On and Off-Policy Learning
On-policy Learning
- 직접 경험을 한다.
- 정책 π를 통해 얻은 경험으로부터 π를 학습한다.
Off-policy learning
- 다른 정책 π′를 통해 얻은 경험으로 부터 π를 학습한다.
Generalized Policy Iteration with MC Evaluation
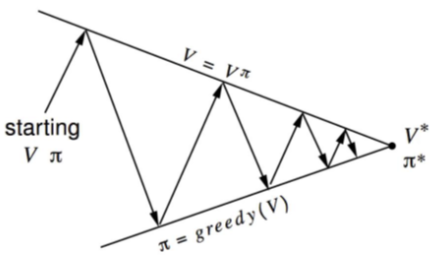
Policy evaluation: Monte-Carlo policy evaluation V=vπ?
Policy improvement: Greedy?
Model-free Policy Improvement
- V(s)를 통한 greedy policy improvement는 MDP의 모델을 필요로 한다.
π′(s)=a∈AargmaxRsa+Pss′aV(s′)
- 반면 Q(s,a)를 통한 greedy policy improvement는 모델이 필요없다.
π′(s)=a∈AargmaxQ(s,a)
Generalized POlicy Iteration with Q-Function
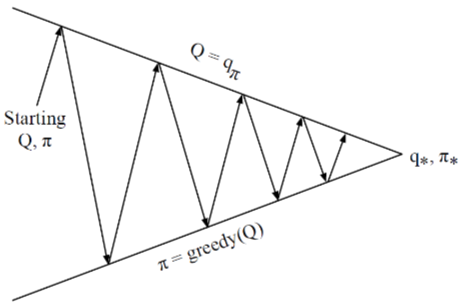
Policy evaluation: Monte-Carlo policy evaluation: Q=qπ
Policy Improvement: Greedy?
Exploration and Exploitation
Exploration은 환경에 대한 더 많은 정보를 찾는 것을 의미한다.
Exploitation은 이미 알고있는 정보를 이용하여 리워드를 최대화하는 걸 의미한다.
ϵ-Greedy Exploration
이는 exploration을 계속할 수 있는 가장 간단한 아이디어로, 모든 m개의 액션들은 0이 아닌 확률로 시도된다.
π(a∣s)={ϵ/m+1−ϵϵ/mif a∗=argmaxa∈AQ(s,a)otherwise
ϵ-Greedy Improvement
Theorem: 어떤 ϵ-greedy 정책 π에 대해서 qπ에 대한 ϵ-greedy 정책 π′는 다음을 만족한다.
vπ′(s)≥vπ(s)
qπ(s,π′(s))=a∈A∑π′(a∣s)qπ(s,a)=ϵ/ma∈A∑qπ(s,a)+(1−ϵ)a∈Amaxqπ(s,a)≥ϵ/ma∈A∑qπ(s,a)+(1−ϵ)a∈A∑1−ϵπ(a∣s)−ϵ/mqπ(s,a)=a∈A∑π(a∣s)qπ(s,a)=vπ(s)
Monte-Carlo Policy Iteration
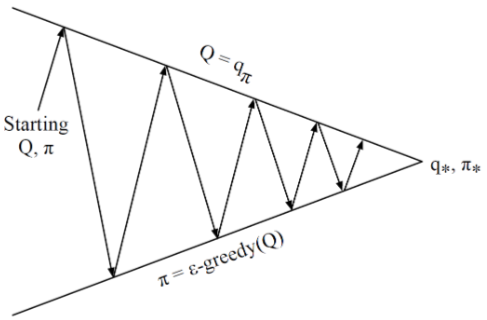
Policy evaluation: Monte-Carlo policy evaluation: Q=qπ
Policy Improvement: ϵ-Greedy policy improvement
Variant Monte-Carlo Policy Iteration
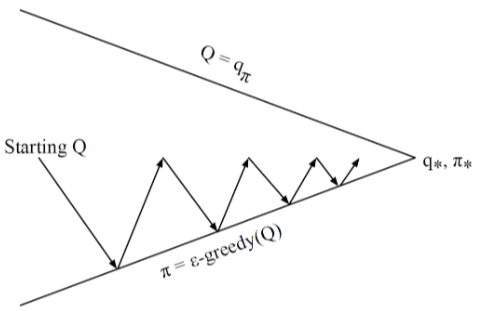
매 에피소드마다:
Policy evaluation: Monte-Carlo policy evaluation: Q≈qπ
Policy Improvement: ϵ-Greedy policy improvement
Greedy in the Limit with Infinite Exploration (GLIE)
Definition: GLIE
모든 state-actionh 순서쌍은 무한히 많이 탐험될 수 있어야 한다.
k→∞limNk(s,a)=∞
policy는 결국 greedy policy로 수렴해야 한다.
k→∞limπk(a∣s)=1(a=a′∈AargmaxQk(s,a′))
예를 들어 ϵk=k1라면 GLIE이다.
Monte-Carlo Control
k번째 에피소드를 샘플링함 π:{S1,A1,R2,…,ST}∼π
각 상태 St와 행동 At에 대해서
N(St,At)Q(St,At)←N(St,At)+1←Q(St,At)+N(St,At)1(Gt−Q(St,At))
그리고 새로운 action-value function을 기반으로 정책을 업데이트한다.
ϵ←k1π←ϵ−greedy(Q)
MC vs TD control
TD는 MC보다 다음과 같은 장점들이 있다.
- 낮은 variance
- online
- 완료되지 않은 시퀀스
자연스러운 생각은 MC대신 바로 TD를 적용하는 것이다.
- TD를 Q(S,A)에 적용하고,
- ϵ-greedy로 정책을 improve하고
- 매 타임스텝마다 업데이트
Model-free Policy Iteration with TD Methods
- Policy evaluation Qπ를 매 time-step마다 temporal difference를 이용해서 학습
- Policy improvement: MC와 동일하게 ϵ-greedy
Updating Action-Value Functions with SARSA
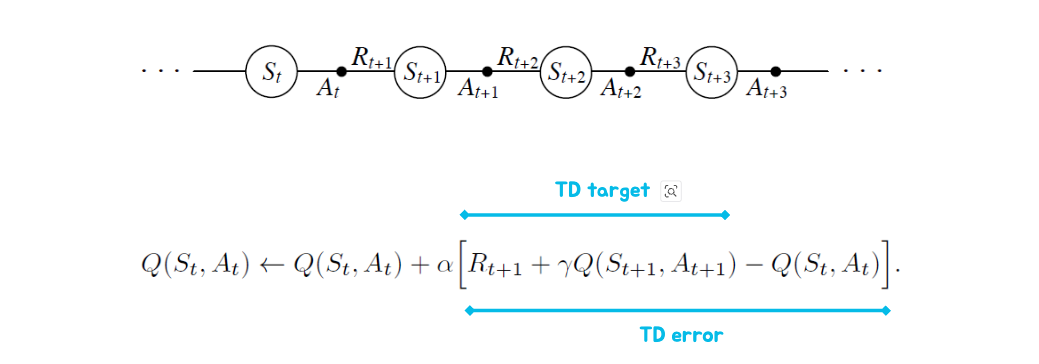
Policy Control with SARSA
- 매 time-step마다
- policy evaluation: Q(S,A)←Q(S,A)+α(R+γQ(S′,A′)−Q(S,A)
- policy improvement: ϵ-greedy
SARSA

n-step SARSA
n=1n=2⋮n=∞ (Sarsa) (MC)qt(1)=Rt+1+γQ(St+1)qt(2)=Rt+1+γRt+2+γ2Q(St+2)⋮qt(∞)=Rt+1+γRt+2+⋯+γT−1RT
Off-Policy Learning
정책 μ(a∣s)를 따를 때, vπ(s)나 qπ(s,a)를 계산하여 π(a∣s)를 평가할 수 있을까?
{S1,A1,R2,…,ST}∼μ
Importance Sampling
EX∼P[f(X)]=∑P(X)f(X)=∑Q(X)Q(X)P(X)f(X)=EX∼Q[Q(X)P(X)f(X)]
Importance Sampling for Off-Policy Monte-Carlo
- π를 계산하기 위해 μ로부터 생성된 return을 사용
- return Gt를 두 정책의 유사도에 따라 가중해야함
- 전체 에피소드에 대한 imporance weight를 곱해줌
Gtπ/μ=μ(At∣St)π(At∣St)μ(At+1∣St+1)π(At+1∣St+1)⋯μ(AT∣ST)π(AT∣ST)Gt
- 수정된 return을 통해 value를 업데이트함.
V(St)←V(St)+α(Gtπ/μ−V(St))
- 단 μ가 0이면 사용할 수 없고, 이는 매우 variance를 크게 만들 수 있음
Importance Sampling for Off-Policy TD
- TD target Rt+1+γV(St+1)에 importance sampling을 적용함.
V(St)←V(St)+α(μ(St,At)π(St,At))(Rt+1+γV(St+1)−V(St))
- 이는 MC importance sampling보다 훨씬 variance가 작음
Q-Learning: Off-policy TD Control
- 이제 action-value Q(S,A)에 대해 생각해보자.
- imporance sampling은 필요없다.
- 다음 action은 At+1∼μ(St)에 의해 뽑힌다.
- 그러나 우리는 다른 후속 action A′∼π(St)를 려해야한다.
- 그리고 Q(St,At)를 대책 action의 value로 업데이트한다.
Q(St,At)←Q(St,At)+α(Rt+1+γQ(St+1,A′)−Q(St,At))
target policy π를 greedy하게 잡으면
π(St)=argmaxa′Q(St+1,a′)
그러면 Q-learning 타겟이 다음과 같이 간단해진다.
Rt+1+γQ(St+1,A′)=Rt+1+γQ(St+1,a′argmaxQ(St+1,a′))=Rt+1+a′maxγQ(St+1,a′)

SARSA vs Q-Learning
Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
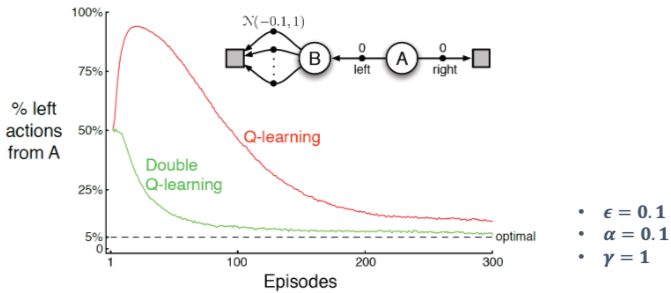
Maximization Bias
- 하나의 상태(state)만 있는 MDP(Markov Decision Process)를 가정하고, 가능한 두 가지 행동 a1, a2가 있다고 하자.
- 이 두 행동은 모두 평균이 0인 확률적 보상(reward)을 가진다:
E(r∣a=a1)=E(r∣a=a2)=0
- 기대 보상이 0이므로, 이론적인 Q값도 둘 다 0이다:
Q(s,a1)=Q(s,a2)=0
- 이전에 a_1과 a_2를 각각 실행해 본 샘플들이 존재한다고 가정하자. (즉, 학습 데이터가 있음)
- 이는 실제 Q가 아니라 샘플 기반으로 추정한 Q값이다. 즉, 유한한 샘플로부터 계산된 Q값:
Q^(s,a1),Q^(s,a2)
- 추정된 Q값을 기반으로, greedy 정책 \hat{\pi}를 정의한다. 즉, 가장 높은 \hat{Q}를 선택하는 정책:
π^=arga’maxQ^(s,a’)
- 샘플로 계산한 추정값 중 최댓값을 취하면, 평균은 0이더라도 양수가 될 가능성이 높다.
→ 최대화 편향(Maximization Bias) 발생:E[max(Q^(s,a1), Q^(s,a2))]>0
Double Learning
- Q값에 대한 greedy policy는 최대화 편향을 발생시킬 수 있다.
- 이를 보완하기 위해 두개의 Q1, Q2를 둔다.
- 하나의 추정치를 통해 max action을 선택함: a∗=argmaxaQ1(s,a)
- 다른 Qㄹ를 이용해서 value를 계산함 a∗:Q2(s,a∗)