BFS
BFS 알고리즘은 Breadth-First Search의 줄임말로 너비 우선 탐색이라고 부르며, 가까운 노드부터 탐색하는 알고리즘이다.
가까운 노드부터(시작점으로부터 거리가 1인 노드부터) 가장 먼 노드까지 순서대로 처리하기 때문에 최단 거리를 찾을 때 유리하다.
BFS 알고리즘에서는 주로 큐(Queue)과 재귀 함수가 주로 사용된다.
<br
큐 (Queue)
큐란 대기줄과 같은 선입선출(First In First Out) 구조를 나타낸다.
python에서는 collections의 deque을 import하여 사용한다.
기본 자료구조인 list를 사용해서 구현할 수 있긴하지만 성능에서 차이가 난다고 한다.
python에서list는LinkedList(시작점을 기록하고 다음 항목의 위치를 기록하여 연결하는 방식의 List)가 아닌 고정된 사이즈의 메모리를 갖는 fixed size memory blocks(array) 이다.즉, 0번째에 x값 1번째에 y값 ... 이 들어가 있는 형태로 0번째를 제거하면 1번째 값을 0번째로, 2번째 값을 1번째로 옮기는 과정이 수행되며, O(n)의 시간복잡도를 갖는다.
이와 달리
collections의deque은 double-linked list로 구현되어 값을 제거해도 O(1)의 시간복잡도를 가진다.
from collections import deque
queue = deque()
queue.append(1) # [1]
queue.append(2) # [1, 2]
queue.popleft() # [2]
queue.append(3) # [2, 3]
queue.append(4) # [2, 3, 4]
queue.append(5) # [2, 3, 4, 5]
queue.popleft() # [3. 4, 5]
print(queue)
# 출력 결과
# [3, 4, 5]코드
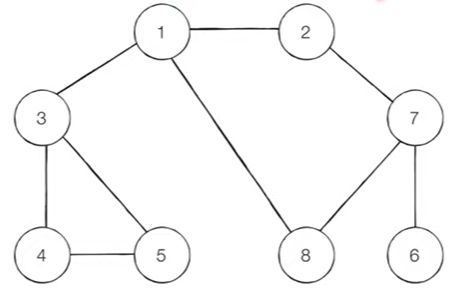
위 그림에서 각각의 노드를 연결된 다른 노들를 기준으로 코드로 표현하면 아래와 같이 나타낼 수 있다.
[
[], # 노드가 1번부터 시작되므로 0번에 빈 값을 넣어준다.
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]이것을 BFS로 풀어보면 다음과 같다(숫자가 낮은 노드를 우선적으로 탐색한다).
def bfs(graph, n, visited):
from collections import deque
visited.append(n)
q = deque([n])
while q:
t = q.popleft()
for i in graph[t]:
if i not in visited:
visited.append(i)
q.append(i)
return visited
graph = [
[], # 노드가 1번부터 시작되므로 0번에 빈 값을 넣어준다.
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
print(bfs(graph, 1, []))
# 출력 결과
# [1, 2, 3, 8, 7, 4, 5, 6]
개발공부를해보자