1️⃣ 분산 추적

분산 추적은 분산 시스템에서 서비스 간의 요청 흐름을 추적하고 모니터링하는 방법입니다.
각 서비스의 호출 관계와 성능을 시각화하여 문제를 진단하고 해결할 수 있도록 돕습니다.
MSA에서는 여러 서비스가 협력하여 하나의 요청을 처리합니다.
따라서 서비스 간의 복잡한 호출 관계로 인해 문제 발생 시 원인을 파악하기 어려울 수 있습니다.
분산 추적을 통해 각 서비스의 호출 흐름을 명확히 파악하고, 성능 병목이나 오류를 빠르게 진단할 수 있습니다.
🔹 주요 개념
트레이스(Trace)
- 트레이스는 하나의 요청이 시작부터 끝까지 각 서비스를 거치는 전체 흐름을 나타냅니다.
- 하나의 트레이스는 여러 개의 스팬으로 구성됩니다.
- 분산 시스템에서 클라이언트의 요청이 여러 서비스로 전달될 때, 각 서비스 호출이 트레이스의 일부로 기록됩니다.
- 트레이스 ID는 각 스팬에 공통으로 부여되며, 이를 통해 전체 요청 흐름을 추적할 수 있습니다.
스팬(Span)
- 스팬은 분산 추적에서 가장 작은 단위로, 특정 서비스 내에서의 개별 작업 또는 요청을 나타냅니다.
- 각 스팬은 시작 시간과 종료 시간을 기록하여 작업의 지속 시간을 나타냅니다.
- 스팬은 고유한 스팬 ID를 가지며, 이는 트레이스 ID와 함께 특정 작업을 식별하는 데 사용됩니다.
- 스팬은 부모-자식 관계를 가질 수 있으며, 이를 통해 호출 계층 구조를 표현합니다.
- 스팬에는 메타데이터(태그, 로그, 이벤트 등)를 추가하여 상세한 정보를 기록 할 수 있습니다.
컨텍스트(Context)
- 컨텍스트는 요청이 서비스 간에 전달될 때 함께 전파되어, 각 서비스가 요청의 전체 흐름에 대한 정보를 가질 수 있게 합니다.
- 컨텍스트는 트레이스 ID, 스팬 ID, 부모 스팬 ID 등의 정보를 포함하여 각 서비스가 요청의 출처와 경로를 추적할 수 있도록 돕습니다.
- 서비스 호출 간에 컨텍스트를 유지함으로써, 분산 시스템 전체에서 일관된 추적이 가능합니다.
2️⃣ Spring Cloud Sleuth
MSA 환경에서는 하나의 클라이언트 요청이 여러 마이크로서비스를 거쳐 처리되기 때문에 전체 흐름을 추적하기 어렵습니다.
이를 해결하기 위해서는 각 요청을 식별할 수 있는 연관된 ID가 필요하며, 이러한 ID를 자동으로 생성하고 전파해주는 것이 Spring Cloud Sleuth입니다.
Spring Cloud Sleuth는 분산 추적을 위한 라이브러리로, Trace ID와 Span ID를 생성하고 이를 HTTP 헤더 등을 통해 서비스 간에 전파합니다.
Trace ID는 하나의 클라이언트 요청 전체를 식별하는 ID로, 요청의 시작부터 끝까지 동일하게 유지됩니다.
Span ID는 각 서비스에서 수행되는 작업 단위를 나타내며, 서비스 호출 단위로 생성됩니다.
이러한 Trace ID와 Span ID를 활용하면 여러 서비스에 걸친 요청 흐름을 하나의 트랜잭션처럼 추적할 수 있으며, 분산 추적 시스템과 연동하여 호출 관계를 시각적으로 확인할 수 있습니다.
다만 Spring Boot 3.0부터는 Spring Cloud Sleuth가 deprecated 되었으며, 기존 Sleuth의 기능은 Micrometer Tracing으로 대체되었습니다.
따라서 Spring Boot 2.x 버전에서는 Sleuth를 사용하고, Spring Boot 3.x 이상에서는 Micrometer Tracing을 사용하는 것이 권장됩니다.
3️⃣ Micrometer
Micrometer는 Spring 기반 애플리케이션에서 메트릭을 수집하고 모니터링하기 위한 라이브러리입니다.
애플리케이션의 요청 수, 응답 시간, 메모리 사용량 등 다양한 성능 지표를 수집할 수 있으며, Prometheus, Grafana 등과 연동하여 이를 시각화할 수 있습니다.
또한 Spring Boot 3.x부터는 Micrometer Tracing을 통해 분산 추적 기능도 제공하며, 기존 Spring Cloud Sleuth가 담당하던 Trace ID와 Span ID 생성 및 전파 기능을 수행합니다.
이를 통해 서비스 간 호출 흐름 추적과 성능 모니터링을 함께 구성할 수 있습니다.
🔹 주요 특징
- 다양한 메트릭 수집: 애플리케이션의 다양한 성능 지표를 수집할 수 있습니다.
- 유연한 연동: Prometheus, Grafana 등 다양한 모니터링 도구와 연동할 수 있습니다.
- 추적 기능: 서비스 간의 호출 흐름을 추적하여 성능 병목을 진단할 수 있습니다.
4️⃣ Zipkin
Zipkin은 트레이스 데이터를 “수집/저장/조회/시각화”하는 역할을 담당하며, Tracing 라이브러리(Sleuth, Micrometer Tracing)와 함께 사용됩니다.
따라서 각 서비스의 trace와 span 데이터를 저장하고 이를 통해 호출 흐름을 시각화 합니다.
🔹 구조
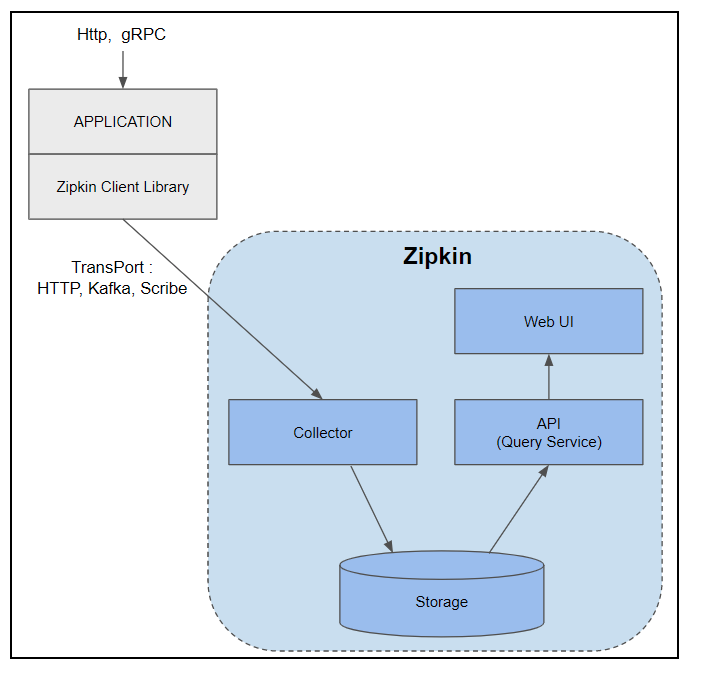
Zipkin은 Zipkin Client Library와 Zipkin Server로 구성되고, Zipkin Server는 Collector, Storage, API(Query Service), Web UI(Dashboard)로 구성됩니다.
-
Zipkin Client Library : 서비스에서 트레이스 정보를 수집하여 Zipkin Server의 Collector 모듈로 전송하며, 지원하는 언어는 Java, Javascript, Go, C# 등이 있다. Collector로 전송할 때는 다양한 프로토콜을 사용할 수 있지만 일반적으로 HTTP를 사용하고, 시스템이 클 경우 Kafka 큐를 통해서도 전송을 한다.
-
Collector : Zipkin Client Library로부터 전달된 트레이스 정보 유효성을 검증하고 검색 가능하게 저장 및 색인화 한다.
-
Storage : Zkipkin Collector로 보내진 트레이스 정보는 Storage에 저장된다. Zipkin은 초창기에는 Cassandra에 데이터를 저장하도록 만들어졌지만(Cassandra가 확장 가능하고 유연한 스키마를 가지고 있기 때문에 Twitter 내에서 많이 사용되었음), 그 뒤로 ElasticSearch나 MySQL도 지원 가능하게 구성되었다. 그 외에 In-Memory도 지원 가능하기 때문에 간단히 로컬에서 테스트할 때는 In-Memory, 소규모는 MySQL, 운영환경에 적용은 Cassandra나 ElasticSearch를 저장소로 사용하는 것이 좋다.
-
API(Zipkin Query Service) : 저장되고 색인화된 트레이스 정보를 검색하기 위한 JSON API이며, 주로 Web UI에서 호출된다.
-
Web UI : 수집된 트레이스 정보를 확인할 수 있는 GUI로 만들어진 대쉬보드이며, 서비스 / 시간 / 어노테이션 기반으로 데이터 확인이 가능하다. Zipkin 서버의 대쉬보드를 사용할 수도 있고, ElasticSearch 백앤드를 이용한 경우는 Kibana 활용도 가능하다.
🔹 주요 특징
- 데이터 수집 및 저장: 각 서비스에서 전송된 트레이스 데이터를 수집하고 저장합니다.
- 시각화: 트레이스 데이터를 시각화하여 서비스 간의 호출 관계를 명확히 파악할 수 있습니다.
- 검색 및 필터링: 특정 트레이스나 스팬을 검색하고 필터링하여 문제를 진단할 수 있습니다.
🔹 Zipkin 서버 설정
Zipkin 서버를 Docker를 사용하여 실행할 수 있습니다:
services:
zipkin:
image: ${ZIPKIN_IMAGE}
container_name: zipkin
ports:
- "9411:9411"
restart: unless-stoppeddocker run -d -p 9411:9411 openzipkin/zipkinZipkin 대시보드에 접속하여 트레이스 데이터가 시각화된 것을 볼 수 있습니다.
URL: http://localhost:9411
4️⃣ Spring Cloud Sleuth
MSA 환경에서는 하나의 클라이언트 요청이 여러 마이크로서비스를 거쳐 처리되기 때문에 전체 흐름을 추적하기 어렵습니다.
이를 해결하기 위해서는 각 요청을 식별할 수 있는 연관된 ID가 필요하며, 이러한 ID를 자동으로 생성하고 전파해주는 것이 Spring Cloud Sleuth입니다.
Spring Cloud Sleuth는 분산 추적을 위한 라이브러리로, Trace ID와 Span ID를 생성하고 이를 HTTP 헤더 등을 통해 서비스 간에 전파합니다.
Trace ID는 하나의 클라이언트 요청 전체를 식별하는 ID로, 요청의 시작부터 끝까지 동일하게 유지됩니다.
Span ID는 각 서비스에서 수행되는 작업 단위를 나타내며, 서비스 호출 단위로 생성됩니다.
이러한 Trace ID와 Span ID를 활용하면 여러 서비스에 걸친 요청 흐름을 하나의 트랜잭션처럼 추적할 수 있으며, 산 추적 시스템과 연동하여 호출 관계를 시각적으로 확인할 수 있습니다.
5️⃣ 실습
이번에는 “클라이언트 사이드 로드 밸런싱” 실습의 결과물을 가지고 진행해보겠습니다.
🔹 Product-service
- build.gradle 파일 디펜던시를 아래와 같이 수정합니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.github.openfeign:feign-micrometer'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
implementation 'org.springframework.cloud:spring-cloud-starter-openfeign'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}- application.yml
spring:
application:
name: product-service
server:
port: 19092
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
management:
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"
tracing:
sampling:
probability: 1.0🔹 Order-service
- build.gradle 파일 디펜던시를 아래와 같이 수정합니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.github.openfeign:feign-micrometer'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
implementation 'org.springframework.cloud:spring-cloud-starter-openfeign'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}- application.yml
spring:
application:
name: order-service
server:
port: 19091
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
management:
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"
tracing:
sampling:
probability: 1.0🔹 Zipkin
- Zipkin 도커 컨테이너 실행 코드를 커맨드를 켜서 입력합니다.
docker run -d -p 9411:9411 openzipkin/zipkin🔹 Run
Eureka Server > Order > Product 순으로 실행합니다.
-
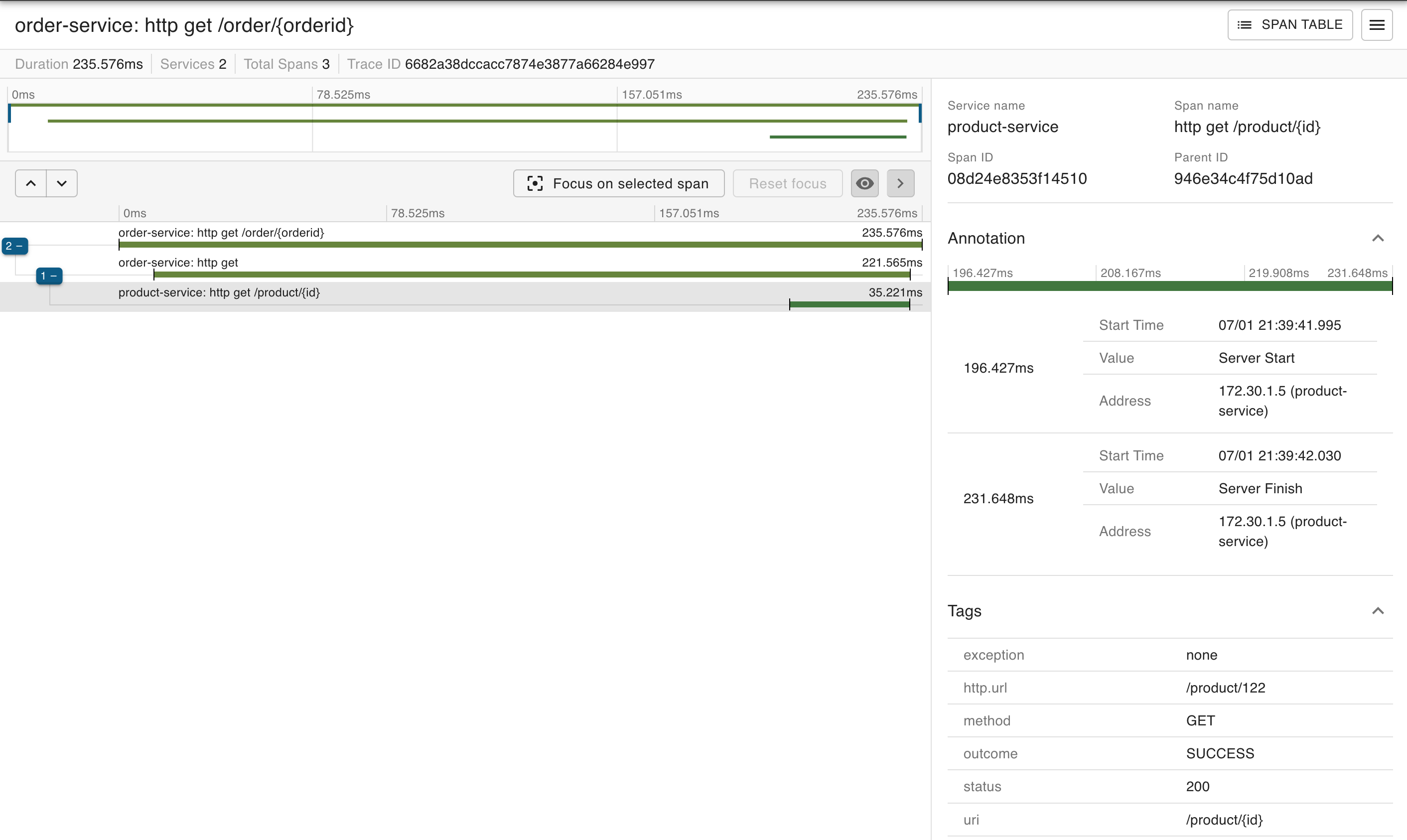
http://localhost:19091/order/1 를 접속해봅니다. 이전의 응답과 결과가 같습니다.

-
http://localhost:9411/zipkin/ 로 접속 후에 RUN QUERY를 클릭합니다. 리스트가 나오며 Spans 3 인 항목의 SHOW를 클릭합니다.
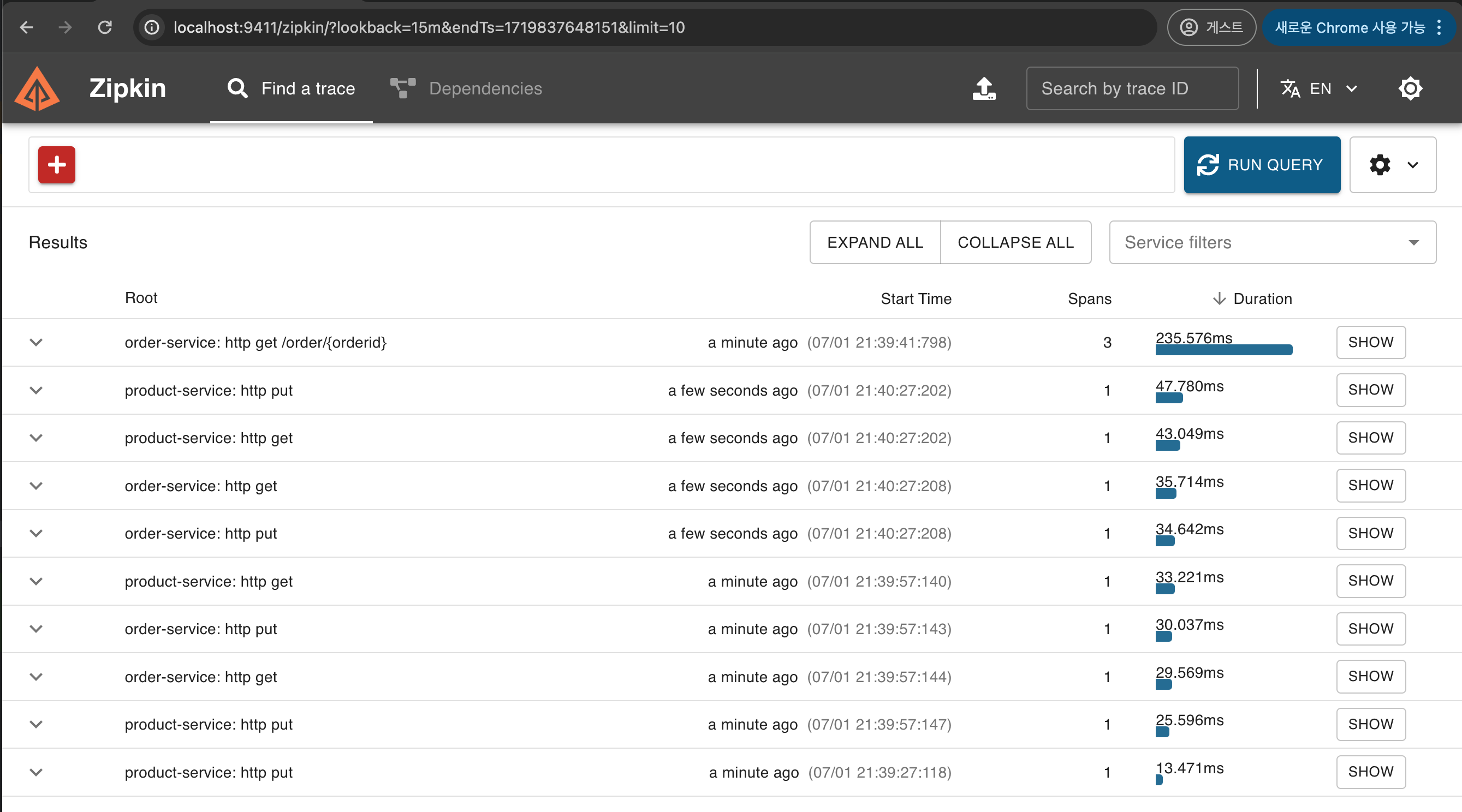
-
Order-service가 Product-service를 호출하는 과정이 트래킹 되는 것을 확인 할 수 있습니다.