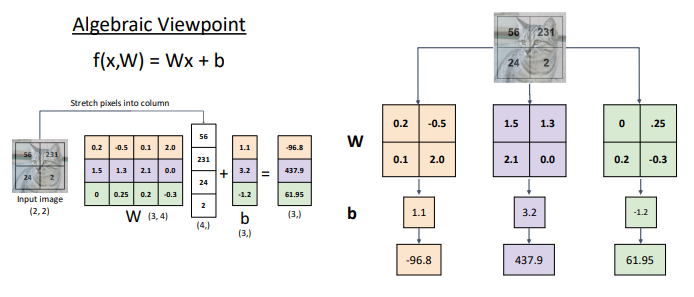
[Linear Classifiers]
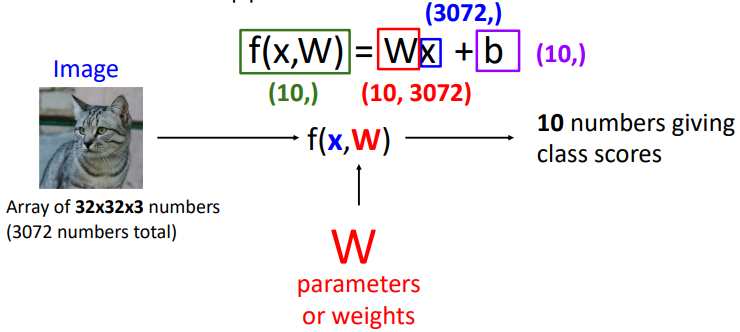
10 numbers giving class scores 이기에 f(x,W) 크기는 (10,) 이다.
- Weight x image + b(10, )
size: (10, 3072) x (3072, ) + (10, )
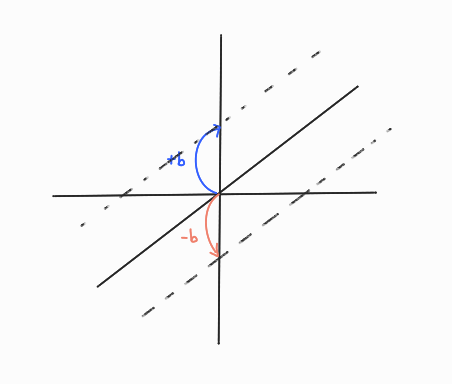
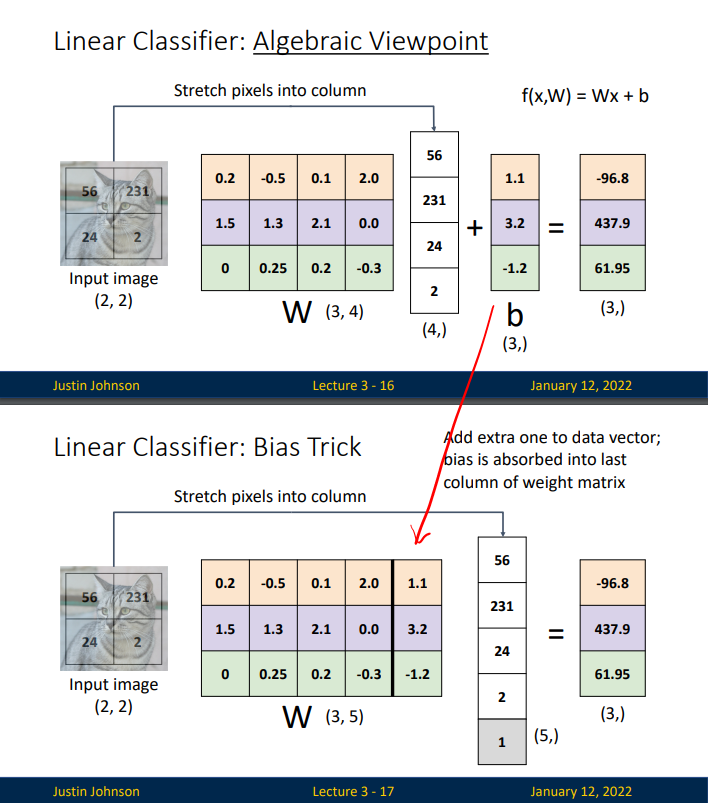
모델이 b에 의해 왔다갔다 하면서 효율적으로 처리가능하다.
b를 weight에 합쳐버리면 차원이 늘지만 유동적으로 이동 가능한 모델이 형성된다.
b에 추가된 1은 동차좌표계를 넣어준 것이다.
f(cx, W) = W(cx) = c * f(x,W)
[Interpreting a Linear Classifier]
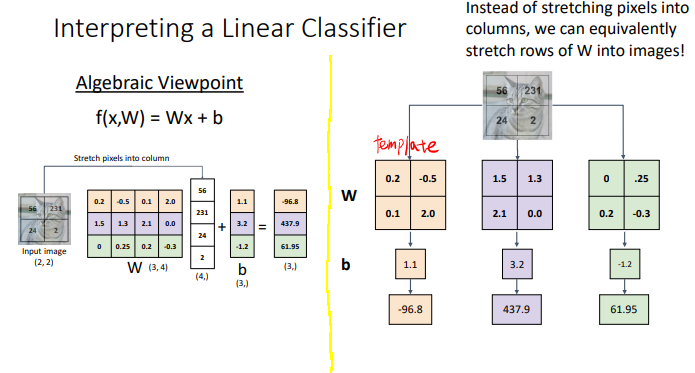
좌측: linear model
우측: template matching
- linear model = template matching
아래와 같은 수많은 template이 존재합니다.

horse는 머리가 두개인 template이 되었습니다.
사진이 많을 수록 좌, 우 확률이 반반이 되기 때문입니다.
이것이 linear model의 한계입니다.
그렇다면 좋은 Weight는 뭘까?
1) Use a loss function = loss정의
2) Find a W that minimizes the loss
function(optimization) = loss값이 가장 작아지는 W 찾기 => W 최적화
- ex) 정답과 가까울 때 loss ↓, 같으면 loss=0
- loss는 정답값과 떨어진 정도이다.
[Loss Function]
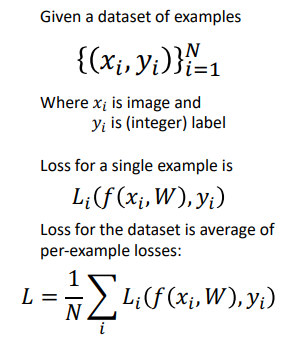
{(xi, yi)}Ni = 1 -> {(고양이img, 1)}
data fair가 들어간다. ( image, label(숫자) )
label {1-고양이, 2-강아지, 3-사자 ...}
L_i ( f (xi, W), yi) -> L_i (f (output, model), yi)
- i번째 pixel에 대한 loss값. (N개)
= 아웃풋과 model간의 차이이다. (작을수록 좋다.)
마지막 수식은 N개마다 따로 보는 것이 아니라 평균을 내는 것이다.
[Cross-Entropy Loss (Multinomal Logistic Regression]
- 파란 수치들을 확률을 활용해 해석하고싶다.

- 파란 박스의 원소에 exp를 적용해 0보다 크거나 같게 만들어준다.
- 빨간 박스는 확률이 아니다. (합이 1이 아님)
- 확률화 하기 위해 빨간 박스를 normalize 시킨다 (결과: 초록박스)
여기서 사용된 exp와 normalize를 살펴보겠다.
- exp = e^n을 계산하는 함수
(exp는 단조 증가함수로 작으면 작고, 크면 크다.)
확률을 구하기위해 softmax function을 활용
첫줄을 구해보겠다.
- e^(3.2) = 24.5
- 빨간 박스의 합 = 188.68
- P = 24.5 / 188.68 => 0.13
- Li = - log(0.13) => 2.04
image와 label이 고양이라고 가정한다.
Li의 의미는 -logP(고양이에 해당하는 확률 값 (0.13) | 고양이 )
※ -log안의 값이 1이 되면 loss가 최소화된다.
※ 주의 log의 밑은 2이다.
