
컨테이너에 문제가 생겼을 때 알 수 있는 방법
파드의 Life cycle
파드는 pending단계에서 시작해서 running단계를 통과하여 파드에 문제가 발생할 경우 Failed로 바뀌며 다양한 상태를 거치게 된다.
파드는 파드의 수명중 한 번만 스케줄된다. 파드가 스케줄되면 파드는 중지되거나 종료될 때까지 해당 노드에서 실행된다.
그렇다면 파드의 상태를 알 수 있는 방법들은 어떤 것이 있을까??
컨테이너 프로브(probe)
livenessProbe
컨테이너가 동작 중인지 여부를 나타낸다. 만약 컨테이너가 running상태가 아니라면 kubelet은 컨테이너를 죽이고, 해당 컨테이너는 재시작 정책의 대상이 된다.
readinessProbe
컨테이너가 요청을 처리할 준비가 되었는지 여부를 나타낸다. 만약 실패한다면 Endpoint controller는 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 ip주소를 제거한다.
startupProbe
컨테이너 내의 애플리케이션이 시작되었는지를 나타낸다. startupProbe가 주어진 경우, 성공할 때까지 다른 나머지 프로브는 활성화되지 않는다. 만약 스타트업 프로브가 실패하면 kubelet이 컨테이너를 죽이고 재시작 정책에 따라 처리된다.
프로브는 컨테이너에서 kubelet에 의해 주기적으로 수행되는 진단이다.
다음은 진단 방법들인 체크 메커니즘이다.
체크 메커니즘
각 프로브는 다음의 4가지 메커니즘 중 단 하나만을 정의해야 한다.
exec
이 명령어는 도커에서도 사용된다. docker run exec -it 를 하게되면 해당 컨테이너에 접속하여 다양한 명령어들을 수행 할 수 있다.
이와 마찬가지로 쿠버네티스에서도 exec를 사용하여 컨테이너 내에서 지정된 명령어를 실행한다. 명령어 상태코드 0으로 종료되면 진단이 성공한 것으로 간주한다.
grpc
grpc를 사용하여 원격 프로시저 호출을 수행한다. 체크 대상이 gRPC 헬스 체크를 구현해야 한다.
응답의 status 가 SERVING 이면 진단이 성공했다고 간주한다
httpGet
지정한 포트와 경로에서 컨테이너의 ip주소에 대한 HTTP GET요청을 수행한다. 200이상 400미만이면 진단이 성공한 것으로 간주한다.
livenessProbe or readinessProbe
httpGet:
port: 8080
path: /
periodSeconds: 1과 같이 사용하게 된다.
tcpSocket
지정된 포트에서 컨테이너의 ip주소에 개해 TCP검사를 수행한다. 포트가 활성화 되어 있다면 진단이 성공한 것으로 간주함
만약 애플리케이션에 HTTP 500과 같은 에러가 발생한 경우
HTTP 에러가 발생했다는 것을 어떻게 알 수 있을까?
컨테이너의 문제가 생기면 kubectl get pods명령어로 상태를 확인 할 수 있다. 하지만 그 컨테이너 안의 코드나 애플리케이션 에러가 발생한다면 확인하기가 쉽지 않다. 또 수많은 컨테이너들의 헬스체크를 하나하나 할 수 없기 때문에 자동으로 재시작 되거나 중지 시켜야 할 것 이다.
문제가 생겼을 때 컨테이너를 재시작 정책에 추가하는 프로브는 livenessProbe이다. livenessProbe와 httpGet 체크를 사용하게 되면 http GET 요청이 실패하게 된다면 livenessProbe에 의해 해당 파드는 재시작 정책에 들어가게 될 것이다.
그 예시로
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
labels:
app: backend
spec:
minReadySeconds: 10
strategy:
type: RollingUpdate
selector:
matchLabels:
app: backend
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
image: dnflekf2748/backend:1.0
ports:
- containerPort: 80
livenessProbe:
httpGet:
port: 8080
path: /
periodSeconds: 1와 같은 코드를 보면 나의 도커허브에 있는 dnflekf27748/backend:1.0 이미지를 이용해 백앤드를 구축하는데 마지막 부분을 보면 httpGet 을 추가하여 http상태를 체크하게 된다. periodSeconds는 해당 초 마다 검사를 진행하게 된다.
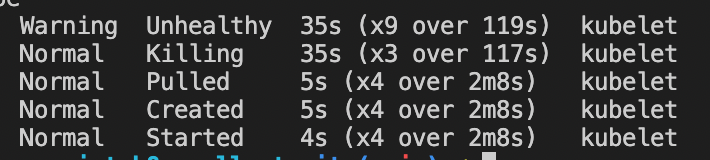
만약 unhealty 상태가 된다면 해당 파드는 죽고 다시 시작하게 된다.
