
Debezium Snapshot
- Debezium MySQL Connector가 최초 생성시 DB 스키마와 읽어들어야 할 테이블 데이터에 대한 초기 스냅샷 수행
Snapshot 모드
-
initial : Binlog Position, Schema, 테이블의 초기 레코드를 카프카로 저장하는 작업 수행
-
schema_only: 테이블의 초기 레코드를 카프카로 저장하지 않고 스키마 변경 정보만 기록
Snapshot 모드 - Initial Snapshot
Connector 최초 생성 시 수행 프로세스
-
My SQL DB에 Global read lock을 획득. 다른 client 들이 테이블
에 writer 하지 못함. -
현재 binlog의 position을 읽음.
-
Connector가 읽어들일 테이블들의 스키마 정보를 가져옴.
-
Global read lock 해제(다른 client들이 테이블 write가능)하고
DDL 변경 사항을 Schema change Topic에 기록. -
Connector가 대상 테이블들의 기존 레코드를 Topic에 전송
-
Topic에 기록된 레코드 offset을 connect-offset 토픽에 기록
-
Connector가 Global read lock 획득 권한이 없으면
Table Lock을 획득함. 이 경우 대상 테이블에 snapshot
이 완료될 때까지 write를 할 수 없음.
오래된 binlog Purge시 Connector 기동 이슈
-
Connector는 자신이 읽어서 Kafka로 보낸 offset 정보를 binlog명과 binlog position으로 connect-offsets 토픽이 기록
-
만약 오랫동안 Connector를 기동하지 않는다면, binlog가 mysql expire log 기간 이상 저장되어 있을 경우 삭제될 수 있음. 이때 Connector는 connect-offsets에 기록된 binlog를 binlog 디렉토리에서 찾지 못해서 기동을 할 수 없음.
-
이 경우 새롭게 Connector를 생성하거나 connect-offsets의 offsets를 재 설정 필요. 또한 오랫동안 정
지할 Connector는 미리 삭제하는 것이 좋음
Numeric과 Decimal Data Type
-
Precision과 scale 값을 가지는 숫자 Data Type
-
MySQL은 Numeric과 Decimal이 서로 동일하게 구현
-
Decimal(7, 3) 이면 9999.999 형태로 DB 저장
-
Decimal(10, 0) 일 때 값을 100.1로 입력해도 100으로 저장됨
-
Decimal(10)이면 precisio이 10, scale이 0 임
-Decimal(또는 numeric)과 같이 precision과 scale을 설정하지 않으면 기본적으로 precision이 10, scale 이 0임.
MySQL date, time, datetime타입 Debezium 변환
-
Debezium Source Connector는 date/time/datetime 변환 모드를 설정할 수 있는 time.precision.mode 파라미터를 제공
-
time.precision.mode의 기본 값은 adaptive_time_microseconds 로 Debezium 내부 변환 타입을 가짐.
-
time.precision.mode=connect는 Connect의 기본 변환 타입을 가짐.
-
adaptive_time_microseconds 또는 connect 설정 시 date/time/datetime 변환 값은 서로 대동 소이함.
-
adaptive_time_microseconds 설정 시에는 Debezium 변환 클래스를 JDBC Sink Connector가 인지하지 못해서 JDBC Sink Connector에서 오류 발생.
-
또한 JDBC Sink Connector는 datetime의 경우 millisecond 단위로 unix epoch time을 변환. Microsecond 단위로 변환된 unix epoch time은 타겟 DB입력 시 오류 발생.
-
떄문에 date/time/datetime 변환을 위해서는 Debezium Source connector에서 time.precision.mode=connect 로 반드시
설정해야 함.
변환 config
source
{
"name": "mysql_cdc_oc_source_datetime_tab_02",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "my-mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "1234",
"database.allowPublicKeyRetrieval": "true",
"database.server.id": "10021",
"database.server.name": "dm_date_02",
"database.include.list": "dm",
"table.include.list": "dm.orders_datetime_tab",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.mysql.dm_date2",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"time.precision.mode": "connect",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}
sink
{
"name": "mysql_jdbc_oc_sink_datetime_tab_02",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "dm_date_02.dm.orders_datetime_tab",
"connection.url": "jdbc:mysql://my-mysql:3306/dm_sink",
"connection.user": "root",
"connection.password": "1234",
"table.name.format": "dm_sink.orders_datetime_tab_sink",
"insert.mode": "upsert",
"pk.fields": "order_id",
"pk.mode": "record_key",
"delete.enabled": "true",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
}
}
이렇게 해주면 정상 변환 완료..
MySQL DATETIME과 TIMESTAMP
-
datetime는 timezone 정보를 가지지 않지만, timestamp는 timezone 정보를 가짐
-
DB는 기본 timezone 선정 필요.
-
Datetime은 클라이언트에서 입력한 값 자체로 DB에 저장되지만, timestamp는 클라이언트 입력값이 UTC로 변환되어 DB에 저장. DB에 저장된 값을 클라이언트에서 출력할 때는 datetime은 DB에 저장된 값을 그대로 출력하지만, timestamp는 DB 저장값을 DB의 timezone 설정에 따라 변환한 뒤 출력
config
source
{
"name": "mysql_cdc_oc_source_datetime_tab_02",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "my-mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "1234",
"database.allowPublicKeyRetrieval": "true",
"database.server.id": "10021",
"database.server.name": "dm_date_02",
"database.include.list": "dm",
"table.include.list": "dm.orders_datetime_tab",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.mysql.dm_date2",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"time.precision.mode": "connect",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}sink
{
"name": "mysql_jdbc_oc_sink_datetime_tab_02",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "dm_date_02.dm.orders_datetime_tab",
"connection.url": "jdbc:mysql://my-mysql:3306/dm_sink",
"connection.user": "root",
"connection.password": "1234",
"table.name.format": "dm_sink.orders_datetime_tab_sink",
"insert.mode": "upsert",
"pk.fields": "order_id",
"pk.mode": "record_key",
"delete.enabled": "true",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
}
}다량의 데이터 테스트
간단한 프로시저를 작성해서 10,000건 정도 insert를 해보고 sync가 잘 맞나 테스트 해보자..
DELIMITER $$
CREATE PROCEDURE InsertRecords5(
IN repeat_cnt INT
)
BEGIN
DECLARE iter_idx INT DEFAULT 1;
WHILE iter_idx <= repeat_cnt DO
INSERT INTO dmtest VALUES (iter_idx, 'test', 'test');
SET iter_idx = iter_idx + 1;
END WHILE;
END$$
DELIMITER ;위는 간단하게 10000건 insert하는 프로시저이다..
조금 오래걸리긴 하지만..

source db

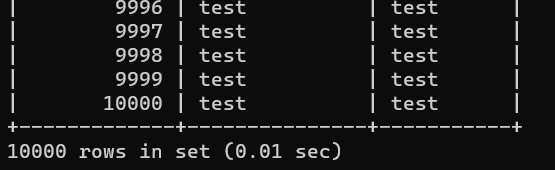
sink db

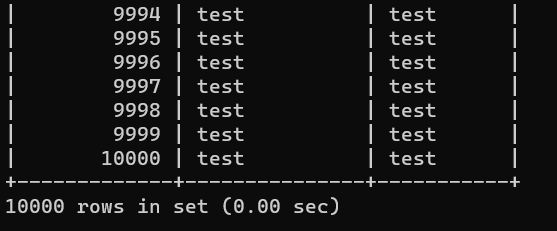
10,000 건이 알맞게 들어갔다. update랑 delete 도 테스트 해보니 정상적으로 작동하였다.
