Redis는 NoSQL 데이터 베이스이다.
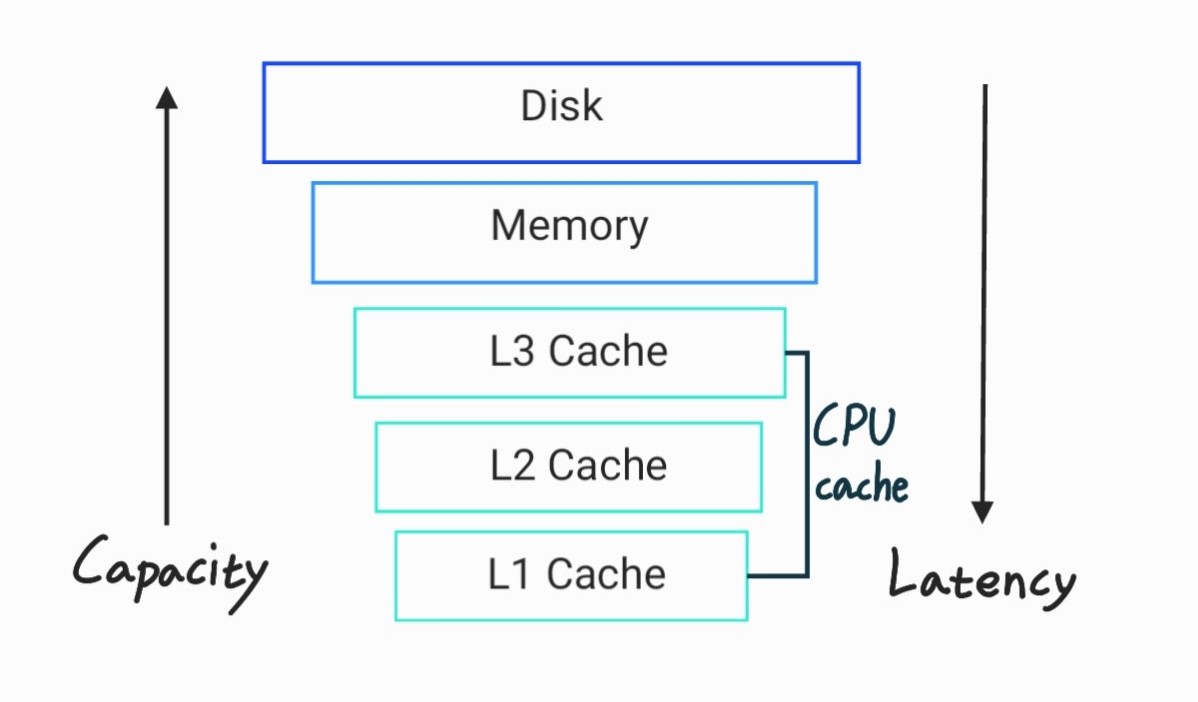
In-memory 구조로 기존 관계형데이터베이스 보다 데이터 전송 속도가 상당히 빠르다.
⇒ 인메모리 구조로 되어있어서 데이터를 메모리에 저장하게 되는데, 메모리 접근이 일반적으로 사용되는 방식인 디스크접근보다 빠르기 때문이다.
💡 NoSQL ?
NotOnlySQL의 약자로 SQL을 보완한다는 의미를 가지고 있다.
레디스가 다른 캐시 시스템과 다른 특징
- Redis는 List, Set, Sorted Set, Hash 등과 같은 Collection을 지원합니다.
- Race condition에 빠질 수 있는 것을 방지함
- Redis는 Single Thread
- 따라서 Atomic 보장 (Atomic = 원자성을 의미. )
- persistence(영속성)를 지원하여 서버가 꺼지더라도 다시 데이터를 불러들일 수 있습니다.
💡 Race condition ?
두 개 이상의 cocurrent한 프로세스(병행 프로세스.)(혹은 스레드)들이 하나의 자원(리소스)에 접근하기 위해 경쟁하는 상태를 말합니다.
💡 Atomicity : 원자성은 관련된 작업들이 부분적으로 실행되다가 중지되는 것이 아니라 하나의 원자 단위로 수행되는 것을 보장하는 특징입니다. 즉, 중간 단계까지 실행되는 것이 아니라 처음부터 끝까지 완전하게 실행되며 중간에서 실패하는 일이 없도록 합니다.
Redis의 주요 사용처
- Remote Data Store
- 여러 서버의 Data 공유를 위해 사용될 수 있음.
- 특히, Redis의 경우 Single Thread 이므로 Race Condition 발생 가능성이 낮다는 것을 활용할 필요가 있을 경우
- 인증 토큰 개발
- Ranking Board (Sorted Set)
- 유저 API Limit
- Job QUeue
Redis 기본 자료 구조 및 명령어
자료 구조 ⇒ Strings, List, Set, Sorted Set, Hash, expire 있다.
< Strings >
일반적으로 사용되는 Key - Value의 형식을 가지는 자료구조입니다. key와 value의 관계는 1 : 1이 됩니다.
(*모든 종류이 문자열을 저장할 수 있어서 JPEG이미지를 저장하거나 HTML fragment를 캐시하는 용도로 자주 사용됨. 저장할 수 있는 최대 사이즈는 512MB. )
기본 명령어 : get, set, del
- get key : key에 해당하는 value를 가져온다. get kim → kim이라는 key 값의 value를 가져온다. 비어있으면 nil이라고 나옴.
- set key value : key에 value를 저장. set kim kind → kim이라는 key에 kind라는 value 값을 넣어준다.
- del key : key를 삭제. del kim → kim이란 key 값을 가지고 있는 것을 삭제한다. ⇒ key 값은 중복이 될 수 없음으로 kim은 하나뿐일 것.
< List >
Redis Collection 중 하나인 List입니다. List는 redis Strings의 묶음 자료구조
입니다. Last 또는 First에 삽입, 삭제가 가능합니다. Redis는 List의 자료구조로 Quick List를 사용한다고 합니다. Quick List의 자세한 내용은 문서
를 참고해주세요.
(*리스트의 중간에 데이터를 삽입해야하는 상황이 있을 수 있다면 List구조는 사용하지 않는다. 대표적인 list 사용 사례는 Pub-Sub패턴이 있다.)
기본 명령어 : lpush , rpush, lpop, rpop, lrange
- lpush key value : List의 index 0쪽으로 데이터를 넣는다. (가장 앞부분에 삽입.)
- rpush key value : List의 index last 쪽으로 데이터를 넣는다. (가장 뒷부분에 삽입)
- lrange key start end : List의 start부터 end까지의 element를 반환.
- lpop key : List의 index 0의 데이터를 꺼내서 반환하고 없앤다.
- rpop key : List의 index last의 데이터를 꺼내서 반환하고 없앤다.
< Set >
중복되지 않는 값을 데이터로 가지는 Collection입니다. 때문에 동일한 값을 입력하면 결과적으로 하나의 값만 남습니다.
또한 Set은 집합이라는 의미에서 value를 member라 부릅니다. 해당 Collection은 순서를 가지지 않습니다. 이런 Set Collection은 좋아요를 누른 사람 수, 특정 상품을 본 사람 수 등을 나타내는데 사용될 수 있습니다.
기본 명령어 : sadd, srem, smembers , scard , spop
- sadd key member : set에 value를 하나 추가
- srem key : set에서 key를 삭제
- smembers key : set에 속해있는 모든 member를 조회
- scard key : set에 속해있는 member의 갯수를 반환
- spop : set에서 무작위로 member를 반환.
< Sorted Set >
중복되지 않는 값을 데이터로 가지는 Collection입니다. 또한 가중치(Score)를 가지고 있고 가중치(Score)에 따른 정렬된 순서를 가지고 있습니다. Score가 같으면 value로 sort됩니다. Value는 중복되지 않으며 Score는 중복될 수 있습니다.
Sorted Set은 특정 API의 TPS를 조절 하거나 Ranking 등에 이용될 수 있습니다.
(*실제로 Sorted set을 사용해서 스코어에 따른 랭킹을 많이 구현한다. 일일이 sorted를 짤 필요 없어서 비교적 간편히 이용할 수 있음.)
기본 명령어 - zadd, zcard, zrange, zrangebyscore
- zadd key score member : 집합에 Score와 Value를 추가합니다.
- zcard key : 집합 속에 있는 member의 갯수를 조회합니다.
- zrange key start stop : index를 범위로하여 조회합니다.
- zrangebyscore key min max : socore를 범위로하여 조회합니다.
< Hash >
내부에 또 다른 Key - value로 이루어진 자료구조
입니다. Hashes는 key 하나에 여러개의 field와 value로 구성됩니다. key 하나에 field와 value 쌍을 40억개(4,294,967,295)까지 저장 가능합니다.
(*RDB의 table과 유사하다. hash의 Key = table의 PK, field = column, value = value. )
기본 명령어 - hset, hget, hdel, hlen, hgetAll, hkeys, hvals
- hset key field value : key에 field와 value를 쌍으로 저장합니다.
- hget key field : key에서 field로 value를 가져옵니다.
- hdel key field : key에서 field를 삭제합니다.
- hlen key : field의 갯수를 반환합니다.
- hgetAll key : field와 value를 모두 반환합니다.
- hkeys key : 모든 field를 반환합니다.
- hvals key : 모든 value를 반환합니다.
< Expire >
expire는 지정한 시간 이후 key를 자동 삭제하는 명령어입니다. key-value 쌍에 Time To Live를 설정할 수 있습니다. 사용에 주의해야할 점이 있습니다. 바로 set, getset의 명령어를 expire 명령어 이후에 key에 다시 적용하면 expire 명령은 없어진다는 것입니다. 따라서 새로 expire를 설정해야합니다. incr, lpush, sadd, zadd, hset와 같은 명령어는 그대로 유지힙니다.
명령어 - expire, ttl
- expire key member second : key에 ttl을 설정합니다.
- ttl key : 남은 ttl을 초단위로 확인합니다.
💡 레디스가 인메모리DB인 만큼, 저장할 수 있는 데이터가 한정적이다. 때문에 레디스는 메모리가 꽉차면 가장 먼저 들어온 데이터를 삭제하거나(FIFO), 사용한 적이 먼 데이터를 삭제하거나(LRU), 더이상 데이터를 입력받지 못하게 한다.
그래서 개발자가 직접 expire를 설정해주는 것이 좋다. timeout을 설정하여 데이터를 적절한 때에 삭제해주며 메모리를 관리해야한다.
💡 페이지 교체 알고리즘 (Page Replacement Algorithm)
(*여기서 말하는 페이지란 가상메모리를 일정한 크기로 나눈 블록을 의미한다.)
페이징 기법으로 메모리를 관리하는 운영체제에서 필요한 페이지가 주기억장치에 적재되지 않았을 시(페이지 부재) 어떤 페이지 프레임을 선택하여 교체할 것인지 결정하는 방법을 페이지 교체 알고리즘
이라고 한다.- FIFO(First In First Out)
가장 먼저 메모리에 올라온 것을 내보내는 것.- OPT(Optimal)
앞으로 가장 오랫동안 사용되지 않을 페이지를 내보내는 것..
****가장 이상적인 방법이나, 프로세스가 앞으로 사용할 페이지를 미리 알아야한다. (불가능함.) 주로 비교 연구 목적을 위해 사용된다.- LRU(Least Recently Used)
가장 오랫동안 사용하지 않은 페이지를 내보내는 것.- LFU(Least Frequently Used)
참조 횟수가 가장 낮은 페이지를 내보내는 것.- MFU(Most Frequently User)
참조 횟수가 가장 많은 페이지를 내보내는 것.
