(*이 시리즈의 내용은 모두 '인공지능 100점을 위한 파이썬 수학' 서적의 내용을 정리한 것입니다. 사진과 같은 자료들 또한 출처가 위 책임을 밝힙니다.)
1. MNIST Dataset 구성
- 손으로 쓴 0부터 9까지의 글자들을 모아둔 것.
- 이 데이터를 사용해서 학습한 후, 얼마나 정확하게 손글씨를 인식할 수 있는지 검증한다.
- 훈련용 데이터 60,000개, 검증용 데이터 10,000개가 있고, 모든 데이터는 가로x세로 28x28 픽셀 크기이다.
# MNIST Dataset 구성
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()keras 패키지의 datasets 클래스에서 mnist 데이터를 포함한 모듈(mnist.py)을 가져온다.
- 이 모듈에는 load.data() 함수가 있는데, 이 함수를 사용하여 학습용 데이터 6만 개와 검증용 데이터 1만 개를 가져온다.
- x_train은 6만 개의 학습용 데이터, y_train은 6만 개 학습용 데이터의 실제 값.
- x_train은 28x28 크기의 행렬이고, y_train은 같은 인덱스를 가지는 x_train의 실제 값인 0에서 9 사이의 정수이다.
(1) x_train의 첫 번째 데이터인 28x28 행렬에 담겨 있는 값을 신경망 프로그램에 통과
(2) 그때 신경망 프로그램의 최종 결괏값, 즉 정답이 y_train의 첫 번째 데이터에 담겨 있고, 그 값은 0~9 사이의 정수이다. 이때 신경망 프로그램에서 판단에 사용되는 일정한 스위치들을 조금씩 조작하고 신경망 프로그램의 최종 결과가 정답에 가깝게 되도록 여려 변수들을 조정한다.
(3) x_train의 두 번째 데이터를 가지고 위의 과정을 반복한다.
(4) x_train의 마지막 데이터, 6만 번째 데이터까지 위 과정을 반복한다.
(5) 위의 과정 반복.
(6) 신경망 프로그램의 여러 변수들이 바뀌면서 학습용 데이터를 넣었을 때 정답이 잘 나오면 훈련을 종료.
(7) 조정된 신경망 프로그램에 검증용 데이터를 입력한다.
(8) x_test 결과값이 y_test 값과 얼마나 같은지 확인.
2. MNIST 화면 출력
# MNIST 화면 출력1
print(type(x_train), x_train.shape)결과는 <class 'numpy.ndarray'>(60000, 28, 28)이다.
- 60000x28x28 크기를 가지는 3차원 배열이 x_train이다.
- 첫 번째 60000은 손글씨 그림 파일의 수이고, 두 번째 28은 열의 수, 세 번째 29은 행의 수가 된다.
첫 번째 데이터인 x_train[0]을 가지고 다시 확인하면,
print(type(x_train[0]), x_train[0].shape)[실행 결과]
<class 'numpy.ndarray'> (28, 28)이제 x_train[0]의 28x28 즉, 784개의 데이터를 살펴보면,

colab으로 직접 출력했을 때 짤린다...
이 데이터를 가지고 직접 그림으로 출력해보면,
# MNIST 화면 출력
import matplotlib.pyplot as plt
image = x_train[0]
plt.imshow(image, cmap='Greys')
plt.show()출력 결과는
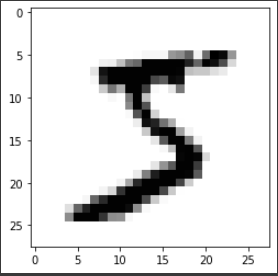
숫자 5를 확인할 수 있다.
