토픽 파티션은 그룹 단위 할당
-
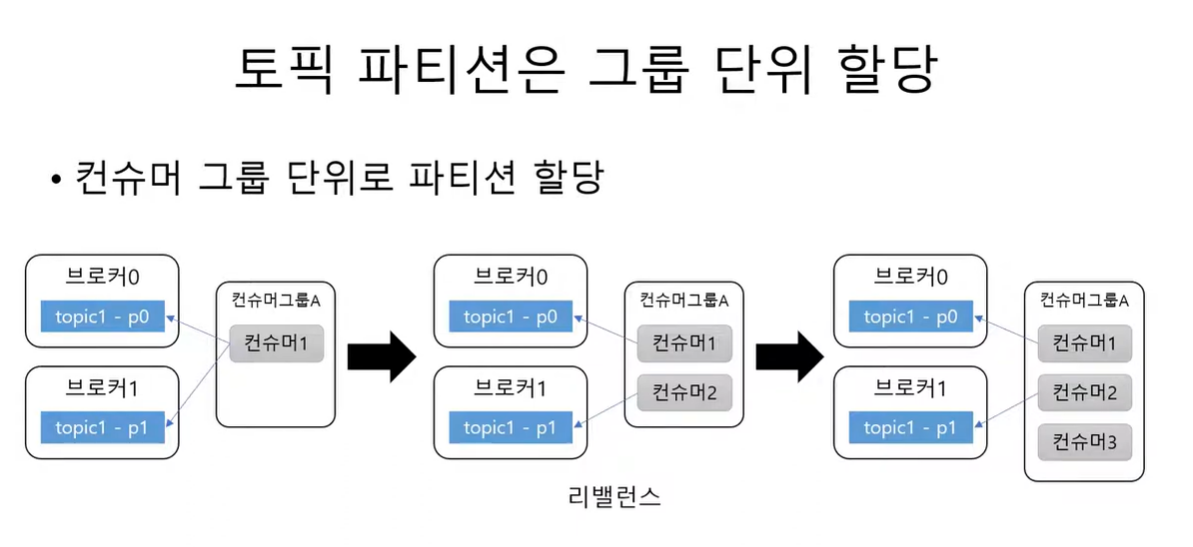
토픽의 파티션은 그룹 단위로 할당 된다. 이 그룹은 그룹 ID로 설정된 것이다.
-
파티션 개수보다 컨슈머 그룹 수 가 많아 지게 되면 컨슈머는 놀게 된다. 예를들어 파티션이 2개이고, 컨슈머가 1개면 컨슈머가 두 파티션으로 부터 데이터를 읽어온다. 그런데 이때 컨슈머를 하나 더 추가 하면 각 파티션으로 연결 된다.
-
하지만 여기서 컨슈머가 더 생긴다면? 이후로 생긴 컨슈머는 놀게 된다. 따라서 컨슈머 개수가 파티션 개수보다 커지면 안 된다. 만약 처리량이 떨어져서 컨슈머를 늘려야 할 일이 생기면 파티션 개수도 늘려야 한다.
커밋과 오프셋
-
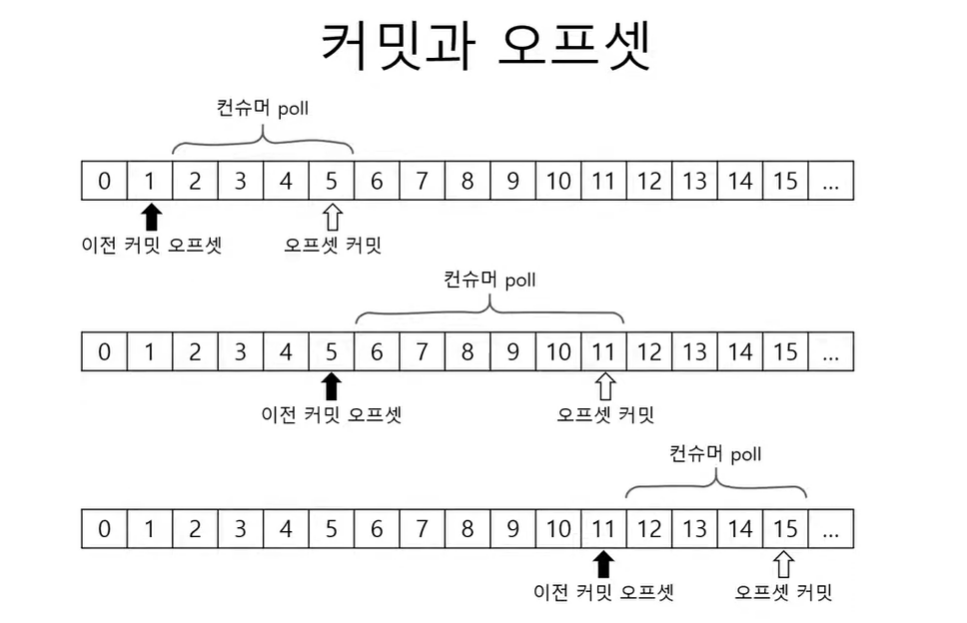
컨슈머의 poll 메소드는 이전에 커밋된 offset 이 있으면 그 offset 이후에 레코드를 읽어온다. 그리고 마지막 읽어온 레코드의 offset을 커밋한다. 그리고 다음 poll 메소드를 실행하면 반복이다.
-
하지만 커밋된 offset 이 없을 수 있는데 이럴땐 auto.offset.reset 이라는 옵션을 적용한다.
-
earliest : 맨 처음 오프셋 사용
-
latest : 가장 마지막 오프셋 사용 (기본값)
-
none : 컨슈머 그룹에 대한 이전 커밋이 없으면 Exception 발생
아래의 코드처럼 application.yml 에 설정 해 놓을 수 있다.
spring:
kafka:
consumer:
auto-offset-reset: latest
group-id: community
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
컨슈머 설정
조회에 영향을 주는 주요 설정
-
fetch.min.bytes: 조회 시 브로커가 전송할 최소 데이터 크기, 기본값 1, 여기서 설정한 값 이상의 데이터가 쌓일 때 까지 기다렸다가 전송해줌. 대기시간은 조금 늘지만 처리량이 증가하는 효과를 볼 수 있음.
-
fetch.max.wait.ms: 데이터가 최소 크기가 될 때 까지 기다릴 시간, 기본값 500, 브로커가 최소 데이터를 모으기까지의 기다리는 시간
-
max.partition.fetch.bytes: 파티션 당 서버가 리턴할 수 있는 최대 크기
자동 커밋 / 수동 커밋
-
enable.auto.commit : true면 일정주기로 컨슈머가 읽은 데이터를 커밋하게 된다.
-
poll(), close() 메소드를 호출할 때 자동 커밋이 실행 된다.
수동커밋 : 동기 / 비동기

재처리와 순서
-
동일 메시지 조회 가능성 : 일시적 커밋 실패, 새로운 컨슈머 추가 및 컨슈머 삭제로 인한 리밸런스 등에 의해 발생함.
-
컨슈머는 멱등성을 고려하여 구현해야 함, 중복된 데이터를 수신하게 될 경우 이미 실행된 로직이 다시 실행될 수 있음.
-
따라서 데이터 특성에 따라 타임스탬프, 일련번호등을 활용해야함
세션 타임아웃, 하트비트, 최대 poll 간격
-
컨슈머는 하트비트를 전송해서 연결을 유지한다.
-
브로커는 일정시간동안 컨슈머로부터 하트비트가 없으면 컨슈머를 그룹에서 빼버리고 리밸런스를 진행한다.
-
관련설정에는 session.timeout.ms 와 heartbeat.interval.ms 가 있는데 관련설정은 찾아보자.
-
max.poll.interval.ms : poll 메소드의 최대 호출간격 : 이 시간 내에 poll 을 사용하지 않으면 컨슈머를 빼버린다.
주의
-
kafkaConsumer 는 쓰레드에 안전하지 않다.
-
여러 쓰레드에서 동시에 사용하지 말 것.
-
wakeup() 메서드 제외
영상참조
