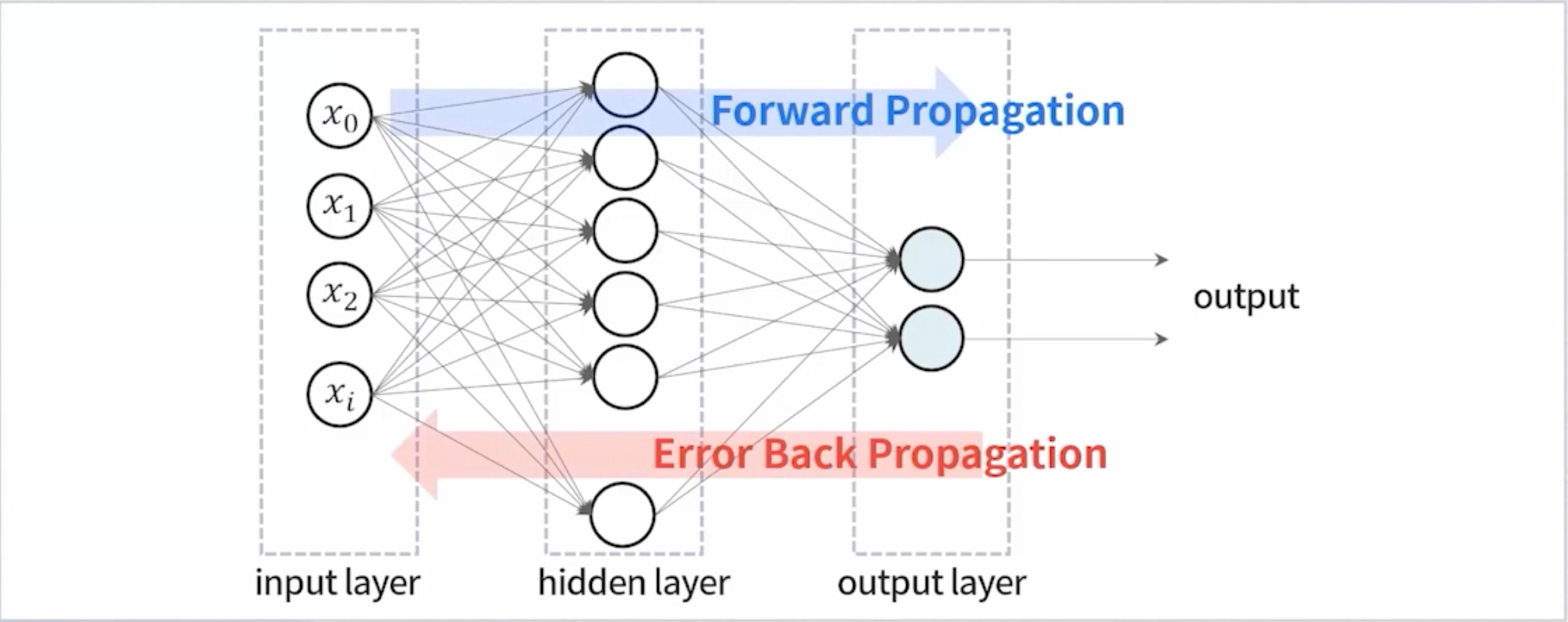
📌딥러닝 학습 방법
딥러닝 모델의 매개변수(weight, bias)를 무작위로 부여한 후, 반복학습을 통해 모델의 출력값을 정답과 일치하도록 매개변수를 조금씩 조정함 -> Gradient Descent 최적화 알고리즘
Perceptron
Perceptron이란 인공 신경망(Aritificial Neural Networt, ANN)의 구성 요소로서 다수의 값을 입력받아 하나의 값으로 출력하는 알고리즘이다.
Perceptron은 perception과 neuron의 합성어이며 인공 뉴런이라고도 부른다. 즉, 뉴런의 동작 과정을 통계학적으로 모델링한 알고리즘. 아래 사진에서 Step Function에 해당되는 부분을 Activation Function이라고 부름출처: https://deepai.org/machine-learning-glossary-and-terms/perceptron
DNN (Deep Neural Network)
DNN이란 입력층(input layer)과 출력층(output layer) 사이에 여러 개의 은닉층(hidden layer)들로 이뤄진 인공신경망이다. 신경망 출력에 비선형 활성화 함수를 추가하여 복잡한 비선형 관계를 모델링 할 수 있음
출처: https://url.kr/5rj9ag
Activation Function
⭐️ vanishing gradient :
딥러닝 분야에서 Layer를 많이 쌓을수록 데이터 표현력이 증가하기 때문에 학습이 잘 될 것 같지만, 실제로는 Layer가 많아질수록 학습이 잘 되지 않는다. 기울기 소실(vanishing gradient) 현상 때문이다.
기울기 소실이란 역전파(Backpropagation) 과정에서 출력층에서 멀어질수록 Gradient값이 매우 작아지는 현상이다.
출처: https://www.kaggle.com/discussions/getting-started/118228
-
Sigmoid Function:
sigmoid 함수의 미분 값은 입력값이 0일 때 가장 크지만 0.25에 불과하고 x값이 크거나 작아짐에 따라 기울기는 거의 0에 수렴한다. 따라서, 역전파 과정에서 sigmoid 함수의 미분값이 거든 곱해지면 출력층과 멀어질수록 Gradient 값이 매우 작아진다. -
tanh(hyperbolic tangent function):
sigmoid처럼 비선형 함수이지만 결과값의 범위가 -1부터 1사이 이기에 중심값이 0이다. sigmoid 함수보다 optimazation이 빠르다는 장점이 있다. 하지만 tanh 함수 역시 x값이 크거나 작아짐에 따라 기울기 크기가 크게 작아지게 때문에 vanishing gradient 문제가 발생한다. -
ReLU(Rectified Linear Unit):
이 함수는 vanishing gradient 문제를 해결한 함수로 입력값이 양수일 경우, 입력값에 상관없이 항상 동일한 미분 값은 1이다. 즉, 역전파 과정에서 기울기 소실되는 문제를 해결한다. 장점은 sigmoid, tanh에 비해 converge되는 속도가 빠르다. 단점으로는 "dying Relu problem"이 발생한다. 입력값이 음수일 경우 미분값은 항상 0이다. 즉, 입력값이 음수인 뉴런은 다시 회생시키기 어렵다는 한계가 있다. 따라서 해당 뉴런이 한 번도 발현하지 않게 될 수도 있다. 최악의 경우에는 네트워크 전체 뉴런의 40%가 죽어있는 경우도 발생한다. 이것을 방지하기 위해 learning rate를 크지 않게 조절하는 것이 중요하다. 또 다른 해결 방안으로는 leaky relu와 같은 activation function을 사용할 수도 있다. -
Leaky ReLU
Leaky ReLU는 입력값이 음수일 때 출력값을 0이 아닌 0.001과 같은 매우 작은 값을 출력하도록 설정한다. 이는 입력값이 음수라도 기울기가 0이 되지 않아 뉴런이 죽는 현상을 방지할 수 있다.
 출처:
출처: ⭐️ Loss Function
🔥 회귀모델 평가
MSE (Mean Squared Error)
제곱을 하기 때문에 특이치(Outlier)에 민감하다.
MAE (Mean Absolute Error)
절대값을 취하기 때문에 가장 직관적으로 알 수 있는 지표이다.
절대값을 취하기에 모델이 Underperformance(실제보다 낮은 값으로 예측)인지 Overperformance(실제보다 높은 값으로 예측)인지 알 수 없다.
🔥 분류모델 평가
이진분류(Binary cross-entropy)
Training data로 가중치와 편향을 학습하고 새롭게 들어온 데이터에 Class 2개 중 속하는 곳을 알려주는 것이다.
다중분류(Categorical cross-entrpy)
분류해야할 Class가 3개 이상인 경우 사용된다.
⭐️ Back Propagation (역전파)
실제값과 예측값에서 오차를 구해서 오차를 output에서 input 방향으로 보냄. 즉, 가중치를 재업데이트 하면서 학습 진행
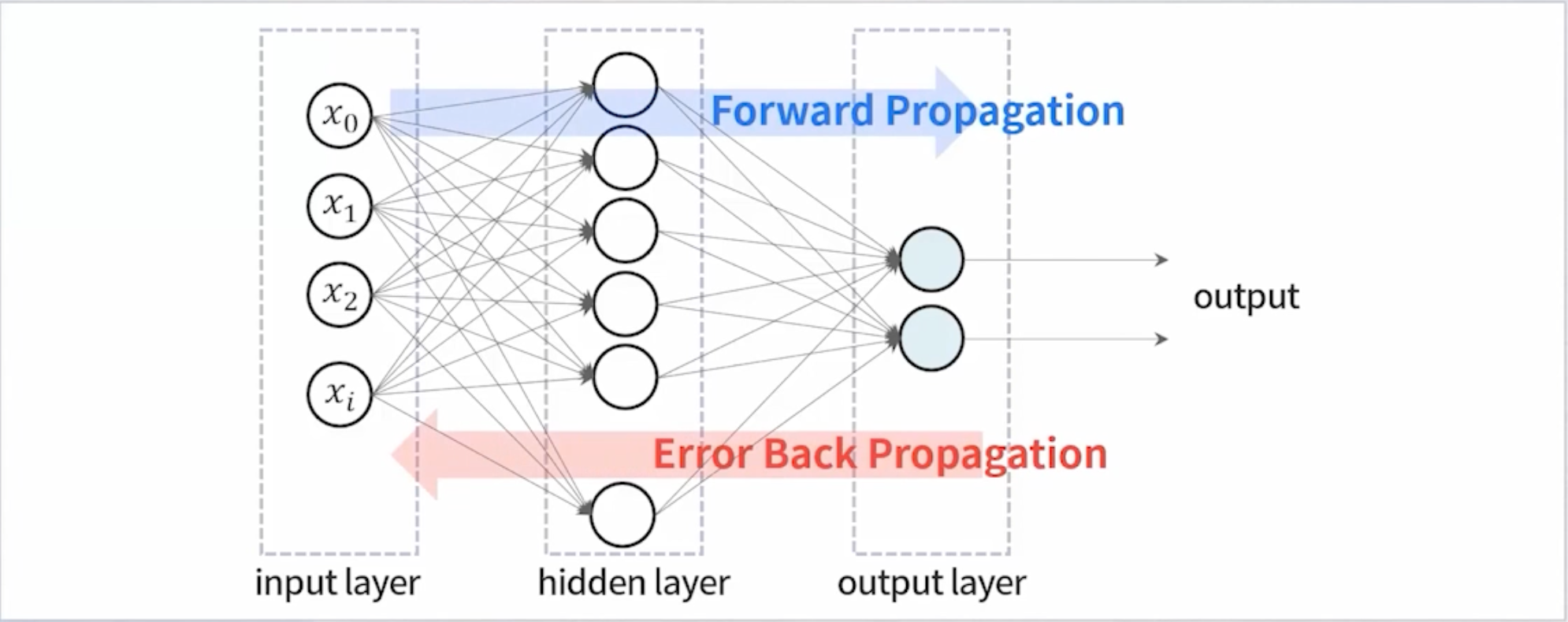 출처:
출처: 