
간단한 서비스 소개
다양한 관심사를 가진 사람들이 모여 소규모로 모임을 구성하고 활동하는 플랫폼을 제공하는 서비스 입니다.
서비스의 목적
소모임은 사용자들에게 특정 주제에 대한 깊이 있는 소통과 친목을 제공하여 다양한 취향을 공유하고 형성할 수 있는 온라인 커뮤니티를 지향 합니다.
서비스의 특징과 장점
소모임 서비스는 사용자들에게 맞춤형활동과 다양한 친구들과의 소통 기회를 제공하여 더욱 풍부하고 유익한 온라인 경험을 제공합니다.
MSA 서비스 개념도
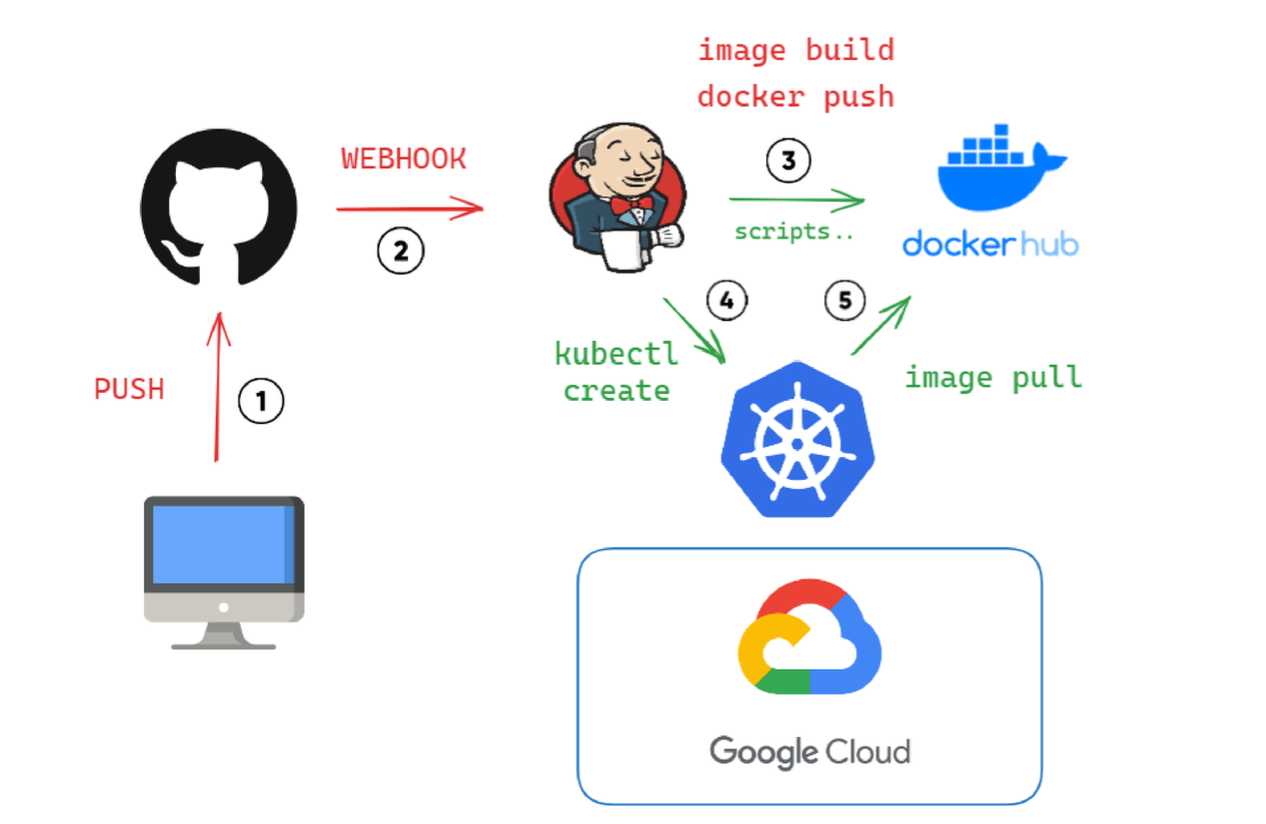
간단하게 설명하면 jenkins 에 git push webhook 을 걸어놓은 상태이며, 업데이트가 될 때 마다 이미지를 빌드하여 docker hub 에 push 합니다.
각 이미지에 해당하는 서버가 빌드되어 있고, update가 된 이미지는 kube 에서 관리 합니다.
개발 환경
- React
- Java (JDK 17)
- SpringBoot, JPA
- Kafka & Kafka Connect (Debezium)
- DB - Mysql, Elasticsearch, Redis, Mongo
- INFRA - docker, kubernetes, Jenkins
- Collaboration - GitHub
핵심기능소개
- 내 취미와 연관된 모임 생성 및 활동
- 내 취미와 연관된 사진 게시 및 게시판 기능
- 모임 일정 만들기 기능
- 모임 일정 단체 채팅방
- 내 취미와 관련된 모임 추천 기능
- 모임정보에 대한 실시간 알람 기능
- 실시간 인기 검색어 기능
- 오탈자 추천 기능
- 검색어자동완성기능
- 위치기반모임추천(beta)
ERD설계
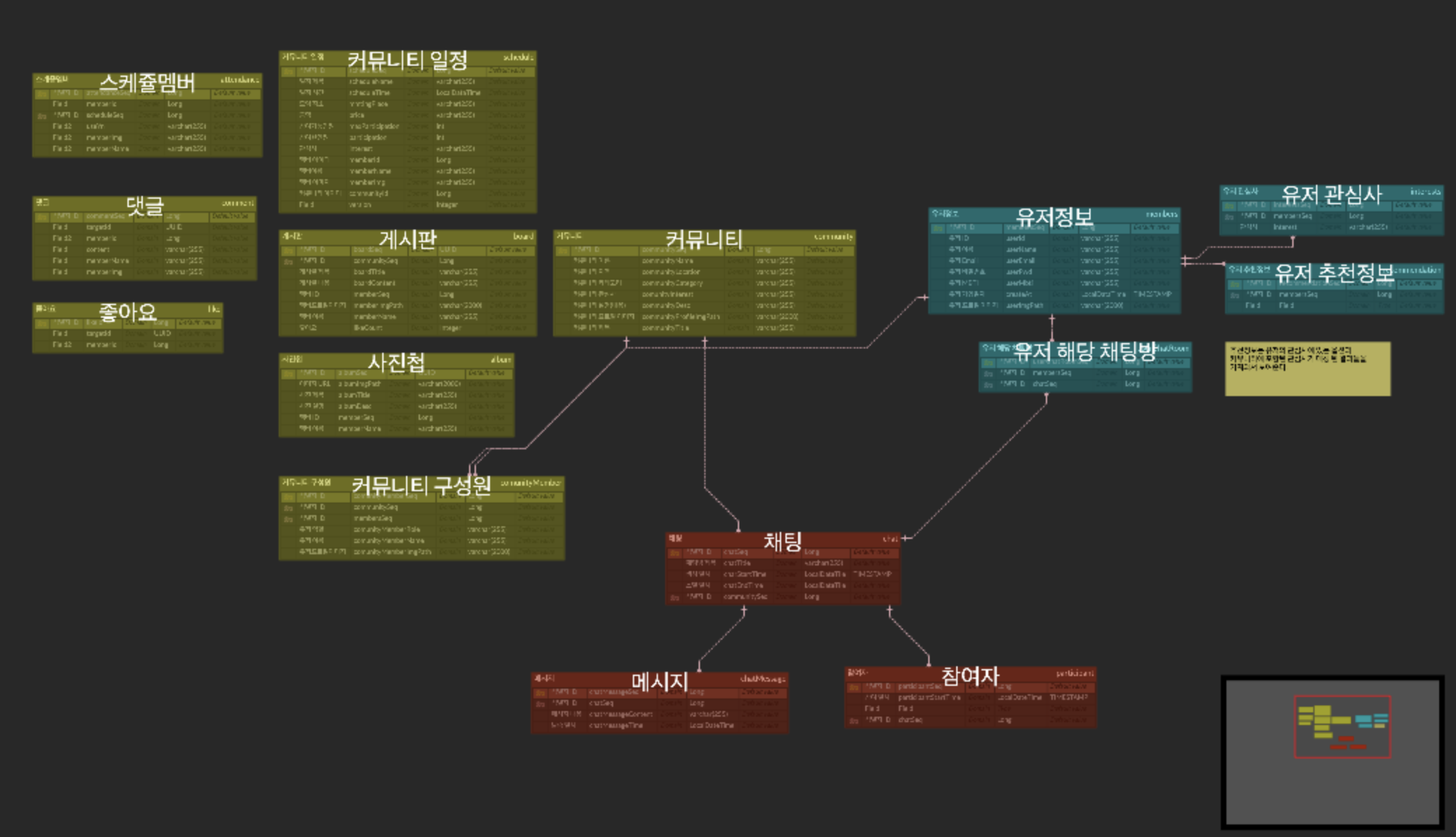
(초기 기획이랑 달라진 부분이 많아서 추후 수정이 필요한 부분이 있긴 하다.)
화면 프로토타입
메인화면, 메뉴(로그인전/후)
회원가입, 마이페이지
모임상세페이지,모임일정, 모임가입리스트, 게시판
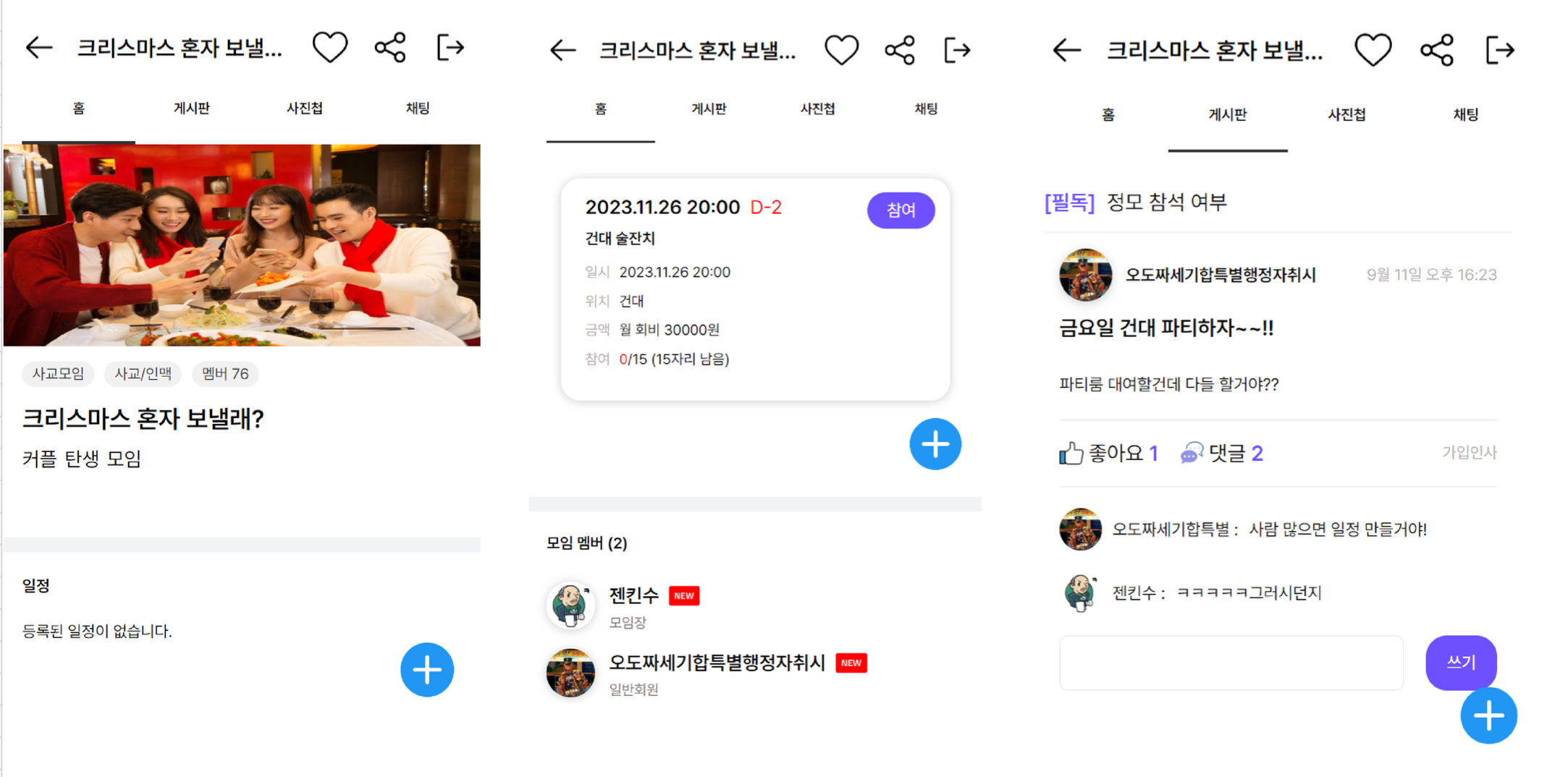
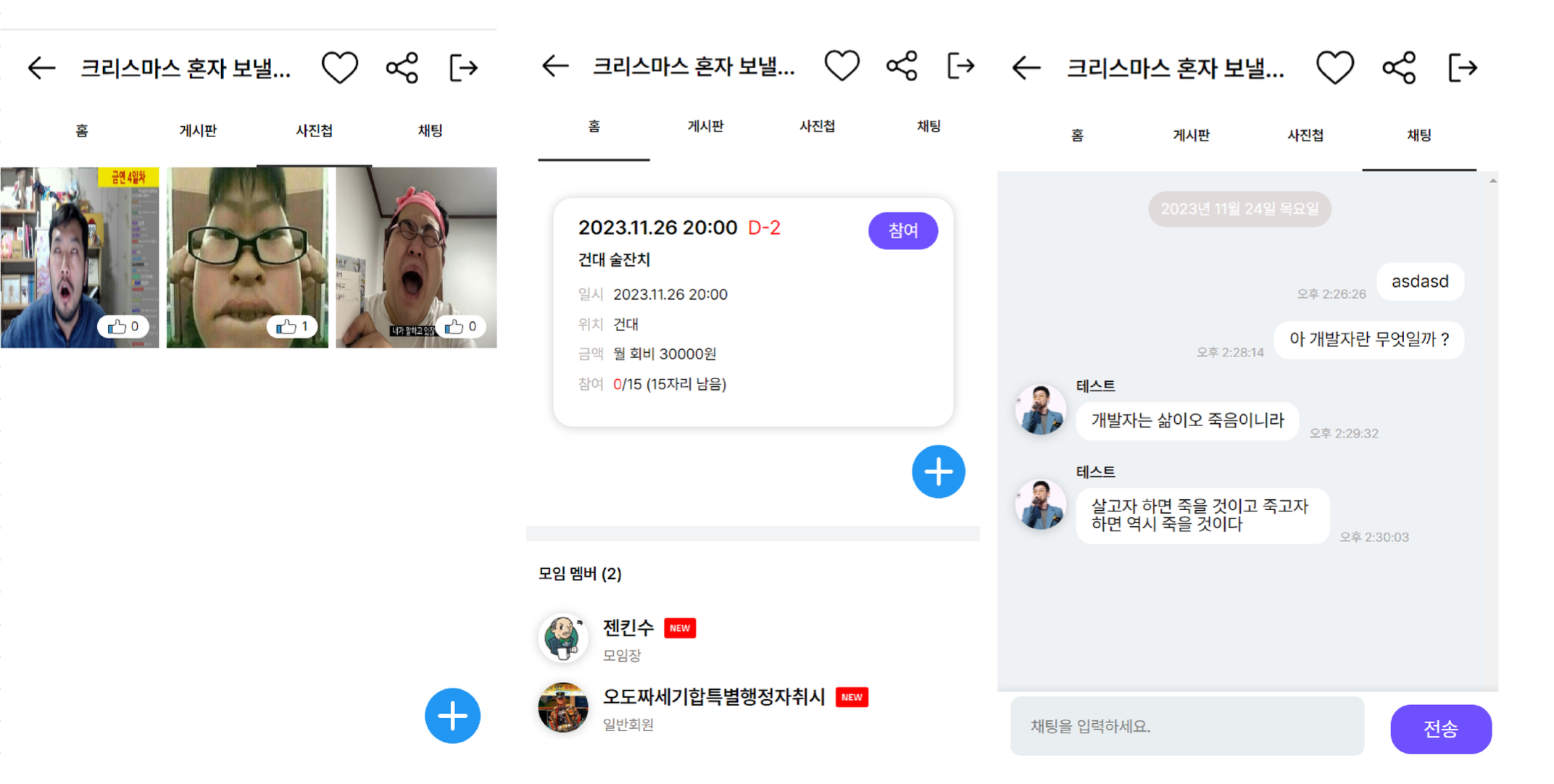
모임앨범게시판,모임단체채팅
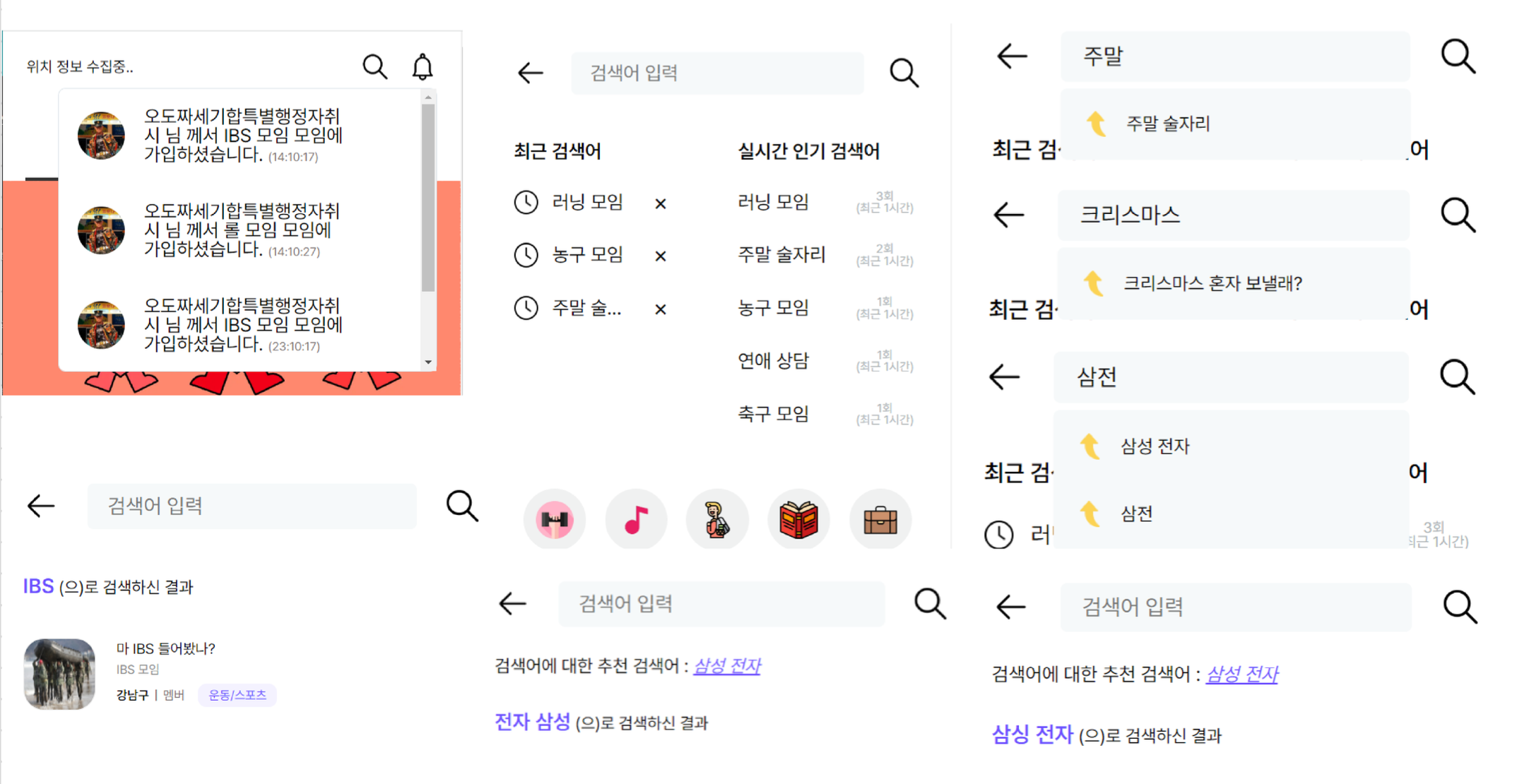
실시간알람, 실시간인기검색어, 연관검색어, 오탈자추천
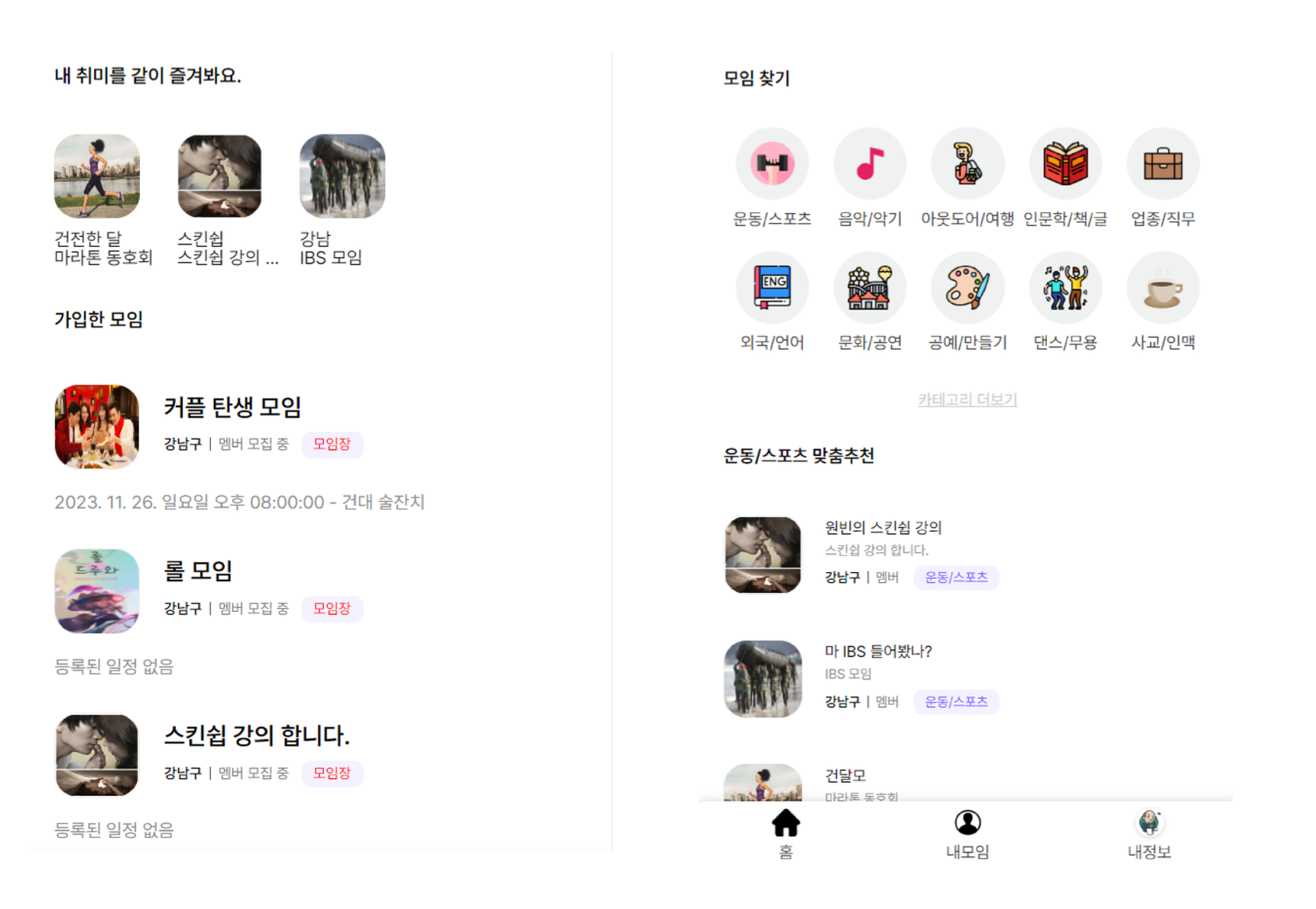
내모임가입정보, 모임추천
(우리들의 소모임 에 배포 되어 있으나.. 무료 요금제 만료로 인해 현재는 운영중이지 않은 상태)
고찰
React - CSR 을 선택한 이유
-
우린 클라우드의 리전을 최대한 싼 곳으로 고를 것이기 때문에.. 웹의 속도가 느려질 수 있다.네이티브 앱과 비슷한 빠른 인터렉션을 구현하고 싶기 때문에 CSR 채택
-
우리의 자원은 한정적이기 때문에 View 렌더링을 브라우저에게 담당시킴으로서 서버의 트래픽을 줄이고 싶었음.
-
물론 SEO 를 조금 더 신경써줘야 하지만 Helmet같은 라이브러리로 어느정도 커버할 수 있다고 생각함. (실제로 다른 프로젝트에서 경험 하였음)
왜 어디서 NoSQL 사용?
-
단순 데이터 삽입, 조회에서 RDB 보다 우수한 성능을 보이기에 사용함
-
채팅 & 알림 저장 기능에서 사용
-
Redis 는 멀티소켓 서버 구현 시 유저의 모임 가입 리스트 캐싱 DB로 사용. (자주 변하지 않는 데이터 인데 매번 RDB를 조회하기 부담스러웠음)
왜 ElasticSearch 사용?
-
실검 및 여러가지 검색 기능을 위해 사용하였는데 처음엔 AWS open Search 고려하였지만 자금 이슈 때문에 ES를 직접 사용.
-
검색 서비스를 위해선 불필요한 행위를 줄이고 검색어에 대한 결과를 빠르게 찾아와야 한다. 하지만 RDBMS의 경우, 인덱스 같은 설정을 해주지 않는 이상 WHERE, LIKE 절 에서 성능이슈를 야기할 수 있다.
-
이에 비해 ES는 분석된 키워드들을 바탕으로 문서를 찾아가는 형식의 역색인 방식을 이용하여 방대한 양의 데이터의 검색,집계 등 기능을 신속하게 처리할 수 있다.
-
또한 ES 에서 제공하는 여러가지 분석기는 사용자 경험을 올려줄 수 있으며 이 모든 기능들을 무료로 사용할 수 있기 때문.
-
하지만 용량 부담이 있었기에 무료 클라우드 요금제를 사용하는 입장에선 인스턴스를 나눠줘야 했었다.
왜 테이블 정규화 안함?
update 요청보다 get 요청이 압도적으로 많은 경우에는 각 서버에서 데이터를 요청하는 것보다 특정 필드를 역정규화하는 방식으로 데이터베이스를 설계함.
ex) RDB community와 ES community 의 경우도 이와 같고, RDB member 필드 중에서 이미지, 닉네임, 아이디를 역 정규화시킴.
서버가 많이 분리되어 있는데 트랜잭션 관리는 ?
-
MySQL DB 간의 트랜잭션 관리는 Saga Pattern 을 도입하기 위해서 공부 중에 있음.
-
이기종 DB 의 트랜잭션은 Kafka Connect를 활용하여 트랜잭션을 관리하였음. (MySQL community 와 ES community)
트러블슈팅 (1) - 동시성 이슈
문제점 및 이슈
모임에 일정참여라는 기능이 있는데 해당 기능에는 인원이 제한되어있다.
많은 유저가 한꺼번에 가입을 할 시 레이스 컨디션(두 개 이상의 프로세스 혹은 스레드가 공유 자원을 서로 사용하려고 하는 현상인) 발생하여 데이터 정합성에 문제가 생김.
시도한 해결방안
-
낙관적 락
update 를 수행할 때 현재 내가 읽은 버전이 맞는지 확인하며 업데이트 하고, 자원에 락을 걸어 선점하지 않으면서 동시성 문제가 발생하면 그때가서 처리하는 낙관적 락 방식. -
Redis - incr
Redis 의 incr 은 key 에 대한 value를 1씩 늘려주는 기능인데, 싱글쓰레드 기반이라 레이스 컨디션을 해결 할 수 있을 뿐 아니라 성능도 굉장히 빠르다. -
Kafka
메시지 큐 & 이벤트 스트리밍 기반의 kafka 는 메시지가 생산되면 해당 메시지는 특정 파티션 내에서 순서대로 기록되고 이를 통해 메시지의 순서와 일관성을 유지하며 레이스 컨디션을 방지할 수 있다.
채택방식과 이유
낙관적 락
해당 기능은 메인 서비스는 아니기 때문에 비교적 적은 충돌이 발생하는 환경이라 판단,낙관적 락은 대부분의 시간 동안은 락을 사용하지 않기 때문에 성능이 향상될 수 있다고 생각하여 채택 함.
Redis - inca 방식도 괜찮지만 이 방식은 단순작업은 굉장히 효율적으로 처리할 수 있지만, 증가한 value값으로 추후 다른 작업이 생길 때 데이터가 일치하지 않을 수 있음.
예를 들면 INCR 명령어가 실행된 이후 GET key를 통해 현재 카운터 값을 얻는 동안, 다른 클라이언트에서 같은 key에 대해 INCR를 수행할 수 있습니다. 이로 인해 GET key에서 얻은 value가 실제로는 이전 카운터 값이 아닐 수 있습니다.
Kafka는 다른 기능에서 많이 사용하고 있기 때문에 비교적 간단한 기능이기 때문인 이 기능 때문에 또 하나의 토픽을 만들고 싶지는 않았음.
결과
동시성 문제 해결함
배운점
동시성 문제를 해결하는 것엔 많은 방법들이 있지만, 어떤 것이 더 좋은지는 사용 사례 및 요구 사항에 따라 갈라지고, 각 접근 방식에 장단점이 있기 때문에 상황에 따라 고려를 해봐야 할 것 같다.
트러블슈팅 (2) - spring cloud 성능이슈
문제점 및 이슈
우리의 프로젝트 아키텍처는 Spring Cloud 생태계에 구축이 되어 있었다. 지금은 알람 기능이 SSE 방식으로 구현 되어 있지만, 초기 기획은 소켓을 열기로 하였다. 이 때 멀티소켓서버를 구축하다가 부하테스트를 하였는데, 이 때 초당 1000개의 요청을 5초정도 버텨주었지만 그 이상은 버틸 수 없었다.
이것을 보아 , 성능이 좋지 않은 클라우드에 배포될 경우 우리 프로젝트는 단일 Eureka Server 에 의존하고 있기 때문에 문제가 생길 수 있겠다 라는 생각이 들었다.
물론 GateWay 서버증설 혹은 Eureka Cluster를 구축하는 방법도 있겠지만,
더 많은 기대값을 도출해내기 위해 쿠버네티스를 사용하기로 하였음
시도한 해결방안
Spring Cloud 위에서 구축되어 있던 환경 및 코드를 쿠버네티스 환경으로 변경
결과
스케일링 및 로드 밸런싱
- 쿠버네티스는 수평 스케일링을 지원하여 서비스 인스턴스의 수를 쉽게 조절할 수 있습니다. 또한, 서비스 디스커버리 및 로드 밸런싱을 쿠버네티스가 자동으로 처리하므로 Gateway나 Eureka 등에서 발생하는 로드 밸런싱 및 디스커버리 문제를 쿠버네티스가 관리합니다.
고가용성
- 쿠버네티스는 여러 노드에 서비스 인스턴스를 분산 배포할 수 있고, 고가용성을 위해 자동으로 재구동되는 기능을 제공합니다. 따라서 단일 장애 지점이나 서비스 다운타임을 최소화할 수 있습니다.
설정 및 스크립팅
- 쿠버네티스는 YAML 파일로 선언적으로 클러스터를 관리할 수 있습니다. 이를 통해 각 서비스의 설정이나 배포를 관리하고, 스크립트를 사용하여 자동화된 배포 프로세스를 구축할 수 있습니다.
상태 관리 및 롤링 업데이트
- 쿠버네티스는 롤링 업데이트와 롤백을 지원하여 서비스를 업데이트하거나 롤백하는 과정을 쉽게 처리할 수 있습니다.
서비스 디스커버리 - 쿠버네티스는 내장된 DNS 서비스 디스커버리를 제공하여 서비스 이름을 통해 서로 통신할 수 있게 해줍니다. 이를 통해 서비스 디스커버리 문제를 간소화할 수 있습니다.
배운점
쿠버네티스 클러스터의 강력하고 편리한 기능에 대해 조금 더 알게 되었음.
트러블슈팅 (3) - SSE ( 알람 기능 )
알람 기능은 kafka + sse 로 구현되었음.
문제점 및 이슈
-
SseEvent의 data전송시 String으로 보내야만함. -> 원본객체를 그대로 보낼 경우 연결이 즉시 종료됩니다.
-
503 Service Unavailable -> SSE 응답을 할 때 아무런 이벤트도 보내지 않으면 재연결 요청을 보낼때나, 아니면 연결 요청 자체에서 오류가 발생합니다. 따라서 첫 SSE 응답을 보낼 시에는 반드시 더미 데이터라도 넣어서 데이터를 전달해야합니다.
-
헤더에 토큰 전달 -> SSE 연결 요청을 할 때 헤더에 JWT 보내줘야 한다면.. EventSource 인터페이스는 기본적으로 헤더 전달을 지원하지 않는 문제가 있기 때문에. event-source-polyfill 을 사용하면 헤더를 함께 보낼 수 있습니다.
-
JPA 사용시 Connection 고갈 문제
- SSE 연결을 통해 서버와 클라이언트 간에 실시간 통신이 이루어집니다.
- SSE 연결을 위한 HTTP 연결이 계속 열려 있습니다.
- JPA를 사용하여 데이터베이스와 상호 작용을 하는 도중, open-in-view 속성이 true로 설정되어 있습니다.
여기서 문제 발생.
- open-in-view가 true로 설정되면, HTTP 요청이 처리되는 동안 Hibernate 세션이 열려 있습니다.
- SSE
- 연결이 열려 있는 동안에는 HTTP 연결이 계속 유지되므로, Hibernate 세션도 유지됩니다.
- Hibernate 세션의 유지는 데이터베이스와의 연결을 의미하며, 이는 Connection 고갈 문제로 이어질 수 있습니다.
따라서, SSE 연결이 오랫동안 열려 있는 상황에서는 open-in-view 속성을 false로 설정하는 것이 바람직하다.
트러블슈팅 (4) - 이기종 DB 의 트랜잭션 문제
문제점 및 이슈
서비스 중 커뮤니티를 생성하면 mysql 과 elasticsearch에 같이 데이터가 들어가야 하는데 요청이 조금 몰릴 시 둘중 하나에만 저장이 되는 현상을 목격 Delete 도 마찬가지
시도한 해결방안
분산트랜잭션을 위한 전통적인 여러가지 패턴이 있지만, 조금 더 확실한 분산 데이터 이동과 복제와 확장성을 위해서 Kafka Connect를 사용 하였음.
데이터베이스의 변경사항을 캡처하고 Kafka로 전송하는 방식에서 큰 차이가 있다.
-
JDBC Source Connector - 주로 주기적인 폴링(Polling) 방식을 사용하여 데이터베이스의 특정 테이블에서 변경된 데이터를 캡처합니다.
때문에 DB성능에 이슈가 생길 우려가 크다. -
Debezium Source Connector - 데이터베이스의 트랜잭션 로그를 읽어서 변경 사항을 캡처합니다. 이는 데이터베이스에 쿼리를 주기적으로 보내는 것이 아니라, 데이터베이스 내부의 로그를 읽어서 변경 사항을 감지합니다. 로그 기반의 방식을 사용하면 변경 사항을 실시간으로 캡처하고, 데이터베이스에 부하를 덜 주면서 효율적으로 동작할 수 있습니다.
-
또한 다양한 이기종 DB를 지원한다.
-
스키마 변환 및 매핑도 사용자가 커스텀 할 수 있으며, 변화하는 스키마에 유연하게 대응하기 위해 Debezium은 동적 필드 매핑도 지원한다.이는 스키마가 변경되더라도 적절히 데이터를 매핑하여 Kafka에 전송할 수 있도록 합니다.
하지만 여러가지 우려할 점도 있다.
-
Elasticsearch 에서 Index 가 생성 될 때 문서의 필드 구조에 따라 자동으로 매핑이 될 수 있는데, 문서에 필드의 수가 많고 , 여러가지 필드의 조합이 있을 경우 인덱스 크기가 증가하게 되고 매핑이 터질 수 있음. 따라서 미리 정의된 명시적 매핑을 사용하여 필요한 필드에 대한 매핑을 미리 지정 하는것이 속편한 것 같긴 하다.
-
Source connector 를 기동할 때 기동하는 시간동안 DB 에 global lock 을 획득하게 된다. 따라서 트래픽이 없는 시간에 기동하던지.. 클러스터를 구성하던지의 대안이 있다.
-
주고 받는 메시지 형식이 크고, 불필요한 필드도 있다. 이것은 데이터가 쌓이게 될 시 성능이슈를 기반한다. SMT 에서 어느정도 커스텀 할 수 있는 대안이 있고, 이 마저 쉬운 작업은 아니기 때문에 Avro 를 도입하는 대안이 있다.
-
주기적으로 변경점을 캡처하여 DML 을 실행하고 있을 때, 다른 세션에서 해당자원을 건드릴 경우 데이터 정합성에 문제가 생길 수 있다. 이는 데이터베이스 에서 사용하는 트랜잭션 격리 수준을 확인해봐야 할 것 같은데 아직 트러블 슈팅중에 있다.
-
단순 DML 의 동기화는 깔끔하게 처리 되지만 한쪽 DB 에는 카운트를 증가 시키고 다른 DB에선 내리고싶다거나 다른 추가적인 작업이 실행하기엔 조금 까다로워 보인다.
결과
DML 10만건을 진행하는 프로시저를 mysql 에서 실행했을 때 targetDB에도 정확하게 반영 됨.
배운점
이기종 DB의 동기화를 도와주는 kafka connect 와 CDC의 개념을 익힐 수 있었음.
트러블슈팅 (5) - Elastic Search Fuzzy 쿼리와 동의어 쿼리의 연동 불가 사항 개선
문제점 및 이슈
검색기능을 구현할 때 동의어 필터와 Fuzzy Query가 동시에 적용되지 않는
문제가 있었습니다.
시도한 해결방안
해당 문제를 해결하기 위하여 Open Source를 분석하였고,분석 결과 Fuzzy Query와 동의어 필터를 검색어에 필터링하는 방식은 지원되지 않음을 이해하였다.
결과
해당 부분을 개선하기 위해 동의어 필터를 색인시에 적용시키는
로직을 도입하여 문제를 해결하였습니다.
트러블슈팅 (6) - Elastic Search 로그 분석 시 매핑 폭발 문제
문제점 및 이슈
유저가 검색어를 요청할 때 스프링 서버에서 적절히 필터링 한 이후 로그백을 통해 Elastic Search로 로그를 보내는 형식으로 유저 검색을 Elastic Search에 저장했습니다. 이 때, 특정 로그를 ElasticSearch에서 커스텀하지 않은 방식으로 동적매핑하는 상황이 발생하였고, 이로 인해 Elastic Search Cluster가 작동 중지하는 상황이 발생하였습니다.
시도한 해결방안
- 명시적인 매핑 정의 ( 인덱스에 새로운 필드를 추가할 때 Elasticsearch가 자동으로 동적 매핑을 생성하지 않도록 하기 위해서 해당 필드에 대한 명시적인 매핑을 정의하였음.)
결과
명시적으로 매핑을 정의하니 동적 매핑 폭발에 대한 이슈는 생기지 않았다. 명시적 매핑 정의 방법 뿐만 아니라 아래의 방법들로도 제어가 가능하다.
-
dynamic Mapping의 제어: 동적 매핑을 완전히 비활성화하거나 필요한 필드만 동적 매핑을 허용하도록 설정할 수 있습니다. index.mapper.dynamic 설정을 사용하여 동적 매핑을 제어할 수 있다.
-
매핑 필터 사용: 필요한 경우, 매핑 필터를 사용하여 특정 필드 유형을 다른 유형으로 변경하거나 필드에서 제외할 수 있습니다.
프로젝트를 마치고 난 뒤 느낀 MSA 장 단점
장점 3가지
-
먼저 장점은 모놀로식 방식에서는 특정 서비스의 로직이 비 정상적으로 작동하면
서버 전체가 제대로 작동하지 않는 문제점이 있지만, MSA에서는 특정 서비스만 오작동하고, 나머지 서버는 원활하게 작동한다는 장점이 있습니다. (고가용성 특화) -
위의 장점과 유사하게 서비스 단위로 서버를 구축하다 보니, 특정 서비스의 구축, 삽입, 수정이 원활합니다.
-
마지막으로 각각의 서비스에 맞춰서 데이터베이스, 언어, 서버를 선택할 수 있다는 장점이 있습니다. 특정 서비스에 맞는 데이터베이스, 프레임워크 선택 등 최적화된 서버를 맞춤 방식으로 증설할 수 있는 장점이 있습니다. (이 프로젝트에선 채팅기능에 mongo, express 로 증설 하였음)
단점 3가지
-
서비스를 작은 단위로 나누다 보니 비정규화된 데이터베이스가 자주 발생하고, 이 문제를 해결하기 위한 트랜잭션 관리가 중요하다. 이 방식을 효율적으로 구현하기에는 많은 공부가 필요합니다.
-
테스트 코드를 작성하기 힘듭니다. 위에서 말한대로 특정 서비스에 특정 로직만 있다면 상관 없겠지만, 특정 서비스가 다른 서버의 서비스와 연동된다면 테스트 코드를 작성하기가 다소 어렵습니다.
-
마지막으로 효율적으로 구현하지 못한다면 오히려 성능과 비용이 모놀리식 보다 부담이 될 수 있습니다. 서비스가 커질수록 기존에 구축한 서버를 수정하는데 오히려 많은 비용이 들 수 있습니다.
