[쉽게 설명하는 논문리뷰] AlexNet (ImageNet Classification with Deep Convolutional Neural Networks)
paper review
PROLOGUE
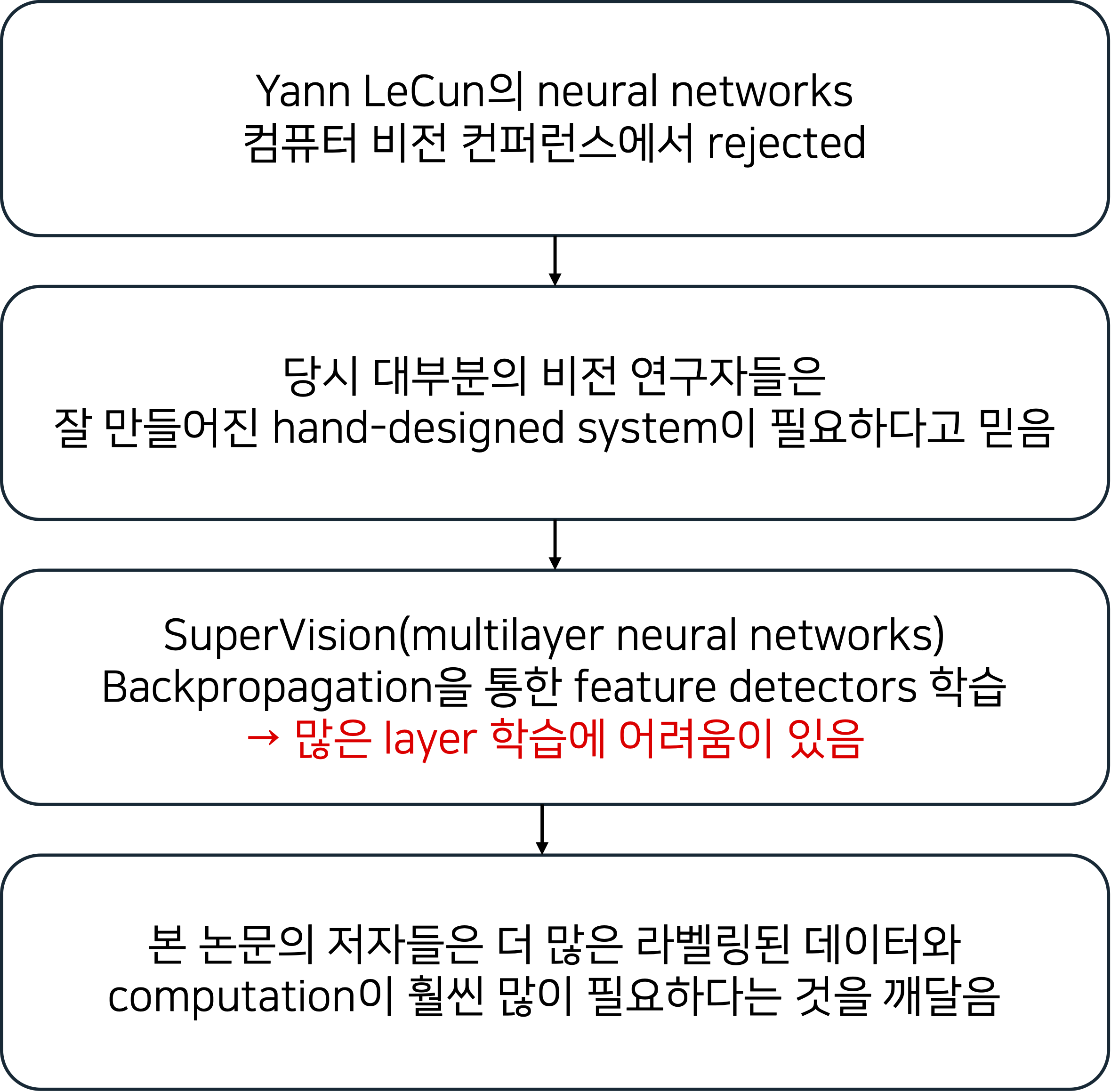
SUMMARY
- 2개의 GPU 병렬연산
- 모든 layer에서 feature를 주고받지 않음
- Max Pooling(overlapped)
- ReLU activation function 사용
- Local Response Normalization
- overfitting 방지를 위해 data augmentation, Dropout 사용
CONTRIBUTIONS
당시 기준(현재와는 맞지않음)
- ImageNet을 학습한 모델들 중 가장 좋은 성능
- 2D convolution에 가장 최적화된 GPU 구현
- 기존과 다른 방식으로 성능 개선과 학습 시간 단축
- overfitting 방지를 위한 효과적인 기법들을 사용
ARCHITECTURE
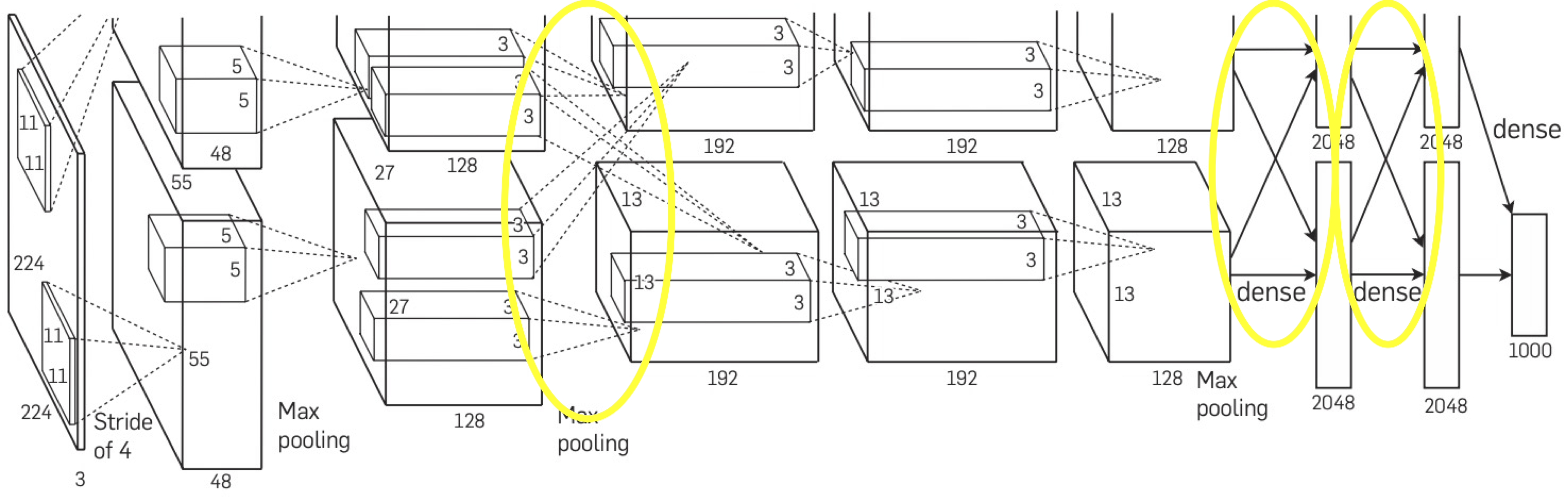
AlexNet의 전체 achitecture이다.
특징 1. ReLU 사용
tanh, sigmoid 활성함수에 비해 ReLU는 학습 속도가 더 빠르다.
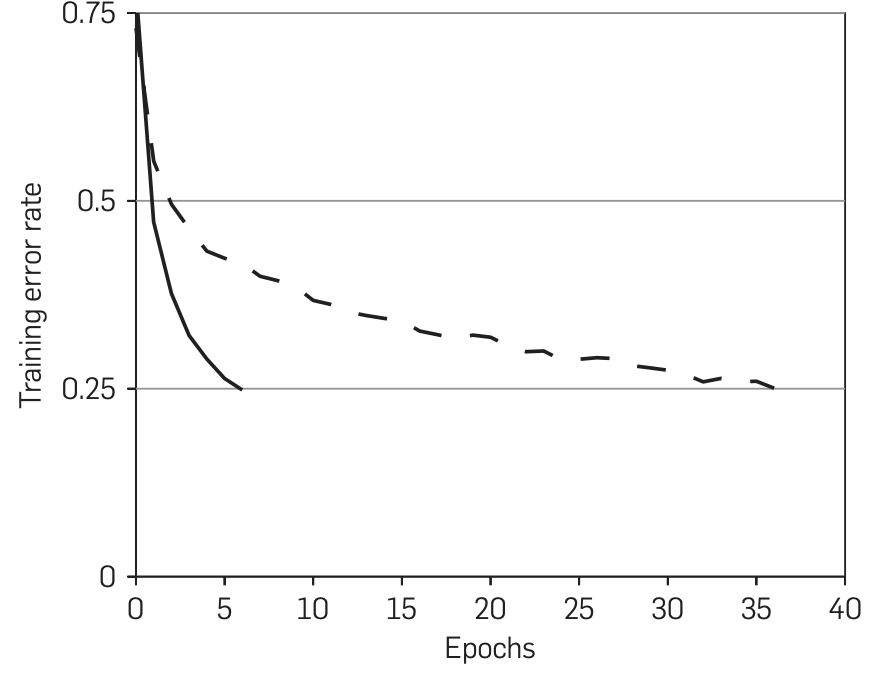
점선은 tanh, 실선은 ReLU이며, CIFAR-10 데이터셋에 학습 에러율을 나타낸 그래프이다.
ReLU가 tanh보다 6배 빨리 25%에 도달했다.
이처럼 빠른 학습 속도는 더 큰 데이터셋에 학습된 큰 모델의 성능에 긍정적인 영향을 미친다.
특징 2. GPU 병렬연산
당시 학습에 GTX 580 3GB GPU 두 개를 사용하여 학습했다고 한다.
GPU의 성능이 부족했기 때문에 두 개의 GPU를 병렬로 사용한다.
각 GPU에 커널(또는 뉴런)의 반을 연산했고, 모든 lyaer에 적용한 것이 아닌 특정 layer에 적용했다. (아키텍쳐 그림에서 노란색 원으로 그려진 부분)
이유는 computation이 허용 가능한 양을 정밀하게 조정할 수 있기 때문이라고 한다.
학습 시간도 한 개의 GPU를 사용할 때보다 조금 더 감소한다.
특징 3. Local response normalization
ReLU는 양수의 입력값에 대해선 그대로 사용하기 때문에 높은 픽셀값이 주변의 픽셀값에 영향을 줄 수 있다. 이를 방지하기 위해서 Local response normalization은 다른 activation map에 같은 위치에 있는 픽셀끼리 정규화를 한다.
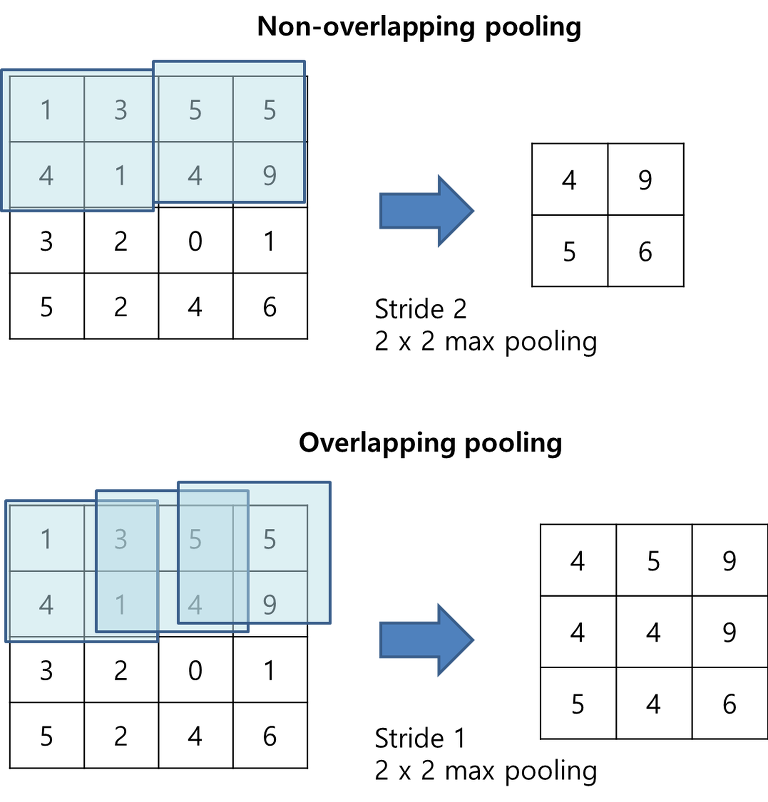
특징 4. Overlapping pooling
AlexNet에서는 stride의 크기를 커널 크기보다 작게하여 겹치는 overlapping pooling을 사용한다.
특징 5. data augmentation (overfitting 방지)
- overfitting을 막기위해 사용
- 좌우 반전과 random crop을 사용
- 하나의 이미지로 비슷한 여러 장의 이미지를 사용하여 computation이 적게 든다.
- level-preserving transformation : 원본데이터(label)의 특성을 보존(preserving)하면서 augmentation(transformation)한다.
- PCA on RGB pixel values
각 pixel의 RGB 값들을 PCA 분석을 통해 eigenvector에 Gaussian distribution으로부터 랜덤한 변수를 곱해준 값을 더한다.

이미지 출처 : Example for PCA on RGB pixel values
특징 6. Dropout (overfitting 방지)
dropout : hidden layer에서 뉴런의 output을 50% 확률로 0으로 만드는 방식으로 overfitting을 방지하기 위해 사용한다. (AlexNet에서는 두 fully connected layer에서 사용한다.)
- dropout은 뉴런이 다른 특정 뉴런에 의존할 수 없게하는 특성이 있다.
- dropout은 수렴에 필요하는 반복 수를 약 두 배 증가시킨다.
EXPERIMENT
- 정성적 평가

- GPU1에서는 색상과 관련없는(color-agnostic) feature 추출
- GPU2에서는 색상에 특화(color-specific) feature 추출
후기
GPU의 발전은 정말 어마어마한 것 같다.
워낙 오래된 모델이지만 더욱 기초를 다지기 위해서 차근히 리뷰를 진행할 생각이다.
출처
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017), ImageNet classification with deep convolutional neural networks, Communications of the ACM, 60(6), 84-90.
