Purpose
크고 무거운 앙상블 모델은 성능 향상은 있지만, 너무 computation cost가 크다.
해당 논문은에선 다음과 같이 비유한다.
곤충의 유충 형태는 환경으로부터 에너지, 영양을 추출하기에 최적화된 형태이다.
성충 형태일 때는 많은 이동, 번식에 최적화되어있다.
반면, large-scale machine learning에서는 다양한 요건에도 불구하고 매우 유사한 학습, 배포 과정을 사용한다. 이는 많은 연산양을 필요로하고 배포를 까다롭게한다.
다양한 방법으로 앙상블 모델을 하나의 모델로 압축하여 배포하기에 훨씬 더 쉽게할 수 있다.
해당 논문은 "knowledge distillation"이라는 방법을 제안하여 모델의 input과 output의 매핑을 흉내내어 모델의 구조에 제한받지 않고 비교적 적은 computation cost로 성능을 향상시킨다.
Knowledge Distillation
- Student model : 작은 모델
- Teacher model : 크고 무거운 모델(앙상블 모델)
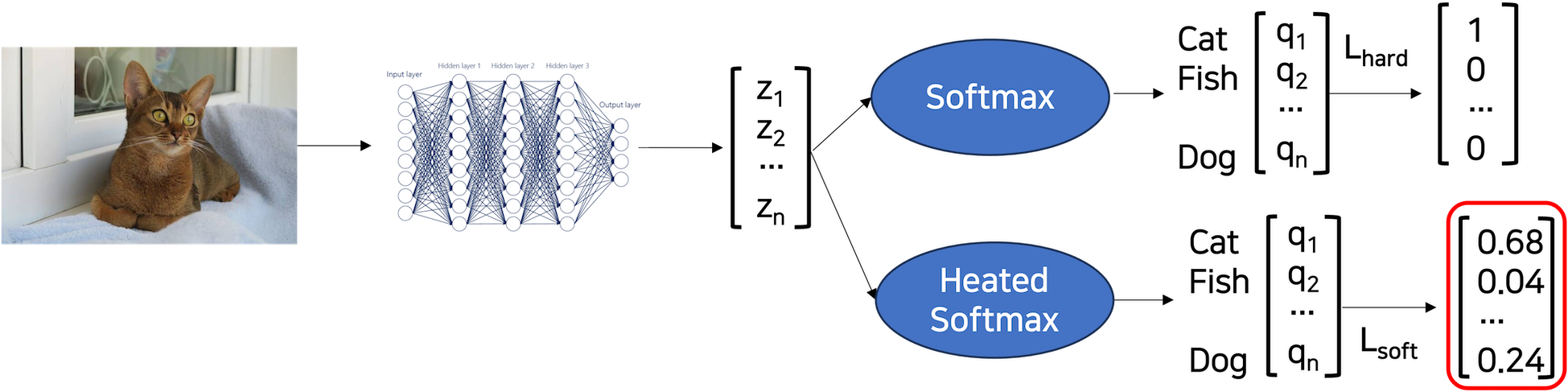
teacher 모델의 class별 확률을 나타내는 "soft target"을 통해 student 모델에게 일반화 능력을 전이하는 방법이다.
soft target이란?
teacher 모델에서 softmax 함수의 output이며, 이는 teacher 모델이 예측하는 class 확률 분포이다. 뒤에서 해당 논문에서 사용하는 Temperature(T)의 개념이 추가된다.
-
그림은 일반적인 앙상블 모델에서의 soft target 예시이다.
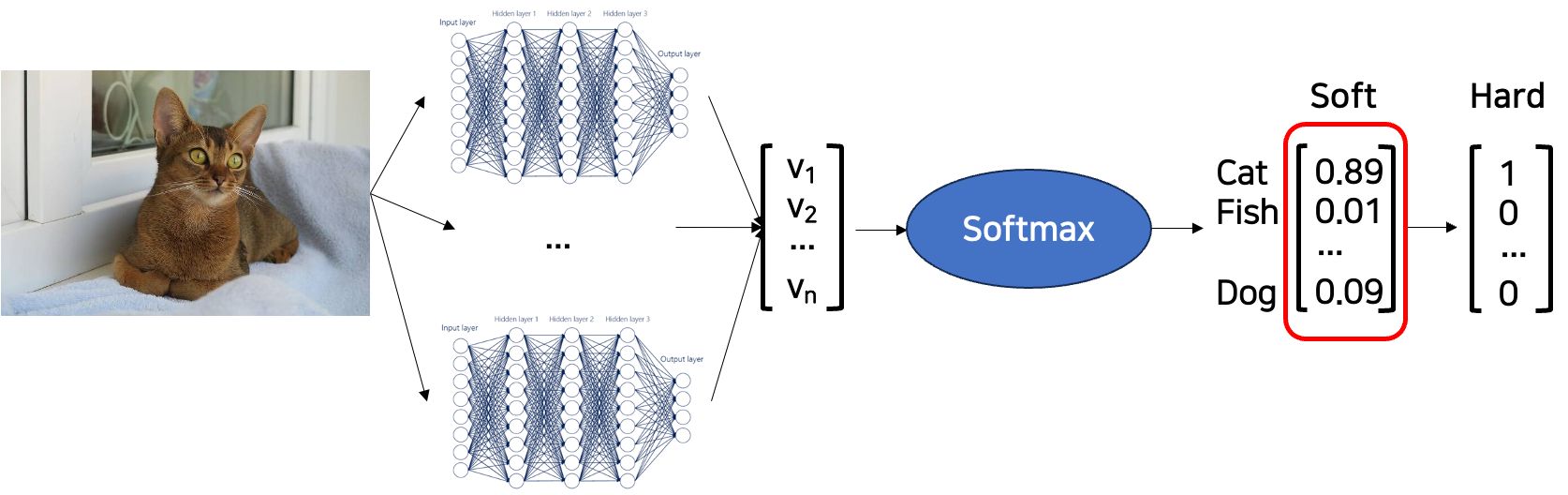
그림에서는 모델이 클래스가 Cat일 확률을 0.89로 보고있다.
이처럼, 쉬운 task일수록 모델은 정답 클래스에 높은 확신을 갖는다.(예를 들면, MNIST 데이터셋)
하지만 fish일 확률 0.01, dog일 확률 0.09와 같은 정보는 0에 너무 가까워서 cross-entropy 비용함수에 거의 영향을 주지 못한다.
따라서 teacher가 student에게 일반화 능력을 전이하기 위해서 cat일 확률이 0.89라는 것도 중요하지만 그 외의 클래스에 대한 확률 역시 중요하기 때문에 Temperature라는 하이퍼파라미터를 사용한다. -
Temperature(T)는 teacher 모델이 적절하게 soft한 target을 생성하도록 최종 softmax의 온도(temperature)를 올려주는 역할을 한다. → class 확률 분포를 scaling한다고 볼 수 있을 것 같다.
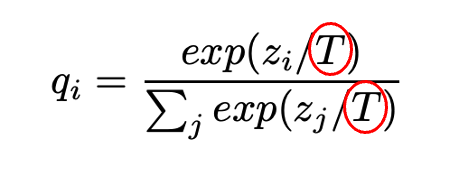
softmax 함수 분모와 분자 logit 각각에 T를 나눠준다 → softmax 가열
- 최종적으로 knowledge distillation의 train
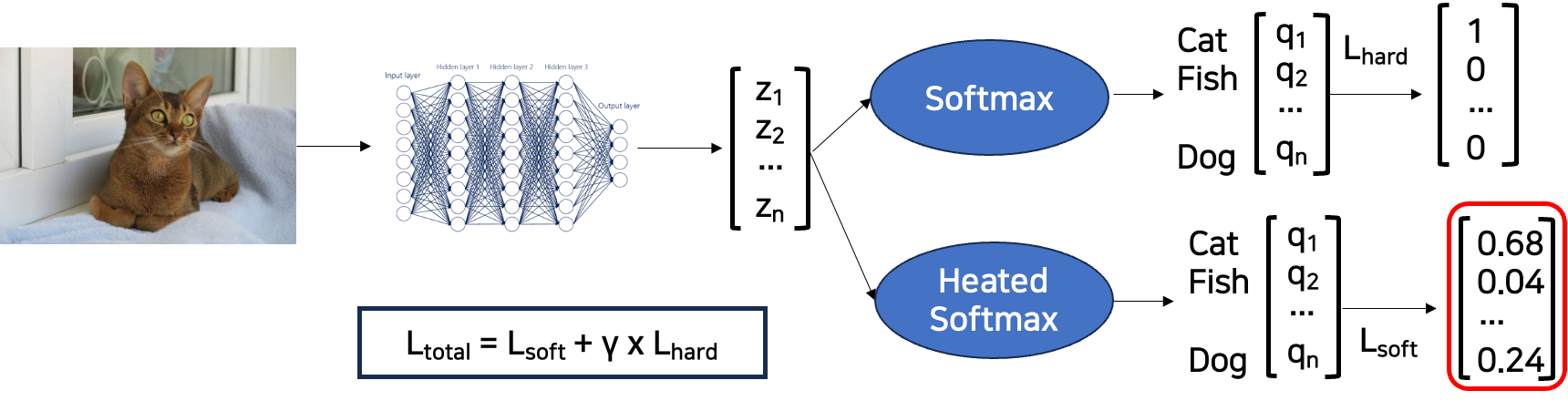
최종적으로 student 모델이 knowledge distillation 기법을 통해 학습할 때는 teacher와 동일한 T로 가열한 soft 값과 teacher의 soft 값의 cross-entropy(1)와 정답 라벨과의 cross-entropy 값(hard)(2)의 weighted average 값이 최종 loss가 된다. (보통 hard loss에 낮은 weight를 주는 것이 더 결과가 좋다고 한다.)
Temperature Setting
-
높은 temperature 일때:
각 확률들이 거의 비슷해짐 → noisy가 증폭될 수 있음 -
낮은 temperature 일 때:
낮은 확률값들은 거의 무시하게 됨 → noisy가 아닐 수 있음
→ Trade-off 관계 -
Standard
간단한 task에 경우 높은 temperature로 작은 확률값들이 무시되지 않게
어려운 task에 경우 낮은 temperature로 (teacher모델이 상대적으로 smart하지 못 할 수 있음)
예제 코드 분석
outline
- CIFAR-10 데이터셋 사용하여 이미지 분류 task
- 간단하게 깊게 쌓은 CNN 모델(teacher)과 상대적으로 얕은 CNN 모델(student)을 정의하기
- Knowledge Distillation을 통해 얕은/간단한 CNN 모델의 accuracy 올리기
- Student model의 knowledge distillation 적용 전과 후의 accuracy 비교하기
Define Teacher model

Define Student model

두 모델의 총 파라미터의 수가 4배 이상 차이나게 CNN 모델을 정의한다.
Teacher / Student model 학습 (distillation X)
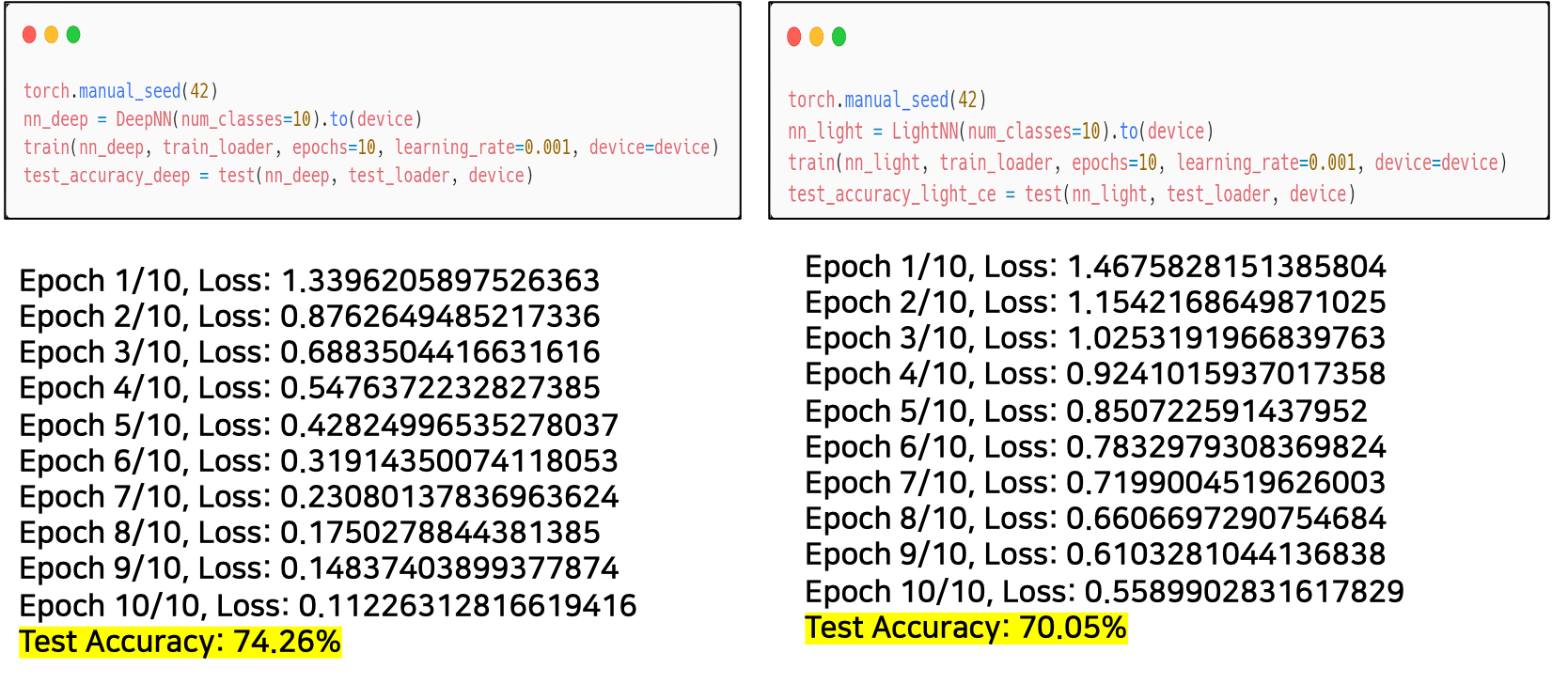
seed를 맞춰 parameter의 initial 값을 동일하게 했다.
knowledge distillation train
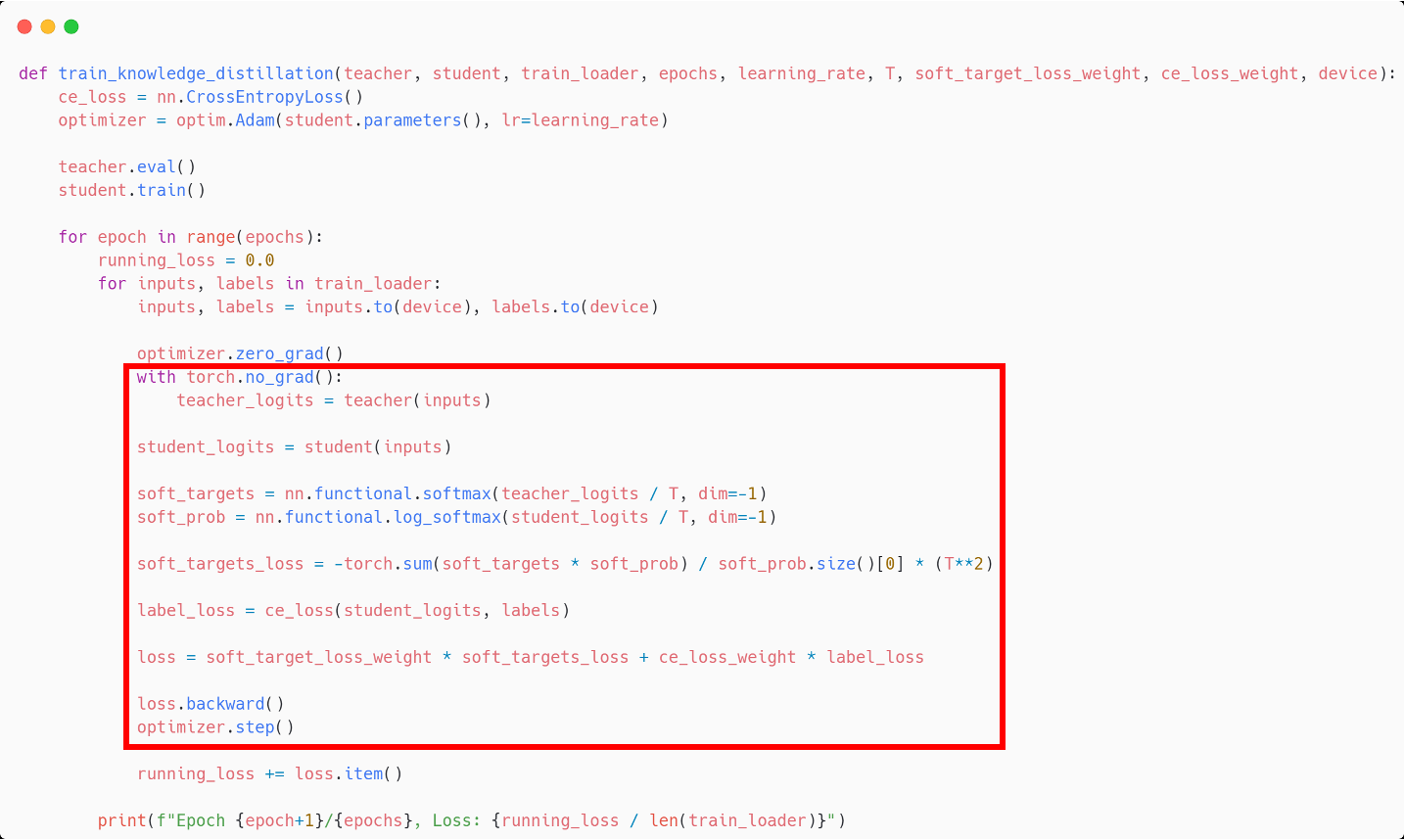
그림에서 빨간색 네모로 마킹해둔 코드가 knowledge distillation을 구현한 부분이다.
(T**2)을 곱하는 부분은 hard loss와 soft loss의 scale을 맞추기 위한 코드이다.
accuracy 비교
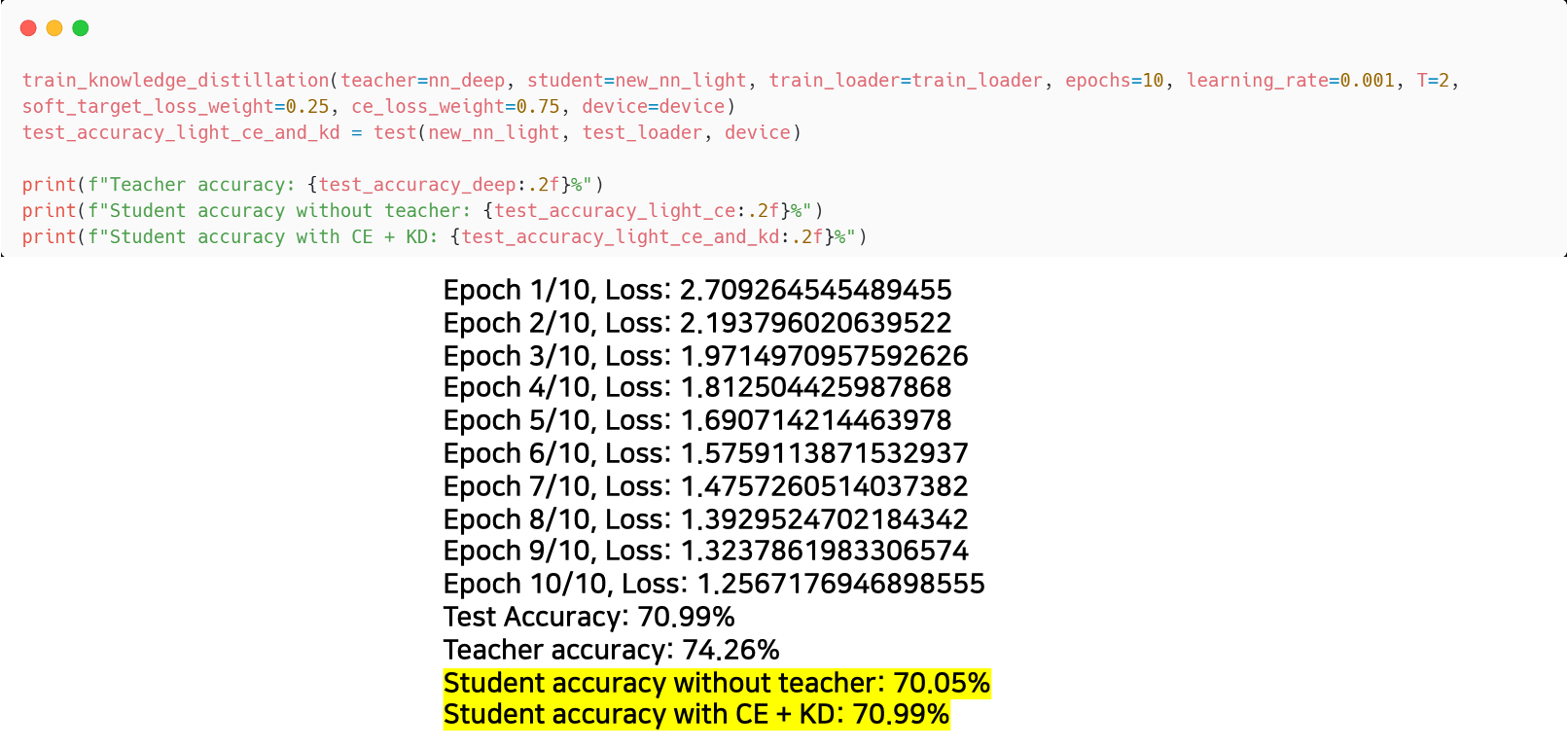
하이라이트 된 마지막 두 행을 통해 knowledge distillation 적용 차이를 확인할 수 있다.
후기
정말 간단하면서도 효과를 볼 수 있는 방법을 제안하고 있어 연구자들이 존경스럽다.
개인적으로 흥미를 느꼈던 연구이기에 이후에 공부했던 self-distillation, Revisiting Knowledge Distillation 두 논문에 대해서 이어서 리뷰를 포스팅할 계획이다.
마지막으로 서울대 김형신 교수님의 유튜브 강의에서 이해하는데 도움이 많이 되었다. 감사합니다.
출처 및 참조
- Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
- Youtube Hyung-Sin Kim 채널, [Ambient AI] Lecture 8: Knowledge distillation
