1) 회귀분석 개요
(1) 회귀분석의 개념
1. ⭐회귀분석⭐
- 회귀분석이란 하나 이상의 독립변수(x1, x2, x3, ...)들이 종속변수(y)에 얼마나 영향을 미치는지 추정하는 통계기법이다.
- 독립변수와 종속변수 간에 인과관계가 있따는 말은 독립변수가 원인이 되어 종속변수에 영향을 미친다는 의미다. 그런 의미에서 독립변수를 원인변수(혹은 설명 변수), 종속변수를 결과변수(혹은 반응 변수)라고도 한다.
- 독립변수가 하나이면 단순선형회귀분석, 2개 이상이면 다중선형회귀분석으로 분석할 수 있다.
- 회귀분석은 기본적으로 변수가 연속형 변수일 때 사용하며, 범주형 변수일 경우 파생변수로 변환하여 사용한다. 만약에 종속변수가 범주형일 경우 로지스틱 회귀분석을 사용한다. 추후 로지스틱 회귀분석에서 자세히 다루기로 한다.
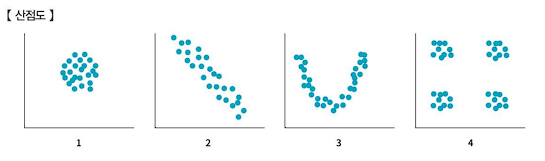
- 변수들이 일정한 경향성을 띤다는 의미는 그 변수들이 일정한 인과관계를 갖고 있다고 추측할 수 있다. 따라서 산점도를 봤을 때 일정한 추세선이 나타난다면, 경향성을 가지거나 혹은 변수들 간에 인과관계가 존재한다고 미루어 생각할 수 있다.
- 다음의 산점도를 보면 2번 그래프는 선형적인 추세선을, 3번 그래프는 2차 곡선 형태의 추세선을 나타내고 있다. 나머지 1번과 4번에서는 데이터들이 어떤 추세선을 나타낸다고 보기 어렵다. 분석을 하기 전 미리 EDA를 통해 산점도를 그려보면 변수들 간에 어떤 의미 있는 관계가 있는지 미리 짐작할 수 있다.
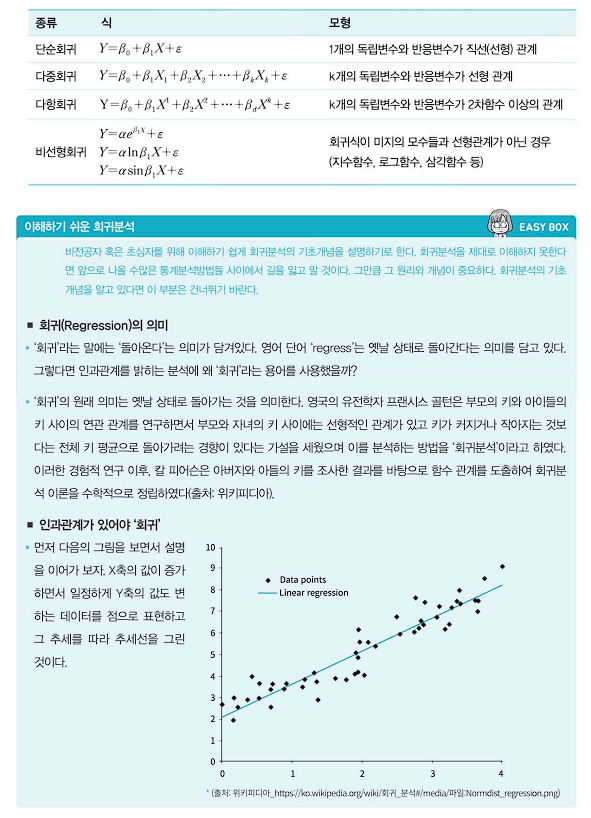
- 회귀분석의 종류

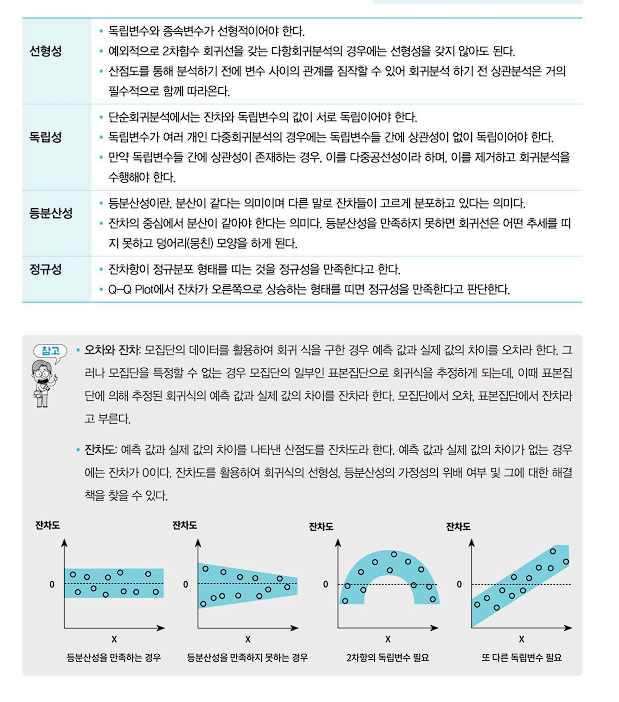
(2) ⭐회귀분석의 가정⭐
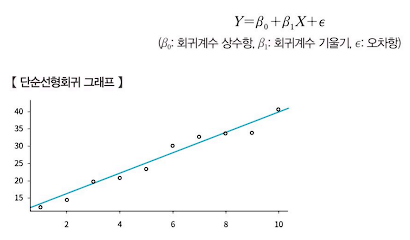
2) 단순선형회귀분석
(1) 회귀계수의 추정
1. 단순선형회귀분석
- 독립변수와 종속변수가 1개씩일 때 둘 사이의 인과관계를 분석하는 것으로, 두 변수의 관계가 선형이다.
- 최소제곱법을 활용하여 실제 데이터와 오차가 가장 작아지는 직선의 방정식을 찾는다.
- 최소제곱법으로 회구계수 추정
- 최소제곱법을 통해 파라미터를 추정하고 추정된 파라미터를 토해 추세선을 그려 값을 예측하는 것이 회귀분석의 기본 알고리즘이다.
- 최소제곱법이란 실제 관측치와 추세선에 의해 예측된 점 사이의 거리, 즉 오차를 제곱해 더한 값을 최소화 하는 것이다. 좌표평면상에서 다양한 추세선이 그려질 수는 있지만, 잔차의 제곱 합이 최소가 되는 추세선이 가장 합리적인 추세선이고 이를 통해 회귀분석을 실행한다.
- 다음 그림에서 오차(파란색) 제곱합이 왼쪽보다 오른쪽 직선이 더 작기 때문에 오른쪽 직선이 더 이상적인 회귀추세선이다.
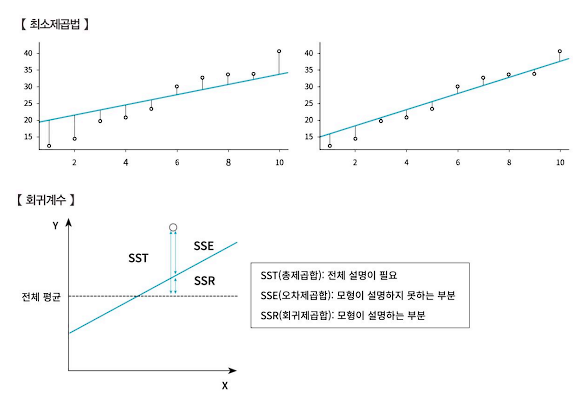
(2) ⭐회귀분석모형의 적합성⭐
1. 회귀분석의 분산분석표
- 회귀분석의 결과에 대한 모형 적합성을 검정하기 위해서는 분산분석표를 사용해야 한다. 독립변수가 1개라면 단순회귀분석, 2개 이상이라면 다중회귀분석을 시행한다. 단순회귀분석과 다중회귀분석의 분산분석표는 다음과 같다.
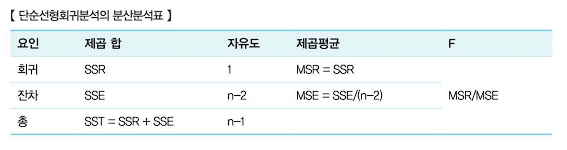
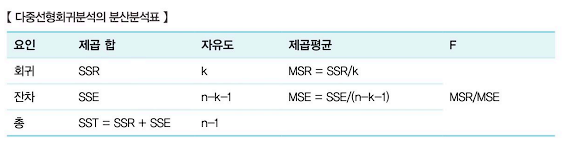
- ⭐회귀모형의 통계적 유의성 검증⭐
- 회귀모형의 통계적 유의성은 F-검증을 통해 확인한다.
- F-검정은 분산의 차이를 확인할 때 사용되는데, 바로 이 분산의 차이가 크다는 것은 회귀모형에서 회귀계수가 크다는 의미를 갖는다.
- F통계량 즉, F값이 크다는 말은 회귀계수가 크고 가파르다는 말과 같으니 변수 간에 유의미한 인과관계가 존재한다고 볼 수 있다는 것 이다.
- 따라서 F갑싱 크면, F값이 '0'에서 얼마나 가까운지 확률적으로 측정한 값인 P값은 상대적으로 작아진다. P값은 회귀모형에서 0.05보다 작을 경우 유의미한 인과관계가 있다고 판단하는 중요한 기준이 된다.
- 회귀계수의 유의성 검증
- 회귀계수의 유의성은 t-검정을 통해 확인할 수 있다. t-통계량은 회귀계수를 표준오차로 나눈 값이다. 따라서 t-통계량이 크다는 것은 분모가 작다는 의미이므로 분모에 해당하는 표준오차가 작다고 볼 수 있다. 반대로 말하면 분자인 회귀계수가 분모보다 크다는 말과 같다.
- t-통계량이 크면 회귀계수도 커지고, 회귀계수가 크므로 유의미한 인과관계가 검증이 되는 것이다. 위의 회귀모형의 통계적 유의성 검증에서 살펴본다면, t-통계량이 크면 회귀계수도 커지고 변수 간에 유의미한 인과관계가 존재하며 P값은 작아진다.
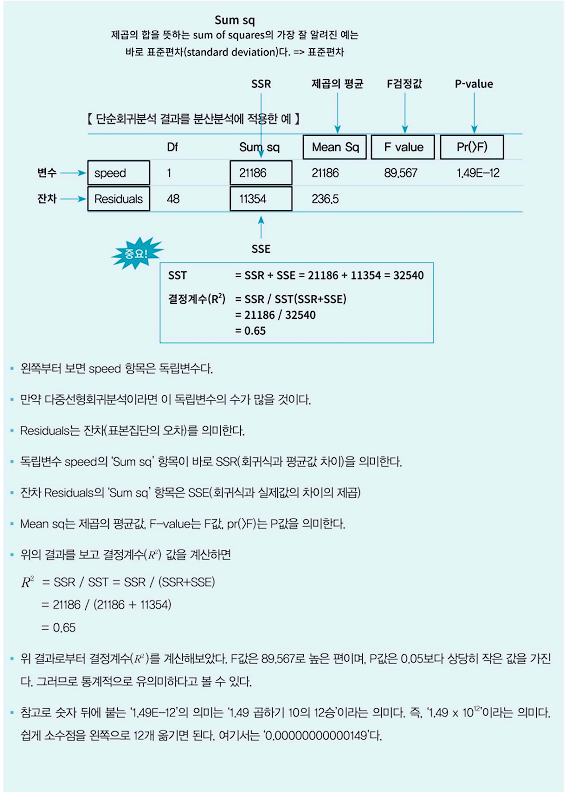
- ⭐모형의 설명력⭐
- 회귀모형의 설명력이 좋다는 의미는 데이터들의 분포가 회귀선에 밀접하게 분포하고 있다는 의미다.
- 회귀분석 결과를 분산분석하고, 도출된 결졍계수 R로 모형의 설명력을 판단한다.
- 결정계수 R이 1에 가깝다면 데이터들이 회귀선에 매우 밀접하게 분포한다는 것이며, 이는 곧 회귀모형의 예측력이 높다는 말과도 같다. 다른 말로 결정계수가 1에 가까울수록 회귀모형이 주어진 자료를 잘 설명한다고 말하기도 한다.
- 결졍계수 R을 구하는 공식은 다음과 같다.
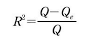
- 여기서 Q는 전체 데이터들의 편차들을 제곱하여 합한 값이며, Qe는 전체 데이터들의 잔차들을 제곱하여 합한 값이다.
- 따라서 이를 다른 공식으로 풀어보면 다음과 같다.

(3) ⭐단순선형회귀분석의 예⭐
1. 자동차 배기량과 연비 회귀분석
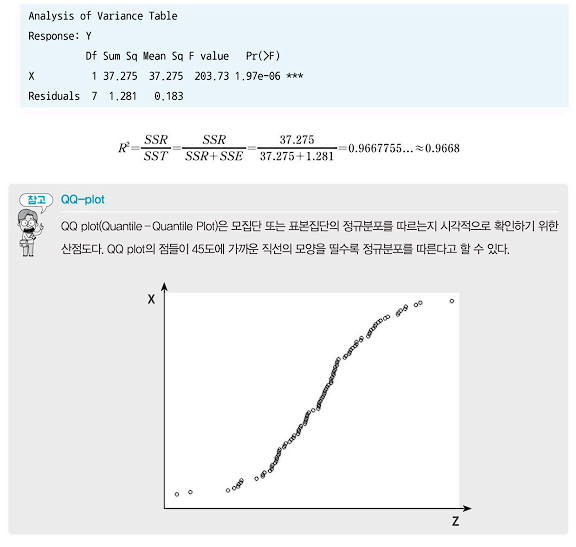
- 다음과 같이 자동차 배기량에 따른 연비 데이터가 있다고 가정해보자. 자동차 배기량과 연비의 인과관계가 존재하는지 회귀분석을 통해 회귀함수를 구해보자.


- p-value의 값이 1.97e-06으로, 유의수준 0.05에서 회귀분석의 귀무가설을 기각한다.
- 따라서'모든 회귀계수는 0이다'라고 할 수 없으므로 주어진 모형은 통계적으로 유의한다.
- 모형이 유의하면 각 회귀계수에 대한 p-value를 확인해야 한다. X의 회귀계수 p-value는 1.97e-06으로 독립변수 X에 대한 귀무가설을 기각한다. 따라서 X의 회귀계수는 -2.4371일 것으로 추정 가능하다.
- 상수향의 추정치는 16.8291이다.
- 따라서 추정되는 회귀식은 Y(연비) = {-2.4371 * (배기량X)} + 16.8291이다.
- 분산분석표와 수정계수





3) 다중선형회귀분석
(1) 다중선형회귀분석
- 독립변수가 2개 이상이고 종속변수가 하나일 때 사용 가능한 회귀분석으로 독립변수와 종속변수의 관계가 선형으로 표현된다. 단순회귀분석이 확장된 형태로 기본적인 회귀계수 및 통계적 유의성 검증 등은 단순회귀분석과 같다. 독립변수가 여러 개이므로 회귀계수도 여러 개다.
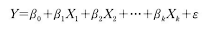
(2) ⭐다중공선성⭐
1. 다중선형회귀분석에서 주의할 것은 다중공선성에 관한 문제다. 독립변수가 1개인 단순선형회귀분석에는 전혀 문제가 안 되지만 독립변수가 2개 이상인 다중선형회귀분석에서는 다중공선성에 유의해야 한다.
- 다중공선성이란 회귀분석에서 독립변수 간에 강한 상관관계가 나타나는 문제다. 다중공선성이 존재하면 회귀분석의 기본 가정인 독립성(독립변수 간에는 상관관계가 없이 독립니다)에 위배된다.
- 또한 A, B라는 변수가 있을 때 이 둘 사이에 다중공선성이 존재하면 A라는 변수가 Y값에 어느 정도의 영향을 미치는지, 또는 B라는 변수가 Y값에 어느 정도 영향을 미치는지 정확하게 판단할 수 없다.
- 다중공선성을 해결하지 않고 분석을 하면 분석 결과의 회귀계수를 신뢰할 수 없고 잘못된 결과가 나올 수있다.
- 다중공선성의 진단
- 결정계수 R^2값이 커서 회귀식의 설명력은 높지만 각 독립변수의 P-value값이 커서 개별 인자가 유의하지 않은 경우 다중공선성을 의심할 수 있다.
- 독립변수 간의 상관계수를 구한다.
- 분산팽창요인(VIF)을 구해 이 값이 10을 넘는다면 보통 다중공선성이 있다고 판단할 수 있다.
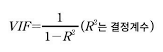
- 다양한 다중공선성 문제 해결법
- 다중공선성의 문제가 발생하는 변수를 제거한다.
- 주성분분석(PCA)을 통해 변수의 차원을 축소한다. 여기서 차원을 축소한다는 의미는 단순히 변수를 삭제하여 차원을 줄이는 게 아니라 원래 데이터가 가진 내재적 속성을 보존하면서 데이터를 축소하는 방법을 의미한다.
- R에서'스크리 산점도(Scree plot)'를 사용해 주성분 개수를 선택한다.
- 선형판별분석(LDA)으로 차원을 축소한다. LDA는 지도학습으로 데이터의 분포를 학습하여 결정경계(Decision Boundary)를 만들어 데이터를 분류한다.
- t-분포 확률정 임베딩(t-SNE)으로 차원을 축소한다.
- 특잇값 분해(SVD)로 차원을 축소한다. PCA와 유사한 행렬 분해 기법을 사용하지만, PCA와 달리 행과 열의 크기를 다른 어떤 행렬에도 적용할 수 있다는 이점이 있다.
(3) ⭐다중선형회귀분석의 예⭐
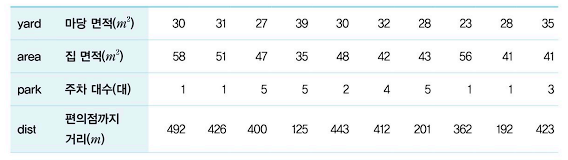
- 다음과 같이 10개의 가구에 대하여 마당 면적, 집 면적, 주차 대수, 가장 가까운 편의점까지의 거리, 집 가격 등의 데이터가 주어져 있다. 주어진 변수에 따른 집 가격의 추정식을 구해보자.


- p-value값이 0.006267이므로 유의수준 0.05에서 귀무가설을 기각한다.
- 따라서 위 추정식은 통계적으로 유의하다고 볼 수 있다.
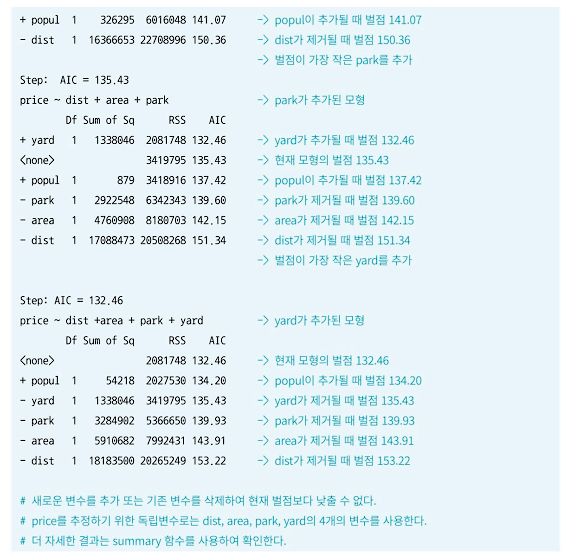
- 각 독립변수에 대한 p-value 값을 유의수준 0.05 이내에서 비교해보면, yard를 제외한 나머지 변수는 통계적으로 유의하다.
- 이 경우 yard를 제외한 나머지 3개를 독립변수로 회귀분석을 재수행할 것을 권장한다.
- 유의미하지 않은 변수 yard를 제외하지 않는다면, 추정되는 회귀식은 다음과 같다.

- 유의미하지 않은 변수 yard를 제외한다면 회귀분석 수행 후 위 회귀식에서 yard를 제외한 회귀식을 도출하면 된다.

4) 최적 회귀방정식
(1) 최적 회귀방정식
1. 최적 회귀방성식의 개념
- 1개의 반응변수 y를 설명하기 위한 k개의 독립변수 후보들이 있을 때 반응변수 y를 가장 잘 설명할 수 있는 회귀실을 찾는 것이 최적 회귀방정식의 목표다.
- 조금 더 쉽게 설명하면, 종속변수에 유의미한 영향을 미칠 것으로 생각되는 독립변수를 선택하는 과정이다. 보통 모델의 성능을 향상시키기 위해 사용한다.
- 정보는 많으면 많을수록 좋지만 모든 변수를 포함하여 분석하는 것이 반드시 좋은 결과를 보장하는 것은 아니다. 변수의 수가 많을 경우 일부 변수는 종속변수와 전혀 관련이 없을 수도 있고, 어떤 변수는 중복된 정보를 포함하고 있을 수 있다. 이러한 변수의 특성을 고려해 선택하는 것은 데이터 모델링에서 중요한 과정이다.
- 앞서 공부한 결정계수(R^2) 혹은 수정된 결정계수(adjusted R^2)도 사실 변수 선택에 활용할 수 있다. 여기서는 결정계수를 활용한 변수선택법 외에 다른 방법을 알아보기로 한다.
- ⭐최적의 회귀방정식을 도출하기 위한 방법⭐
- 변수선택법은 크게 부분집합법과 단계적 변수선택법으로 나눌 수 있다.
- 부분집합법은 모든 가능한 모델을 고려하여 가장 좋은 모델을 선정하는 방법이다. 변수가 많아짐에 따라 검증해야 하는 회귀 분석도 많아지는 단점이 있다. 변수의 개수가 적은 경우 높은 설명력을 가진 결과를 도출해내는 데 효과적이다. '임베디드 기법'이라고도 하며 라쏘, 릿지, 엘라스틱넷 등의 다양한 방법을 사용한다.
- 단계적 변수선택법은 말 그대로 일정한 단계를 거치면서 변수를 추가하거나 혹은 제거하는 방식으로 최적의 회귀방정식을 도출하는 방식이다. 전진선택법, 후진제거법, 단계선택법 등이 있다. 일반적으로 많이 사용되며, 이 책에서도 이를 중심으로 설명하기로 한다.

(2) ⭐변수 선택에 사용되는 성능지표⭐
1. 벌점화(penalty:페널티)방식의 AIC와 BIC
- 회귀 모형은 변수의 수가 증가할수록 편향(bias)은 작아지고 분산(variance)은 커지려는 경향이 있다.
- 그래서 변수의 수가 많아 복잡해진 모형에 벌점, 즉 일종의 패널티를 주어 최적 회귀방정식을 도출(회귀 모형의 설명력을 높이고자)하는 방법이다.
- 결과적으로 패널티가 적은 회귀모형이 좋은(설명력이 높은=최적화된 회귀방정식) 회귀모형이라고 할 수 있다. AIC와 BIC의 두 벌점 모두 편향과 분산이 최적이 되는 균형점을 제안해준다.
- AIC(Akaike Information Criterail: 아카이케 정보 기준)
- 모델의 성능지표로서 MSE에 변수 수만큼 페널티는 주는 지표다.
- 일반적으로 회귀분석에서 Model Selcetion할 때 많이 쓰이는 지표다.

- BIC(Bayes Information Criteria: 베이즈 정보 기준)
- AIC의 단점인, 표본(n)이 커질 때 부정확하다는 단점을 보완한 지표가 BIC이다.
- BIC는 AIC와 큰 차이는 없지만 표본이 커질 경우 좀 더 정확한 결과가 나타난다.
- BIC의 경우 변수의 개수가 많을수록 AIC보다 더 큰 페널티를 주기 때문에 변수의 개수가 적은 모형이 우선이라면 BIC를 참고하는 것이 권장된다.
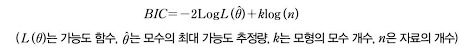
- 멜로우 Cp(Mallow's Cp)
- 멜로우가 제안한 통계량으로 Cp값은 최조자승법으로 사용하여 추정된 회귀모형의 적합성을 평가하는 데 사용된다.
- Cp값은 수정된 결정계수(R^2)및 AIC와 밀접한 관련이 있다.
- Cp값은 모든 변수가 다 포함될 경우에 p값과 같아진다. 따라서 나쁜 모델은 Cp값이 p값보다 클 때 이며 좋은 모델은 최소한 p값보다 작을 때다.
(2) ⭐단계적 변수 선택법⭐
1. 전진선택법(forward selection)
- 모든 독립변수 가운데 기준 통계치에 가장 많은 영향을 줄 것으로 판단되는 변수부터 하나씩 추가하면서 모형을 선택한다. 설명력이 가장 높은 설명변수(p-value가 가장 작은 변수)부터 시작해 하나씩 모형에 추가한다.
- 변수의 개수가 많을 때 사용할 수 있지만 변숫값이 조금만 변해도 결과에 큰 영향을 미치기 때문에 안정성이 부족한 방법이다.
- 상관계수의 절댓값이 가장 큰 변수에 대해 부분 F검정으로 유의성 검정을 하고 더는 유의하지 않은 경우 해당 변수부터는 더이상 변수를 추가하지 않는다.
- 후진제거법(backward elimination)
- 독립변수를 모두 포함하여 가장 적은 영향을 주는 변수부터 하나씩 제거하는 방법이다.
- 전진 선택법과 반대로 상관계수의 절댓값이 가장 작은 변수에 대해 부분 F검정을 실시한다. 검정 결과가 가정 적은 영향을 주는 변수(p-value가 큰 변수)부터 하나씩 제거한다.
- 전체 변수의 정보를 이용한다는 장점이 있지만 변수의 개수가 너무 많은 경우 적용하기 어렵다.
- 단계별 방법(stepwise method)
- 전진선택법과 후진제거법을 보완한 방법이다.
- 전진선택법에 의해 변수를 추가하면서 추가될 때 예상되는 벌점 값과 이미 추가된 변수가 제거될 때 예상되는 벌점 값이 가장 작도록 만들어 나가는 방법이다.
(3) ⭐최적 회귀방정식 실습⭐
- 다음의 집값 관련 데이터로 최적 회귀방정식 도출 실습을 해보자.







5) 고급 회귀분석

(1) 정규화 선형회귀
1. 과적합과 과소적합
- 과적합(overfitting) 또는 과대적합이란 모델이 학습 데이터를 과하게 학습하는 것을 의미한다.
- 일반적으로 학습 데이터에 과적합되면 일반화 성능이 낮아져 이미 학습한 훈련용 데이터에 대한 성능은 높게 나오지만, 아직 학습하지 않은 데스트 데이터에 대한 성능은 낮게 나온다.
- 그 이유는 모델이 학습 데이터에 너무 과하게 맞춰져서 새로운 데이터에 일반화하기가 어렵기 때문이다. 반대로 모델이 너무 단순해서 학습 데이터조차 제대로 예측하지 못하는 경우를 과소적합(underfitting)이라고 한다.
- 정규화 선형회귀
- 회귀번에서 과적합되면 계수의 크기도 과도하게 증가하는 경향이 있다. 따라서 이를 방지하기 위해 계수의 크기를 제한하는 방법을 사용하는데, 이것을 정규화 선형회귀라 부른다.
- 정규화 선형회귀에는 제약 조건의 종류에 따라 릿지(Ridge), 라쏘(Lasso), 엘라스틱넷(Elastic Net)회귀모형이 사용된다.
- ⭐정규화 선형회귀의 종류⭐
✔ 라쏘(Lasso Regression)
- L1 규제라고도 하며, 가중치들의 절댓값의 합을 최소화하는 것을 제약조건으로 추가하는 방법이다.
- 라쏘 회귀에선 일정한 상숫값이 패널티로 부여되어 일부 불필요한 가중치 파라미터를 0으로 만들어 분석에서 아예 제외시킨다. 몇 개의 의미 있는 변수만 분석에 포함시키고 싶을 때 효과적인 방법이다.
✔ 릿지(Rigde Regression)
- L2규제라고도 하며, 가중치들의 제곱합을 최소화하는 것을 제약조건으로 추가하는 방법이다.
- 일부 가중치 파라미터를 제한하지만, 완전히 0으로 만들지는 않고 0에 가깝게 만든다.
- 릿지 회귀는 매우 크거나 작은 이상치의 가중치를 0에 가깝게 유도함으로써 선형 모델의 일반화 성능을 개선하는 데 사용할 수 있다.
✔ 엘라스틱넷(Elastic net)
- 라쏘와 릿지를 결합한 모델이다.
- 가중치의 절댓값의 합과 제곱합을 동시에 제약조건으로 가지는 모형이다.
(2) 일반화 선형회기(GLM, Generalized Linear Regression)
1. 일반화 선형회귀의 개념
- 회귀분석은 종속변수가 정규분포를 따른다는 정규성을 전제로 한다. 앞서 '회귀분석의 가정'에서 언급한 바 있다. 하지만 종속변수가 범주형 자료이거나 정규성을 만족하지 못하는 경우가 있다.
- 이렇게 회기분석을 하고 싶지만 종속변수가 범주형 자료이거나 정규성을 만족하지 못 하는 경우 그 종속변수를 적절한 함수 f(x)로 정의한 다음, 이 함수 f(x)와 독립변수를 선형 결합하여 회귀분석을 수행할 수 있는데 이를 일반화 선형회귀라 한다.
- 일반화 선형회귀의 구성요소
- 확률 요소(Random Component): 종속변수의 확률분포를 규정하는 성분
- 선형 예측자(Linear Predictor, 혹은 체계적 성분): 종속변수의 기댓값을 정의하는 독립변수들 간의 선형 결합
- 연결 함수(Link function): 확률 요소와 선형예측자를 연결하는 함수
- ⭐일반화 선형회귀의 종류⭐
✔ 로지스틱 회귀(Logistic Regression)
- 로지스틱 회귀는 종속변수가 범주형 변수(0 또는 1, 합격/불합격, 사망/생존 등)인 경우로 의학연구에 많이 사용된다.
- 로지스틱 회귀 분석(Logistic Regreesion Analysis)은 종속 변수와 독립 변수 간의 관계를 나타내어 예측 모델을 생성한다는 점에서는 선형 회귀 분석 방법과 동일하다. 하지만 독립 변수(x)에 의해 종속 변수(y)의 범주로 분류한다는 측면은 '분류 분석'방법으로 분류한다.
- 자세한 것은 데이터 마이닝 분류 분석 편에서 다루기로 한다.
✔포아송 회귀(Poisson Regression)
- 종속변수가 특정 시간 동안 발생한 사건의 건수에 대한 도수 자료(count data, 음수가 아닌 정수)인 경우이면서, 종속변수가 정규분포를 따르지 않거나 등분산성을 만족하지 못하는 경우에 포아송 회귀분석이 사용된다.
- 선형회귀모형이 최소제곱법으로 모수를 추정한다면 포아송 회귀모형은 최대 가능도 추정(MLE, Maximum Likelihood Estimation)을 통해 모수를 측정한다.
(3) 더빈 왓슨(Durbin-Watson)검정
1. 오차항의 상관관계
- 먼저 오차항이 서로 상관관계를 갖는 경우를 생각해보자. 오차항이 상관관계를 갖는 경우는 대부분의 경우 시계열 데이터의 경우다.
- 시계열 분석은 다음에 공부할 것이므로 간단히 살펴보면, 시계열 데이터는 시간의 흐름대로 나열된 데이터를 말한다. 시계열 데이터들은 연속적인 일련의 관측치들이 서로 상관되어 있다. 즉, 하나의 잔차항의 크기가 이웃하는 다른 잔차항의 크긱와 서로 일정한 관련이 있다. 이를 자기상관성이라한다.
- 더빈 왓슨 검정
- 회귀분석에 있어서는 오차항이 서로 연관성이 없어야 한다. 이 말은 회귀분석에서의 오차항의 공분산은 '0'이라는 것이다. 만약 자기 상관성이 있따면 회귀분석이 아니라 시계열 분석이나 다른 분석방법을 수행해야 한다.
- 회귀분석에 있어 이러한 자기상관성이 존재하는지(오차항이 독립성을 만족하는지=오차항이 서로 연관성이 없는지) 검정하는 방법이 바로 '더빈 왓슨 검정'이다.
- '더빈 왓슨 검정' 통계량 값이 2에 가까울수록 오차항의 자기상관이 없다는 의미다. 만약 0에 가깝다면 양의 상관관계가, 4에 가깝다면 음의상관관계가 있다고 판단한다.


뭐든 열심히