📝 논문 기본 정보
- 논문명: [Infrared Small Target Detection with Scale and Location Sensitivity]
- 저자: [Qiankun Liu et al.]
- 발표 연도: [2024]
- 학회/저널: [CVPR]
- 논문 링크: [https://arxiv.org/abs/2403.19366]
- 핵심 키워드:
#computer vision,#적외선 탐지,#Small target detection
💡 초록 (Abstract) 요약 및 핵심 아이디어
- we first propose a novel Scale and Location Sensi- tive (SLS) loss to handle the limitations of existing losses
1) for scale sensitivity
2) for location sensitivity
이 논문은 기존 IoU, Dice의 한계점을 극복하고자 Scale과 Location에 sensitive한 loss를 제안하여 Infrared Small target detection 성능을 향상시켰다.
🤔 문제 정의 및 연구 배경 (Introduction)
-
연구 배경: 적외선 소형 표적 탐지 (Infrared small target detection, IRSTD)는 장거리 카메라 촬영과 노이즈 및 클러터 간섭으로 종종 작고 희미하여 탐지가 어렵다. 기존 방법들은 필터링 기반 방법, local contrast 기반 방법, low-rank 기반 방법으로 나눌 수 있다. DL의 발전으로 경사 하강법을 통해 유용한 특징을 자동으로 학습할 수 있다.
-
문제 정의: 손실 함수로 널리 사용되는 IoU 및 Dice는 크기와 위치에 대한 민감도가 부족하다. 크기와 민감도에 민감도가 떨어지면 서로 다른 크기와 위치의 target을 구별하기 어렵게 만들어 detection 성능을 저해한다.
-
논문의 기여:
1) Infrared small target detection을 위한 새로운 scale 및 location 민감 손실 함수를 제안하여, 다양한 크기와 위치의 객체를 구별하는 데 도움을 준다.
2) U-Net에 multi-scale head를 도입하여 간단하면서 효과적인 detector 제안
📚 관련 연구 (Related Work)
- Loss Functions for IRSTD
- loss for adversarial training, edge loss for the detecting of target edges, likelihood loss: 특정 네트워크 아키텍처에 맞춰져 있어 활용성이 제한적
🛠️ 제안 방법론 (Methodology)
Scale and Location Sensitivity Loss
- 크기 민감 loss + 위치 민감 loss
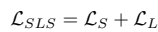
Scale Sensitive Loss
- : 예측된 픽셀 집합
- : ground-truth 픽셀 집합
- 기본적인 IoU loss
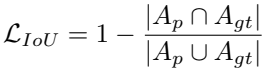
- Scale sensitive loss는 IoU에 가중치 부여하여 구현
- Var( , ) : 주어진 스칼라 값들의 분산(variance)를 구하는 함수
- 와 사이의 격차가 클수록 w가 작아지고 loss가 더 커짐
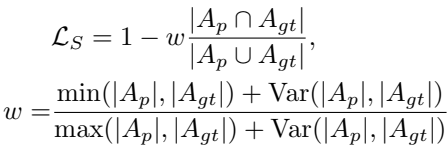
Location Sensitive Loss
- , : , 모든 픽셀의 좌표를 평균 낸 중심점
- 중심점의 좌표를 극좌표계로 변환
- 극좌표계에서 거리 각도

- location sensitive loss (거리 오류 + 방향 오류)
- 거리 오류 측정 : 예측된 중심점까지의 거리와 실제 중심점까지의 거리의 상대적 비율
→ 원점으로부터의 거리 오차를 상대적인 비율로 계산하여 표적의 위치에 상관없이 일관된 페널티 부여 - 각도 오류 측정 : 예측된 각도와 실제 각도의 차이를 측정 (사인함수 사용)
→ 사인 함수를 이용해 각도의 주기성 문제를 해결하고, 방향 오차를 더 정확하고 부드럽게 측정 (e.g. 1도와 359도의 차이처럼 경계에 가까운 큰 차이가 발생할 때, 주기성을 반영하여 오류를 올바르게 측정)
- 거리 오류 측정 : 예측된 중심점까지의 거리와 실제 중심점까지의 거리의 상대적 비율
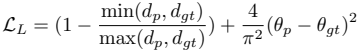
MSHNet Detector
- 기본 U-Net에 multi-scale head 추가
- 다양한 스케일의 feature map들을 각각 다른 prediction head를 통해 prediction 생성

- MSHNet에 대한 설명은 구현된 code가 잘 설명하는 것 같다
import torch
import torch.nn as nn
# ResNet Block 생략 / CBAM 추가된 ResNet block
class MSHNet(nn.Module):
def __init__(self, input_channels, block=None): # block 인자는 ResNet
super().__init__()
param_channels = [16, 32, 64, 128, 256]
param_blocks = [2, 2, 2, 2]
self.pool = nn.MaxPool2d(2, 2) # 다운샘플링을 위한 Max Pooling
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) # 업샘플링
self.up_4 = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True)
self.up_8 = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=True)
self.conv_init = nn.Conv2d(input_channels, param_channels[0], 1, 1)
# U-Net의 인코더 부분 (Contracting Path)
self.encoder_0 = self._make_layer(param_channels[0], param_channels[0], block)
self.encoder_1 = self._make_layer(param_channels[0], param_channels[1], block, param_blocks[0])
self.encoder_2 = self._make_layer(param_channels[1], param_channels[2], block, param_blocks[1])
self.encoder_3 = self._make_layer(param_channels[2], param_channels[3], block, param_blocks[2])
# U-Net - Bottleneck
self.middle_layer = self._make_layer(param_channels[3], param_channels[4], block, param_blocks[3])
# U-Net의 디코더 부분 (Expansive Path)
self.decoder_3 = self._make_layer(param_channels[3]+param_channels[4], param_channels[3], block, param_blocks[2])
self.decoder_2 = self._make_layer(param_channels[2]+param_channels[3], param_channels[2], block, param_blocks[1])
self.decoder_1 = self._make_layer(param_channels[1]+param_channels[2], param_channels[1], block, param_blocks[0])
self.decoder_0 = self._make_layer(param_channels[0]+param_channels[1], param_channels[0], block)
# 각 디코더 레벨에서 예측을 생성하는 다중 스케일 헤드 (Multi-Scale Head)
self.output_0 = nn.Conv2d(param_channels[0], 1, 1) # 스케일 0 예측
self.output_1 = nn.Conv2d(param_channels[1], 1, 1) # 스케일 1 예측
self.output_2 = nn.Conv2d(param_channels[2], 1, 1) # 스케일 2 예측
self.output_3 = nn.Conv2d(param_channels[3], 1, 1) # 스케일 3 예측
# 다중 스케일 예측 결과를 하나로 합치는 최종 레이어
self.final = nn.Conv2d(4, 1, 3, 1, 1)
def _make_layer(self, in_channels, out_channels, block, block_num=1):
# ResNet 블록을 연속적으로 쌓는 함수
layer = []
layer.append(block(in_channels, out_channels))
for _ in range(block_num-1):
layer.append(block(out_channels, out_channels))
return nn.Sequential(*layer)
def forward(self, x, warm_flag):
# Encoder
x_e0 = self.encoder_0(self.conv_init(x))
x_e1 = self.encoder_1(self.pool(x_e0))
x_e2 = self.encoder_2(self.pool(x_e1))
x_e3 = self.encoder_3(self.pool(x_e2))
# Bottleneck
x_m = self.middle_layer(self.pool(x_e3))
# Decoder
x_d3 = self.decoder_3(torch.cat([x_e3, self.up(x_m)], 1)) # 인코더의 특징맵(x_e3)을 연결
x_d2 = self.decoder_2(torch.cat([x_e2, self.up(x_d3)], 1)) # 인코더의 특징맵(x_e2)을 연결
x_d1 = self.decoder_1(torch.cat([x_e1, self.up(x_d2)], 1)) # 인코더의 특징맵(x_e1)을 연결
x_d0 = self.decoder_0(torch.cat([x_e0, self.up(x_d1)], 1)) # 인코더의 특징맵(x_e0)을 연결
if warm_flag: # SLS 손실을 사용하는 다중 스케일 학습 단계
# 각 스케일에서 개별 예측 마스크 생성
mask0 = self.output_0(x_d0)
mask1 = self.output_1(x_d1)
mask2 = self.output_2(x_d2)
mask3 = self.output_3(x_d3)
# 모든 스케일의 마스크를 업샘플링하여 합치고 최종 예측 생성
output = self.final(torch.cat([mask0, self.up(mask1), self.up_4(mask2), self.up_8(mask3)], dim=1))
# SLS 손실 계산을 위해 모든 중간 마스크와 최종 마스크를 반환
return [mask0, mask1, mask2, mask3], output
else:
# 가장 해상도가 높은 스케일에서만 최종 예측 생성
output = self.output_0(x_d0)
# 추론 시에는 최종 예측만 반환
return [], outputTraining MSHNet with SLS Loss
- ⇓ : 다운샘플링
- 최종 loss : 5개의 scale에 SLS loss 평균
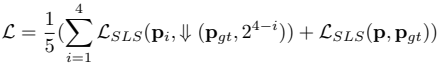
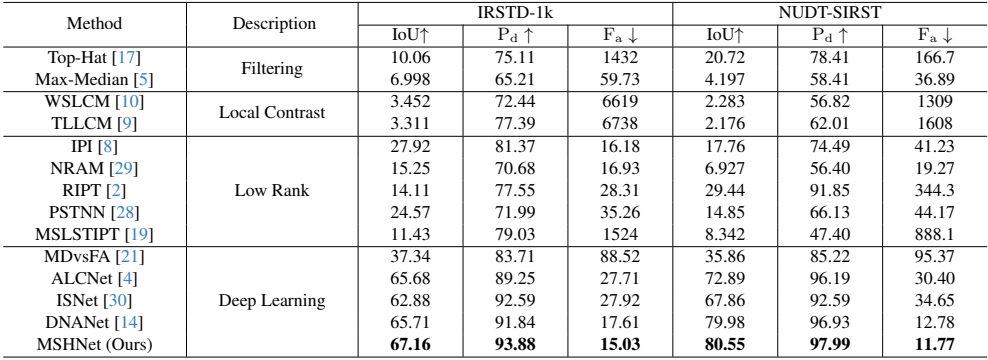
📊 실험 결과 및 분석 (Experiments & Results)
- 평가 지표: IoU, (오탐지율), (탐지 확률)
- 주요 결과: IRSTD-1k 데이터셋에 대한 기존 method들과의 비교
- 정성적 결과 (Qualitative Results): MSHNet은 low-contrast infrared image에 대해 더 정확히 식별해냈다. 저자는 SLS 손실과 다중 스케일 헤드 덕분이라고 분석

- 결과 분석:
- 다양한 크기 레벨의 표적에 좋은 성능을 보인다.
- SLS 손실을 사용하면 지표에서는 성능이 더 나빠지는데, 모든 크기의 target을 구별하려고 시도하여 더 많은 오탐지 픽셀이 실제 표적으로 처리될 수 있기 때문이다.
- 가중치 w의 도입이 에 긍정적인 영향을 미치며, 더 정확한 형태를 생성하고 오탐지를 줄인다. location sensitve loss가 도입될 때 더 많은 오탐지가 발생했지만, IoU와 는 모두 크게 향상되었다.
- location sensitve loss를 도입했을 때에도 에서 더 좋은 지표를 보이지만, 더 많은 오탐지가 발생했다. 다양한 위치 오류에 대한 구별 능력이 작은 target에 더 민감하게 만들어, 일부 노이즈를 표적으로 처리할 가능성을 높일 수 있다.
- multi-scale head를 더 많이 늘릴수록 detection 성능이 향상되었다.
💬 논의 및 결론 (Discussion & Conclusion)
-
논문의 기여 및 주요 발견: SLS loss를 제안하여, scale 및 location에 민감한 loss를 multi-scale head에 도입하여, infrared image에서 더 좋은 detection 성능을 보인다.
-
연구의 한계점: 더 많은 오탐지가 발생할 수 있음
-
향후 연구 방향: 일부 노이즈를 target으로 처리할 수 있어 향후에는 더 적합한 location sensitive loss를 설계
📝 나의 비판적 검토 및 생각 (My Critical Review & Thoughts)
- 가장 인상 깊었던 점/강점: 제안한 method가 단순하면서도 실험에서 효과를 입증함
- 재현성: https://github.com/ying-fu/MSHNet/tree/main
- 궁금한 점 / 질문: 3D scaling 및 task 특성 추가 반영 여부
- 적용 가능성: 3D 데이터에 적용 및 데이터 특성에 따른 loss 반영
