퍼사드 패턴
Facade란 건물의 정면을 의미하는데, 퍼사드 패턴은 복잡한 건물의 정면을 바라보는 것처럼 복잡한 시스템에 대하여 단순한 인터페이스를 제공함으로써 사용자와 시스템간 또는 여타 시스템과의 결합도를 낮추어 시스템 구조에 대한 파악을 쉽게 하는 패턴으로 오류에 대해서 단위별로 확인할 수 있게 하며, 사용자의 측면에서 단순한 인터페이스 제공을 통해 접근성을 높일 수 있는 디자인 패턴이다.
예를들어 라이브러리의 각 클래스와 메서드들이 어떤 목적의 동작인지 이해하기 어려워 바로 가져다 쓰기에는 난이도가 높을때, 이에 대한 적절한 네이밍과 정리를 통해 사용자로 하여금 쉽게 라이브러리를 다룰수 있도록 인터페이스를 만드는데, 우리가 교제를 보고 필기노트에 재정리를 하듯이 클래스를 재정리하는 행위로 보면 된다.
즉, 퍼사드 패턴은 복잡하게 얽혀 있는 것을 정리해서 사용하기 편한 인터페이스를 고객에게 제공하고, 고객은 복잡한 시스템을 알 필요없이 시스템의 외부에 대해서 단순한 인터페이스를 이용하기만 하면 된다.
구조
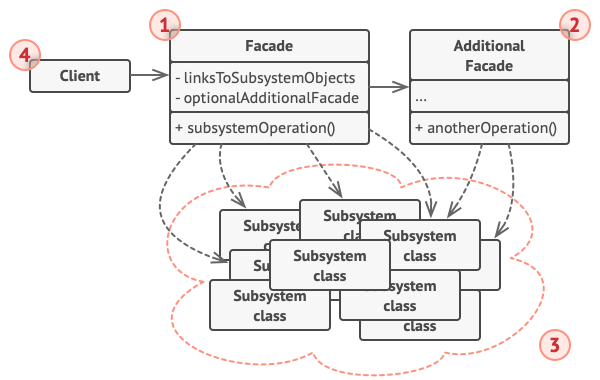
- Facade : 서브시스템 기능을 편리하게 사용할 수 있도록 하기 위해 여러 시스템과 상호 작용하는 복잡한 로직을 재정리해서 높은 레벨의 인터페이스를 구성한다. Facade 역할은 서브 시스템의 많은 역할에 대해 ‘단순한 창구’가 된다. 클라이언트와 서브시스템이 서로 긴밀하게 연결되지 않도록 한다.
- Additional Facade : 퍼사드 클래스는 반드시 한개만 존재해야 한다는 규칙같은 건 없다. 연관 되지 않은 기능이 있다면 얼마든지 퍼사드 2세로 분리한다. 이 퍼사드 2세는 다른 퍼사드에서 사용할 수도 있고 클라이언트에서 직접 접근할 수도 있다.
- SubSystem(하위 시스템) : 수십 가지 라이브러리 혹은 클래스들
- Client : 서브 시스템에 직접 접근하는 대신 Facade를 사용한다.
퍼사드 패턴은 전략 패턴이나 팩토리 패턴과 같은 여타 다른 디자인 패턴과는 다르게 클래스 구조가 정형화 되지 않은 패턴이다. 반드시 클래스 위치는 어떻고 어떤 형식으로 위임을 해야되고 이런것이 없다. 그냥 퍼사드 클래스를 만들어 적절히 기능 집약화만 해주면 그게 디자인 패턴이 되는 것이다. (패턴이라기 보단 논리에 가깝다)
C언어나 파이썬에서 어떠한 복잡한 로직의 코드가 있으면 이걸 main 함수에서 모두 실행하는 것이 아니라, 함수(function) 분리를 통해 main 함수의 코드를 심플하게 구성해본 경험이 있을 것이다. 이를 객체 지향 프로그래밍 관점으로 치환한 것이 퍼사드 패턴이다. 즉, 퍼사드는 복잡한 것(내부에서 실행되고 있는 많은 클래스의 관계나 사용법)을 단순하게 보여주는 것에 초점을 둔다. 클라이언트로 하여금 복잡한 것을 의식하지 않도록 해주는 것이다.
구현
기본 형태
// Row.java (Subsystem)
public class Row {
private String name;
private String birthDay;
private String email;
public Row(String name, String birthDay, String email) {
this.name = name;
this.birthDay = birthDay;
this.email = email;
}
public String getName() {
return name;
}
public String getBirthDay() {
return birthDay;
}
public String getEmail() {
return email;
}
}
// Database.java (Subsystem)
public class Database {
private Map<String, Row> rows = new HashMap<>();
public void insert(Row row) {
rows.put(row.getName(), row);
}
public Row query(String name) {
return rows.get(name);
}
}
// Cache.java (Subsystem)
public class Cache {
private Map<String, Row> rows = new HashMap<>();
public void put(Row row) {
rows.put(row.getName(), row);
}
public Row get(String name) {
return rows.get(name);
}
}
// Print.java (Subsystem)
public class Print {
private Row row;
public Print(Row row) {
this.row = row;
}
public void printName() {
System.out.println("[Print] name of the row is " + row.getName());
}
public void printBirthDay() {
System.out.println("[Print] birthday of the row is " + row.getBirthDay());
}
public void printEmail() {
System.out.println("[Print] email of the row is " + row.getEmail());
}
}퍼사드 패턴을 사용하지 않았을 때
위와 같은 서브시스템들이 모여 있고 클라이언트 메서드에서 위 기능들을 사용한다고 가정해보자.
만약 퍼사드 패턴을 사용하지 않을 경우 클라이언트 메서드는 다음과 같이 구현될 것이다.
public class Client {
public static void main(String[] args) {
Database db = new Database();
// 데이터베이스에 데이터 추가
db.insert(new Row("홍길동", "2008-10-11", "red_road_bronze@naver.com"));
db.insert(new Row("손흥민", "1992-05-05", "sonny@nice.one"));
db.insert(new Row("뉴진스", "2021-12-25", "newJeans@gmail.com"));
Cache cache = new Cache();
String name = "뉴진스";
// 성능 향상을 위해 캐시에 Row정보 우선 검색
Row row = cache.get(name);
// 캐시에 데이터 없으면 Database에 쿼리 && 캐시에 데이터 저장
if (row == null) {
row = db.query(name);
if (row != null) {
cache.put(row);
}
}
// 데이터 조회 결과 출력
if (row != null) {
Print print = new Print(row);
print.printName();
print.printBirthDay();
print.printEmail();
} else {
System.out.println(name + " does not exist on the database.");
}
}
}// 실행 결과
[Print] name of the row is 뉴진스
[Print] birthday of the row is 2021-12-25
[Print] email of the row is newJeans@gmail.com
위와 같이 여러 객체의 여러 메서드를 다루며 요청이 처리되는 과정을 그대로 메인 로직에 구현하게 되면, 당장은 문제가 없을 지라도 이후에 수정이나 확장이 필요한 경우 각 로직이 기억이 안날 수 있고 협업하는 다른 개발자들도 모든 객체의 로직을 하나하나 알아봐야 하는 번거로움이 있다.
퍼사드 패턴 적용
퍼사드 패턴을 적용 하기 위해서는 우선 해당 로직을 기능별로 분류하여 각 기능을 수행하는 메서드를 가진 Facade 클래스를 만들어 준다. 그리고 클라이언트는 각 객체에 직접 접근하는 것이 아닌 퍼사드 클래스에 접근하여 각 기능을 수행한다.즉, 마치 교제에 있는 풀어져 있는 내용들을 필기노트에 요약하듯이, 퍼사드 객체에 사용 로직을 묶어 재정리 함으로써 단순화 시켜 개발을 보다 용이하게 해주는 것이다.
// Facade.java
public class Facade {
private Database db = new Database();
Cache cache = new Cache();
public void insertAll() {
db.insert(new Row("홍길동", "2008-10-11", "red_road_bronze@naver.com"));
db.insert(new Row("손흥민", "1992-05-05", "sonny@nice.one"));
db.insert(new Row("뉴진스", "2021-12-25", "newJeans@gmail.com"));
}
public void printRow(String name) {
Row row = cache.get(name);
if (row == null) {
row = db.query(name);
if (row != null) {
cache.put(row);
}
}
if (row != null) {
Print print = new Print(row);
print.printName();
print.printBirthDay();
print.printEmail();
} else {
System.out.println(name + " does not exist on the database.");
}
}
}
// Client.java
public class Client {
public static void main(String[] args) {
Facade facade = new Facade();
facade.insertAll();
facade.printRow("뉴진스");
}
}// 실행 결과
[Print] name of the row is 뉴진스
[Print] birthday of the row is 2021-12-25
[Print] email of the row is newJeans@gmail.com
목적
- 시스템이 너무 복잡할때
- 그래서 간단한 인터페이스를 통해 복잡한 시스템을 접근하도록 하고 싶을때
- 시스템을 사용하고 있는 외부와 결합도가 너무 높을 때 의존성 낮추기 위할때
장점
- 하위 시스템의 복잡성에서 코드를 분리하여, 외부에서 시스템을 사용하기 쉬워진다.
- 하위 시스템 간의 의존 관계가 많을 경우 이를 감소시키고 의존성을 한 곳으로 모을 수 있다.
- 복잡한 코드를 감춤으로써, 클라이언트가 시스템의 코드를 모르더라도 Facade 클래스만 이해하고 사용 가능하다.
외부에서 내부 로직을 직접 사용하기 떄문에 내부 로직의 구조를 변경한다고 하거나 파라미터나 리턴값 등을 변경할 경우 직접적으로 영향을 받아 수정이힘들거나 불가능한 경우가 종종 있다. 하지만 중간에 매개체 역할을 해주는 퍼사드 객체가 있기 때문에 실제 내부 로직이 어떻게 변경이 되더라도 상관이 없어지므로 의존성이 감소된다.
단점
- 퍼사드가 앱의 모든 클래스에 결합된 God 객체가 될 수 있다
- 퍼사드 클래스 자체가 서브시스템에 대한 의존성을 가지게 되어 의존성을 완전히는 피할 수는 없다.
- 어찌되었건 추가적인 코드가 늘어나는 것이기 때문에 유지보수 측면에서 공수가 더 많이 들게 된다.
- 따라서 추상화 하고자하는 시스템이 얼마나 복잡한지 퍼사드 패턴을 통해서 얻게 되는 이점과 추가적인 유지보수 비용을 비교해보며 결정하여야 한다.
참고
