드디어 월요일부터 위코드 1차 프로젝트가 시작되었다..!!! 기다리고 설레었던 프로젝트가 벌써 시작되었다니.. 시간이 참 빠른 것 같다😅 5-6명씩 한팀으로 정해졌고 총 6팀이었다. 백엔드 2명 프론트 3-4명으로 구성되었는데 어느 분들이랑 같은 팀이 될지 엄청 궁금했는데 다들 좋은 분들이랑 되어서 너무 좋다! 힘들지만 즐거운 2주를 보낼 수 있을 거 같다😊
클론코딩프로젝트인데 우리팀의 사이트는 카카오 프렌즈였다:) 팀이 정해진 후 팀끼리 각자 해야 할 것들과 우선순위 등 여러가지를 정해서 트렐로에 올린 후 멘토님들과 팀별로 모임을 갖고 조언을 들었다. 나는 백엔드이기 때문에 일단은 모델링이 제일 중요하기 때문에 같은 팀이 된 다른 한분과 같이 모델링을 먼저 하기로 하였고 클론코딩이지만 우리는 초보이기 때문에 전체 다 하는 건 아니고 일단은 전체 카테고리중 2개와 메인 페이지의 카테고리 4개만 하기로 하였다. 자세한 것은 프론트 엔드 분들과의 소통을 통해서 이것저것 맞춰가기로 하였다. 소통이 정말 중요하다는 것을 첫날부터 느꼈다. 데이터를 주고 받는 변수가 같아야 하고 어떤 식으로 주고 받을지 등등 여러가지 대화를 하였다.
메인카테고리 2개를 하기로 하였기 때문에 백엔드의 다른 한분과 카테고리 하나씩을 맡아서 크롤링을 하기로 했다. 스타벅스의 음료 페이지를 크롤링 한 적이 있었기 때문에 비슷하다 생각하였고 쉽다고 생각하였지만 그것은 큰 오산이었다....😂
첫 페이지에서는 크롤링을 성공하였지만 다른 페이지로 넘어가자 막히기 시작하였다. selenium을 이용해서 다음 페이지를 클릭하였고 beautifulsoup을 이용하여 필요한 태그들을 긁어오는 방식이었는데 다음 페이지도 url 이 완전히 같았기 때문에 페이지는 이동해도 자꾸 1쪽의 태그만 긁어지는 상황이 발생하였다...😭
나와 다른 백엔드 분 둘다 같은 문제에서 막혀서 이런 저런 방법도 써보고 구글링도 엄청 했지만 결국 다음날까지 풀지 못하였고 멘토님께 힌트를 달라고 하게 되었다. 힌트를 얻고 나니 이렇게 허무할 수가..
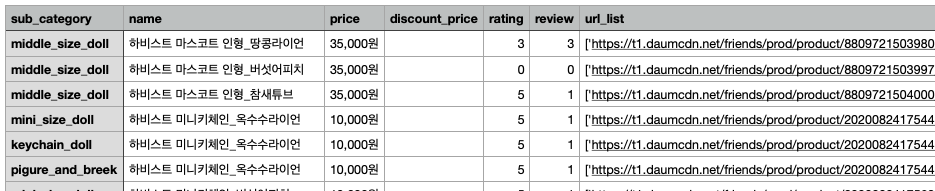
내 나름 이유를 생각해본 결과 url 이 같은 상황이었고 beautifulsoup은 정적페이지를 긁어오는 데 많이 사용되었고 selenium은 동적페이지를 긁어오는데 많이 사용되는데, 페이지를 넘어가도 url이 변하지 않았기 때문에 정적페이지를 긁어오는 beautifulsoup으로는 그래서 1쪽만 계속 긁어오게 되었던 것 같다. 일단 긁어오려고 생각한 파일들로는 성공을 하였다😋
하지만 프로젝트를 진행하면서 모델링도 수정하는 일이 생길 수도 있고 크롤링을 좀 고쳐나가야 하겠지만 일단은 여기까지 성공한 것에 만족하고 많이 해볼수록 늘고 익숙해질것이라 생각한다🙂
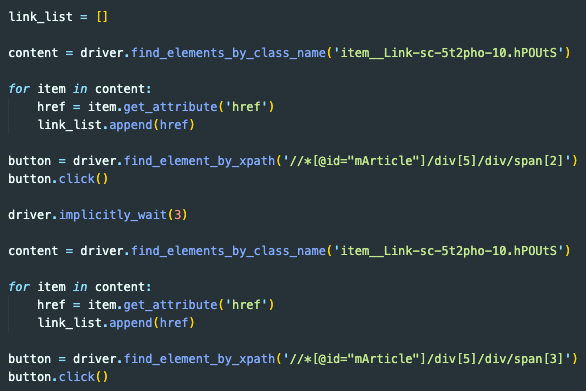
이런 식으로 beautifulsoup 은 전혀 사용하지 않고 selenium만 이용해 크롤링을 하였다. 상품리스트 페이지에서 class name 으로 원하는 태그를 찾고 그 안의 href 를 찾아서 링크들을 찾았다. xpath를 이용해 다음 페이지로 가는 버튼을 클릭하여 다음 페이지에서 같은 방식으로 태그들을 찾았다. 빈 리스트를 하나 만들어 링크들을 추가하였고 그 리스트를 for문으로 돌려 상세페이지를 긁어왔다.
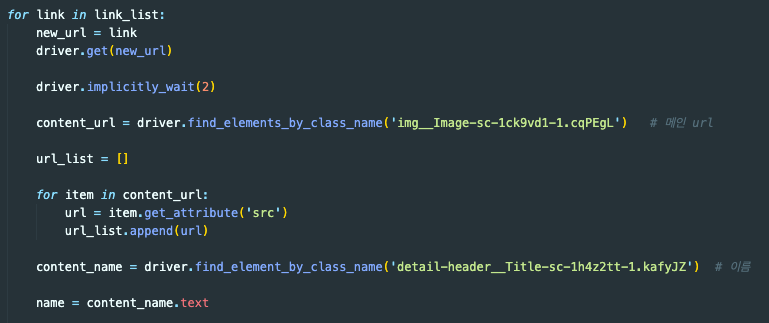
막상 완성하고 보니 단순해 보이지만 크롤링 초보자인 나에게는 어려운 시간들이었다. 그래도 이렇게 삽질도 해보고 성공도 해보고 하면서 배워가는 것이 많다는 것을 느꼈다. 다음주까지 진행하는 1차 프로젝트를 끝까지 잘 해내고 싶고 많이 배워서 2차 프로젝트도 잘 해내길 바라는 중이다🥁