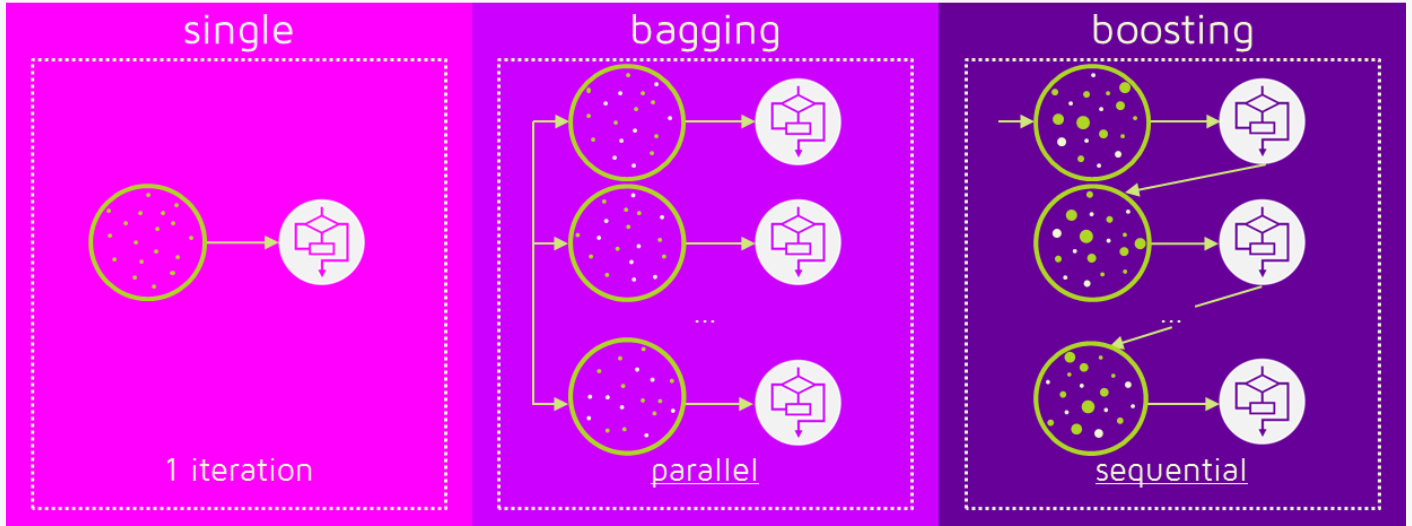
Ensemble
여러 개의 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법
✅ 약한 모델 여러 개를 조합하여 더 정확한 예측 방식 적절한 Hyperparameter 튜닝이 중요
Boosting
이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식
✅ 대표 모델: XGBoost, LightGBM
순차적인 학습을 하며 weight를 부여해서 오차를 보완하므로 학습 시간이 길수 있음
- 배깅 (Bagging): 여러개의 DecisionTree 활용하고 샘플 중복 생성을 통해 결과 도출. 병렬(parallel)로 각각 학습을 진행. RandomForest
- 부스팅 (Boosting): 약한 학습기를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식. 학습한 데이터의 결과에 잘못 예측된 데이터 가중치를 부여하고, 또 그 데이터를 이용하여 학습을 진행하는 방법으로 sequential하게 진행. XGBoost, LGBM
출처: https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
Stacking
여러 개 모델이 예측한 결과 데이터를 기반으로 final_estimator 모델로 종합하여 예측 수행
✅ 성능은 향상될 수 있으나 과대적합(overfitting)을 유발할 수 있음.
스태킹 (Stacking): 여러 모델을 기반으로 예측된 결과를 통해 Final 학습기(meta 모델)이 다시 한번 예측
출처: https://wikidocs.net/165452
Weighted Blending
각 모델의 예측값에 대하여 weight를 곱하여 최종 output 계산
✅ 가중치의 합은 1.0이 되도록 함
XGBoost
!pip install xgboost
from xgboost import XGBClassifier
model = XGBClassifier(n_estimators=50)
model.fit(X_train,y_train)
pred = model.predict(X_test)LightGBM
!pip install lightgbm
from xgboost import LGBMClassifier
model = LGBMClassifier(n_estimators=50)
model.fit(X_train,y_train)
pred = model.predict(X_test)