 적용할 수 있음
CDC 아키텍처
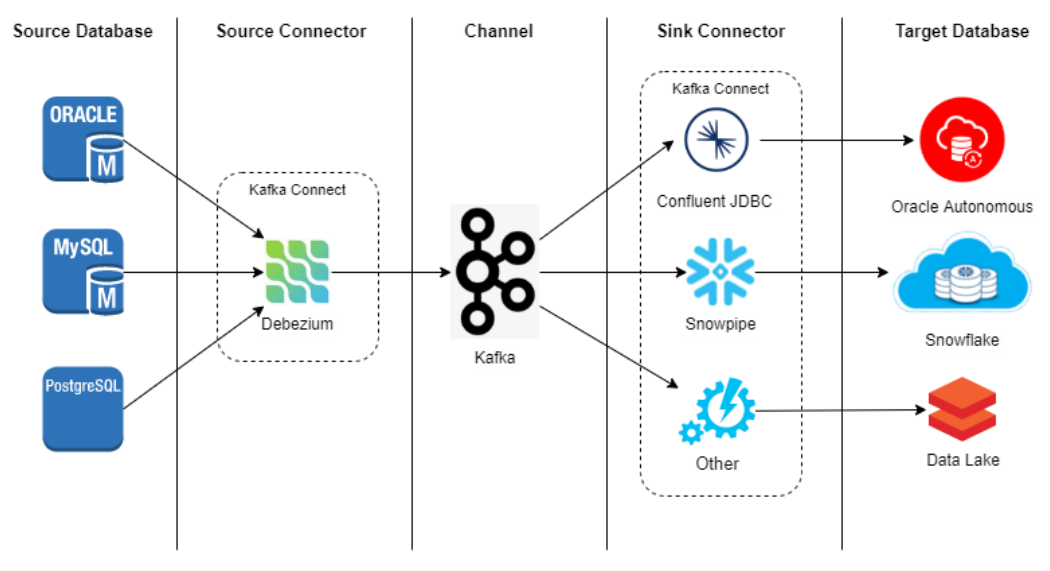
Debezium 아키텍처
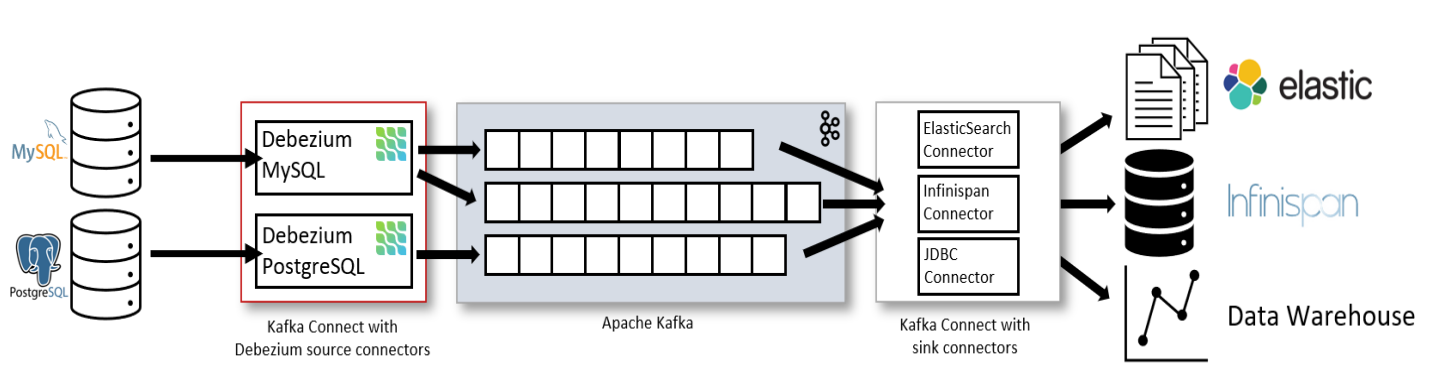
Debezium 장점
-
CDC 기반의 Source Connector로 소스 DB 성능에 큰 영향 없이 대용량의 변경 데이터를 매우 빠르게 추출
-
DBMS 복제(Replication) 수준의 안정적이고 정확한 데이터 추출
-
Kafka 기반의 RDBMS 연계 운영 환경에서 가장 많이 사용되는 Kafka Source Connector
Debezium 이벤트 메시지
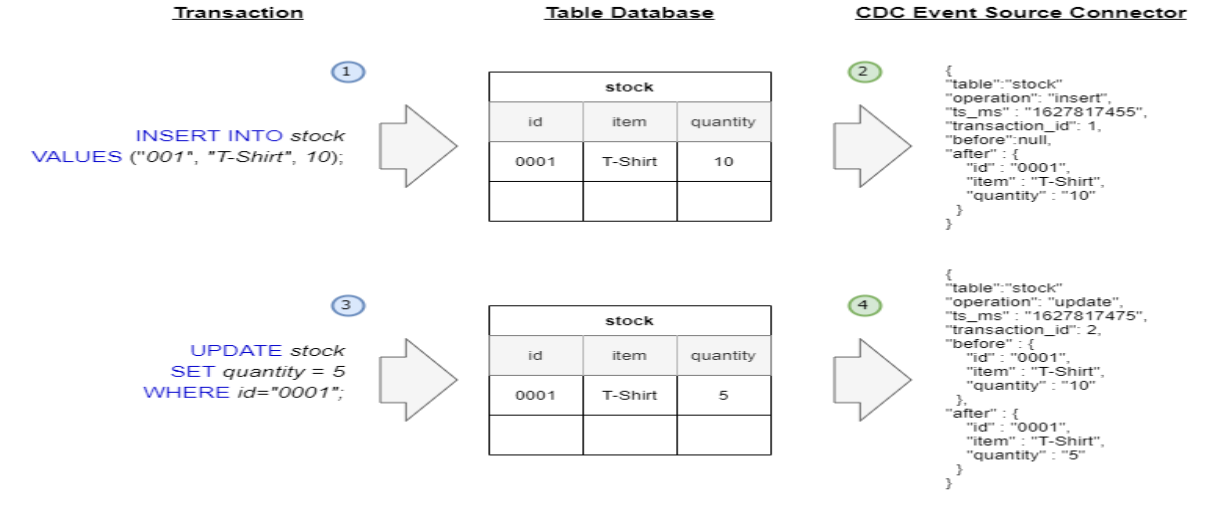
-
delete 는 insert의 반대로 들어감
-
before가 있는 이유는 rollback 때문..
Debezium for Kafka유의 사항
-
Debezium Source Connector는 Source 데이터에서 Kafka 까지만 연계됨. Kafka에서 타겟(Sink) 연계는 JDBCSink Connector로 수행되어야 함.
-
소스 DB의 DDL 변경을 타겟 DB에서 정확히 반영하기 어려움
-
타겟 DB로의 데이터 입력이 JDBC Sink Connector의 기능에 제약됨(계속 업데이트 되서 추가되고 있긴 함)
다운로드
confluent hub 에서 debezium mysql connector 1.9.7 선택
https://www.confluent.io/hub/debezium/debezium-connector-mysql
혹은
debezim.io 에서 mysql connetor plugin 1.9.7.Final 선택
https://debezium.io/releases/1.9/
docker container 내부로 넘겨주자..
docker cp debezium-connector-mysql-1.9.7.Final-plugin.tar.gz c352b188cd28:/opt/bitnami/connect
//tar 풀고 압축해제 하자..
tar -xvf debezium-connector-mysql-1.9.7.Final-plugin.tar.gz
//plugin 디렉토리에 디렉토리 추가..
mkdir cdc_source_connector
// jar 만 plugin 디렉토리로 옮기자..
cp *.jar ../connector_plugins/cdc_source_connector/
// connect 기동..후 확인
http GET http://localhost:8083/connector-plugins
{
"class": "io.debezium.connector.mysql.MySqlConnector",
"type": "source",
"version": "1.9.7.Final"
}
이게 있어야함..
// class 만..
http GET http://localhost:8083/connector-plugins | jq '.[].class'
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirAvroSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirBinaryFileSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirJsonSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirLineDelimitedSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.SpoolDirSchemaLessJsonSourceConnector"
"com.github.jcustenborder.kafka.connect.spooldir.elf.SpoolDirELFSourceConnector"
"io.debezium.connector.mysql.MySqlConnector" -> 이게 있어야 함
"org.apache.kafka.connect.mirror.MirrorCheckpointConnector"
"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector"
"org.apache.kafka.connect.mirror.MirrorSourceConnector"
DB Replication 권한 생성 및 테스트 DB 생성
create database oc;
show databases;
# 데이터베이스 사용권한 부여
grant all privileges on oc.* to 'connect_dev'@'%' with grant option;
flush privileges;
// 모든 권한 부여
grant all privileges on *.* to 'connect_dev'@'%' with grant option;
flush privileges;
//connect_dev 로 접속 후..
use oc;
drop table if exists customers;
drop table if exists products;
drop table if exists orders;
drop table if exists order_items;
-- 아래 Create Table 스크립트수행.
CREATE TABLE customers (
customer_id int NOT NULL PRIMARY KEY,
email_address varchar(255) NOT NULL,
full_name varchar(255) NOT NULL
) ENGINE=InnoDB ;
CREATE TABLE products (
product_id int NOT NULL PRIMARY KEY,
product_name varchar(100) NULL,
product_category varchar(200) NULL,
unit_price decimal(10,0) NULL
) ENGINE=InnoDB ;
CREATE TABLE orders (
order_id int NOT NULL PRIMARY KEY,
order_datetime timestamp NOT NULL,
customer_id int NOT NULL,
order_status varchar(10) NOT NULL,
store_id int NOT NULL
) ENGINE=InnoDB ;
CREATE TABLE order_items (
order_id int NOT NULL,
line_item_id int NOT NULL,
product_id int NOT NULL,
unit_price decimal(10, 2) NOT NULL,
quantity int NOT NULL,
primary key (order_id, line_item_id)
) ENGINE=InnoDB;
select * from customers;
select * from products;
select * from orders;
select * from order_items;
// root로 로그인하여 현재 복제하는 binlog 정보 확인
SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM performance_schema.global_variables WHERE variable_name='log_bin';
Debezium MySQL Source Connector 파라미터 주요 특징
• 하나의 Source Connector로 여러 개의 Source 테이블 데이터를 유연하게 추출할 수 있으며 하나의 Source 테이블은 하나의 Topic으로 생성
• Source 테이블의 PK는 자동으로 Kafka 토픽의 Key값으로 생성됨
• 토픽명은 기본적으로 database server name.database명.table명으로 생성. SMT를 통해 변경 가능
• Source 테이블의 DDL 변경 사항을 Kafka 토픽으로 저장할 수 있음
• 기본 Topic 메시지는 JDBC Source Connector와 다르게 구성되어 있으며(before/after 값 구성) JDBC Sink Connector에서 데이터를 입력하기 위해서는 SMT를 이용해서 메시지 재 변경 필요
• Delete를 위한 tombstone 메시지를 생성하기 위해 SMT를 적용해야 함.
• Date, datetime, timezone등의 일자/시간관련 타입, numeric, decimal 등의 precision/scale관련 타입은 JDBC Sink Connector가 호환될 수 있는 타입으로 만들어져야 함 .
// Connector 명
"name": “mysql_cdc_oc_source",
config:
// Connector 클래스명
"connector.class":"io.debezium.connector.mysql.MySqlConnector",
//최대 task의 수. Connector별로 반드시 1
"tasks.max": "1",
// DB 접속 정보
"database.hostname": "192.168.56.101",
"database.port": "3306",
"database.user": "connect_dev",
"database.password": "connect_dev",
"database.allowPublicKeyRetrieval": "true",
// MySQL 접속시 Connector가 가지는 고유 ID.
// 여러 개의 CDC Connector들은 반드시 고유한 ID를 가져야 함.
"database.server.id": "10000",
//MySQL 접속시 Connector가 가지는 명칭.
//해당 값으로 접두어를 가지는 카프카 토픽명이 생성됨
"database.server.name": “mysql01",
// 데이터를 추출할 DB들. 설정하지 않으면 모든 DB의 정보를 추출
// 여러 개의 DB들을 설정할 때는 콤마로 분리
"database.include.list": "oc",
// 데이터를 추출할 테이블들. 설정하지 않으면
// database.include.list에 있는 DB들의 모든 테이블을 추출
“table.include.list": "oc.customers, oc.orders",
// Connector가 새로운 이벤트 발생을 대기하는 시간. 기본은 1초
“poll.interval.ms”: "1000",
// Source 테이블에 DDL 변경 시 정보를 토픽에 저장 여부. 기본은 true
“include.schema.changes”: “true”,
// DDL 및 DB 변경 정보를 저장할 브로커와 토픽명
// 2.0에서 이름이 변경됨
"database.history.kafka.bootstrap.servers": "192.168.56.101:9092",
"database.history.kafka.topic": "schema-changes.mysql.oc",
// Key와 Value Converter 클래스명
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
// Delete event 발생 시 tombstone event 발생 여부. 기본은 true
// Sink 쪽에서 Delete 수행하기 위해서 반드시 true로 설정되어야 함
“tombstones.on.delete”: “true”,
// After message만 생성하기 위한 SMT 적용
"transforms": "unwrap",
// After message 생성용 SMT 클래스
"transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState",
// After Message 생성 시 tombstone 메시지의 경우 삭제 여부
// Sink쪽에서 Delete 수행하기 위해서 반드시 false가 되어야 함
"transforms.unwrap.drop.tombstones": "false“
// Debezium의 time관련 precisio은 Kafka Connect 지원 기본 레벨로 변경 Micro seconds 단위를 milli seconds 단위로 변환.
// 기본은 adaptive_time_microseconds
“time.precision.mode”: “connect”,
// Timestamp with timezone 컬럼에 대해서 UTC 변환 참조 설정.
"database.connectionTimeZone": "Asia/Seoul”,
