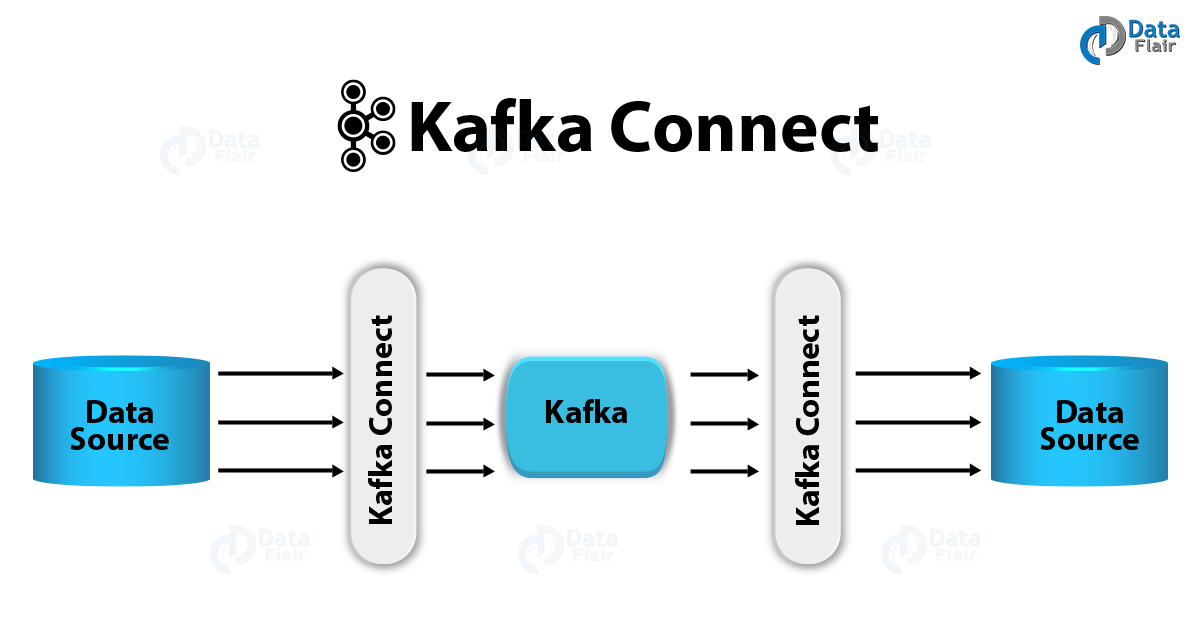
카프카 Connect
카프카 Connect는 Kafka 메시지 시스템(Broker/Producer/Consumer)를 기반으로 다양한 데이터 소스 시스템(예:RDBMS)에서 발생한 데이터 이벤트를 다른 데이터 타겟으로 전달하기 위해서 만들어진 Kafka Component
예시를 들어보자
-
RDBMS 에서 어떤 데이터가 INSERT 가 되었음
-
위 작업에 대한 내용으로 EVENT 가 발생하고 Kafka Connect 에서 읽어온다.
-
Kafka Connect 가 data를 formatting 한 후 Kafka로 전송
-
kafka 로 전송된 data가 다시 Connect에서 파싱이 되고
-
파싱된 데이터가 이전에 INSERT와 같은 형태로 target DB에 저장이 됨
-
INSERT,UPDATE,DELETE 와 같은 데이터는 전부 target DB 쪽에 동기화, 연동이 가능함
kafka core에서 구현이 가능은 한데 왜 connect?
-
별도의 kafka client 코딩이 필요없음 ( 직렬화, 역직렬화 , JDBC 코드 등 )
-
Connecter 와 Config 만 지정해주면 됨..
이전엔 kafka connect 같은 시스템이 없었을까 ?
EAI
-
EAI Solution 들을 쓰긴 했었음. 하지만 가격이 비쌈, 심지어 플러그인도 비쌈
-
대용량 데이터 연계가 쉽지 않음
-
그래서 CDC 가 나왔는데 EAI랑 결이 다르긴 함
CDC
-
CDC 는 RDBMS만 가능함. CDC는 원래는 동기종 특성을 가지고 있다. mysql -> mysql 또는 oracle -> oracle
-
지금은 이기종도 가능함. 하지만 중요한 건 RDBMS -> RDBMS 인데
-
지금은 다른것도 가능은 함
-
RDBMS에 redo log과 bin log 에 모든 dml이 들어가는데 이걸 이용해서 빠르게 보내버림.
카프카 Connect 의 다양한 활용
-
Data Pipeline 이 가능함
- producer 에서 보낸 data를 kafka 가 받을 수 있게 처리를 하고 또 consumer가 받을 수 있게 처리를 해줄 수 있는 파이프 라인 구성가능
-
DW ETL 활용 가능 (난 처음들어보긴 하는데 나중에 더 찾아보자)
-
MSA 에서도 각기 다른 DB의 sync를 맞춰줄수 있음
-
DB OFF loading ( 운영계 DB에서 부하가 걸리고 자주 쓰는 쿼리는 DB를 따로빼서 그쪽으로 붙게 관리) 도 활용 가능
카프카 Connect 의 주요 구성 요소
Connector
• Jdbc source/sink Connector
• debezium CDC source Connector (CDC 기반)
• Elasticsearch sink connector
• File Connector
• MongoDB source/sink Connector
Transformation
- SMT(Single MessageTransformation)
Convertor
일반적으로 producer 에서 broker, consumer 에 보내는 메시지는 직렬화 , 역직렬화를 사용한다.
하지만 Connector 에서 보내는 메세지는 fomatting 이 필요함
대표적으로 아래의 2개를 사용함
-
JsonConverter
-
AvroConverter
예를들어
RDBMS(soruce db) 에서 record 나 class 를 sinkDB 에 보내는데 record나 class만 가지고는 sinkDB 쪽에 저장을 할 수 없음.
JDBC 코드로도 바뀌어야하고, 다른 메타성 정보들을 JSON & Avro 컨버터로 할것인지를 정해야 함.
이걸 Config 에서 컨트롤 가능하다.
Config
그림으로 보는 Kafka Connect 흐름
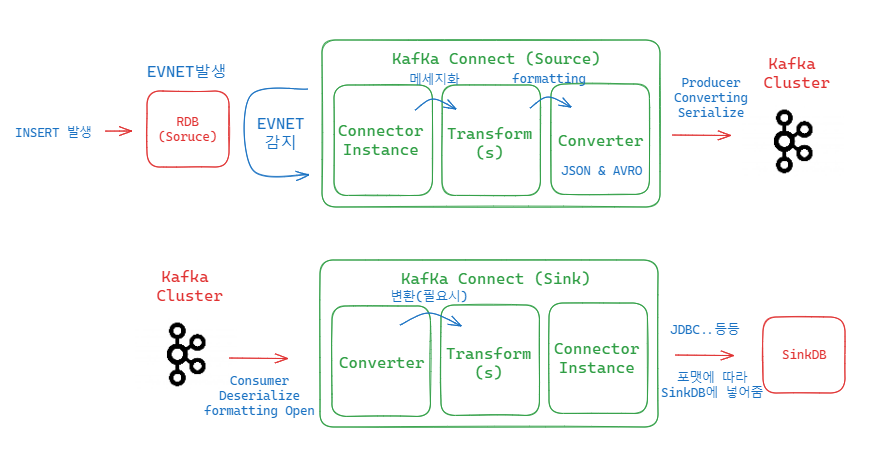
source 쪽
-
Source 쪽 RDB 에서 INSERT 가 되면서 EVENT 발생
-
Source 쪽 Connector Instance에선 EVNET를 감지하고 있음. 그리고 감지함
-
Converter에 넘기기 전 메세지화를 시키고 필요시 다른 변환도 Transform에서 가능
-
Converter는 받은 메시지의 포맷을 JSON 으로 할건지 Abro 로 할건지 정하고 kafka 로 넘겨줌 (broker)
sink 쪽
-
consumer 가 역직렬화를 하고, source 쪽 converter 에서 정한 formatting을 열어봄.
-
다른 변환이 필요한게 있다면 실행시켜줄 수 있음
-
Connector Instance 에서 SinkDB 에 넣어주기 위한 각종 Instance가 있고 아까 정해놓은 포맷에 따라 JDBC 등등을 이용 해 SinkDB에 저장함
Connect Cluster 아키텍처
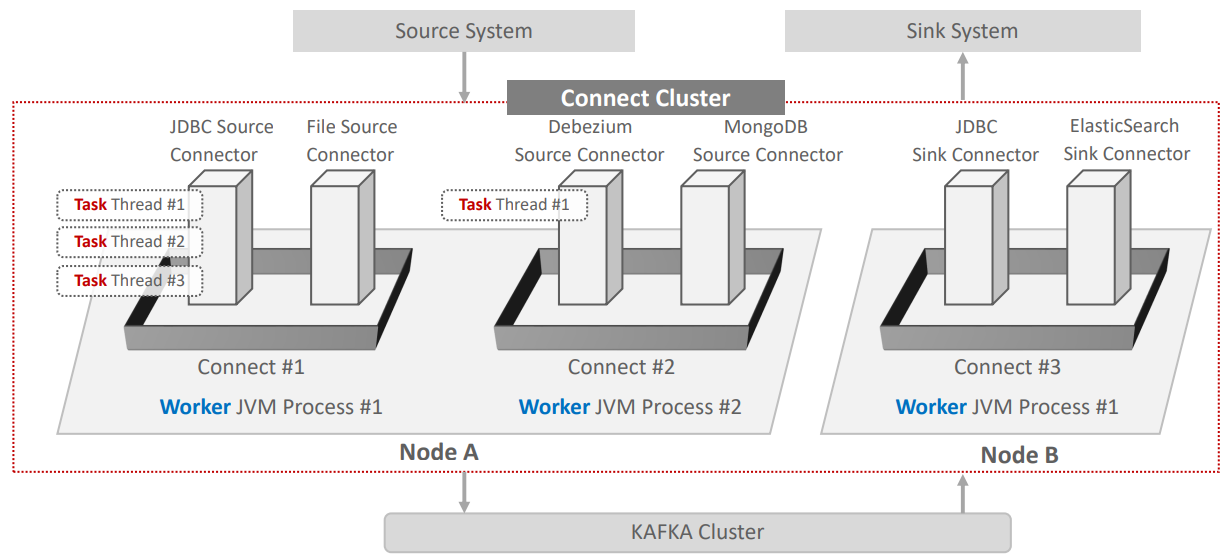
-
여러가지 커넥터가 하나의 group 로 묶을 수 있고, group Id 지정가능
-
connect 를 기동하는 명령어(connect Distributed)를 기동하면 Connect 가 올라옴
-
올라오면 JVM Process 가 하나 올라오고 메모리 잡음
-
이를 Worker 라고 부름
-
쉽게 말하면 Connect 하나 띄운다 -> Worker Process를 하나 만든다
-
Connector Instance의 실제 수행은 Thread 레벨로 수행되며 이를 Task라고 함
-
Connect 유형은 Standalone과 Distributed mode로 나뉨. 단일 Worker Process로만 Connect Cluster 구성이 가능할 경우 Standalone mode, 여러 Worker Process들로 구성이 가능할 경우(포트는 다르게) Distributed mode임.
kafka connetc 기동
version: "3.8"
networks:
kafka-net:
driver: bridge
services:
zookeeper:
image: bitnami/zookeeper:latest
networks:
- kafka-net
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
networks:
- kafka-net
ports:
- '9093:9093'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper나는 현재 위와 같은 compose로 docker를 실행중이다..
docker ps -> kafka container id 확인
docker exec -it [kafka container id] /bin/bash
cd /opt/bitnami/kafka/bin
이렇게 가보면 많은 쉘 파일이 있다.
connect-distributed.sh
connect-distributed.sh 이걸 나중에 기동하면 되는데
얘를 까보면 .. 일단 java에 대한 환경설정들이랑 실행을 할때
connect-distributed.propertiese 를 가져오라고도 되어있고..
connect당 log4j를 조절한다.. 라는 내용도 있음
connect-distributed.propertiese 얘는 뭐길래 기동할때마다 가져올까 ?
/opt/bitnami/kafka/config 에 가서 열어보면 몇가지 중요한 설정이 있다.
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] connect-distributed.properties"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/connect-log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xms256M -Xmx2G"
fi
EXTRA_ARGS=${EXTRA_ARGS-'-name connectDistributed'}
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
exec $(dirname $0)/kafka-run-class.sh $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectDistributed "$@"
connect-distributed.propertiese
중요한 설정
-
bootstrap.servers=localhost:9092
-> kafka broker -
group.id=connect-cluster
-> 커넥트 클러스터들의 그룹아이디를 지정해주는 것 (컨슈머 그룹id랑 충돌하지 말아달라고 되어있음) -
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
-> default 로 connect 를 띄울때마다 어떤 converter 를 쓸건지 ? -
offset.storage.topic=connect-offsets
-
#listeners=HTTP://:8083
-> 기본이 8083으로 잡힘 -
#plugin.path=
-> connect를 기동할 때 connector 들이 어느 path 에 있어야하는지 ?
기동
/opt/bitnami/kafka/bin/connect-distributed.sh /opt/bitnami/kafka/config/connect-distributed.properties
하고 ps -ef | grep java 해보면 ps(Worker) 먹고 있음
간단히 jps로도 확인가능
여러개 키려면 포트 바꿔줘야힘..
Caused by: java.net.BindException: Address already in use
그대로 다시 켜보니 포트 충돌나서 에러남..
그래서
connect-distributed.properties 를 하나 copy 해서..
vi 로 열어서..
listeners=HTTP://localhost:8084 로 바꿈
그리고 켜봄..
jps 로 확인한 모습

일단 좀 쓰기 편하게 스크립트로 저장 해 놓자..
vi connect_start.sh
/opt/bitnami/kafka/bin/connect-distributed.sh /opt/bitnami/kafka/config/connect-distributed.properties
저장.
그리고 log를 보고싶은데 너무많아서 일단 에러 표준출력만 해주기 위해 아래 스크립트 추가..
mkdir connect_console_log
vi connect_start_log.sh
log_suffix=`date +"%Y%m%d%H%M%S"`
/opt/bitnami/kafka/bin/connect-distributed /opt/bitnami/kafka/config/connect-distributed.properties 2>&1 | tee -a /opt/bitnami/kafka/connect_console_log/connect_console_$log_suffix.log
log_suffix=`date +"%Y%m%d%H%M%S"`
/opt/bitnami/kafka/bin/connect-distributed.sh /opt/bitnami/kafka/config/connect-distributed.properties 2>&1 | tee -a ./connect_console_log/connect_console_$log_suffix.log
chmod +x connect*.sh
하고 ls connect_console_log/
connect_console_20231030162318.log
-> 에러 표준출력 으로 해줬음
Sink와 Source Connector 종류 예시
Source Connector
• JDBC (Source/Sink) Connector
• Debezium CDC Source Connector
• MySQL, Postgresql, Oracle, MongoDB등
• File System Source Connector
• MongoDB (Source/Sink) Connector
• S3 Source Connector
...
Sink Connector
• JDBC (Source/Sink) Connector
• Elasticsearch Sink Connector
• Snowflake Sink Connector
• Redshift Sink Connector
• Bigquery Sink Connector
• S3 Sink Connector
...
Connector 설치는 두가지 방법이 있다.
-
사용자가 직접 Connector의 plugin.path에 Connector plugin 설치
-
confluent-hub 명령어를 이용하여 설치
