
기획의도
-
각자의 취미 모임을 가입하여 여가 활동을 즐기는 어플 소모임을 보고 카피하여 만든 프로젝트이다.
-
하나의 서버에 문제가 생겨도 다른 서버에 영향을 주지 않기 위해 MSA 기반으로 프로젝트를 진행 할 예정이다.
-
Netflix Eureka Server 로 Server 들을 관리하며 load Balancer 를 사용할 예정이다.
-
Eureka 안에서 openfeign 으로 Server 끼리의 소통을 진행할 예정이다.(다음 주 공부하는 kafka 로 고도화 예정)
-
프론트에선 모든 서비스로 request 를 뿌려주는 netty 기반 Server로 GateWay 역할을 구축할 예정. (non-blocking)
-
openfeign 을 통해 소통 하던 부분을 구축하고, 후에 Kafka를 구축해서 고도화를 해볼 예정.
ERD
- MSA 로 모든 서비스를 찢기 전에 ERD 를 작성해보았다.
-
community
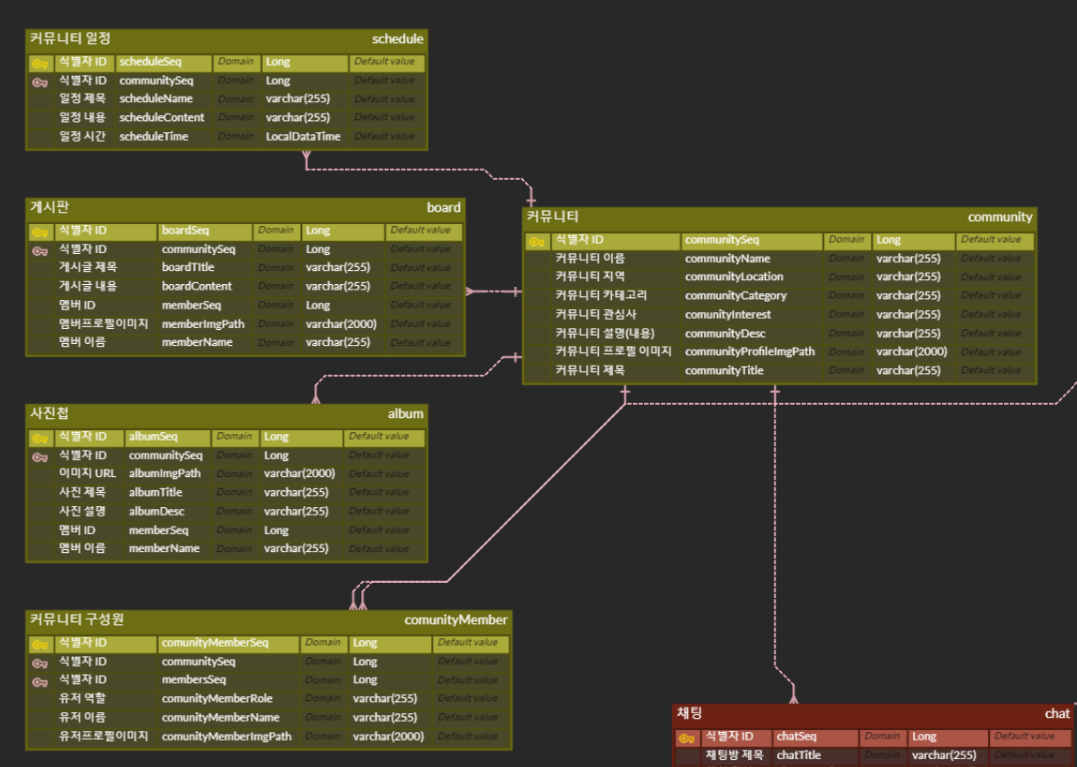
-
user
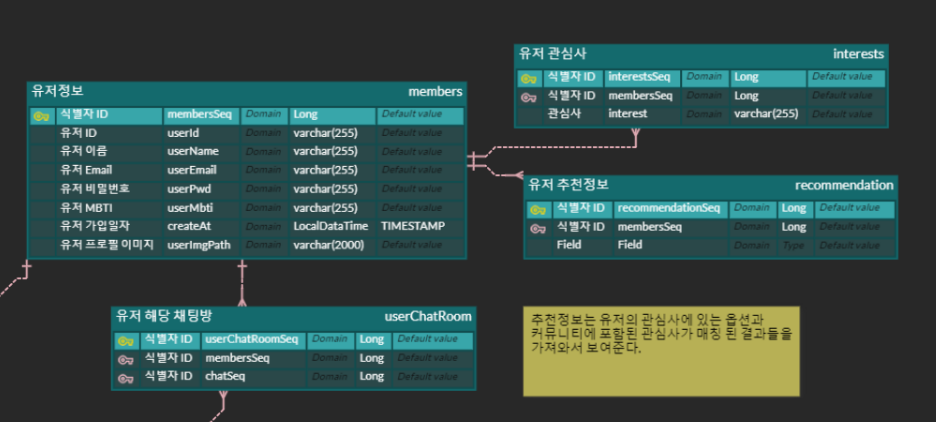
-
chatting
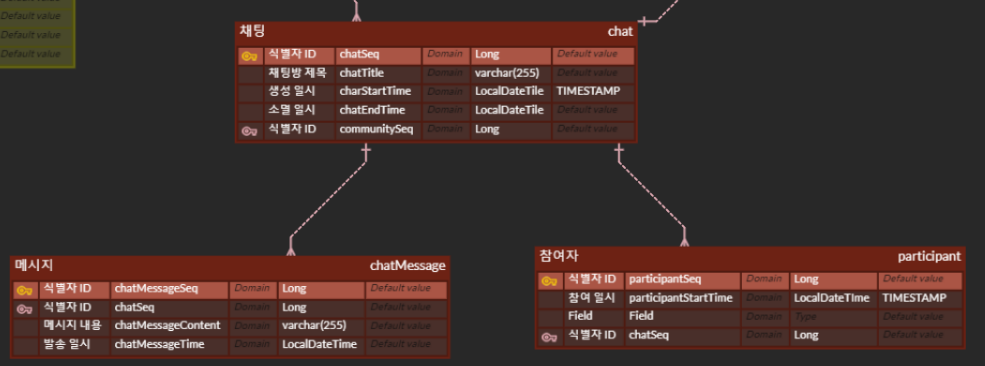
Server 분리
-
Eureka Server (8761)
- server 들을 관리하며 load balancer 제공
-
Config Server (8888)
- jwt token 발급을 위한 secret key config 공통 사용
-
GateWay Server - (8000)
- netty 의 non-blocking 기반으로 request 들을 각각의 server에 뿌려줌
-
Auth Server
- kakao oauth 처럼 인증서버를 따로 둔 뒤 해당 인증 서버에서 회원가입과 로그인을 완료 한 뒤 Token을 발급받아 Main 서비스로 쏴준다.
-
User Server - Eureka Client
- User 하위 도메인에는 Interest (유저의 흥미) , Reserve (유저의 찜 목록) 이 있다.
- User 를 MSA 기반으로 분리하지 않은 이유는 프로젝트 특성상 User에 트래픽이 몰릴 가능성은 적기 때문에 하나의 프로젝트에서 진행하기로 하였다.
-
Community Server - Eureka Client
- 프로젝트의 핵심 Server 라고 생각하기 때문에 실제로 실무를 돌때는 여러대의 server를 운용해야 할 것 이다.
- 또한 MSA 기반으로 해당하는 community 와 관련된 하위 도메인들은 전부 다 분리 시켜 놓았다.
- community 를 생성하면 프론트에서 로그인한 userId를 같이 올려주고 CommunityMember 에도 같이 save 될 수 있게 해놓았다.
-
Board Server - Eureka Client
- Community 의 하위 도메인인 Board Server 고 CQRS로 게시글 쓰기와 읽기서버를 나눌 예정이다.
-
Comment Server - Eureka Client
- Board 의 하위 도메인인 댓글 서버 이다.
-
CommunityMember Server - Eureka Client
- Member가 가입한 CommunityList를 보여준다. Member가 Community에 가입할 때 Insert 된다.
-
Schedule Server - Eureka Client
- Community 의 하위 도메인인 일정 server이다.
-
Album Server - Eureka Client
- Board 의 하위 도메인인 사진첩 server 이다.
-
Like Server - Eureka Client
-
board 와 album 의 하위도메인인 좋아요 server이다.
-
like 추가 시 구분 값에 따라 board & album 의 필드에 like count 필드를 수정 하는 쿼리를 날린다.. // 좋아요 뺄 때도..
-
-
Chatting Server - Eureka Client
- node/express server로 구성 되어 간단히 채팅을 구현.
- mongo db 에 data 저장.
-
Band - Client ( 3000 )
- main project client
-
Auth - Client ( 3001 )
- auth server 의 client
그림으로 보는 Server 분리 현황
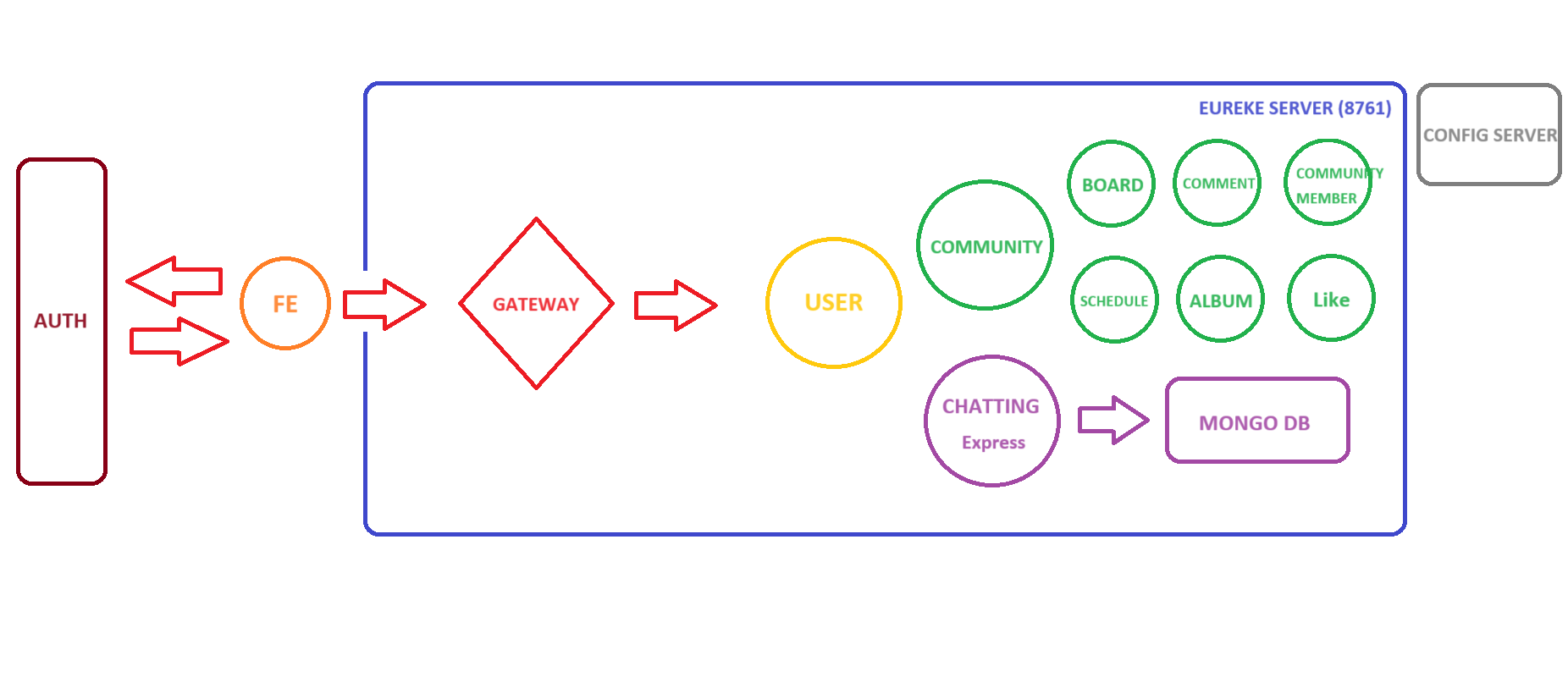
- FE 쪽에서는 우리의 원래 서비스로 기존 회원가입과, auth 서버를 통해서 회원가입을 하는 2가지 방법이 있다.
auth server를 통한 로그인
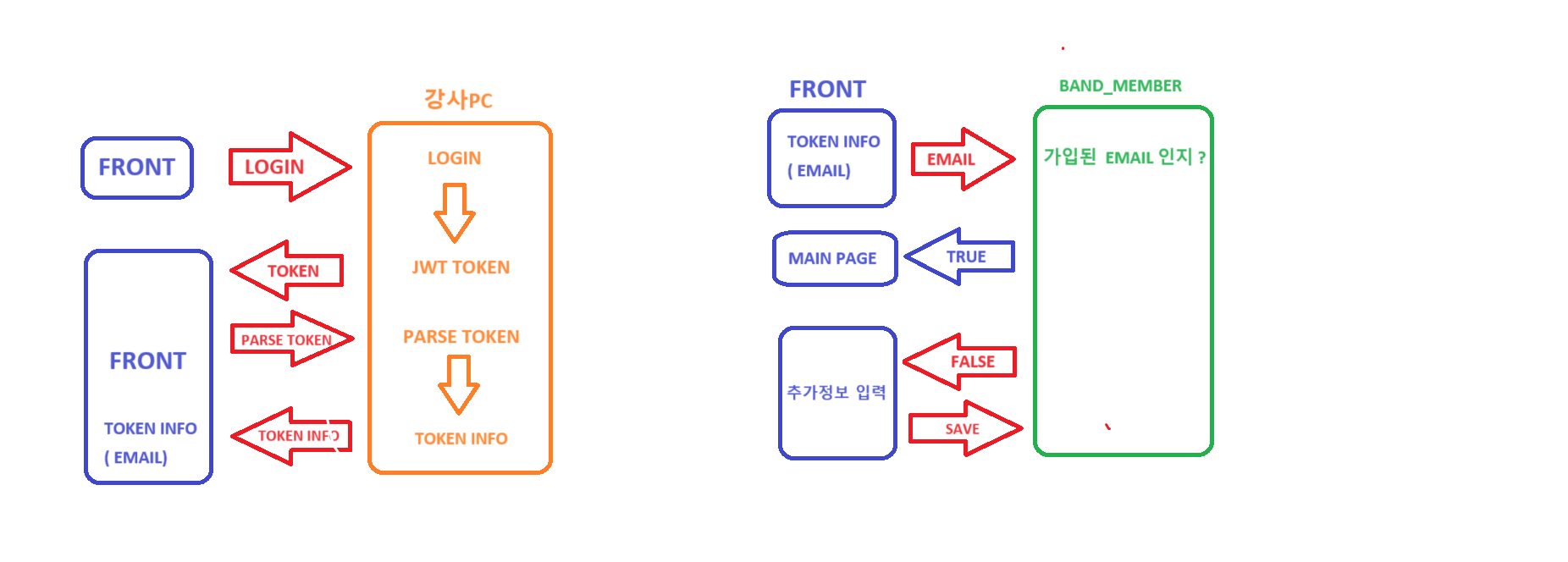
- 프론트에서 auth 서버를 통한 로그인 과정
-
fe 에서 auth 서버로 로그인을 누른다.
-
auth 서버에서 짜놓은 로직으로 회원가입을 한다.
-
auth 서버에서 방금 가입한 계정으로 로그인을 한다.
-
로그인을 하면 TOKEN이 발급되고 그 OKEN이 요청한 FRONT쪽으로
넘어오게 된다. -
fe 에서 방금 받은 토큰을 다시 넘긴다 . 이유는 토큰을 까야하니까. 근데 왜 우리꺼에서 토큰을 깔 수없냐? - 우리의 시크릿 키랑 auth server의 시크릿키가 달라서.
-
auth server에서 token을 parse 한 정보를 다시 front 로 보내준다.
-
프론트에서는 Auth server에서 Email과 name 을 받아오게된다.
-
받아온 정보에서 우리의 service에 받아온 email을 던져서 현재 가입한 회원인지 체크를 한다.
-
가입된 회원이라면? mainpage로 넘겨주면서 전역 셋팅(유저정보를 프론트에서 가지고 있는 행위 )을 하고
-
가입되지않은 회원이라면? 추가정보 ( 비밀번호, 흥미, 등등 )을 받아서
우리의 service에 다시 저장한다. -
이렇게 하는 이유는 우리의 서비스에 필수적인 데이터로 흥미나 프로필이미지 등이 있는데 이런 데이터는 token에 없기때문임..
-
login 시 access token 과 refresh token을 둘다 발급한다.
-
access token 은 만료시간을 조금 짧게 주고 refresh token 은 시간을 조금 길게 줘서 최상단 컴포넌트 혹은 주로 사용하는 로직에서 access token이 만료되었는지 계속 확인한다.
-
만료가 되었다면 ? refresh token을 이용해서 access를 재발급한다.
-
refresh token 이 만료되면 강제로 로그아웃을 시킨다.
-
아래의 코드는 front login 로직인데 로그인이 성공하면 로그인 정보를 redux(localstorage)에 담아서 저장하고 모든 요청의 header 에 token을 추가하게 된다.
export const login = async (userId, userPwd) => {
// redux(localstorage) 에 저장 할 정보들
const res = {
isLogin : false,
id : null,
username : null,
profileImgPath : null,
mbti : null,
token : null,
userSeq : null,
interest : []
}
try {
// 로그인과 동시에 userId 와 pwd 를 이용한 Jwt Token 발행 함수..
const response = await userLogin(userId, userPwd);
if (response.status === 200) {
const jwtToken = 'Bearer ' + response.data.data.token;
res.isLogin = true;
res.id = response.data.data.email;
res.username = response.data.data.username;
res.profileImgPath = response.data.data.profileImgPath;
res.mbti = response.data.data.mbti;
res.token = jwtToken;
res.userSeq = response.data.data.userId;
res.interest = response.data.data.interests;
// 토큰 인증 성공시 모든 API에 기본 요청 토큰 설정..
apiClient.interceptors.request.use((config) => {
config.headers.Authorization = jwtToken;
return config;
});
return res;
} else {
return res;
}
} catch (error) {
return error;
}
}server 끼리의 소통 방법 (openfeign)
밑의 예시는 유저의 프로필을 업데이트 할 때 유저정보를 가지고 있는 모든 server들에 같이 update를 해주는 service 로직이다
@Transactional
public void updateUser(Long id, SignupRequest request){
userRepository.updateUser(id, request);
communityMemberClient.updateMemberInCommunityMember(new CommunityMemberRequest(id,null
, request.getName(), request.getImgPath(), null,null
),id);
albumClient.memberUpdateInAlbum(id,new AlbumUpdateRequest(
request.getName(), request.getImgPath()
));
boardClient.updateMemberBoard(id,new AlbumUpdateRequest(
request.getName(), request.getImgPath()
));
scheduleClient.updateMemberBoard(id, new AlbumUpdateRequest(
request.getName(), request.getImgPath()
));
chattingClient.updateMember(id, new AlbumUpdateRequest(
request.getName(), request.getImgPath()
));
}아래의 예시처럼 클래스를 저장해놓고 service 로직에서 의존성 주입을 해서 사용하면 Eureka 에서 관리하고 있는 서비스 중에서 BAND-ALBUM-SERVICE 로 되어있는 album_server 의 controller로 연결이 되서 이어서 로직이 실행 된다.
@FeignClient("BAND-ALBUM-SERVICE")
public interface AlbumClient {
@PutMapping("api/v1/album/memberid/{memberId}")
void memberUpdateInAlbum(
@PathVariable("memberId") Long memberId,
@RequestBody AlbumUpdateRequest request
);
}pub/sub 을 이용한 server 끼리의 소통 방법 (kafka)
위에서 openFeign 으로 소통하던 것들을 kafka 로 대체하였다.
아래는 토픽을 생성하였고,
@Component
public class TopicConfig {
public final static String communityMember = "communityMember";
@Bean
public NewTopic communityMemberTopic() {
return new NewTopic(communityMember, 1, (short)1);
}
@Bean
public RecordMessageConverter converter() {
return new JsonMessageConverter();
}
@Bean
public CommonErrorHandler errorHandler(KafkaOperations<Object, Object> kafkaOperations) {
return new DefaultErrorHandler(
new DeadLetterPublishingRecoverer(kafkaOperations),
new FixedBackOff(1000L, 2)
);
}
}아래의 코드에서는 commumity 에서 해당하는 topic 으로 데이터를 전송하였다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CommunityMemberProducer {
private final ProducerFactory<String, CommunityMemberReqeust> producerFactory;
public void send(CommunityMemberReqeust communityMemberReqeust) {
KafkaProducer<String, CommunityMemberReqeust> kafkaProducer = new KafkaProducer<>(producerFactory.getConfigurationProperties());
kafkaProducer.send(new ProducerRecord<>(TopicConfig.communityMember, communityMemberReqeust), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
log.info("Kafka 전송 성공: {}", metadata);
log.error("Kafka 전송 중 오류 발생: {}", exception);
// exception 에 대한 핸들링..
}
});
}
}아래는 communityMember 이며 kafka 에 대해서는 같은 설정을 해주고 consumer 설정을 마쳐 주었다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CommunityMemberConsumer {
private final CommunityMemberService communityMemberService;
@KafkaListener(topics = TopicConfig.communityMember)
public void listen(CommunityMemberReqeust communityMemberReqeust) {
System.out.println("consumer : " + communityMemberReqeust);
communityMemberService.saveCommunityMember(communityMemberReqeust);
}
@KafkaListener(topics = TopicConfig.communityMemberDLT)
public void dltListen(byte[] in) {
log.info("dlt : " + new String(in));
}
@KafkaListener(topics = TopicConfig.communityMemberUpdate)
public void updateCommunityMember(CommunityMemberReqeust communityMemberReqeust) {
communityMemberService.updateMemberInCommunityMember(communityMemberReqeust);
}
}해당하는 topic 을 구독하고 메시지를 수신하였고, 메시지를 수신하면서 원래 사용하던 로직을 실행하도록 하였고, 혹시 메시지 수신에 받지 못하는 데이터가 있으면 dlt 라는 토픽을 만들어서 그 곳에 데이터를 쌓아놓고 다시 장애가 해결 되었을 시 dlt에서 토픽을 받아오고 로직을 실행하도록 해놓았다.
@Configuration
public class ConsumerConfig {
@Bean
public CommonErrorHandler errorHandler(KafkaOperations<Object, Object> kafkaOperations) {
return new DefaultErrorHandler(
new DeadLetterPublishingRecoverer(kafkaOperations),
new FixedBackOff(1000L, 2)
);
}
}장애 발생시 재 요청은 2번을 하게 설정해놓았다.
openFeign 을 사용하던 다른곳도 전부 kafka 로 바꿨으며 , 추가 할 내용은 장애가 발새아면 데이터를 가지고 있다가 log를 작성하여 파일로 빼던지, 혹은 다른 에러 핸들링이 필요할 것 같다.
또한 서비스에 따라서 producer 의 ack 설정과 브로커의 batch.size 설정을 필요로 할 것 같다.
해결한 이슈
-
의존성 충돌
-
query DSL 과 eureka client 의 의존성이 서로 충돌하는 문제가 생겼다.
-
implementation group: 'org.springframework.cloud', name: 'spring-cloud-starter-netflix-eureka-client', version: '4.0.3' 모듈로 해결함.
-
-
DB 동시성 이슈
커뮤니티에 일정을 참여할 수 있는 기능이 있는데.. 만약 인원제한이 5명인데 한꺼번에 200명이 일정 참여를 한다면 ..? DB에 일관성 문제가 생기게 된다.
-
동시성 문제란 ? 동일한 하나의 데이터에 2 이상의 스레드, 혹은 세션에서 가변 데이터를 동시에 제어할 때 나타는 문제로,
-
하나의 세션이 데이터를 수정 중일때, 다른 세션에서 수정 전의 데이터를 조회해 로직을 처리함으로써 데이터의 정합성이 깨지는 문제를 말합니다.
일정 참여는 데이터베이스에서 인원을 조회한 이후에 인원이 max를 넘기지 않았다면 예약-멤버 중간 테이블에 멤버를 저장하고 예약 테이블에서 인원 +1 을 하도록 로직을 작성하였다.
근데 문제가 생겼다.
쓰레드 두가지가 동시에 일정 참여 테이블을 조회해서 특정 값을 기억한 이후 중간 테이블에 각자 멤버를 저장하고 이후에 가지고 있던 특정 값에 +1한 값으로 테이블을 업데이트 하였다.
즉 중간 테이블에는 2명이 들어가지만 겉으로 보여지는 예약 테이블에서는 +1이 되는 것이다. 이렇게 일관성이 깨진다.
이를 해결하기 위한 방식으로 멀티 쓰레드가 하나의 쓰레드를 사용할 때 lock을 거는 synchronized의 방식이 존재하지만 이는 서버가 여러개일 경우 해결되지 않는다.(데이터 베이스는 하나이기 때문이다)
그러면 어떻게 해야할까?
- Perssimistic Lock
데이터 베이스에 락을 거는 Perssimistic Lock방식이 있다. 자원 요청에 따른 동시성문제가 발생할 것이라고 예상하고 락을 걸어버리는 비관적 락 방식이다. 하지만, 데드락이 걸릴 수 있기 때문에 주의하여 사용해야하며, 속도는 느려질 수 있다.(하지만 결제같은 로직은 느리더라도 확실해야 하기 때문에 사용하는게 좋다)
- Optimistic Lock
실제로 Lock을 이용하지 않고 버전을 이용함으로써 정합성을 맞추는 방식이다. update를 수행할 때 현재 내가 읽은 버전이 맞는지 확인하며 업데이트 하는 방식이다. 자원에 락을 걸어 선점하지 않고, 동시성 문제가 발생하면 그때가서 처리하는 낙관적 락 방식이다. => 이 방식으로 만약 버전이 다르다면 다시 읽은 후에 작업을 수행하는 롤백 작업을 수행해야 해서 만약 먼저 요청했지만 그 사이 업데이트 돼서 다시 큐의 마지막에 서는 억울한 상황이 발생할 수 있다(공평성 문제). 대신 데드락을 방지할 수 잇다.
- Name Lock
Permission Lock과 유사하지만, Passimistic Lock 은 row 나 table 단위로 락을 고만, Named Lock 은 metadata 단위로 락을 건다는 차이점이 존재한다. named lock은 time out을 구현하기 간단하다
Optimistic Lock
-
간단하게 필드에 @version으로 필드 하나 생성해서 @Lock으로
repository 매서드 관리하면 된다 -
이걸로 해결 가능한 이유는 멤버를 조회할 때도 version을 업데이트 하도록 atomic하게 관리가 가능하지만 멤버를 업데이트할 때 atomic하게 버전이 올라가서 버전 컨트롤하기가 쉽다. 즉 버전이 다르면 업데이트가 롤백되고, 버전이 같으면 atomic하게 version 필드를 +1한다.
-
더미 엔티티도 버전을 초기화해서 생성하는 것을 잊지 않도록 하자. 더미 데이터 조차 set하면 entity가 버전을 바꾼다.
Schedule.java
@Table(name = "Schedules", indexes = {
@Index(name = "idx_community_id", columnList = "communityId")})
@Entity
@Builder
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Schedule {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String scheduleName;
private LocalDateTime scheduleTime;
private String meetingPlace;
private String price;
private int maxParticipation;
private int participant;
private String interest;
private Long memberId;
private String memberName;
private String memberImage;
private Long communityId;
@Version
private Integer version;
}ScheduleRepository.java
public interface ScheduleRepository extends JpaRepository<Schedule, Long> {
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from Schedule s where s.id = :id")
Optional<Schedule> findAllByIdWithOptimisiticLock(@Param("id") Long id);
}@Lock(LockModeType.OPTIMISTIC) 어노테이션은 Java Persistence API (JPA)에서 제공하는 방식 중 하나로, 엔티티(여기서는 Schedule 클래스)의 데이터 일관성을 유지하기 위해 사용됩니다. 이 어노테이션을 사용하면 다중 요청으로 인해 엔티티의 데이터 일관성이 깨질 가능성을 방지할 수 있다.
LockModeType.OPTIMISTIC을 사용하는 경우, 데이터베이스에서 엔티티를 읽을 때 버전 관리가 수행됩니다. 각 엔티티에는 버전 번호가 있고, 이 버전 번호는 엔티티가 업데이트될 때마다 증가합니다. 이 버전 번호는 동시 업데이트를 방지하기 위한 장치로 작용합니다.
@Lock(LockModeType.OPTIMISTIC)을 사용한 메소드인 findAllByIdWithOptimisiticLock는 주어진 id에 해당하는 Schedule 엔티티를 검색할 때, 해당 엔티티의 버전을 함께 가져옵니다. 그리고 이 메소드는 동시에 여러 요청이 들어올 경우, 다음과 같은 방식으로 작동합니다.
-
처음에 한 요청이 findAllByIdWithOptimisiticLock 메소드를 호출하여 엔티티를 읽습니다.
-
다른 요청이 동일한 엔티티를 수정하고 저장하면(업데이트하면), 해당 엔티티의 버전 번호가 증가합니다.
-
처음의 요청이 엔티티를 수정하기 전에 버전 번호를 확인합니다. 이때, 버전 번호가 처음에 읽은 버전과 다르다면, 엔티티가 다른 요청에 의해 수정되었다는 것을 인식하게 됩니다.
-
따라서 처음의 요청은 엔티티를 업데이트하지 않고 예외를 발생시키거나 다른 적절한 처리를 수행할 수 있습니다.
이것은 동시 업데이트로 인한 데이터 일관성 문제를 방지하기 위한 일종의 낙관적인 잠금(Optimistic Locking) 메커니즘입니다.
Pessimistic Locking vs Optimistic Locking
Pessimistic Locking (비관적 잠금, LockModeType.PESSIMISTIC_READ)
이 방식은 엔티티를 읽을 때 먼저 해당 엔티티에 잠금을 거는 방식입니다. 다른 트랜잭션에서 해당 엔티티를 수정하려고 시도하면 잠금이 해제될 때까지 대기해야 합니다. 이러한 방식은 엔티티에 대한 읽기 연산 중에도 다른 트랜잭션에서 해당 엔티티를 수정할 수 없도록 막습니다.
Optimistic Locking (낙관적 잠금, LockModeType.OPTIMISTIC)
이 방식은 엔티티를 읽을 때 잠금을 걸지 않습니다. 대신, 엔티티를 수정할 때 버전 관리를 통해 충돌을 감지합니다. 엔티티의 버전이 수정되면(즉, 엔티티가 업데이트될 때마다 버전이 증가) 다른 트랜잭션에서 해당 엔티티를 수정할 수 없도록 합니다. 따라서 엔티티의 읽기 연산은 다른 트랜잭션의 수정 연산과 충돌하지 않습니다.
- OPTIMISTIC_FORCE_INCREMENT : 낙관적 잠금의 한 변형으로, 엔티티를 읽을 때도 잠금을 걸지 않지만 엔티티를 수정하지 않으면서도 버전을 강제로 증가시키는 방식입니다. 다른 트랜잭션이 해당 엔티티를 수정하는 것을 방지하고 엔티티의 버전을 업데이트하는 역할을 합니다. 이렇게 하면 엔티티를 수정하지 않아도 버전 충돌을 감지할 수 있습니다.
4.레디스(redisson - Java Client lib)
@Transactional
public ResponseEntity<RestResult<Object>> toggleAttendanceByRedis(AttendanceRequestDto attendanceRequestDto) {
Long memberId = attendanceRequestDto.getMemberId();
Long communityId = attendanceRequestDto.getCommunityId();
Long scheduleId = attendanceRequestDto.getScheduleId();
String useYn = attendanceRequestDto.getUseYn();
// 이곳에서 락을 건다.
RLock lock = redissonClient.getLock("tempKey");
try {
boolean available = lock.tryLock(5, 1, TimeUnit.SECONDS);
if (!available) {
System.out.println("lock 실패");
}else{
Schedule schedule = scheduleRepository.findById(attendanceRequestDto.getScheduleId()).get();
if (schedule.getParticipant() < schedule.getMaxParticipation()){
if ("Y".equals(useYn)) {
//참석할 수 있는 최대 인원과 현재 참석한 인원 비교
if (schedule.getParticipant() < schedule.getMaxParticipation()) {
Boolean attendanceCheck = checkAttendance(memberId,scheduleId);
if (attendanceCheck){
return ResponseEntity.status(HttpStatus.BAD_REQUEST)
.body(new RestResult<>("BAD_REQUEST", new RestError("BAD_REQUEST", "이미 가입했습니다.")));
}
// 참석
Attendance attendance = Attendance.builder()
.schedule(schedule)
.useYn(attendanceRequestDto.getUseYn())
.memberId(attendanceRequestDto.getMemberId())
.build();
attendanceRepository.save(attendance);
// 참석 인원 증가
schedule.setParticipant(schedule.getParticipant()+1);
scheduleRepository.flush();
} else {
return ResponseEntity.status(HttpStatus.BAD_REQUEST)
.body(new RestResult<>("BAD_REQUEST", new RestError("BAD_REQUEST", "일정 정원이 초과되었습니다.")));
}
} else if ("N".equals(useYn)) {
//불참
Attendance attendance = attendanceRepository.findByMemberId(attendanceRequestDto.getMemberId());
// 참석 인원 감소
schedule.setParticipant(schedule.getParticipant() - 1);
attendanceRepository.delete(attendance);
}
return ResponseEntity.ok(new RestResult<>("success", "참석이 완료 되었습니다."));
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 하나의 로직이 끝나고 unlock 함.
lock.unlock();
}
return null;
}-
RLock lock = redissonClient.getLock("tempKey"); 라인에서 tempKey라는 이름의 락을 생성합니다.
-
lock.tryLock(5, 1, TimeUnit.SECONDS);를 사용하여 락을 시도합니다. 이 메서드는 5초 동안 락을 획득하기를 시도하며, 1초마다 재시도합니다. 만약 락을 획득하지 못하면(!available) "lock 실패" 메시지를 출력하고 해당 부분에서 동시성 문제를 막습니다. 즉, 락을 획득하지 못한 스레드는 해당 블록에 진입하지 않습니다.
-
finally 블록에서는 lock.unlock();를 호출하여 락을 해제합니다. 이 부분은 락을 획득한 후에 예외가 발생하더라도 락이 안전하게 해제됨을 보장합니다.
5.카프카
카프가 적용만으로 동시성문제를 완화 시킬 수 있던 이유는 다음과 같다.
-
비동기 통신: 카프카는 비동기 메시지 큐로, 메시지를 프로듀서에서 컨슈머로 비동기적으로 전달합니다. 이 비동기 통신 방식을 통해 메시지를 효율적으로 큐잉하고 처리할 수 있으므로 DB 작업이나 다른 비즈니스 로직을 블로킹하지 않고 처리할 수 있습니다.
-
분산 아키텍처: 카프카는 분산 아키텍처를 사용하므로 여러 프로듀서와 컨슈머 간에 메시지를 분산하고 처리할 수 있습니다. 이는 DB에 대한 동시성 문제를 완화하는 데 도움이 됩니다. 메시지가 여러 컨슈머에 동시에 전달되고 처리되기 때문에, DB 쿼리나 트랜잭션 충돌을 최소화할 수 있습니다.
-
이벤트 소싱과 CQRS: 카프카를 사용하면 이벤트 소싱과 CQRS (Command Query Responsibility Segregation) 패턴을 구현할 수 있습니다. 이를 통해 데이터 변경 사항을 이벤트로 기록하고 이벤트 스트림을 사용하여 데이터를 업데이트하거나 조회할 수 있습니다. 이러한 패턴은 동시성 문제를 줄이고 데이터 일관성을 보장하는 데 도움을 줍니다.
-
메시지 순서 보장: 카프카는 메시지의 순서를 보장하는 데 강력한 지원을 제공합니다. 이를 통해 DB에 대한 연산 순서를 일관되게 유지할 수 있으며, 데이터 일관성과 동시성을 관리하는 데 도움이 됩니다.
-
복제와 복구: 카프카는 메시지를 복제하고 데이터의 손실을 방지하기 위한 메커니즘을 제공합니다. 이를 통해 시스템 장애 시에도 데이터를 안전하게 복구할 수 있으며, DB와의 상호작용 중에 예기치 않은 오류가 발생해도 데이터 손실을 최소화할 수 있습니다.
카프카 동시성제어 주의할 점
-
카프카의 각 토픽은 여러 파티션으로 나눠질 수 있습니다. 파티션은 데이터를 병렬로 처리할 수 있게 해주는데, 이것은 동시성을 확보하는 좋은 방법입니다.
-
그러나 파티션 수가 늘어날수록 데이터를 올바르게 처리하고 순서를 보장하는 것이 어려워질 수 있습니다.
-
파티션 당 하나의 컨슈머를 할당하는 경우, 컨슈머의 수가 파티션 수보다 적을 때는 문제가 없지만, 파티션 수보다 많은 컨슈머를 할당하면 각 컨슈머가 데이터를 올바르게 처리하기 위해 동기화가 필요할 수 있습니다.
-
또한, 컨슈머 그룹 내에서 동일한 파티션에 대해 여러 컨슈머가 동시에 읽으려고 하는 경우 데이터 처리의 순서가 보장되지 않을 수 있습니다. 이러한 동시성 이슈를 해결하기 위해서는 카프카 컨슈머 그룹의 구성과 파티션의 수를 고려하여 적절한 동시성 제어 방법을 선택해야 합니다.
사용 모듈 & 스킬
Server : Netflix Eureka Server GateWay Server Netty express boot & JPA Kafka
DB : MySql MongoDB Redis
Front : React Rtk
Auth : Security & JWT
CSR 을 선택한 이유
-
소모임은 실제로는 웹이 아닌 앱에만 서비스가 있기 때문에 네이티브 앱과 비슷한 빠른 인터렉션을 구현하고 싶었음.
-
View 렌더링을 브라우저에게 담당시킴으로서 서버의 트래픽을 줄이고 싶었음.
-
그 중 많이 사용되는 react 와 vue 중 에서 현재 캠프에서 배우고 사용되고 있는 react 로 채택
CSS in JS 를 선택한 이유 ( module.css )
-
스타일시트의 묶음을 유지보수 할 자원을 할당하고 싶지 않았다.
-
복잡한 애플리케이션 내에서 선택자 충돌을 피할 수 없는 경우가 있고 BEM과 같은 네이밍 컨벤션은 한 프로젝트 내에서는 도움이 되지만, 서드파티 코드를 통합할 때는 도움이 되지 않는다. 따라서 CSS를 컴파일 할 때, 기본적으로 고유한 이름을 생성 하는 방식을 채택 하였다.
-
흔히 사용하는 Sass 는 근무할 당시 많이 사용해보았고 파일이 늘어날수록 문어다발식 import 가 되다보면 관리도 쉽지않고 빌드 시간도 비약적으로 늘어날 뿐더러 애초에 관리를 해야된다는 리소스 자체가 부담 이었다.
화면 미리보기
메인 화면만 몇개 샘플로 올리고 추후에 배포하도록 하겠다.
로그인

메인
메인 모임 추천 리스트 화면
이 외에도 모임 상세보기, 게시판, 앨범, 채팅, 일정, 내정보 등 여러가지 화면이 있지만 모두 올리기는 번거로우니 나중에 배포예정
git
