Purpose
RNN과 CNN을 전혀 사용하지 않고 Self-attention을 사용한 Transformer 모델이 2017년에 자연어처리에서 성공적으로 활용되고있다. Transformer가 가진 연산 효율성과 확장성 덕분에 방대한 크기의 모델을 학습하는 것이 가능해졌다.
해당 논문에서는 컴퓨터 비전에서도 Transformer를 이미지에 직접적으로 적용하기 위한 시도를 하였다.
Method
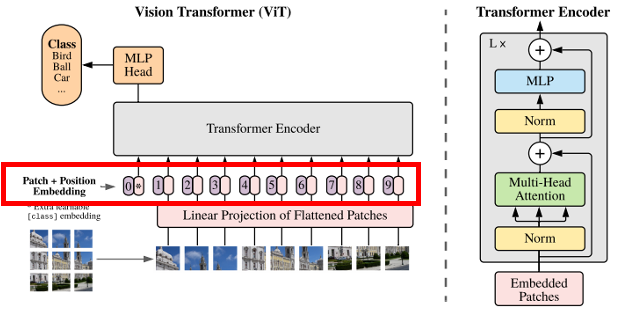
모델의 전체 아키텍쳐는 다음 그림과 같다.

해당 저자들이 서론에서 언급한 것과 같이 자연어처리에서 쓰이는 Transformer의 Encoder와 크게 달라지지 않았다.
달라진 점은 크게 두 가지 정도로 본다.
- Encoder 내의 Norm의 위치
- MLP layer의 활성화 함수를 GELU를 사용
그리고 이미지를 단어가 아닌 이미지 패치로 토큰화 시켰다는 점이 해당 논문의 핵심 아이디어라고 생각한다.
이제 모델에서 사용하는 모듈을 하나씩 살펴본다.
1. 이미지 패치
자연어처리 Transformer에서는 각각의 단어(토큰)이 Transformer 인코더의 Input으로 쓰이지만 Vision Transformer에서는 이미지를 적용하기 위해 일정한 크기로 나누어 각각의 이미지 패치(토큰)가 Transformer encoder의 Input으로 사용된다.
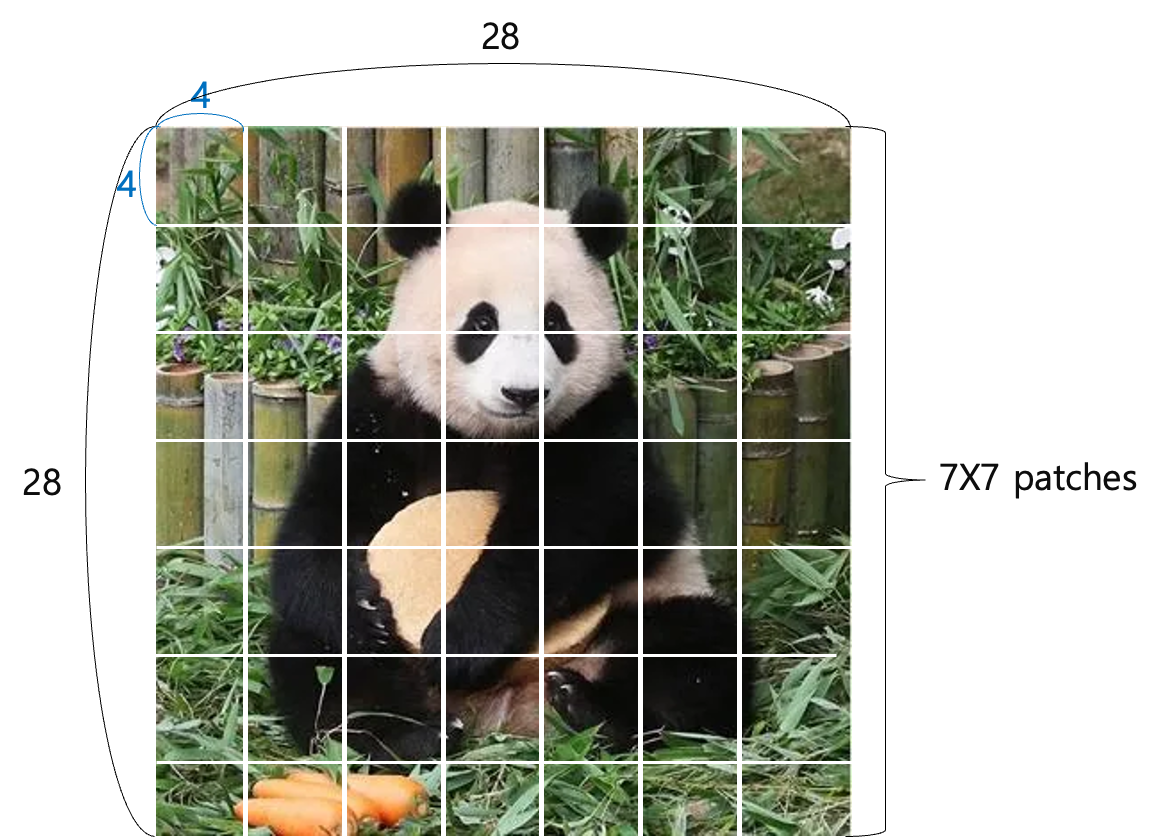
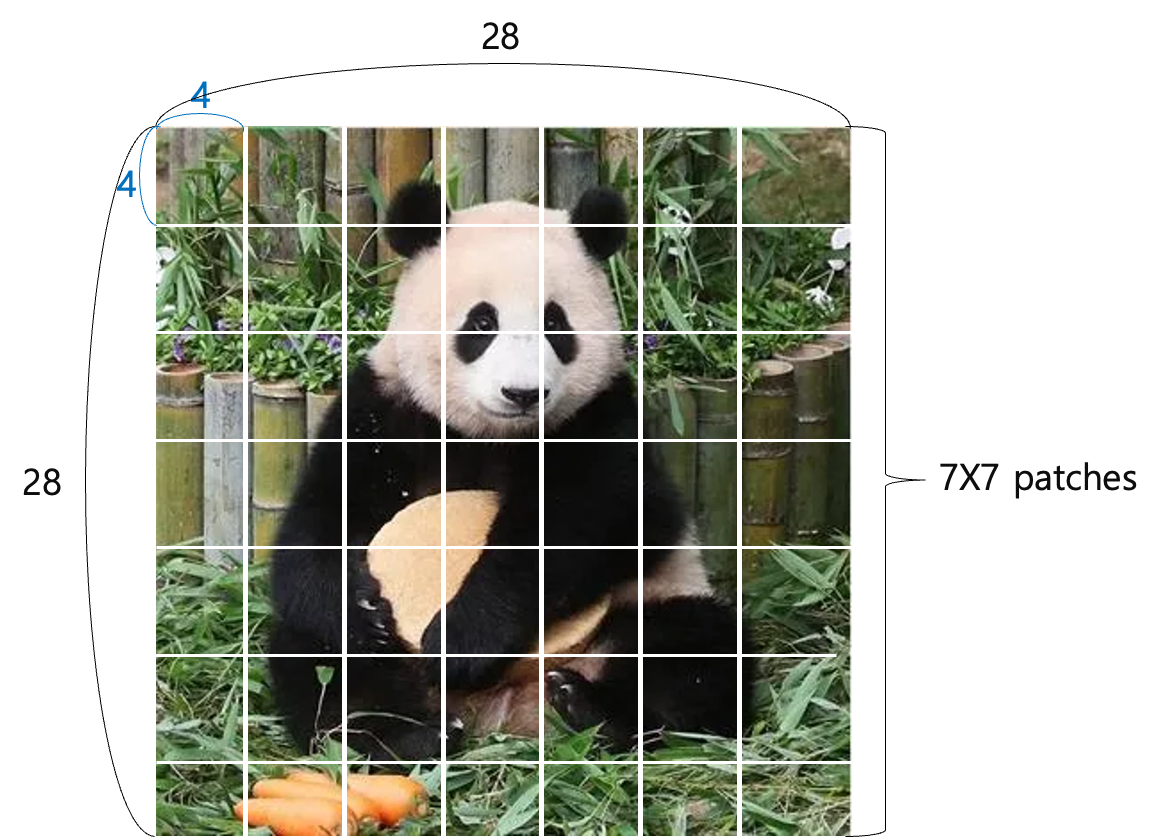
자세히 알아보기 위해 예시로 28x28크기의 푸바오 이미지를 통해 설명한다.
 [사진 출처 : 푸바오 - 나무위키]
[사진 출처 : 푸바오 - 나무위키]
이미지를 4x4 크기의 패치로 나누면 위 그림과 같이 28x28 이미지가 총 49개의 패치로 나눠진다.
다음 사진은 각 패치를 펼쳤을 때(flatten) 이미지의 모양(shape)을 표현한다.

pytorch notation을 따라 작성했다.
각 패치를 펼치면 48개의 원소가 flatten된 형태일 것이다.
그런 패치가 49개 있고, 필요에 따라 linear projection을 하여 embedding dimension(마지막 차원)의 수를 조정한다.
예시의 경우 linear projection을 거치지 않은 (배치 크기, 49, 48) shape으로 진행한다.
패치화 Pytorch 구현 코드에 대해 인터넷에서 찾은 3가지 버전을 소개한다.
1) loop를 통한 패치화(Pytorch)
 [코드 출처 : https://medium.com/@brianpulfer/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c]
[코드 출처 : https://medium.com/@brianpulfer/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c]
2) einops 라이브러리 사용
einops의 rearrange 함수를 사용하면 더 직관적이고 짧은 코드로 패치화가 가능하다.

3) Conv2D layer 사용
논문의 저자들은 Conv layer를 사용했을 때 더 성능의 향상이 있다고 한다.
 [코드 출처 : https://yhkim4504.tistory.com/5]
[코드 출처 : https://yhkim4504.tistory.com/5]
2. 클래스 토큰 & 위치 인코딩
- 클래스 토큰
클래스 토큰은 BERT 모델에서와 유사하다고 한다.
각 이미지를 대표하는 토큰이며, 파라미터로 선언되어 모델 학습을 통해 업데이트 된다.
이후 MLP Head에서 클래스 토큰을 사용하여 분류를 진행한다.
예시 코드
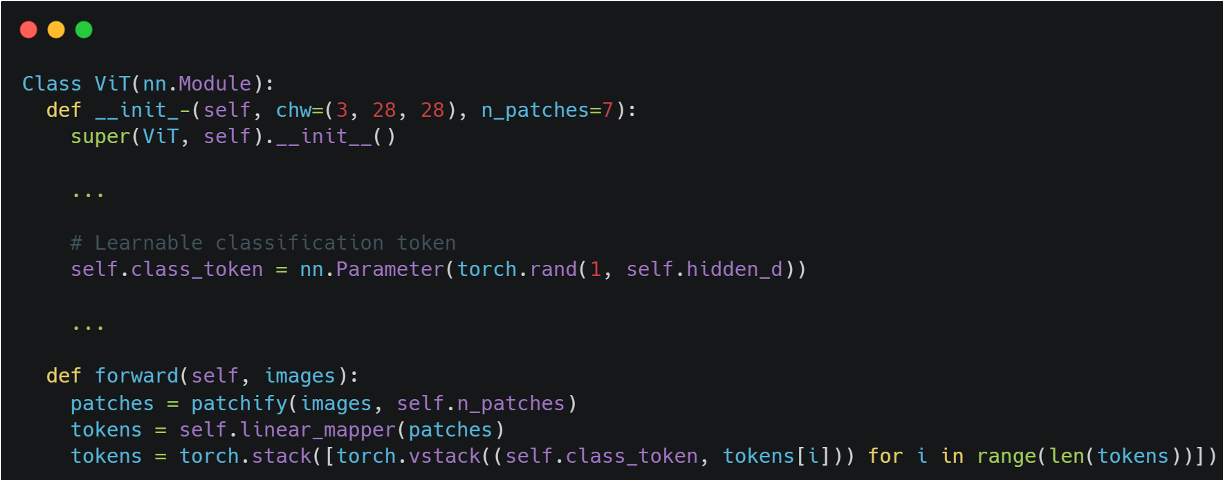
위 코드에서처럼 파라미터로 선언하여 각 이미지마다 concat 시켜준다.
- 위치 인코딩(Positional Encoding)
자연어처리에서 Transformer와 같이 position 정보를 포함하기 위해 position embedding을 진행한다. 사인/코사인 함수같은 고정된 값의 position embedding도 있지만 파라미터를 선언하여 위치 정보를 학습시키는 방식이 더 많이 쓰이는 것 같다.
예제 코드
클래스 토큰과 마찬가지로 랜덤 이니셜한 파라미터를 선언했으며, 예제 이미지의 경우 (7^2 + 1, 48)의 형태를 갖는 벡터로 표현된다. repeat 함수를 통해 모든 이미지의 패치 + 클래스 토큰에 덧셈 연산을 통해 위치 정보를 포함시킨다.
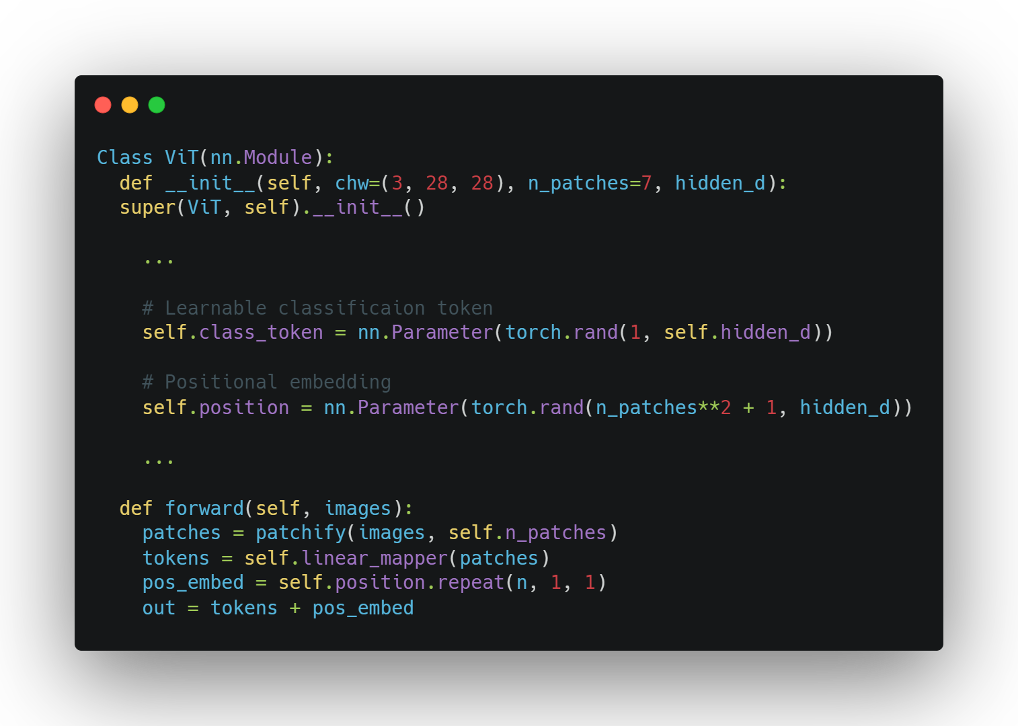
여기까지가 저자가 Transformer를 이미지에 scaling한 과정이다.
3. Transformer 인코더
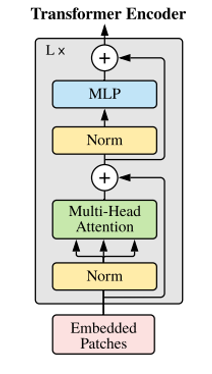
인코더는 앞서 언급한 것처럼 Norm의 위치가 바뀌었다.
- Norm
- Layer Normalization을 사용했고, 이는 Batch Normalization의 batch에 대한 의존성이 높은 단점을 보완한다.
- 임베딩 차원에만 적용한다.
4. Multi-Head Attention
기존 Transformer와 동일하게 Multi-Head Self-Attention을 사용한다.
내부 동작을 구현한 예제 코드와 연산 과정을 시각화해봤다.
예제코드
실제 구현엔 쓰지않지만 연산 과정을 직관적으로 표현할 수 있어 가져왔다.
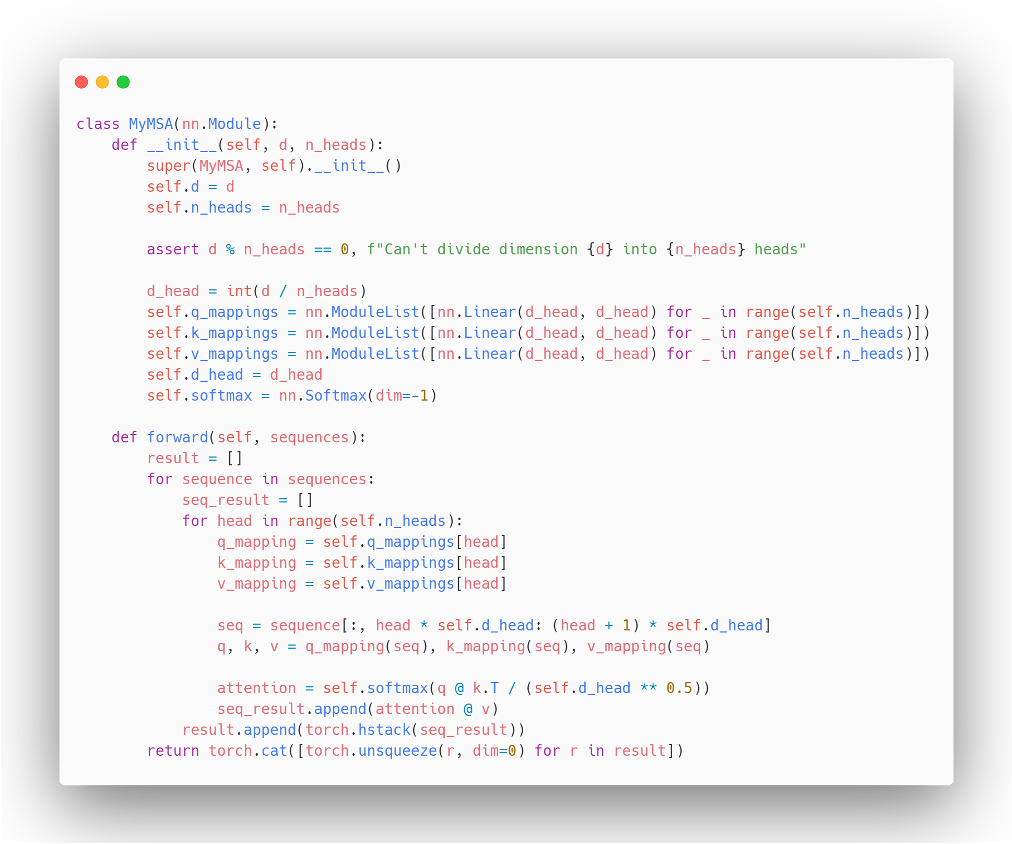
시각화
위 코드를 linear projection을 거쳐 임베딩 차원이 16일때 즉, (N, 50, 16) 형태로 Encoder에 들어왔을 때를 시각화했다.

4. MLP(Multi-Layer perceptron)
- Transformer의 Feed Forward와 비슷하다.
- 코드에선 hidden layer를 n배로 팽창시켜 설정했다.
- GELU 활성화 함수를 사용하며, GELU는 ReLU보다 좀 더 부드러운 곡선을 그린다. 다른 활성화 함수보다 빠르게 수렴하며, 낮은 오차를 보인다.
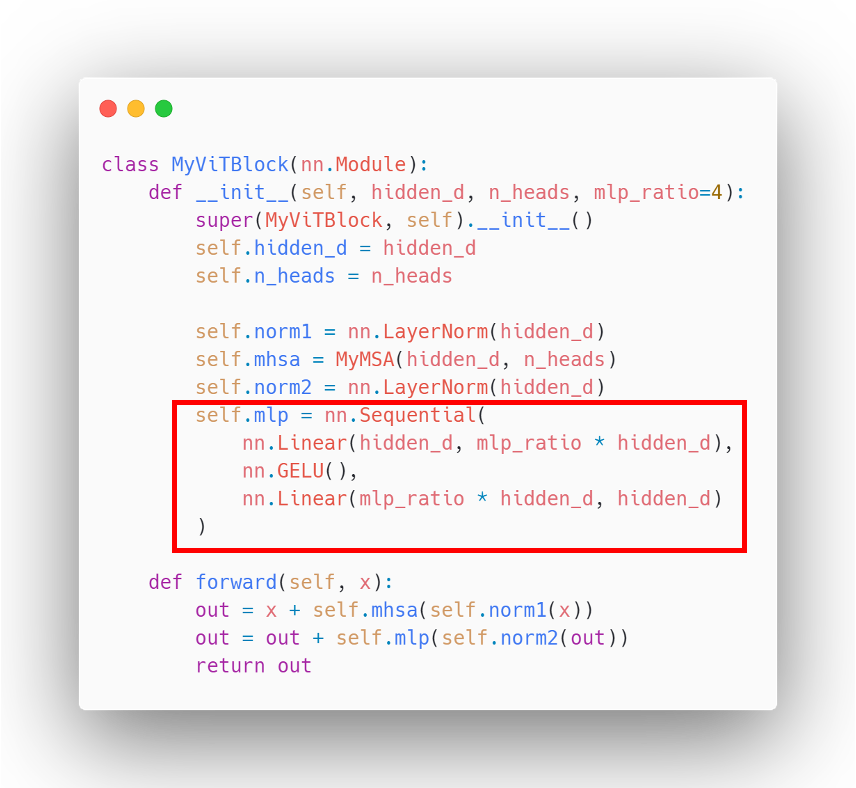
5. MLP Head 및 분류
- 기존 Transformer와 동일하게 Encoder 블록을 여러 개 쌓아올린다.
- 각 샘플의 class token만 추출한다.
- 분류 클래스 수에 맞게 FCL → Softmax

Experiments
-
image classification benchmarks 비교
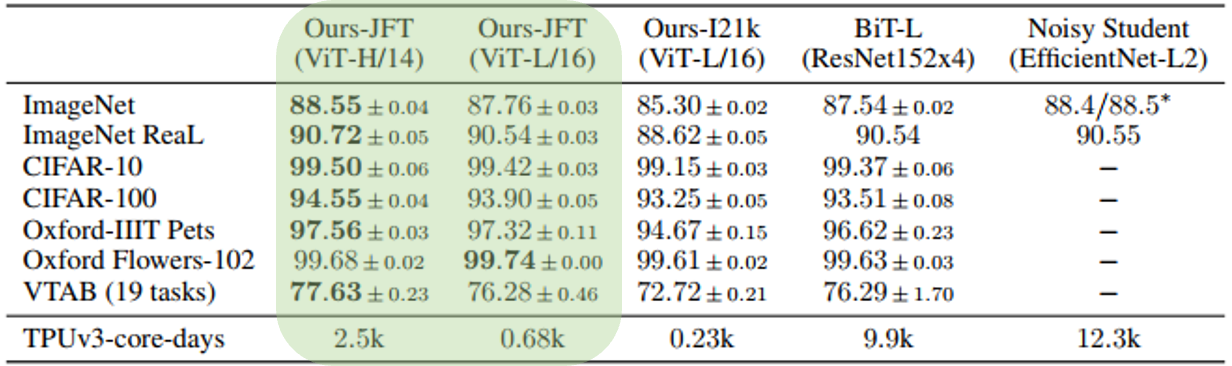
✔︎ JFT-300M으로 사전 학습된 ViT모델은 분류 task에서 ResNet(BiT)기반 모델을 능가
✔︎ 사전 학습에 더 적은 리소스 사용 -
pre-training
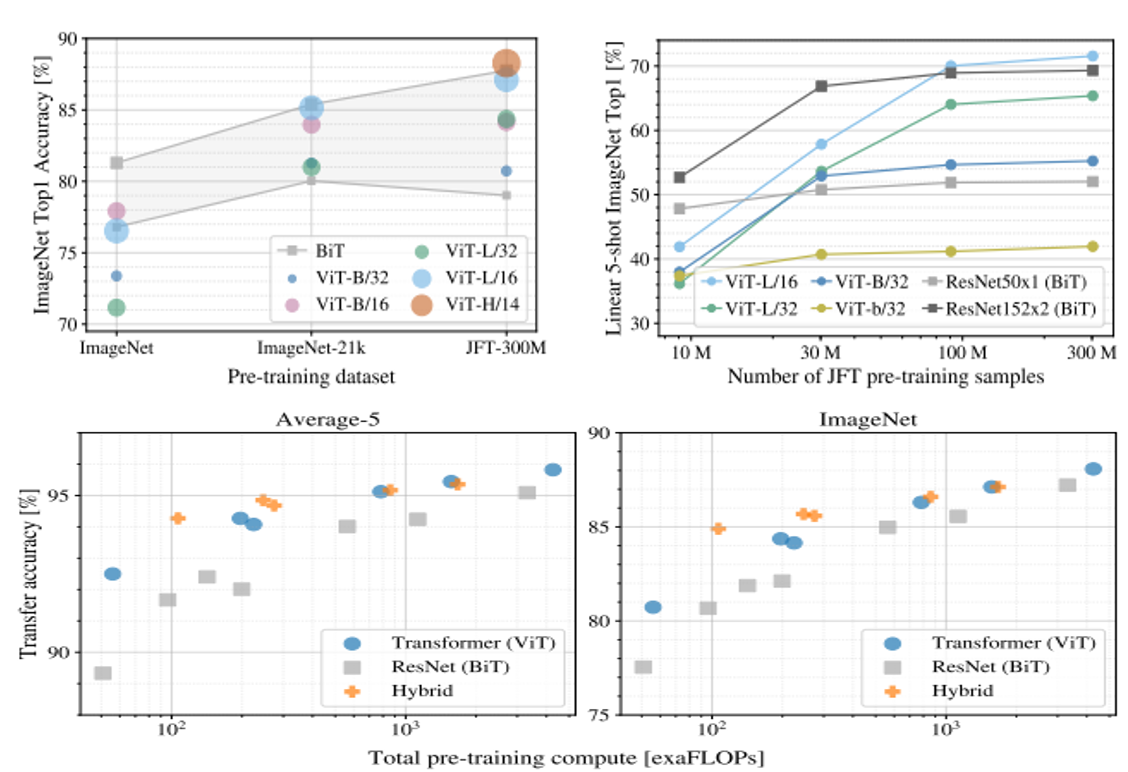
✔︎ 사전학습 데이터셋의 크기가 커질수록 성능이 향상됨
✔︎ 같은 사전학습 계산양으로 두고 보았을 때, CNN기반 모델에 비해 더 성능이 높음
Limitations
- CNN과 달리 self-attention은 이미지의 특성이 반영된 inductive bias가 작다.
이로 인해 방대한 양의 데이터셋으로 사전학습이 필요하다.
→ 이미지가 갖고 있는 locality(지역성) 특징을 추출하는 convolutional filter과 같은 방식이 아닌 global한 특징을 추출하는 Self-attention을 사용하기 때문이다.
후기
AI 분야의 연구가 워낙 빨라 해당 논문은 21년에 나왔지만 지금 리뷰를 하기엔 너무 지난 논문처럼 느껴진다.
하지만 가장 열심히 또 오랫동안 분석하였기에 자신있는 논문이였다.
한줄평은 Transformer를 이미지에 적용하는데 큰 의의를 갖지만 한계점도 드러난 논문인 것 같다.
출처
- Dosovitskiy, Alexey et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ArXiv abs/2010.11929 (2020)
- 코드 구현1, https://github.com/FrancescoSaverioZuppichini/ViT
- 코드 구현2, https://medium.com/@brianpulfer/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
