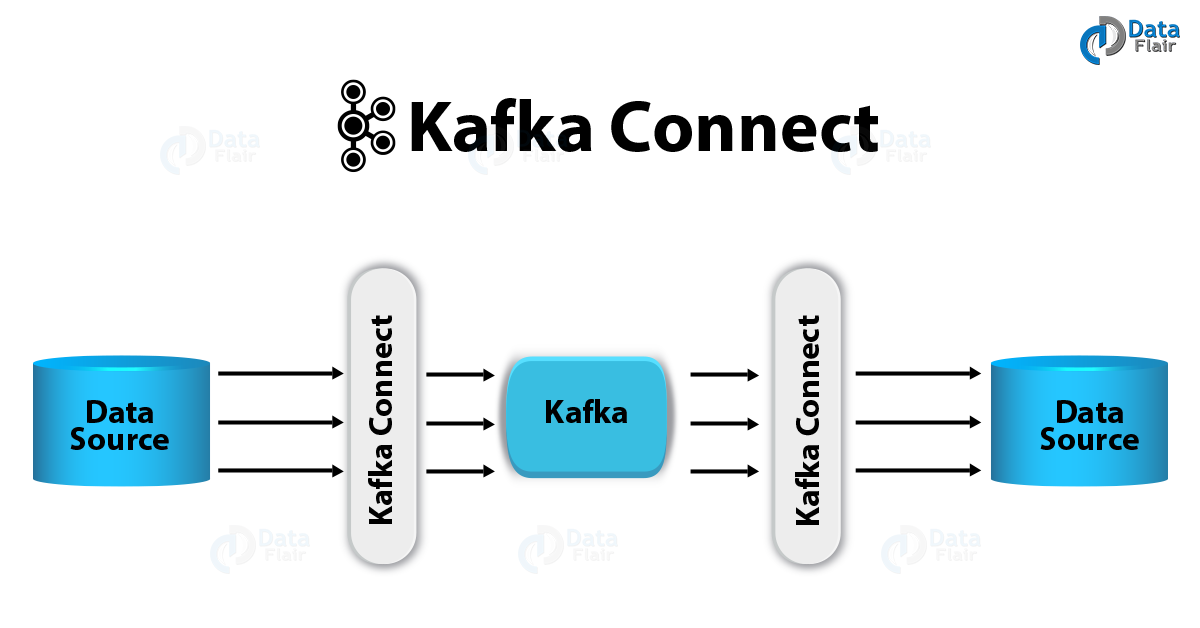
오늘은 source connector 중 하나인 Spooldir 에 대해 포스팅 해보도록 하겠다.
특정 디렉토리에 위치한 CSV, Json 포맷등의 파일들을 Event Message로 만들어서 Kafka로 전송하는 Source Connector
해당 디렉토리를 주기적으로 모니터링 수행하면서 새로운 파일이 생성될 때 마다 Kafka로 메시지 전송
다운로드
https://www.confluent.io/hub/jcustenborder/kafka-connect-spooldir
docs도 참고하자.. (완벽하진 않음)
https://docs.confluent.io/kafka-connectors/spooldir/current/overview.html
주의사항
-
Connector를 다운로드 받음. 하나의 Connector는 보통 여러 개의 jar library들로 구성됨
-
여러 개의 jar library로 구성된 하나의 Connector를 plugin.path로 지정된 디렉토리에 별도의 서브 디렉토리로 만들어
서 jar library들을 이동 시켜야 함. -
Kafka Connect는 기동시에 plugin.path로 지정된 디렉토리 밑의 서브 디렉토리들에 위치한 모든 jar 파일을 로딩함.
따라서 신규로 Connector를 Connect로 올릴 시에는 반드시 Connect를 재기동해야 반영됨 -
Connector는 Connector명, Connector 클래스명, Connector 고유의 환경 설정등을 REST API를 통해 Kafka Connect에 전
달하여 새롭게 생성 -
REST API에서 성공 Response(HTTP 201)이 반환되더라도 Kafka Connect Log 메시지를 반드시 확인하여 제대로
Connector가 동작하는지 확인 필요
컨테이너 내부에 다운로드
일단 난 docker 로 실행중이기 때문에 해당 bash로 접속한 후..
저번 포스팅에서 만들어줬던 쉘을 실행시키자...
./connect_start.shconnect_start.sh
/opt/bitnami/kafka/bin/connect-distributed.sh /opt/bitnami/kafka/config/connect-distributed.properties
일단 다운로드 받은 파일을 docker 내부 컨테이너로 복사해주자..
docker cp jcustenborder-kafka-connect-spooldir-2.0.65.zip 9e45e96cc41e:/opt/bitnami/kafka복사가 완료되었으면 압축을 풀어놓자..
apt-get install unzip
unzip jcustenborder-kafka-connect-spooldir-2.0.65.zip
압축 푼 경로에 lib 하위에 있는 jar들이 spooldir connector의 주요역할을 하게 된다. 사실 spooldir connector가 jar파일들의 집합체라고 볼 수 있는 것 이다.
셋팅
// 일단 두개의 경로 생성.. 용도는 이름 그대로..
mkdir connector_plugins
mkdir connector_configs
그리고 connect 를 기동할 때 참조하던 properties 로 가서 맨 밑에 plugin.path 를 내가 만든 디렉토리로 적어주자.

저장 후 connect 재기동 ->
그리고 압축 풀었던 경로인
jcustenborder-kafka-connect-spooldir-2.0.65/lib 안에 있는 jar 파일들을 맨 처음 만들었던 경로로 다 옮겨줘야 한다.
find jcustenborder-kafka-connect-spooldir-2.0.65/lib -type f -name "*.jar" | xargs
-I {} cp {} ./connector_plugins/난 위의 명령어를 사용하였다. 해당경로에서 .jar 로 끝나는 걸 전부 찾아서 복사하였음.
그런데 여기서 문제가 조금 있는게 내가 만들어준 해당 디렉토리로 바로 복사하면 안되고 그 디렉토리의 하위디렉토리를 하나 더 만들어서 그쪽에 넣어주어야한다.
그리고 또 다른 커넥터 사용시 또 다른 디렉토리를 추가하는식으로 늘려나가야 한다.
/opt/bitnami/kafka/connector_plugins# mkdir spooldir_soruce
cp *.jar ../../connector_plugins/spooldir_soruce/명령어에 익숙해지기 위해 위에선 장황하게 썻으나 여기선 그냥 간단하게 사용..
하지만 이 디렉토리에 jar파일을 모두 옮겨놓는다고 해서 자동적용이 되지 않는다 따라서.. 재기동..
플러그인이 제대로 적용된 모습이다.
Connector 생성 순서 및 유의사항
-
Connector를 다운로드 받음. 하나의 Connector는 보통 여러 개의 jar library들로 구성됨
-
여러 개의 jar library로 구성된 하나의 Connector를 plugin.path로 지정된 디렉토리에 별도의 서브 디렉토리로 만들어
서 jar library들을 이동 시켜야 함. -
Kafka Connect는 기동시에 plugin.path로 지정된 디렉토리 밑의 서브 디렉토리들에 위치한 모든 jar 파일을 로딩함.
따라서 신규로 Connector를 Connect로 올릴 시에는 반드시 Connect를 재기동해야 반영됨 -
Connector는 Connector명, Connector 클래스명, Connector 고유의 환경 설정등을 REST API를 통해 Kafka Connect에 전
달하여 새롭게 생성 -
REST API에서 성공 Response(HTTP 201)이 반환되더라도 Kafka Connect Log 메시지를 반드시 확인하여 제대로
Connector가 동작하는지 확인 필요
REST API 기반의 Connect 관리
• GET : 기동 중인 모든 Connector들의 리스트, 개별 Connector의 config와 현재 상태
• POST: Connector 생성 등록, 개별 Connector 재 기동.
• PUT: Connector 일시 정지 및 재 시작, Connector의 새로운 config 등록, Config validation
• DELETE: Connector 삭제
Connector 생성
일단 REST API 사용과 편하게 보기 위해 아래 두가지 모듈을 설치하자.
apt-get install curl
apt-get install jq설치했으니 GET 요청으로 connector의 리스트와 상태를 한번 보자.
curl -X GET -H "Content-Type: application/json" http://localhost:8083/connector-plugins
->
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirAvroSourceConnector",
"type": "source"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirBinaryFileSourceConnector",
"type": "source"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirLineDelimitedSourceConnector",
"type": "source"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirSchemaLessJsonSourceConnector",
"type": "source"
},
{
"class": "com.github.jcustenborder.kafka.connect.spooldir.elf.SpoolDirELFSourceConnector",
"type": "source"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
"type": "source",
"version": "3.6.0"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
"type": "source",
"version": "3.6.0"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"type": "source",
"version": "3.6.0"
}
Config 생성을 먼저 해주자
만들었던 디렉토리에 config 설정을 넣어주자
vi connector_configs/spooldir_source.json
{
"name": "csv_spooldir_source",
"config": {
"tasks.max": "3", -> task thread 의 최대 개수 (무조건 3개가 뜨는건 아님 최대 3개, 병렬 쓰레드를 지원하는 커넥터만 가능 )
"connector.class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector", -> 이런 클래스 이용.. 커넥트 마다 다름.. docs 찾아서 다 넣어줘야 함
"input.path": "/home/min/spool_test_dir",
"input.file.pattern": "^.*\\.csv", -> .csv 로 끝나는 건 전부..
"error.path": "/home/min/spool_test_dir/error",
"finished.path": "/home/min/spool_test_dir/finished",
"empty.poll.wait.ms": 30000,
"halt.on.error": "false",
"topic": "spooldir-test-topic", -> kafka topic.. 없으면 auto create
"csv.first.row.as.header": "true",
"schema.generation.enabled": "true"
}
}
일단 config에서 설정한 폴더들을 다 만들어주자..
그리고 test 할 csv 파일을 다운받자.
wget https://raw.githubusercontent.com/chulminkw/KafkaConnect/main/sample_data/csv-spooldir-source.csv -O csv-spooldir-source-01.csv
이후 spooldir_test_dir 로 .. cp..connect 를 기동하면 내부 토픽을 만들게 된다.
일단 내 컨테이너의 내부 토픽 경로..
cd /bitnami/kafka/data
그리고 connector 생성을 해보자..
나의 경우엔 docker 내부 컨테이너를 이용하는데 해당버전이 컨플루언터의 버전과 호환되지 않았다.
그래서 다른버전을 계속 시도해보다가 62버전이 호환이 되서 해당 버전으로 새롭게 해서 connector를 생성하였다.
// connector 생성..
curl -X POST -H "Content-Type: application/json" http://localhost:8083/connectors --data @spooldir_source.json
그리고 조회..
curl -X GET http://localhost:8083/connectors/csv_spooldir_source/status | jq '.'아까 max.thread 옵션을 3으로 준 결과
{
"name": "csv_spooldir_source",
"connector": {
"state": "RUNNING",
"worker_id": "172.20.0.3:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.20.0.3:8083"
},
{
"id": 1,
"state": "RUNNING",
"worker_id": "172.20.0.3:8083"
},
{
"id": 2,
"state": "RUNNING",
"worker_id": "172.20.0.3:8083"
}
],
"type": "source"
}정상적으로 잘 들어갔다면 토픽이 만들어졌을것이다.
내 토픽경로로 들어가보고..
한번 토픽의 내용 컨슈머 쪽에서 보자..
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic spooldir-test-topic
--from-beginning --property print.key=true우리의 csv 파일이랑은 조금 다르게..schema 라는 것이 추가 되어 있는 모습
{"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"id"},{"type":"string","optional":true,"field":"first_name"},{"type":"string","optional":true,"field":"last_name"},{"type":"string","optional":true,"field":"email"},{"type":"string","optional":true,"field":"gender"},{"type":"string","optional":true,"field":"ip_address"},{"type":"string","optional":true,"field":"last_login"},{"type":"string","optional":true,"field":"account_balance"},{"type":"string","optional":true,"field":"country"},{"type":"string","optional":true,"field":"favorite_color"}],"optional":false,"name":"com.github.jcustenborder.kafka.connect.model.Value"},"payload":{"id":"1","first_name":"Rubi","last_name":"McLleese","email":"rmclleese0@dailymail.co.uk","gender":"Female","ip_address":"12.218.17.190","last_login":"2017-12-22T10:37:27Z","account_balance":"16071.32","country":"PL","favorite_color":"#81eac9"}}data 가 convertor 를 거치면서 schema라는걸 만들어준다.
실제 value는 payload 에 있다.
그리고 spool_test_dir 에 있던 csv 파일은 작업이 완료되고 finished 디렉토리로 옮겨져있음.
Connect 에서 Connector 를 등록할 때의 프로세스
spooldir connector를 path 등록하고 아직 POST 로 올리기 전 상태..
-
POST 요청으로 config와 함께 생성
-
connect thread 생성
-
connect thread 가 POST요청이랑 같이 온 config 를 본다.
-
task 의 개수는 connector 가 멀티스레드를 지원할 경우에 늘어난다.
-
보통 connector class 를 구현할때 poll 메소드를 구현해놓는다.
-
connector는 producer를 생성,호출 까지는 하는데 data 를 넘겨주는 레벨 정도 이고..
-
실제로 producer에서 메세지 와 data가 가는건 connector framework에 있는 convertor 에서 작업을 하게된다.
task 3개가 돌고 있는지 확인해보자.
-
connect 기동
-
connector 가 실행중이어야 함.
jstack 4758(jps 로 확인) | grep task-thread
-> config 에서 task 3개 설정해서 3개 나오는 모습
"task-thread-csv_spooldir_source-2" #55 prio=5 os_prio=0 cpu=78.82ms elapsed=4196.10s tid=0x00007fd8d8010300 nid=0x1449 waiting on condition [0x00007fd97e4f3000]
"task-thread-csv_spooldir_source-1" #56 prio=5 os_prio=0 cpu=323.84ms elapsed=4196.10s tid=0x00007fd92800e860 nid=0x144a waiting on condition [0x00007fd97e3f2000]
"task-thread-csv_spooldir_source-0" #57 prio=5 os_prio=0 cpu=92.05ms elapsed=4196.10s tid=0x00007fd920015db0 nid=0x144b waiting on condition [0x00007fd97e2f1000]
Spool Dir Source Connector의 주요 파라미터
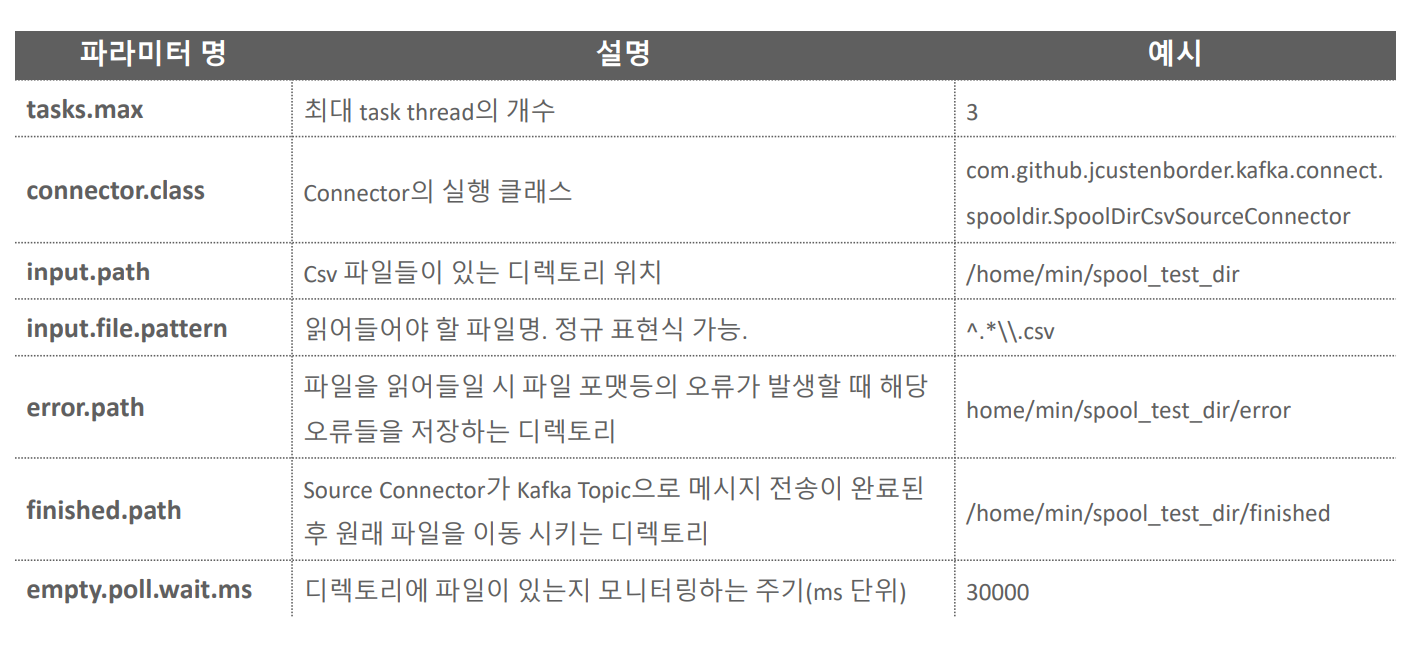

쳤던 명령어.. 위의 자료를 보면서 다시 한번 복습해보자.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic spooldir-test-topic
--from-beginning --property print.key=trueConverter의 역할
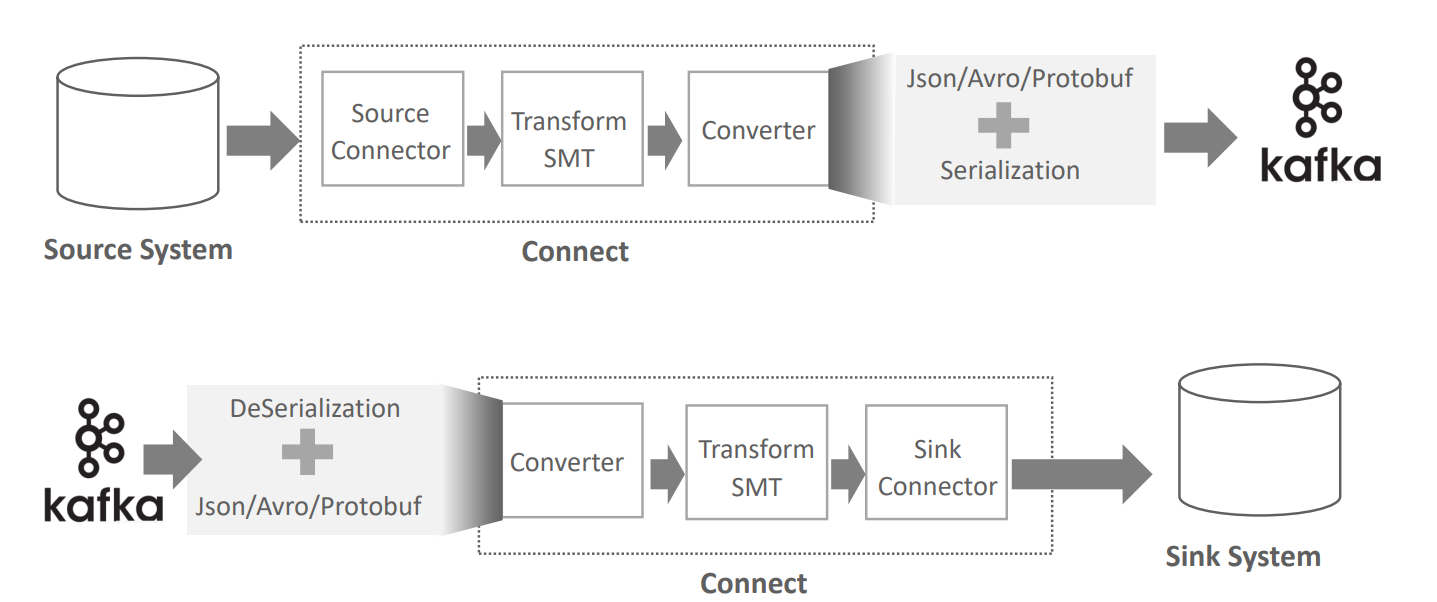
-
source 가 rdb라고 했을 때 변경사항이 발생한다.(INSERT 등 )
-
source connector가 특정 테이블을 모니터링을 하고 있음..
-
그리고 변경 부분을 이벤트로 만든다..
-
필요시 transform 에서 변경..
-
컨버터를 적용, 포맷팅을 어떻게 지정할건지..JSON, AVRO 등등..
-
그리고 원하는 type으로 변경을 한 후 직렬화 시켜서 kafka로 보냄
-
sync 쪽에서 convertor 가 먼저 돌게 되어 있음.
-
역직렬화를 하면서 해당 data의 type이 JSON 인지 AVRO인지 알고 있으니 메시지를 풀어낸다.
-
필요시 transform 에서 변경..
-
sink connector 에서 풀어낸 메시지를 sinkDB쪽에 저장하게 됨
Converter 대표적 지원 포맷
• Json
• Avro
• Protobuf
• Json/Avro 포맷의 경우 schema와 payload로 구성
• Schema는 해당 레코드의 schema 구성을,payload는 해당 레코드의 값을 가짐.
• Connector 별로 Json 포맷은 조금씩 다를수 있지만 전반적으로 대부분 비슷
• Json Schema의 경우 레코드 별로 Schema를 가지고 있으므로 메시지 용량이 커짐. 이의 개선을 위해 Avro Format과 Schema Registry를 이용하여 Schema 정보의 중복 생성 제거
포맷 형식
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false, -> not null 인지 ?
"field": "customer_id"
},
{
"type": "string",
"optional": false,
"field": "email_address"
},
{
"type": "string",
"optional": false,
"field": "full_name"
}
],
"optional": false,
"name": "mysql02.oc.customers.Value"
},
"payload": {
"customer_id": 864,
"email_address": "testuser_864",
"full_name": "testuser_864"
}
}커넥트 내부 토픽 이해
-
내부적으로 connect를 생성하면 내부 토픽들이 있다.
-
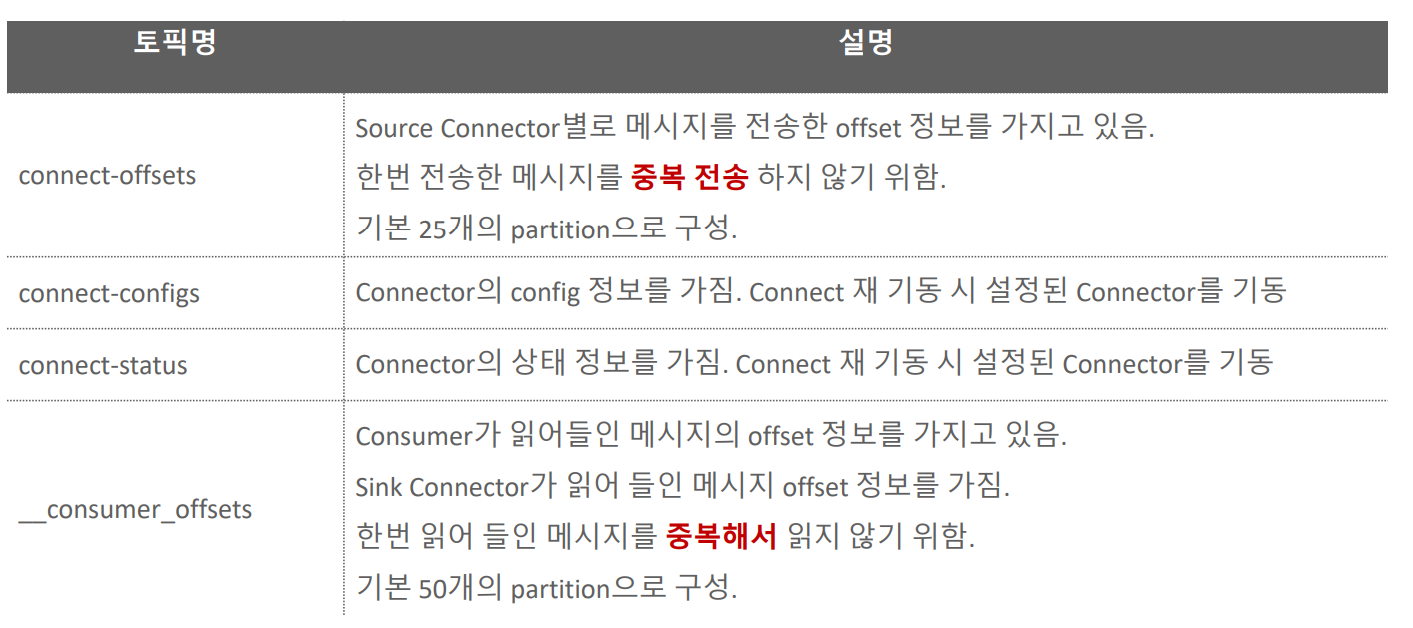
대표적으로 connet-config (connect들의설정) & offset 이 있고 이게 25개의 파티션으로 되어있다. 그리고 connect-status(connect들의상태)
-
connect-offset은 개별 커넥터별로 한번 kafka로 전송한 레코드 들에 대한 오프셋을 가지고 있다.
-
__consumer-offset은 기본적으로 50개의 파티션이 만들어짐
Consumer의 subscribe, poll, commit
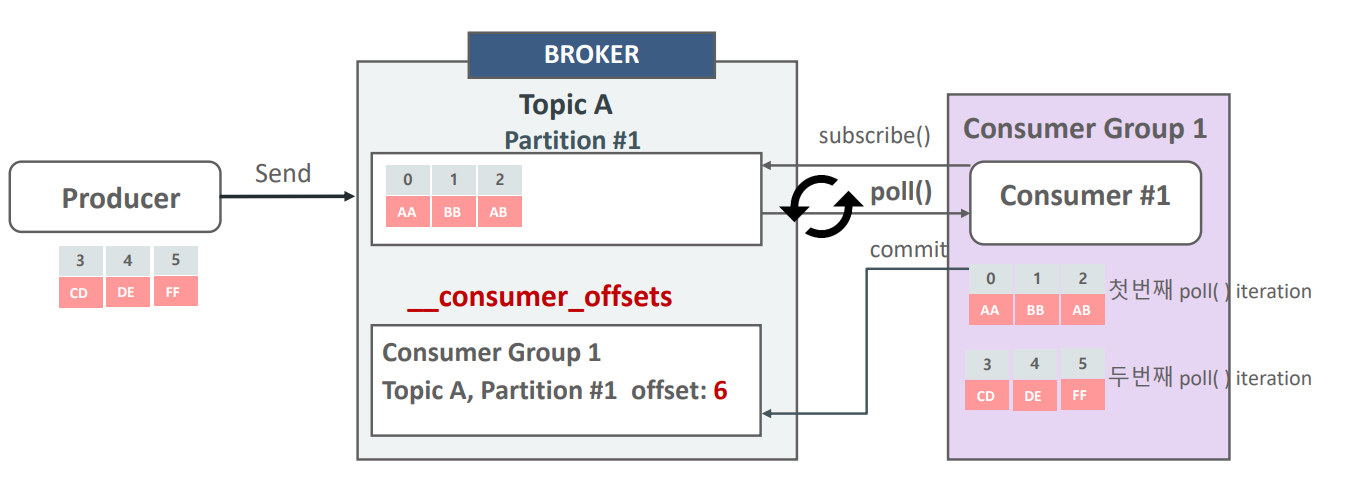
-
맨 처음 consumer_offset 이 0일 때는 producer 쪽 offset을 0부터 읽어라 라고 해서 쌓여있는 메시지 0,1,2를 읽음
-
그리고 producer offset 0,1,2, 다음인 3번이 consumer_offset에 적재됨
-
그리고 topicA에 다음 메시지인 3,4,5가 들어오면 consumer_offset은 3이기 때문에 topic에 있는 3번 data부터 읽어들일수가 있음.
connect-offsets 내부 토픽
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-offse
ts --from-beginning --property print.key=true | jq '.'
[
"csv_spooldir_source",
{
"fileName": "csv-spooldir-source-01.csv"
}
]
{
"offset": 848
}
[
"csv_spooldir_source",
{
"fileName": "csv-spooldir-source-01.csv"
}
]
{
"offset": 1000
}현재 2개가 들어가있음.
대괄호가 key, 중괄호 value
SMT(Single Message Transform)
Connect에서 메시지의 변환을 위해 제공하는 라이브러리
-
Source 시스템의 메시지를 Kafka로 전송전에 변환하거나 Kafka에서 Sink 시스템으로 데이터를 입력하기 전에
변환할 때 적용 -
Connect는 Connector와 Config 만으로 인터페이스 하므로 메시지 변환도 Config에서 SMT를 기술하여 적용해
야 함. -
SMT가 제공하는 변환 기능은 SMT를 구현한 Java 클래스를 기반으로 제공되며, Kafka Connect는 기본적인SMT 클래스를 가지고 있음.
-
Connect에서 기본제공하는 SMT 클래스외에 3rd Party에서 별도의 SMT를 Plugin 형태로 제공할 수도 있음.
-
SMT 변환은 Chain 형태로 연속해서 적용할 수 있음.
