Review
Return은 step t에서 총 할인된 리워드들의 합이다.
Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
vπ(s)는 s 상태에서 π 정책하에 return의 기댓값이다.
vπ(s)=E[Rt+1+γv(St+1)∣St=s]
qπ(s,a)는 s 상태에서 a행동을 했을 때, π 정책하에 return의 기댓값이다.
qπ(s,a)=E[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
Model-free Reinforcement learning
Model-free prediction(evaluation)
- MDP를 모를 때 value function을 예측하는 것
- 이 policy가 얼마나 좋은지
Model-free control(improvement)
- MDP를 모를 때 value function을 최적화하는 것
- 어떻게 더 좋은 policy를 학습할 수 있을지
Model-free Policy Evaluation
- 실제 MDP 모델 없이 특정 policy의 기대 return 값을 예측하는 것.
Monte-Carlo Reinforcement Learning
- MC method는 경험들의 episode로 직접 학습한다.
- MC는 model-free로, MDP transition이나 reward에 대한 지식이 필요없다.
- MC는 완전한 episode를 통해 학습한다: Bootstapping을 하지 않는다.
- MC는 간단한 아이디어를 사용한다: value가 return의 평균이라는 것.
- episodic MDP에서만 적용할 수 있다. 즉: 모든 에피소드는 종료되어야 한다.
Monte Carlo Policy Evaluation
- 목표: π 하의 경험들의 episode로 vπ(s)를 학습하는 것.
S1,A1,R2,…,Sk∼π
- return은 총 discounted reward임
Gt=Rt+1+γRt+2+⋯+γT−1RT
- value function은
expected return임Vπ(s)=Eπ[Gt∣St=s]
- Monte-Carlo policy evaluation은
expected return 대신 경험적 mean return을 사용함.
First-Visit Monte-Carlo Policy Evaluation
State s를 평가하기 위해
- 에피소드에서 s에 처음 도달한 시간 t에,
- counter를 증가시키고 N(s)←N(s)+1
- total return을 증가시키고, S(s)←S(s)+G(t)
- value를 mean return으로 업데이트하고 V(s)←N(s)S(s)
- 큰수의 법칙에 따라 N(s)→∞에 따라 V(s)→Vπ(s)로 수렴한다.
Every-Visit Monte-Carlo Policy Evaluation
State s를 평가하기 위해
- 에피소드에서 s에 매번 도달한 시간 t에,
- counter를 증가시키고 N(s)←N(s)+1
- total return을 증가시키고, S(s)←S(s)+G(t)
- value를 mean return으로 업데이트하고 V(s)←N(s)S(s)
- 큰수의 법칙에 따라 N(s)→∞에 따라 V(s)→Vπ(s)로 수렴한다.
Incremental Mean
μk=k1j=1∑kxj=k1(xk+j=1∑k−1xj)=k1(xk+(k−1)μk−1)=μk−1+k1(xk−μk−1)
Incremental Monte-Carlo Update
각 state마다, 리턴 Gt로 상태 St를 업데이트할 수 있다.
N(St)V(St)←N(St)+1←V(St)+N(St)1(Gt−V(St))
non-stationary problem에서는 다음과 같이 running mean을 계산할 수 있다.
V(St)←V(St)+α(Gt−V(St))
Temporal-Difference Learning
- TD도 똑같이 경험의 epidsode를 통해 직접 학습한다.
- TD도 model-free로, MDP transition이나 reward에 대한 사전지식 없이 학습할 수 있다.
- TD는 완료되지 않은 episode에 대해 학습할 수 있다.
- TD는 예측값을 예측값을 통해 업데이트한다. (bootstrapping)
Monte Carlo vs Temporal Difference
Incremental Monte-Carlo:
V(St)←V(St)+α(Gt−V(St))
Temporal-difference elarning algorithm
- value V(St)를 Rt+1+γV(St+1)로 업데이트한다.
V(St)←V(St)+α(Rt+1+γV(St+1)−V(St))
- Rt+1+γV(St+1)를 TD target이라고 부르고, δt=Rt+1+γV(St+1)−V(St)를 TD error라고 부른다.

MC vs TD
MC는 완전한 시퀀스로부터만 학습할 수 있다.
- MC는 에피소드의 끝까지 기다려야 한다.
- MC는 episodic 환경에서만 동작한다.
TD는 완료되지 않은 시퀀스로부터 학습할 수 있다.
- TD는 최종 outcome 없이 학습할 수 있다.
- TD는 매 스텝마다 온라인으로 학습할 수 있다.
- TD는 continuing 환경에서도 동작한다.
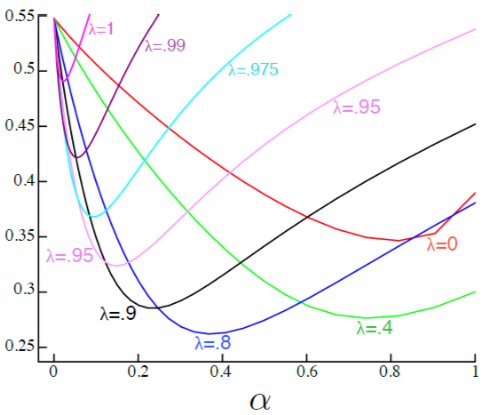
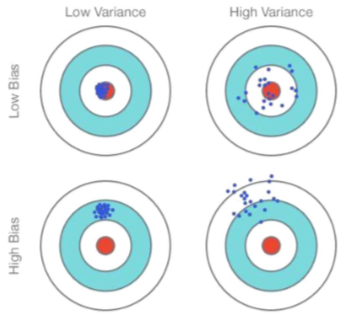
Bias/Variance Trade-off
- bias는 학습 알고리즘에서 잘못된 가정으로부터 도출된 에러임.
- variance는 training set에서 작은 변동으로 인한 민감도로 부터 나오는 에러임.
- return Gt=Rt+1+γRt+2+…는 vπ(st)의 unbiased 추정이다.
- 실제 TD target은 vπ(st)의 unbiased 추정이다.
- 그러나 TD target Rt+1+γV(St+1)은 biased 추정이다.
- TD target은 return보다 훨씬 낮은 variance를 갖는다.
Bias/Variance of MC vs TD
MC: high variance, zero bias
TD: low variance, some bias
Batch MC and TD
Finite dataset에 대한 batch(offline) solution
- 주어진 K개의 episode에 대해
- 반복적으로 k∈[1,K]를 샘플링해서
- 샘플링된 에피소드에 대해 MC나 TD를 적용
MC vs TD
- 가장 단순한 TD에서 (s,a,r,s′)를 V(s)를 업데이트할때 사용한다.
- 따라서 업데이트당 O(1), 에피소드 당 O(L)이 소요
- MC 도 에피소드 당 O(L)이 소요됨.
- TD는 Markov structure를 이용하므로, Markov 도메인에서 유용하다.
- MC는 Markov property를 이용하지 않으므로, non-Markov 환경에서 더 유용하다.
n-step Return
n=1n=2⋮n=∞(TD)⋮(MC)Gt(1)Gt(2)⋮Gt(∞)===Rt+1+γV(St+1)Rt+1+γRt+2+γ2V(St+2)Rt+1+γRt+2+⋯+γT−1RT
n-step temporal-difference learning은 다음과 같이 할 수 있다.
V(St)←V(St)+α(Gt(n)−V(St))
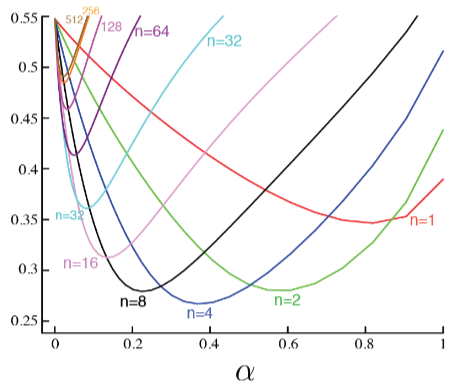
Averaging n-step Returns
여러 n에 대해서 n-step return을 평균할 수 있다. 예를 들어:
21G(2)+21G(4)
모든 time-step의 정보를 효율적으로 모을 수 있을까?
λ-return
TD(λ)는 n-step update를 평균하는 하나의방법으로,
- 각각은 λn−1의 비율로 가중되며,
- λ-return은 다음과 같이 정의된다.
Gtλ≐(1−λ)n=1∑∞λn−1Gt:t+n
- 그리고 이 λ-return을 이용한 백업은 다음과 같다.
V(st)=V(st)+α[Gtλ−Vt(st)]
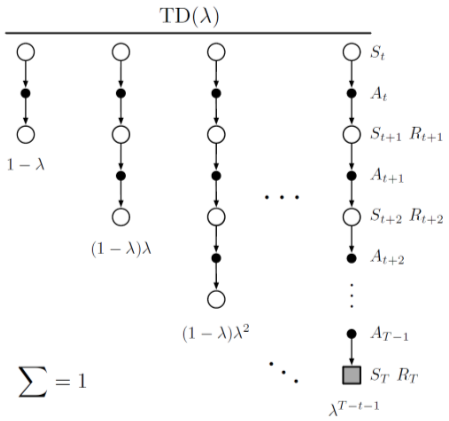
λ가 0이면 one-step TD를 하는 것이고,
λ가 1이면 MC를 하는 것이다.
Gtλ=(1−λ)n=1∑∞λn−1Gt(n)=(1−λ)n=1∑T−t−1λn−1Gt(n)+λT−t−1Gt