
저번에 MSA 기반으로 만들었던 소모임 프로젝트는 간단하게 유저들끼리 취미,모임,동아리를 만들어서 서로 가입하고 정보를 나누고 취미활동을 하는 프로젝트 이다.
이번에 기능을 추가해서 고도화 하려고 한다. 몇가지 코드들은 리팩토링 했고, 기능 추가에 대한 기획서를 작성했는데 기능 구현이 될 때마다 포스팅을 하려고 한다.
오늘은 ELK를 사용해 유저들이 생성한 모임을 검색할 수 있는 기능을 구현 할 것이다.
먼저 내가 구현하고싶은 검색기능은 다음과 같다.
구현 예정 검색 기능
-
최근 검색어
- 최근 검색어 5개 노출
- FIFO 방식으로 마지막 검색어 추가 시 첫번째 검색어 삭제
- 프론트단 에서 처리할 것
-
실시간 인기 검색어
- 유저들이 검색한 키워드를 집계하여 상위 TOP5 를 노출할 것
- 현재시간으로 부터 1시간 전 까지만 수집할 것
-
검색어 자동완성
- Google 처럼 내가 입력하는 단어에 대해 자동완성을 하여 검색어를 추천
- 자동완성을 해주는 기준은 유저들이 많이 검색한 키워드 순으로 추천
- 유저들이 생성한 모임의 이름이 매치되는게 있다면 추천
- 동의어 사전을 사용해 "삼전"을 검색해도 "삼성전자"가 나오게 끔 구현
-
오탈자 추천 검색어
- 유저의 오탈자에 대한 키워드로 비슷한 키워드를 추천 해 준다.
- 기본적으로 유저들이 많이 검색한 키워드를 기준으로 추천을 해 준다.
최근 검색어
최근 검색어는 프론트쪽에서 localstorage를 사용해서 처리하기로 하였음.
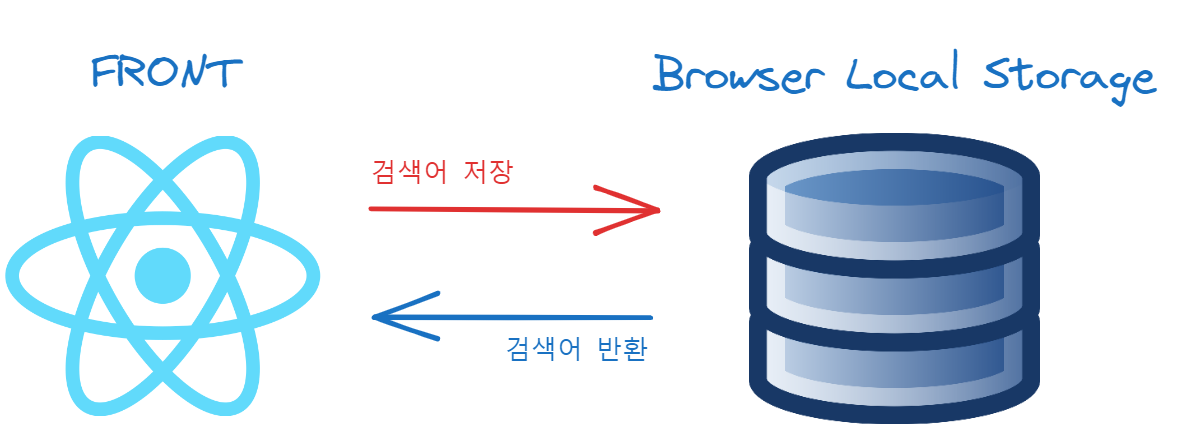
logic
const historyKeywordFunc = (text) => {
// 로컬 스토리지에서 기존 검색 기록을 가져옴.. 기존 기록이 없으면 빈 배열을 생성..
const existingHistory = JSON.parse(localStorage.getItem('searchHistory')) || [];
// 중복 검사가 완료되면 추가
if (!existingHistory.includes(text)) {
// 새로운 검색어를 검색 기록 배열에 추가..
existingHistory.push(text);
}
// 검색 기록 배열의 길이가 5개를 초과하면 첫 번째 항목을 삭제..
if (existingHistory.length > 5) {
existingHistory.shift();
}
// 업데이트된 검색 기록 배열을 다시 로컬 스토리지에 저장..
localStorage.setItem('searchHistory', JSON.stringify(existingHistory));
}
위의 코드로 구현을 하였고 화면은 아래와 같다.
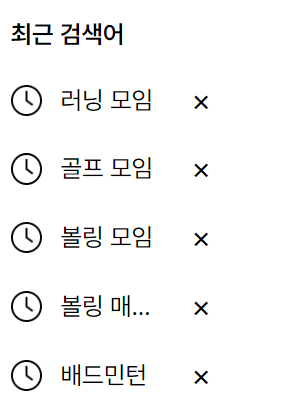
간단히 이런식으로 구현을 하였고 레이아웃이 넘어가면 ...처리 를 해놓았다.
실시간 인기 검색어
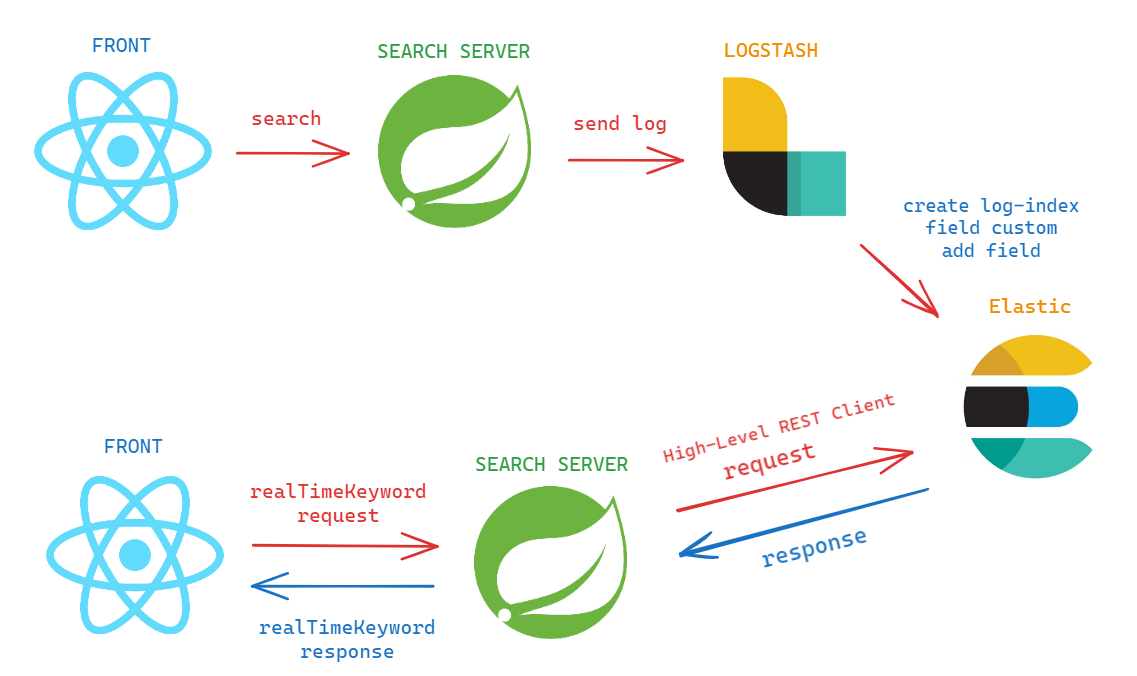
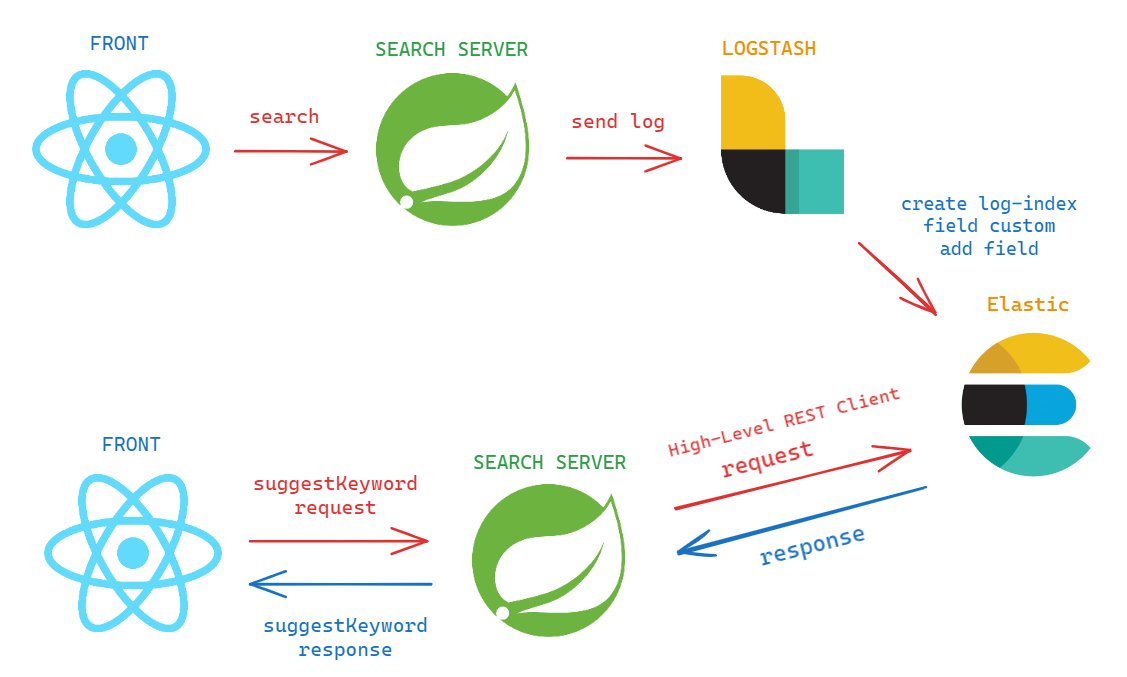
1. front 에서 keyword 를 검색하면 search server 에서 log 를 찍는다.
@Override
public List<Community> searchByName(String name) {
log.info("?name=" + name);
return repository.findAllByName(name);
}"?name=" 이라는 prefix는 사실 필요없음. logstash 에서 내가 지정한 텍스트를 다른 텍스트로 치환할 수 있는지 테스트 하기 위해 달아놓은 것..
2. search server 에서 찍은 log를 logstash 로 보내준다.
build.gradle
implementation 'com.internetitem:logback-elasticsearch-appender:1.6'
implementation 'dev.akkinoc.spring.boot:logback-access-spring-boot-starter:3.2.1'
implementation group: 'net.logstash.logback', name: 'logstash-logback-encoder', version: '7.2'3. logstash 에서 찍은 log를 custom 하여 es 로 보내준다.
아래처럼 logback 파일을 만들어주자
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- Console -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{10} - %msg%n</pattern>
</encoder>
</appender>
<!-- Logstash -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:4560</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<fieldNames>
<message>name</message>
</fieldNames>
</encoder>
</appender>
<!-- 로그 레벨 설정 -->
<logger name="com.example.band_search2.service.CommunityService" level="info">
<appender-ref ref="LOGSTASH" />
</logger>
<root level="info">
<appender-ref ref="CONSOLE" />
</root>
</configuration>위에 설정에서 spring boot project 의 모든 로그중 info레벨만 console에 찍고 있고
CommunityService 에서 생성되는 log 만 LOGSTASH로 전송하고 있다.
logstash config
input{
tcp {
port => 4560
codec => json_lines
}
}
filter {
mutate {
add_field => { "special_flag_name" => "%{name}" }
gsub => ["name", "\?name=", ""]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "accesslogs"
}
}아까 log에서 찍어놓은 "?name=" 을 치환하고,
special_flag_name 이라는 field 를 추가하고, name field에 있는 값을 복사한다.
여기서 special_flag_name 를 만들고 복사하는 이유는..
나중에 집계기능을 사용할건데 집계 기능을 사용하려면 인덱스 패턴을 만들고 필드.keyword 라는 하위필드가 필요하다.
여기서 이슈가 생긴다.
@Data @AllArgsConstructor @NoArgsConstructor @Builder
@Document(indexName = "accesslogs", useServerConfiguration = true)
@Mapping(mappingPath = "logs/mapping.json")
@Setting(settingPath = "logs/setting.json")
public class AccessLog {
@Id
private String id;
@Field(type = FieldType.Search_As_You_Type)
private String name;
}위의 AccessLog index 의 name type이 Search_As_You_Type 이기 때문에 name.keyword 하위필드는 생기지 않고 자동으로 ngrams 하위필드가 생성이 된다.
따라서 special_flag_name 을 하나 더 만들어서 special_flag_name.keyword 로 기준으로 나중에 집계기능을 사용할 것 이다.
이렇게 까지하면 유저가 검색한 키워드가 계속해서 logstash 를 타고 es로 올라갈 것 이다.
유저가 러닝 모임 이라고 검색하고 조회를 해본다면 ?
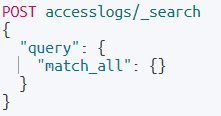
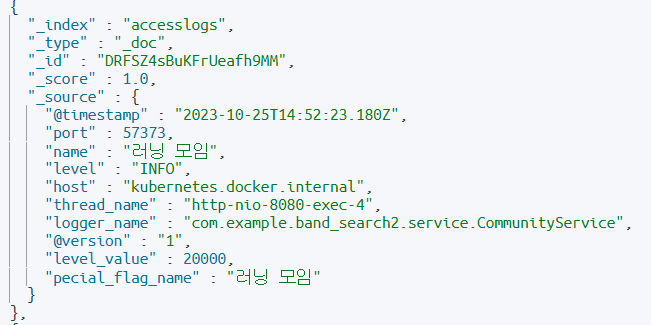
이라는 결과를 받을 수 있다.
4. front 에서 실시간 검색을 요청하면 search server 에서 값을 반환해준다.
현재 spring data elasticsearch 를 사용중인데, 이 모듈을 사용하면 Repository 쪽에서 @Query 라는 어노테이션을 사용할 수 있고, kibana devtools 에서 사용한 문법을 그대로 사용할 수 있다.
하지만 그건 복사 붙여넣기만 하면 쉽게 가능하기 때문에 나는 High-Level REST Client(java API)를 사용하였다.
@Override
public List<RealTimeSearchKeyword> getRecentTop5Keywords() throws IOException {
// 실검 담을 List 준비
List<RealTimeSearchKeyword> realTimeSearchKeywords = new ArrayList<>();
// 최근 1시간..
// 시간을 비교할때 Long으로 넘겨줘야함..
// 기본적으로 dynamic finder가 long으로 비교한다고 한다.
LocalDateTime now = LocalDateTime.now();
LocalDateTime truncatedNow = now.truncatedTo(ChronoUnit.HOURS);
long startMillis = truncatedNow.atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();
long endMillis = now.atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();
// Elasticsearch 질의 생성
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// timestamp 기준 최근 1시간 전 까지..
sourceBuilder.query(QueryBuilders.rangeQuery("@timestamp").gte(startMillis).lte(endMillis));
// log 중 queryString 기준으로 count 집계 후 top 5 추출..
sourceBuilder.aggregation(AggregationBuilders.terms("duplicate_messages")
.field("pecial_flag_name.keyword")
.size(5));
// application 으로 시작하는 index 에서 검색..
SearchRequest searchRequest = new SearchRequest("accesslogs*");
searchRequest.source(sourceBuilder);
// 검색 결과
SearchResponse response = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
// 검색 결과에서 집계결과만 빼옴..
Terms duplicateMessages = response.getAggregations().get("duplicate_messages");
if (duplicateMessages != null) {
// 집계결과를 DTO로 변환..
for (Terms.Bucket bucket : duplicateMessages.getBuckets()) {
String key = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
RealTimeSearchKeyword realTimeSearchKeyword = new RealTimeSearchKeyword(key, docCount);
realTimeSearchKeywords.add(realTimeSearchKeyword);
}
}
return realTimeSearchKeywords;
}요청을 하게 되면 사용자들의 로그의 집계 데이터에 따라..

위와 같은 데이터를 받게 된다. count는 검색이 된 횟수이다.
따라서 저 데이터를 받아서 프론트 쪽에서는
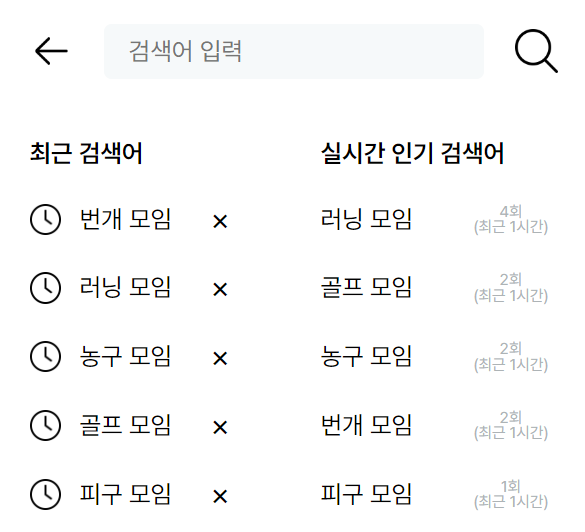
이런식으로 구현을 해줬다. 타 사이트 같은 경우에 몇회 검색이 되었는지 노출이 되진 않지만 나는 어차피 기능 구현한 김에 노출 시켜줬다.
검색어 자동완성
자동완성 검색어도 실시간 인기 검색어 처럼 구조는 같다.
자동완성 검색어는 이전에 포스팅 했던 search_as_you_type 을 사용할 것 이다.
1. 먼저 색인을 해주자
{
"properties" : {
"name" : {"type" : "search_as_you_type", "analyzer" : "custom_analyzer"}
}
}
{
"analysis": {
"analyzer": {
"korean": {
"type": "nori"
},
"custom_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "custom_synonym_filter"]
}
},
"filter": {
"custom_synonym_filter": {
"type": "synonym",
"synonyms_path": "synonyms.txt"
}
}
}
}
type을 search_as_you_type 로 해주고, 분석기는 nori 와 custom 을 달아주었다. custom 분석기는 동의어 사전으로 사용할 예정이다.
자동완성을 해주는 기준 데이터는 유저가 검색을 하면서 쌓은 로그 + 현재 만들어져 있는 모임의 이름이다.
query
POST accesslogs/_search
{
"query": {
"bool": {
"must": {
"multi_match": {
"query": "우유",
"fields": ["name", "name._2gram", "name._3gram"],
"fuzziness": 2
}
}
}
},
"size": 0,
"aggs": {
"duplicate_messages": {
"terms": {
"field": "pecial_flag_name.keyword",
"size": 5
}
}
}
}kibana 에서 위와 같은 쿼리로 검색을 할 시

우유 로 검색했지만 그릭요거트 까지 검색되는걸 볼 수 있다. 이유는 "fuzziness": 2로 주었기 때문이다. 2글자에 "fuzziness": 2 로 주니 전체가 다 나온듯 하여 auto 로 바꿔주었다.
그리고 count 는 유저가 검색한 횟수인데 이 횟수를 토대로 자동완성 검색을 했을 시 가중치를 적용하여 많이 검색한 검색어가 상위로 노출되게 끔 할 수 있다.
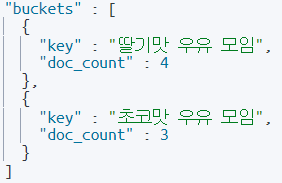
auto 로 바꿔주니 아래와 같은 데이터를 볼 수 있음. 또는
POST accesslogs/_search
{
"query": {
"bool": {
"must": {
"multi_match": {
"query": "우유",
"fields": ["name", "name._2gram", "name._3gram"],
"fuzziness": 2
}
}
}
},
"size": 0,
"aggs": {
"duplicate_messages": {
"terms": {
"field": "pecial_flag_name.keyword",
"size": 5
}
}
},
"min_score": 0.1
}2를 주되 "min_score": 0.1 를 활용하는 방법이 있다. 하지만 이는 완벽한 테스트는 되지 않았으므로 "fuzziness": 2를 상황에 맞게 주는게 옳은 방법 인 것 같다.
프론트 적용
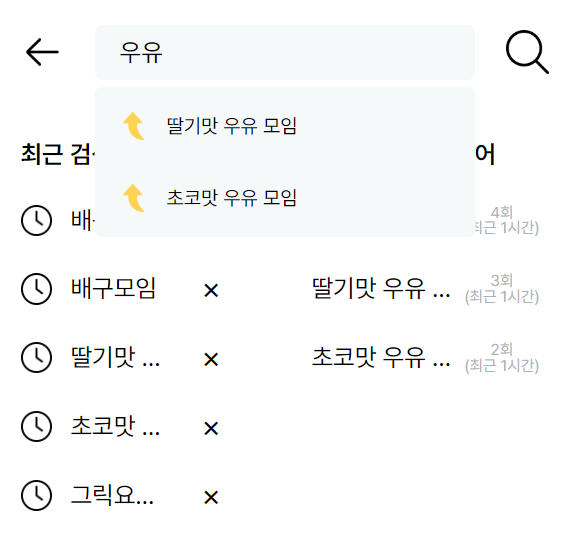
아래처럼 적용된 모습을 볼 수 있음.
동의어
삼성전자, 삼전, 삼자, 삼성, 삼바
위의 내용이 담긴 파일을 elasticsearch-7.2.0\config 경로에
synonyms.txt을 저장 해 주고 색인할 때 분석기를 적용해줬다.
POST accesslogs/_search
{
"query": {
"bool": {
"must": {
"multi_match": {
"query": "삼전",
"fields": ["name", "name._2gram", "name._3gram"],
"fuzziness": "auto"
}
}
}
},
"size": 0,
"aggs": {
"duplicate_messages": {
"terms": {
"field": "pecial_flag_name.keyword",
"size": 5
}
}
}
}결과는 ?
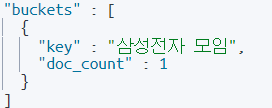
삼성전자, 삼전, 삼자, 삼성, 삼바 모두 같은 데이터를 출력한다.
프론트는 ?
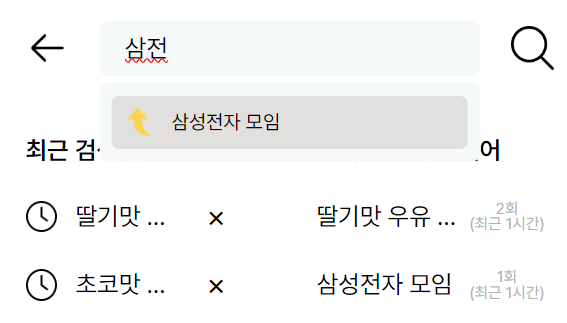
역시 잘 되는 모습.
java code
@Override
public List<RealTimeSearchKeyword> getSuggestKeywords(String name) throws IOException {
// 추천 검색어 담을 List 준비
List<RealTimeSearchKeyword> suggestKeywords = new ArrayList<>();
// Elasticsearch 질의 생성
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// log 중 queryString 기준으로 count 집계 후 top 5 추출..( 가중치 역할 )
sourceBuilder.aggregation(AggregationBuilders.terms("duplicate_messages")
.field("pecial_flag_name.keyword")
.size(5));
// multi_match 쿼리 생성
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(name)
.field("name")
.field("name._2gram")
.field("name._3gram")
.fuzziness(name.length() < 3 ? "auto" : 2);
// Bool 쿼리로 조합하고 min_score 추가
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(multiMatchQueryBuilder);
// 검색 결과에서 최소 점수를 지정
sourceBuilder.query(boolQueryBuilder)
.minScore(0.1F);
sourceBuilder.query(boolQueryBuilder);
// application 으로 시작하는 index 에서 검색..
SearchRequest searchRequest = new SearchRequest("accesslogs*");
searchRequest.source(sourceBuilder);
// 검색 결과
SearchResponse response = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
// 검색 결과에서 집계결과만 빼옴..
Terms duplicateMessages = response.getAggregations().get("duplicate_messages");
if (duplicateMessages != null) {
// 집계결과를 DTO로 변환..
for (Terms.Bucket bucket : duplicateMessages.getBuckets()) {
String key = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
RealTimeSearchKeyword realTimeSearchKeyword = new RealTimeSearchKeyword(key, docCount);
suggestKeywords.add(realTimeSearchKeyword);
}
}
// 커뮤니티 이름으로도 검색..
List<Community> allByName = communityRepository.findAllByName(name);
for (Community community : allByName) {
RealTimeSearchKeyword realTimeSearchKeyword = new RealTimeSearchKeyword(community.getName(), 1L);
suggestKeywords.add(realTimeSearchKeyword);
}
return suggestKeywords;
}java API 로는 위의 코드로 구현하였다.
오탈자 추천 검색어
일단 오탈자 추천 검색어를 위해 아래와 같이 색인을 해줬다.
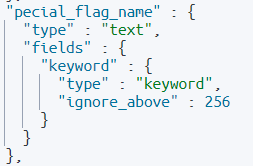
query
제왕골프 라는 데이터를 가지고 있고, 일부로 오타를 내서 제왕굴프 라는 단어를 fuzzy 검색 해보겠다. "fuzziness"는 2 로 주겠다.
POST /accesslogs/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"pecial_flag_name": "제왕굴프"
}
},
{
"fuzzy": {
"pecial_flag_name.keyword": {
"value": "제왕굴프",
"fuzziness": 2
}
}
}
]
}
}
}결과는 ?
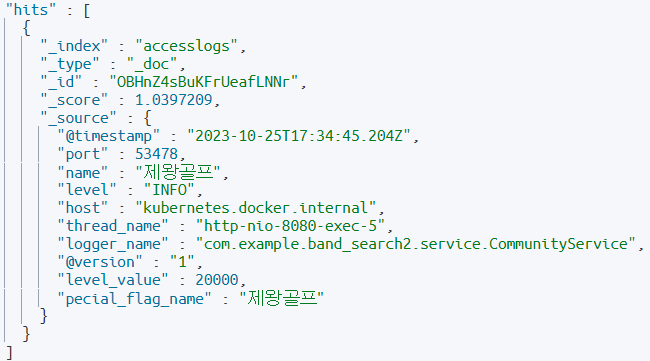
오탈자 예상 추천 검색어를 받아올 수 있다.
한번 더 테스트 해보자.
고의적으로 "딸기맛 유우" 로 검색을 해보자
POST /accesslogs/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"pecial_flag_name": "딸기맛 유우"
}
},
{
"fuzzy": {
"pecial_flag_name.keyword": {
"value": "딸기맛 유우",
"fuzziness": 2
}
}
}
]
}
}
}결과는 ?

원하는 data를 받아올 수 있다.
모임 통합 검색
통합검색은 ES에 올라가 있는 모임 데이터 에서 모임 이름과 모임 설명에 텍스트가 포함된 결과만 도출해낸다.
아키텍처 간소화를 할 수 있을까 ?
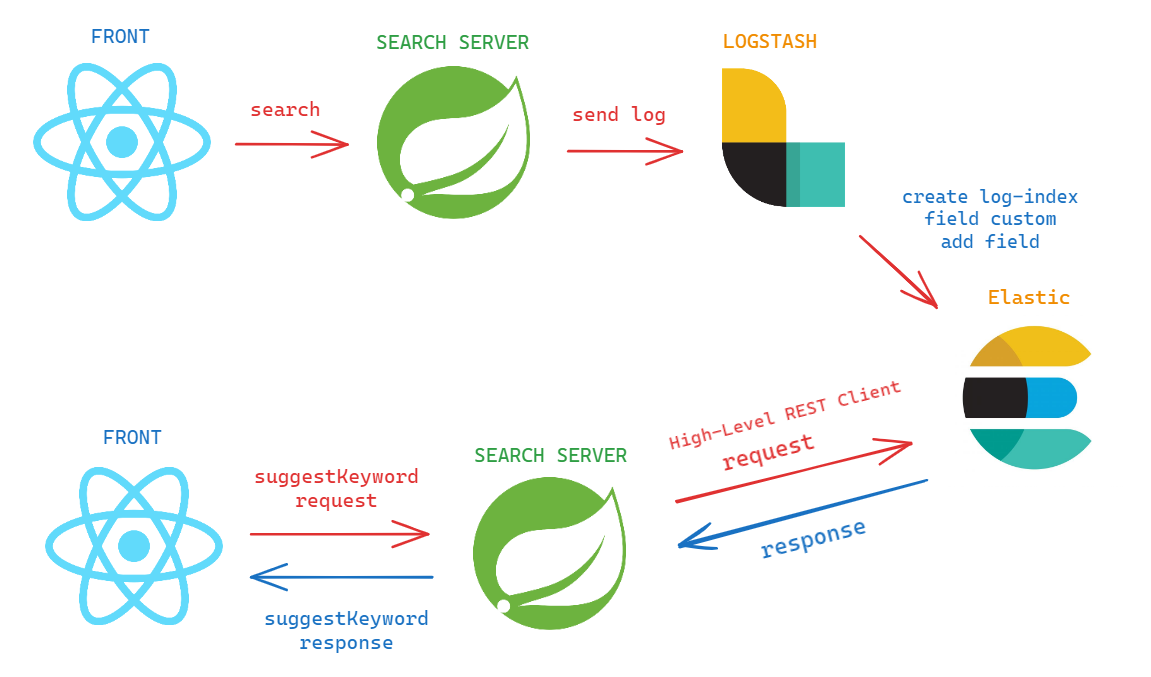
현재 아키텍처는 유저들의 검색로그를 먼저 만들고 그걸 토대로 실시간 검색을 가져고오 있다.
그런데 front 에서 꼭 search server를 들려야할까 ?
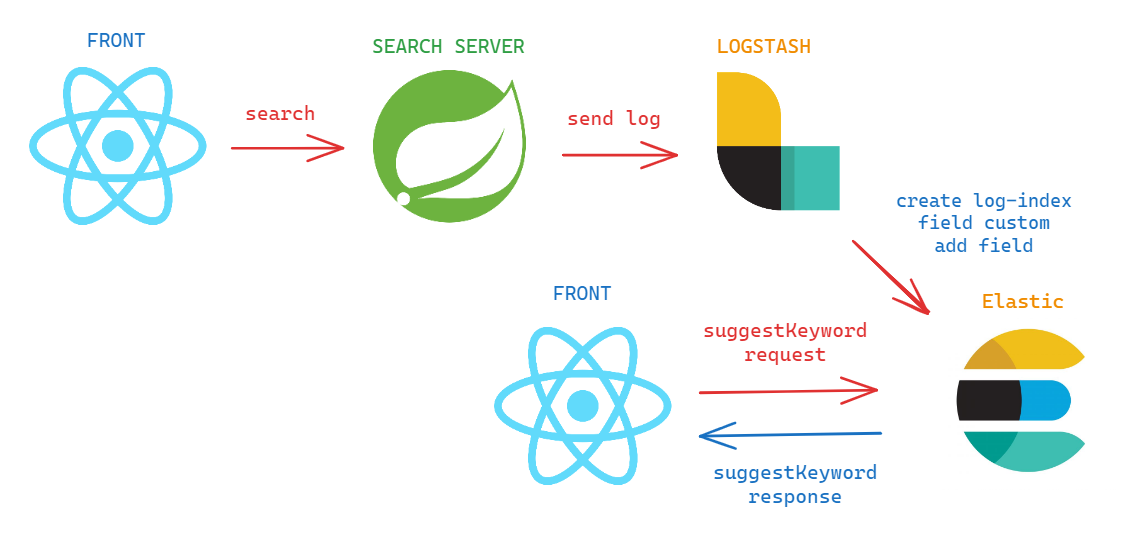
위와 같은 그림으로 로그는 search server에서 수집해야하기 때문에 어쩔 수 없다고 해도 실시간 검색어를 받아올 때 search server를 들려야 하는 이유는 뭘까 ?
몇몇개의 장단점을 유추해보자.
search server 경유에 대한 장단점
장점
-
보안 및 권한 관리 : 백엔드에서 Elasticsearch와 통신하므로 보안 및 권한 관리를 중앙 집중화할 수 있다. 백엔드에서 인증 및 권한 검사를 수행할 수 있다.
-
로직 분리 : 프론트엔드와 Elasticsearch 간의 로직을 백엔드에서 처리하여 프론트엔드는 더 간단한 구조를 유지할 수 있다.
단점:
-
지연 시간 : 백엔드를 통해 데이터를 가져오므로 추가적인 네트워크 지연 시간이 발생할 수 있다.
-
복잡성 : 백엔드 서버를 유지하고 관리해야 하므로 시스템이 더 복잡해질 수 있습니다.
search server 를 경유하지 않을 경우
client 에서 단순 axios 와 같은 http통신 라이브러리로 바로 es로 쏘기 보다는 아래와 같은 라이브러리를 사용하도록 하자.
이유는 보안, 에러 처리, 성능 최적화 및 유지보수 측면이 있다.
npm install @elastic/elasticsearchconst { Client } = require('@elastic/elasticsearch');
const client = new Client({ node: 'http://localhost:9200' });
async function search() {
const response = await client.search({
index: 'index_name',
body: {
query: {
match: { field_name: '검색어' }
}
}
});
console.log(response.body.hits.hits);
}
search();형식만 잘 맞춰 쓰고 실시간집계 요청처럼 단순 GET 요청은 이런 방법도 괜찮지 않을까 싶기도 하다.
