Pooling and batch normalization
EX1) 1 X 1 Convolution
이전에는 지역적 특성(locality)를 보기 위해 주변 3개의 pixel, 5개의 pixel 이렇게 살펴보았다.
1 X 1 Conv는 한 pixel만 본다는 뜻으로 주변의 locality를 고려하지 않는다.
가중치를 보고 학습을 진행하면서 주로 feature의 size를 줄여준다.
★ image의 channel을 줄여준다. (가로, 세로의 size는 유지)

도형의 제일 아래에 있는 64, 32는 Depth이다.
- 왼쪽의 64 depth를 가진 도형에 1X1 conv를 적용시킨다.
- depth=1이 된다.
- 32 filter를 적용시켜 output channel의 크기가 32가 된다.
앞서 보았던 개념처럼 가로 세로의 size는 유지하면서 channel을 줄여준다.
<다른개념>
Stride: 몇 칸씩 이동? → 가로 세로를 줄여서 output의 size가 작아진다.
Pooliing Layers: Another way to downsample
downsample: image size ↓
- ex) stride: 2칸씩 이동 -> 1/2
- 여기서 다루는 여러가지 Pooling
[Max Pooling]
제일 큰 값을 추출하는 Pooling 기법
Max 이외에도 average, medium 등이 존재한다.
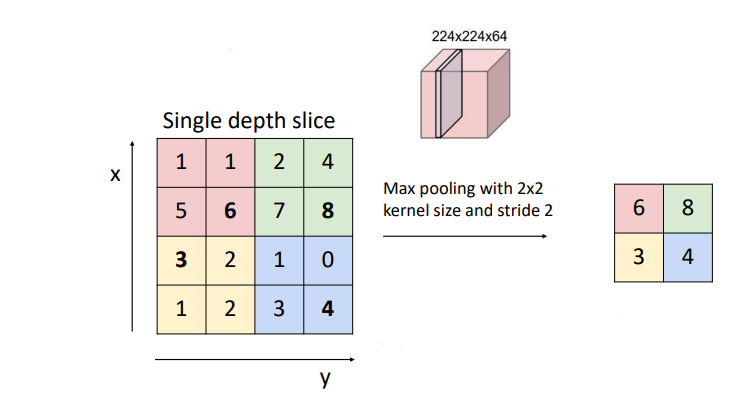
- Max pooling을 2X2로 진행
- 그 중 가장 큰 수 추출
- 2칸 이동(stride 2)
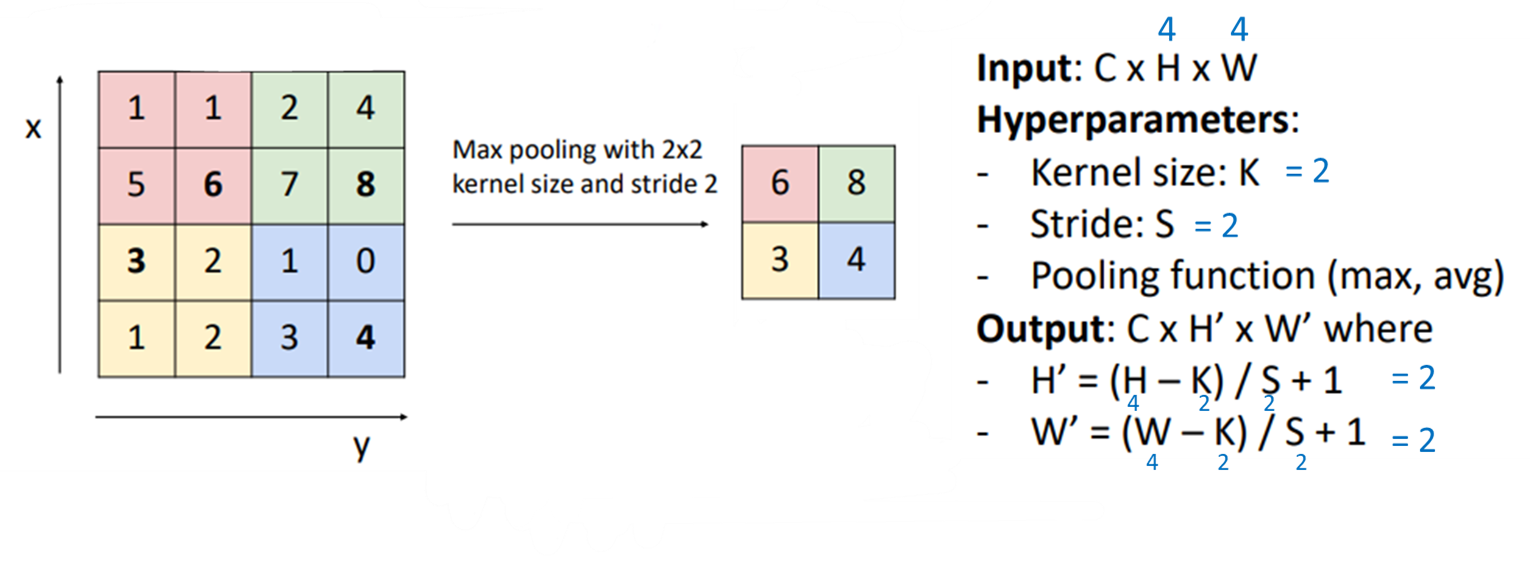
(4 X 4) → (2 X 2) 가로, 세로별 1/2씩 줄었다.
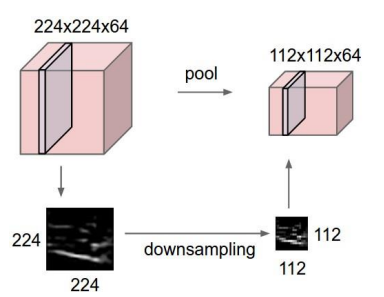
이 그림에서도 224 → 112 (1/2배)
★ Channel은 그대로 유지 (바뀌는건 1X1 Conv임)강력한 값을 살리고 의미없는 값을 거르기 때문에 이미지의 모양이 유지된다.
.
아래의 두가지는 용도에 맞게 사용하는 것이 좋다.
[Stride 2] - Learnable Parameter
- 학습이 된 parameter를 계속해서 바꾸고 바꾼다.
→ 값이 계속 바뀌니 값의 보존이 힘들다.image의 size를 줄이면서 다른 Feature를 뽑는 것이다.
[Maxpooling] - Learnable Parameter None!
- 단순하게 max를 뽑는 것으로 Learnable Parameter None!
- 학습을 안 하고 큰 값을 넣어준다.
→ 큰 값이 살아남음 = 이미지 값이 보존되었다.iamge의 size만 줄이는 효과
식을 통해 (4X4) → (2X2)가 되는 과정을 살펴봅니다.
[Convolutional Networks]
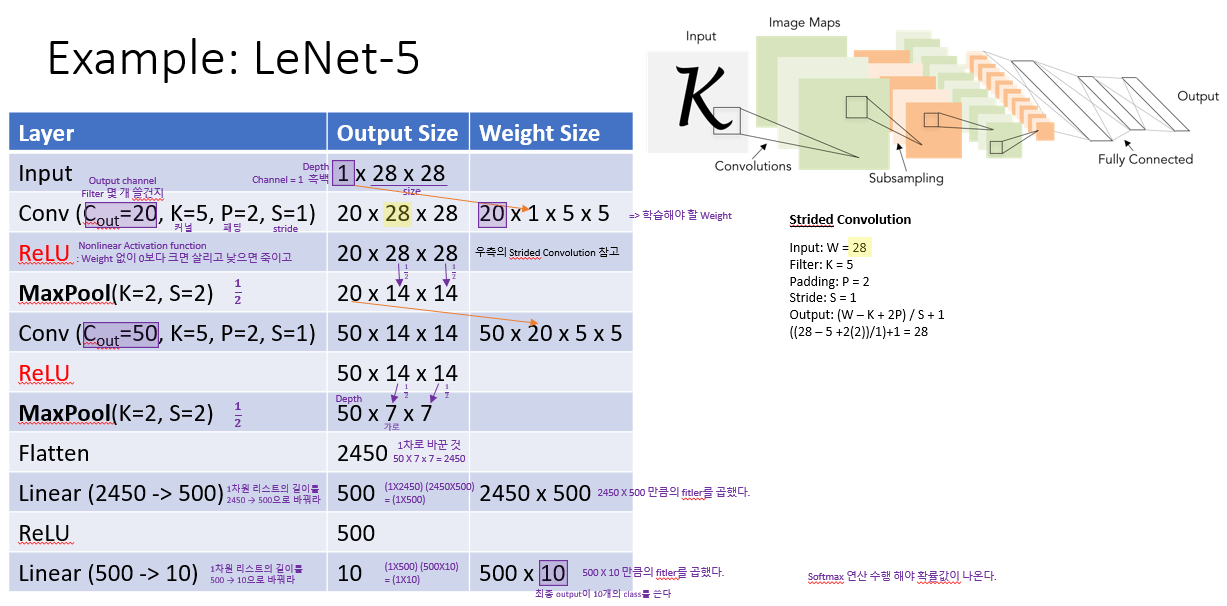
Problem: Deep Networks very hard to train! (학습 할 Data도 많고,,,)
→ Normalization 필요하다.
.
[Batch Normalization]
zero mean and unit variance: 0~1 사이의 값이 나오도록 규제를 준다.
internal convariate shift
값이 너무 출렁거릴 수 있다. = 딥러닝 학습이 어렵다. = 샘플에 민감하다.
→ 정규화 하면 성능↓
→ 정규화에 감마, 베타 적용하면 (성능↑, 안정적)
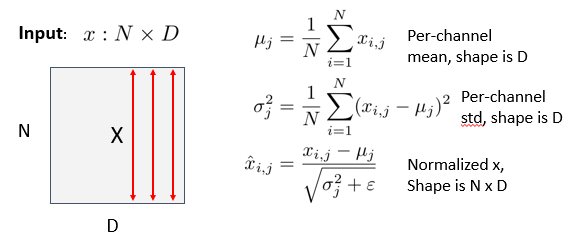
N: 행(데이터 개수)
D: 열(채널의 개수) = 차원
x1 [ 0 1 2 3 4 5 6 ... D개]
x2 [ 0 1 2 3 4 5 6 ... D개]
x3 [ 0 1 2 3 4 5 6 ... D개]
x4 [ 0 1 2 3 4 5 6 ... D개]
.
n개
채널별 평균값(μj): x1[0] + x2[0] + x3[0] + x4[0] +...+ xn[0] / n
ε 는 분모의 0을 방지하기 위한 상수이다.
위의 zero-mean, unit variance는 너무 강한 규제가 존재한다.
따라서 Learnable scale and shift parameter를 추가한다. -> 성능이 좋아진다.
γ(감마) β(베타) 추가. 둘 다 D차원이다.
- γ -> σ 학습변수
- β -> μ 학습변수

만약 γ=1, β=0이면 그냥 정규화랑 같아진다.
채널만 보고 H, W는 모두 1로 본다.
[Layer Normalization]
[Instance Normalization]
