🔥 Scikit-learn
가장 많이 사용하는 머신러닝 패키지, 많은 머신러닝 알고리즘이 내장되어 있음
from sklearn.family import Modelex)
from sklearn.linear_model import LinearRegression model = LinearRegression()
📌 머신러닝 주요 알고리즘 분류
회귀
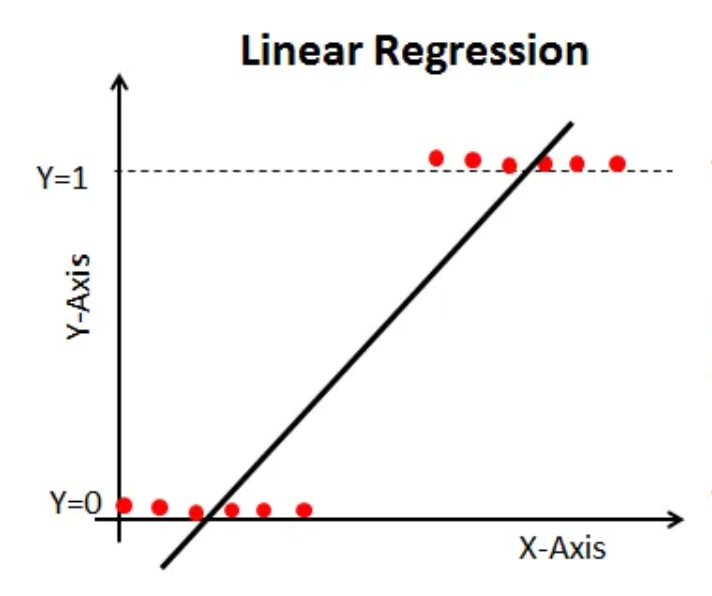
- Linear Regression
분류
- Logistic Regression
이진 분류 규칙은 0과 1의 두 클래스를 갖는 것으로, 일반 선형 회귀 모델을 이진분류에 사용하기 어려움
이를 해결하기 위해 로지스틱(logistic) or sigmoid 함수를 사용하여 로지스틱 회귀 곡선으로 변환하여 이진 분류 할 수 있음
✅ 시그모이드 값 ⍺ < 0.5 이면 0, ⍺ >= 0.5 이면 1로 분류한다.
사용법:from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) pred = model.predict(X_test)
Sigmoid Function출처: https://bit.ly/35MhQwg
회귀분류
- K-Nearest Neighbor
새로운 데이터가 주어졌을 때 기존 데이터 가운데 가장 가까운 k개 이웃의 정보로 새로운 데이터를 예측하는 방법론
✅ 알고리즘이 간단하며, 큰 데이터셋과 고차원 데이터에 적합하지 않음. max_depth은 최대 depth을 의미한다.
사용법:from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors = 3) knn.fit(X_train, y_train) pred = knn.predict(X_test)
출처: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
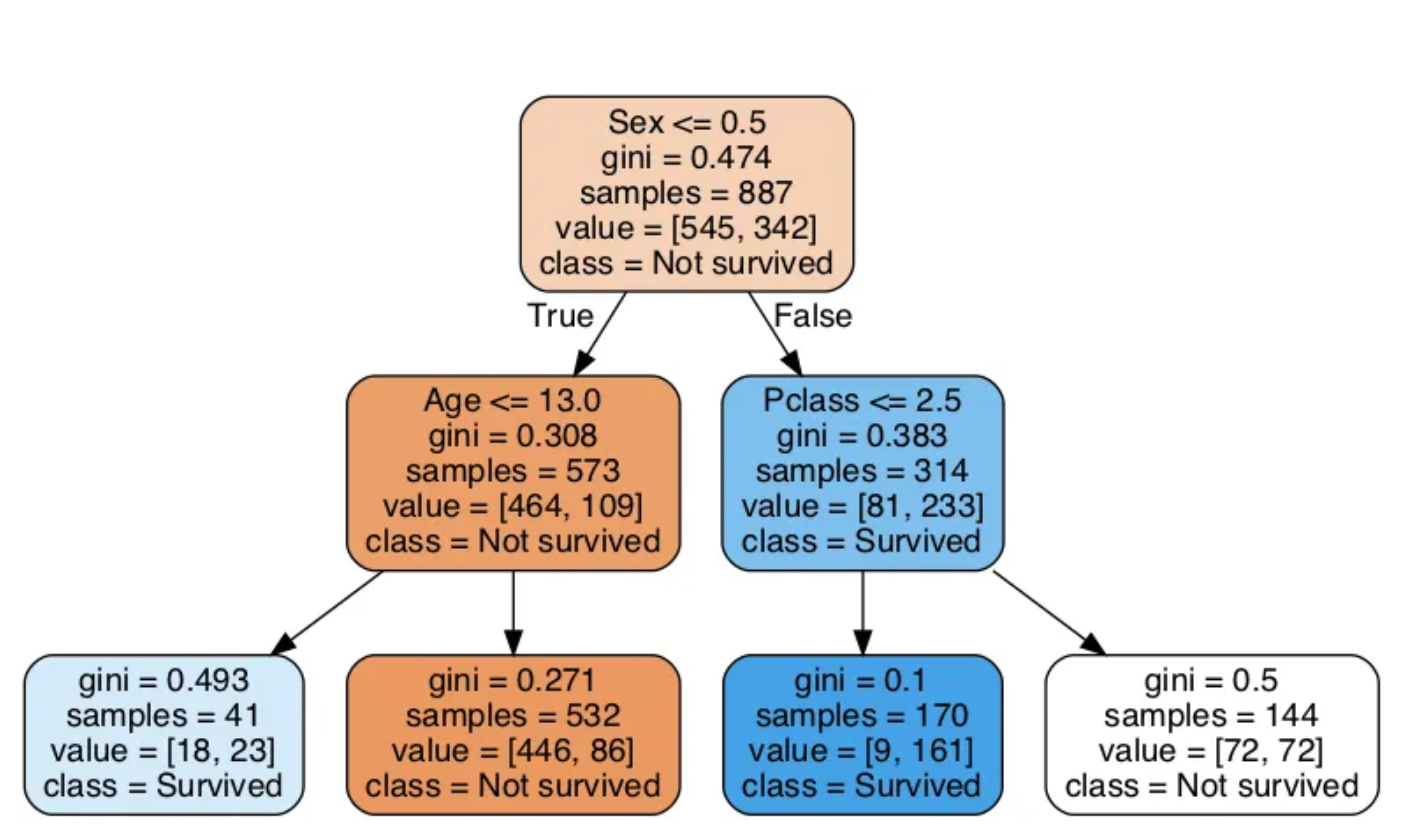
- Decision Tree
분류와 회귀 작업이 가능한 머신러닝 알고리즘
복잡한 데이터셋도 학습할 수 있으며 강력한 머신러닝 알고리즘인 랜덤 포레스트의 기본 구성 요소
사용법:from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(max_depth=2) model.fit(X_train, y_train) pred = model.predict(X_test)
- Random Forest
일련의 예측기(분류, 회귀모델)로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측을 얻을 수 있음
Train set로부터 무작위로 각기 다른 서브셋을 만들어 일련의 결정 트리 분류기를 훈련시킬 수 있음.
✅ 다수결 원칙에 의해 각 트리에서 나온 결과에서 가장 많이 나온 결과를 채택한다. n_estimators의 하이퍼 파라미터는 Decision Tree의 개수를 의미한다.
사용법:from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=50) model.fit(X_train, y_train) pred = model.predict(X_test)
출처: https://www.kaggle.com/discussions/getting-started/176257
 출처:
출처: 