
스키마 레지스트리(Schema Registry)
Converter 지원 포맷
• Json
• Avro
• Protobuf
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "customer_id"
},
{
"type": "string",
"optional": false,
"field": "email_address"
},
{
"type": "string",
"optional": false,
"field": "full_name"
}
],
"optional": false,
"name": "mysql02.oc.customers.Value"
},
"payload": {
"customer_id": 864,
"email_address": "testuser_864",
"full_name": "testuser_864"
}
}-
Json/Avro 포맷의 경우 schema와 payload로 구성
-
Schema는 해당 레코드의 schema 구성을, payload는 해당 레코드의 값을 가짐.
-
Connector 별로 Json 포맷은 조금씩 다를수 있지만 전반적으로 대부분 비슷
-
Json Schema의 경우 레코드 별로 Schema를 가지고 있으므로 메시지 용량이 커짐. 이의 개선을 위해 Avro Format과 Schema Registry를 이용하여 Schema 정보의 중복 생성 제거
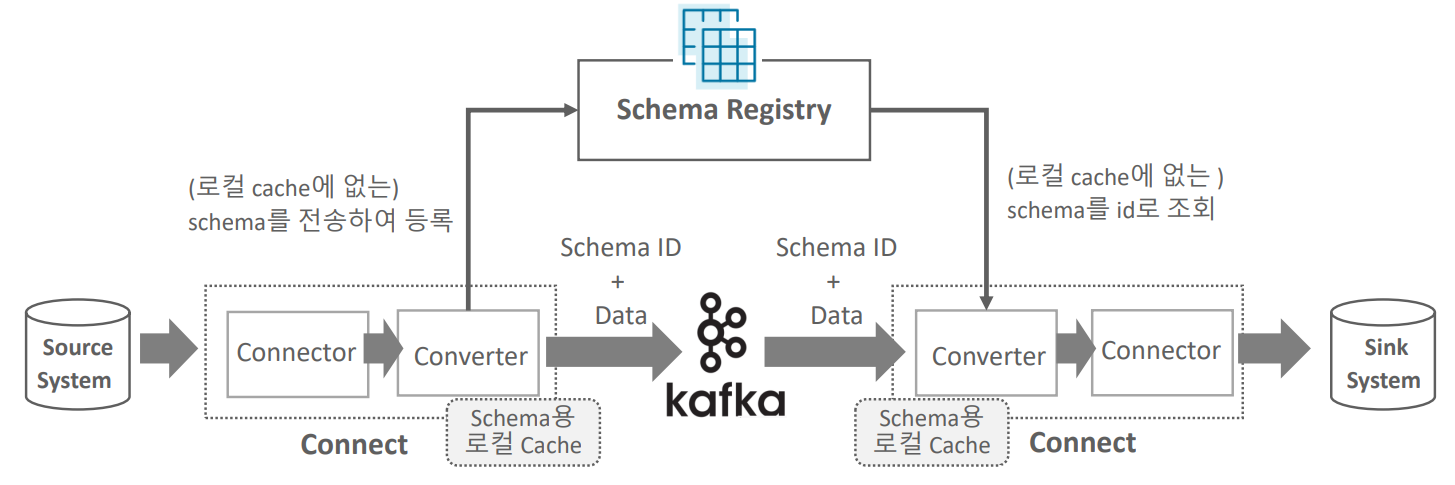
Schema Registry 란
-
Confluent Kafka는 Schema Registry를 통해 Schema 정보를 별도로 관리하는 기능 제공
-
토픽으로 전송되는 Data의 Schema는 Schema Registry에서 ID + Version 별로 중앙 관리되므로 레코드 별로 Schema를 중복해서 전송할 필요가 없음.
AVRO 란
-
데이터 직렬화를 수행하는 시스템
- 보다 컴팩트하고 빠른 binary 데이터 포맷 제공
-
스키마를 제공
-
Json 포맷으로 쉽게 스키마 메시지를 정의
-
다양한 데이터 타입을 제공(String, bytes, int, long, float, double, boolean 뿐만 아니라 enum, arrays, maps등의
보다 복잡한 데이터 타입도 지원) -
하지만 기본적으로 하나의 메시지마다 별도의 스키마를 가지고 있는 구조임.
-
메시지를 자바 객체로 쉽게 만들어 줄 수 있음

Web Developer