f (x, W) = Wx + b
x는 이미지이기 때문에 불변한다.
따라서 최적의 W를 찾는 것이 중요하다.
[Cross-entropy Loss]
모델이 좋은 지 나쁜 지의 기준점
model이 안 좋다 -> loss가 크다.
model이 좋다. -> loss가 작다.
[Neural Networks] = Deep Learning 10page
linear model의 한계
data가 non-linear하게 섞이면 예측이 매우 어려워진다. (추측할 수 없게 된다.)
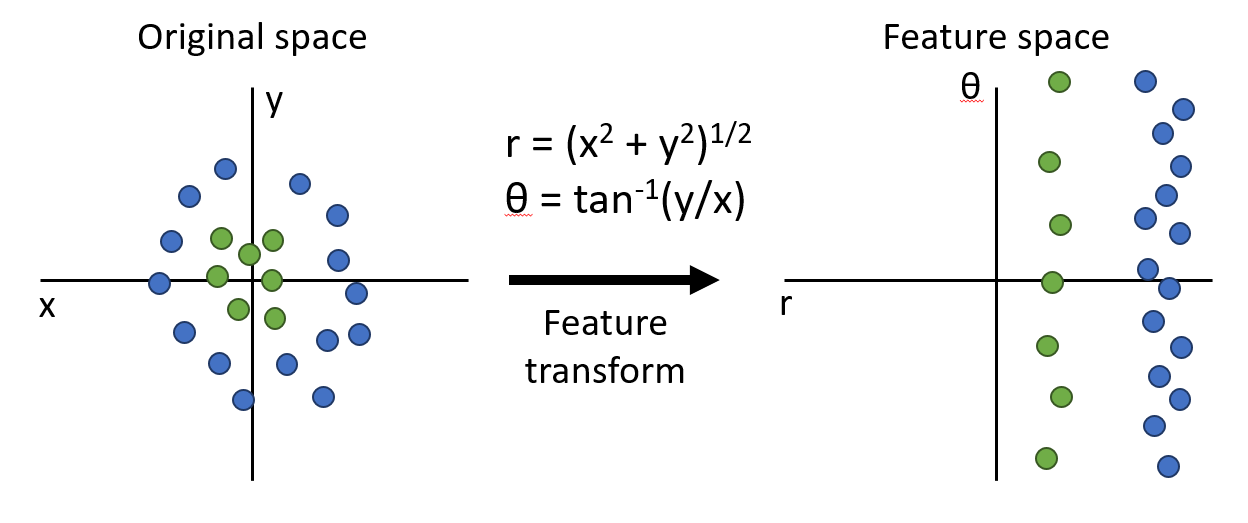
좌측의 non-linear data들은 모여있는데 각도가 다양하게 한 바퀴 도는 모습을 볼 수 있다.
따라서 x, y 축을 적절한 계산을 통해 반지름과 각도 축으로 feature space를 변경해준다.
우측의 그래프에서는 linear하게 풀 수 있게 되었다.
[Neural Networks]
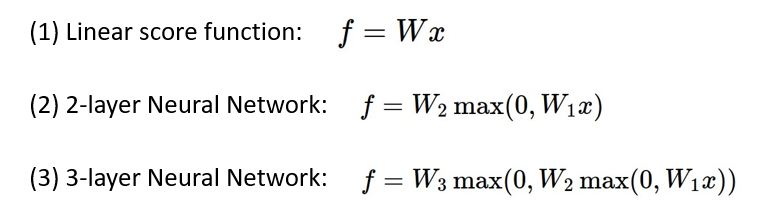
우리는 여기서 (2) 2-layer Neural Network를 자세히 살펴본다.
(called Activation Function)
Activation Function의 예
[ReLU function] *(linear -> non-linear)
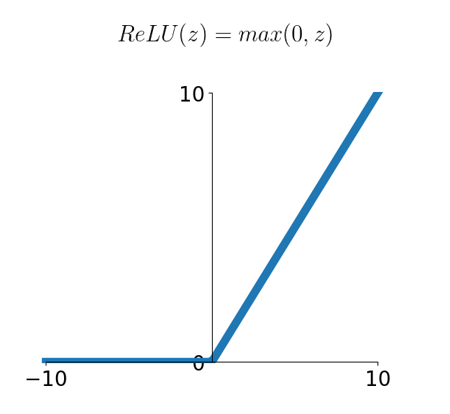
max 함수로 인해 순서성이 생깁니다.
입력값이 음수가 먼저 들어오면 0이 되고, 양수가 들어오면 값이 살아남습니다.
따라서 연산의 순서에 따라 값이 달라집니다.
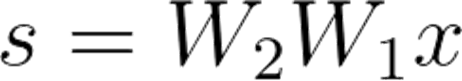
해당 식에 activation function을 적용시키지 않으면?
- [W2]*[W1]의 가중치 곱의 새로운 벡터인 [W3] 생성.
[W2][W1][x] = ([W2][W1])[x] = ([W3])[x] = [W3]x
◎ 결과: s=[W3]x
Neural Networks = 층을 여러 개 쌓는다고 생각할 것
아래의 사진 2개는 2-layer Neural Network 이다.
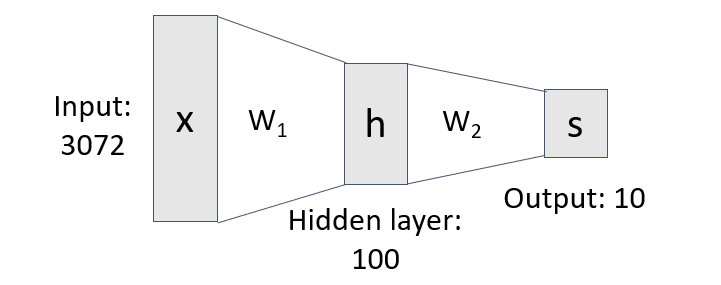
hidden layer는 100개 있다.
- x에서 3072개의 input이 들어온다.
- 가중치들의 합을 가지고 template matching을 통해 h에 matching 된다. (ex. 고양이발, 고양이귀)
- h가 더 큰 범위의 template으로 최종 matching 된다. (ex. 고양이)
- 범주별로 가중치가 나타나고, 거기서 나중에 정보를 활용하면 되는 것.
[Fully-connected neural network] (=Multi-Layer Perceptron)
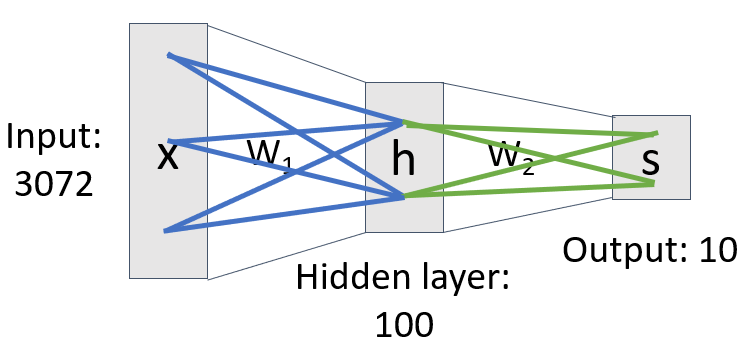
hidden layer가 클 수록 특징이 더 세분화 되기 때문에 정교하게 분류가 가능해진다.
But! 너무 크면 앞에서 보았던 말의 머리가 두 개인 문제가 발생할 수 있다.
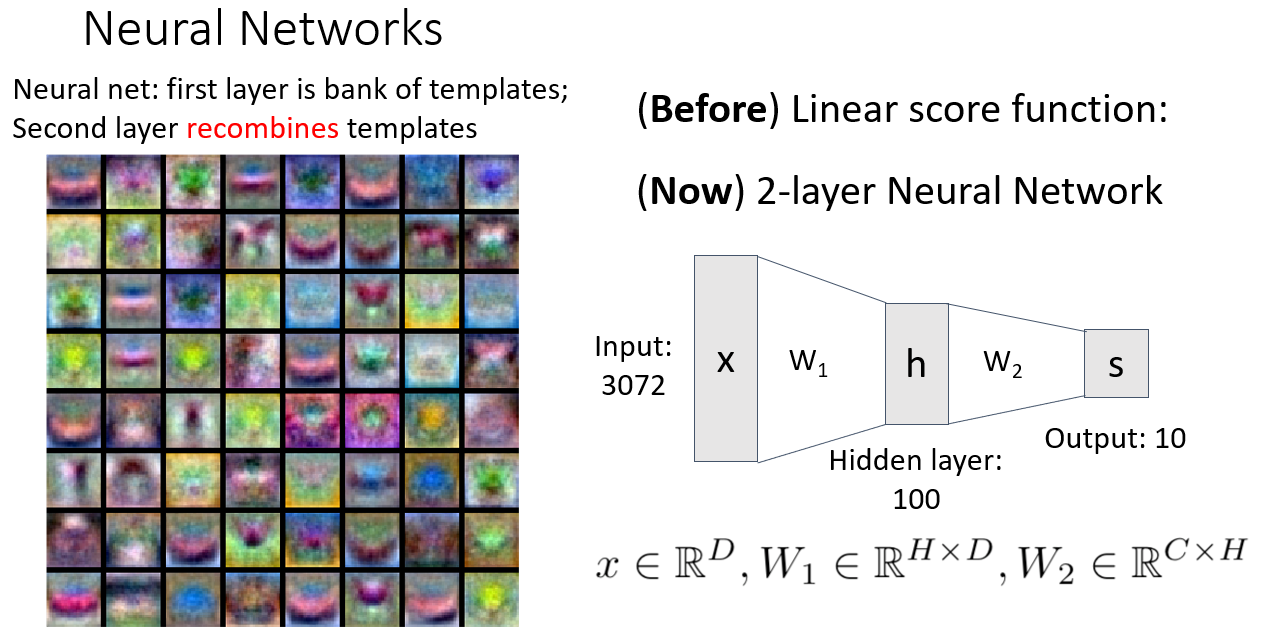
2번째 레이어에서 템플릿(또는 이전 레이어의 특징)을 재결합하는 것은 다양한 특징을 조합하여 보다 고수준의 표현을 학습하는 과정을 의미합니다.
이전 레이어에서 얻은 다양한 특징을 재조합하는 방식은 여러가지가 있을 수 있습니다:
- 특징 간의 결합 (Feature Combination):
이전 레이어의 여러 특징들을 결합하여 하나의 뉴런이나 여러 뉴런들이 새로운 특징을 표현하도록 하는 과정입니다.
예를 들어, 두 개의 특징을 연결(concatenate)하거나, 더하거나, 빼거나, 곱하거나 등의 연산을 수행하여 새로운 특징을 생성할 수 있습니다.- 템플릿 간의 조합 (Template Combination):
이전 레이어의 각 템플릿(또는 특징)들 사이의 관계를 학습하고, 이를 통해 새로운 표현을 만드는 과정입니다.
템플릿 간의 상호 작용이나 관계를 학습하여 더 복잡한 표현이나 패턴을 발견하고 이를 재조합하여 새로운 표현을 만들어냅니다.
위의 정보를 참고합니다.
- second layer recombine templates
추출된 template간의 결합, 재결합을 통해 template을 섞어준다.
노이즈 제거, 일반화, 강력한 특징 추출 등의 장점
2 layer가 엄청나게 많아지면 Deep이 됩니다.
