여기서 일단 다음 챕터들을 스킵함
- VIII. Complex Data Types
- IX. Application Development
- X. Big Data
- XI. Data Analytics
DBMS는 내구성을 위해 파일시스템과 상호작용함.
Classification of Storage Media
Storage는 다음 두개로 나뉘어진다.
- volatile storage: 전원이 꺼지면 내용을 잃음
- non-volatile storage: 전원이 꺼져도 내용을 잃지 않음
Performance of Storage Media
storage media의 선택에 영향을 미치는 요소
- Latency (PCI > Memory bus - 물리적으로 멂)
- Bandwidth: 한번에 읽을 수 있는 데이터의 양 (HBM)
- Cost
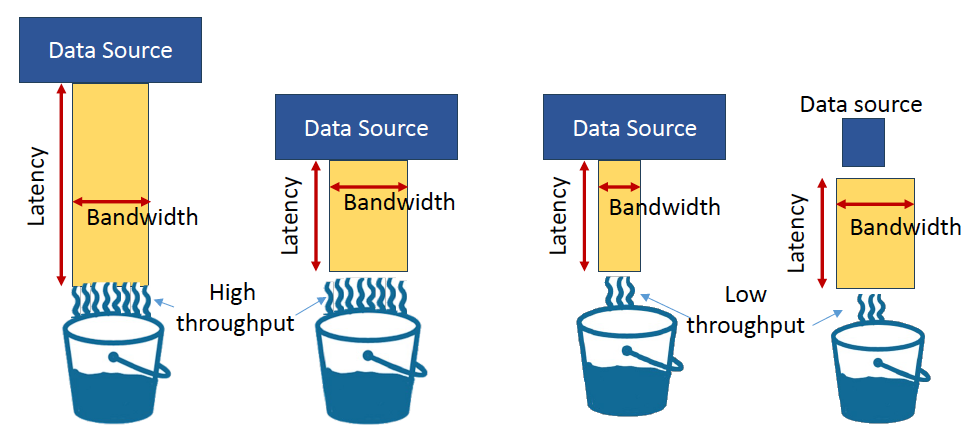
- latency와 throughput은 완전히 독립적임. High throughput이 Low latency를 보장하지 않음
IO Granularity of Storage Media
- CPU 내에 Register, 그 옆에 CPU Cache가 있음.
- Cache miss가 발생한다면, 8Byte만 읽으려고 하더라고 그 근처 64byte를 그대로 캐시로 올림
- Disk와 Memory 사이에는 4KB단위로 데이터를 전송하므로, Disk에서도 4KB 단위로 관리함
Before HDD, there was Magnetic Tapes
카세트 테이프
플로피 디스크: 헤드가 더 큼
Magnetic Hard Disk Mechanism
- 플로피 디스크를 발전시킨 형태
- platter가 계속 돌면서 원하는 데이터를 찾음
Performance Measures of Disk
- Access time = Seek time + Rotational latency
- Seek time: arm이 움직이는 시간
- Rotational latency: 플래터가 회전하는 시간
- Data-transfer rate: 1초에 몇바이트를 읽는지
- 디스크를 sequential하게 읽으면 굉장히 빠른데, random하게 읽으면 굉장히 느림
- seek가 느리기 때문
Flash Storage
OS 때 했으므로 패스
DBMS
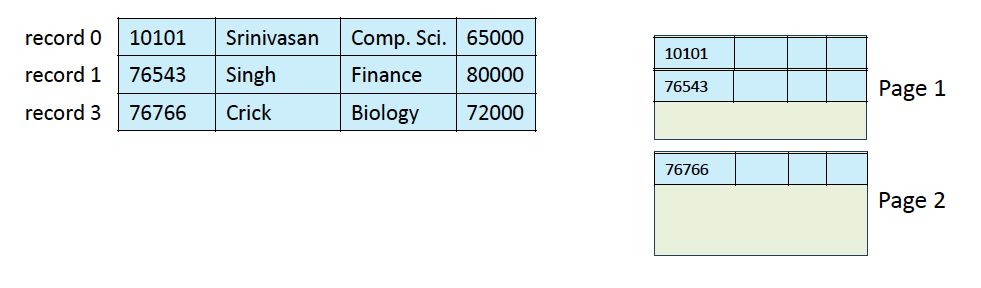
Fixed-Length Records
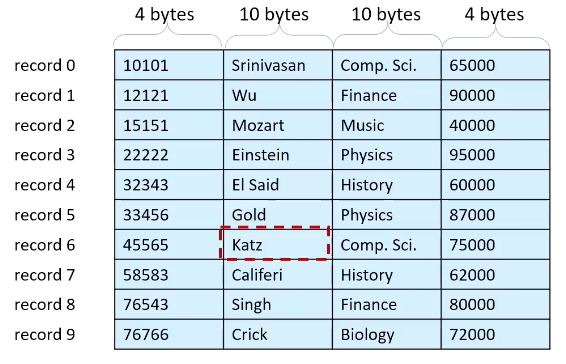
record 6의 두번째 attribute는 28 * 6 + 4로 읽을 수 있음
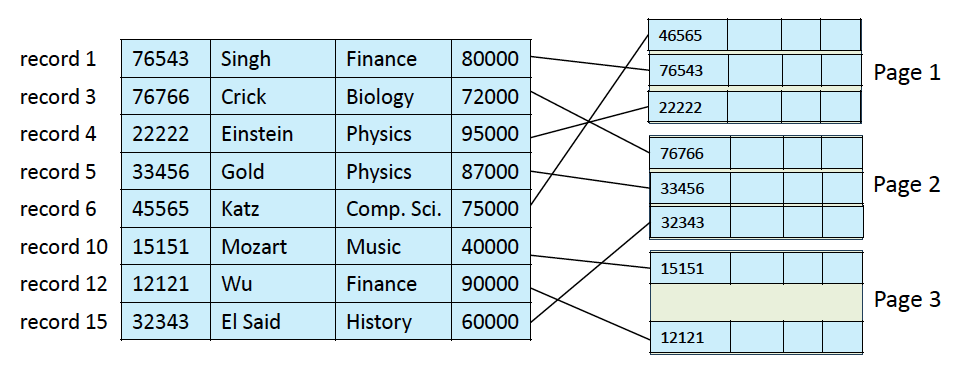
delete를 한다면?
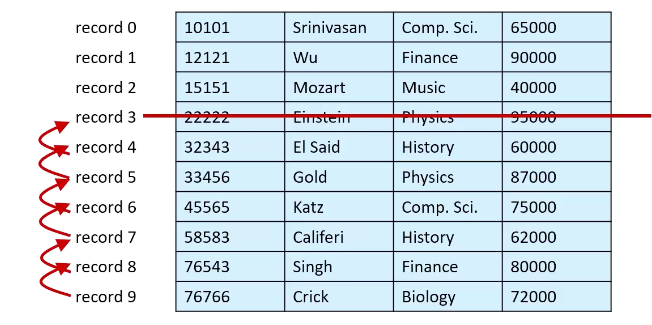
- 뒤에서부터 하나씩 당겨오는 옵션
- 마지막 레코드를 삭제된 위치로 가져오는 옵션
- 삭제된 채로 내버려두고, free record에 대한 정보를 따로 관리하는 방법
Variable-Length Records
- varchar같은 record가 있음
- length 정보도 같이 저장해야함

- 처음에 메타데이터를 저장할 header 부분을 4바이트씩 3개 저장하고, 8바이트를 할당해서 salary 값을 씀
- 만약 null이 필요하다면 Null bitmap 1바이트를 사용해야 함
- 그 뒤로 데이터 저장
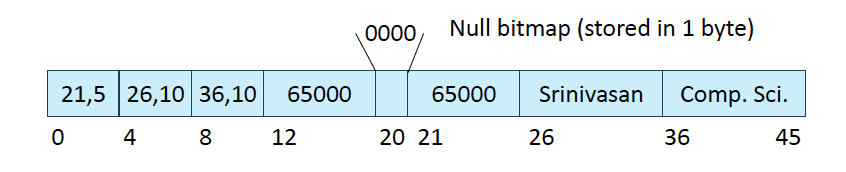
Page Layout
- Slotted page라는 구조를 사용해서 데이터를 저장함
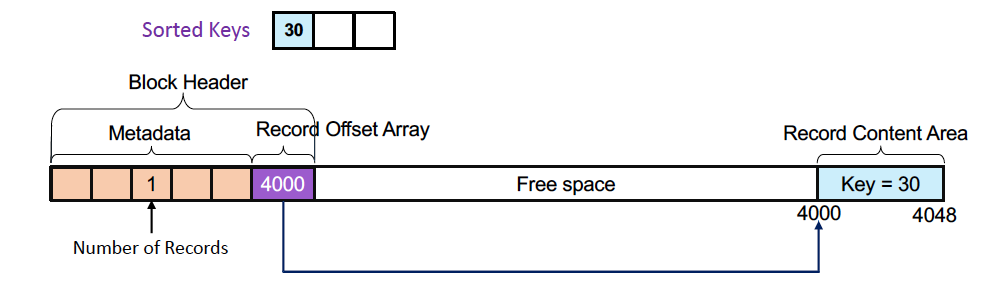
Slotted Page Structure
- 처음에 30이라는 기본키를 insert
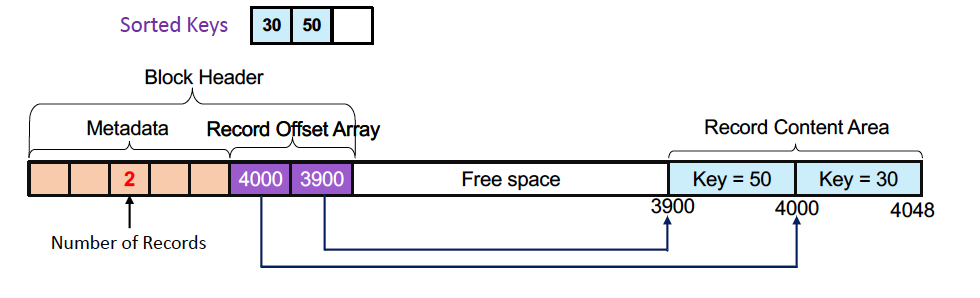
- 50을 insert
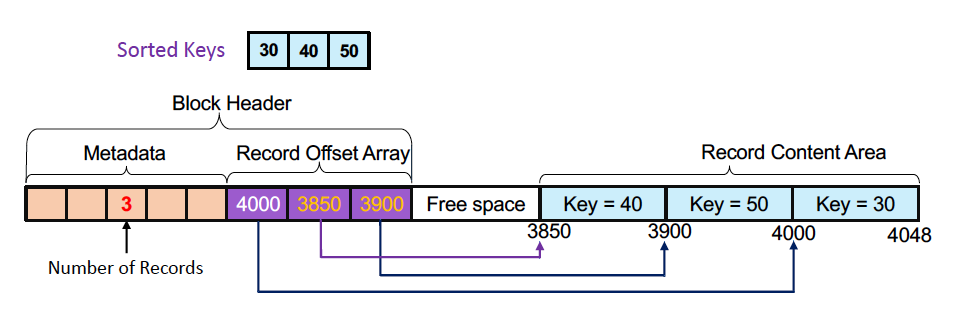
- 40을 insert
데이터는 내버려두고, record offset Array만 정렬한 상태로 저장
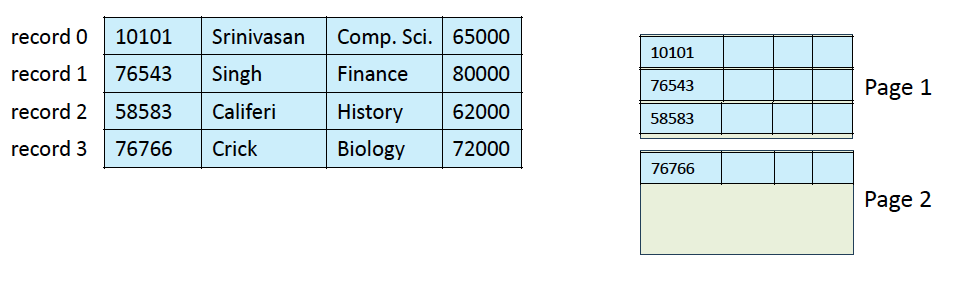
Organization of Records in Files
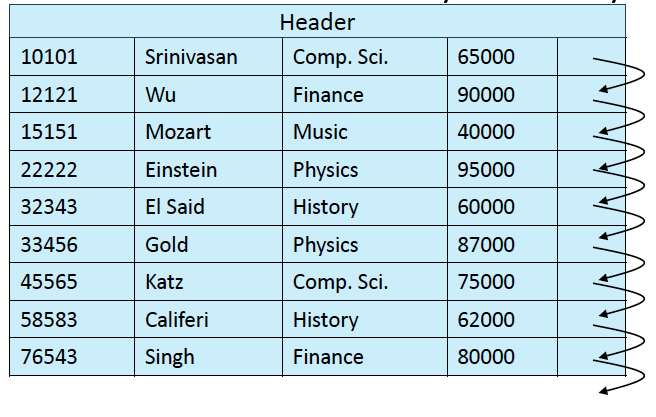
Heap file
- Heap: 자료구조 heap이 아님. 그냥 랜덤하게 저장할 수 있는 공간
- Slotted Page 구조로 저장되는데, sort하지 않음
- 그냥 여유공간이 있는 위치에 마구마구 쌓아넣음
여기에서 record 2를 지우면
그냥 이렇게 둠.
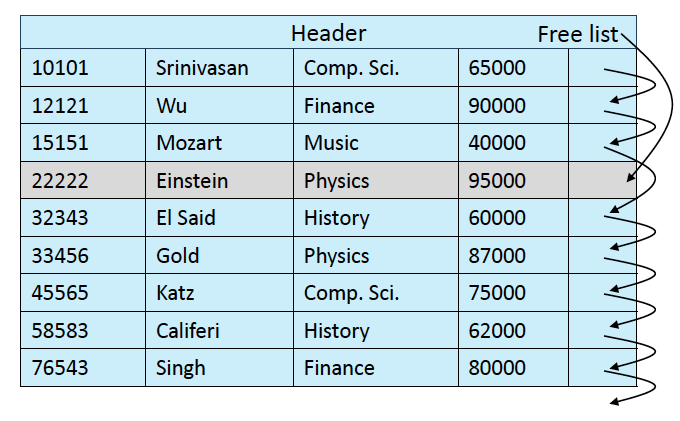
이렇게 쓰다보면 이렇게 됨.
-
빈공간을 찾기 위해 Free-space map을 사용함.
-
비율로 각 page의 빈공간을 저장

-
위처럼 multi level로 사용하게 되는데,이떄는 진짜 max heap을 사용함.
Sequential File Organization
- 데이터를 정렬해서 관리함
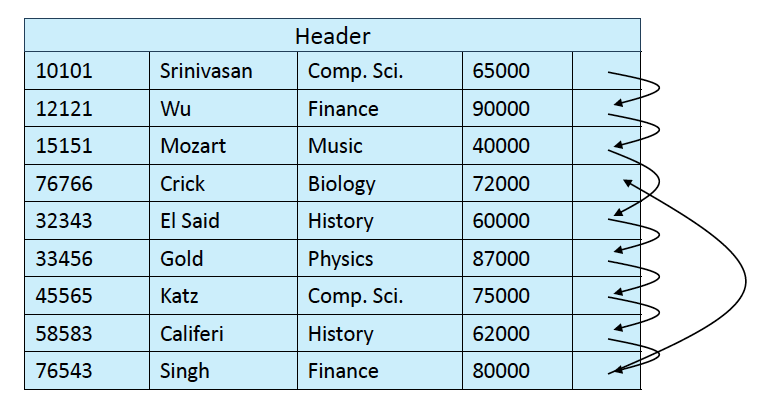
- 근데 이런 방식은 계속 랜덤하게 점프해야하기 때문에 Cache miss를 계속 일으켜 주기적으로 재정렬을 해줘야함
Multitable Clustering Table
- join 연산은 sorting이 되어있으면 좋음
- join이 계속 일어난다면 미리 같이 저장할 수 있음
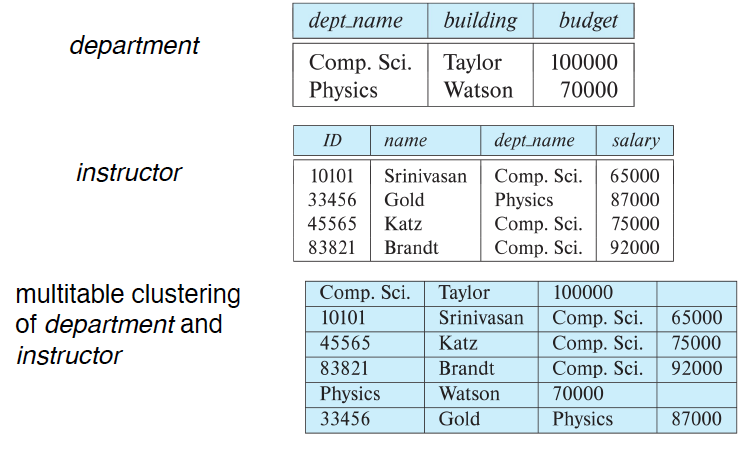
- 이렇게 하는 가장 큰 이유는 그냥 sequential access가 빠르기 때문
Column-Oriented Storage
- NoSQL에서 자주 사용하는 방식
- columnar representation이라고도 부름
- null을 마구마구 저장하지 않기 위함
Data Dictionary
aka system catalog
- 테이블에 대한 정보, 통계적인 데이터 등의 메타데이터를 관리하는 별도의 테이블이 있음
- 파일 포맷(Sequential, Heap, B+tree, ...) 도 저장
- 통계적인 데이터는 Optimization 파트에서 사용할 예정
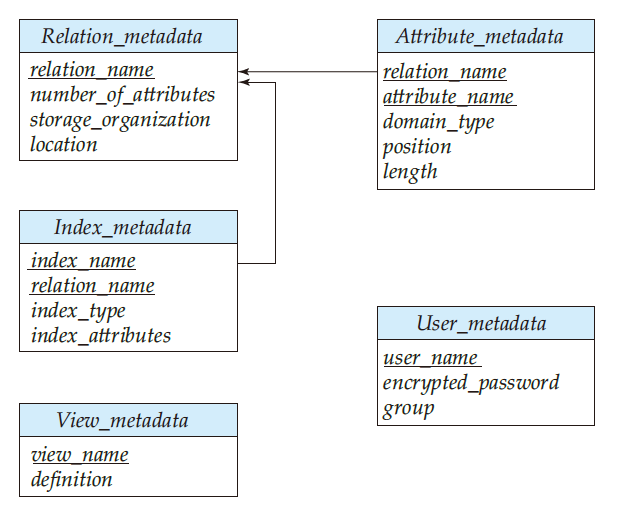
Storage Access
- DBMS는 OS가 아닌 자체 Cache를 사용함.
- 그 이유는 알고리즘을 마음대로 사용하기 위함.
- Buffer manager: buffer cache를 관리하는 서브시스템
Buffer Manager
- DBMS는 블럭이 필요할 때 buffer manager(RAM)를 부름
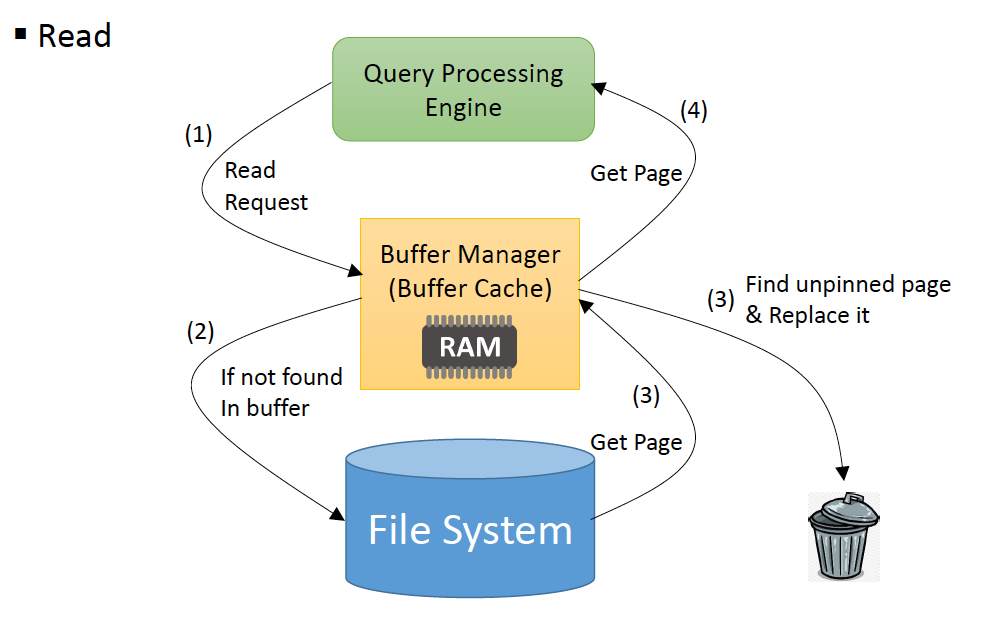
- read 요청을 보냄
- buffer cache에 존재한다면 바로 반환. 없다면 file system 탐색
- 페이지를 cache 업데이트 (Buffer replacement)
unpinned: 사용하고 있는 페이지
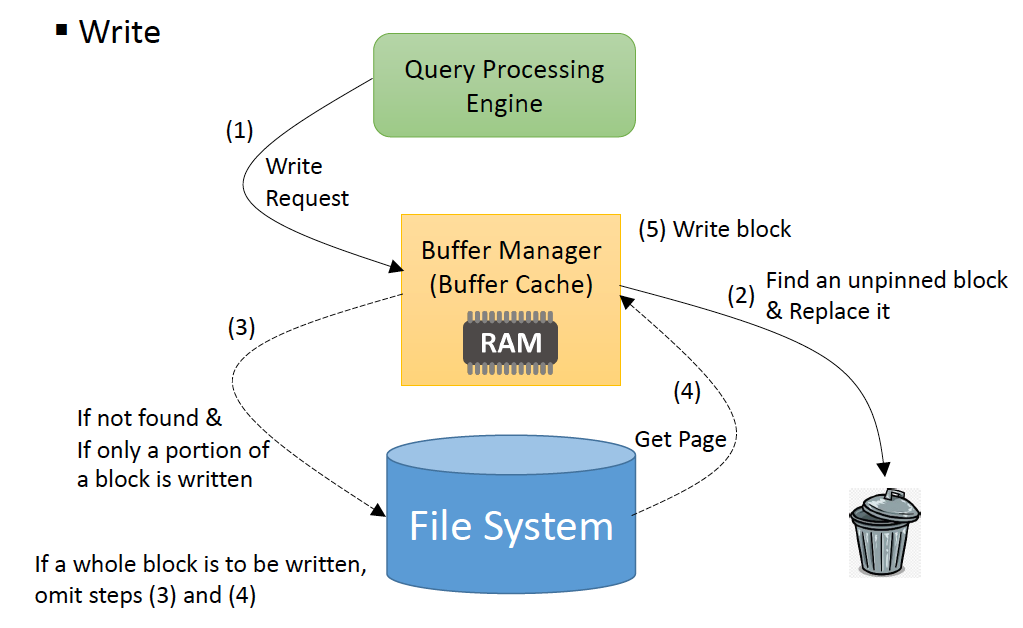
- buffer manager에게 쓰기를 요청
- X의 사이즈가 4KB또는 8KB면 3번, 4번 스텝을 무시함
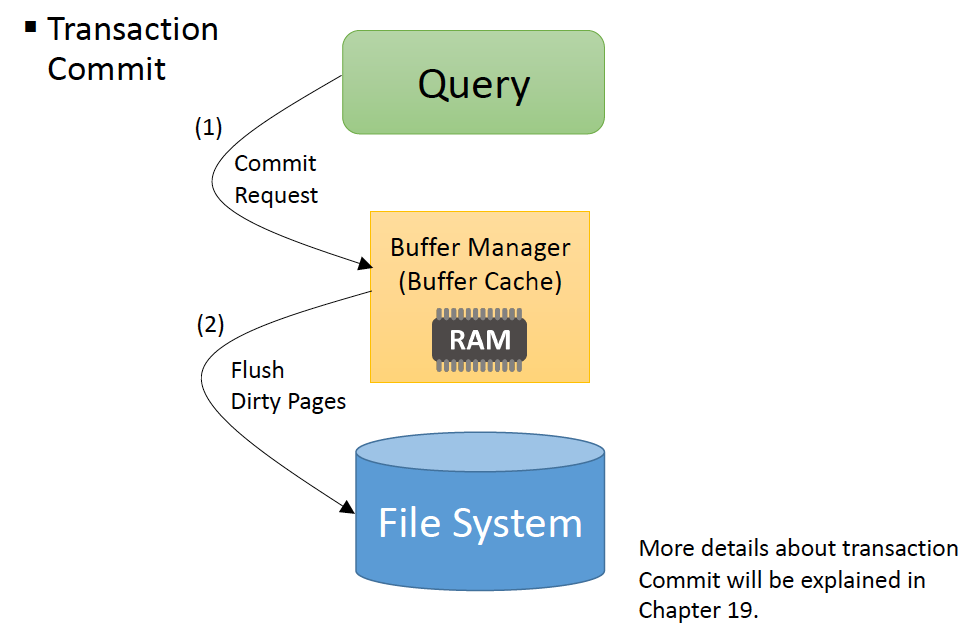
pin 했던 페이지들도 싹다 unpin
dirty page들을 모두 flush (logging을 한다면 안할 수도 있음)
Buffer manager & Replacement Policy
- Pin되어있는 페이지는 현재 살아있는 transaction이 필요로하는 페이지라는 것임.
- 여러 transaction이 각자 pin을 할 수 있으므로, pin은 single bit가 아닌 count로 관리해야함
- Reader: shared lock, Writers: exclusive lock
Buffer-Replacement Policy
-
운영체제는 LRU를 좋아함.
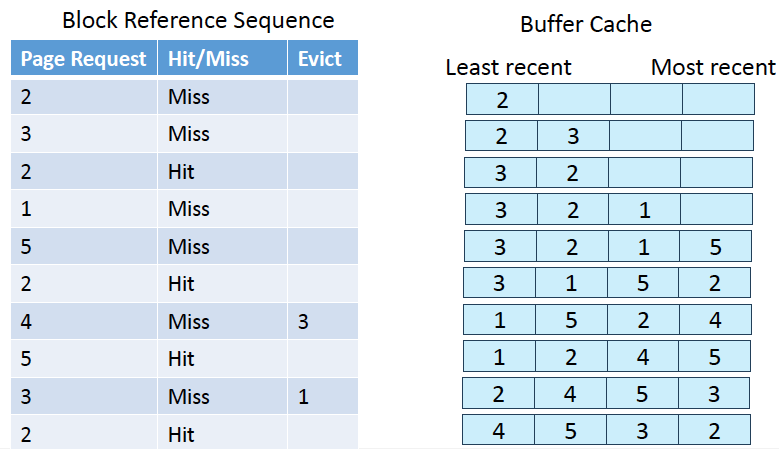
-
이는 DBMS에서 Sequential Flooding이라는 문제가 발생할 수 있음.
-
join을 수행할 때
for each tuple tr of r do
for each tuple ts of s do
if the tr and ts match ...- 만약 ts가 buffer cache보다 크다면 두번째 사이클을 돌 때 캐시 히트가 발생하지 않음
- Data Dictionary는 확률정보, 테이블의 크기, Key들의 분포 등 다양한 통계량을 알고 있음. -> LRU보다 더 잘 할 수 있을 것
Toss-immediate strategy
페이지를 읽자마자 버리는 방법: Buffer Cache가 변하지 않음.
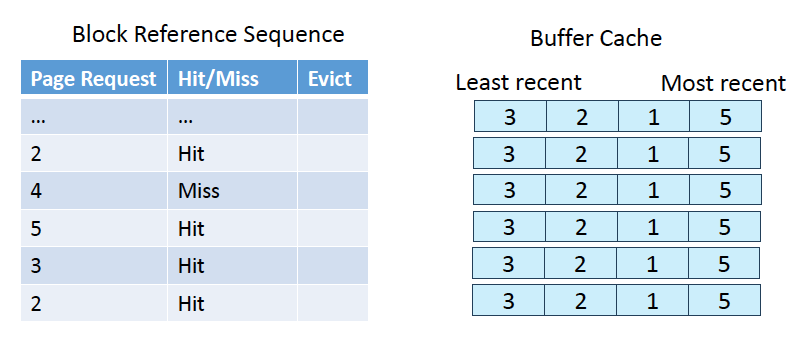
MRU strategy
가장 최근에 사용한 페이지를 replace함
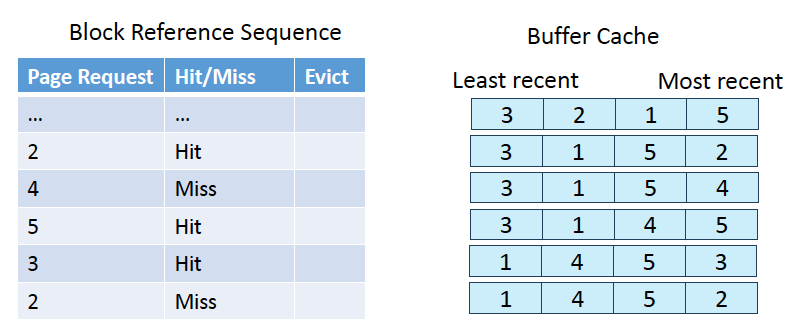
이게 좋은 이유?
- sequential flooding 때문에.
- 바로 직전에 caching한 페이지를 계속 버리면 outer table의 두번째 cycle 때 적어도 일정량의 cache hit가 보장됨
