
개요
먼저 우리의 서비스에는 RDB 와 key-value db 에 동시에 적재를 해야 하는 로직이
이 전에 포스팅 했던 걸 토대로..
현재 우리 프로젝트의 문제점이였던 다수의 서버에 대한 데이터 일관성을 잡아줄 수 있는 방법이 필요하였다.
방법이야 많겠지만.. 몇가지 대안을 떠올린 것은
Saga 분산 트랜잭션 패턴
설명이 너무 잘 나와있어서 아래의 링크를 참고하자.
https://learn.microsoft.com/ko-kr/azure/architecture/reference-architectures/saga/saga
2PC (Two-Phase Commit) 패턴
2PC는 분산 트랜잭션 프로토콜로서 트랜잭션의 일관성을 유지하기 위한 방법 중 하나입니다. 이 패턴은 두 단계로 나뉘어 진행됩니다. 첫 번째 단계에서는 참여자들에게 트랜잭션을 준비하라는 메시지를 보내고, 두 번째 단계에서는 모든 참여자에게 트랜잭션을 커밋하라는 메시지를 보내어 트랜잭션을 완료합니다.
Kafka-Connect ( 채택 )
여러가지의 MSA 패턴으로 데이터일관성을 잡으려는 노력도 물론 필요하다. 하지만 먼저 해보고 싶었던 건, kafka-connect를 보고싶었고, 이걸로 구현을 한 뒤, 나머지 일관성에 대한 로직은 위의 패턴들로 구성을 해보려고한다.
그림으로 보는 아키텍처
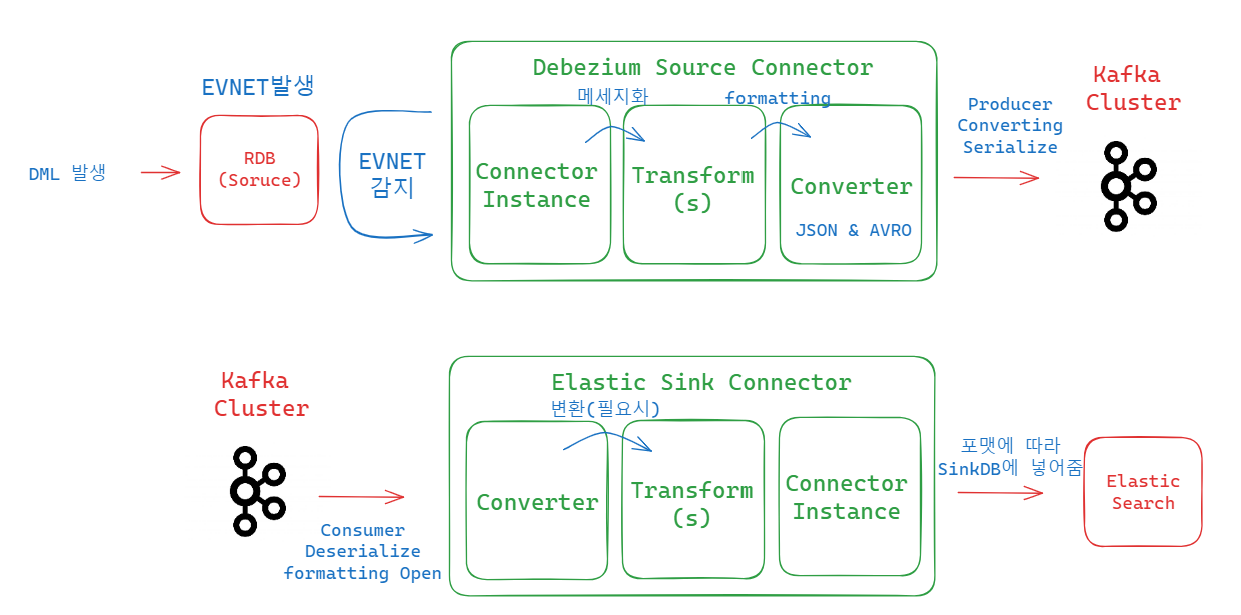
-
mysql 에서 DML 발생 시, readlog와 binlog 를 기반으로 캡처를 하여 변경점을 감지한 뒤
-
캡쳐하여 포맷팅 한 후 sink connector 쪽으로 data를 넘겨주고
-
sink connector 쪽에서 SMT로 원하는 포맷을 진행하고 target DB에 적재시킨다.
docker 구성
version: "3.8"
services:
zookeeper:
image: bitnami/zookeeper:latest
networks:
- docker_kafka-net
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
networks:
- docker_kafka-net
ports:
- '9093:9093'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
volumes:
- "C:\\kafka_set:/volumes"
depends_on:
- zookeeper
networks:
docker_kafka-net:
external:
name: docker_kafka-net위의 docker-compose 를 사용하였다.
또한 mysql도 설치하고 같은 네트워크에 묶어주었음.
docker-compose -f docker-compose-kafka-last.yml up -d
기동해주고.. volumes을 local pc 환경에 연결해놨기 때문에
폴더에 connector 관련된 모듈들을 전부 다 넣어놓은 상태이다.
필요한 모듈들을 전부 script로 만들어놓았다.

kafka가 기동이 되면 container 내부 안으로 들어가서..
만들어놓은 쉘파일들을 기동하여 환경 셋팅해주고..
connect기동하고.. connector들을 올리자..
config
debezium
{
"name": "mysql_cdc_source_connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "my-mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "1234",
"database.allowPublicKeyRetrieval": "true",
"database.server.id": "12000",
"database.server.name": "sink",
"database.include.list": "community",
"table.include.list": "community.communities",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.mysql.sink",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"time.precision.mode": "connect",
"database.connectionTimeZone": "Asia/Seoul"
}
}es
{
"name": "es_sink_connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "sink.community.communities",
"key.ignore": "false",
"connection.url": "http://elasticsearch:9200",
"type.name": "kafka-connect",
"name": "es_sink_connector",
"schema.ignore": "true",
"write.method": "upsert",
"behavior.on.null.values": "delete",
"transforms": "extractKey,unwrap",
"transforms.extractKey.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractKey.field":"id",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}결과
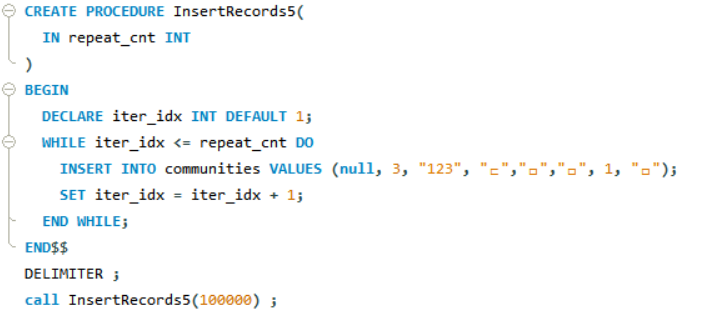
DELIMITER $$
CREATE PROCEDURE InsertRecords5(
IN repeat_cnt INT
)
BEGIN
DECLARE iter_idx INT DEFAULT 1;
WHILE iter_idx <= repeat_cnt DO
INSERT INTO dmtest VALUES (iter_idx, 'test', 'test');
SET iter_idx = iter_idx + 1;
END WHILE;
END$$
DELIMITER ;
call InsertRecords5(100000)해당 프로시저를 테이블에 맞게 설계하여 100,000 건을 insert와 update, delete를 해보았다.
mysql 10만건
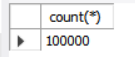
es 10만건

delete

mysql 10만건 삭제
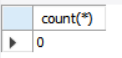
es 10만건 삭제
위 처럼 트랜잭션이 보장되는 현상을 볼 수 있다.
문답
Q. mysql 에 겹치는 pk 가 있을 경우 ?
-> 애초에 insert가 안됨.
Q. es 에 겹치는 pk 가 있을 경우 ?
-> "write.method": "upsert", 옵션에 의하여 해당 데이터가 없으면 추가되고 있으면 변경 됨.
Q. 한번의 flow에서 mysql엔 A라는 데이터를 넣고싶고 es엔 B라는
데이터를 넣고싶을 때
-> SMT 로 형식변환하면 어느정도 까진 가능한데 조금 까다롭다.
Q. source connector 자체가 주기적으로 query를 보내서 변경점을 파악하는거니까 db 성능 이슈가 생길 수 있지 않아 ?
-> 그런 방식의 source connector도 있지만, debezium source connector는 query 를 일정주기로 가져오는 것 이 아니라, 데이터베이스 내부의 로그 변경 사항을 실시간으로 캡처한다. 이 방식을 통해 변경 사항이 발생한 즉시 Kafka 토픽으로 데이터가 전송된다.
결론 = log 기반이기 때문에 query를 보내지않아서 db 성능에 큰 이슈없음.
Q. source connector 를 기동할 때 이슈는 ?
-> source connector 를 기동할 때 순간적으로 해당 DB에 global lock을 획득하게 된다. 따라서 이 때 순간적으로 데이터 유실이 발생할 수 있기 때문에 트래픽이 없는 시간에 하던지 아니면 클러스터를 구성하던지 몇몇개의 대안이 있다.
Q. 서로 주고 받는 메시지 형식이 너무 길던데 문제없어?
-> 스키마 형식이 문제가 생길 수 있다. 크기도 하고, 물론 SMT 를 사용하여 변환할 수 있지만, 그 마저도 제한과 한계가 있다.
그 메시지의 양을 줄이고 , source와 sink 사이에서 타입 이슈를 쉽게 해결하기 위해 Avro 를 도입하여도 좋은 방법이다.
connect 추가 의문
여러가지 상황이 있을 것 같아서 의문과 답이 생길 때 마다 추가로 포스팅 할 것이다.
첫번째 시나리오
-
count 를 2씩 누적으로 10000번 업데이트 하는 프로시저가 있다.
-
대략 5000번 실행되고 있을 때 다른 세션에서 해당 count 를 1 업데이트한다.
-
그럼 끝나고 난 후의 count는 홀수일까 짝수일까 ?
Q. 프로시저는 끊기지 않고 10000번이 다 실행될 것 인가 ?
Q. mysql과 es에 정확한 값이 들어갈 것 인가 ?
Q. 프로시저는 끊기지 않고 10000번이 다 실행될 것 인가 ?
