[Overfitting]
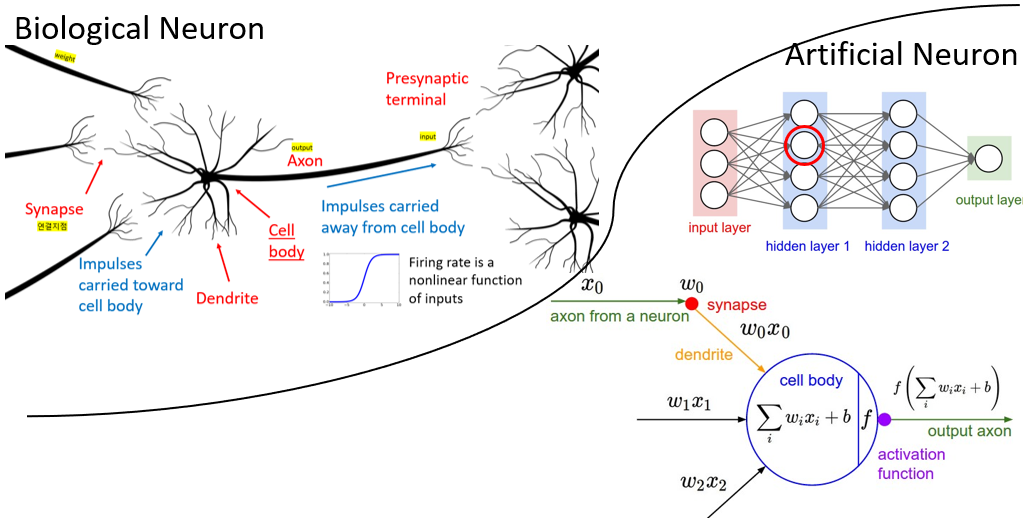
앞의 게시물에서 hidden layer의 크기가 너무 커서 말의 머리가 두개인 문제가 발생했다.
- hidden layer의 크기가 크다 = model이 크다.
관련된 예제그림을 살펴본다.
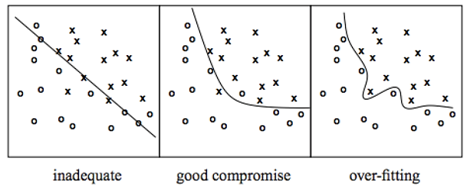
3) over-fitting: loss가 엄청 적기 때문에 train data(알고 있는)에 대해서는 정확하다.
그러나 실제의 data에 대해서는 불안정하다.
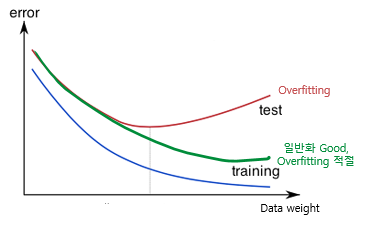
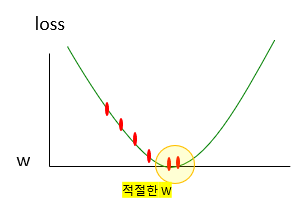
regularization(정규화)의 목적
- avoid overfitting
- minimize traning error
정규화의 강도는 𝜆로 설정한다.
[Regularizers]
f = Wx
W 값의 range가 크지 않음을 선호.
W1 = 100x1
W2 = 1x2
- Weight의 범위가 클 수록 noise↑ / data의 의존도 ↑
[Regularization: Beyond Training Error]
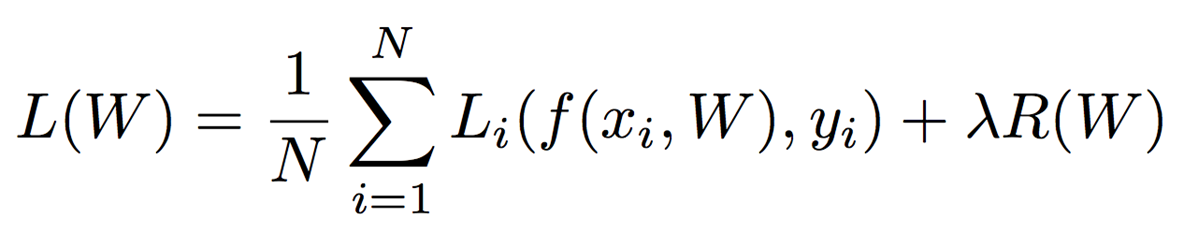
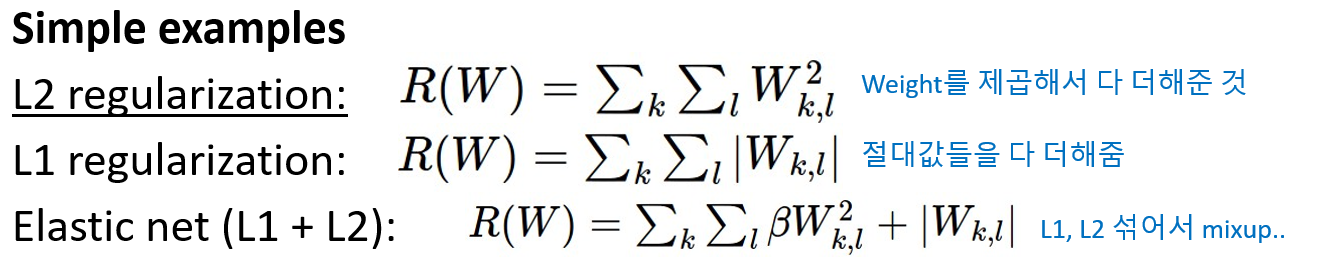
- [L2 예제] (크게 보면 ∑^2이므로 L2이다.)
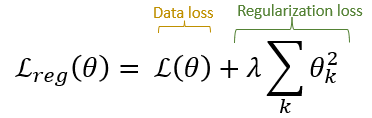
- [L1 예제] ( ∑ | 절대값 | )
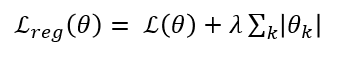
- [Elastic net (L1+L2)] (L1, L2 섞어서)
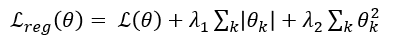
[Effect of the decay coefficient 𝜆]
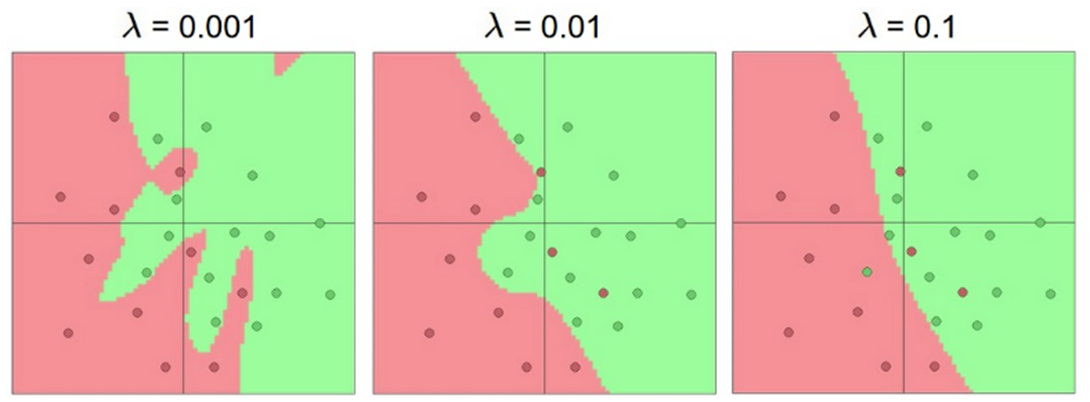
overfitting을 피하려면 𝜆를 높여야한다.
𝜆가 0.1인 그림은 거의 linear 모델 수준으로 단순하다.
그러나 test엔 이런 linear model형태가 훨씬 좋다.
[Model-based machine learning]
-
모델을 선택한다.
-
최적화할 기준을 정한다.(objective function)
-
학습 알고리즘 개발 (find W and b that minimize)
Our optimization criterion
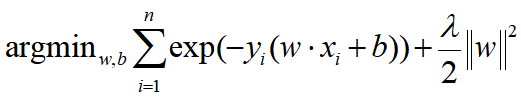
- -yi: loss function: 예측된 결과값이 틀린 곳에 패널티 부여
- ||W||: 큰 가중치에 패널티 부여
-> 이 함수는 볼록한 형태로 경사하강법(gradient descent)를 사용할 수 있다.
추후에 objective를 미분하면 아래의 수식으로 바뀌게 된다.
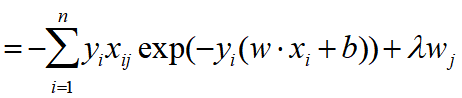
[Gradient descent]
- pick a starting point (w) ←랜덤으로 결정
- 차원이 손실되지 않을 때 까지 차원의 감소를 진행한다.
- 차원 선택
- 차원 손실의 반대 방향으로 이동
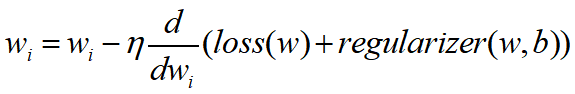
- 반대 방향으로 이동해야 하기 때문에 -h이다.
- loss(w), regularizer(w,b) 두 가지의 미분을 다 고려해야 한다.
.
결국!
최종적으로 보는 부분

[빨간 박스]
wj가 양수이면 결국 저만큼 빼준다는 의미 = graph( ↙ )
wj가 음수이면(작은 값이면) 저만큼 더해준다. graph( ↗ )
j의 절대값의 크기가 작아지면서 (= 0에 가까워지면서)
범위 자체의 크기는 같으니 절대값으로 비교한다.
= data에 민감하고 싶지 않은 것.
[결론]
[L1 regularization]
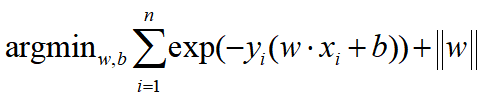
||w|| : 모든 element의 절대값을 씌우고 더한 것
절대값은 미분이 안 되니 +, - 로 나누어서 미분해준다.
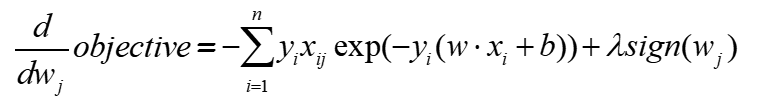
sign: 0보다 크면 기울기 = 1
sign: 0보다 작으면 기울기 = -1

[빨간 박스]
양수이면 sign = 1 → weight를 1만큼 빼준다
음수이면 sign = -1 -> weight를 1만큼 더해준다.
앞에 -가 있기 때문에 반대의 연산이 일어나는 것이다.
L1, L2 모두 절대값을 줄인다.
- [L1]
: 무조건 +1 혹은 -1으로 계속 가기에 시간이 흘러도 같은 크기로 간다.
weight 자체를 0으로 만드는 경우가 많다. (우리는 이것을 선호한다)
= sparse cording = 0이 많다.
- [L2]
: 본인의 크기만큼 조절 (본인을 곱해서 이동)
대부분의 값들을 빠르게 0에 가까운 수로 만들어준다.
L1보다 느릴 수 있지만 자신의 몸집만큼 이동한다.
그러나 자신의 몸집이 0에 가까워질수록 동작을 잘 하지 않는다.
0이 되려면 너무 많은 학습이 필요하기에 0으로 만들기 보다는 0에 가까운 수로 만들어준다.
아래는 Regularization의 다양한 방법에 대한 설명이다.
[Regularization: Dropout]
- overfitting을 방지하는 여러가지 방법 중 하나
- 앙상블 학습 효과로 인해 성능향상 (랜덤으로 dropout하기 때문에 경우의 수가 다양)
앙상블이란?
: 1개의 proeiction → 1개의 output 생성한 후 하나의 network가 아니라 여러 network를 골고루 활용해서 결과를 내는 기법
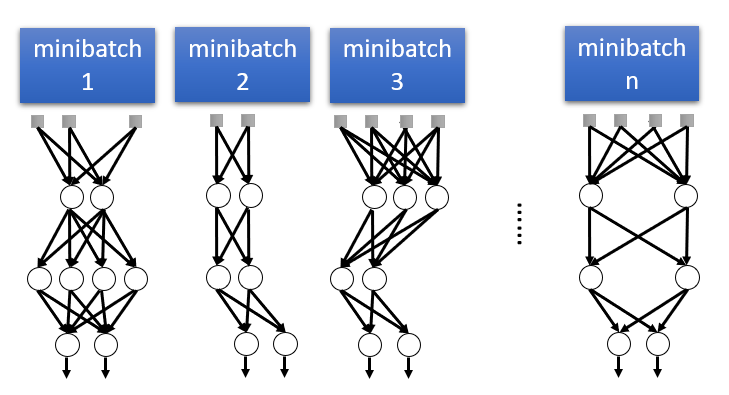
data에 민감한 상태를 해소하기 위해 중간에 나오는 output을 무작위로 0(sparse)으로 만든다.
0이 된 연산은 의미가 없어지기 때문에 gradient가 update 되지 않는다.
▶ overfitting이 덜 된다.
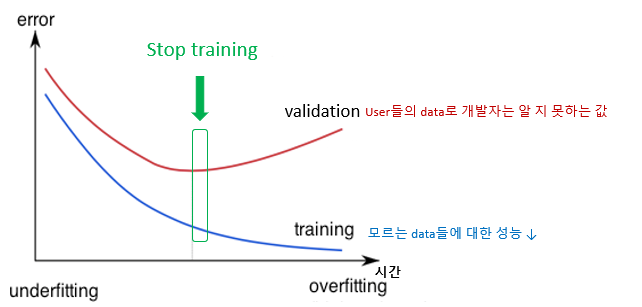
[Regularization: Early Stopping]
-
During model training, use a validation set
: 검증이 된 set를 사용하는 데 전체 중 75%의 data로만 학습하고, 25%의 데이터로 test를 진행한다. -
일정 시점(n)이후에도 validation accuracy or loss가 개선되지 않으면 stop
(n called patience)
다양한 Activation Function (ReLU를 일반적으로 가장 많이 사용)

이후에 배울 Neuron 한눈에 보기