이 장에서는 리눅스의 텍스트를 효과적으로 처리하는 명령어들에 대해 알아본다.
wc : 바이트 수, 단어 수, 행 수 세기
순서대로 행 수, 단어 수, 바이트 수, 파일 이름을 의미한다.

그리고 각각을 -l, -w, -c 옵션으로 출력할 수 있다.

행 수를 출력하는 -l는 자주 사용되는데, 이를테면 한 행에 한 건의 데이터가 기록되어 있는 파일은 행 수를 세면 데이터의 총 건수를 확인할 수 있다.
그리고 다음과 같이 ls 명령어에 붙이면 파일과 디렉터리가 몇 개 있는지도 알 수 있다.

wc 명령어와 같은 필터 명령어들은 파일을 지정하지 않으면 표준 입력을 읽는다 하였다.
표준 입력을 사용하도록 명시적으로 지정하려면 -을 사용하기도 한다.

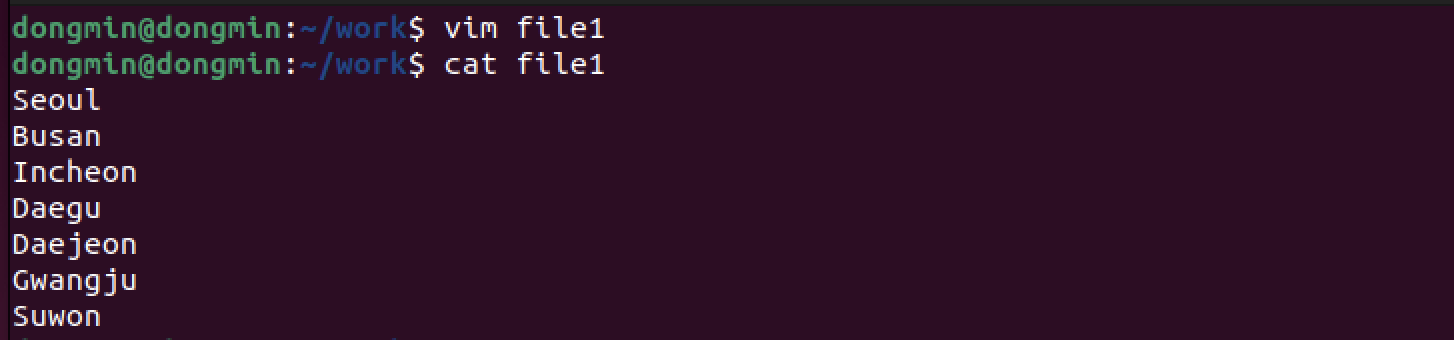
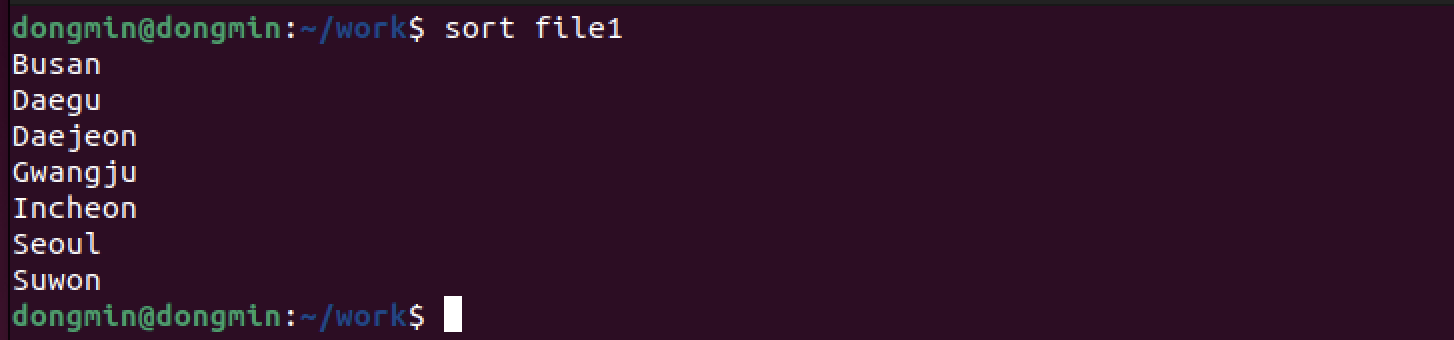
sort : 행 단위로 정렬하기
아무 옵션을 지정하지 않으면 알파벳순으로 정렬한다.
각 행의 특정 항목을 기준으로 정렬도 가능하다.
앞서 ps 명령어는 프로세스 ID를 기준으로 출력한다 하였다.
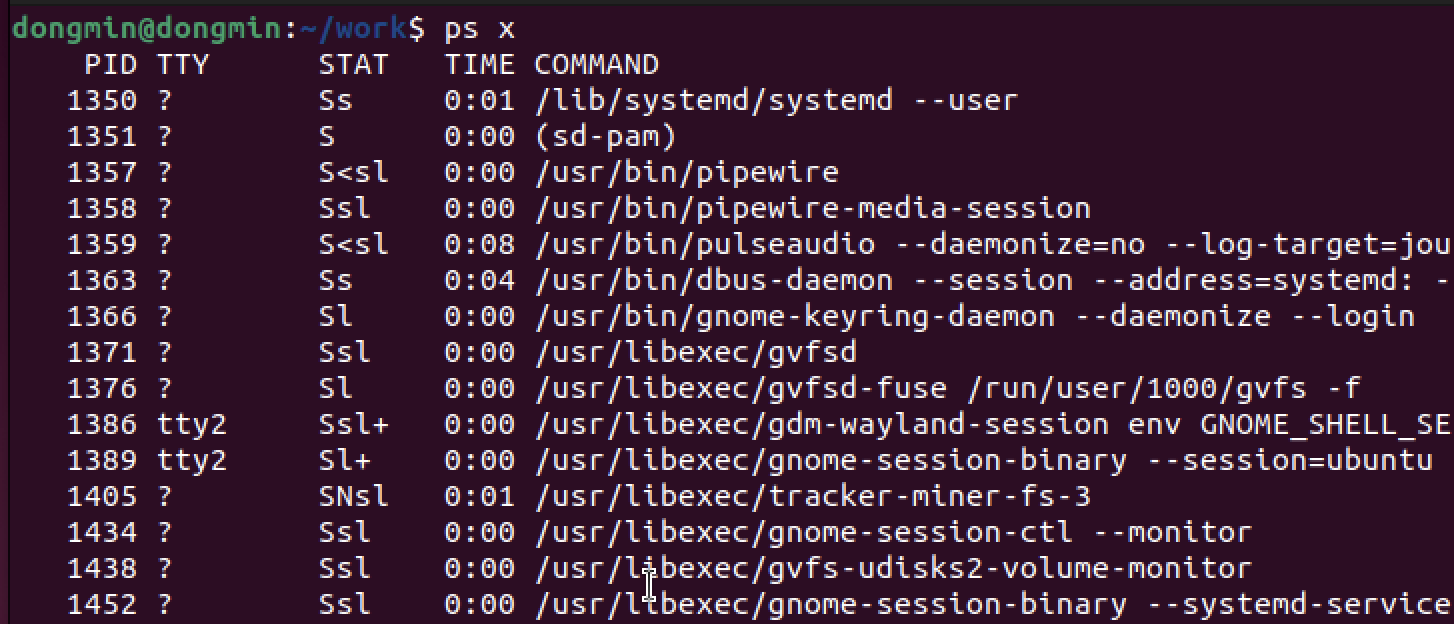
공백을 기준으로 필드가 구분되어 있음을 알 수 있는데, COMMAND를 기준으로 하고 싶다면 -k 옵션을 사용한다. (5는 COMMAND필드가 5번째이므로)
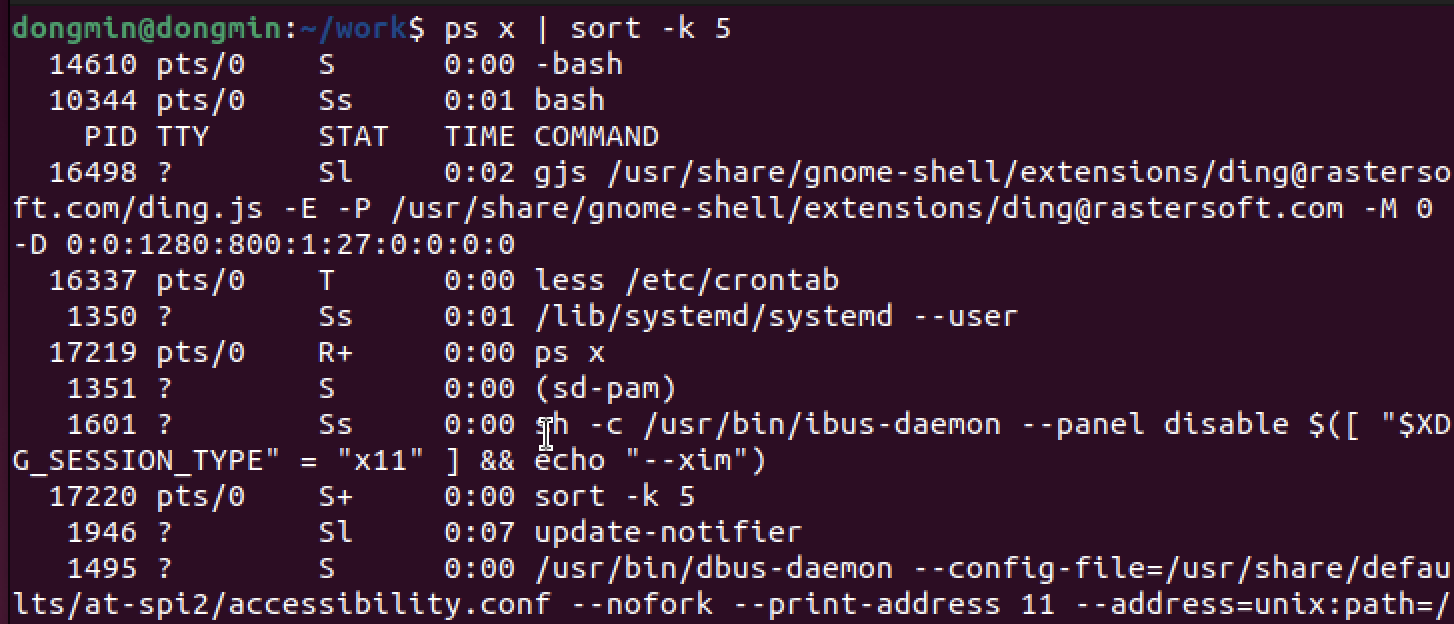
-n : 숫자 값으로 정렬
문자열을 숫자 값으로 인식하고 정렬하는 옵션이다.
-r : 역순으로 정렬
알파벳 내림차순으로 정렬한다
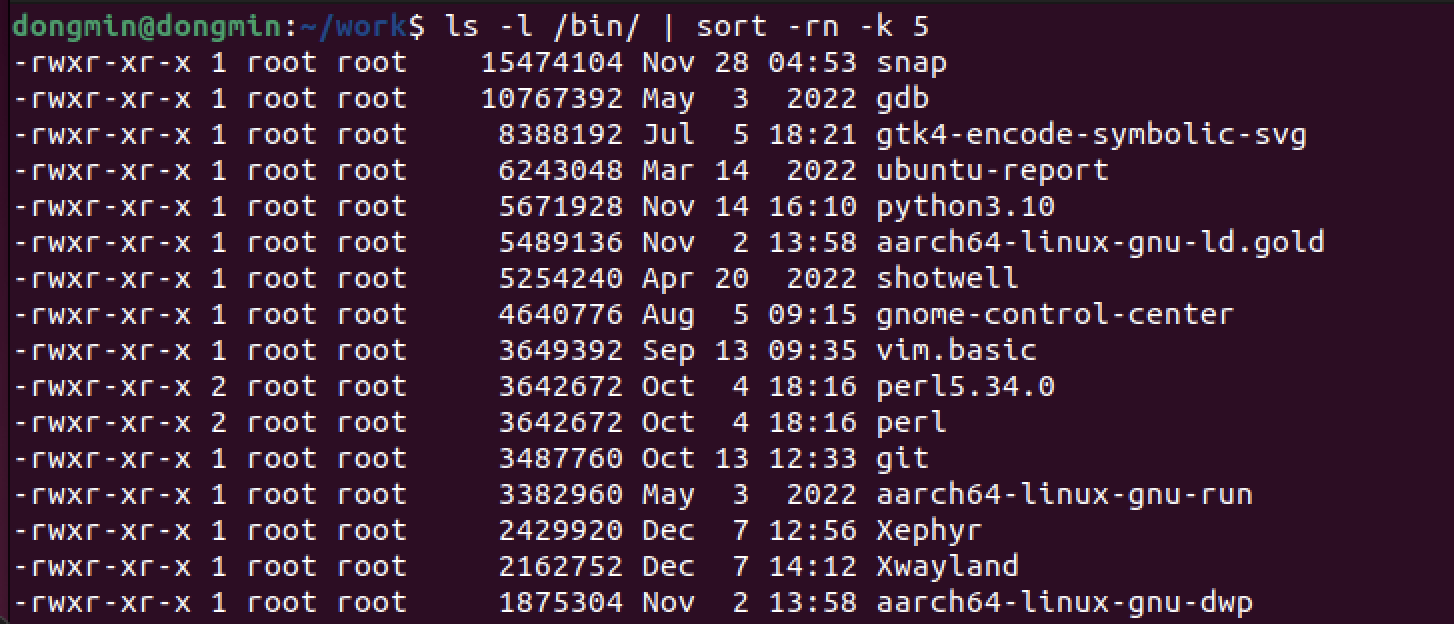
-rn : 숫자 값이 큰 순으로 정렬
5번째 필드인 파일 크기를 기준으로 크기가 큰 순으로 정렬한 것.
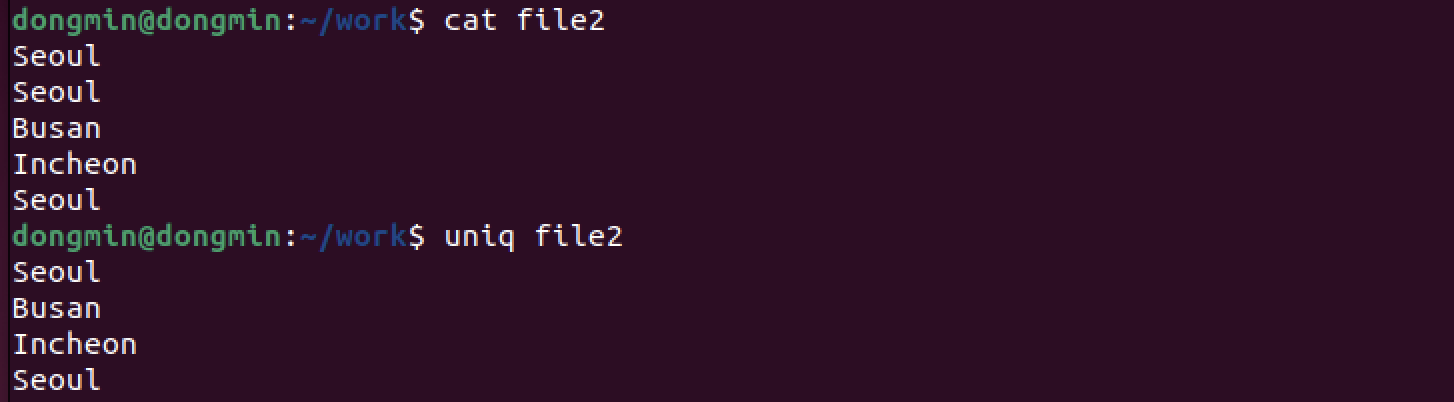
uniq : 중복 제거
연속된 중복 데이터를 하나만 출력하는 명령어
다만 연속되지 않은 중복 데이터는 없애지 않는다.
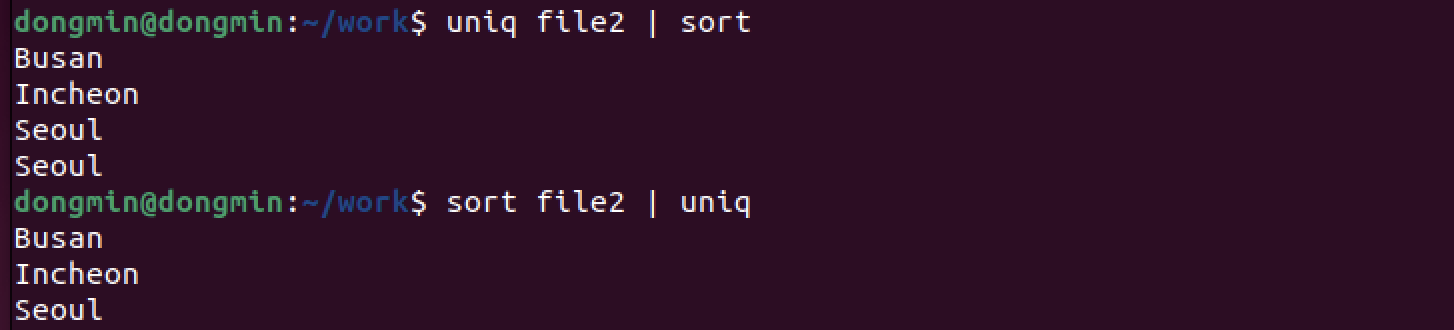
이때 sort를 하고 uniq을 실행하면 중복을 없앨 수 있다.
다음과 같이 파이프 라인 순서에 따라 결과물이 다를 수 있음을 유의하자.
sort 의 -u 옵션을 사용하면 중복 데이터를 한 번만 표시하여 중복을 없앨 수도 있다.

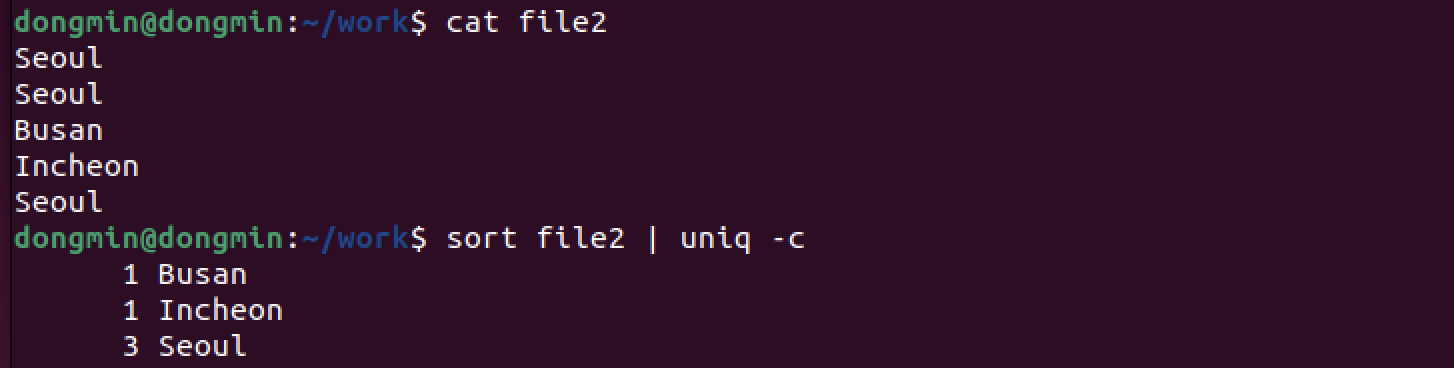
-c : 중복 데이터의 개수 세기
중복된 데이터의 개수를 알려준다.
중복이 가장 많은 순으로 출력

이처럼 데이터의 출현 빈도를 파악할 수 있겠다.
cut : 입력의 일부 추출하기
입력의 일부를 추출하여 출력하는 명령어
cut -d <구분자> -f <필드 번호> [<파일 이름>]
구분자로 지정한 문자를 기준으로 입력 데이터를 분할하여 그 중에서 <필드 번호>로 지정한 데이터만 출력한다.
-d로 구분자를 지정하지 않으면 기본으로 탭이 사용된다.
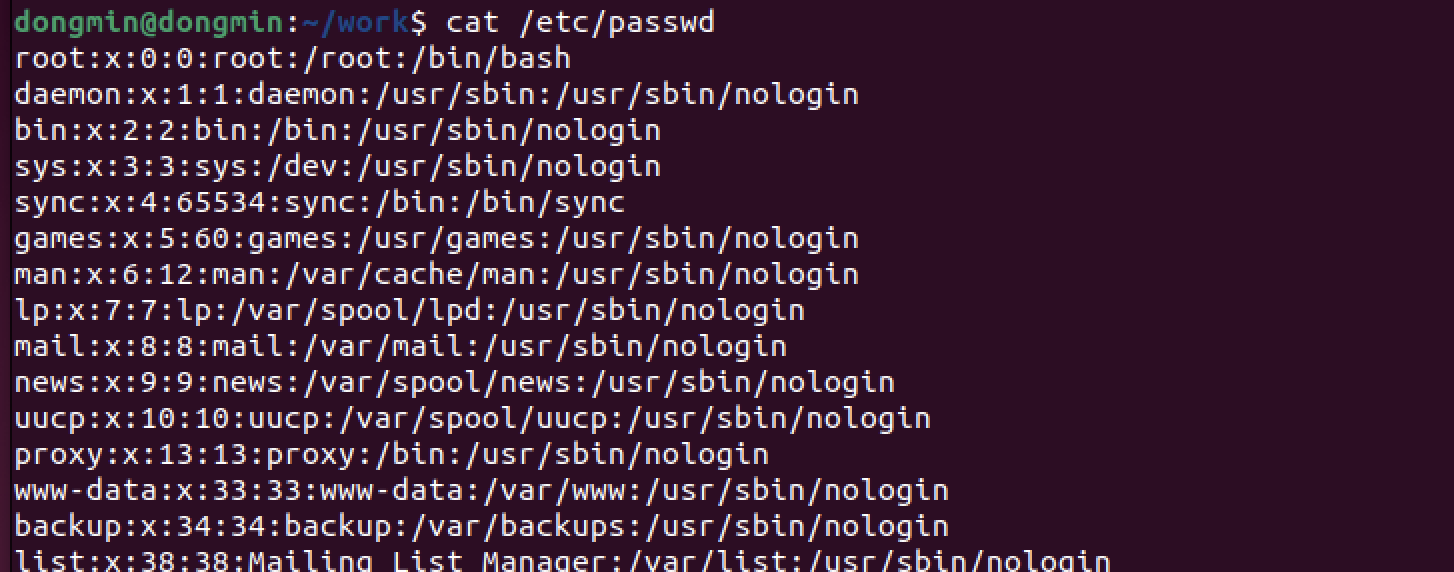
위의 /etc/passwd 파일의 경우에는 :을 구분자로 사용하는데, 여기서 7번째 필드에 해당하는 로그인 셸만 출력해보자
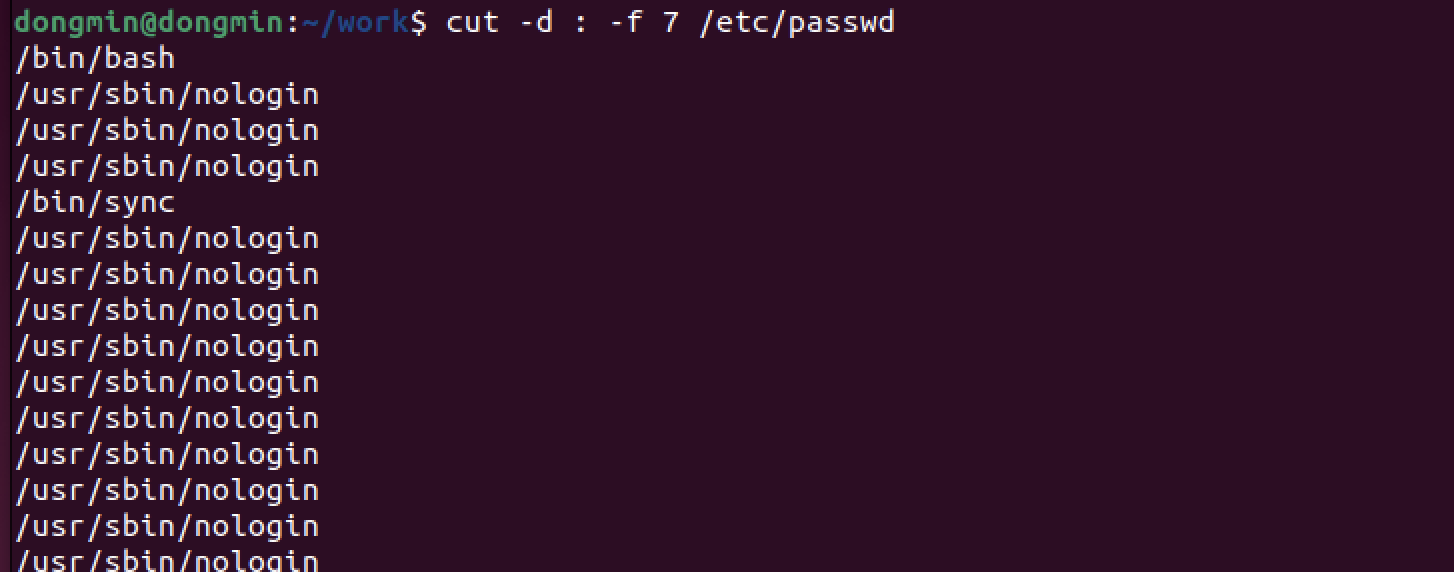
출력할 필드는 쉼표를 사용하여 여러 개를 지정할 수도 있다.
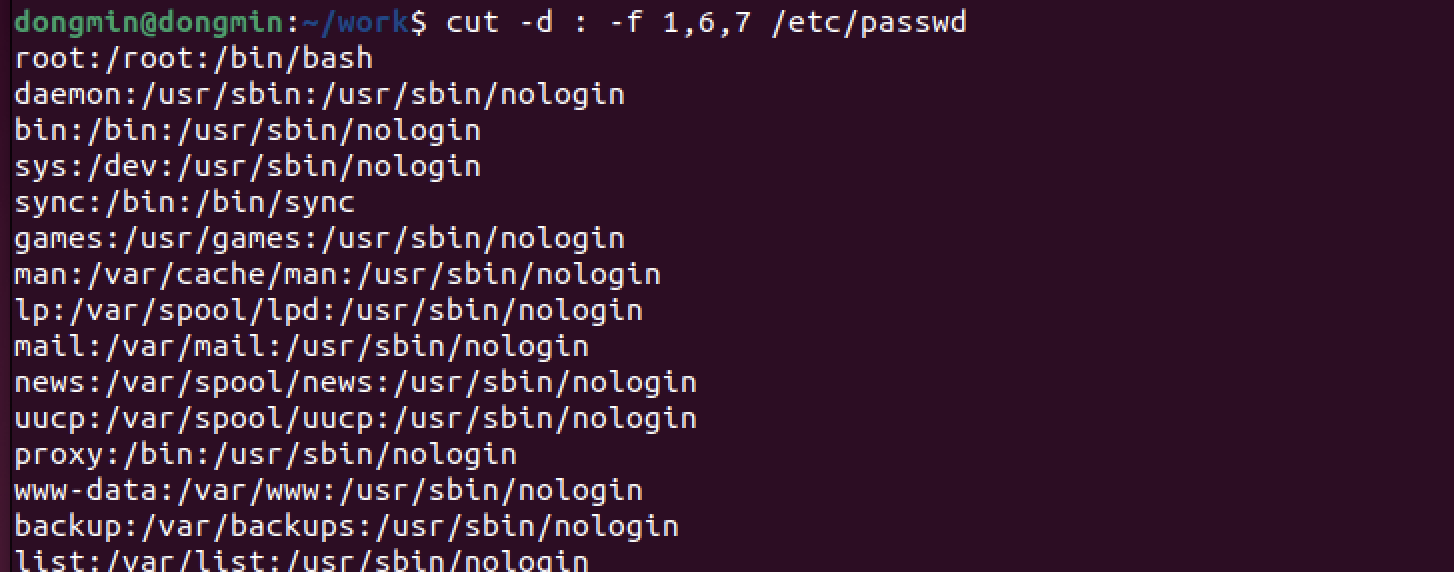
1번째 필드인 사용자 이름, 6번째 필드인 홈 디렉터리, 7번째 필드인 로그인 셸을 출력해보자
tr : 문자 교환과 삭제하기
문자를 치환하는 명령어
tr <치환 전 문자> <치환 후 문자>
- ex)
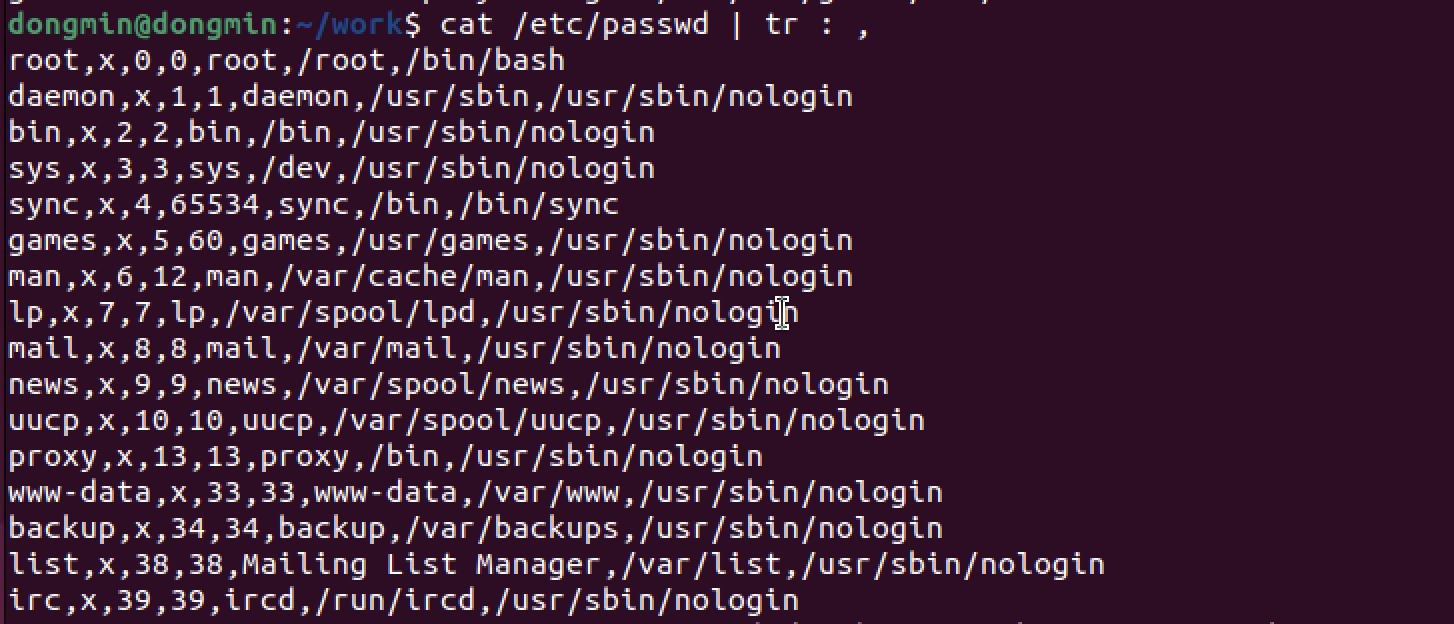
:을,로 치환
- ex) 문자 여러 개를 동시에 치환
a, b, c 각 문자를 A, B, C로 바꾼 것
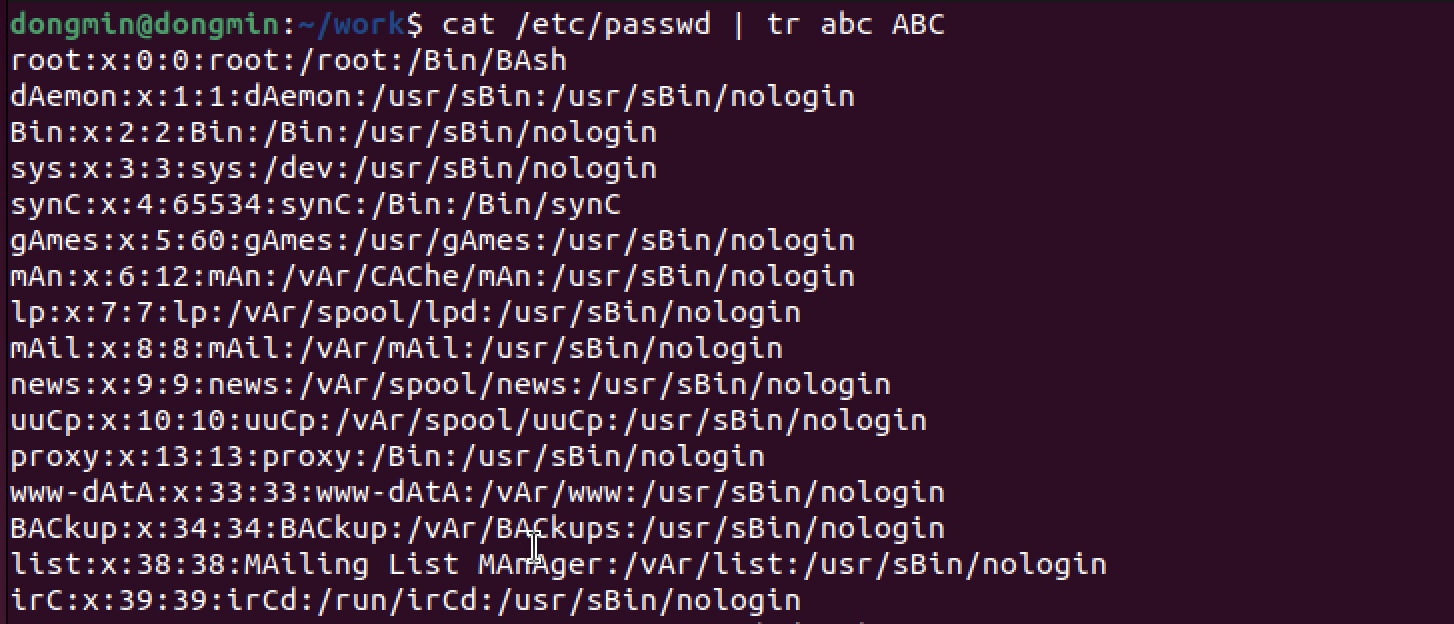
하이픈(-)으로 치환할 문자 범위를 지정할 수도 있다.
a-g는 abcdefg와 같은 의미이다.
- ex) 모든 소문자를 대문자로 치환
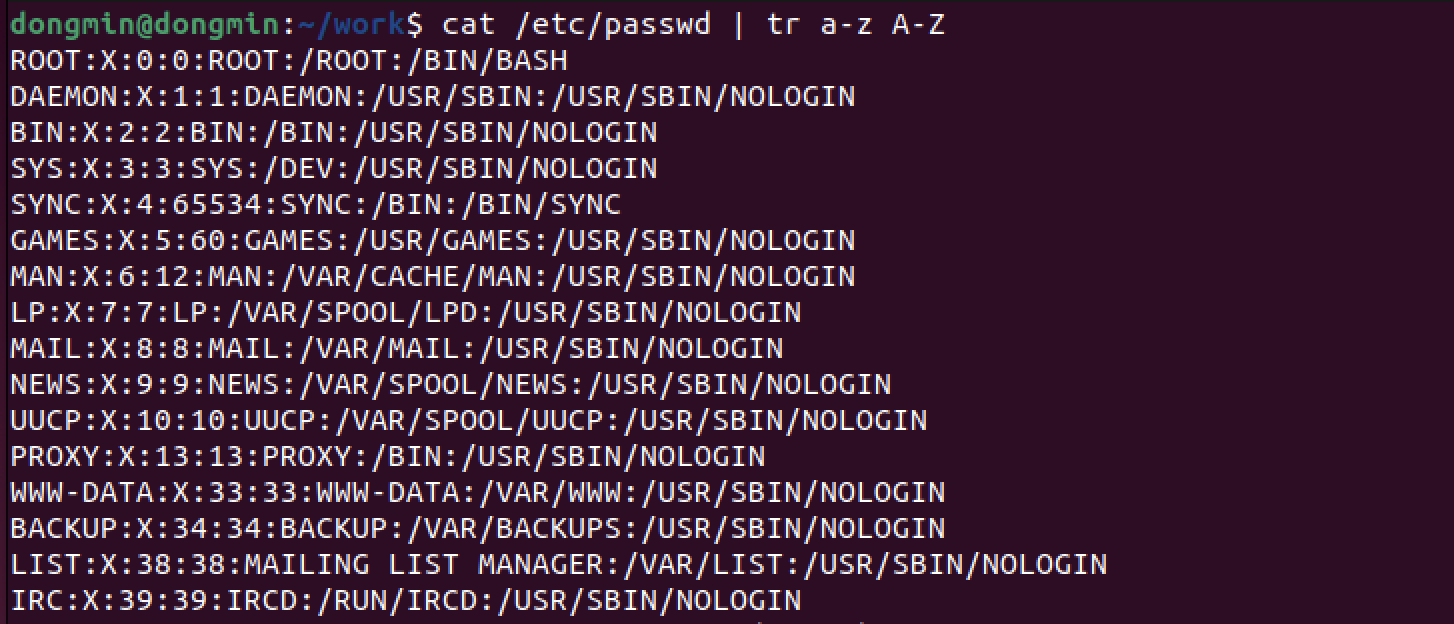
파일 지정은 불가
지금까지 살펴본 필터 명령어들은 파일을 지정하지 않으면 표준 입력을 읽고, 지정하면 해당 파일을 읽었다. 하지만 tr 명령어는 표준 입력만 받아들이도록 설계되었다.
그래서 파일 지정이 불가하며 지정하면 에러가 발생한다.

그렇기에 tr 명령어 실행을 위해서는 파이프라인 혹은 리다이렉션을 이용한다.
cat /etc/passwd | tr : ,
tr : , < /etc/passwd
문자 삭제하기
특정 문자를 삭제하는 것도 가능하다.
tr -d <삭제할 문자>
tr 명령어로 문자를 지우는 것은 개행문자를 전부 없앨 때 자주 사용된다.
-d 옵션으로 개행문자 \n을 지정하면 개행문자를 전부 지우고 한 행으로 만들 수 있다.

tail : 마지막 부분 출력하기
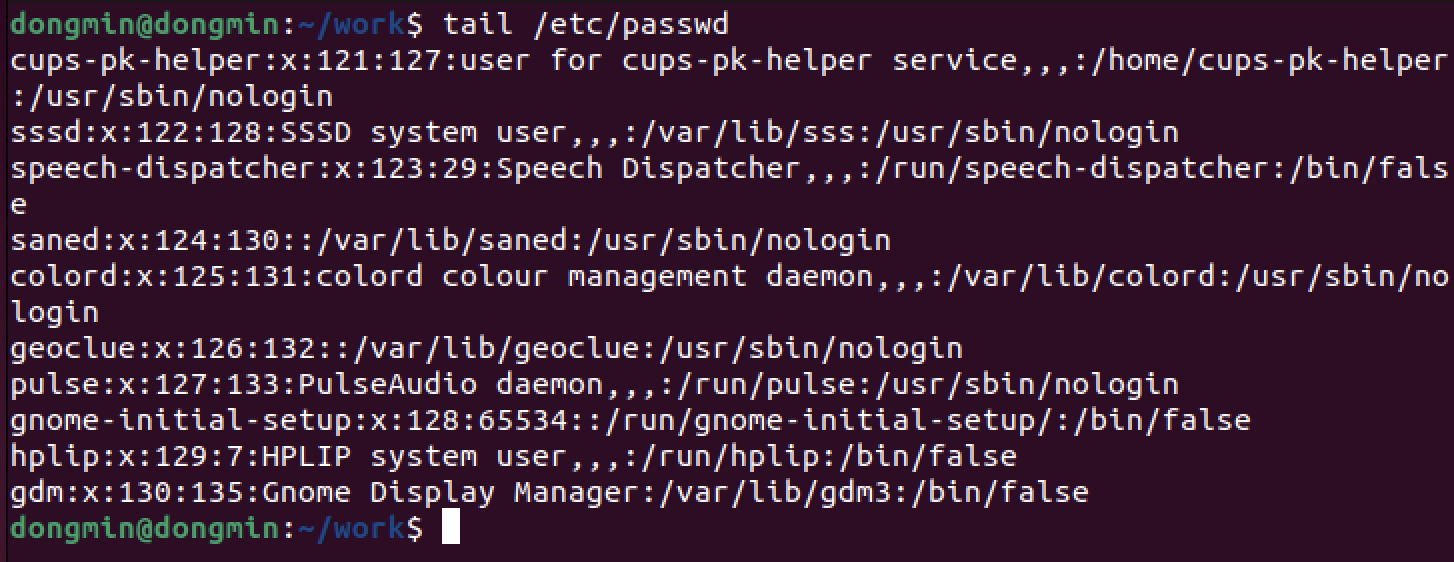
마지막 부분을 출력하는 명령어이다.
옵션을 지정하지 않으면 마지막 10행을 출력한다.
-n 옵션으로 출력할 행 수를 지정할 수 있다.

tail의 반대는 head 명령어이다.

파일 모니터링하기
애플리케이션의 로그처럼 파일 내용이 계속해서 추가되는 경우에는 tail의 -f 옵션을 사용한다. 추가될 때마다 실시간으로 내용을 출력하여 파일을 모니터링할 수 있다.
tail -f <파일 이름>
다음과 같이 tail -f를 실행하면 커서가 멈춘 것처럼 보이는데, (벗어나려면 Ctrl + c)

>>는 표춘 출력의 출력을 파일 끝에 추가하는 것이었다. 이를 사용해 파일에 문자열을 추가하고 tail -f를 다시 실행해보면 추가된 내용이 곧바로 출력되며 다시 커서가 멈춘다. 이처럼 로그 파일을 실시간으로 모니터링하는 경우가 많다.

diff : 차이 출력하기
두 파일의 차이점을 출력하는 명령어이다.
diff [옵션] <비교 파일 1> <비교 파일 2>
소스 코드나 설정 파일의 편집 전과 후의 차이점을 확인할 때 이 명령어를 자주 사용한다.
다음 diff 명령어의 실행 결과를 함께 살펴보자.
diff .bashrc.org .bashrc
12c12
< PS1='\$ '
---
> PS1='[\u@\h] \w\$ '먼저 12c12는 비교 파일에서 어떤 변화가 있었는지를 나타낸다
<변경 범위 1> <변경 종류> <변경 범위 2>와 같은 양식이며, 변경 종류는 a, c, d 세 가지가 있다.
a: add(추가)
c: change(변경)
d: delete(삭제)
<범위 1>a<범위 2>: 첫 번째 파일범위 1뒤에 두 번째 파일범위 2내용이 추가.
<범위 1>c<범위 2>: 첫 번째 파일범위 1부분이 두 번째 파일범위 2내용으로 변경.
<범위 1>d<범위 2>: 첫 번째 파일범위 1부분이 삭제.
즉, 위 예에서는 .bashrc.org 파일의 12번째 행이 .bashrc 파일의 12번째 행으로 변경되었음을 의미한다.
또한 diff 명령어의 출력 결과 중 2번째 행 이후는 실제 파일의 변경 내용이 표시된다.
각 행의 앞에 있는 < 는 첫 번째 파일에만 있는 행을, > 는 두 번째 파일에만 있는 행을 의미한다.
< PS1='\$ ' <- 지워진 행
---
> PS1='[\u@\h] \w$ ' <- 추가된 행두 파일의 차이점만 표시되며 공통점은 표시되지 않는다. 따라서 두 파일이 완전히 같은 내용이라면 아무것도 표시되지 않는다.
파일 안에서 여러 부분을 수정했다면 차이점이 범위 단위로 표시된다.
다음은 세 군데를 변경한 경우이다. 각 변경 범위는 헝크(hunk)라 부른다.
diff .bashrc.org .bashrc
12c12
< PS1='\$ '
---
> PS1='[\u@\h] \w\$ '
20,21d19
<
< set -o ignoreeof
40a39,41
> alias ls='ls-F'
> alias la='ls-a'
> alias li='ls-l'위의 예를 해석하면 다음과 같다. 세 군데의 헝크로 나뉘며,
1. 첫 번째 파일의 12번째 행이 두 번째 파일의 12번째 행으로 변경됨
2. 첫 번째 파일의 20번째 행과 21번째 행이 삭제됨
3. 첫 번째 파일의 40번째 행 뒤에 2번째 파일의 39~41번째 행의 내용이 추가됨
그리고 실제 변경된 내용들이 <혹은 >로 시작되는 행에 표시되고 있다.
통일 포맷
diff 명령어로 차이를 출력하는 형식에는 여러 가지가 있다. 앞서 살펴본 <, >외에도
통일 포맷(unified format) 형식이 자주 사용된다.
-u 옵션을 지정하면 사용이 가능하다.

위와 같이 통일 포맷에서 첫 두 행은 지정한 파일의 이름과 변경 시각이 표시된다.
3번째 행부터는 차이가 출력이 되는데, 추가된 경우에는 +, 삭제된 경우에는 -가 표시된다.
또한 통일 포맷은 변경된 부분뿐만 아니라 앞뒤 몇 행도 함께 표시가 되어 어디를 수정하였는지 파악하기 좀 더 쉽게 해준다.
@@로 시작하는 행의 의미는 다음과 같다.
@@-<첫 번째 파일의 변경이 시작된 행>-<변경된 행 수>+<2번째 파일의 변경이 시작된 행>-<변경된 행 수>@@
여기서 변경되기 시작된 행은 파일의 행 번호를 의미하고, 변경된 행 수는 각 헝크의 행 수(변경이 발생한 행과 그 전후를 포함)를 의미한다.
예를 들어 @@-17,8 +17,6@@ 의미는 다음과 같다.
1. 첫 번째 파일의 17번째 행부터 8행
(-17,8은 첫 번째 파일. 파일의 17번째 행부터 표시하며 출력 행 수는 8행)
2. 두 번째 파일의 17번째 행부터 6행
(+17,6은 두 번째 파일. 파일의 17번째 행부터 표시하며 출력 행 수는 6행)
diff의 사용법과 패치
어떤 파일을 변경한 뒤에 다른 사람에게 전달할 때 파일 전체를 전달하는게 아니라 diff 명령어로 출력된 부분만 전달하는 것도 가능하다.
변경된 부분을 전달받은 사람은 원래의 파일에 변경된 부분을 적용하여 변경이 완료된 파일을 얻을 수 있다. 그러면 크기가 큰 파일을 변경했을 때 굳이 파일 전체를 전달하지 않아도 된다.
이렇게 변경된 내용만 담은 파일을 패치(patch)라고 한다.
diff 명령어로 얻은 변경 사항은 patch 명령어로 적용이 가능하다.
패치를 적용할 때 원본 파일이 변경되어 행 번호가 바뀌었다면 에러가 발생할 수 있다.
하지만 통일 포맷을 사용하면 변경 앞뒤의 내용이 포함되어 있어서 어느 정도 변경 사항이 있어도 패치에 성공한다. 따라서 요즘에는 변경 사항을 파악하기 쉽고 패치하기 쉬운 통일 포맷을 많이 사용한다.
