JDBC Sink Connector
-
카프카 토픽에서 메시지를 읽어들여서 타겟 DB로 데이터 입력/수정/삭제를 수행
-
Connect의 Consumer가 주기적으로 카프카 토픽 메시지를 읽어서 타겟 DB로 데이터 연동Consumer DBMS 접속 및 DBMS 데이터 입력/수정/삭제
-
RDBMS에서 데이터 추출은 JDBC Source Connector, CDC Source Connector등을 사용하지만 RDBMS로 데이터 입력은 주로 JDBC Sink Connector를 사용
JDBC Sink Connector 설정
// Connector 명
"name": "mysql_jdbc_sink_01",
"config" :
// Connector 클래스명
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
// 최대 task의 수
"tasks.max": "1",
// 토픽명. 만약 기존에 없는 토픽이면 새롭게 생성
"topics": "mysql_jdbc_customers",
// DB 접속 정보
"connection.url": "jdbc:mysql://localhost:3306/om_sink",
"connection.user": "connect_dev",
"connection.password": "connect_dev",
// DB Table데이터 입력 모드. upsert는 update/insert 모두 가능.
//insert는 insert만 가능 Upsert시에는 pk.mode와 pk.fields가 명확하게 명시되어 있어야 함.
"insert.mode": "upsert",
// Table의 PK가 Topic 메시지의 key값에 있음. record_value는 PK가 메시지의 value값
"pk.mode": "record_key",
// Topic 메시지의 PK 컬럼명
"pk.fields": "customer_id",
// Value값이 Null인 Key에 대응되는 PK를 가지는 데이터를 삭제할지 여부 true로 설정 시 pk.mode는 record_key가 되어야 함.
"delete.enabled": "true",
// 입력 테이블명. 없으면 Topic 명으로 자동 생성
"table.name.format": "om_sink.customers_sink",
// 입력 테이블명이 없으면 DB에 자동 생성. True는 권장되지 않음
"auto.create": "true",
// 소스 테이블의 컬럼 변경 사항을 타겟 테이블에 자동으로 반영할 지 여부
“auto.evolve”: “true”,
// Key와 Value의 Converter 유형
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
JDBC Sink Connector 다운로드
아래의 링크에서 10.6.0 버전을 선택하였음.
jdbc 는 source , sink connector가 한 모듈에 같이 들어있음.
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
DB 셋팅
일단 생성을 위해서 db 환경설정을 해주자..
create database oc_sink;
grant all privileges on oc_sink.* to 'connect_dev'@'%' with grant option;
CREATE TABLE customers_sink (
customer_id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
email_address varchar(255) NOT NULL,
full_name varchar(255) NOT NULL,
system_upd timestamp NOT NULL
) ENGINE=InnoDB ;
# update용 system_upd 컬럼에 인덱스 생성.
create index idx_customers_sink_001 on customers_sink(system_upd);
CREATE TABLE products_sink (
product_id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
product_name varchar(100) NULL,
product_category varchar(200) NULL,
unit_price decimal(10, 0) NULL,
system_upd timestamp NOT NULL
) ENGINE=InnoDB ;
# update용 system_upd 컬럼에 인덱스 생성.
create index idx_products_sink_001 on products_sink(system_upd);
CREATE TABLE orders_sink (
order_id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_datetime timestamp NOT NULL,
customer_id int NOT NULL,
order_status varchar(10) NOT NULL,
store_id int NOT NULL,
system_upd timestamp NOT NULL
) ENGINE=InnoDB ;
# update용 system_upd 컬럼에 인덱스 생성.
create index idx_orders_sink_001 on orders_sink(system_upd);
CREATE TABLE order_items_sink (
order_id int NOT NULL,
line_item_id int NOT NULL,
product_id int NOT NULL,
unit_price decimal(10, 2) NOT NULL,
quantity int NOT NULL,
system_upd timestamp NOT NULL,
primary key (order_id, line_item_id)
) ENGINE=InnoDB;
# update용 system_upd 컬럼에 인덱스 생성.
create index idx_order_items_sink_001 on order_items_sink(system_upd);
select * from customers_sink;
select * from products_sink;
select * from orders_sink;
select * from order_items_sink;
db 설정이 끝낫다면..
일단 JDBC Sink Connector Plug in을 넣어주자..
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
다만 여기서 받은 모듈에 jdbc connector 가 mysql 버전이 빠져있다.
https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.29
여기서 jar 파일 같이 받아서 kafka container 내부로 옮겨주자.
다 옮겼다면
압축을 풀어주고 나온 폴더 lib 하위에 있는 모든 jar파일을
내 plugin 디렉토리로 넣어주자. 다른 게시글에서와 똑같은 작업이기 때문에 참고 스크린샷은 넣지 않겠음.
다 넣어주고 connect 재기동 하면..

플러그인이 잘 올라간 모습..
JDBC Sink Connector 생성
config
해당 디렉토리에 config 설정을 넣어주고 궁금한 파라미터는 위를 보면서 매칭해보자. 이 설정에는 고의로 table.name.format 값에 없는 테이블을 주고 auto.create를 true 로 해놓은 다음 결과를 테스트 할 것이다.
{
"name": "mysql_jdbc_sink_customers_00",
"config": {
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "mysql_jdbc_customers",
"connection.url": "jdbc:mysql://my-mysql:3306/om_sink",
"connection.user": "connect_dev",
"connection.password": "connect_dev",
"insert.mode": "upsert",
"pk.mode": "record_key",
"pk.fields": "customer_id",
"delete.enabled": "true",
"table.name.format": "om_sink.customers_sink_base",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"auto.create": "true"
}
}
// 커넥터 등록
http POST http://localhost:8083/connectors @mysql_jdbc_sink_customers_00.json
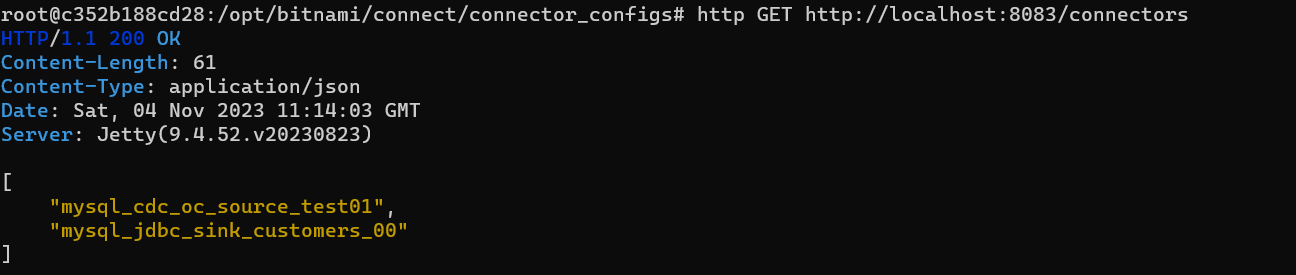
잘 올라간 모습
JDBC Sink Connector의 Update 로직
-
Insert into customers values (1, ‘test_name’)
-
update customers set full_name='updated_name',
system_upd=now() where customer_id=1; -
DB의 Update도 Kafka 메시지 Event로 발생
-
Sink Connector는 Target 테이블의 해당 PK로 기존 레코드
가 있으면 Update 적용
JDBC Sink Connector의 Delete 로직
-
Insert into customers values (1, ‘test_name’)
-
Delete from customers where customer_id = 1
-
Delete KAFKA 메시지 Event로 발생(Key값은 PK값으로 Value는 Null 값으로 생성)
-
Sink Connector는 Target 테이블의 Key값은 있지만 Value가 Null인 메시지를 처리 시 해당 PK로 기존 레코드가 있으면
Delete 적용
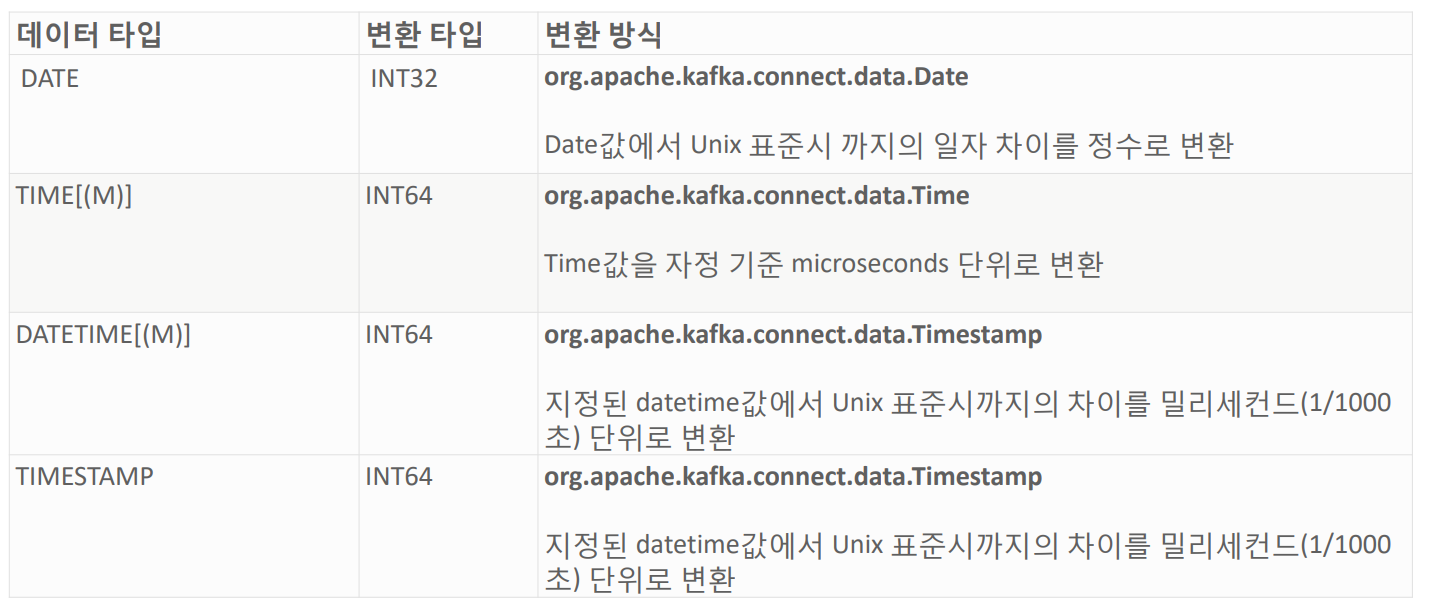
JDBC Source Connector MySQL 날짜/시간관련 데이터 변환